爬虫第三次作业
作业①:
(1)ImageDownloadThread实验
-
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.weather.com.cn)。分别使用单线程和多线程的方式爬取。
-
输出信息:
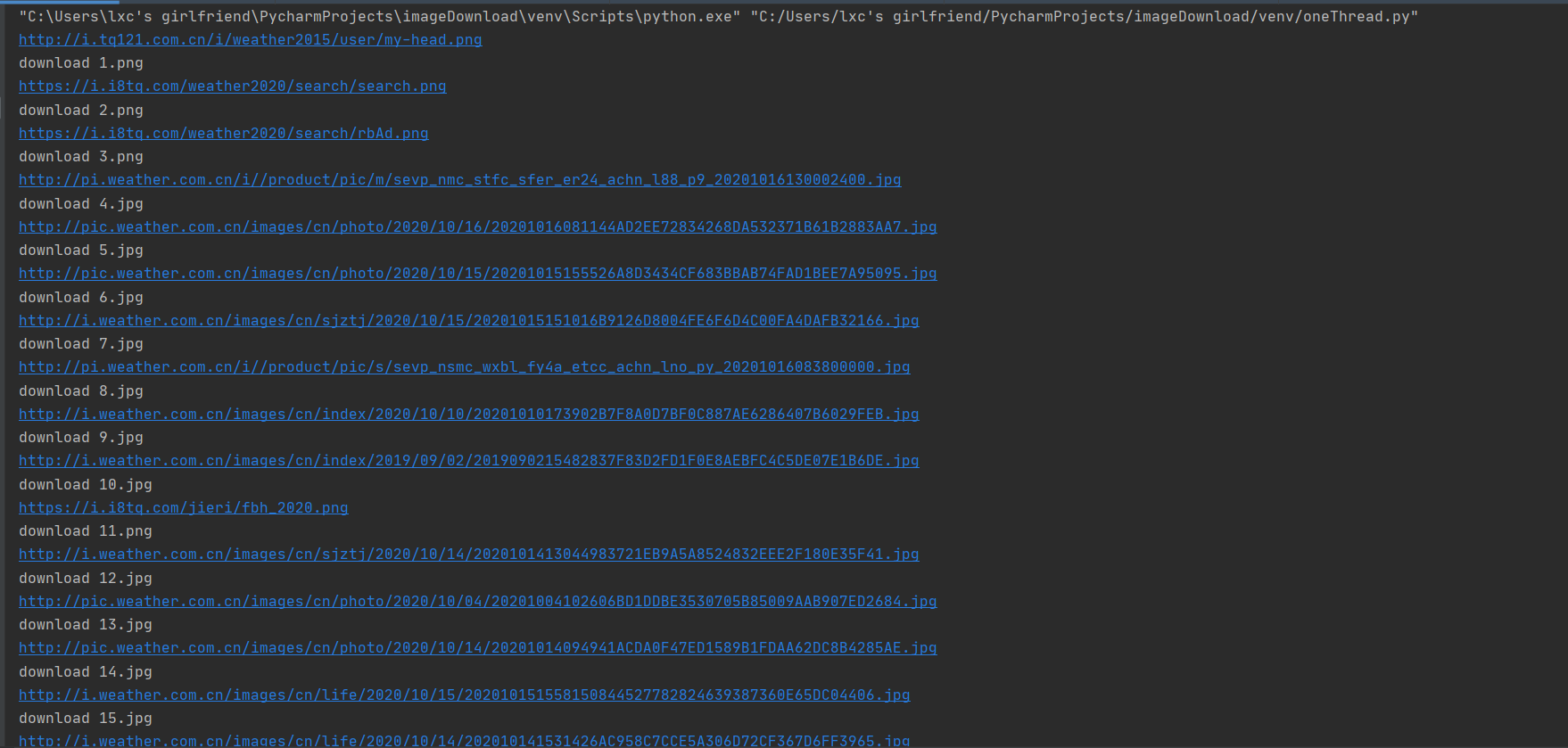
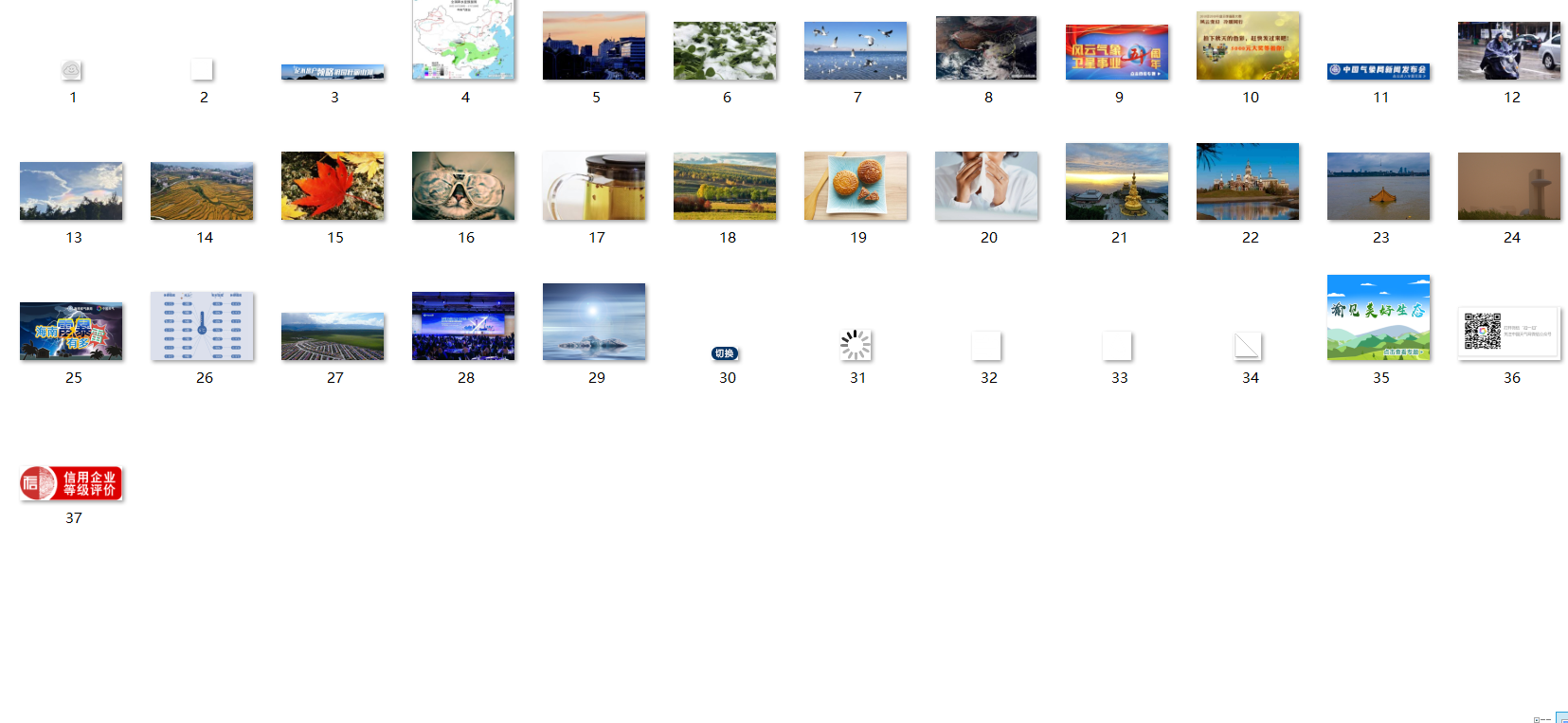
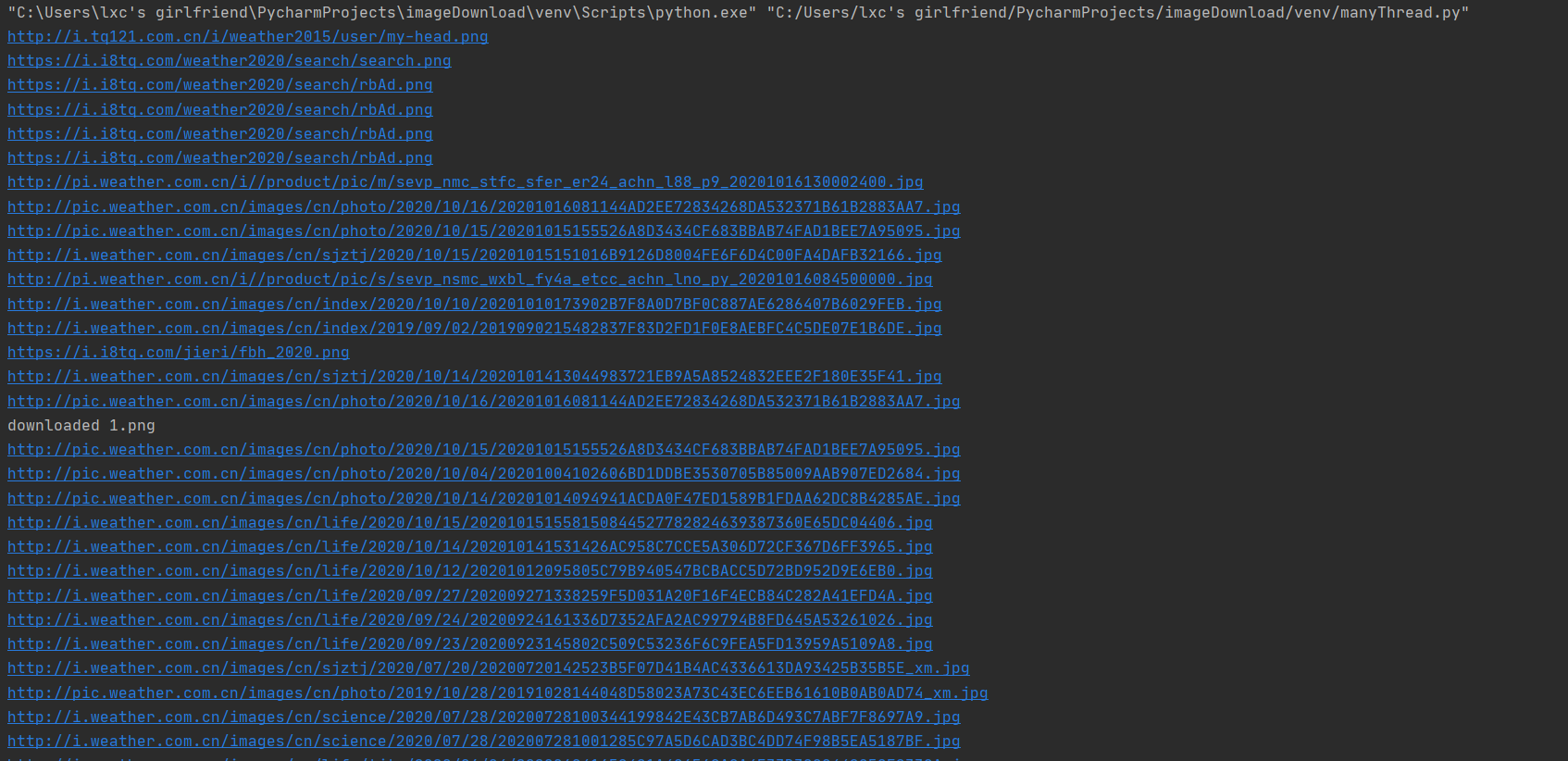
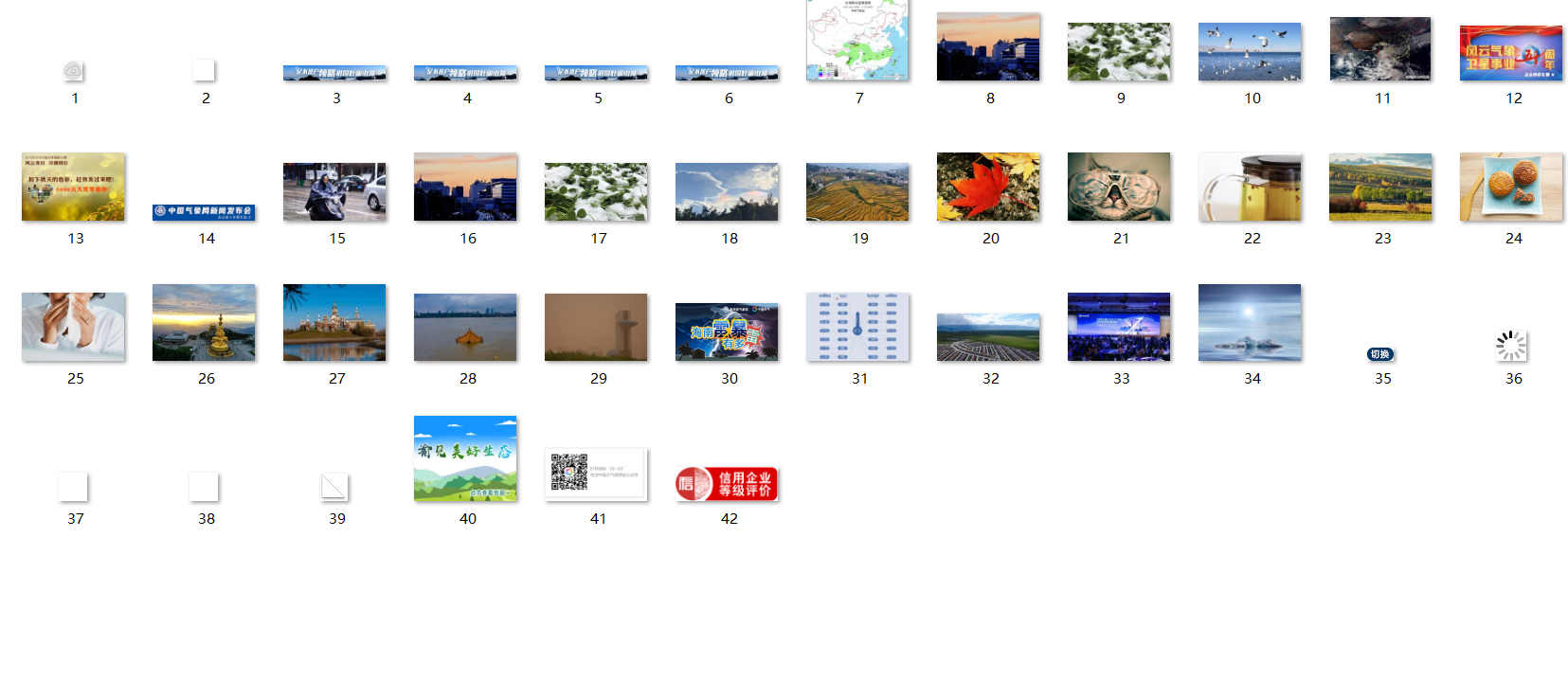
将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
单线程
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
def imageSpider(start_url):
try:
urls = []
req = urllib.request.Request(start_url,headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data,["utf-8"])
data = dammit.unicode_markup
soup = BeautifulSoup(data,"lxml")
images = soup.select("img") # 选择图像文件
for image in images:
try:
src = image["src"] # 图像文件的src地址
url = urllib.request.urljoin(start_url,src)
if url not in urls:
urls.append(url)
print(url)
download(url)
except Exception as err:
print(err)
