多层神经网络与应用—MNIST手写数字识别(二)
二、多层神经网络建模与模型的保存还原
主要内容:
2.1 两层神经网络的构建
2.2三层神经网络的构建
2.3重构建模过程
2.4训练模型的保存
2.5训练模型的还原与应用
2.1 两层神经网络的构建
H1_NN=256 #第1隐藏层神经元为256个 H2_NN=64 #第2隐藏层神经元为64个 #输入层 -第1隐藏层参数和偏置项 W1 = tf.Variable(tf.truncated_normal([784,H1_NN], stddev=0.1)) #设置标准差0.1 多层神经网络生成权值时不要用完全随机的方法 b1 = tf.Variable(tf.zeros([H1_NN])) #第1隐藏层 - 第2隐藏层参数和偏置项 W2 = tf.Variable(tf.truncated_normal([H1_NN,H2_NN], stddev=0.1)) b2 = tf.Variable(tf.zeros([H2_NN])) #第2隐藏层 - 输出层参数和偏置项 W3 = tf.Variable(tf.truncated_normal([H2_NN,10], stddev=0.1)) b3 = tf.Variable(tf.zeros([10])) Y1 = tf.nn.relu(tf.matmul(x,W1)+b1) #计算第1隐藏层结果 Y2 = tf.nn.relu(tf.matmul(Y1,W2)+b2) #计算第2隐藏层结果 forward = tf.matmul(Y2, W3) + b3 #计算输出结果 pred = tf.nn.softmax(forward)
这里生成随机数的方式做了改变,用了tf.truncated_normal()函数,从截断的正态分布中输出随机数。stddev是标准差,如果随机数的标准差大于两倍的0.1就会重新生成,使得W1的值相对比较均匀。在多层神经网络中最好还是采用这种随机的方式。
其余代码和单层神经网络一致。完整代码如下:


#Created by:Huang #Time:2019/10/15 0015. import tensorflow as tf import tensorflow.examples.tutorials.mnist.input_data as input_data import matplotlib.pyplot as plt import numpy as np from time import time mnist = input_data.read_data_sets("MNIST_data/",one_hot=True) #定义标签数据占位符 x= tf.placeholder(tf.float32, [None, 784], name='X') #图片大小28*28 y= tf.placeholder(tf.float32, [None, 10], name='Y') H1_NN=256 #第1隐藏层神经元为256个 H2_NN=64 #第2隐藏层神经元为64个 #输入层 -第1隐藏层参数和偏置项 W1 = tf.Variable(tf.truncated_normal([784,H1_NN], stddev=0.1)) #设置标准差0.1 多层神经网络生成权值时不要用完全随机的方法 b1 = tf.Variable(tf.zeros([H1_NN])) #第1隐藏层 - 第2隐藏层参数和偏置项 W2 = tf.Variable(tf.truncated_normal([H1_NN,H2_NN], stddev=0.1)) b2 = tf.Variable(tf.zeros([H2_NN])) #第2隐藏层 - 输出层参数和偏置项 W3 = tf.Variable(tf.truncated_normal([H2_NN,10], stddev=0.1)) b3 = tf.Variable(tf.zeros([10])) Y1 = tf.nn.relu(tf.matmul(x,W1)+b1) #计算第1隐藏层结果 Y2 = tf.nn.relu(tf.matmul(Y1,W2)+b2) #计算第2隐藏层结果 forward = tf.matmul(Y2, W3) + b3 #计算输出结果 pred = tf.nn.softmax(forward) loss_function = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=forward,labels=y)) #注意第一个参数是不做Softmax的前向计算结果 #设置训练参数 train_epochs = 40 #训练轮数 batch_size=50 #单次训练样本数(批次大小) total_batch= int(mnist.train.num_examples/batch_size)#一轮训练有多少批次 display_step=1 #显示粒度 learning_rate=0.01 #学习率 #选择优化器 optimizer = tf.train.AdamOptimizer(learning_rate).minimize(loss_function) #定义准确率 correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(pred,1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))#准确率,将布尔值转化为浮点数,并计算平均值 #记录训练开始时间 startTime = time() sess = tf.Session() sess.run(tf.global_variables_initializer()) for epoch in range(train_epochs): for batch in range(total_batch): xs, ys = mnist.train.next_batch(batch_size) # 读取批次数据 sess.run(optimizer,feed_dict={x:xs,y:ys}) # 执行批次训练 #total_batch个批次训练完成后,使用验证数据计算课差与准确率;验证集没有分批 loss,acc = sess.run([loss_function,accuracy],feed_dict={x:mnist.validation.images,y:mnist.validation.labels}) #打印训练过程中的详细信息 if (epoch+1) % display_step == 0: print("Train Epoch:",'%02d' %(epoch+1),"Loss=","{:.9f}".format(loss),"Accuracy=","{:.4f}".format(acc)) duration = time()-startTime #显示运行总时间 print("Train Finished takes:","{:.2f}".format(duration)) #使用测试集评估模型 accu_test = sess.run(accuracy,feed_dict={x:mnist.test.images,y:mnist.test.labels}) print("Test Accuracy:",accu_test)
运行结果为:
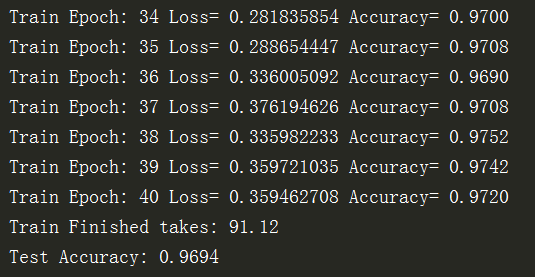
可以发现,多层效果不一定就比单层网络效果好!还是要通过对超参数的调整来优化模型
2.2三层神经网络的构建
H1_NN=256 #第1隐藏层神经元为256个 H2_NN=64 #第2隐藏层神经元为64个 H3_NN=32 #输入层 -第1隐藏层参数和偏置项 W1 = tf.Variable(tf.truncated_normal([784,H1_NN], stddev=0.1)) #设置标准差0.1 多层神经网络生成权值时不要用完全随机的方法 b1 = tf.Variable(tf.zeros([H1_NN])) #第1隐藏层 - 第2隐藏层参数和偏置项 W2 = tf.Variable(tf.truncated_normal([H1_NN,H2_NN], stddev=0.1)) b2 = tf.Variable(tf.zeros([H2_NN])) #第2隐藏层 - 第3隐藏层参数和偏置项 W3 = tf.Variable(tf.truncated_normal([H2_NN,H3_NN], stddev=0.1)) b3 = tf.Variable(tf.zeros([H3_NN])) #第3隐藏层 - 输出层参数和偏置项 W4 = tf.Variable(tf.truncated_normal([H3_NN,10], stddev=0.1)) b4 = tf.Variable(tf.zeros([10])) Y1 = tf.nn.relu(tf.matmul(x,W1)+b1) #计算第1隐藏层结果 Y2 = tf.nn.relu(tf.matmul(Y1,W2)+b2) #计算第2隐藏层结果 Y3 = tf.nn.relu(tf.matmul(Y2,W3)+b3) #计算第3隐藏层结果 forward = tf.matmul(Y3, W4) + b4 #计算输出结果 pred = tf.nn.softmax(forward)
其余代码和单层神经网络一致。完整代码如下:
#Created by:Huang #Time:2019/10/15 0015. #Created by:Huang #Time:2019/10/15 0015. import tensorflow as tf import tensorflow.examples.tutorials.mnist.input_data as input_data import matplotlib.pyplot as plt import numpy as np from time import time mnist = input_data.read_data_sets("MNIST_data/",one_hot=True) #定义标签数据占位符 x= tf.placeholder(tf.float32, [None, 