爬虫第五次作业
作业①:
(1)JDSelenium
-
要求:
- 熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
- 使用Selenium框架爬取京东商城某类商品信息及图片。
-
候选网站:http://www.jd.com/
-
关键词:学生自由选择
-
输出信息:MYSQL的输出信息如下
mNo mMark mPrice mNote mFile 000001 三星Galaxy 9199.00 三星Galaxy Note20 Ultra 5G... 000001.jpg 000002......
代码
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import urllib.request
import threading
import os
import datetime
from selenium.webdriver.common.keys import Keys
import time
import re
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import pymysql
class MySpider:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.193 Safari/537.36"}
imagePath = r"C:\Users\lxc's girlfriend\Desktop\images"
def startUp(self, url, key):
# 初始化谷歌浏览器
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
self.driver = webdriver.Chrome(chrome_options=chrome_options)
# 初始化变量
self.threads = []
self.No = 0
self.imgNo = 0
# 初始化数据库
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="123456", db="mydb",charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
try:
# 如果有表就删除
self.cursor.execute("drop table lznoodles")
except:
pass
try:
# 建立新的表
sql = "create table lznoodles (mNo varchar(32) primary key, mShop varchar(256), mPrice varchar(32), mNote varchar(1024), mFile varchar(256))"
self.cursor.execute(sql)
except:
pass
except Exception as err:
print(err)
# 初始化图片文件夹
try:
if not os.path.exists(MySpider.imagePath):
os.mkdir(MySpider.imagePath)
images = os.listdir(MySpider.imagePath)
for img in images:
s = os.path.join(MySpider.imagePath, img)
os.remove(s)
except Exception as err:
print(err)
# 打开网站并搜索key中的值
self.driver.get(url)
keyInput = self.driver.find_element_by_id("key")
keyInput.send_keys(key)
keyInput.send_keys(Keys.ENTER)
# 获取总页数
WebDriverWait(self.driver, 1000).until(EC.presence_of_element_located((By.XPATH, "//span[@class='p-skip']/em/b")))
self.final = int(self.driver.find_element_by_xpath("//span[@class='p-skip']/em/b").text)
def closeUp(self):
try:
# 关闭数据库、断开与谷歌浏览器连接
self.con.commit()
self.con.close()
self.driver.close()
except Exception as err:
print(err)
def insertDB(self, mNo, mShop, mPrice, mNote, mFile):
try:
sql = "insert into lznoodles (mNo,mShop,mPrice,mNote,mFile) values (%s,%s,%s,%s,%s)"
self.cursor.execute(sql, (mNo, mShop, mPrice, mNote, mFile))
except Exception as err:
print(err)
def download(self, src1, src2, mFile):
data = None
if src1:
try:
req = urllib.request.Request(src1, headers=MySpider.headers)
resp = urllib.request.urlopen(req, timeout=10)
data = resp.read()
except:
pass
if not data and src2:
try:
req = urllib.request.Request(src2, headers=MySpider.headers)
resp = urllib.request.urlopen(req, timeout=10)
data = resp.read()
except:
pass
if data:
print("download begin", mFile)
fobj = open(MySpider.imagePath + "\\" + mFile, "wb")
fobj.write(data)
fobj.close()
print("download finish", mFile)
def processSpider(self):
try:
print(self.driver.current_url)
# 慢慢下拉,等所有数据加载出来
for y in range(10):
js = 'window.scrollBy(0,500)'
self.driver.execute_script(js)
time.sleep(0.5)
WebDriverWait(self.driver, 1000).until(EC.presence_of_all_elements_located((By.CLASS_NAME, 'gl-item')))
lis =self.driver.find_elements_by_class_name('gl-item')
for li in lis:
# 获取想要的数据
try:
src1 = li.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("src")
except:
src1 = ""
try:
src2 = li.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("data-lazy-img")
except:
src2 = ""
try:
price = li.find_element_by_xpath(".//div[@class='p-price']//i").text
except:
price = "0"
try:
note = li.find_element_by_xpath(".//div[@class='p-name p-name-type-2']//em").text
except:
note = ""
try:
shop = li.find_element_by_xpath(".//span[@class='J_im_icon']/a").get_attribute("title")
except:
shop = ""
self.No = self.No + 1
no = str(self.No)
while len(no) < 6:
no = "0" + no
print(no, shop, price)
# 确定图片url并下载
if src1:
src1 = urllib.request.urljoin(self.driver.current_url, src1)
p = src1.rfind(".")
mFile = no + src1[p:]
elif src2:
src2 = urllib.request.urljoin(self.driver.current_url, src2)
p = src2.rfind(".")
