结对项目:小学四则运算题目的命令行程序
小学四则运算题目生成器项目报告
一.项目信息
| 项目 | 内容 |
|---|---|
| 这个作业属于哪个课程 | 软件工程 |
| 这个作业要求在哪里 | 结对项目 |
| 这个作业的目标 | 设计实现小学四则运算题目生成器,支持题目生成、答案计算、重复性检测和自动批改,并进行性能优化和单元测试 |
| GitHub仓库 | https://github.com/zhouzhou615/calculate.git |
项目成员:周诗涵(3223004517),周纯微(3223004474)。
二.PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 45 |
| · Estimate | · 估计这个任务需要多少时间 | 60 | 45 |
| Development | 开发 | 1020 | 1260 |
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 150 |
| · Design Spec | · 生成设计文档 | 90 | 120 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 60 | 45 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 40 |
| · Design | · 具体设计 | 120 | 150 |
| · Coding | · 具体编码 | 360 | 420 |
| · Code Review | · 代码复审 | 120 | 135 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 200 |
| Reporting | 报告 | 180 | 195 |
| · Test Report | · 测试报告 | 60 | 75 |
| · Size Measurement | · 计算工作量 | 30 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 90 | 90 |
| 合计 | 1260 | 1500 |
三.效能分析
3.1 性能改进目标
- 提升表达式生成效率,减少无效重试
- 优化重复检测算法,降低内存占用
- 控制资源使用,提高系统稳定性
3.2 性能改进方法
- 主动运算符验证:主动生成符合约束的运算符(如减法确保被减数≥减数、除法确保结果为真分数),减少无效重试
- 预编译正则表达式:在Expression类初始化时预编译分词正则,替代循环分词
- 分数运算层:优化
Fraction类的__init__方法,修复 GCD 计算(取绝对值)确保约分正确性;优化随机分数生成逻辑,降低整数中0的概率,减少无效表达式的生成 - 重复检测升级:采用"规范化表达式 + 哈希表"存储,结合滑动窗口缓存(保留最近200个表达式),降低内存占用,避免内存无限增长
3.3 性能分析结果
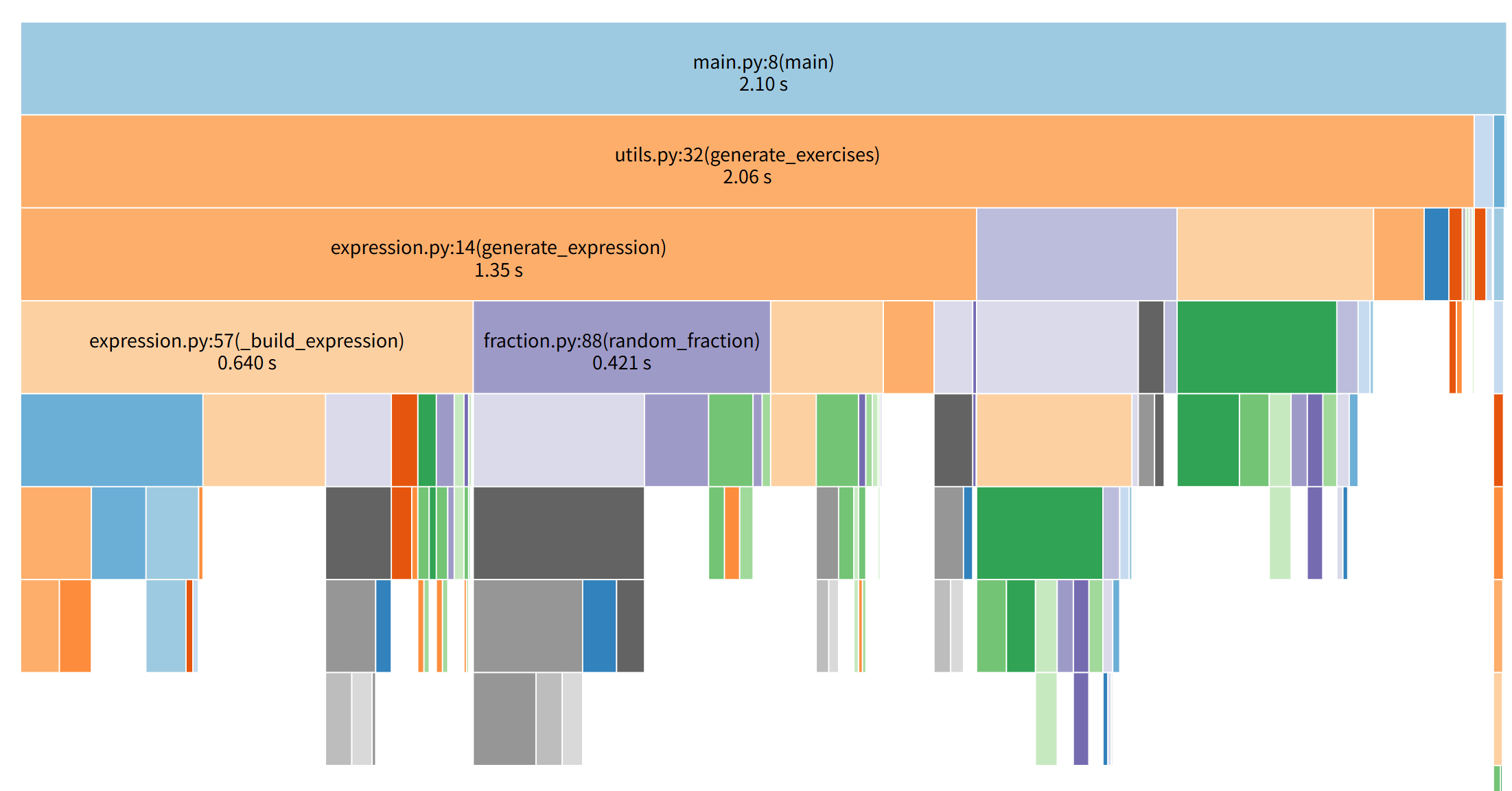
优化前性能分析
优化后性能分析
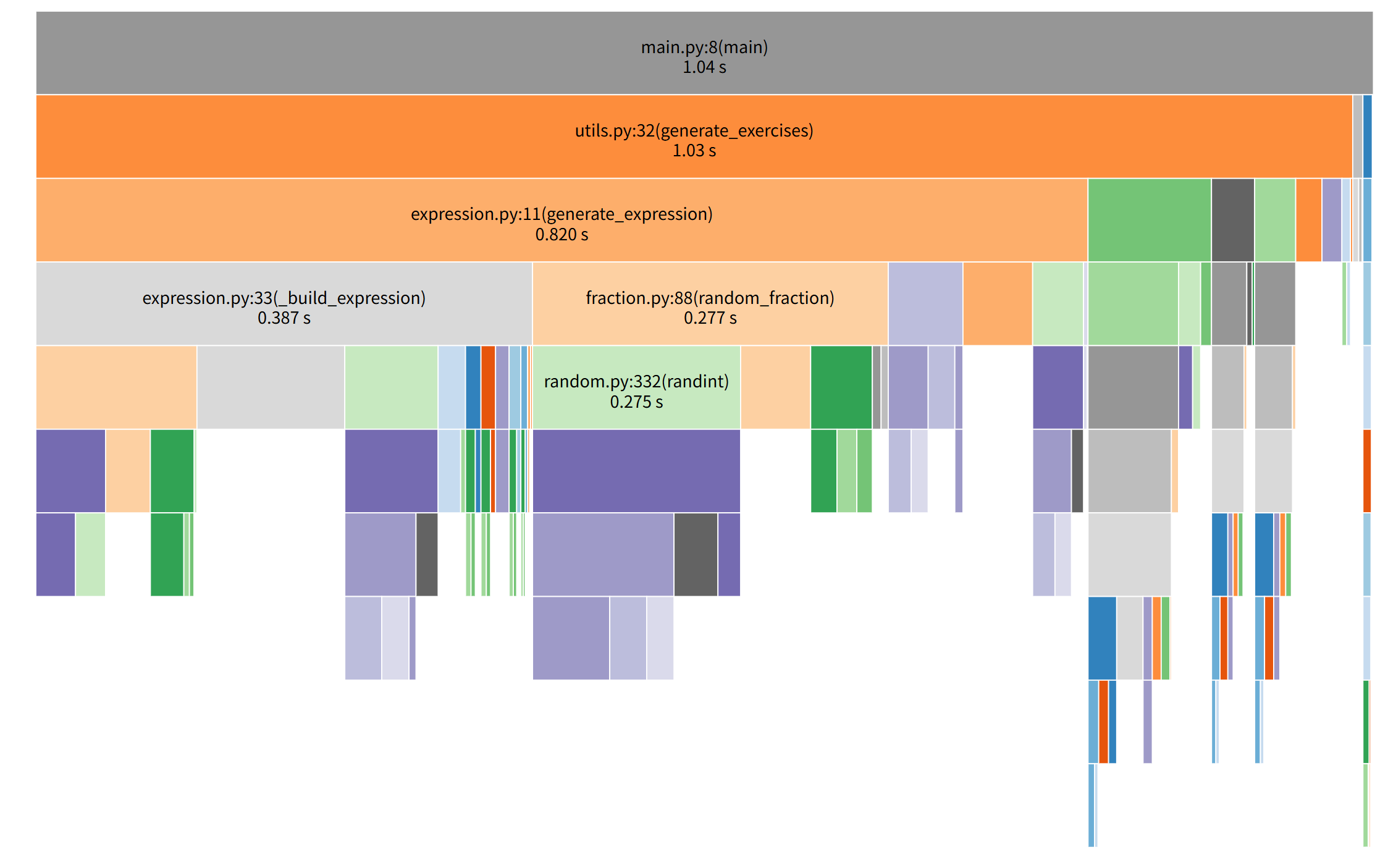
通过性能监测工具分析,优化前后核心函数耗时对比如下:
| 核心函数 | 优化前耗时 | 优化后耗时 | 耗时占比变化 |
