梯度算法之梯度上升和梯度下降
梯度算法之梯度上升和梯度下降
- 方向导数
当讨论函数沿任意方向的变化率时,也就引出了方向导数的定义,即:某一点在某一趋近方向上的导数值。
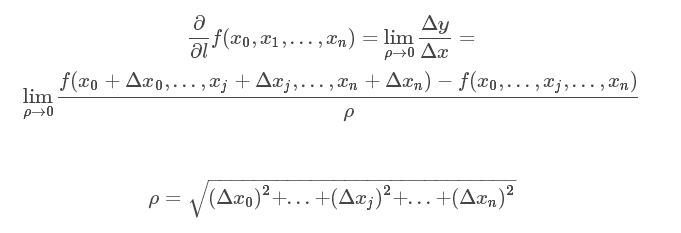
导数和偏导数的定义中,均是沿坐标轴正方向讨论函数的变化率。那么当讨论函数沿任意方向的变化率时,也就引出了方向导数的定义,即:某一点在某一趋近方向上的导数值。
通俗的解释是: 我们不仅要知道函数在坐标轴正方向上的变化率(即偏导数),而且还要设法求得函数在其他特定方向上的变化率。而方向导数就是函数在其他特定方向上的变化率。
- 梯度
![]()
![]()


函数在某一点的梯度是这样一个向量,它的方向与取得最大方向导数的方向一致,而它的模为方向导数的最大值。
注意点:
1)梯度是一个向量
2)梯度的方向是最大方向导数的方向
3)梯度的值是最大方向导数的值
- 梯度下降与梯度上升
在机器学习算法中,在最小化损失函数时,可以通过梯度下降思想来求得最小化的损失函数和对应的参数值,反过来,如果要求最大化的损失函数,可以通过梯度上升思想来求取。
梯度下降
关于梯度下降的几个概念

梯度下降的代数方法描述


梯度下降的矩阵方式描述


梯度上升
梯度上升和梯度下降的分析方式是一致的,只不过把 θθ 的更新中 减号变为加号。
梯度下降的算法优化
-
算法的步长选择。在前面的算法描述中,我提到取步长为1,但是实际上取值取决于数据样本,可以多取一些值,从大到小,分别运行算法,看看迭代效果,如果损失函数在变小,说明取值有效,否则要增大步长。前面说了。步长太大,会导致迭代过快,甚至有可能错过最优解。步长太小,迭代速度太慢,很长时间算法都不能结束。所以算法的步长需要多次运行后才能得到一个较为优的值。
-
算法参数的初始值选择。 初始值不同,获得的最小值也有可能不同,因此梯度下降求得的只是局部最小值;当然如果损失函数是凸函数则一定是最优解。由于有局部最优解的风险,需要多次用不同初始值运行算法,关键损失函数的最小值,选择损失函数最小化的初值。
-
归一化。由于样本不同特征的取值范围不一样,可能导致迭代很慢,为了减少特征取值的影响,可以对特征数据归一化,也就是对于每个特征x,求出它的均值 x¯和标准差std(x),然后转化为:
![]()
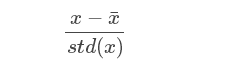
这样特征的新期望为0,新方差为1,迭代次数可以大大加快。
梯度算法之批量梯度下降,随机梯度下降和小批量梯度下降
在机器学习领域,体梯度下降算法分为三种
- 批量梯度下降算法(BGD,Batch gradient descent algorithm)
- 随机梯度下降算法(SGD,Stochastic gradient descent algorithm)
- 小批量梯度下降算法(MBGD,Mini-batch gradient descent algorithm)
批量梯度下降算法
BGD是最原始的梯度下降算法,每一次迭代使用全部的样本,即权重的迭代公式中(公式中用θ代替θi),
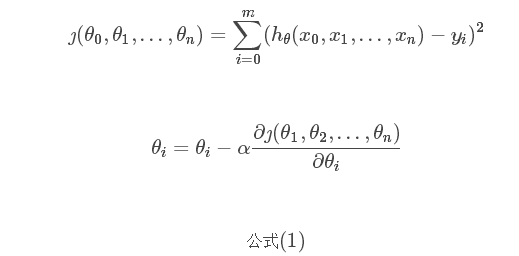
这里的m代表所有的样本,表示从第一个样本遍历到最后一个样本。
特点:
- 能达到全局最优解,易于并行实现
- 当样本数目很多时,训练过程缓慢
随机梯度下降算法
SGD的思想是更新每一个参数时都使用一个样本来进行更新,即公式(1)中m为1。每次更新参数都只使用一个样本,进行多次更新。这样在样本量很大的情况下,可能只用到其中的一部分样本就能得到最优解了。
但是,SGD伴随的一个问题是噪音较BGD要多,使得SGD并不是每次迭代都向着整体最优化方向。
特点:
- 训练速度快
- 准确度下降,并不是最优解,不易于并行实现
小批量梯度下降算法
MBGD的算法思想就是在更新每一参数时都使用一部分样本来进行更新,也就是公式(1)中的m的值大于1小于所有样本的数量。
相对于随机梯度下降,Mini-batch梯度下降降低了收敛波动性,即降低了参数更新的方差,使得更新更加稳定。相对于批量梯度下降,其提高了每次学习的速度。并且其不用担心内存瓶颈从而可以利用矩阵运算进行高效计算。一般而言每次更新随机选择[50,256]个样本进行学习,但是也要根据具体问题而选择,实践中可以进行多次试验,选择一个更新速度与更次次数都较适合的样本数。mini-batch梯度下降可以保证收敛性,常用于神经网络中。
补充
在样本量较小的情况下,可以使用批量梯度下降算法,样本量较大的情况或者线上,可以使用随机梯度下降算法或者小批量梯度下降算法。
在机器学习中的无约束优化算法,除了梯度下降以外,还有前面提到的最小二乘法,此外还有牛顿法和拟牛顿法。
梯度下降法和最小二乘法相比,梯度下降法需要选择步长,而最小二乘法不需要。梯度下降法是迭代求解,最小二乘法是计算解析解。如果样本量不算很大,且存在解析解,最小二乘法比起梯度下降法要有优势,计算速度很快。但是如果样本量很大,用最小二乘法由于需要求一个超级大的逆矩阵,这时就很难或者很慢才能求解解析解了,使用迭代的梯度下降法比较有优势。
梯度下降法和牛顿法/拟牛顿法相比,两者都是迭代求解,不过梯度下降法是梯度求解,而牛顿法/拟牛顿法是用二阶的海森矩阵的逆矩阵或伪逆矩阵求解。相对而言,使用牛顿法/拟牛顿法收敛更快。但是每次迭代的时间比梯度下降法长。
参考资料:
https://blog.csdn.net/gamer_gyt/article/details/78797667
https://blog.csdn.net/gamer_gyt/article/details/78806156


 浙公网安备 33010602011771号
浙公网安备 33010602011771号