mFile = no + src2[p:]
if src1 or src2:
T = threading.Thread(target=self.download, args=(src1, src2, mFile))
T.setDaemon(False)
T.start()
self.threads.append(T)
else:
mFile = ""
self.insertDB(no, shop, price, note, mFile) # 将爬取到的数据写入数据库
# 获取当前页数
WebDriverWait(self.driver, 1000).until(EC.presence_of_element_located((By.XPATH, "//span[@class='p-num']/a[@class='curr']")))
curr = int(self.driver.find_element_by_xpath("//span[@class='p-num']/a[@class='curr']").text)
# 翻页直到最后一页
if (curr < self.final):
WebDriverWait(self.driver, 1000).until(EC.presence_of_element_located((By.CLASS_NAME, 'pn-next')))
nextPage = self.driver.find_element_by_class_name('pn-next')
nextPage.click()
time.sleep(3)
self.processSpider()
except Exception as err:
print(err)
def executeSpider(self, url, key):
starttime = datetime.datetime.now()
print("Spider starting......")
self.startUp(url, key)
print("Spider processing......")
self.processSpider()
print("Spider closing......")
self.closeUp()
for t in self.threads:
t.join()
print("Spider completed......")
endtime = datetime.datetime.now()
elapsed = (endtime - starttime).seconds # 计算爬虫耗时
print("Total ", elapsed, " seconds elapsed")
url = "http://www.jd.com"
spider = MySpider()
while True:
print("1.爬取")
print("2.退出")
s = input("请选择(1,2):")
if s == "1":
spider.executeSpider(url, "螺蛳粉") # 爬取螺蛳粉商品的相关信息
continue
elif s == "2":
break
运行结果
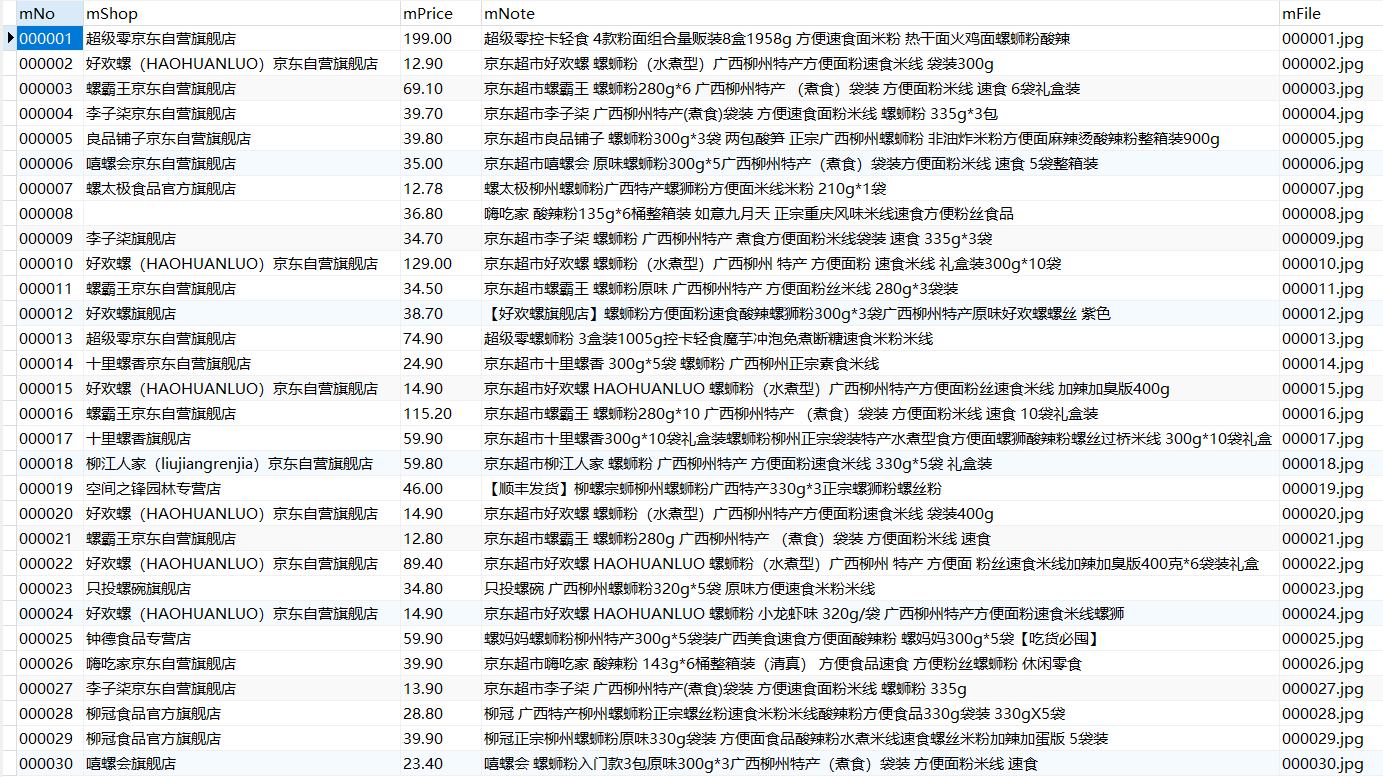
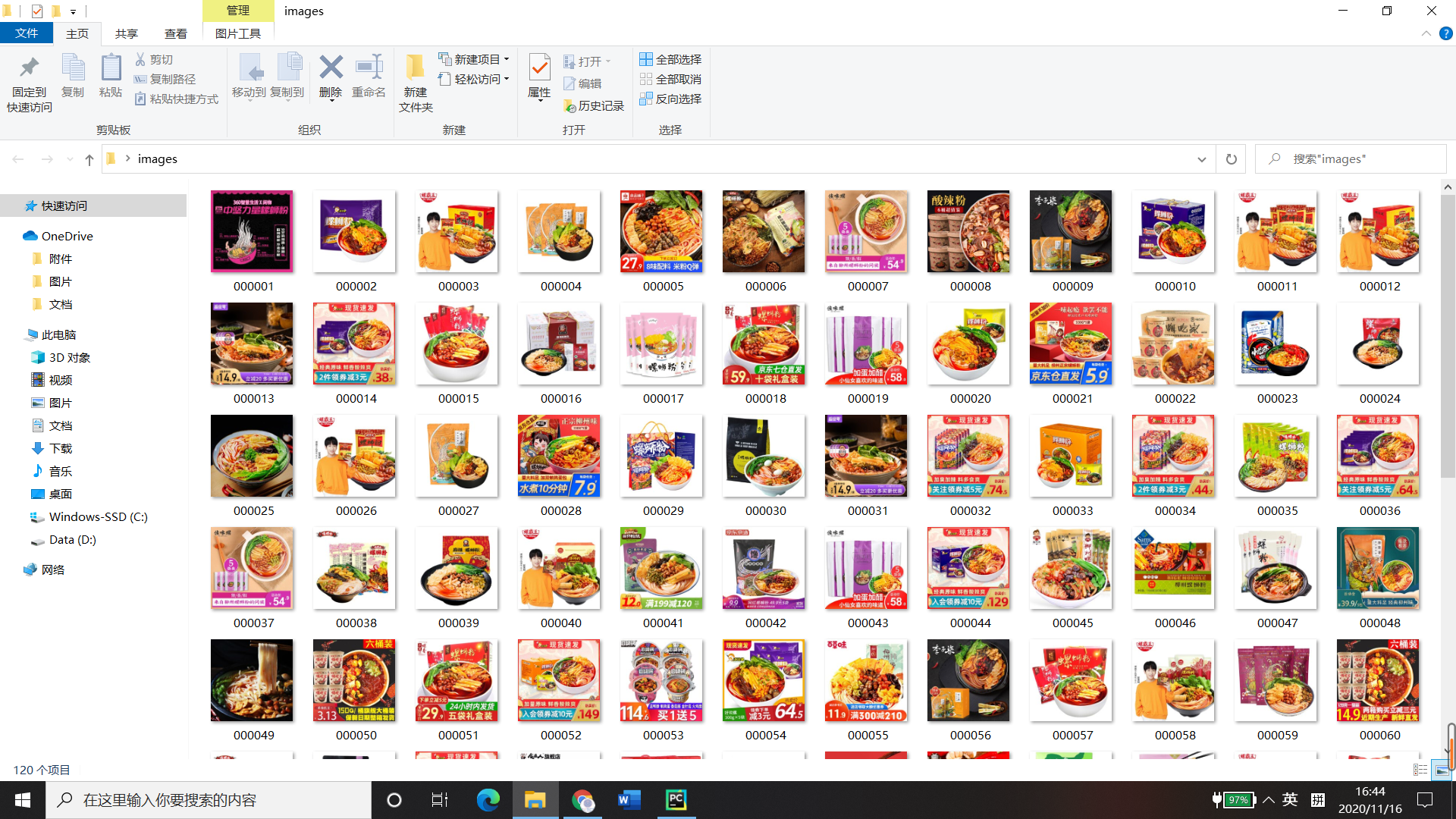
(2)心得体会
搜索页面要拉到底才能定位所有商品信息,但也不能一穿到底,要慢慢拉。按照ppt里给出的代码,即使是到了最后一页还是可以定位到且可点击“下一页”元素,所以要根据当前页码和总页码进行比较从而翻页。
作业②:
(1)StocksSelenium实验
-
要求:
- 熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
- 使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
-
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
-
输出信息:MYSQL数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头:
序号 股票代码 股票名称 最新报价 涨跌幅 涨跌额 成交量 成交额 振幅 最高 最低 今开 昨收 1 688093 N世华 28.47 62.22% 10.92 26.13万 7.6亿 22.34 32.0 28.08 30.2 17.55 2......
