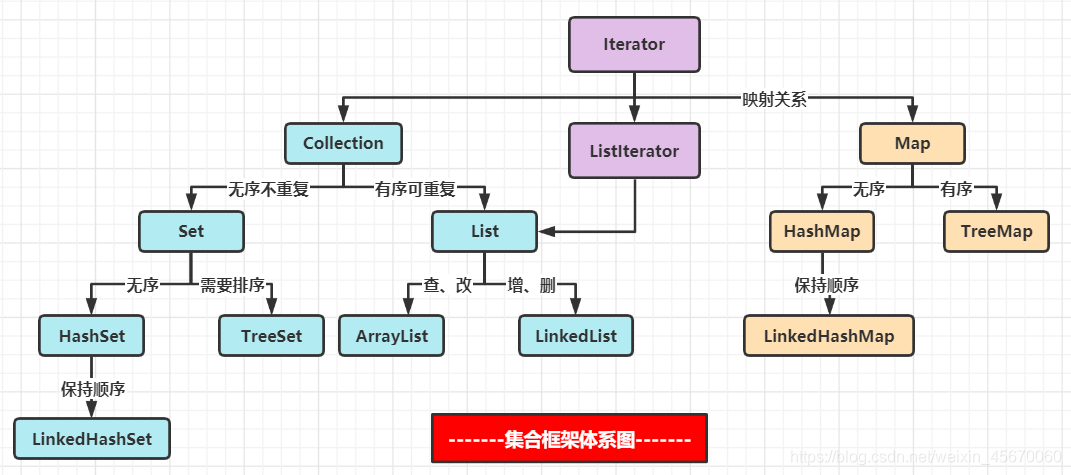
集合源码探索
一、迭代器(Iterator)
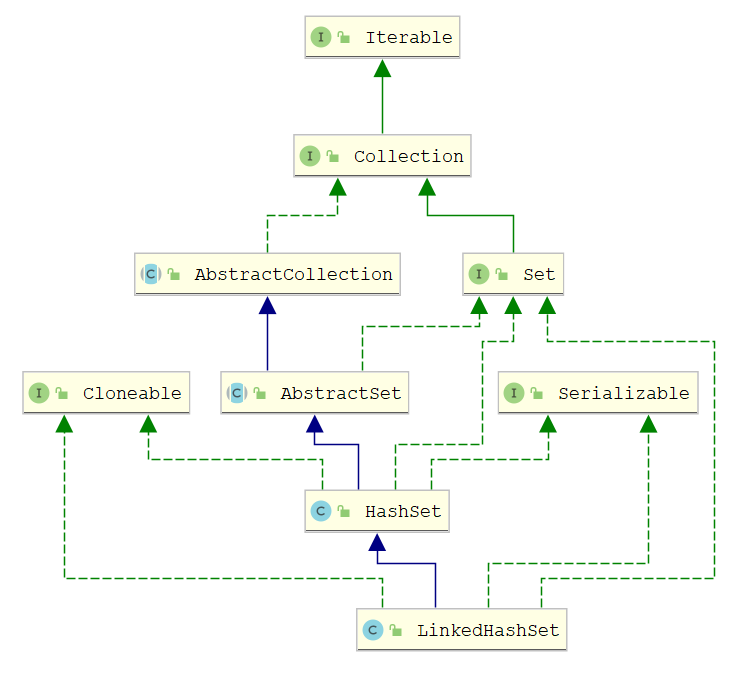
JAVA集合以面向对象的思想分为两大类,单例集合与双例集合。
Collection为单例集合,Map为双例集合
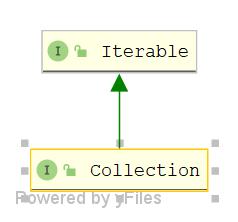
Collection接口是继承自Iterable接口,Iterable接口是一个迭代器![]()
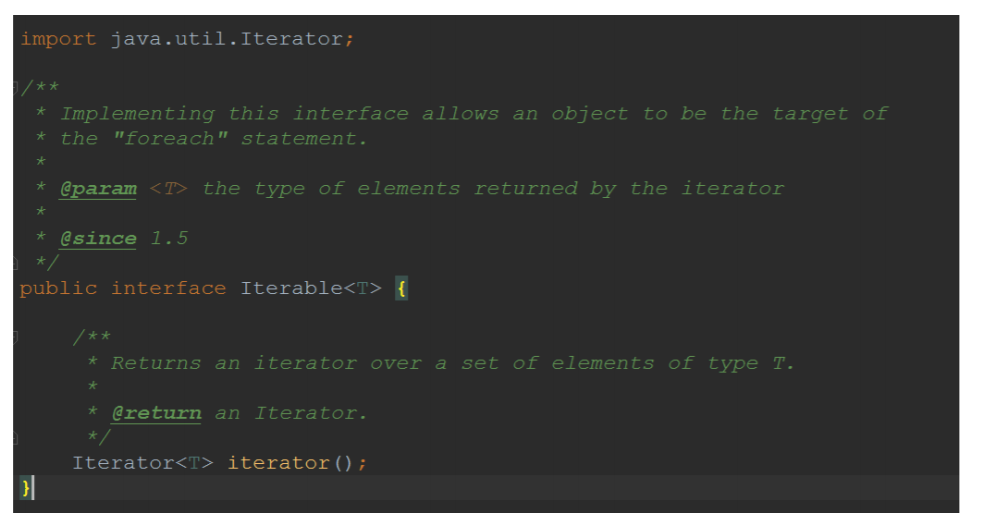
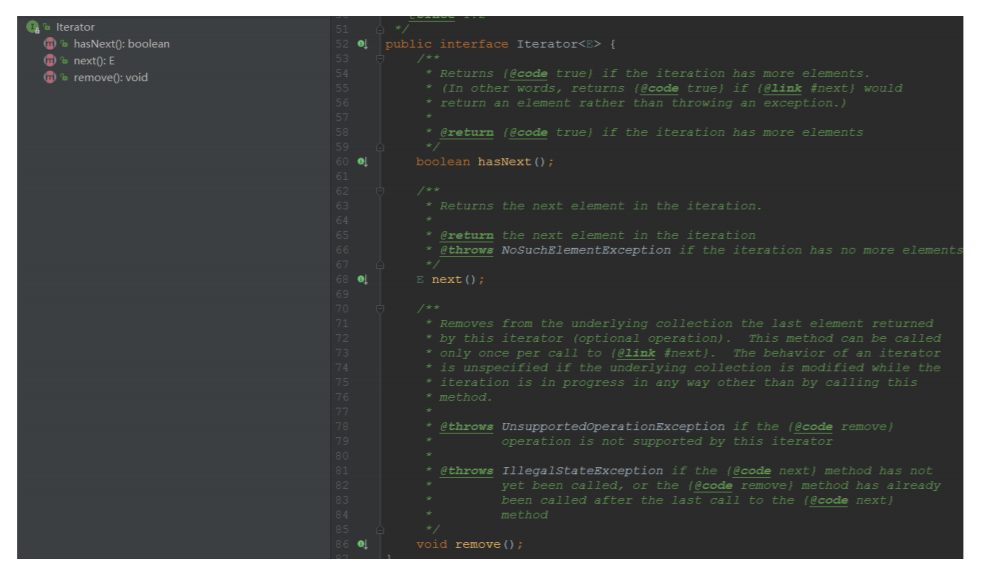
它有iterator()这个⽅法,返回的是Iterator 再来看⼀下,Iterator也是⼀个接⼝,它只有三个⽅法:
- hasNext()
- next()
- remove()
可是,我们没能找到对应的实现⽅法,只能往Collection的⼦类下找找了,于是我们找到了--- >ArrayList于是,我们在ArrayList下找到了iterator实现的身影:
它是在ArrayList以内部类的⽅式实现的!并且, 从源码可知:Iterator实际上就是在遍历集合
二、Collection接口
Collection接口继承自Iterable接口
Collection继承体系
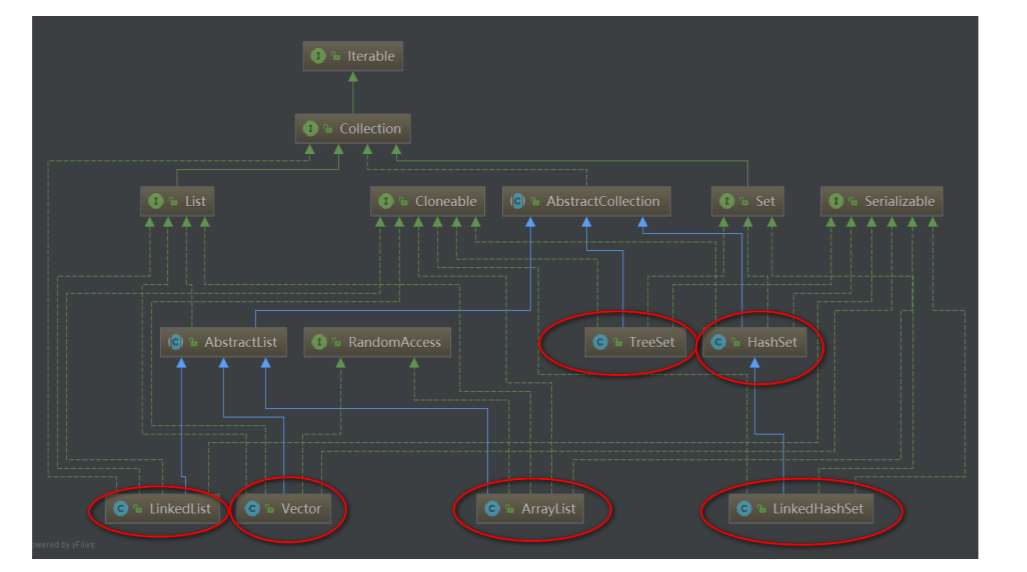
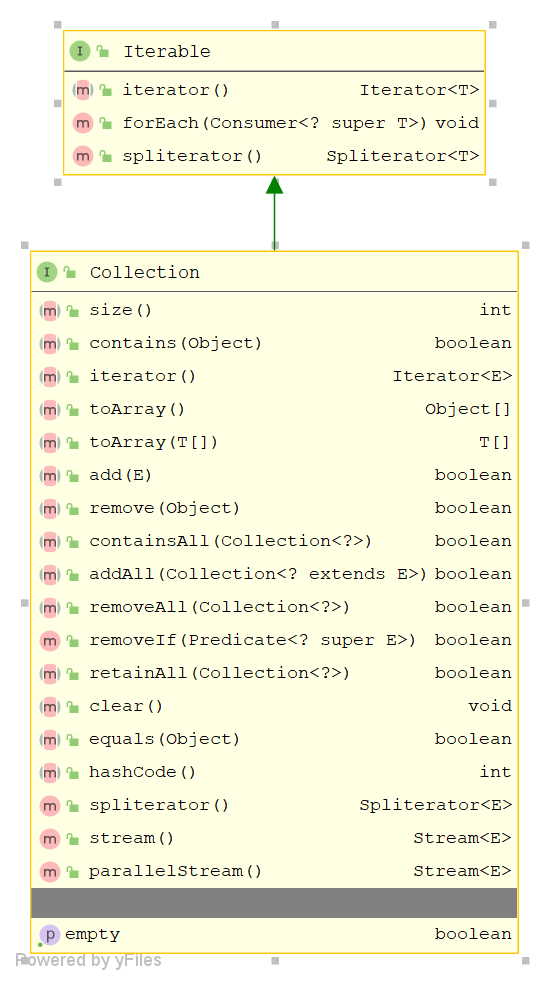
Collection功能:
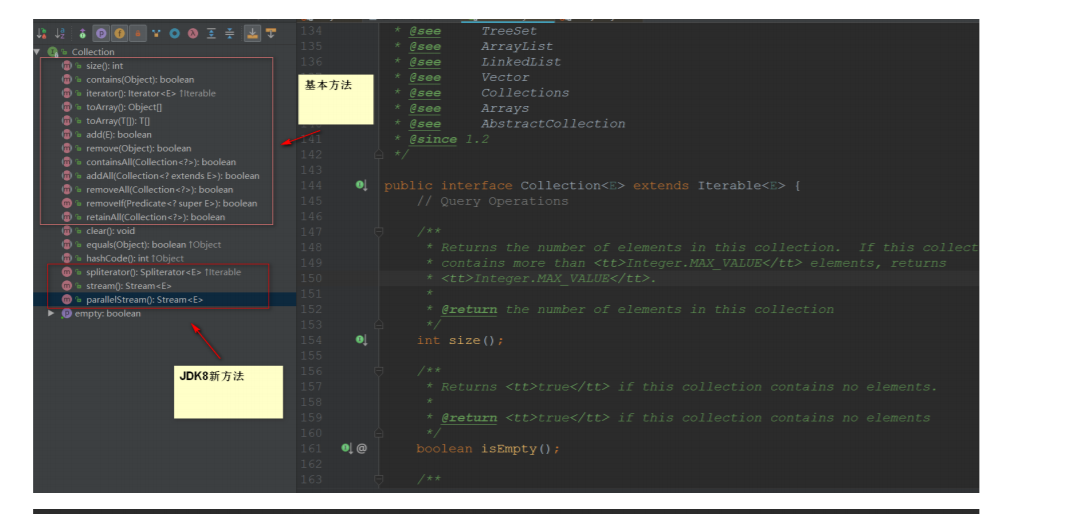
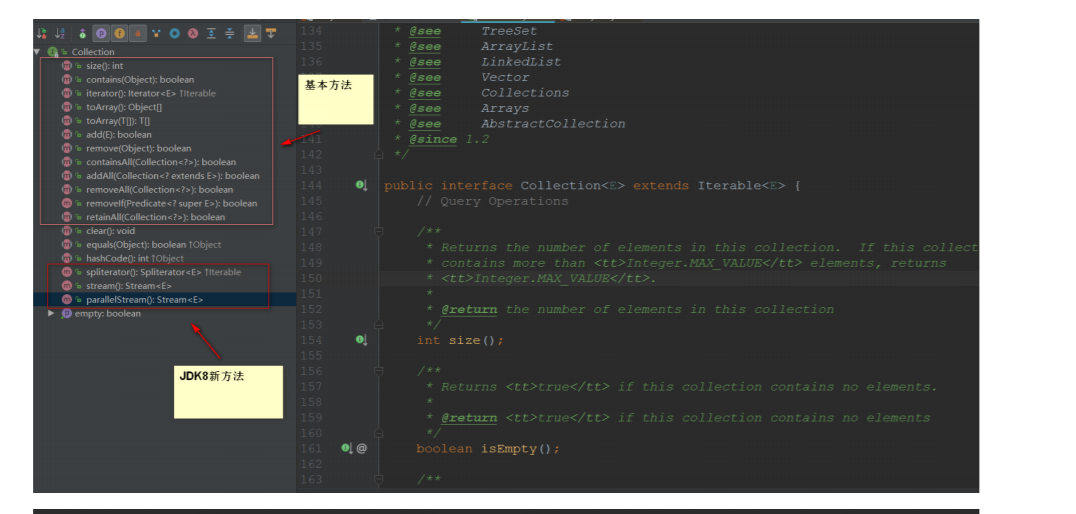
三、List集合
Collection主要学习集合的类型两种:Set和List
List集合的特点就是:有序(存储顺序和取出顺序⼀致),可重复
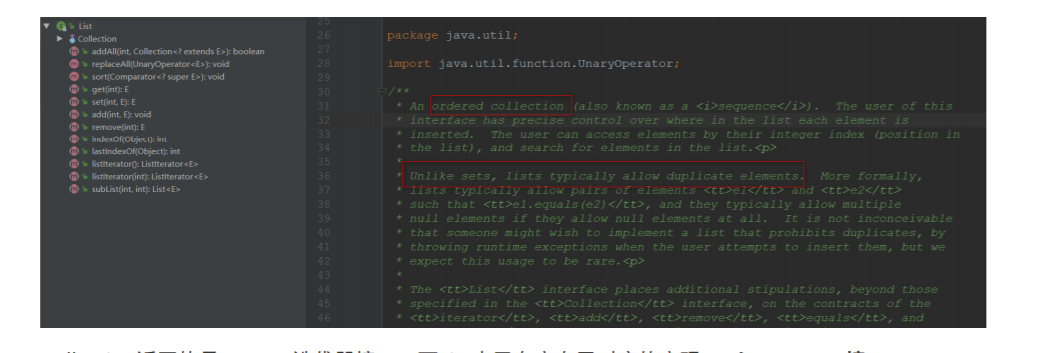
Collection返回的是Iterator迭代器接⼝,⽽List中⼜有它⾃⼰对应的实现-->ListIterator接⼝ 该接⼝⽐普通的Iterator接⼝多了⼏个⽅法
