磕磕碰碰做完的寒假作业TuT(三)
寒假快结束 做完作业好上路🌙
① 实时粉丝部分('◡') 🌼
先上两位up粉丝实时统计的作业图~
兴趣使然做了两个up的粉丝实时可视化,设置是两秒进行一次抓取,共抓取十次。
如果要实现题目所说的每小时抓取,那就把time.sleep(1)的1改成3599就好啦。⏰
沃玛在短短的这几秒之内粉丝数上涨了一个!恭喜沃玛!(哈哈哈哈哈哈哈哈
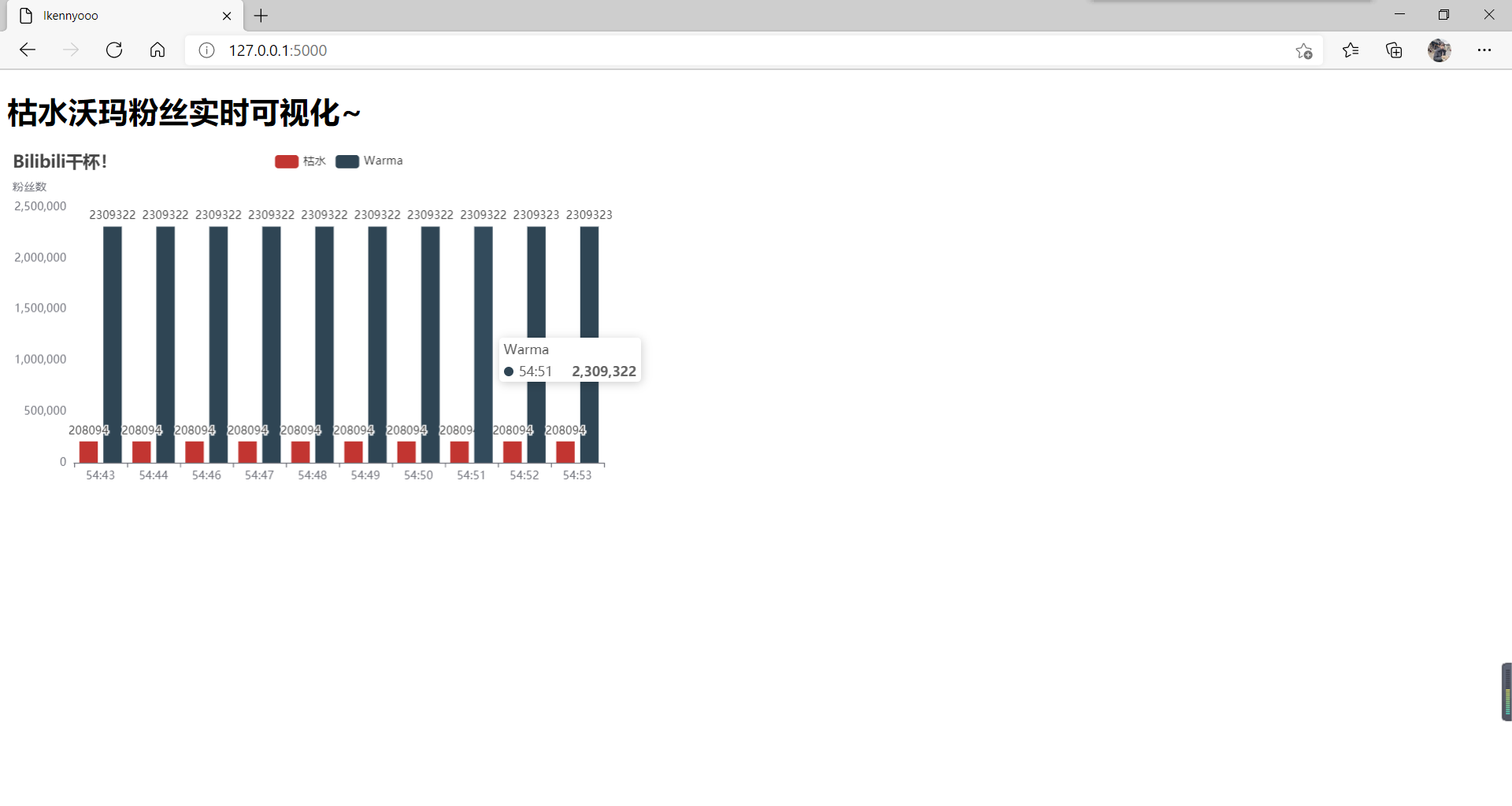
(我太喜欢沃玛和枯水啦!耶!!😍)
——————————————————————————————————
🔺 主要代码(在html里需要有相关引用echarts.min.js、Barchart的代码)✨
——————————————————————————————————
import requests
from flask import Flask, render_template
import time
from pyecharts import options as opts
from pyecharts.charts import Bar
app = Flask(__name__)
@app.route("/")
def index():
shi = []
shu = []
shi_warma = []
shu_warma = []
for i in range (0,10):
uid = "699438"
name = "枯水"
url = "https://api.bilibili.com/x/relation/stat?vmid=" + uid + "&jsonp=jsonp"
resp = requests.get(url) # 通过url爬取到我们想要的json数据
info = eval(resp.text)
fensi = info["data"]["follower"]
shi.append(str(time.strftime("%M:%S")))
shu.append(fensi)
time.sleep(1)
for i in range (0,10):
uid = "53456"
name = "沃玛"
url = "https://api.bilibili.com/x/relation/stat?vmid=" + uid + "&jsonp=jsonp"
resp_warma = requests.get(url) # 通过url爬取到我们想要的json数据
info_warma = eval(resp_warma.text)
fensi_warma = info_warma["data"]["follower"]
shi_warma.append(str(time.strftime("%M:%S")))
shu_warma.append(fensi_warma)
time.sleep(1)
bar = (
Bar()
.add_xaxis([shi[0], shi[1], shi[2], shi[3], shi[4], shi[5], shi[6], shi[7], shi[8], shi[9]])
.add_yaxis("枯水", [shu[0], shu[1], shu[2], shu[3], shu[4], shu[5], shu[6], shu[7], shu[8], shu[9]])
.add_yaxis("Warma", [shu_warma[0], shu_warma[1], shu_warma[2], shu_warma[3], shu_warma[4], shu_warma[5], shu_warma[6], shu_warma[7], shu_warma[8], shu_warma[9]])
.set_global_opts(title_opts=opts.TitleOpts(title="Bilibili干杯!", subtitle="粉丝数"))
)
return render_template("枯水沃玛粉丝可视化.html", shi=shi, shu=shu, bar_options=bar.dump_options())
