分布式日志系统Graylog、ELK的分析和对比
一、为什么需要分布式日志系统
一般我们需要进行日志分析场景:直接在日志文件中 grep、awk 就可以获得自己想要的信息。但在规模较大也就是日志量多而复杂的场景中,此方法效率低下,面临问题包括日志量太大如何归档、文本搜索太慢怎么办、如何多维度查询。需要集中化的日志管理,所有服务器上的日志收集汇总。常见解决思路是建立集中式日志收集系统,将所有节点上的日志统一收集,管理,访问。
大型系统通常都是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,构建一套集中式日志系统,可以提高定位问题的效率。
一个完整的集中式日志系统,需要包含以下几个主要特点:
- 收集-能够采集多种来源的日志数据
- 传输-能够稳定的把日志数据传输到中央系统
- 存储-如何存储日志数据
- 分析-可以支持 UI 分析
- 警告-能够提供错误报告,监控机制
在分布式系统中,众多服务分散部署在数十台甚至是上百台不同的服务器上,要想快速方便的实现查找、分析和归档等功能,使用Linux命令等传统的方式查询到想要的日志就费时费力,更不要说对日志进行分析与归纳。
如果有一个集中的日志系统,便可以将各个不同的服务器上面的日志收集在一起,不仅能方便快速查找到相应的日志,还有可能在众多日志数据中挖掘到一些意想不到的关联关系。
作为DevOps工程师,会经常收到分析生产日志的需求。在机器规模较少、生产环境管理不规范时,可以通过分配系统账号,采用人肉的方式登录服务器查看日志。然而高可用架构中,日志通常分散在多节点,日志量也随着业务增长而增加。当业务达到一定规模、架构变得复杂,靠人肉登录主机查看日志的方式就会变得混乱和低效。解决这种问题的方法,需要构建一个日志管理平台:对日志进行汇聚和分析,并通过Web UI授权相关人员查看日志权限。
二、ELK介绍
ELK是三个开源软件的缩写,分别为:Elasticsearch 、 Logstash以及Kibana , 它们都是开源软件。不过现在还新增了一个Beats,它是一个轻量级的日志收集处理工具(Agent),Beats占用资源少,适合于在各个服务器上搜集日志后传输给Logstash,官方也推荐此工具,目前由于原本的ELK Stack成员中加入了 Beats 工具所以已改名为Elastic Stack。
Elastic Stack包含:
-