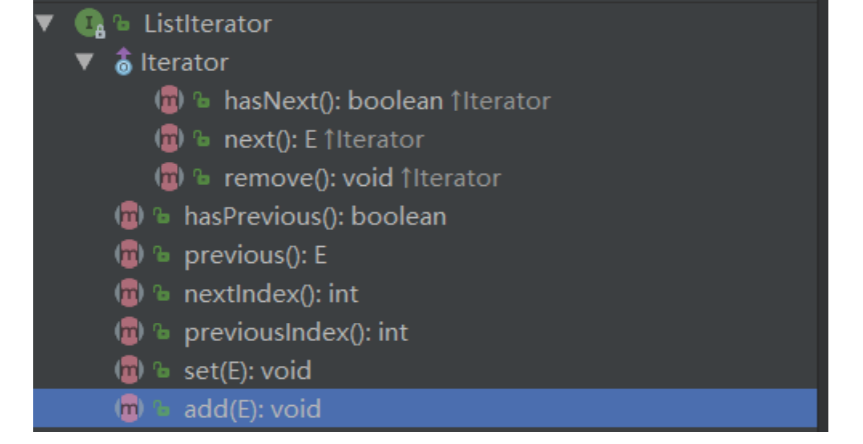
从⽅法名就可以知道:ListIterator可以往前遍历,添加元素,设置元素
List集合常⽤的⼦类有三个:
- ArrayList 底层数据结构是数组。线程不安全
- LinkedList 底层数据结构是链表。线程不安全
- Vector 底层数据结构是数组。线程安全
四、Set集合
从Set集合的⽅法我们可以看到:⽅法没有⽐Collection要多
Set集合的特点是:元素不可重复
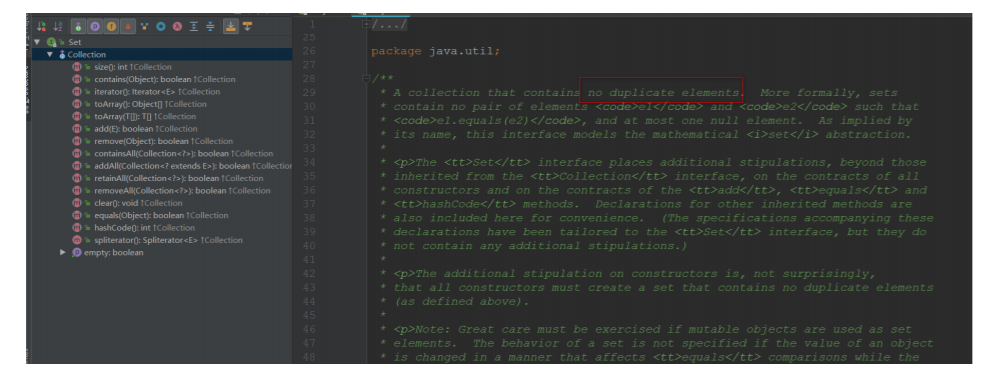
Set集合常⽤⼦类
- HashSet集合 :
底层数据结构是哈希表(是⼀个元素为链表的数组)
- TreeSet集合:
底层数据结构是红⿊树(是⼀个⾃平衡的⼆叉树)
保证元素的排序⽅式
- LinkedHashSet集合:
底层数据结构由哈希表和链表组成。
五、ArrayList解析
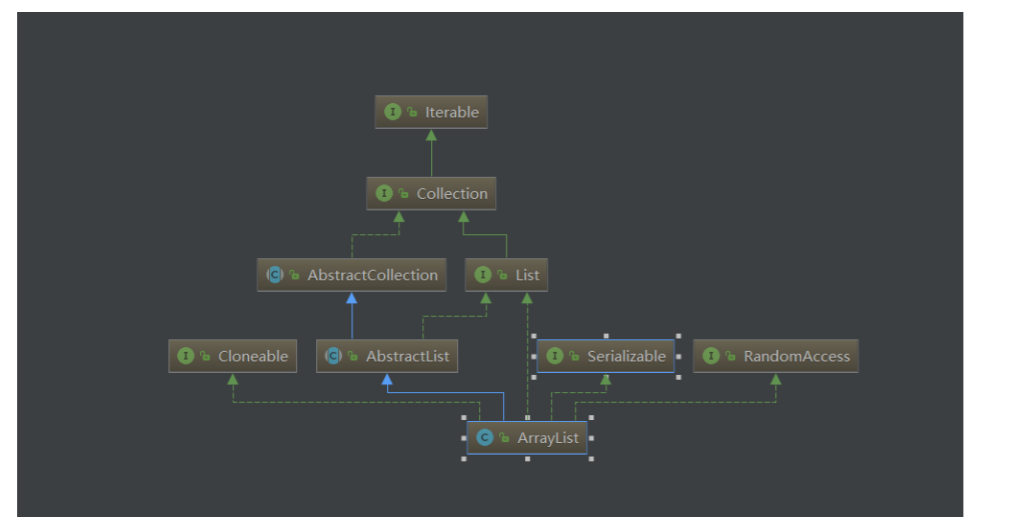
ArrayList继承自AbstractList,实现了List、Cloneable、Serializable、RandomAccess接口
ArrayList属性:
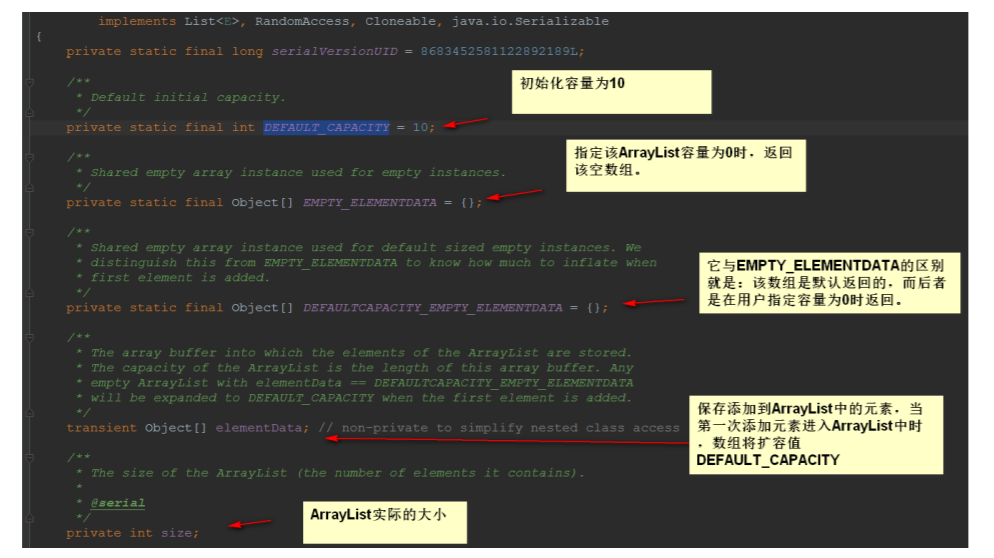
根据上⾯我们可以清晰的发现:ArrayList底层其实就是⼀个数组,ArrayList中有扩容这么⼀个概念, 正因为它扩容,所以它能够实现“动态”增⻓
5.1、构造方法
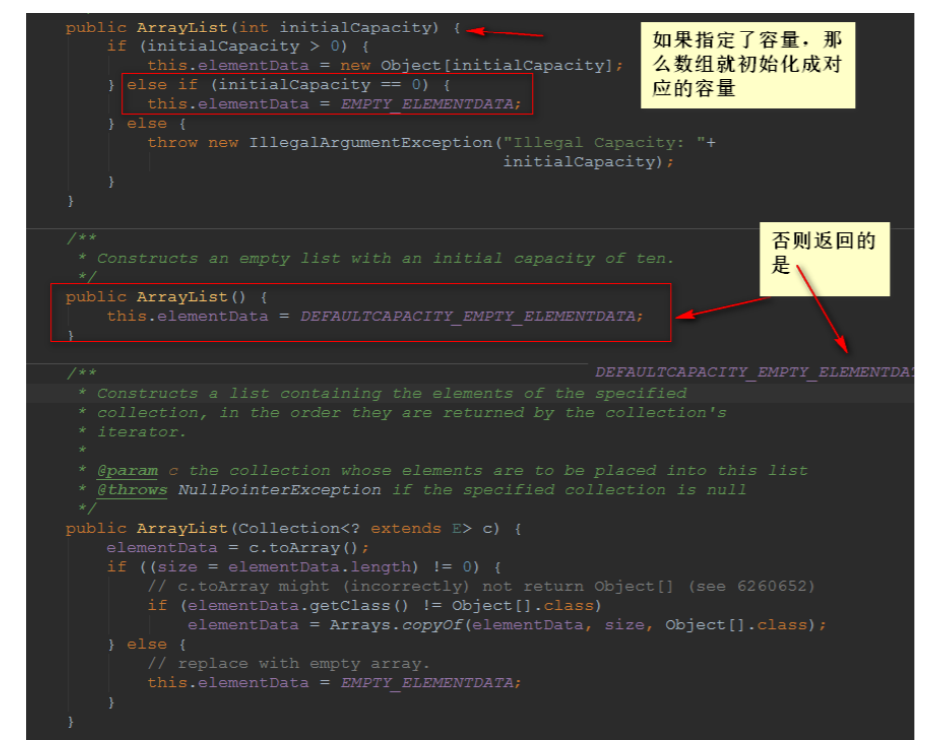
5.2、Add方法
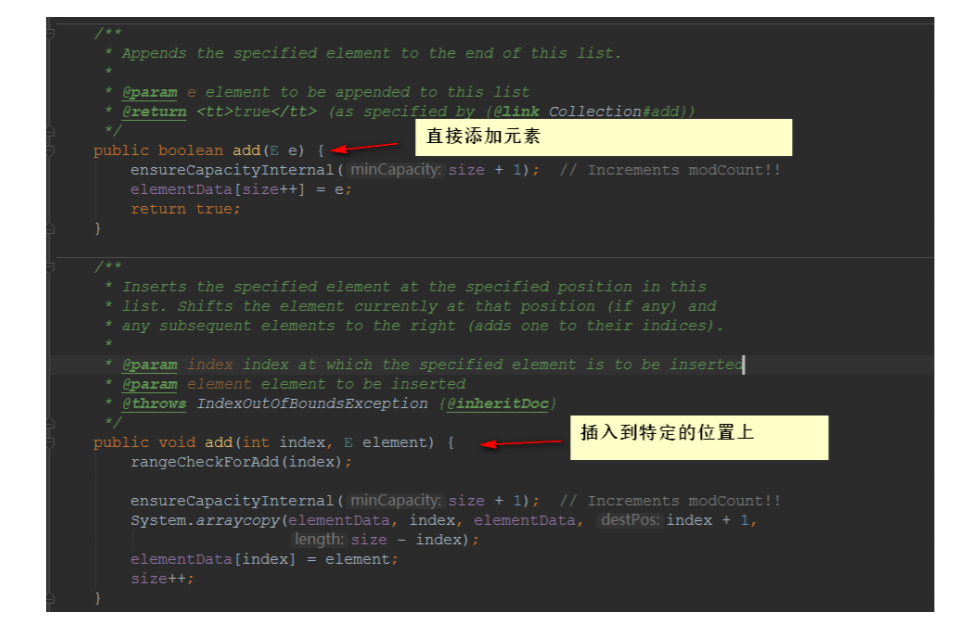
5.2.1 add(E e)
将指定的元素追加到此列表的末尾。
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
步骤:
- 检查是否需要扩容 插⼊元素,确认list容量,尝试容量加1,看看有⽆必要
- 插入元素
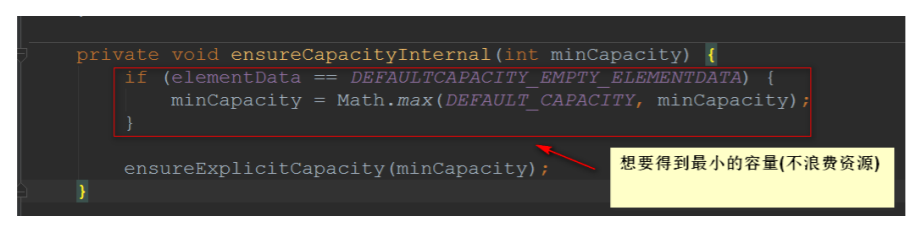
随后调⽤ ensureExplicitCapacity() 来确定明确的容量,我们也来看看这个⽅法是怎么实现的:
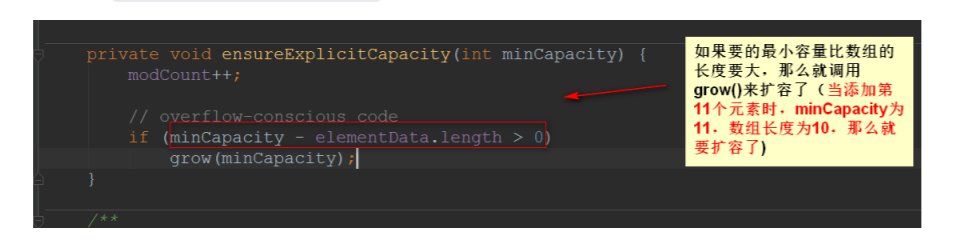