except Exception as err:
print(err)
def download(url):
global count
try:
count += 1
if(url[len(url)-4] == "."):
ext = url[len(url)-4:]
else:
ext = ""
req = urllib.request.Request(url,headers=headers)
data = urllib.request.urlopen(req,timeout=100)
data = data.read()
# 将下载的图像文件写入本地文件夹
fobj = open("C:\\Users\\lxc's girlfriend\\Desktop\\images\\"+str(count)+ext,"wb")
fobj.write(data)
fobj.close()
print("download "+str(count)+ext)
except Exception as err:
print(err)
start_url = "http://www.weather.com.cn/"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36"}
count = 0
imageSpider(start_url)
多线程
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import threading
def imageSpider(start_url):
global threads
global count
try:
urls = []
req = urllib.request.Request(start_url,headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data,["utf-8"])
data = dammit.unicode_markup
soup = BeautifulSoup(data,"lxml")
images = soup.select("img") # 选择图像文件
for image in images:
try:
src = image["src"] # 图像文件的src地址
url = urllib.request.urljoin(start_url,src)
if url not in urls:
print(url)
count = count + 1
# 创建线程
T = threading.Thread(target=download, args=(url, count))
T.setDaemon(False)
T.start()
threads.append(T)
except Exception as err:
print(err)
except Exception as err:
print(err)
def download(url,count):
try:
if (url[len(url) - 4] == "."):
ext = url[len(url) - 4 :]
else:
ext = ""
req = urllib.request.Request(url,headers=headers)
data = urllib.request.urlopen(req,timeout=100)
data = data.read()
# 将下载的图像文件写入本地文件夹
fobj = open("C:\\Users\\lxc's girlfriend\\Desktop\\images\\" + str(count) + ext,"wb")
fobj.write(data)
fobj.close()
print("downloaded " + str(count) + ext)
except Exception as err:
print(err)