784], name='X') #图片大小28*28 y= tf.placeholder(tf.float32, [None, 10], name='Y') H1_NN=256 #第1隐藏层神经元为256个 H2_NN=64 #第2隐藏层神经元为64个 H3_NN=32 #输入层 -第1隐藏层参数和偏置项 W1 = tf.Variable(tf.truncated_normal([784,H1_NN], stddev=0.1)) #设置标准差0.1 多层神经网络生成权值时不要用完全随机的方法 b1 = tf.Variable(tf.zeros([H1_NN])) #第1隐藏层 - 第2隐藏层参数和偏置项 W2 = tf.Variable(tf.truncated_normal([H1_NN,H2_NN], stddev=0.1)) b2 = tf.Variable(tf.zeros([H2_NN])) #第2隐藏层 - 第3隐藏层参数和偏置项 W3 = tf.Variable(tf.truncated_normal([H2_NN,H3_NN], stddev=0.1)) b3 = tf.Variable(tf.zeros([H3_NN])) #第3隐藏层 - 输出层参数和偏置项 W4 = tf.Variable(tf.truncated_normal([H3_NN,10], stddev=0.1)) b4 = tf.Variable(tf.zeros([10])) Y1 = tf.nn.relu(tf.matmul(x,W1)+b1) #计算第1隐藏层结果 Y2 = tf.nn.relu(tf.matmul(Y1,W2)+b2) #计算第2隐藏层结果 Y3 = tf.nn.relu(tf.matmul(Y2,W3)+b3) #计算第3隐藏层结果 forward = tf.matmul(Y3, W4) + b4 #计算输出结果 pred = tf.nn.softmax(forward) loss_function = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=forward,labels=y)) #注意第一个参数是不做Softmax的前向计算结果 #设置训练参数 train_epochs = 40 #训练轮数 batch_size=50 #单次训练样本数(批次大小) total_batch= int(mnist.train.num_examples/batch_size)#一轮训练有多少批次 display_step=1 #显示粒度 learning_rate=0.01 #学习率 #选择优化器 optimizer = tf.train.AdamOptimizer(learning_rate).minimize(loss_function) #定义准确率 correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(pred,1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))#准确率,将布尔值转化为浮点数,并计算平均值 #记录训练开始时间 startTime = time() sess = tf.Session() sess.run(tf.global_variables_initializer()) for epoch in range(train_epochs): for batch in range(total_batch): xs, ys = mnist.train.next_batch(batch_size) # 读取批次数据 sess.run(optimizer,feed_dict={x:xs,y:ys}) # 执行批次训练 #total_batch个批次训练完成后,使用验证数据计算课差与准确率;验证集没有分批 loss,acc = sess.run([loss_function,accuracy],feed_dict={x:mnist.validation.images,y:mnist.validation.labels}) #打印训练过程中的详细信息 if (epoch+1) % display_step == 0: print("Train Epoch:",'%02d' %(epoch+1),"Loss=","{:.9f}".format(loss),"Accuracy=","{:.4f}".format(acc)) duration = time()-startTime #显示运行总时间 print("Train Finished takes:","{:.2f}".format(duration)) #使用测试集评估模型 accu_test = sess.run(accuracy,feed_dict={x:mnist.test.images,y:mnist.test.labels}) print("Test Accuracy:",accu_test)
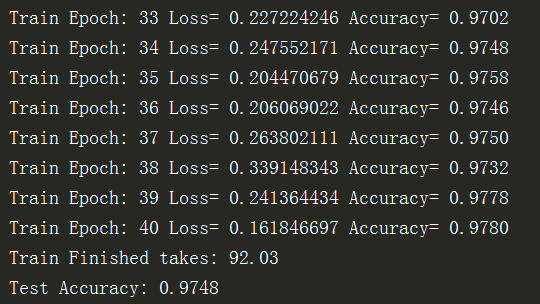
2.3重构建模过程