所以,接下来看看 grow() 是怎么实现的
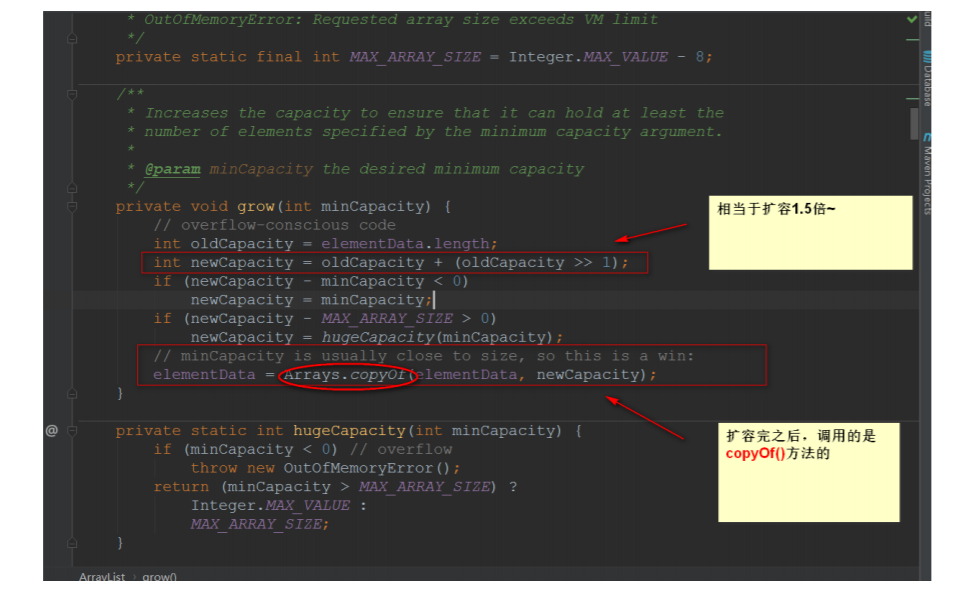
进去看 copyOf() ⽅法
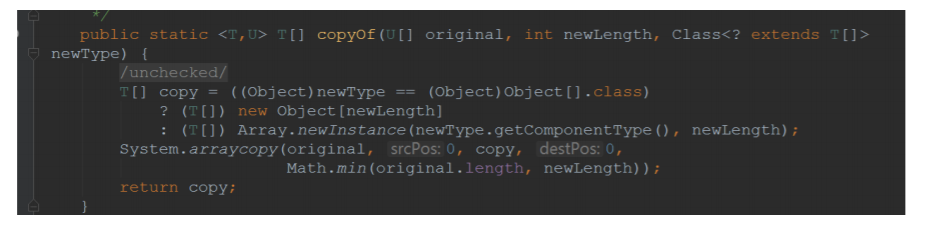
到⽬前为⽌,我们就可以知道 add(E e) 的基本实现了:
⾸先去检查⼀下数组的容量是否⾜够
- ⾜够:直接添加
- 不⾜够:扩容
- 扩容到原来的1.5倍
- 第⼀次扩容后,如果容量还是⼩于minCapacity,就将容量扩充为minCapacity。
5.2.2 add(int index, E element)
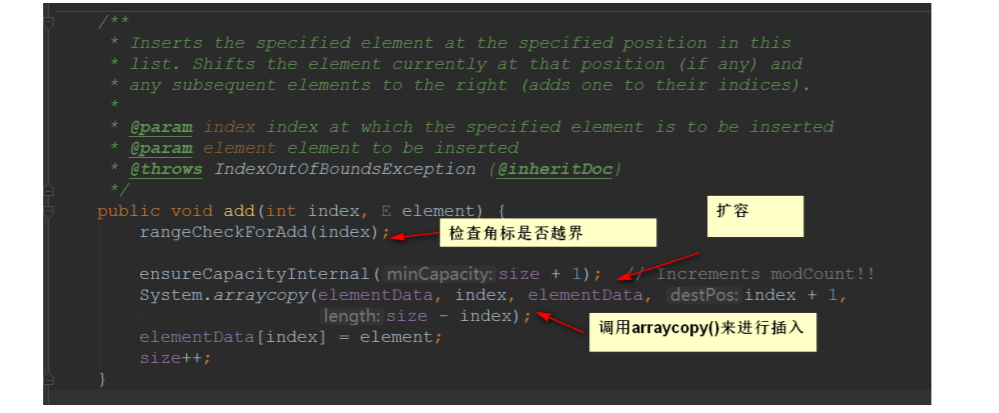
步骤实现:
检查⻆标
空间检查,
如果有需要进⾏扩容 插⼊元素
我们发现,与扩容相关ArrayList的add⽅法底层其实都是 arraycopy() 来实现的 看到 arraycopy() ,我们可以发现:该⽅法是由C/C++来编写的,并不是由Java实现:

总的来说: arraycopy() 还是⽐较可靠⾼效的⼀个⽅法。
5.3、get方法
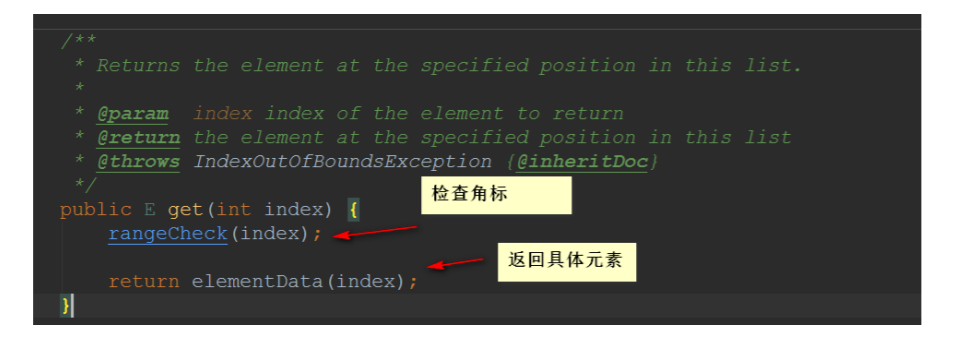
// 检查⻆标
private void rangeCheck(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
// 返回元素
E elementData(int index) {
return (E) elementData[index];
}
实现步骤:
- 检查角标
- 返回元素
5.4、set方法
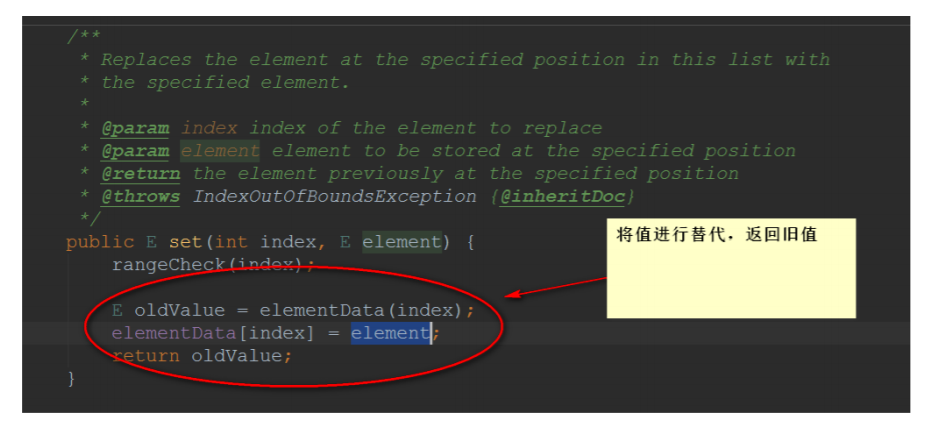
//检查角标
private void rangeCheck(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
//替换元素
E elementData(int index) {
return (E) elementData[index];
}
//返回旧值
return oldValue;
实现步骤:
- 检查⻆标
- 替代元素
- 返回旧值
5.5、remove方法
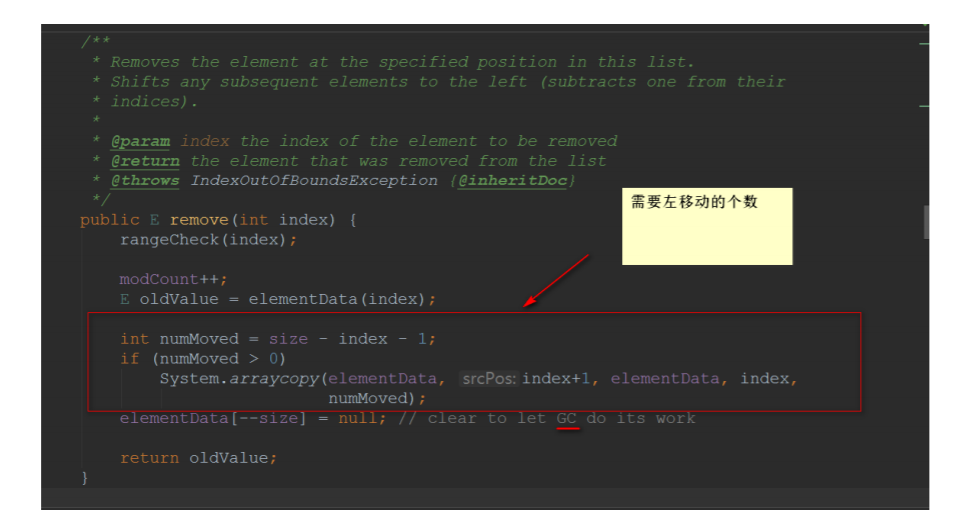