Elasticsearch是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。详细可参考Elasticsearch权威指南
-
Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
-
Kibana 也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
- Beats在这里是一个轻量级日志采集器,其实Beats家族有6个成员,早期的ELK架构中使用Logstash收集、解析日志,但是Logstash对内存、cpu、io等资源消耗比较高。相比 Logstash,Beats所占系统的CPU和内存几乎可以忽略不计
ELK Stack (5.0版本之后)--> Elastic Stack == (ELK Stack + Beats)。目前Beats包含六种工具:
- Packetbeat: 网络数据(收集网络流量数据)
- Metricbeat: 指标 (收集系统、进程和文件系统级别的 CPU 和内存使用情况等数据)
- Filebeat: 日志文件(收集文件数据)
- Winlogbeat: windows事件日志(收集 Windows 事件日志数据)
- Auditbeat:审计数据 (收集审计日志)
- Heartbeat:运行时间监控 (收集系统运行时的数据)
2.1 ELK架构
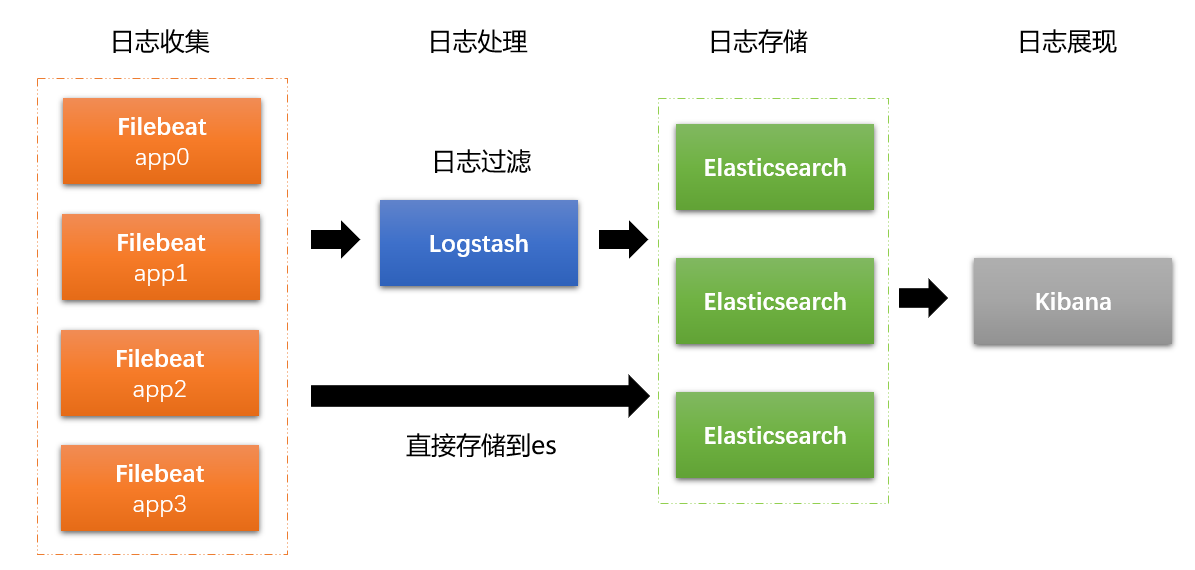
filebeat是作为客户端的日志收集器,部署在若干个产出日志的应用系统上,将数据传输到es集群和logstash服务,传递给logstash的数据会被进一步处理最终流入es集群,kibana从es中获取索引日志信息进行展现。
2.2 ELK优缺
2.2.1、ELK优点
- 处理方式灵活:elasticsearch是实时全文索引,具有强大的搜索功能
- 配置相对简单:elasticsearch全部使用JSON 接口,logstash使用模块配置,kibana的配置文件部分更简单。
- 检索性能高效:基于优秀的设计,虽然每次查询都是实时,但是也可以达到百亿级数据的查询秒级响应。
- 集群线性扩展:elasticsearch和logstash都可以灵活线性扩展
- 前端操作绚丽:kibana的前端设计比较绚丽,而且操作简单
2.2.2、ELK缺点
- 不能处理多行日志,比如Mysql慢查询,Tomcat/Jetty应用的Java异常打印