在之前的建模过程中,首先需要根据隐藏层的数量构建相应的模型,层数越多,定义的W、b、Y就越多。既然构建每层隐藏层的时候,都需要定义相关的W、b以及计算结果Y,我们能否重新优化构造一下呢? 可以定义全连接层函数,有了这个函数,以后定义全连接层的神经网络时,不管有多少层,对于每一层的定义都可以通过这个函数来解决,使得整个建模过程看起来更加直观,条理也更加清晰。
#定义全连接层函数 def fcn_layer(inputs,input_dim,output_dim,activation=None): #输入数据,输入神经元数量,输出神经元数量,激活函数 W = tf.Variable(tf.truncated_normal([input_dim, output_dim], stddev=0.1)) # 以截断正态分布的随机数初始化W b = tf.Variable(tf.zeros([output_dim])) # 以0初始化b XWb = tf.matmul(inputs, W)+b # 建立表达式:inputs * W + b if activation is None: # 薪认不使用激活函数 outputs = XWb else: # 若传入激活函数,则用其对输出结果进行变换 outputs = activation(XWb) return outputs
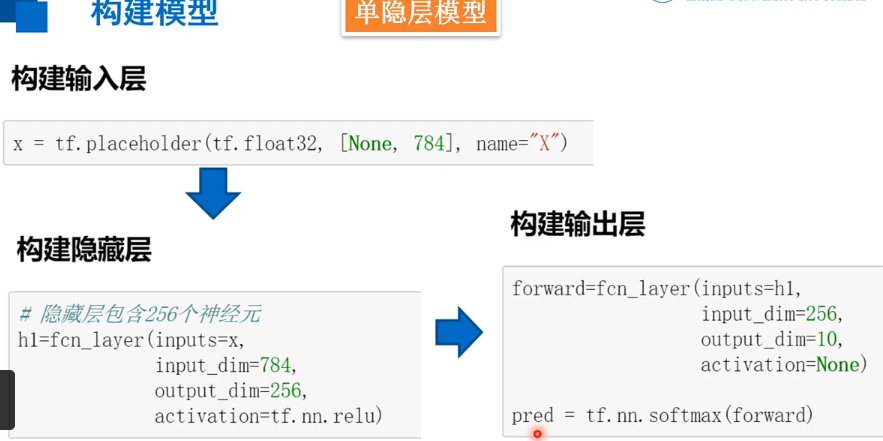
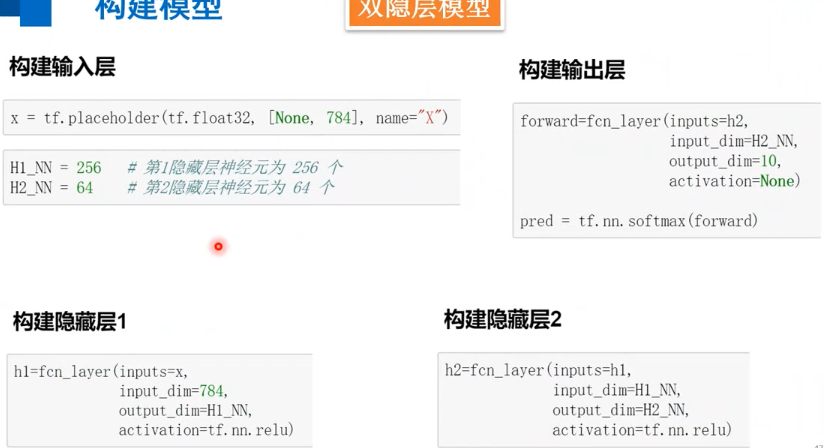

2.4训练模型的保存
2.4.1初始化参数和文件目录
为了做好模型的保存,需要添加一些参数。首先用到了save_step,即模型保存的粒度(训练多少轮保存一次),如果设为1,那么每一轮都会保存。在这里设置为5,即每五轮保存一次。模型保存在计算机上需要有一个具体的位置,我们建立了一个目录“./ckpt_dir/”,前面的点表示当前文件目录下新建一个子目录。这里会用到os库,所以需要导入进来,接着做一个判断,如果当前目录下不存在这个子目录则创建一个新的子目录。

2.4.2训练并存储模型

在训练模型之前,若所有的变量都定义好了,就可以调用tf.train.Saver()去初始化saver,存储模型将通过saver来实现。
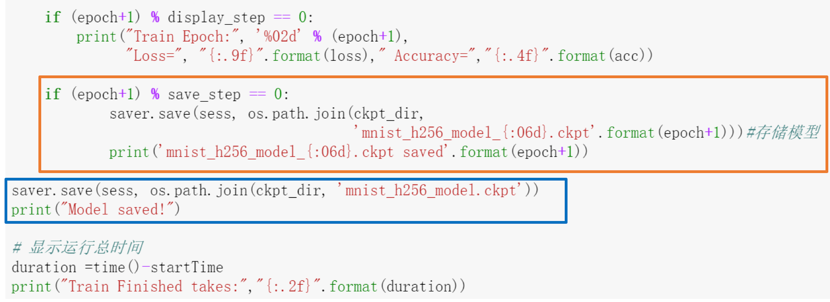
在训练模型中,橙框的上面部分输出了这一轮的训练结果(损失值以及精确率);橙框中的代码是加入的代码,它表示当这一轮结果需要保存的时候,调用saver的save方法,里面的有两个参数:第一个参数是当前运行的会话,它要把会话中的所有变量的值保存下来,第二个参数是所要保存模型的文件名,这个文件名需要包含具体目录,所以这里利用了os.path.join()函数来合成,第一个参数是刚才定义的子目录,第二个参数是模型的名字,名字中保留了一个记录轮次的格式,这样就可以知道这个文件是第几轮训练的结果。然后输出一个提示,告诉我们已经保存完成。当所有轮次训练完毕后,再通过蓝框中的代码保存最后的结果。
完整代码如下:
#基于单隐藏层神经网络的手写数字识别(模型重构+保存模型) import tensorflow as tf import tensorflow.examples.tutorials.mnist.input_data as input_data import matplotlib.pyplot as plt import numpy as np from time import time import os mnist = input_data.read_data_sets("MNIST_data/",one_hot=True) #定义全连接层函数 def fcn_layer(inputs,input_dim,output_dim,activation=None): #输入数据,输入神经元数量,输出神经元数量,激活函数 W = tf.Variable(tf.truncated_normal([input_dim, output_dim], stddev=0.1)) # 以截断正态分布的随机数初始化W b = tf.Variable(tf.zeros([output_dim])) # 以0初始化b XWb = tf.matmul(inputs, W)+b # 建立表达式:inputs * W + b if activation is None: # 薪认不使用激活函数 outputs = XWb else: # 若传入激活函数,则用其对输出结果进行变换 outputs = activation(XWb) return outputs x= tf.placeholder(tf.float32, [None, 784], name='X') #构建输入层 y= tf.placeholder(tf.float32, [None, 10], name='Y') #定义标签数据占位符 h1 = fcn_layer(inputs=x,input_dim=784,output_dim=256,activation=tf.nn.relu) #构建隐藏层 forward = fcn_layer(inputs=h1,input_dim=256,output_dim=10,activation=None) #构建输出层 pred = tf.nn.softmax(forward) loss_function = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=forward,labels=y)) #注意第一个参数是不做Softmax的前向计算结果 #设置训练参数 train_epochs = 40 #训练轮数 batch_size=50 #单次训练样本数(批次大小) total_batch= int(mnist.train.num_examples/batch_size)#一轮训练有多少批次 display_step=1 #显示粒度 learning_rate=0.01 #学习率 save_step=5 #存储模型的粒度 #创建保存模型文件的目录 ckpt_dir="./ckpt_dir/" if not os.path.exists(ckpt_dir): #判断如果不存在则创建一个子目录 os.makedirs(ckpt_dir) #选择优化器 optimizer = tf.train.AdamOptimizer(learning_rate).minimize(loss_function) #定义准确率 correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(pred,1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))#准确率,将布尔值转化为浮点数,并计算平均值 saver = tf.train.Saver() #声明完所有变量后,调用tf.train.Saver #记录训练开始时间 startTime = time() sess = tf.Session() sess.run(tf.global_variables_initializer()) for epoch in range(train_epochs): for batch in range(total_batch): xs, ys = mnist.train.next_batch(batch_size) # 读取批次数据 sess.run(optimizer,feed_dict={x:xs,y:ys}) # 执行批次训练 #total_batch个批次训练完成后,使用验证数据计算课差与准确率;验证集没有分批 loss,acc = sess.run([loss_function,accuracy],feed_dict={x:mnist.validation.images,y:mnist.validation.labels}) #打印训练过程中的详细信息 if (epoch+1) % display_step == 0: print("Train Epoch:",'%02d' %(epoch+1),"Loss=","{:.9f}".format(loss),"Accuracy=","{:.4f}".format(acc)) if (epoch + 1) % save_step == 0: saver.save(sess, os.path.join(ckpt_dir,'mnist_h256_model_{:06d}.ckpt'.format(epoch+1)))#存储模型 print('mnist_h256_model_{:06d}.ckpt saved'.format(epoch+1)) saver.save(sess, os.path.join(ckpt_dir,'mnist_h256_model.ckpt')) print("Model saved!") duration = time()-startTime #显示运行总时间 print("Train Finished takes:","{:.2f}".format(duration)) #使用测试集评估模型 accu_test = sess.run(accuracy,feed_dict={x:mnist.test.images,y:mnist.test.labels}) print("Test Accuracy:",accu_test)
执行训练之后,
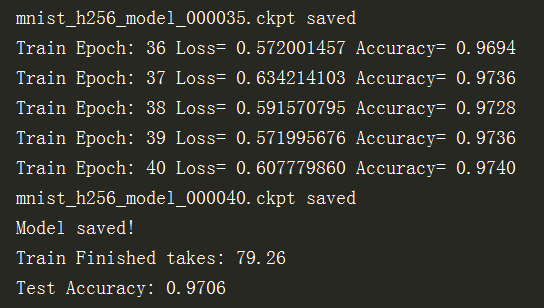
进入对应的目录,可以看到保存的文件:
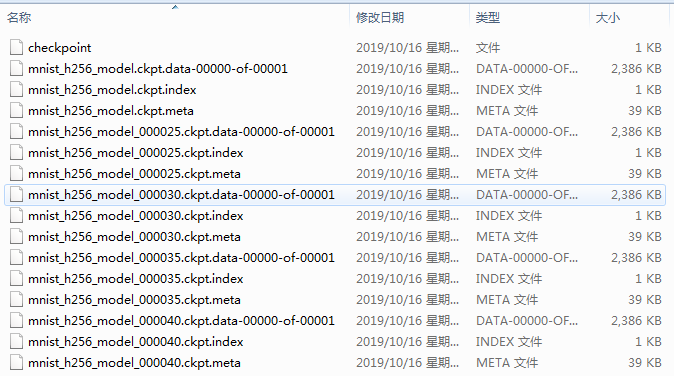
可以看到每一轮的模型文件都有三个文件。由于模型保存的机制中缺省最多保留最近5份模型,因此最初几轮的模型就没有了。因为最上面还有一个checkpoint文件,所以这里总共是16个文件。
2.5训练模型的还原与应用
之前把训练模型存盘,实际上保存的是模型里所有变量当前运行的值。这相当于是训练模型的快照,把保存的时间点的所有变量都变成存盘文件保存起来。如果要还原这个模型,我们需要从存盘的模型中把所有变量的值读取出来,赋给当前准备被还原的模型。
2.5.1定义相同结构的模型