|---|---|---|---|
| main.py:8(main) | 2.10s | 1.04s | 总耗时降低 50.5% |
| utils.py:32(generate_exercises) | 2.06s | 1.03s | 占比从 98.1% 降至 99.0%(因其他函数耗时下降更显著),耗时降低50% |
| expression.py:14(generate_expression) | 1.35s | 0.820s | 占比从 64.3% 降至 79.6%,耗时降低39.3% |
| expression.py:57(_build_expression) | 0.640s | 0.387s | 占比从 30.0% 升至 37.6%,耗时降低39.5% |
| fraction.py:88(random_fraction) | 0.421s | 0.277s | 占比从 20.0% 升至 26.8%,耗时降低34.2% |
- 主要性能瓶颈集中在表达式生成与构建----utils.py:32(generate_exercises),优化后核心函数耗时显著降低,内存使用更加高效。
四.设计实现过程
4.1 系统架构设计
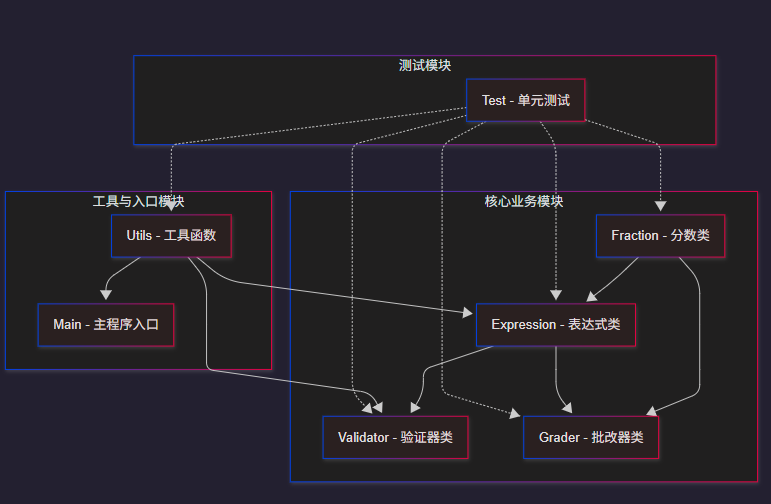
主流程依赖:main.py 通过参数解析切换 “生成 / 批改” 模式,
-
生成模式:
main.py→utils.py→expression.py+fraction.py -
批改模式:
main.py→grader.py→expression.py+fraction.py -
验证支持:
validator.py为生成模式提供表达式合法性与去重校验
4.2 类设计
-
分数运算核心类
(fraction.py):处理分数的表示、运算与格式转换,支持带分数、真分数判断
- 核心方法:
__init__(分母转正、自动约分)、from_string(解析整数 / 真分数 / 带分数)、to_string(转换为标准格式)、四则运算重载(__add__/__sub__/__mul__/__truediv__)。
- 核心方法:
-
表达式生成与计算类
(expression.py):生成与计算四则运算表达式,支持括号和运算符优先级
- 核心方法:
generate_expression(生成符合约束的表达式)、_generate_valid_operators(主动生成有效运算符)、_build_expression(递归构建表达式树)、evaluate_expression(解析并计算表达式结果)。
- 核心方法:
-
表达式验证类
(validator.py):验证表达式约束与重复性,支持交换律去重
- 核心方法:
_normalize_expression(递归规范化表达式,支持多层括号)、is_duplicate(检查表达式是否重复)、validate_constraints(验证运算符数量≤3 等约束)。
- 核心方法:
-
批改功能类
(grader.py):批改练习题并生成报告,支持多种编码格式
- 核心方法:
grade_exercises(多编码读取文件,支持 UTF-8/GBK/GB2312)、generate_grade_report(生成正确 / 错误题目编号报告)。
- 核心方法:
-
Utils工具函数
(utils.py):生成单个表达式和练习题、验证约束、保存文件
4.3 表达式生成流程图