if __name__ == '__main__':
app.run()
② 粉丝重合度部分('◡') 🦅
爬了两组三部 爬了两天 结果两组重合度都是0
结果重合度还是0,我另起了一个文件测试了一下,发现确实两部两部的重合人数还是有两三个,但是三部都看并写了影评的还是zero。😭
(粉丝数据打码处理)
—————————————
🔺 主要代码( 获取数据 )✨
—————————————
def getData(url,commentAll):
try:
# 获取处理后的请求
req = getRequest(url)
# 打开网址
html = urllib.request.urlopen(req)
# 读取数据(data得到所有数据)
data = html.read()
# print(data)
# 定义soup对象,解析网页
soup = BeautifulSoup(data, "html.parser")
# 找到装有所有评论的id名为content的div
# ["数据"] 数组里只有一个元素----数据
comments = soup.select("#content")[0]
# print(comments)
# 读取到每一条评论,div的class名为name
items = comments.select(".name")
# print(items)
# 循环遍历每一条评论
for i in items:
author = i.string
# 将 用户名装入在字典里面
commentAll.append(author)
except:
pass
return commentAll
—————————————
🔺 主要代码( 重合度计算 )✨
—————————————
num1 = 0
chong12 = [val for val in A if val in B] # 前两部的重合数
chong3 = [val for val in A if val in B if val in C] # 三部总的重合数
print("三部影片影评的重合的用户:") # 打印重合用户
for it in chong3: # 计算重合数(num1为计数变量)
num1 += 1
print(it, end=" ")
print("")
print("三部影片影评的用户重合数:" + str(num1)) # 打印重合数
rate = len(chong3)/(3*len(nihao)-2*len(chong3))
print("三部影片影评的用户重合度:" + str(rate*100) + "%")
上豆瓣看了一下,翻了几页影评,发现确实和抓到的是同一拨人,数据应该没抓错w 可能真的没有人三部都看并写了影评……?👨👩
(本来这里放了评论用户与抓到的数据的对比图,因为看到欧欧的博文想到版权问题,就不放了)
接下来要不带电脑出三天门,回来再爬爬其他电影w
③ 参考资料✍ :
2. Python爬虫基础5天速成(2021全新合集)Python入门+数据可视化
And 谢谢Exungsh小鱼儿、小白马的帮助!感谢感谢!
④ 总结📚
1.这次作业大部分是我自己独立学习、搜索资料、不断调试而成的。ik进步了!耶!✌
2.不过还是有很多不足需要改善。比如算法、代码的理解以及应用,都要努力加强!💪
3.之前有个小半天,因为懒而躺在床上看教程没有动手实践,然后起床的时候发现忘了好多好多,上机不知道从何入手,还要再从头快速浏览寻找记忆点……然后我体会到,光看不练只是假把式,真枪实干才能出真知。📐
4.遇到困难的时候知识面广的同学都能迅速找到对应的应该学习的相关东西,而我经常要百度搜索 “如果要实现XXXX需要什么” 这类问题。所以我还需要扩展知识面,让自己面对问题的时候可以有迹可寻,有理可查。🔍
5.越来越体会到Python的强大👍
以上!寒假第三份作业做完啦!谢谢大家!(完结撒花~🌹🌹🌹)
寒假也好快呀,接下来出三天门,再预习预习高数,就要上课了
新的学期加油加油加油加油加油加油,高数、C++ 我来啦!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号