首先,我们还是要定义一个和以前存盘模型相同结构的模型,只有它们的结构相同,这些变量才能吻合,才能把读取出来的变量的值赋给等待着被覆盖的变量的值。
这里还是采用单层的256个神经元的神经网络的结构模型,构建相同的输入层、隐藏层、输出层。。

2.5.2设置模型文件的存放目录

设置还原模型的文件所存放的位置,这个目录跟存盘文件的目录相同。因为这个存盘文件缺省就是最多保留最近的五份模型文件,所以恢复时,会找最新的那一份文件。
2.5.3读取还原模型

这里同样需要创建一个saver,然后通过红框中的语句,得到存盘文件里所有模型的最新状态。如果它找到了这个存盘文件,就可以从目录中读取参数,恢复到当前的会话中,而原本会话中的值就被覆盖掉了。之后输出模型已从当前目录下恢复的提示。
恢复好以后,就可以利用这个模型。可以直接用来预测准确率,也可以断点续训,在当前存盘文件数据的基础上继续做优化训练。
2.5.4输出还原模型的准确率
print("Accuracy",accuracy.eval(session=sess,feed_dict={x:mnist.validation.images,y:mnist.validation.labels}))

这里测试出来的准确率和当时存盘时的准确率是一样的
2.5.5执行预测
.........................
完整代码:
import tensorflow as tf import tensorflow.examples.tutorials.mnist.input_data as input_data import matplotlib.pyplot as plt import numpy as np from time import time import os mnist = input_data.read_data_sets("MNIST_data/",one_hot=True) #定义全连接层函数 def fcn_layer(inputs,input_dim,output_dim,activation=None): #输入数据,输入神经元数量,输出神经元数量,激活函数 W = tf.Variable(tf.truncated_normal([input_dim, output_dim], stddev=0.1)) # 以截断正态分布的随机数初始化W b = tf.Variable(tf.zeros([output_dim])) # 以0初始化b XWb = tf.matmul(inputs, W)+b # 建立表达式:inputs * W + b if activation is None: # 薪认不使用激活函数 outputs = XWb else: # 若传入激活函数,则用其对输出结果进行变换 outputs = activation(XWb) return outputs x= tf.placeholder(tf.float32, [None, 784], name='X') #构建输入层 y= tf.placeholder(tf.float32, [None, 10], name='Y') #定义标签数据占位符 h1 = fcn_layer(inputs=x,input_dim=784,output_dim=256,activation=tf.nn.relu) #构建隐藏层 forward = fcn_layer(inputs=h1,input_dim=256,output_dim=10,activation=None) #构建输出层 pred = tf.nn.softmax(forward) #定义准确率 correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(pred,1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))#准确率,将布尔值转化为浮点数,并计算平均值 ckpt_dir="./ckpt_dir/" #设置目录 #读取模型 saver = tf.train.Saver() #声明完所有变量后,调用tf.train.Saver sess = tf.Session() sess.run(tf.global_variables_initializer()) ckpt = tf.train.get_checkpoint_state(ckpt_dir) if ckpt and ckpt.model_checkpoint_path: saver.restore(sess, ckpt.model_checkpoint_path) #从已保存的模型中读取参数 print("Restore model from"+ckpt.model_checkpoint_path) #输出模型准确率 print("Accuracy",accuracy.eval(session=sess,feed_dict={x:mnist.test.images,y:mnist.test.labels}))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号