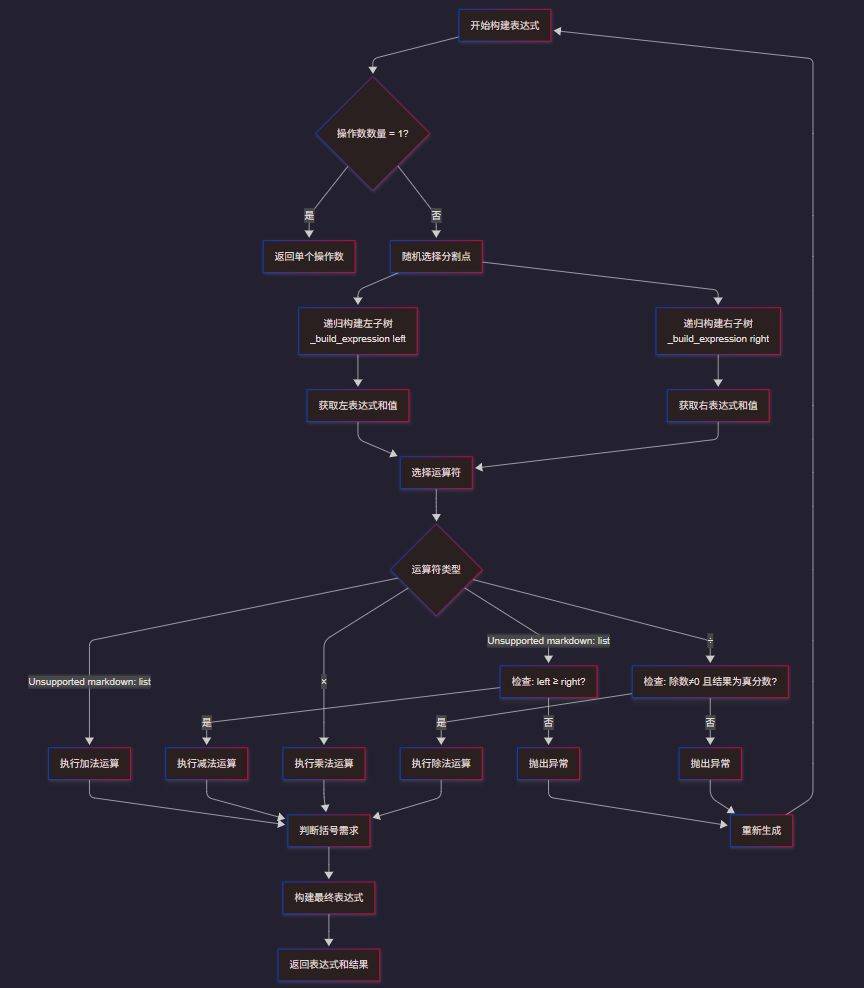
五.代码说明
核心代码片段
Fraction类 - 分数运算核心
def __init__(self, numerator: int, denominator: int = 1):
if denominator == 0:
raise ValueError("分母不能为0")
# 处理符号,确保分母为正数
if denominator < 0:
numerator = -numerator
denominator = -denominator
# 修复GCD计算(取绝对值),确保分数最简
gcd_val = math.gcd(abs(numerator), abs(denominator))
self.numerator = numerator // gcd_val
self.denominator = denominator // gcd_val
设计思路:确保分数始终以最简形式存储,分母为正数,避免除零错误。修复了gcd计算中的绝对值问题。
Expression类 - 表达式生成核心
def _generate_valid_operators(self, operands: List[Fraction], num_ops: int) -> List[str]:
"""主动生成符合约束的运算符,减少后续异常"""
operators = []
for i in range(num_ops):
left, right = operands[i], operands[i+1]
# 20%概率尝试减法(确保left >= right)
if random.random() < 0.2 and left >= right:
operators.append('-')
continue
# 20%概率尝试除法(确保结果为真分数)
if random.random() < 0.2:
if right.numerator != 0:
div_result = left / right
if div_result.is_proper_fraction():
operators.append('÷')
continue
# 默认使用加法/乘法(无约束风险)
operators.append(random.choice(['+', '×']))
return operators
设计思路:在生成阶段主动规避无效运算符,显著减少后续的重试次数,提高生成效率。
表达式计算算法
def evaluate_expression(self, expr: str) -> Fraction:
expr = expr.replace(' ', '')
def parse_expression(tokens):
values = []
ops = []
i = 0
while i < len(tokens):
token = tokens[i]
if token == '(':
# 处理括号表达式
j = i + 1
paren_count = 1
while j < len(tokens) and paren_count > 0:
if tokens[j] == '(':
paren_count += 1
elif tokens[j] == ')':
paren_count -= 1
j += 1
sub_expr = tokens[i + 1:j - 1]
