正反向进阶查询
'''在filter括号内也可以使用正反向查询'''
1.数据对象点正反向概念
2.values点正反向
3.filter括号内使用正反向
eg:
models.Book.objects.filter(publish__pk=1).values('publish_name','publish_addr')
聚合查询
聚合查询关键字:avg,count,sum,max,min
'''没有分组之前的聚合函数需要使用关键字aggregate'''
from django.db.models import Max, Min, Sum, Avg, Count
res = models.Book.objects.aggregate(Max('price'), Min('price'), Sum('price'), Avg('price'), Count('pk'))
print(res)
分组查询 annotate
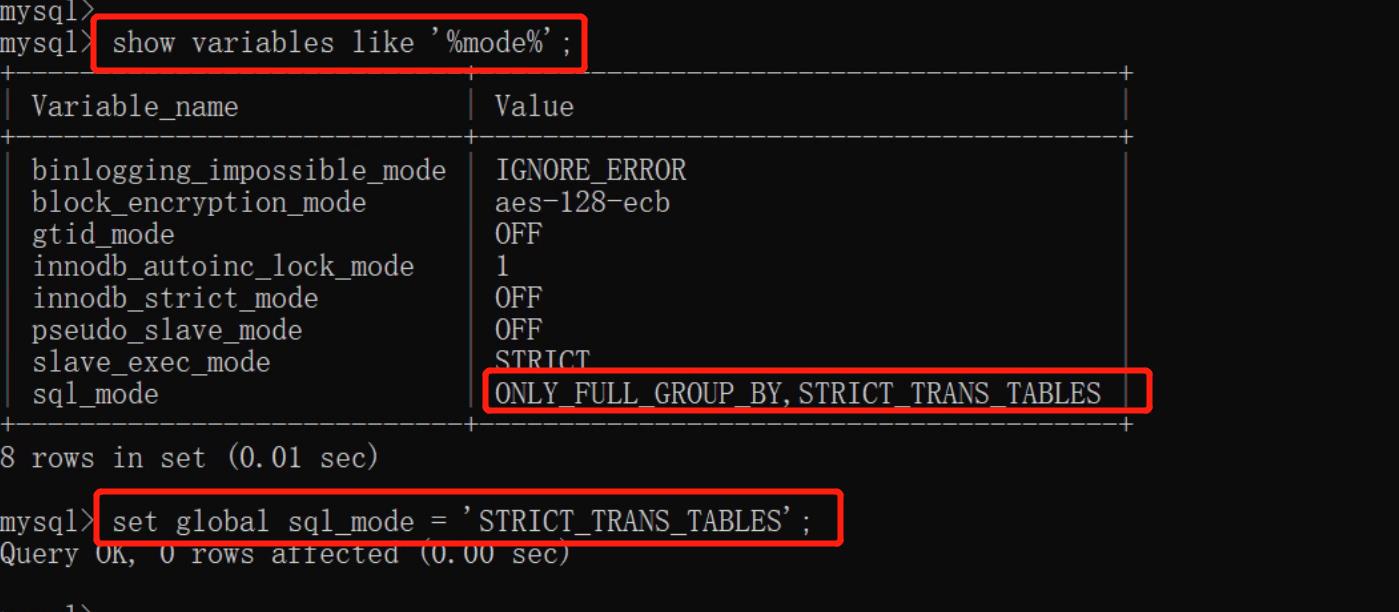
'''分组查询的特性是:默认只能够获取分组的字段,其他字段需要使用方法'''
这个特性可以在cmd中取消,具体命令和操作看下图
"""
1.按照整条数据分组
models.Book.objects.annotate() 按照一条条书籍记录分组
2.按照表中某个字段分组()
models.Book.objects.values('title').annotate() 按照annotate之前values括号中指定的字段分组
"""
# 示例:统计不止一个作者的图书
'''filter在annotate前面则是where 在annotate后面则是having'''
res = models.Book.objects.annotate(author_num=Count('authors__pk')).filter(author_num__gt=1).values('title','author_num')
# print(res)
![image]()
F与Q查询
导入模块 from django.db.models import F/Q
F :能够将表中指定的字段作为关系
'''f查询:查询条件不是自定义的 而是来自表中的其他字段'''
from djano.db.models import f
1.查询库存大于卖出书的书籍
models.Book.objects.filter(storage_num__gt=F('sale_num'))
2.将所有的书籍的价格上涨1000元
models.Book.objects.update(price=F('price')+1000)
3.将所有书籍名称加一个爆款后缀
from djano.db.models.functions import concat
from django.db.modles import Value
models.Book.objects.filter(pk=5).update(title=Concat(F('title'),Value('爆款')))
'''Q:可以改变filter括号内多个条件之间的逻辑运算符 还可以将查询条件的字段改为字符串形式'''
# 将查询条件改为字符串形式
1.先用Q产生一个对象
q_obj=Q()
2.给对象添加查询条件 (可以添加多个 默认为and关系 可以修改为or)
q_obj.children.append('pk',1)
res = models.Book.objects.filter(q_obj)
eg:动态添加多个查询条件
res = Q()
res.connector='OR' # 指定使用'or'作为查询条件
res.children.append(('age__contains','18')) # contain模糊查询 不忽略大小写 icontain 忽略大小写
res.children.append(('name__contatins','summer'))
models.user.objects.values('age','name').filter(res) # 查询年龄18或者名字是summer的用户
ORM查询优化(面试会问)
目的是为了减少数据库的使用
多对多四个方法:
#1.only与defer 【单表查询】
only()
数据对象点括号内的字段 不会再走数据库查询
defer()
数据对象点括号内的字段 会再走数据库查询
eg: # only
res = Book.objects.only('price','title')
for obj in res:
print(obj.price)
print(obj.title)
print(obj.publish) # 走数据库查询
eg: # defer 【与only刚好相反】
res = Book.objects.defer('price','title')
for obj in res:
print(obj.price)
print(obj.title)
print(obj.publish) # 不走数据库查询
# 2.select_related与prefetch_related 【多表查询】
select_related()
