爬虫第二次作业
作业①:
(1)WeatherForecast实验
要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
输出信息:
| 序号 | 地区 | 日期 | 天气信息 | 温度 |
|---|---|---|---|---|
| 1 | 北京 | 7日(今天) | 晴间多云,北部山区有阵雨或雷阵雨转晴转多云 | 31℃/17℃ |
| 2 | 北京 | 8日(明天) | 多云转晴,北部地区有分散阵雨或雷阵雨转晴 | 34℃/20℃ |
| 3 | 北京 | 9日(后台) | 晴转多云 | 36℃/22℃ |
| 4 | 北京 | 10日(周六) | 阴转阵雨 | 30℃/19℃ |
| 5 | 北京 | 11日(周日) | 阵雨 | 27℃/18℃ |
| 6...... |
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import sqlite3
class WeatherDB:
# 打开weathers数据库
def openDB(self):
self.con = sqlite3.connect("weathers.db")
self.cursor = self.con.cursor()
try:
self.cursor.execute("create table weathers (wCity varchar(16),wDate varchar (16),wWeather varchar (14),wTemp varchar (32),constraint pk_weather primary key (wCity,wDate))")
except:
self.cursor.execute("delete from weathers")
# 关闭数据库
def closeDB(self):
self.con.commit()
self.con.close()
# 插入数据
def insert(self,city,date,weather,temp):
try:
self.cursor.execute("insert into weathers (wCity,wDate,wWeather,wTemp) values (?,?,?,?)",(city,date,weather,temp))
except Exception as err:
print(err)
# 展示数据
def show(self):
self.cursor.execute("select * from weathers")
rows = self.cursor.fetchall()
print("%-16s%-16s%-32s%-16s"%("city","date","weather","temp"))
for row in rows:
print("%-16s%-16s%-32s%-16s"%(row[0],row[1],row[2],row[3]))
class WeatherForecast:
def __init__(self):
self.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36"}
self.cityCode = {"北京":"101010100","上海":"101020100","广州":"101280101","深圳":"101280601"}
def forecastCity(self,city):
if city not in self.cityCode.keys():
print(city + " code cannot be found")
return
url = "http://www.weather.com.cn/weather/"+self.cityCode[city]+".shtml"
try:
req = urllib.request.Request(url,headers=self.headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data,["utf-8"])
data = dammit.unicode_markup
soup = BeautifulSoup(data,"lxml")
lis = soup.select("ul[class='t clearfix'] li") # 选中未来七天天气预报
for li in lis:
try:
date = li.select('h1')[0].text #选中日期
weather = li.select('p[class="wea"]')[0].text #选中天气信息
temp = li.select('p[class="tem"] span')[0].text + "/" + li.select('p[class="tem"] i')[0].text #选中最高和最低温
print(city,date,weather,temp)
self.db.insert(city,date,weather,temp) # 将爬取到的数据存入weathers数据库中
except Exception as err:
print(err)
except Exception as err:
print(err)
def process(self,cities):
self.db = WeatherDB()
self.db.openDB()
# 爬取每个城市未来七天天气预报并保存数据库
for city in cities:
self.forecastCity(city)
self.db.show()
self.db.closeDB()
ws = WeatherForecast() # 创建WeatherForecast对象
ws.process(["北京","上海","广州","深圳"]) # 对指定城市集进行爬取和保存入数据库的操作
print("completed")

(2)心得体会
本次实验主要考察如何将爬取到的数据存入数据库中及数据库的基本操作,看看例题代码就能大概了解了。
作业②:
(1)StockQuotes实验
要求:用requests和BeautifulSoup库方法定向爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
新浪股票:http://finance.sina.com.cn/stock/
- 技巧:在谷歌浏览器中进入F12调试模式进行抓包,查找股票列表加载使用的url,并分析api返回的值,并根据所要求的参数可适当更改api的请求参数。根据URL可观察请求的参数f1、f2可获取不同的数值,根据情况可删减请求的参数。
参考链接:https://zhuanlan.zhihu.com/p/50099084