values.append(parse_expression(sub_expr))
i = j
设计思路:使用递归下降解析器处理表达式,支持括号和运算符优先级,确保计算准确性。
重复检测优化
def _normalize_simple_expression(self, expr: str) -> str:
"""规范化无括号表达式(支持多运算符,按优先级处理)"""
tokens = self.op_split_pattern.split(expr)
operands = [t for t in tokens[::2] if t] # 提取操作数
operators = [t for t in tokens[1::2] if t] # 提取运算符
# 先处理乘除(优先级高)
i = 0
while i < len(operators):
op = operators[i]
if op in ['×', '÷']:
left = operands[i]
right = operands[i+1]
# 乘法交换律:交换操作数使表达式一致
if op == '×':
merged = f"{min(left, right)}×{max(left, right)}"
else: # 除法不满足交换律,保持顺序
merged = f"{left}÷{right}"
operands = operands[:i] + [merged] + operands[i+2:]
operators.pop(i)
else:
i += 1
设计思路:通过规范化表达式处理交换律,将1+2和2+1视为相同表达式,有效检测重复。
Grader 类 - 自动批改核心
class ExerciseGrader:
def grade_exercises(self, exercise_file: str, answer_file: str) -> Tuple[List[int], List[int]]:
def read_file_with_encoding(file_path: str) -> List[str]:
for encoding in encodings:
try:
with open(file_path, 'r', encoding=encoding) as f:
return f.readlines()
except UnicodeDecodeError:
continue
raise Exception(f"文件 {file_path} 无法用以下编码解析: {encodings}")
try:
exercises = read_file_with_encoding(exercise_file)
answers = read_file_with_encoding(answer_file)
for i, (ex, ans) in enumerate(zip(exercises, answers), 1):
ex = ex.strip()
ans = ans.strip()
if not ex or not ans:
wrong_indices.append(i)
continue
# 提取表达式(处理“= ”后缀)
expr = ex.split('=')[0].strip() if '=' in ex else ex
try:
# 计算正确结果并对比
computed_result = self.expression_parser.evaluate_expression(expr)