# 该方法括号内的参数只能填写一对多和一对一的表 多对多不可用!
填写外键字段 自动连表 后续无需走数据库查询
res = Book.objects.select_related(publish)
for obj in res:
print(obj.publish.title) # 不再走数据库查询
prefetch_related()
填写外键字段 子查询 后续也无需走数据库查询
res = Book.objects.prefetch_related(publish)
for obj in res:
print(obj.publish.title) # 不再走数据库查询
# 底层就是子查询 其实是走了两条slq的 对比上面的方法多了一条
事务操作
ACID:
原子性,一致性 隔离性 持久性
# from django.db import transaction
开启事务:
try:
with transaction.atomic():
pass 可以写多条ORM语句
except Exception as e:
print(e)
# 用异常捕获检测的话能更好的保障数据的安全性
模型层常见字段
1.AutoField int自增列,必须填入参数 primary_key=True
2.IntegerField 整数类型
3.CharField 字符串类型 必须提供max_length参数, max_length表示字符长度
'''Django中的CharField对应的MySQL数据库中的varchar类型 没有设置对应char类型的字段,但是Django允许我们自定义新的字段'''
4.DateField 日期字段,日期格式 YYYY-MM-DD
ORM常见字段参数
max_length
verboses_name # 用于在后台进行显示 类似于中文备注 便于查看
auto_now #每次更新数据记录的时候会更新该字段
auto_now_add #创建数据记录的时候会把当前时间添加到数据库 除非人为更改 否则一直不变
null
default
max_digits
choice()方法取值
related_name 关联字段起别名
unique
models.CASCADE # 删除数据 关联数据一起删除
# mysql 索引和慢查询优化
foreignkey的on_delete的选择:
1.models.CASCADE 级联删除,用的很少,除非真的删除
2.models.SET_NULL 关联字段可以设为空 null=true
3.models.SET_DEFAULT 关联字段设为默认值 defalut=’‘
4.models.DO_NOTHING 什么都不用做,不用强外键关联
5.models.SET() 放函数内存地址,关联字段删除时,会执行这个函数
# 外键关联的好处与坏处:
好处:插入修改数据有校验,能够保证数据不会出现错乱,不会出现脏数据
坏处:有校验速度就会慢,数据量越大速度越慢,可以通过程序控制不加入脏数据
在django中不建立外键关联,也可以使用foreignkey,不需要加to,直接写参数,虽然没有约束但是关系还在
choice
gender_choice = ((1,'男'),(2,'女'),(3,'未知'))
gender = models.IntegerField(choices=gender_choice)
print(obj.get_gender_display()) # 直接按照数字对应的中文展示
------------
related_name:反向操作时(基于对象的跨表查询)使用的字段名,用于代替原反向操作时的'表名小写_set'
related_query_name:反向操作时(基于链表的跨表查询)使用的链接前缀,用于替换表名
多对多三种创建方式
# 1.系统自动创建
models.ManyToManyField(to='')
优点:第三张表自动创建
缺点:第三张表扩展性差
#2.全手动创建
class Book(models.Model):
pass
class Author(models.Model):
pass
class Book2Author(models.Model):
book_id = models.ForeignKey(to="Book")
author_id = models.ForeignKey(to="Author")
优点:可以任意添加想要的属性、
缺点:无法使用正反向查询和多对多四个方法(only和defer,select_related和prefetch_related)
# 3.半自动创建 through
class Book(models.Model):
authors = models.ManyToManyField(to='Author',
through='Book2Author'
through_fields=('book_id','author_id') # 写好需要关联的两个字段
)
class Author(models.Model):
pass
class Book2Author(models.Model):
book_id = models.ForeignKey(to="Book")
author_id = models.ForeignKey(to="Author")
优点:扩展性强,并且支持正反向查询
缺点:无法使用多对多四个方法


 浙公网安备 33010602011771号
浙公网安备 33010602011771号