

多线程实际开发深入了解-CAS算法
1.参考:https://blog.csdn.net/Jbinbin/article/details/86212688,
https://www.cnblogs.com/jingmoxukong/p/12109049.html,
https://mp.weixin.qq.com/s?__biz=MzI3ODcxMzQzMw==&mid=2247483728&idx=1&sn=3d734dc972a244891406cfbc443eabed&chksm=eb538466dc240d7033b889665b579a490266b8c8f1e7a08da35f67ca484dad19503e8b230e05&scene=21#wechat_redirect
https://blog.csdn.net/qq_32998153/article/details/79529704
2.理解:线程问题,更多的是对于在于并发,处理并发考虑的锁的概念,其实所谓的锁就是保证对象执行的顺序和线程的同步,这样就有了悲观锁和乐观锁的,
JDK1.5之前的时候只有悲观锁,也就是我们常说的synchronized(用于方法块和对象实例,定义是外部锁和内部锁),而java之后的发展又衍生了乐观锁的概念,
今天想学习的就是乐观锁的知识点,并发包:java.util.concurrent.*
3.CAS算法理解(乐观锁的基础之一):
介绍:
1.CAS(Compare and Swap),即比较再交换。(字面含义也能看出算法的用意)
2.原理:对CAS的理解,CAS是一种无锁算法,CAS有3个操作数,内存值V,旧的预期值A,要修改的新值B。当且仅当预期值A和内存值V相同时,将内存值V修改为B,否则什么都不做。
代码块伪写法:
do{
备份旧数据;
基于旧数据构造新数据;
}while(!CAS( 内存地址,备份的旧数据,新数据 ))
3.为了更好的理解我觉得作者的举例很好,如下:
(1)t1,t2线程是同时更新同一变量56的值 (也可以理解为对同一个资源对象操作,又变量举例可能理解起来更加方便)
(2)因为t1和t2线程都同时去访问同一变量56,所以他们会把主内存的值完全拷贝一份到自己的工作内存空间,所以t1和t2线程的预期值都为56。
(我觉得可以看到一个重点底层运行的时候会对对象资源做一次地址备份,以方便比较和替换,而这里说的就是旧的预期值(所以说旧的预期值就是开辟的线程对象对数据的备份了))
(3)假设t1在与t2线程竞争中线程t1能去更新变量的值,而其他线程都失败。(失败的线程并不会被挂起,而是被告知这次竞争中失败,并可以再次发起尝试--这是队列等待)。
t1线程去更新变量值改为57,然后写到内存中。此时对于t2来说,内存值变为了57,与预期值56不一致,就操作失败了,想改的值不再是原来的值
注:这里我觉得问题很多:重点首先的明确下这里必须是共享的对象资源或者是访问的是同一个对象实例,或者是保证事务的同一性,说白了就是Java的存在地址一样,
访问的还得是静态资源,资源共享所有CAS算法就是扯淡,t2拿不到改变的值还是照样做了跟新操作,所以下面总结的留神)。
(4)总结:就是指当两者进行比较时,如果相等,则证明共享数据没有被修改,替换成新值,然后继续往下运行;如果不相等,说明共享数据已经被修改,放弃已经所做的操作,然后重新执行刚才的操作。
容易看出 CAS 操作是基于共享数据不会被修改的假设,采用了类似于数据库的commit-retry 的模式。优势:当同步冲突出现的机会很少时,这种假设能带来较大的性能提升。
4.CAS的开销问题:
1.CAS(比较并交换)是CPU指令级的操作,只有一步原子操作,所以非常快。而且CAS避免了请求操作系统来裁定锁的问题,不用麻烦操作系统,直接在CPU内部就搞定了。但CAS就没有开销了吗?不!有cache miss的情况。
2.说白了CAS就是基于CPU操作了,那么消耗内存就是对于CPU机制问题,描述如下:
图解:
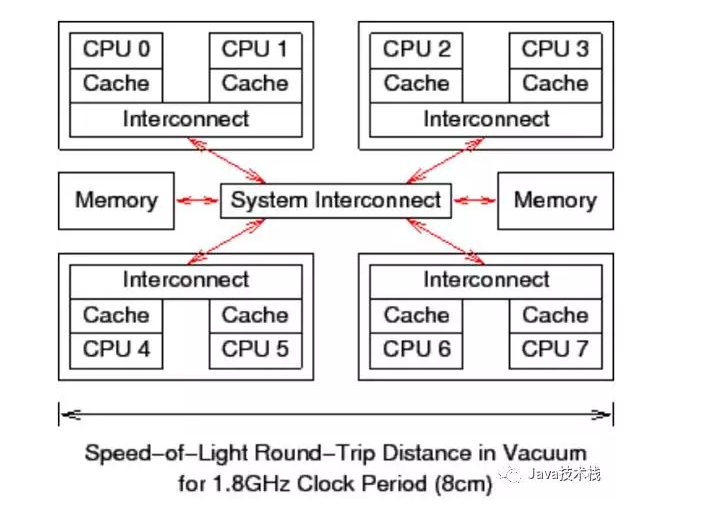
(1)每个CPU有cache(CPU内部的高速缓存,寄存器),管芯内还带有一个互联模块,使管芯内的两个核可以互相通信。