实现步骤:
- 检查⻆标
- 删除元素
- 计算出需要移动的个数,并移动
- 设置为null,让Gc回收
ArrayList是基于动态数组实现的,在增删时候,需要数组的拷⻉复制。 ArrayList的默认初始化容量是10,每次扩容时候增加原先容量的⼀半,也就是变为原来的1.5倍
5.6、Vector与ArrayList区别
Vector是jdk1.2的类了,⽐较⽼旧的⼀个集合类。
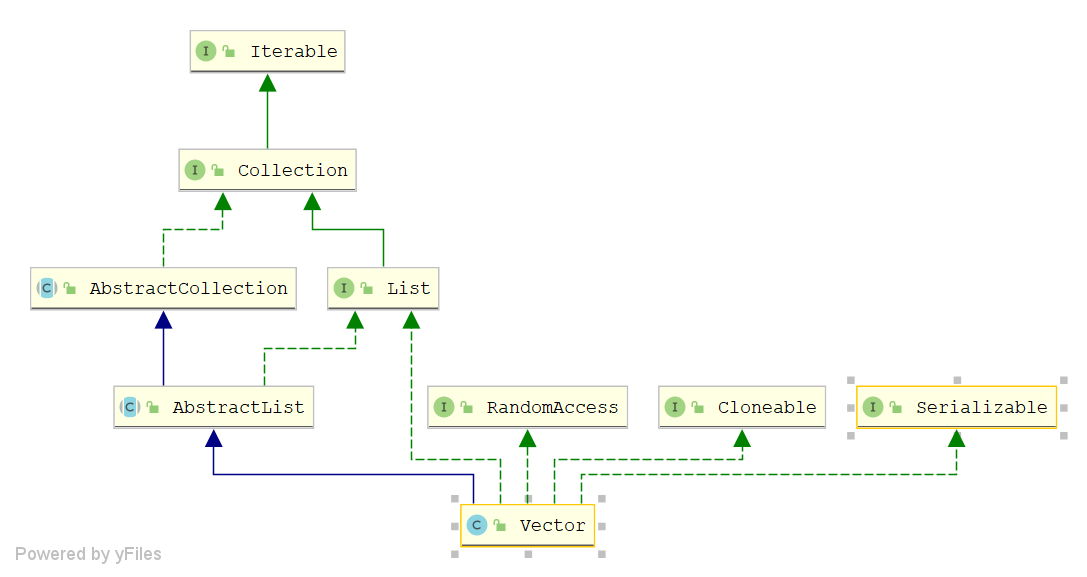
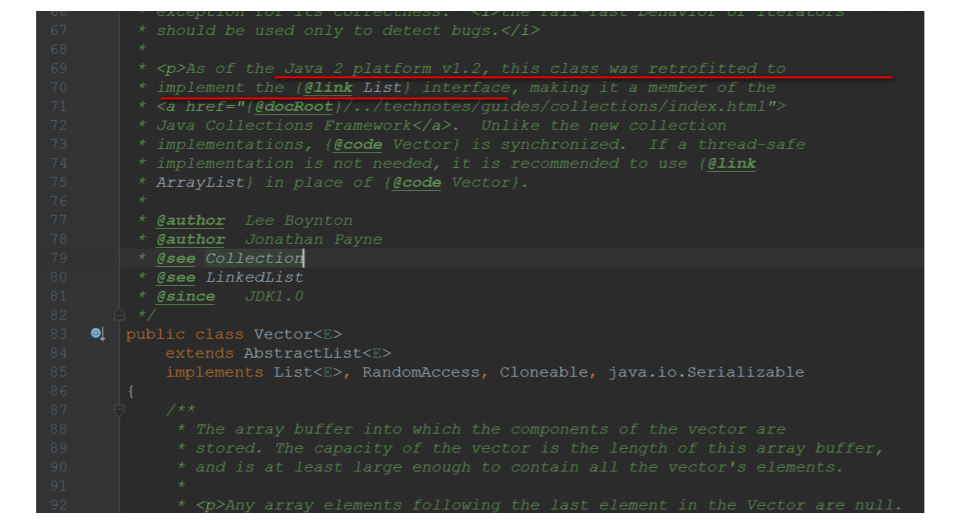
Vector底层也是数组,与ArrayList最⼤的区别就是:同步(线程安全) Vector是同步的
我们可以从⽅法上就可以看得出来:
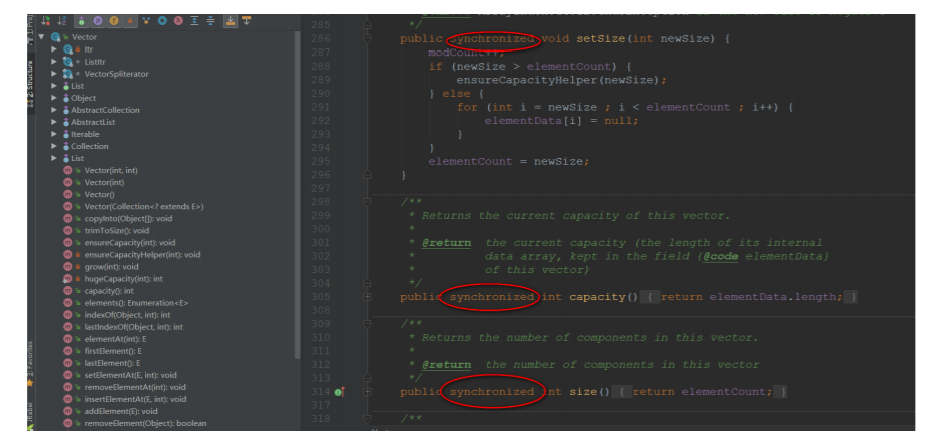
在要求⾮同步的情况下,我们⼀般都是使⽤ArrayList来替代Vector的了~ 如果想要ArrayList实现同步,可以使⽤Collections的⽅法:就可以实现同步了
List list = Collections.synchronizedList(new ArrayList(...));
还有另⼀个区别:
- ArrayList在底层数组不够⽤时在原来的基础上扩展0.5倍,Vector是扩展1倍。
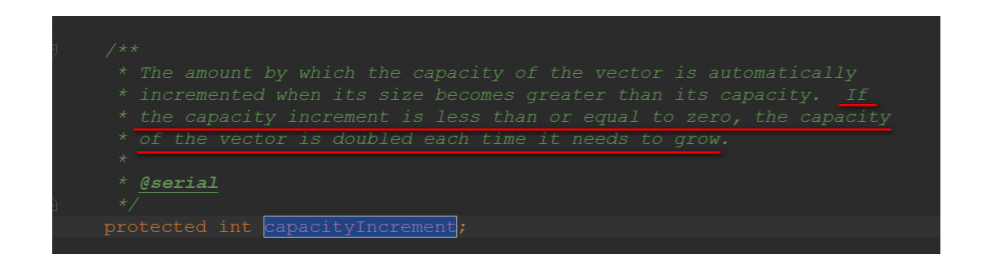
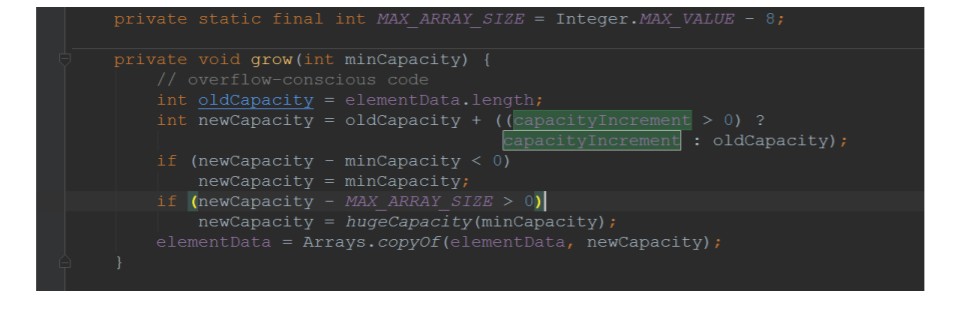
虽然同步容器的所有方法都加了锁,但是对这些容器的复合操作无法保证其线程安全性。需要客户端通过主动加锁来保证。
public Object deleteLast(Vector v){
int lastIndex = v.size()-1;
v.remove(lastIndex);
}
上面这个方法是一个复合方法,包括size()和remove(),乍一看上去好像并没有什么问题,无论是size()方法还是remove()方法都是线程安全的,那么整个deleteLast方法应该也是线程安全的。
但是时,如果多线程调用该方法的过程中,remove方法有可能抛出ArrayIndexOutOfBoundsException。
