
交换排序算法---冒泡排序与快速排序
本文介绍两种交换排序方法:冒泡排序、快速排序
冒泡排序(BubbleSort)
基本思想
每次遍历完序列都把最大(小)的元素放在最前面,然后再对剩下的序列重复前面的一个过程,每次遍历完之后待排序序列就少一个元素,当待排序序列减小为只有一个元素的时候排序就结束了.因此,复杂度在最坏的情况下是O(N 2).
实现过程
将被排序的记录数组R[1..n]垂直排列,每个记录R[i]看作是重量为R[i].key的气泡。根据轻气泡不能在重气泡之下的原则,从下往上扫描数组R:凡扫描到违反本原则的轻气泡,就使其向上"飘浮"。
如此反复进行,直到最后任何两个气泡都是轻者在上,重者在下为止。
(1)初始
R[1..n]为无序区。
(2)第一趟扫描
从无序区底部向上依次比较相邻的两个气泡的重量,若发现轻者在下、重者在上,则交换二者的位置。即依次比较(R[n],R[n-1]),(R[n-1],R[n-2]),…,(R[2],R[1]);
对于每对气泡(R[j+1],R[j]),若R[j+1].key<R[j].key,则交换R[j+1]和R[j]的内容。
第一趟扫描完毕时,"最轻"的气泡就飘浮到该区间的顶部,即关键字最小的记录被放在最高位置R[1]上。
(3)第二趟扫描
扫描R[2..n]。扫描完毕时,"次轻"的气泡飘浮到R[2]的位置上……
最后,经过n-1 趟扫描可得到有序区R[1..n]
注意: 1.第i趟扫描时,R[1..i-1]和R[i..n]分别为当前的有序区和无序区;
2.扫描仍是从无序区底部向上直至该区顶部;
3.扫描完毕时,该区中最轻气泡飘浮到顶部位置R[i]上,结果是R[1..i]变为新的有序区。
举例说明排序过程
待排序数组(6,8,5,7,4)完整的排序过程

更多"冒泡排序测试",到《冒泡排序动画演示》
下面是Java实现代码
public class SortSolution {
static int count = 0;
/**
* 改进后的冒泡排序算法的实现:
* @param list 欲排序的数组
* @author tony
*/
public static void improvedBubbleSort(int[] list) {
boolean needNextPass = true;
for(int i = 0; i < list.length && needNextPass; ++i) {
needNextPass = false;//标志置为false,假定未交换
for(int j = list.length-1; j > i; --j) {//j>i;前i个已经有序,无需遍历
if(list[j] < list[j-1]) { //逆序,开始交换
int temp = list[j];
list[j] = list[j-1];
list[j-1] = temp;
needNextPass = true;//标志置为true,发生交换
count++;
}
}
//内层循环判断出有序后,便不再进行循环
if (!needNextPass) return;
System.out.print("第" + (i + 1) + "次排序结果:");
for (int k = 0; k < list.length; k++) {