(2)中央的系统互联模块可以让四个管芯相互通信,并且将管芯与主存连接起来。数据以“缓存线”为单位在系统中传输,“缓存线”对应于内存中一个 2 的幂大小的字节块,大小通常为 32 到 256 字节之间。
(3)当 CPU 从内存中读取一个变量到它的寄存器中时,必须首先将包含了该变量的缓存线读取到 CPU 高速缓存。同样地,CPU 将寄存器中的一个值存储到内存时,
不仅必须将包含了该值的缓存线读到 CPU 高速缓存,还必须确保没有其他 CPU 拥有该缓存线的拷贝。
(4)例子:
如果 CPU0 在对一个变量执行“比较并交换”(CAS)操作,而该变量所在的缓存线在 CPU7 的高速缓存中,就会发生以下经过简化的事件序列:
1.CPU0 检查本地高速缓存,没有找到缓存线。
2.请求被转发到 CPU0 和 CPU1 的互联模块,检查 CPU1 的本地高速缓存,没有找到缓存线。
3.请求被转发到系统互联模块,检查其他三个管芯,得知缓存线被 CPU6和 CPU7 所在的管芯持有。
4.请求被转发到 CPU6 和 CPU7 的互联模块,检查这两个 CPU 的高速缓存,在 CPU7 的高速缓存中找到缓存线。
5.CPU7 将缓存线发送给所属的互联模块,并且刷新自己高速缓存中的缓存线。
6.CPU6 和 CPU7 的互联模块将缓存线发送给系统互联模块。
7.系统互联模块将缓存线发送给 CPU0 和 CPU1 的互联模块。
8.CPU0 和 CPU1 的互联模块将缓存线发送给 CPU0 的高速缓存。
9.CPU0 现在可以对高速缓存中的变量执行 CAS 操作了
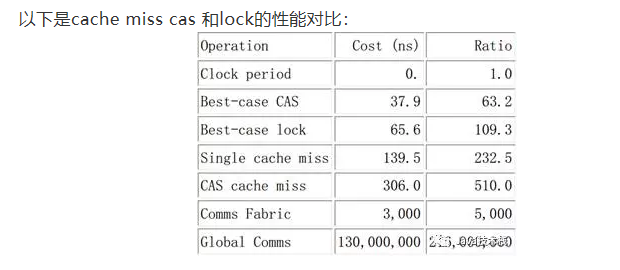
总结:以上是刷新不同CPU缓存的开销。最好情况下的 CAS 操作消耗大概 40 纳秒,超过 60 个时钟周期。
这里的“最好情况”是指对某一个变量执行 CAS 操作的 CPU 正好是最后一个操作该变量的CPU,所以对应的缓存线已经在 CPU 的高速缓存中了,
类似地,最好情况下的锁操作(一个“round trip 对”包括获取锁和随后的释放锁)消耗超过 60 纳秒,超过 100 个时钟周期。这里的“最好情况”意味着用于表示锁的数据结构已经在获取和释放锁的 CPU 所属的高速缓存中了。
锁操作比 CAS 操作更加耗时,是因深入理解并行编程为锁操作的数据结构中需要两个原子操作。缓存未命中消耗大概 140 纳秒,超过 200 个时钟周期。
需要在存储新值时查询变量的旧值的 CAS 操作,消耗大概 300 纳秒,超过 500 个时钟周期。想想这个,在执行一次 CAS 操作的时间里,CPU 可以执行 500 条普通指令。这表明了细粒度锁的局限性。
5.CAS算法在JDK中的应用
介绍:在原子类变量中(基于CAS算法,提供的一套工具类,原子变量就相当于基于修饰词volatile,保证原子性,有条件的读改写操作),
如java.util.concurrent.atomic中的AtomicXXX,都使用了这些底层的JVM支持,为数字类型的引用类型提供一种高效的CAS操作,
而在java.util.concurrent中的大多数类在实现时都直接或间接的使用了这些原子变量类。
源码:
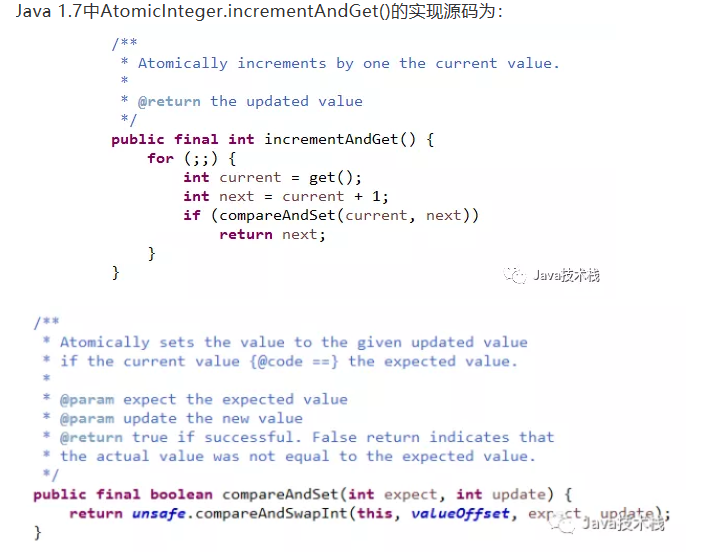
总结:由此可见,AtomicInteger.incrementAndGet的实现用了乐观锁技术,调用了类sun.misc.Unsafe库里面的 CAS算法,用CPU指令来实现无锁自增。所以,AtomicInteger.incrementAndGet的自增比用synchronized的锁效率倍增。
注:在Java中,AtomicStampedReference类就实现了用版本号作比较额CAS机制。
1. java语言CAS底层如何实现?
利用unsafe提供的原子性操作方法。
2.什么事ABA问题?怎么解决?
当一个值从A变成B,又更新回A,普通CAS机制会误判通过检测。
利用版本号比较可以有效解决ABA问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号