代码
import pymysql
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import datetime
import time
class MySpider:
def startup(self, url):
# 初始化谷歌浏览器
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
self.driver = webdriver.Chrome(chrome_options=chrome_options)
# 初始化变量
self.TAB_NO = 1
self.curr = 1
# 初始化数据库
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="123456", db="mydb",
charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
try:
# 如果有表就删除
self.cursor.execute("drop table HSAStocks")
self.cursor.execute("drop table SHAStocks")
self.cursor.execute("drop table SZAStocks")
except:
pass
try:
# 建立新的表
sql1 = "create table HSAStocks (mNo varchar(256) primary key, mCode varchar(256), mName varchar(256), mClose varchar(256), mChangePercent varchar(256), mChange varchar(256), mVolume varchar(256), mAmount varchar(256), mAmplitude varchar(256))"
sql2 = "create table SHAStocks (mNo varchar(256) primary key, mCode varchar(256), mName varchar(256), mClose varchar(256), mChangePercent varchar(256), mChange varchar(256), mVolume varchar(256), mAmount varchar(256), mAmplitude varchar(256))"
sql3 = "create table SZAStocks (mNo varchar(256) primary key, mCode varchar(256), mName varchar(256), mClose varchar(256), mChangePercent varchar(256), mChange varchar(256), mVolume varchar(256), mAmount varchar(256), mAmplitude varchar(256))"
self.cursor.execute(sql1)
self.cursor.execute(sql2)
self.cursor.execute(sql3)
except:
pass
except Exception as err:
print(err)
# 打开网站并获取当前总页数
self.driver.get(url)
self.final = int(self.driver.find_element_by_xpath("//span[@class='paginate_page']/a[last()]").text)
def closeup(self):
try:
# 关闭数据库、断开与谷歌浏览器连接
self.con.commit()
self.con.close()
self.driver.close()
except Exception as err:
print(err)
def insertdb(self, table, mno, mcode, mname, mclose, mchangepercent, mchange, mvolume, mamount, mamplitude):
try:
sql = "insert into " + table + "(mNo, mCode, mName, mClose, mChangePercent, mChange, mVolume, mAmount, mAmplitude) values (%s,%s,%s,%s,%s,%s,%s,%s,%s)"
self.cursor.execute(sql, (mno, mcode, mname, mclose, mchangepercent, mchange, mvolume, mamount, mamplitude))
except Exception as err:
print(err)
def processspider(self):
try:
print("Page", self.curr)
WebDriverWait(self.driver, 1000).until(EC.presence_of_all_elements_located((By.XPATH, "//table[@id='table_wrapper-table']/tbody/tr")))
trs = self.driver.find_elements_by_xpath("//table[@id='table_wrapper-table']/tbody/tr")
for tr in trs:
# 获取想要的数据
try:
no = tr.find_element_by_xpath("./td[position()=1]").text
while len(no) < 6:
no = "0" + no
except:
no = ""
try:
code = tr.find_element_by_xpath("./td[position()=2]/a").text
except:
code = ""
try:
name = tr.find_element_by_xpath("./td[position()=3]/a").text
except:
name = ""
try:
close = tr.find_element_by_xpath("./td[position()=5]/span").text
except:
close = ""
try:
changePercent = tr.find_element_by_xpath("./td[position()=6]/span").text
except:
changePercent = ""
try:
change = tr.find_element_by_xpath("./td[position()=7]/span").text
except:
change = ""
try:
volume = tr.find_element_by_xpath("./td[position()=8]").text
except:
volume = ""
try:
amount = tr.find_element_by_xpath("./td[position()=9]").text
except:
amount = ""
try:
amplitude = tr.find_element_by_xpath("./td[position()=10]").text
except:
amplitude = ""
print(no, code, name, close, changePercent, change, volume, amount, amplitude)
# 判断当前属于哪个模块并将数据写入数据库相应的表中
if self.TAB_NO == 1:
self.insertdb("HSAStocks", no, code, name, close, changePercent, change, volume, amount, amplitude)
elif self.TAB_NO == 2:
self.insertdb("SHAStocks", no, code, name, close, changePercent, change, volume, amount, amplitude)
else:
self.insertdb("SZAStocks", no, code, name, close, changePercent, change, volume, amount, amplitude)
# 翻页直到最后一页
if self.curr < self.final:
WebDriverWait(self.driver, 1000).until(EC.presence_of_element_located((By.XPATH, "//div[@class='dataTables_paginate paging_input']/a[position()=2]")))
nextPage = self.driver.find_element_by_xpath("//div[@class='dataTables_paginate paging_input']/a[position()=2]")
self.driver.execute_script('arguments[0].click()', nextPage)
time.sleep(3)
self.curr += 1
self.processspider()
# 翻模块
if self.TAB_NO < 3:
self.TAB_NO += 1
nextTab = self.driver.find_element_by_xpath(
"//ul[@class='tab-list clearfix']/li[position()=" + str(self.TAB_NO) + "]/a")
self.driver.execute_script('arguments[0].click()', nextTab)
time.sleep(3)
WebDriverWait(self.driver, 1000).until(EC.presence_of_element_located((By.XPATH, "//span[@class='paginate_page']/a[last()]")))
self.final = int(self.driver.find_element_by_xpath("//span[@class='paginate_page']/a[last()]").text)
self.curr = 1
print()
print(self.TAB_NO)
print()
self.processspider()
except Exception as err:
print(err)
def executespider(self, url):
starttime = datetime.datetime.now()
print("Spider starting......")