start_url = "http://www.weather.com.cn/"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36"}
count = 0
threads = []
imageSpider(start_url)
for t in threads:
t.join()
print("The End")
(2)心得体会
本次实验之前都有复现过,还挺简单。
作业②:
(1)ScrapyImageDownload实验
-
要求:使用scrapy框架复现作业①。
-
输出信息:
同作业①
import scrapy
class ImagedownloadItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
src = scrapy.Field()
pass
pipelines.py
import urllib.request
class ImagedownloadPipeline:
count = 0
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36"}
def process_item(self, item, spider):
try:
self.count += 1
src = item['src']
if src[len(src) - 4] == ".":
ext = src[len(src) - 4:]
else:
ext = ""
req = urllib.request.Request(src, headers=self.headers)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
# 将下载的图像文件写入本地文件夹
fobj = open("C:\\Users\\lxc's girlfriend\\Desktop\\images\\" + str(self.count) + ext, "wb")
fobj.write(data)
fobj.close()
print("downloaded "+str(self.count)+ext)
except Exception as err:
print(err)
return item
setting.py
BOT_NAME = 'imageDownload'
SPIDER_MODULES = ['imageDownload.spiders']
NEWSPIDER_MODULE = 'imageDownload.spiders'
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'imageDownload.pipelines.ImagedownloadPipeline': 300,
}
mySpider.py
import scrapy
from ..items import ImagedownloadItem
class MySpider(scrapy.Spider):
name = "mySpider"
start_urls = ["http://www.weather.com.cn/"]
def parse(self, response):
try:
data = response.body.decode()
selector = scrapy.Selector(text=data)
srcs = selector.xpath('//img/@src').extract() # 选择图像文件的src地址
for src in srcs:
print(src)
# 将提取出的src交由item处理
item = ImagedownloadItem()
item['src'] = src
yield item
except Exception as err:
print(err)
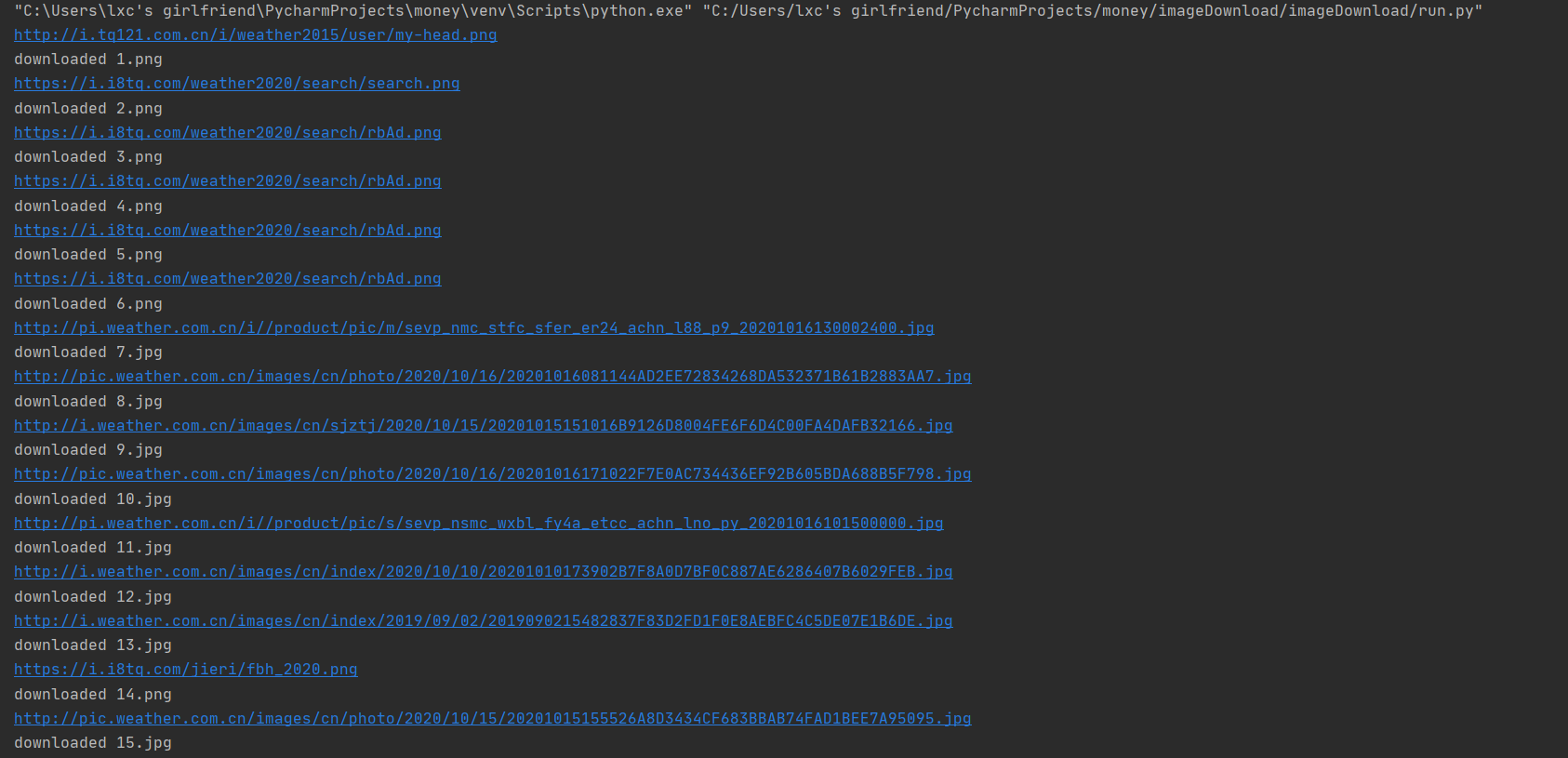
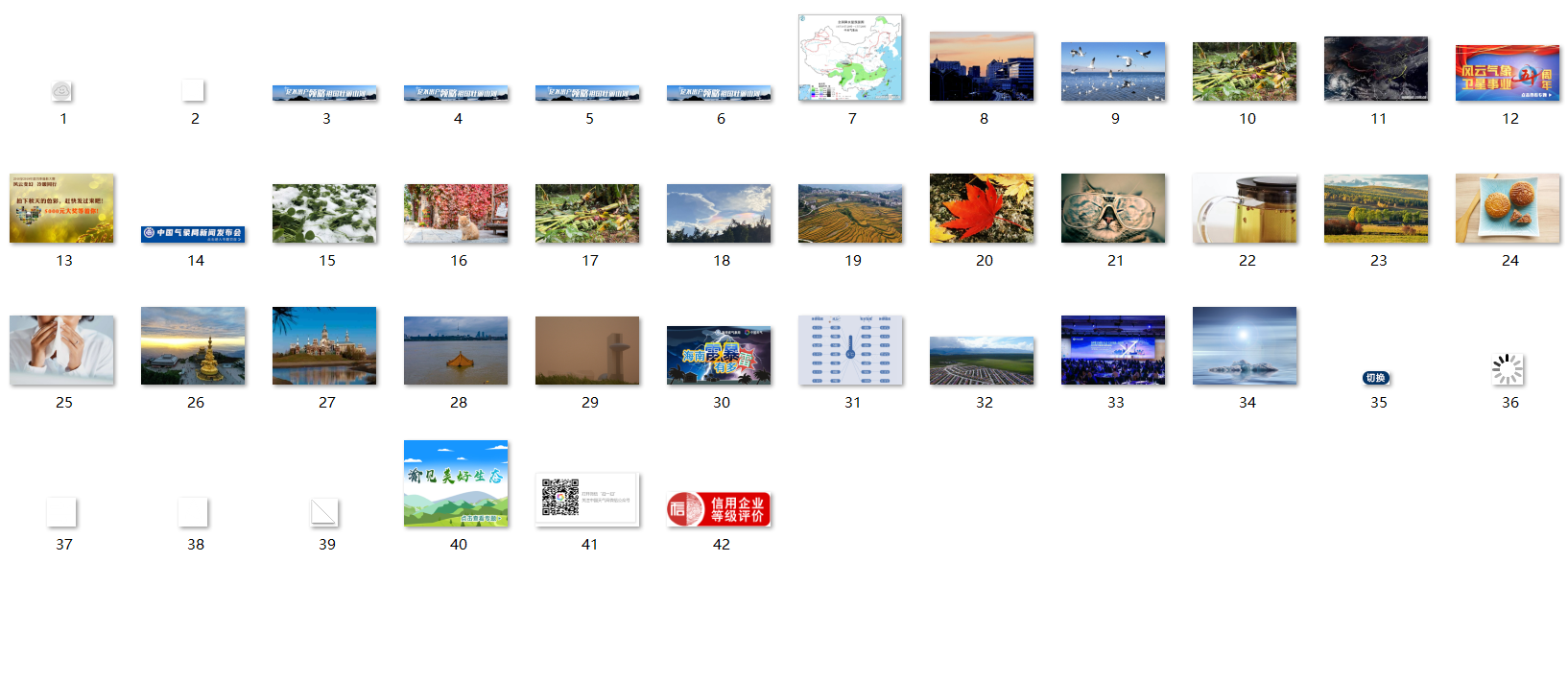