System.out.print(list[k] + "\t");
}
System.out.println("");
}
System.out.print("最终排序结果:");
for (int l = 0; l < list.length; l++) {
System.out.print(list[l] + "\t");
}
}
public static void main(String[] args) {
int[] array = new int[6];
for (int k = 0; k < array.length; k++) {
array[k] = (int) (Math.random() * 100);
}
System.out.print("排序之前结果为:");
for (int i = 0; i < array.length; i++) {
System.out.print(array[i] + "\t");
}
System.out.println("");
runBubbleSort(array);
System.out.println("交换次数:"+count);
}
}
排序结果如下:
排序之前结果为:11 97 83 89 55 18
第1次排序结果:11 18 97 83 89 55
第2次排序结果:11 18 55 97 83 89
第3次排序结果:11 18 55 83 97 89
第4次排序结果:11 18 55 83 89 97
交换次数:9
时间复杂度
Cmax = n (n-1)/2 = O(n2)
Mmax = 3n(n-1)/2= O(n2)
算法稳定性
快速排序 (Quick Sort)
基本思想:
每一趟排序中找一个点pivot,将表分割成独立的两部分,其中一部分的所有Record都比pivot小,另一部分比pivot大,然后再按此方法对这两部分数据分别进行快速排序。
快速排序采用了分治法的思想:即将问题分解为若干个规模更小但结构与原问题相似的子问题;递归地解这些子问题,然后将这些子问题的解组合为原问题的解。
算法描述:
设要排序的数组是A[0]……A[N-1],首先任意选取一个数据(通常选用第一个数据)作为关键数据,然后将所有比它小的数都放到它前面,所有比它大的数都放到它后面,这个过程称为一趟快速排序。一趟快速排序的算法是:
1)设置两个变量I、J,排序开始的时候:I=0,J=N-1;
2)以第一个数组元素作为关键数据,赋值给key,即 key=A[0];
3)从J开始向前搜索,即由后开始向前搜索(J=J-1),找到第一个小于key的值A[J],并与A[I]交换;
4)从I开始向后搜索,即由前开始向后搜索(I=I+1),找到第一个大于key的A[I],与A[J]交换;
5)重复第3、4、5步,直到 I=J; (3,4步是在程序中没找到时候j=j-1,i=i+1。找到并交换的时候i, j指针位置不变。另外当i=j这过程一定正好是i+或j+完成的最后另循环结束)
例如:待排序的数组A的值分别是:(初始关键数据:X=49) 注意关键X永远不变,永远是和X进行比较,无论在什么位子,最后的目的就是把X放在中间,小的放前面大的放后面。
A[0] 、 A[1]、 A[2]、 A[3]、 A[4]、 A[5]、 A[6]:
49 38 65 97 76 13 27