self.startup(url)
print("Spider processing......")
print(1)
print()
self.processspider()
print("Spider closing......")
self.closeup()
print("Spider completed......")
endtime = datetime.datetime.now() # 计算爬虫耗时
elapsed = (endtime - starttime).seconds
print("Total ", elapsed, " seconds elapsed")
url = "http://quote.eastmoney.com/center/gridlist.html#hs_a_board"
spider = MySpider()
while True:
print("1.爬取")
print("2.退出")
s = input("请选择(1,2):")
if s == "1":
spider.executespider(url)
continue
elif s == "2":
break
运行结果
沪深A股
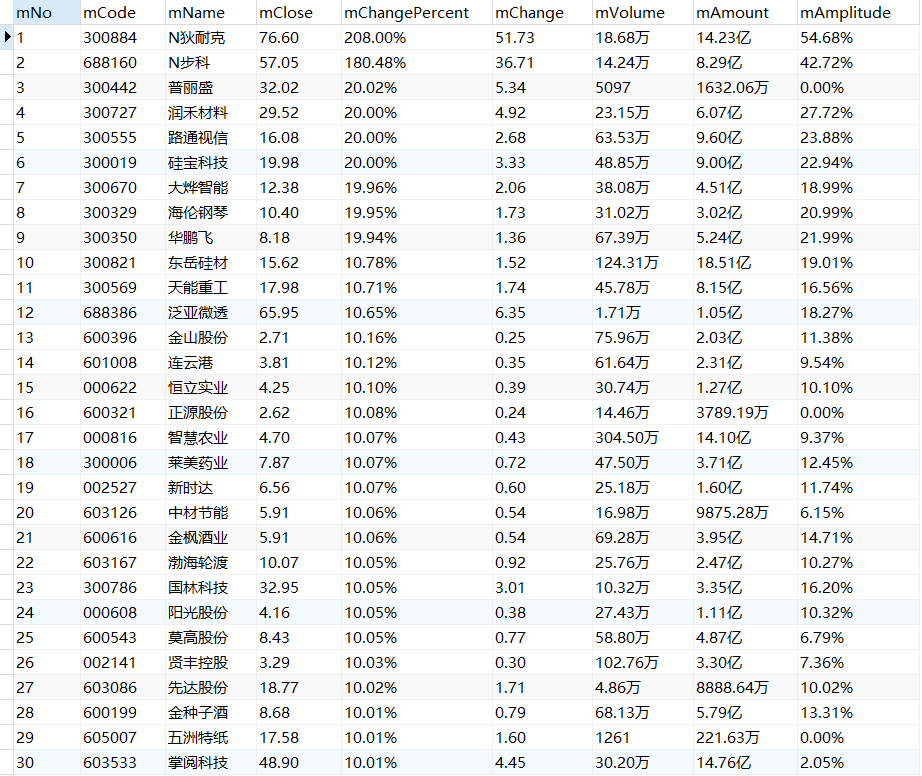
上证A股
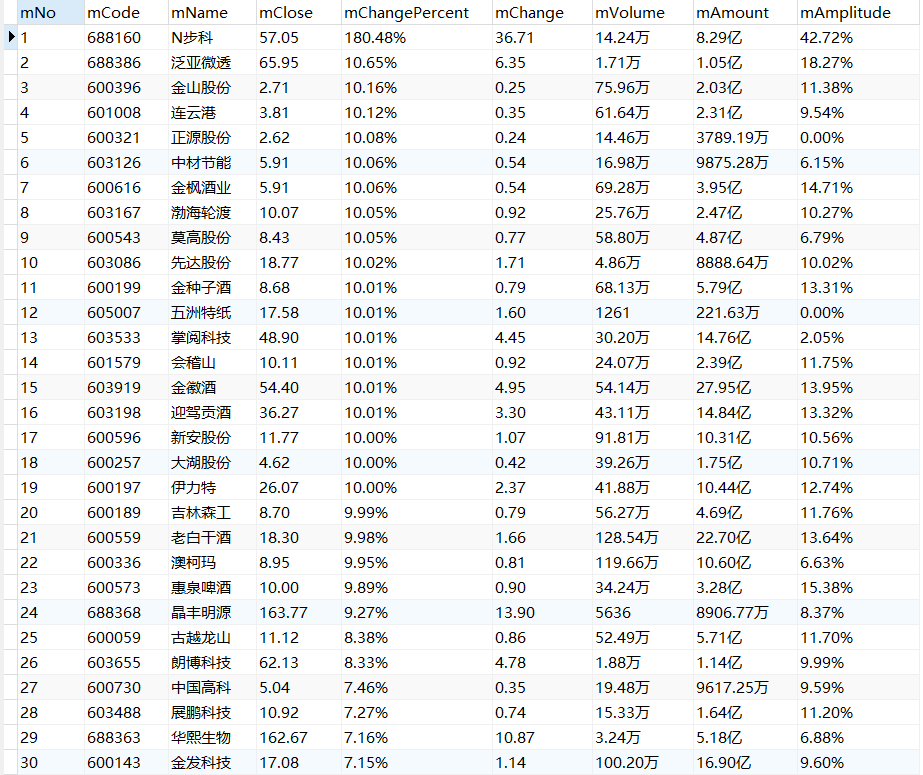
深证A股
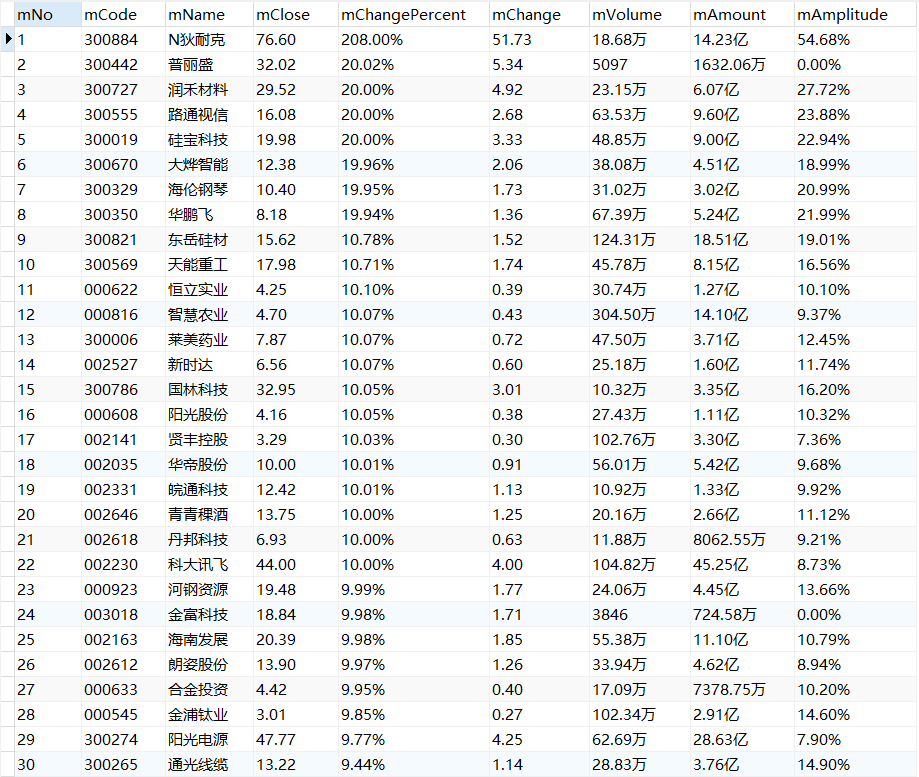
(2)心得体会
点击页面上某些元素时,可能会被广告或其他乱七八糟的东西遮挡,例如翻页时可用self.driver.execute_script('arguments[0].click()', nextPage)就很快乐。定位一些动态元素的时候,灵活运用position()和last()很不戳!