我们上面贴了remove的源码,我们可以分析得出:当index >= elementCount时,会抛出ArrayIndexOutOfBoundsException ,也就是说,当当前索引值不再有效的时候,将会抛出这个异常。
因为removeLast方法,有可能被多个线程同时执行,当线程2通过index()获得索引值为10,在尝试通过remove()删除该索引位置的元素之前,线程1把该索引位置的值删除掉了,这时线程一在执行时便会抛出异常。

为了避免出现类似问题,可以尝试加锁:
public void deleteLast() {
synchronized (v) {
int index = v.size() - 1;
v.remove(index);
}
}
六、LinkedList解析
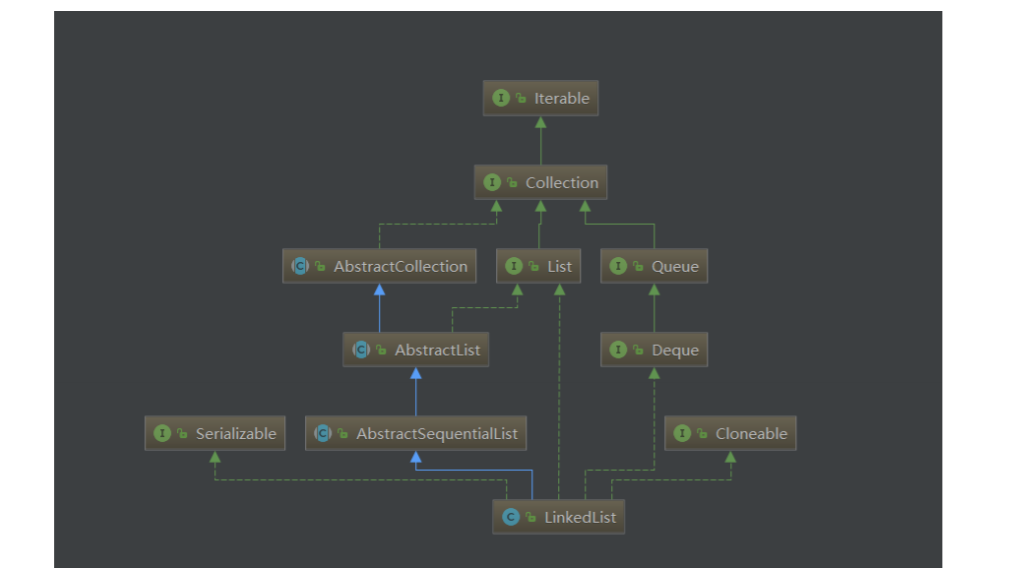
LinkedList底层是双向链表
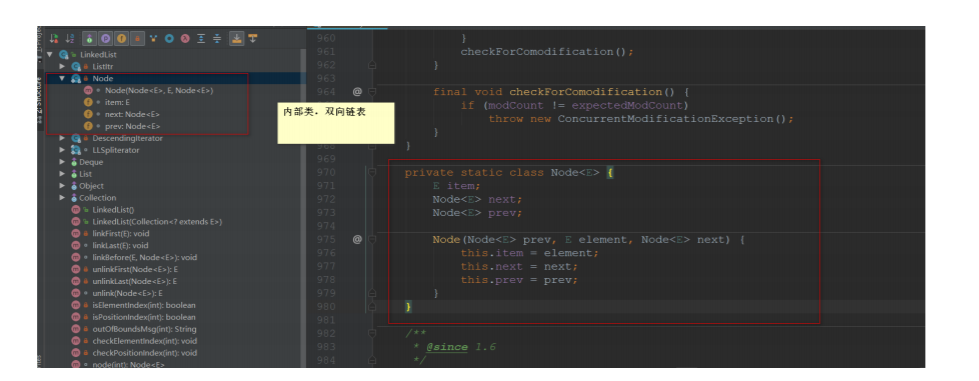
从结构上,我们还看到了LinkedList实现了Deque接⼝,因此,我们可以操作LinkedList像操作队列 和栈⼀样

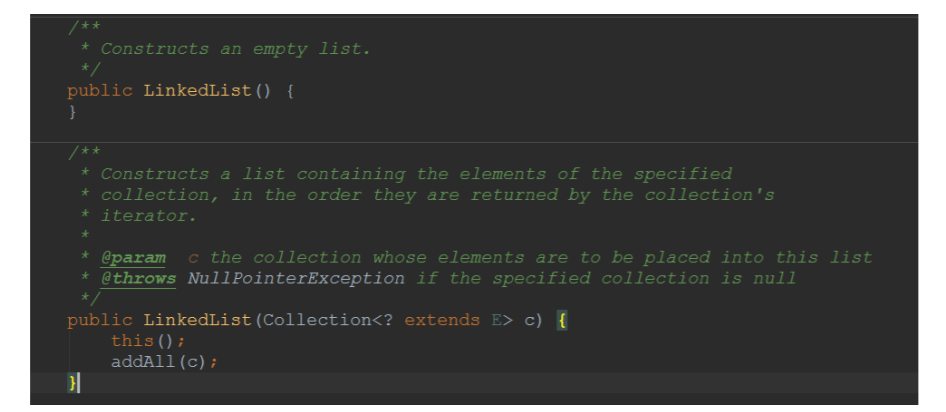
6.1、构造方法
6.2、add方法


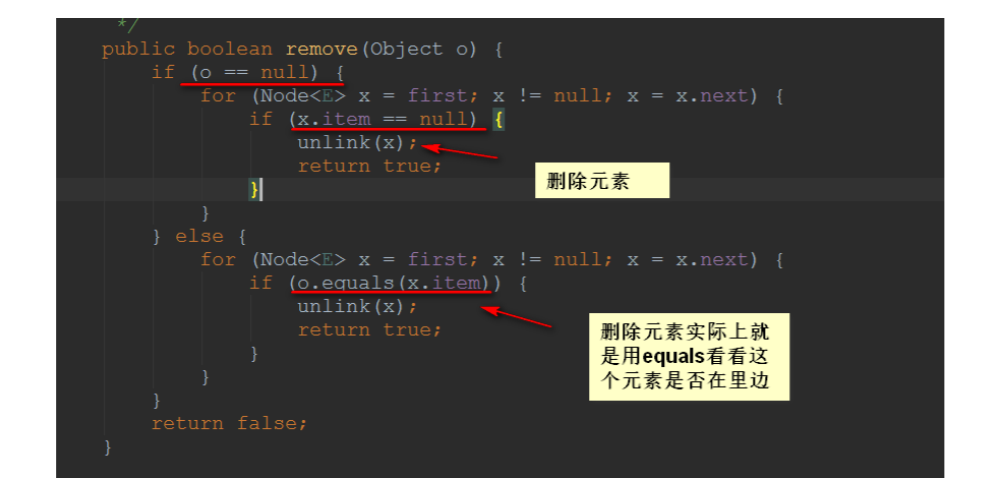
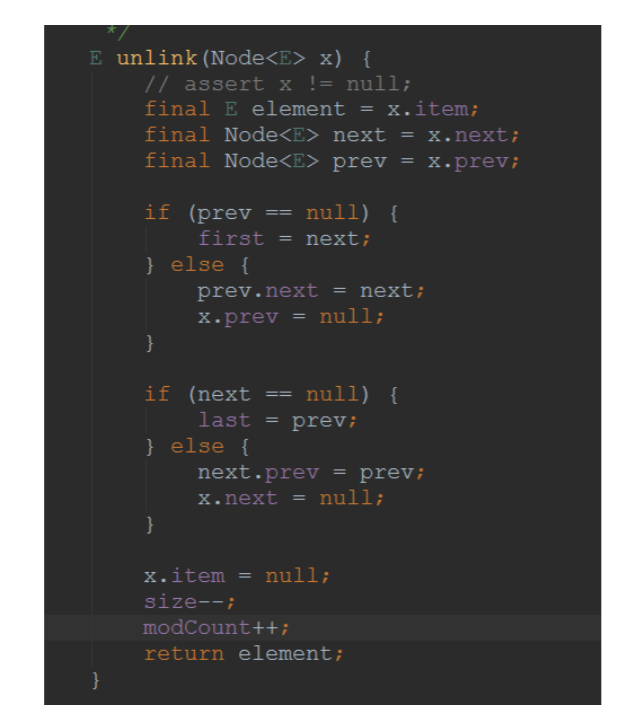
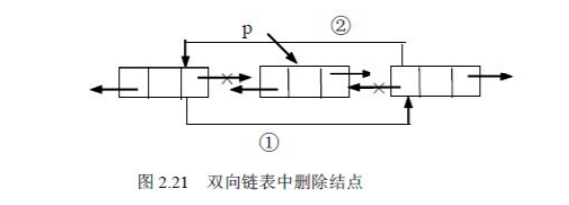
6.3、remove方法
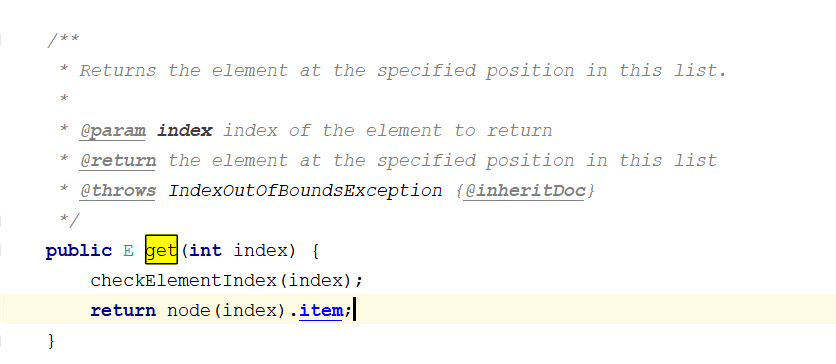
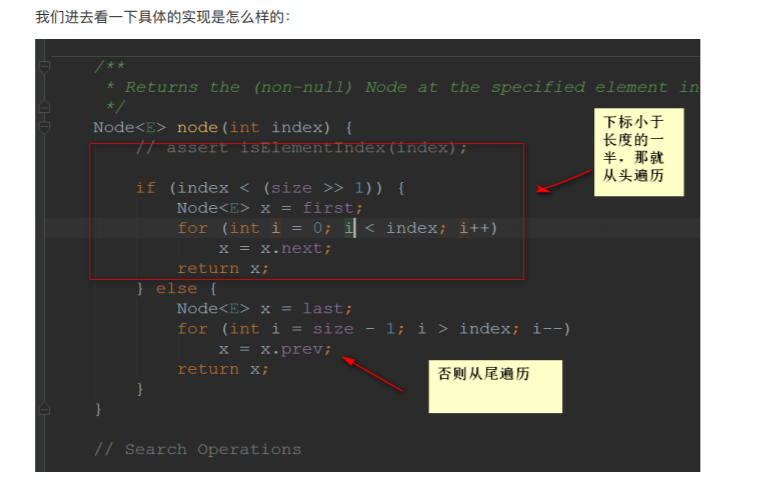
6.4、get方法
6.5、set方法
set⽅法和get⽅法其实差不多,根据下标来判断是从头遍历还是从尾遍历
public E set(int index, E element) {
checkElementIndex(index);
Node<E> x = node(index);
E oldVal = x.item;
x.item = element;
return oldVal;
}
6.6、List集合总结
-
ArrayList:
底层实现是数组 ArrayList的默认初始化容量是10,每次扩容时候增加原先容量的⼀半,也就是变为原来的1.5倍 在增删时候,需要数组的拷⻉复制(navite ⽅法由C/C++实现)
-
LinkedList:
底层实现是双向链表[双向链表⽅便实现往前遍历]
-
Vector:
底层是数组,现在已少⽤,被ArrayList替代
原因有两个: Vector所有⽅法都是同步,有性能损失。
Vector初始length是10 超过length时 以100%⽐率增⻓,相⽐于ArrayList更多消耗内存。
总的来说:查询多⽤ArrayList,增删多⽤LinkedList。
ArrayList增删慢不是绝对的(在数量⼤的情况下,已测试): 如果增加元素⼀直是使⽤ add() (增加到末尾)的话,那是ArrayList要快 ⼀直删除末尾的元素也是ArrayList要快【不⽤复制移动位置】 ⾄于如果删除的是中间的位置的话,还是ArrayList要快!
但⼀般来说:增删多还是⽤LinkedList,因为上⾯的情况是极端的
七、Set解析
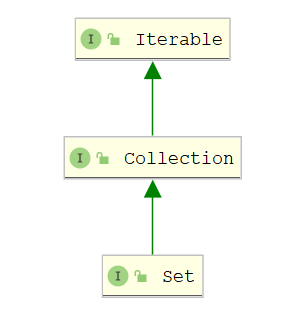
Set特性:
- Set<E> extends Collection<E>
- Set接口中的元素是无序不可重复的
- Set集合的底层就是Map
7.1 HashSet
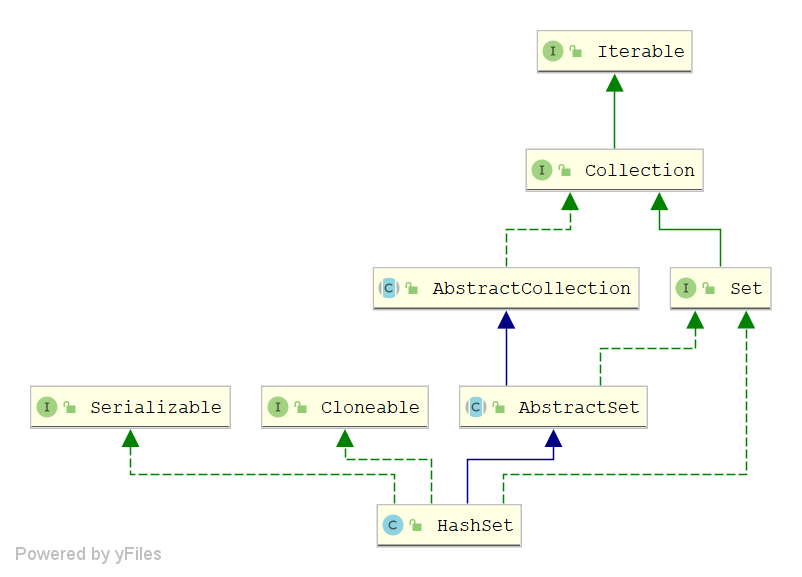
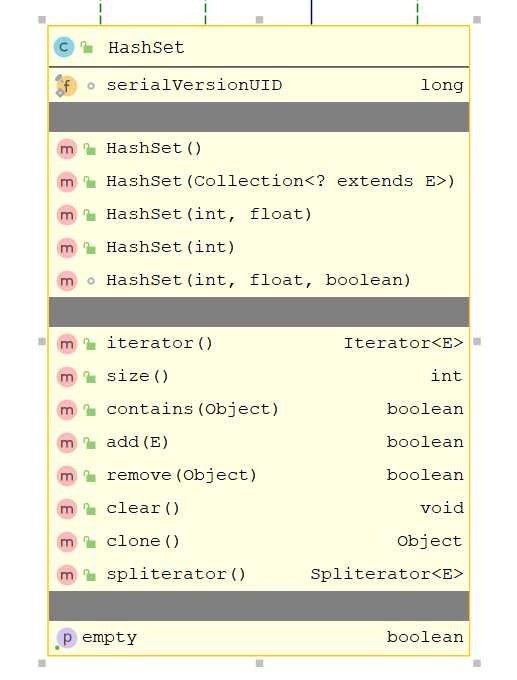
HashSet特性:
- HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, java.io.Serializable
- 实现Set接⼝
- 不保证迭代顺序
- 允许元素为null
- 底层实际上是⼀个HashMap实例
- ⾮同步
- 初始容量⾮常影响迭代性能,不要讲初始容量设置太高(或负载因数过低)
我们知道Map是⼀个映射,有key有value,既然HashSet底层⽤的是HashMap,那么value在哪⾥呢?
value是⼀个Object,所有的value都是它 所以可以直接总结出:HashSet实际上就是封装了HashMap,操作HashSet元素实际上就是操作 HashMap。这也是⾯向对象的⼀种体现,重⽤性贼⾼!