(2)心得体会
之前我们学习的是将数据处理的过程放在同一py文件下,而scrapy框架采用的是pipelines处理数据,在代码编写上没有太大的差异,只要搬过去就行了。
作业③:
(1)ScrapyStock实验
-
要求:使用scrapy框架爬取股票相关信息。
-
候选网站:东方财富网:https://www.eastmoney.com/
-
输出信息:
序号 股票代码 股票名称 最新报价 涨跌幅 涨跌额 成交量 成交额 振幅 最高 最低 今开 昨收 1 688093 N世华 28.47 62.22% 10.92 26.13万 7.6亿 22.34 32.0 28.08 30.2 17.55 2......
import scrapy
class EasymoneyItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
code = scrapy.Field()
name = scrapy.Field()
close = scrapy.Field()
changePercent = scrapy.Field()
change = scrapy.Field()
volume = scrapy.Field()
amount = scrapy.Field()
amplitude = scrapy.Field()
pass
pipelines.py
class EasymoneyPipeline():
count = 0
print("序号\t股票代码\t股票名称\t最新报价\t涨跌幅\t跌涨额\t成交量\t成交额\t振幅")
# 打印结果
def process_item(self, item,spider):
try:
self.count += 1
print(str(self.count)+"\t"+item['code']+"\t"+item['name']+"\t"+item['close']+"\t"+item['changePercent']+"\t"\