作业③:
(1)MOOCSelenium实验
-
要求:
- 熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
- 使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
-
候选网站:中国mooc网:https://www.icourse163.org
-
输出信息:MYSQL数据库存储和输出格式
Id cCourse cCollege cTeacher cTeam cCount cProcess cBrief 1 Python数据分析与展示 北京理工大学 嵩天 嵩天 470 2020年11月17日 ~ 2020年12月29日 “我们正步入一个数据或许比软件更重要的新时代。——Tim O'Reilly” 运用数据是精准刻画事物、呈现发展规律的主要手段,分析数据展示规律,把思想变得更精细! ——“弹指之间·享受创新”,通过8周学习,你将掌握利用Python语言表示、清洗、统计和展示数据的能力。 2......
代码
import pymysql
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import datetime
import time
import re
class MySpider:
def startup(self, url, key):
# 初始化谷歌浏览器
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
self.driver = webdriver.Chrome(chrome_options=chrome_options)
# 初始化变量
self.No = 0
self.curr = 1
# 初始化数据库
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="123456", db="mydb",
charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
try:
# 如果有表就删除
self.cursor.execute("drop table courses")
except:
pass
try:
# 建立新的表
sql = "create table courses (mNo varchar(256) primary key, mName varchar(256), mSchool varchar(256), mTeachers varchar(256), mCount varchar(256), mTerm varchar(256), mIntro varchar(1024))"
self.cursor.execute(sql)
except:
pass
except Exception as err:
print(err)
# 打开网站并搜索大数据
self.driver.get(url)
keyInput = self.driver.find_element_by_xpath("//input[@name='search']")
keyInput.send_keys(key)
keyInput.send_keys(Keys.ENTER)
# 获取总页数
WebDriverWait(self.driver, 1000).until(EC.presence_of_element_located((By.XPATH, "//div[@class='course-card-list-pager ga-click f-f0']/ul/li[last()-1]/a")))
self.final = int(self.driver.find_element_by_xpath("//div[@class='course-card-list-pager ga-click f-f0']/ul/li[last()-1]/a").text)
def closeup(self):
try:
# 关闭数据库、断开与谷歌浏览器连接
self.con.commit()
self.con.close()
self.driver.close()
except Exception as err:
print(err)
def insertdb(self, no, name, school, teachers, count, term, intro):
try:
sql = "insert into courses (mNo, mName, mSchool, mTeachers, mCount, mTerm, mIntro) values (%s, %s, %s, %s, %s, %s, %s)"
self.cursor.execute(sql, (no, name, school, teachers, count, term, intro))
except Exception as err:
print(err)
def processspider(self):
try:
search_handle = self.driver.current_window_handle # 获取搜索页面窗口
WebDriverWait(self.driver, 1000).until(EC.presence_of_all_elements_located((By.XPATH, "//div[@class='m-course-list']/div/div")))
divs = self.driver.find_elements_by_xpath("//div[@class='m-course-list']/div/div")
for div in divs:
# 点击该课程信息页面
course = div.find_element_by_xpath(".//div[@class='cnt f-pr']/a")
course.click()
# 将当前窗口切换为该课程信息窗口
handles = self.driver.window_handles
self.driver.switch_to_window(handles[1])
# 获取想要的数据
try:
name = self.driver.find_element_by_xpath("//span[@class='course-title f-ib f-vam']").text
except:
name = ""
try:
school = self.driver.find_element_by_class_name('u-img').get_attribute('alt')
except:
school = ""
try:
result = []
result = self.teacherJoin(result)
teachers = '、'.join(result) # 每个老师用'、'分隔开
except:
teachers = ""
try:
count = self.driver.find_element_by_class_name('course-enroll-info_course-enroll_price-enroll_enroll-count').text
count = re.compile(r"[0-9]*").findall(count)[3]
except:
count = ""
try:
term = self.driver.find_element_by_xpath("//div[@class='course-enroll-info_course-info_term-info_term-time']/span[position()=2]").text
except:
term = ""
try:
intro = self.driver.find_element_by_class_name('course-heading-intro_intro').text
except:
intro = ""
self.No += 1
no = str(self.No)
while len(no) < 4:
no = "0" + no
print(self.driver.current_url)
print(no, name, school, teachers, count)
self.insertdb(no, name, school, teachers, count, term, intro) # 将爬取到的数据写入数据库
# 关闭当前窗口并切回搜索页面窗口
self.driver.close()
self.driver.switch_to_window(search_handle)
# 翻页直到最后一页
if self.curr < self.final:
nextPage = self.driver.find_element_by_xpath("//li[@class='ux-pager_btn ux-pager_btn__next']/a")
nextPage.click()
self.curr += 1
time.sleep(1)
self.processspider()
except Exception as err:
print(err)
def teacherJoin(self, result):
teachers = self.driver.find_elements_by_xpath("//div[@class='um-list-slider_con_item']//h3[@class='f-fc3']")
# 将老师添加到列表中
for teacher in teachers:
result.append(teacher.text)
# 划到下一页
try:
slider_next = self.driver.find_element_by_xpath("//span[@class='u-icon-arrow-right-thin f-ib f-pa']")
slider_next.click()
self.teacherJoin(result)
except:
pass
return result
def executespider(self, url, key):
starttime = datetime.datetime.now()
print("Spider starting......")