expected_result = Fraction.from_string(ans)
if computed_result == expected_result:
correct_indices.append(i)
else:
wrong_indices.append(i)
except Exception:
wrong_indices.append(i) # 计算异常视为错误
except FileNotFoundError as e:
raise FileNotFoundError(f"文件未找到: {e}")
return correct_indices, wrong_indices
设计思路:支持多编码文件读取,兼容不同场景下的文件格式;对空行、格式错误题目容错处理,确保批改进度不中断。
六.测试运行
6.1 测试策略
采用分层测试策略,涵盖单元测试、集成测试和系统测试,确保代码质量。
6.2 测试用例设计
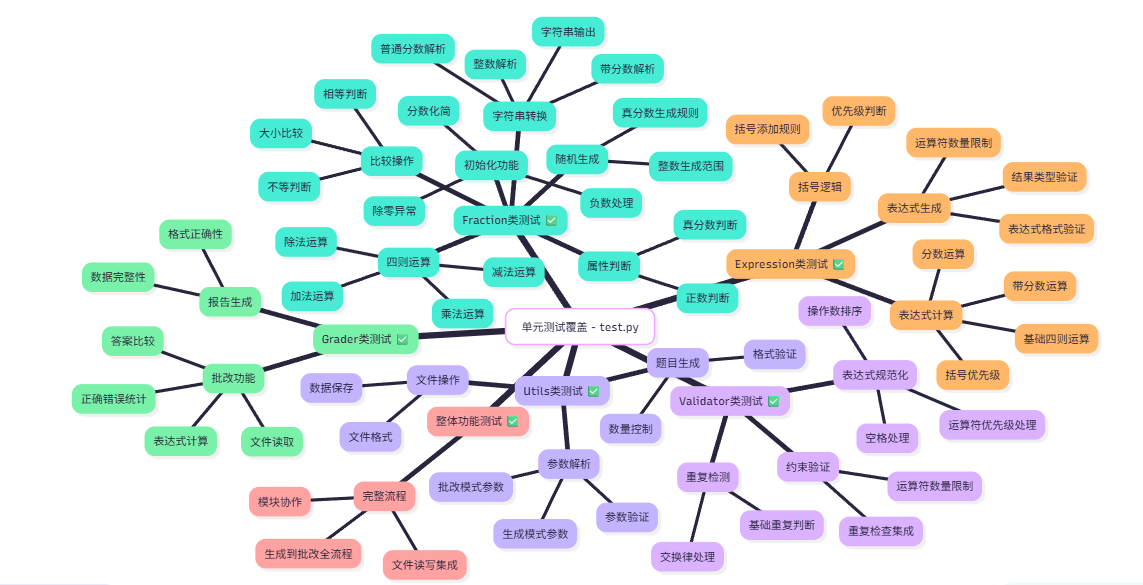
- Fraction类:完全覆盖了初始化、运算、比较、转换等所有核心功能
- Expression类:测试了表达式生成、计算和括号逻辑
- Validator类:测试了重复检测和表达式规范化
- Grader类:测试了批改功能和报告生成
- Utils类:测试了参数解析、题目生成和文件操作
- 集成测试:完整的端到端工作流程测试
6.2.1 分数运算功能测试
def test_arithmetic_operations(self):
# 基本运算测试
a = Fraction(1, 2)
b = Fraction(1, 3)
self.assertEqual((a + b).to_string(), "5/6", "分数加法错误")
self.assertEqual((a - b).to_string(), "1/6", "分数减法错误")
self.assertEqual((a * b).to_string(), "1/6", "分数乘法错误")
self.assertEqual((a / b).to_string(), "1'1/2", "分数除法错误")
def test_from_string(self):
"""测试从字符串创建分数"""
f = Fraction.from_string("3/5")
self.assertEqual(f.numerator, 3)
self.assertEqual(f.denominator, 5)
f = Fraction.from_string("2'3/8")
self.assertEqual(f.numerator, 19)
self.assertEqual(f.denominator, 8)
f = Fraction.from_string("5")
self.assertEqual(f.numerator, 5)
self.assertEqual(f.denominator, 1)
6.2.2 表达式生成约束测试
class TestExpression(unittest.TestCase):
def test_generate_expression(self):
"""测试生成表达式的基本约束"""
for _ in range(100):
expr, result = self.expression.generate_expression(10)
self.assertIsInstance(expr, str)