7.2 TreeSet
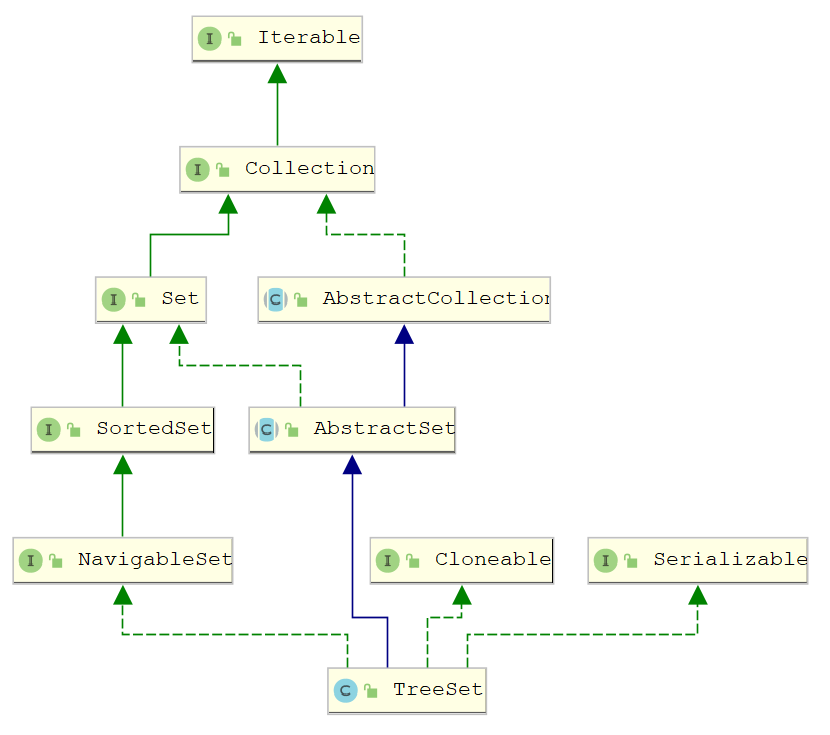
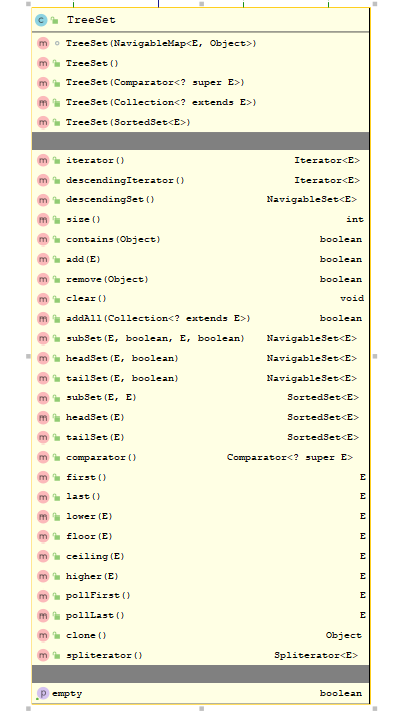
TreeSet特性:
- TreeSet<E> extends AbstractSet<E>implements NavigableSet<E>, Cloneable, java.io.Serializable
- 实现NavigableSet接⼝
- 可以实现排序功能
- 底层实际上是⼀个TreeMap实例
- ⾮同步
7.3 LinkedHashSet
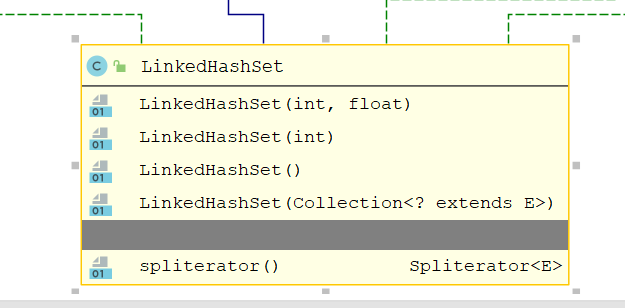
LinkedHashSet特性:
- LinkedHashSet<E> extends HashSet<E> implements Set<E>, Cloneable, java.io.Serializable
- 迭代是有序的 允许为null
- 底层实际上是⼀个HashMap+双向链表实例(其实就是LinkedHashMap)...
- ⾮同步 性能⽐HashSet差⼀丢丢,因为要维护⼀个双向链表
- 初始容量与迭代⽆关,LinkedHashSet迭代的是双向链表
7.4 Set集合总结
可以很明显地看到,Set集合的底层就是Map
HashSet:
- ⽆序,允许为null,底层是HashMap(散列表+红⿊树),⾮线程同步
TreeSet:
- 有序,不允许为null,底层是TreeMap(红⿊树),⾮线程同步
LinkedHashSet:
- 迭代有序,允许为null,底层是HashMap+双向链表,⾮线程同步