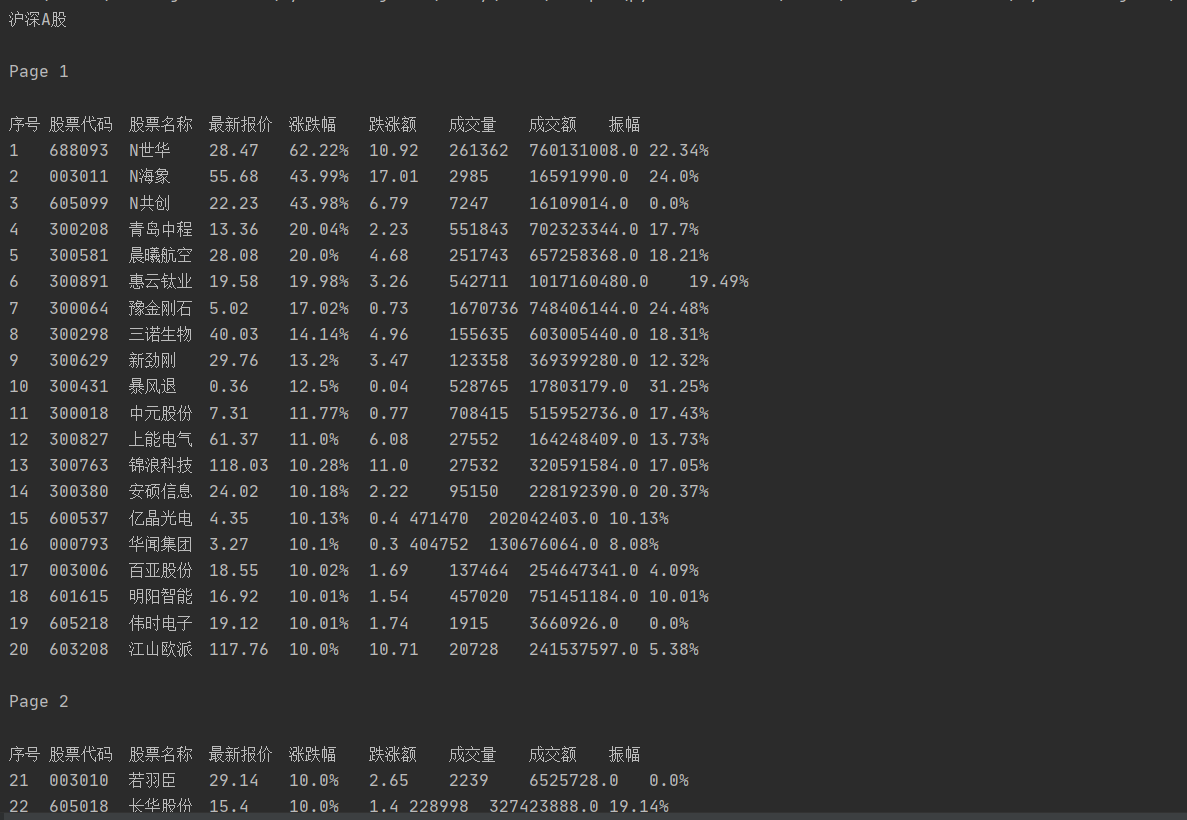
- 输出信息:
| 序号 | 股票代码 | 股票名称 | 最新报价 | 涨跌幅 | 涨跌额 | 成交量 | 成交额 | 振幅 | 最高 | 最低 | 今开 | 昨收 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 688093 | N世华 | 28.47 | 62.22% | 10.92 | 26.13万 | 7.6亿 | 22.34 | 32.0 | 28.08 | 30.2 | 17.55 |
| 2...... |
import requests
import re
def getHtml(fs,page):
url = "http://48.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112408904583834025714_1601430401745&pn="+str(page)+\
"&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs="+fs+\
"&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1601430401746"
data = requests.get(url)
return data
def getOnePageStock(fs,page):
data = getHtml(fs,page)
# 选中需要打印的数据
f12 = '"f12":".*?"'
f14 = '"f14":".*?"'
f2 = '"f2":[0-9]*\.?[0-9]*'
f3 = '"f3":[0-9]*\.?[0-9]*'
f4 = '"f4":[0-9]*\.?[0-9]*'
f5 = '"f5":[0-9]*'
f6 = '"f6":[0-9]*\.?[0-9]*'
f7 = '"f7":[0-9]*\.?[0-9]*'
code = re.compile(f12, re.S).findall(data.text)
name = re.compile(f14, re.S).findall(data.text)
close = re.compile(f2, re.S).findall(data.text)
changePercent = re.compile(f3, re.S).findall(data.text)
change = re.compile(f4, re.S).findall(data.text)
volume = re.compile(f5, re.S).findall(data.text)
amount = re.compile(f6, re.S).findall(data.text)
amplitude = re.compile(f7, re.S).findall(data.text)
# 处理数据格式并打印
for i in range(len(code)):
code[i] = code[i].split(":")[1].replace('"',"")
name[i] = name[i].split(":")[1].replace('"',"")
close[i] = str(close[i].split(":")[1])
changePercent[i] = str(changePercent[i].split(":")[1])+"%"
change[i] = str(change[i].split(":")[1])
volume[i] = str(volume[i].split(":")[1])
amount[i] = str(amount[i].split(":")[1])
amplitude[i] = str(amplitude[i].split(":")[1])+"%"
if close[i] == "":
close[i] = "-"
if changePercent[i] == "%":
changePercent[i] = "-"
if change[i] == "":
change[i] = "-"
if volume[i] == "":
volume[i] = "-"
if amount[i] == "":
amount[i] = "-"
if amplitude[i] == "%":
amplitude[i] = "-"
print(str(20*(page-1)+i+1)+"\t"+code[i]+"\t"+name[i]+"\t"+close[i]+"\t"+changePercent[i]+"\t"+change[i]+"\t"+\
volume[i]+"\t"+amount[i]+"\t"+amplitude[i])
fs = {"沪深A股":"m:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23","上证A股":"m:1+t:2,m:1+t:23","深证A股":"m:0+t:6,m:0+t:13,m:0+t:80",\
"新股":"m:0+f:8,m:1+f:8","中小板":"m:0+t:13","创业板":"m:0+t:80","科创板":"m:1+t:23","沪股通":"b:BK0707","深股通":"b:BK0804",\
"B股":"m:0+t:7,m:1+t:3","上证AB股比价":"m:1+b:BK0498","深证AB股比价":"m:0+b:BK0498","风险警示板":"m:0+f:4,m:1+f:4","两网及退市":"m:0+s:3"}
# 对不同模块内的股票信息进行操作
for i in fs.keys():
page = 1
print(i)
print()
# 同一模块内翻页
while True:
data = getHtml(fs[i],page)
data1 = getHtml(fs[i],page+1)
data = re.compile('"diff":\[(.*?)\]').findall(data.text)
data1 = re.compile('"diff":\[(.*?)\]').findall(data1.text)
if data != data1: # 判断是否循环到最后一页
print("Page "+str(page))
print()
print("序号\t股票代码\t股票名称\t最新报价\t涨跌幅\t跌涨额\t成交量\t成交额\t振幅")
getOnePageStock(fs[i],page) # 对指定模块和页码进行操作
print()
else:
break
page += 1
(2)心得体会
本次实验对我来说较难的部分是如何运用正则表达式获取数据,又学到一种方法,不错子!同时也更深入了解如何跳转页面了,牛鼻子!