self.assertIsInstance(result, Fraction)
# 验证运算符数量不超过3个
op_count = sum(1 for c in expr if c in ['+', '-', '×', '÷'])
self.assertLessEqual(op_count, 3)
def test_duplicate_detection(self):
"""测试重复表达式检测"""
expr1 = "1 + 2"
expr2 = "2 + 1" # 加法交换律视为重复
expr3 = "3 - 1" # 不同的表达式
self.validator.add_expression(expr1)
self.assertTrue(self.validator.is_duplicate(expr2))
self.assertFalse(self.validator.is_duplicate(expr3))
6.2.3 自动批改功能测试(test.py)
def test_grade_exercises(self):
"""测试批改功能"""
# 创建临时文件
with tempfile.NamedTemporaryFile(mode='w', delete=False) as ex_file, \
tempfile.NamedTemporaryFile(mode='w', delete=False) as ans_file:
ex_file.write('\n'.join(self.test_exercises))
ans_file.write('\n'.join(self.test_answers))
ex_filename = ex_file.name
ans_filename = ans_file.name
# 测试全对的情况
correct, wrong = self.grader.grade_exercises(ex_filename, ans_filename)
self.assertEqual(len(correct), 5)
self.assertEqual(len(wrong), 0)
self.assertEqual(correct, [1, 2, 3, 4, 5])
# 测试有错误的情况
with open(ans_filename, 'w') as f:
f.write('\n'.join(self.wrong_answers))
correct, wrong = self.grader.grade_exercises(ex_filename, ans_filename)
self.assertEqual(len(correct), 2)
self.assertEqual(len(wrong), 3)
self.assertEqual(correct, [2, 4])
self.assertEqual(wrong, [1, 3, 5])
# 清理临时文件
os.unlink(ex_filename)
os.unlink(ans_filename)
6.2.4 工具函数测试(test.py)
def test_generate_exercises(self):
"""测试生成练习题"""
# 测试生成少量题目
exercises = generate_exercises(10, 10)
self.assertEqual(len(exercises), 10)