进行第一次交换后: 27 38 65 97 76 13 49 ( 按照算法的第三步从后面开始找)
进行第二次交换后: 27 38 49 97 76 13 65 ( 按照算法的第四步从前面开始找>X的值,65>49,两者交换,此时:I=3 )
进行第三次交换后: 27 38 13 97 76 49 65( 按照算法的第五步将又一次执行算法的第三步从后开始找
进行第四次交换后: 27 38 13 49 76 97 65( 按照算法的第四步从前面开始找大于X的值,97>49,两者交换,此时:I=4,J=6 )
此时再执行第三步的时候就发现I=J,从而结束一趟快速排序,那么经过一趟快速排序之后的结果是:27 38 13 49 76 97 65,即所以大于49的数全部在49的后面,所以小于49的数全部在49的前面。
快速排序就是递归调用此过程——在以49为中点分割这个数据序列,分别对前面一部分和后面一部分进行类似的快速排序,从而完成全部数据序列的快速排序,最后把此数据序列变成一个有序的序列,根据这种思想对于上述数组A的快速排序的全过程如下所示:
初始状态 {49 38 65 97 76 13 27}
进行一次快速排序之后划分为 {27 38 13} 49 {76 97 65}
分别对前后两部分进行快速排序 {27 38 13} 经第三步和第四步交换后变成 {13 27 38} 完成排序。
{76 97 65} 经第三步和第四步交换后变成 {65 76 97} 完成排序。
伪代码描述:
QUICKSORT(A, p, r)
if p < r //仅当区间长度大于1才开始排序
then q ← PARTITION(A, p, r) //选取pivot主元
QUICKSORT(A, p, q - 1) //对左子序列排序
QUICKSORT(A, q + 1, r) //对右子序列排序
PARTITION(A, p, r)
x ← A[r]
i ← p - 1
for j ← p to r - 1
do if A[j] ≤ x
then i ← i + 1
exchange A[i] ←→ A[j]
exchange A[i + 1] ←→ A[r]
return i + 1
算法图示:
下面以数列a={30,40,60,10,20,50}为例,演示它的快速排序过程(如下图)。
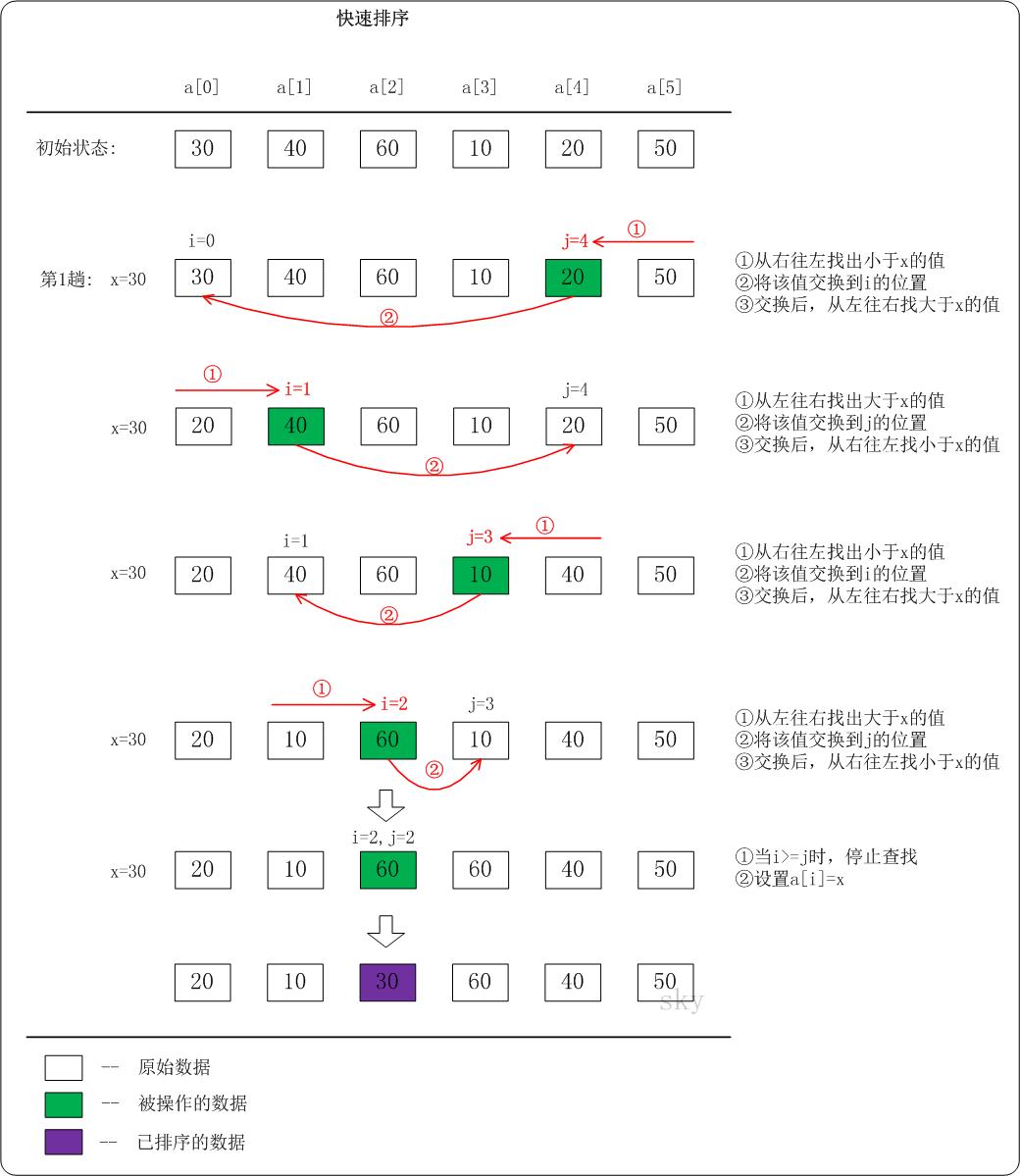
上图只是给出了第1趟快速排序的流程。在第1趟中,设置x=a[i],即x=30。
(01) 从"右 --> 左"查找小于x的数:找到满足条件的数a[j]=20,此时j=4;然后将a[j]赋值a[i],此时i=0;接着从左往右遍历。
(02) 从"左 --> 右"查找大于x的数:找到满足条件的数a[i]=40,此时i=1;然后将a[i]赋值a[j],此时j=4;接着从右往左遍历。
(03) 从"右 --> 左"查找小于x的数:找到满足条件的数a[j]=10,此时j=3;然后将a[j]赋值a[i],此时i=1;接着从左往右遍历。
(04) 从"左 --> 右"查找大于x的数:找到满足条件的数a[i]=60,此时i=2;然后将a[i]赋值a[j],此时j=3;接着从右往左遍历。
(05) 从"右 --> 左"查找小于x的数:没有找到满足条件的数。当i>=j时,停止查找;然后将x赋值给a[i]。此趟遍历结束!
