

深度优先搜索(DFS)数据结构中的应用
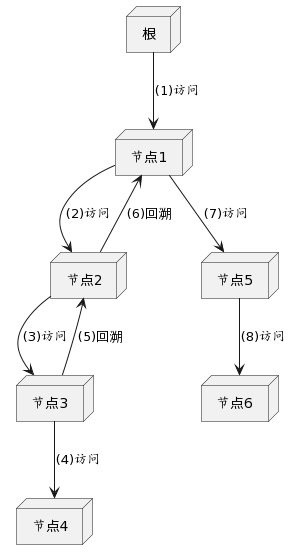
深度优先搜索(DFS)是一种经典的树和图的遍历算法。它通过一条路径尽可能深地搜索树的分支,当节点v的所在边已经被探寻过,搜索将回溯到发现节点v的那条边的起始节点。这一过程一直进行到已发现从源节点可达的所有节点为止。
以下是使用DFS在树状数据结构中搜索包含特定关键字的节点的一个典型实现:
1 using System; 2 using System.Collections.Generic; 3 4 public class TreeSearch 5 { 6 public static void Main() 7 { 8 // 假设这是树的根节点 9 var rootNode = new Node { DisplayName = "Root", Children = new List<Node>() }; 10 11 // 添加一些示例节点 12 rootNode.Children.Add(new Node { DisplayName = "Child1", Children = new List<Node>() }); 13 rootNode.Children.Add(new Node { DisplayName = "Child2", Children = new List<Node>() }); 14 15 // 调用搜索函数,搜索包含"keyword"的节点 16 var matchingItems = SearchNodesContaining(rootNode, "keyword"); 17 18 // 输出匹配的节点 19 foreach (var item in matchingItems) 20 { 21 Console.WriteLine(item.DisplayName); 22 } 23 } 24 25 // 搜索包含特定关键字的节点的函数 26 private static List<Node> SearchNodesContaining(Node node, string searchTerm) 27 { 28 var matchingItems = new List<Node>(); 29 var searchStack = new Stack<Node>(); 30 31 searchStack.Push(node); 32 33 while (searchStack.Count > 0) 34 { 35 var currentNode = searchStack.Pop();//弹栈 36 37 if (currentNode.DisplayName.Contains(searchTerm)) 38 { 39 matchingItems.Add(currentNode); 40 } 41 42 foreach (var child in currentNode.Children) 43 { 44 searchStack.Push(child);//压栈,递归遍历,将不同层级的节点循环插入此栈中,让最下层的子节点在栈的最上面,实现深度优先搜索 45 } 46 } 47 48 return matchingItems; 49 } 50 } 51 52 // 定义树节点的类 53 public class Node 54 { 55 public string DisplayName { get; set; } 56 public List<Node> Children { get; set; } = new List<Node>(); 57 }
在上述代码中,我们首先定义了一个Node类来表示树中的节点,其中包含节点的名称和子节点列表。然后在Main方法中创建了一个树的示例结构,并调用了SearchNodesContaining方法来搜索包含特定关键字的节点。
SearchNodesContaining方法接收一个节点和一个要搜索的关键字作为参数,并返回一个包含所有匹配节点的列表。方法内部使用了一个栈searchStack来存储待访问的节点,并通过一个while循环来遍历整个树。如果当前节点的DisplayName包含搜索关键词,则将该节点加入到matchingItems列表中。同时,还会遍历当前节点的所有子节点,并将它们压入栈中,以便后续处理。
最后,我们遍历并输出matchingItems列表中的所有节点名称,这些节点都是包含指定关键字的。通过这种方式,DFS帮助我们高效地在树状数据结构中找到所需的信息。
补充说明:栈(Stack)是一种特殊的线性数据结构,其特点是只能在一端(称为栈顶)进行添加或删除操作,遵循后进先出(LIFO,Last In First Out)的原则。这意味着最后一个进入栈的元素总是第一个被取出。
栈的主要特性包括:
-
后进先出:栈的顶部是最新的元素,每次添加或删除操作都在栈顶进行。
-
单一入口出口:栈只有一个入口和一个出口,即栈顶。
-
栈顶指针:栈通常使用一个指针来指向栈顶元素。
-
栈的存储结构:栈可以使用数组或者链表来实现,但最常见的是使用数组来实现。
-
栈的操作:栈的基本操作包括压栈(push)、弹栈(pop)、查看栈顶元素(peek)、判断栈是否为空(isEmpty)等。
栈的应用非常广泛,例如在计算机程序设计中,函数调用、递归、表达式求值、状态机等都离不开栈的使用。
DFS XML搜索图示:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号