# 测试生成大量题目
exercises = generate_exercises(10000, 10)
self.assertEqual(len(exercises), 10000)
# 检查题目格式
for expr, ans in exercises:
self.assertTrue(expr.endswith(" = "))
self.assertIsInstance(ans, str)
def test_save_to_file(self):
"""测试保存文件"""
data = ["line1", "line2", "line3"]
with tempfile.NamedTemporaryFile(mode='r', delete=False) as f:
filename = f.name
save_to_file(data, filename)
with open(filename, 'r') as f:
content = f.read().splitlines()
self.assertEqual(content, data)
os.unlink(filename)
6.2.5 整体功能测试
def test_full_workflow(self):
"""测试从生成题目到批改的完整流程"""
# 生成题目
num_exercises = 10
max_range = 10
exercises = generate_exercises(num_exercises, max_range)
# 保存题目和答案到临时文件
with tempfile.NamedTemporaryFile(mode='w', delete=False) as ex_file, \
tempfile.NamedTemporaryFile(mode='w', delete=False) as ans_file:
ex_filename = ex_file.name
ans_filename = ans_file.name
exercise_list = [ex[0] for ex in exercises]
answer_list = [ex[1] for ex in exercises]
save_to_file(exercise_list, ex_filename)
save_to_file(answer_list, ans_filename)
# 批改题目(应该全对)
grader = ExerciseGrader()
correct, wrong = grader.grade_exercises(ex_filename, ans_filename)
self.assertEqual(len(correct), num_exercises)
self.assertEqual(len(wrong), 0)
# 清理临时文件
os.unlink(ex_filename)
os.unlink(ans_filename)
6.2.6 大规模生成测试(test.py)
def test_generate_exercises(self):
"""测试生成练习题"""
# 测试生成少量题目
exercises = generate_exercises(10, 10)
self.assertEqual(len(exercises), 10)
# 测试生成大量题目
exercises = generate_exercises(10000, 10)