+item['change']+"\t"+item['volume']+"\t"+item['amount']+"\t"+item['amplitude'])
except Exception as err:
print(err)
return item
setting.py
BOT_NAME = 'easyMoney'
SPIDER_MODULES = ['easyMoney.spiders']
NEWSPIDER_MODULE = 'easyMoney.spiders'
ROBOTSTXT_OBEY = False # 要将其设为False否则无法打印
ITEM_PIPELINES = {
'easyMoney.pipelines.EasymoneyPipeline': 300,
}
mySpider.py
import scrapy
from ..items import EasymoneyItem
import re
import json
class mySpider(scrapy.Spider):
name = "mySpider"
start_urls = ["http://54.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124015380571520090935_1602750256400&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1602750256401"]
def parse(self, response):
try:
data = response.text
# 去除多余信息并转换成json
start = data.index('{')
data = json.loads(data[start:len(data) - 2])
if data['data']:
# 选择和处理数据格式
for stock in data['data']['diff']:
item = EasymoneyItem()
item["code"] = stock['f12']
item["name"] = stock['f14']
item["close"] = str(stock['f2'])
item["changePercent"] = stock['f3'] if stock['f3'] == "-" else str(stock['f3'])+'%'
item["change"] = str(stock['f4'])
item["volume"] = str(stock['f5'])
item["amount"] = str(stock['f6'])
item["amplitude"] = str(stock['f7']) if stock['f7'] == "-" else str(stock['f7'])+'%'
yield item
# 查询当前页面并翻页
pn = re.compile("pn=[0-9]*").findall(response.url)[0]
page = int(pn[3:])
url = response.url.replace("pn="+str(page), "pn="+str(page+1))
yield scrapy.Request(url=url, callback=self.parse)
except Exception as err:
print(err)
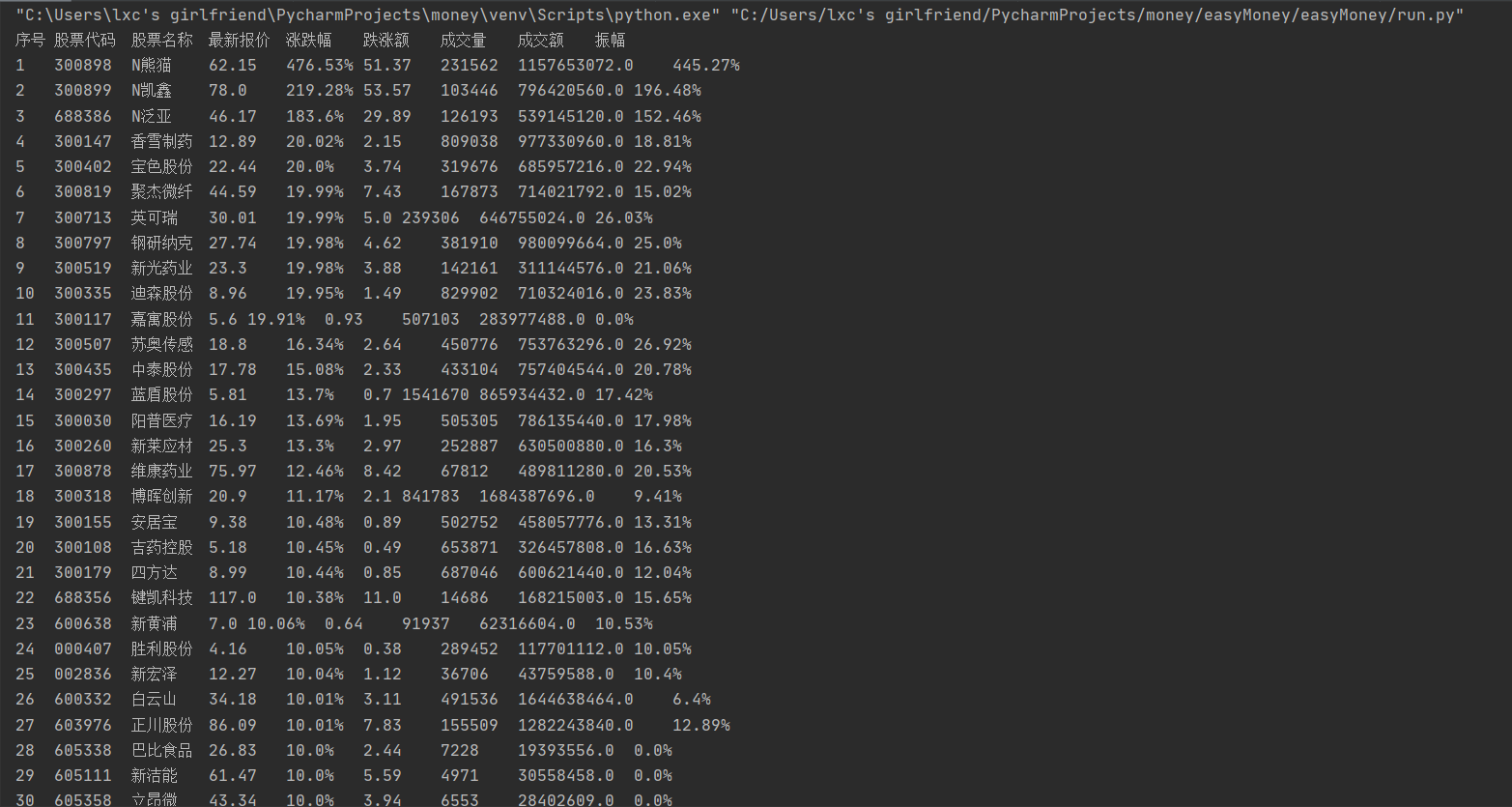
(2)心得体会
使用scrapy框架爬取数据时,如果想要在屏幕上打印出结果,🆘🆘🆘一定要记得在setting.py中将ROBOTSTXT_OBEY设为False🆘🆘🆘
这次实验还学会了用json库处理数据,但在使用json对象前要先把{}以外的多余信息去除,然后将字符串用loads()方法转换为json对象。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号