按照同样的方法,对子数列进行递归遍历。最后得到有序数组!
算法实现:
public static void QuickSort(int[] A, int left, int right) {
// 划分后的基准记录的位置
if (left < right) {
int pivotpos = partition(A, left, right); // 对R[left..right]做划分
QuickSort(A, left, pivotpos - 1); // 对左区间递归排序
QuickSort(A, pivotpos + 1, right); // 对右区间递归排序
}
}
public static int partition(int a[], int left, int right) // 返回枢轴位置
{
int low = left;
int high = right;
int pivot = a[low];////数组的第一个作为中轴主元
while (low < high) {
while (low < high && a[high] >= pivot) {//从右往左找
high--;
}
a[low] = a[high];//比中轴小的记录移到低端
while (low < high && a[low] <= pivot) {//从左往右找
low++;
}
a[high] = a[low];//比中轴大的记录移到高端
}
a[low] = pivot;//把中轴记录到尾,此时low和high已经相等,左区间<pivot<右区间
return low;//返回中轴的位置
}
public static void main(String[] args) {
int i;
int[] a = new int[10];
for (int k = 0; k < a.length; k++) {
a[k] = (int) (Math.random() * 100);
}
System.out.printf("before sort:");
for (i = 0; i < a.length; i++)
System.out.printf("%d ", a[i]);
System.out.printf("\n");
QuickSort(a, 0, a.length - 1);
System.out.printf("after sort:");
for (i = 0; i < a.length; i++)
System.out.printf("%d ", a[i]);
System.out.printf("\n");
}
算法性能:
快速排序的运行时间与划分是否对称有关,而后者又与选择了哪一个元素来进行划分有关。如果划分是对称的,那么本算法从渐近意义上来讲,就和合并算法一样快;如果划分是不对称的,那么本算法渐近上就和插入算法一样慢。
最坏情况:
快速排序的最坏情况划分行为发生在划分过程产生的两个区域分别包含n-1个元素和1个元素的时候。假设算法的每一次递归调用中都出现这种不对称划分,划分的时间代价为Θ(n)。因为对一个大小为0的数组进行递归调用后,返回T(0) = Θ(1),故算法的运行时间可以递归的表示为:
T(n) = T(n-1) + T(0) + Θ(n) = T(n-1) + Θ(n)
从直观上来看,如果将每一层递归的代价加起来,就可以得到一个算术级数, 其和值的量级为Θ(n2) , 因此如果在算法的每一层递归上,划分都是最大程度不对称的,那么算法的运行时间就是Θ(n2) ,这种情况,快速排序的运行时间并不比插入排序的更好,此外,当输入数组已经是完全排好序时,快速排序的运行时间为Θ(n2),而在同样情况下,插入排序的运行时间为O(n)
最好情况:
在partition可能做的最平衡的划分中,得到的两个子问题的大小都不可能大于n/2,因为其中的一个子问题的大小为[n/2],另一个子问题的大小为[n/2]-1, 在这种情况下,快速排序运行的速度要快得多,这时表达其运行时间的递归式为:
T(n) = T(n/2) + Θ(n)
该递归式的解为T(n) = O(nlgn),由于在每一层递归上,划分的两边都是对称的,因此从渐近意义上看,算法运行的就快了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号