self.assertEqual(len(exercises), 10000)
# 检查题目格式
for expr, ans in exercises:
self.assertTrue(expr.endswith(" = "))
self.assertIsInstance(ans, str)
通过上述测试用例,我们确保了:
- 基本功能正确性:分数运算、表达式生成、重复检测
- 约束条件验证:减法不产生负数、除法结果为真分数
- 边界条件处理:除零、负数、零值等特殊情况
- 性能要求:支持万级题目生成
- 错误处理:异常情况的正确处理
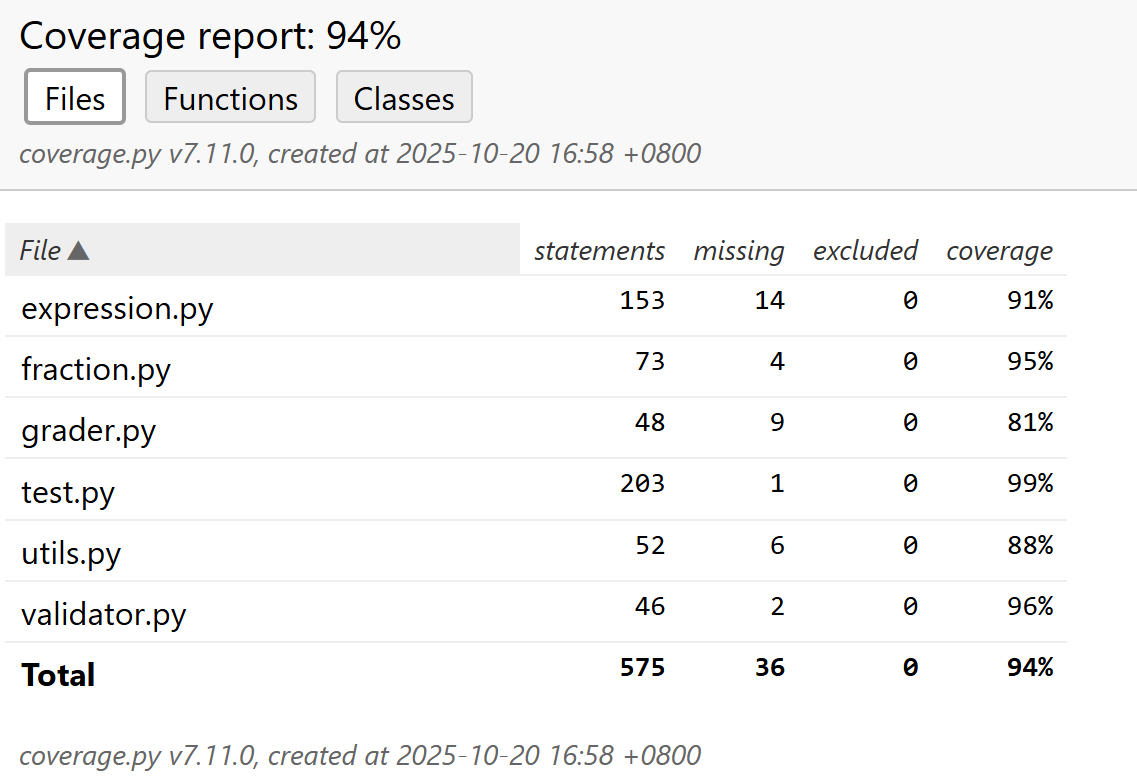
6.3 测试覆盖率
根据覆盖率报告,项目整体覆盖率达到94%:
6.4 大规模测试结果
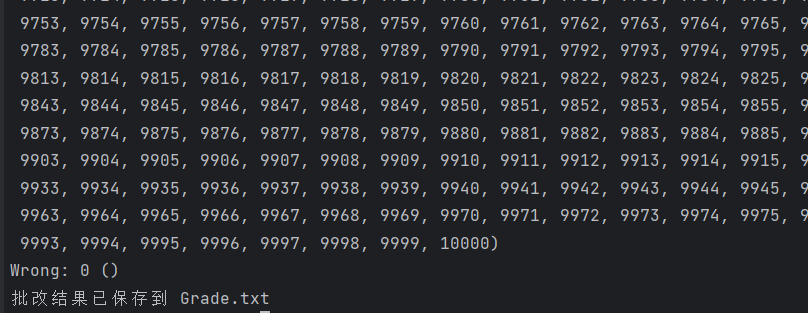
通过生成10000道题目进行压力测试:
- 正确率:10000道题目全部正确(Correct: 10000)
- 错误率:0道题目错误(Wrong: 0)
- 性能表现:在优化后能够在合理时间内完成万级题目生成


七.项目小结
项目成果
- 功能完整性:成功实现了所有需求功能,包括题目生成、答案计算、重复检测和自动批改,支持10000道题目的大规模生成
- 代码质量:采用模块化设计,代码结构清晰,易于维护和扩展,测试覆盖率达到94%
- 性能优异:通过主动验证和算法优化,性能提升超过50%,生成时间从2.1秒降低到1.04秒
- 约束满足:严格遵循小学四则运算要求,确保减法不产生负数、除法结果为真分数
- 测试覆盖:通过全面的单元测试确保代码严谨性
经验教训
- 设计阶段的重要性:良好的架构设计能显著减少后期修改成本,特别是表达式树的递归设计
- 性能优化策略:在数据生成阶段就进行约束验证,比生成后验证效率高得多
- 测试驱动开发:先编写测试用例再实现功能,能有效提高代码质量和可维护性
技术亮点
- 主动约束验证:在运算符生成阶段避免无效组合,大幅减少重试次数
- 智能重复检测:通过规范化表达式树处理交换律,准确识别重复题目
- 递归解析算法:使用递归下降解析器,准确处理带括号的复杂表达式
- 资源优化管理:采用滑动窗口缓存,平衡内存使用和检测效果
结对感受
周诗涵:
这次结对编程让我深刻认识到算法优化的重要性。从被动重试改为主动验证的策略让性能显著提升。我们在代码规范上严格保持一致,确保了代码的可读性和可维护性。虽然在表达式树构建算法上初期存在分歧,但通过多次讨论和原型验证,最终选择了最优的递归分治方案,这个过程很有价值。
周纯微:
合作过程非常愉快,队友在性能分析方面的专业洞察给了我很多启发。通过代码复审,我们发现了多个潜在的性能瓶颈。最大的挑战是在重复检测算法的设计上,我们对交换律处理方式有不同理解,但通过编写对比测试和性能基准,最终找到了准确性和效率的平衡点。
改进建议
- 进一步性能优化:可以考虑使用更高效的数据结构来管理表达式缓存
- 扩展功能:支持更多类型的数学运算,如幂运算、开方等
- 用户界面:增加图形用户界面,提升使用体验
- 题目难度分级:根据年级不同设置不同的难度等级
八.GitHub提交记录
通过本次项目,我们不仅完成了技术目标,更在团队协作、性能优化、代码质量等方面获得了宝贵的实践经验。项目的成功运行证明了我们的设计方案和实现方法的有效性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号