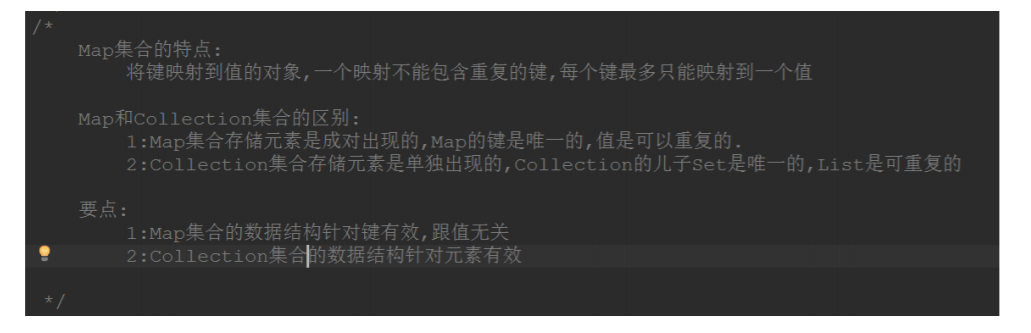
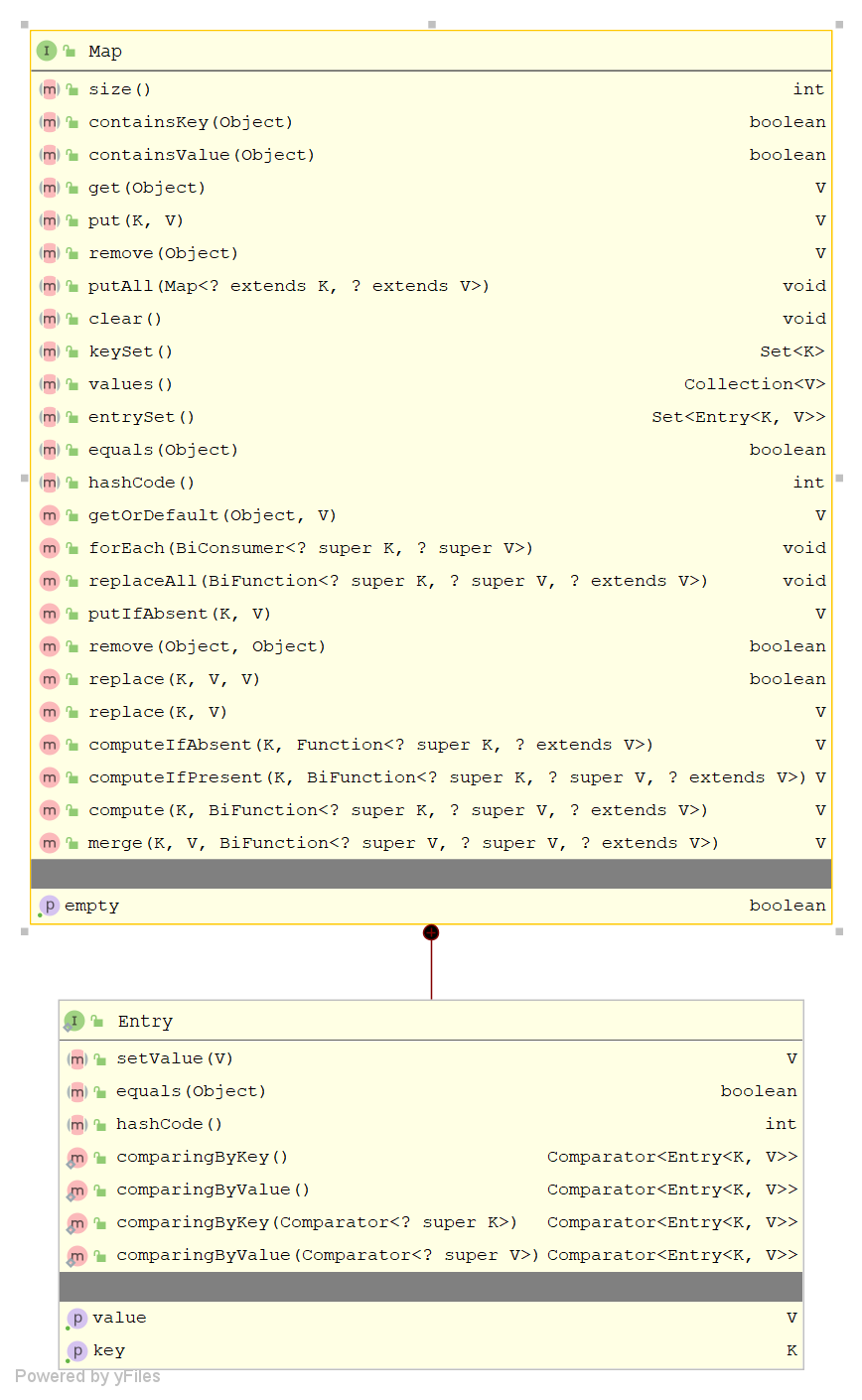
八、 Map集合解析
Map在《Core Java》中称之为-->映射
映射模型:
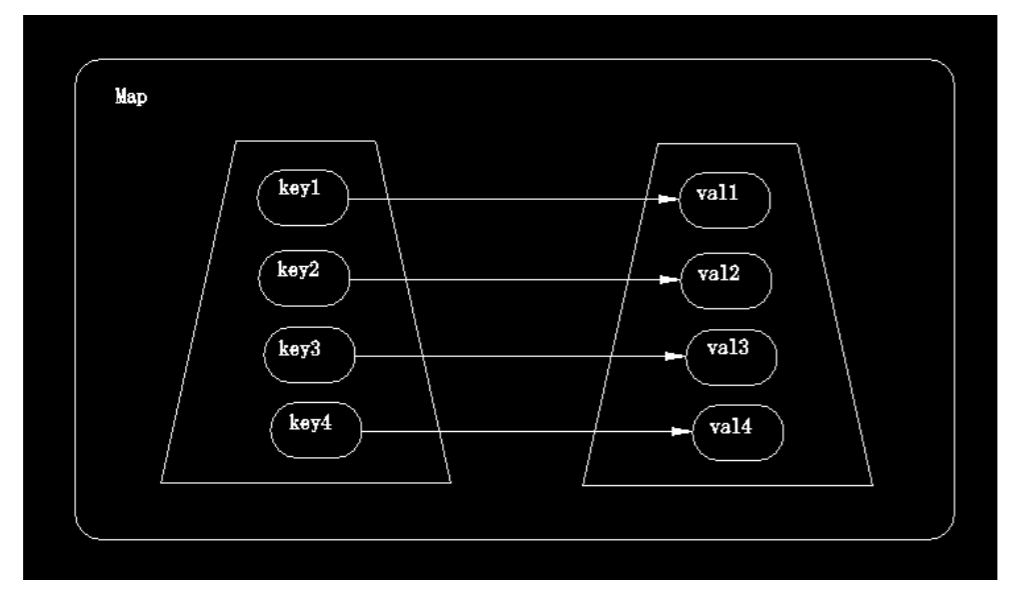
Map与Collection的区别:

8.1 HashMap 解析
我们知道Hash的底层是散列表,⽽在Java中散列表的实现是通过数组+链表的~ 再来简单看看put⽅法就可以印证我们的说法了:数组+链表-->散列表
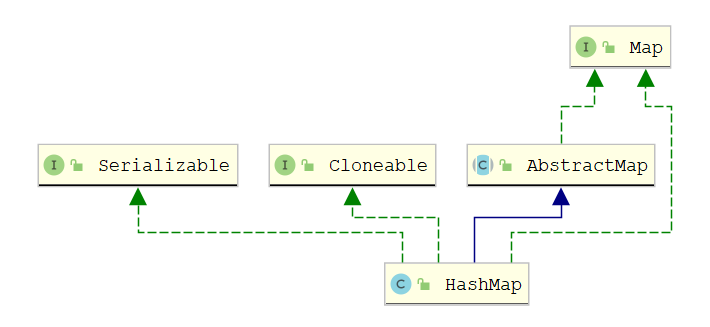
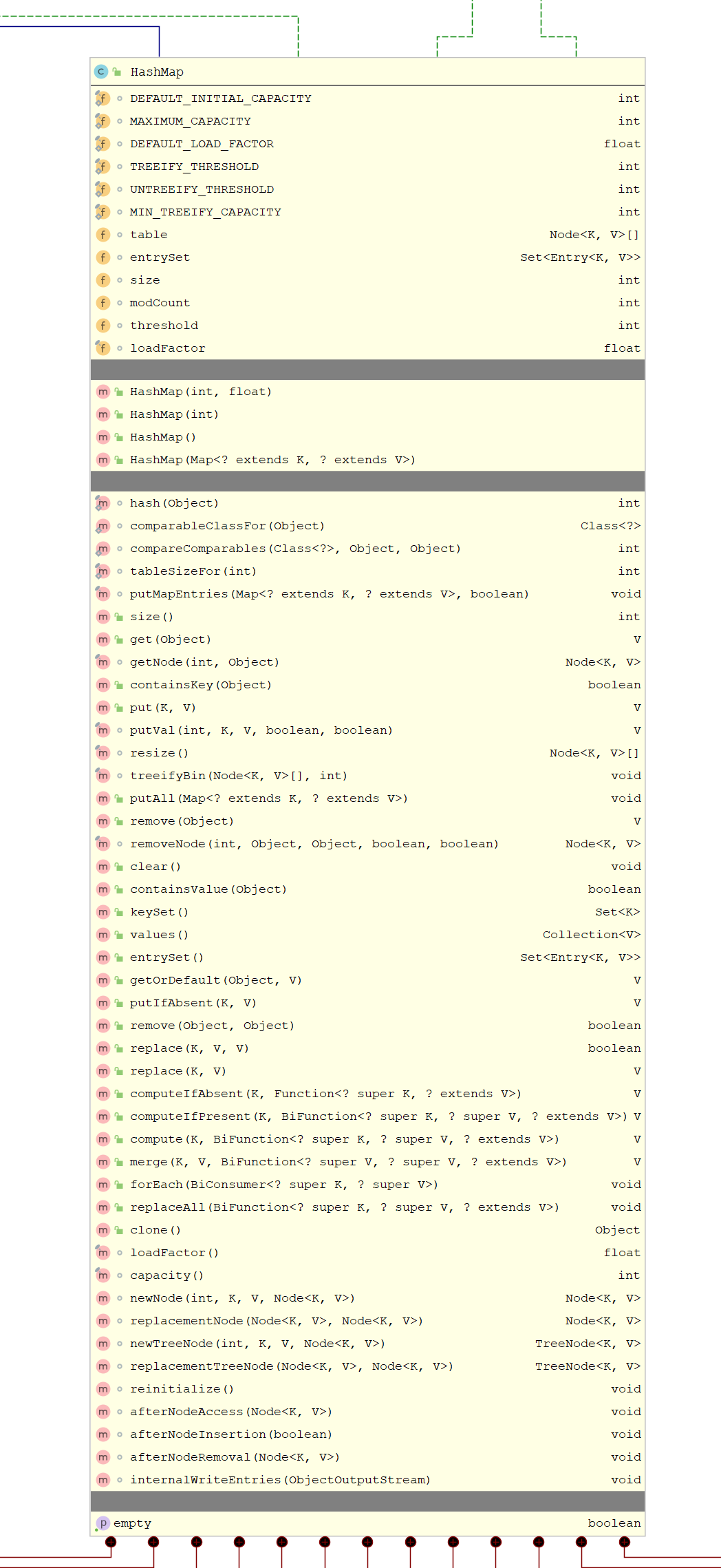
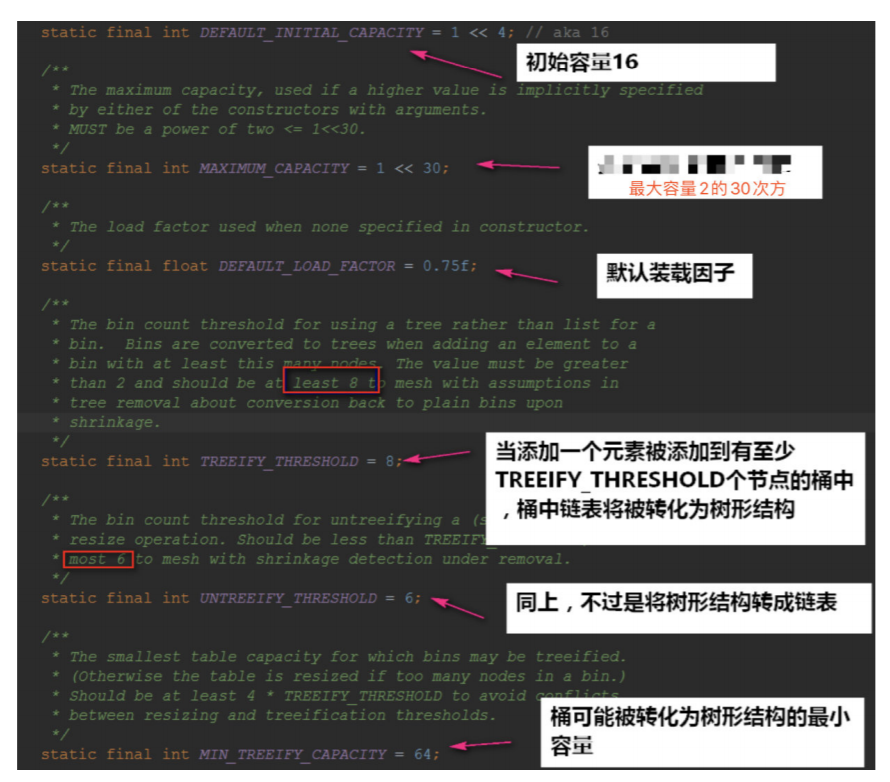
HashMap特性:
- ⽆序,允许为null,⾮同步
- 底层由散列表(哈希表)实现
- 初始容量和装载因⼦对HashMap影响挺⼤的,设置⼩了不好,设置⼤了也不好、
8.2 构造方法
HashMap的构造⽅法有4个:
在上⾯的构造⽅法最后⼀⾏,我们会发现调⽤了 tableSizeFor() ,我们进去看看: 看完上⾯可能会感到奇怪的是:为啥是将2的整数幂的数赋给threshold?
threshold这个成员变量是阈值,决定了是否要将散列表再散列。
它的值应该是: capacity * load factor 才对的。
其实这⾥仅仅是⼀个初始化,当创建哈希表的时候,它会重新赋值的:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号