self.startup(url, key)
print("Spider processing......")
self.processspider()
print("Spider closing......")
self.closeup()
print("Spider completed......")
endtime = datetime.datetime.now()
elapsed = (endtime - starttime).seconds # 计算爬虫耗时
print("Total ", elapsed, " seconds elapsed")
url = "https://www.icourse163.org/"
spider = MySpider()
while True:
print("1.爬取")
print("2.退出")
s = input("请选择(1,2):")
if s == "1":
spider.executespider(url, "大数据") # 爬取大数据相关的课程信息
continue
elif s == "2":
break
运行结果
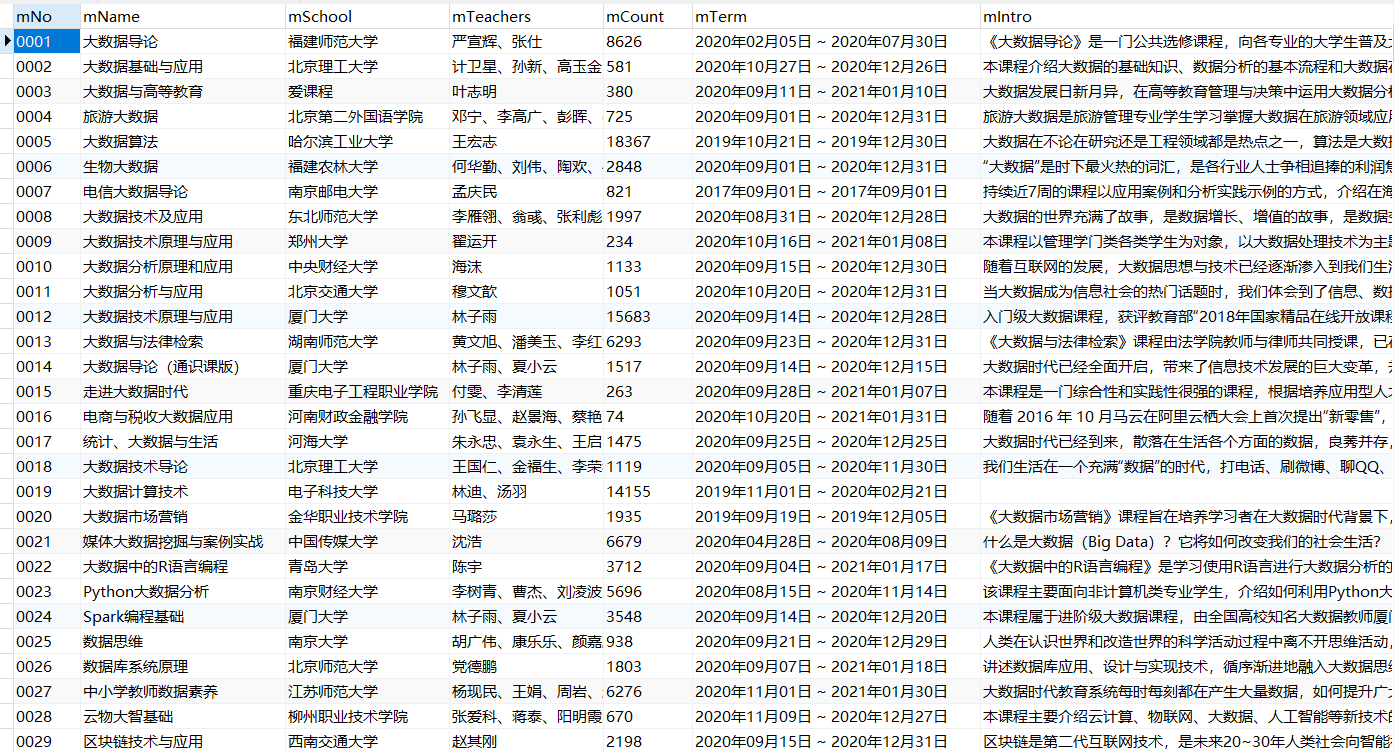
(2)心得体会
做了前两次实验这次就比较熟练了,除了爬得很慢好像其他的都还好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号