- 不能保留原始日志,只能把原始日志分字段保存,这样搜索日志结果是一堆Json格式文本,无法阅读。
- 不复合正则表达式匹配的日志行,被全部丢弃。
三、Graylog
graylog是一个简单易用、功能较全面的日志管理工具,graylog也采用Elasticsearch作为存储和索引以保障性能,MongoDB用来存储少量的自身配置信息,master-node模式具有很好的扩展性,UI上自带的基础查询与分析功能比较实用且高效,支持LDAP、权限控制并有丰富的日志类型和标准(如syslog,GELF)并支持基于日志的报警。
在日志接收方面通常是网络传输,可以是TCP也可以是UDP,在实际生产环境量级较大多数采用UDP,也可以通过MQ来消费日志。
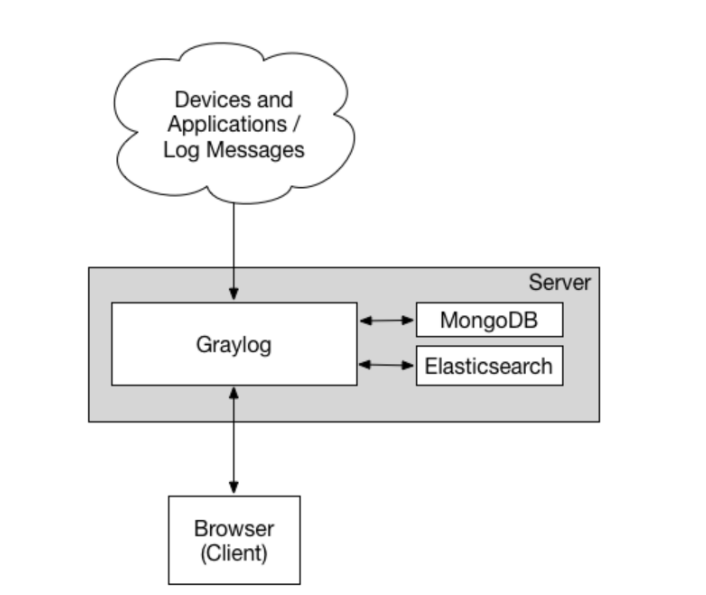
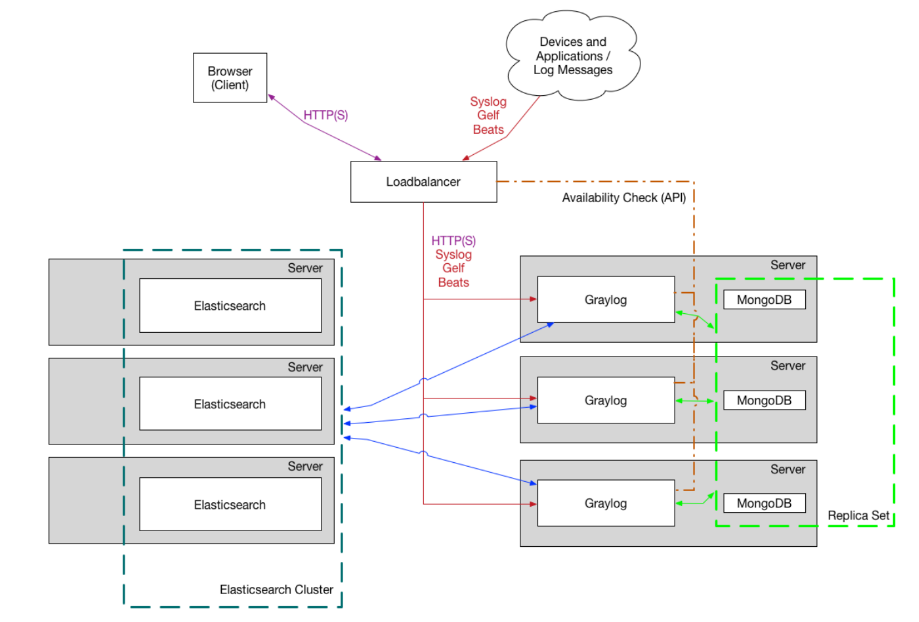
3.1 Graylog架构
-
单机部署
-
集群部署
官方文档:https://docs.graylog.org/docs
3.2 Graylog优缺
3.2.1、Graylog优点
- 一体化方案,安装方便,不像ELK有3个独立系统间的集成问题。
- 采集原始日志,并可以事后再添加字段,比如http_status_code,response_time等等。
- 自己开发采集日志的脚本,并用curl/nc发送到Graylog Server,发送格式是自定义的GELF,Flunted和Logstash都有相应的输出GELF消息的插件。自己开发带来很大的自由度。实际上只需要用inotify_wait监控日志的MODIFY事件,并把日志的新增行用curl/nc发送到Graylog Server就可。
- 搜索结果高亮显示,就像google一样。
- 搜索语法简单,比如: source:mongo AND reponse_time_ms:>5000 ,避免直接输入elasticsearch搜索json语法搜索条件可以导出为elasticsearch的搜索json文本,方便直接开发调用elasticsearch rest api的搜索脚本。
3.2.2、Graylog缺点
- 控制台操作页面是英文的,针对国内开发使用者使用起来不方便,还得额外汉化,汉化可能失败
- 使用网络传输,可能会占用项目网络

 浙公网安备 33010602011771号
浙公网安备 33010602011771号