作业③:
(1)FindingStock实验
要求:根据自选3位数+学号后3位选取股票,获取印股票信息。抓包方法同作②。
候选网站:东方财富网:https://www.eastmoney.com/
新浪股票:http://finance.sina.com.cn/stock/
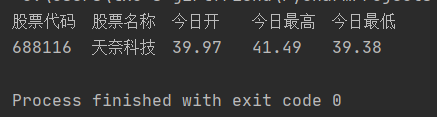
- 输出信息:
| 股票代码号 | 股票名称 | 今日开 | 今日最高 | 今日最低 |
|---|---|---|---|---|
| 605006 | 山东玻纤 | 9.04 | 8.58 | 8.13 |
import requests
import re
def getHtml(fs,page):
url = "http://48.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112408904583834025714_1601430401745&pn="+str(page)+\
"&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs="+fs+\
"&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1601430401746"
data = requests.get(url)
return data
def getOnePageStock(fs,page):
data = getHtml(fs,page)
# 选中需要打印的数据
f12 = '"f12":".*?"'
f14 = '"f14":".*?"'
f17 = '"f17":[0-9]*\.?[0-9]*'
f15 = '"f15":[0-9]*\.?[0-9]*'
f16 = '"f16":[0-9]*\.?[0-9]*'
code = re.compile(f12, re.S).findall(data.text)
name = re.compile(f14, re.S).findall(data.text)
open = re.compile(f17, re.S).findall(data.text)
high = re.compile(f15, re.S).findall(data.text)
low = re.compile(f16, re.S).findall(data.text)
# 处理数据格式并打印
for i in range(len(code)):
code[i] = code[i].split(":")[1].replace('"', "")
name[i] = name[i].split(":")[1].replace('"', "")
open[i] = open[i].split(":")[1]
high[i] = high[i].split(":")[1]
low[i] = low[i].split(":")[1]
# 查找股票代码为688116的股票的信息并打印
if code[i] == "688116":
print("股票代码\t股票名称\t今日开\t今日最高\t今日最低")
print(code[i] + "\t" + name[i] + "\t" + open[i] + "\t" + high[i] + "\t" + low[i] + "\t")
return 1 # 若已查找到则返回1
fs = {"沪深A股":"m:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23","上证A股":"m:1+t:2,m:1+t:23","深证A股":"m:0+t:6,m:0+t:13,m:0+t:80",\
"新股":"m:0+f:8,m:1+f:8","中小板":"m:0+t:13","创业板":"m:0+t:80","科创板":"m:1+t:23","沪股通":"b:BK0707","深股通":"b:BK0804",\
"B股":"m:0+t:7,m:1+t:3","上证AB股比价":"m:1+b:BK0498","深证AB股比价":"m:0+b:BK0498","风险警示板":"m:0+f:4,m:1+f:4","两网及退市":"m:0+s:3"}
# 对不同模块内的股票信息进行操作
for i in fs.keys():
page = 1
# 同一模块内翻页
while True:
data = getHtml(fs[i],page)
data1 = getHtml(fs[i],page+1)
data = re.compile('"diff":\[(.*?)\]').findall(data.text)
data1 = re.compile('"diff":\[(.*?)\]').findall(data1.text)
if data != data1: # 判断是否循环到最后一页
flag = getOnePageStock(fs[i],page)
# 当flag == 1时,代表已查找到想要的数据可停止查找
if flag == 1:
break
else:
break
page += 1
if flag == 1:
break
# flag != 1时,没找到想要的信息
if flag != 1:
print("Can't find")
(2)心得体会
本次实验是作业②的衔接,没有太大难度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号