CO
网站
C语言-汇编转换
CSAPP官方课程
cmu官方配套网站
课的lab
深入浅出计算机组成原理博客
系统概述
硬件
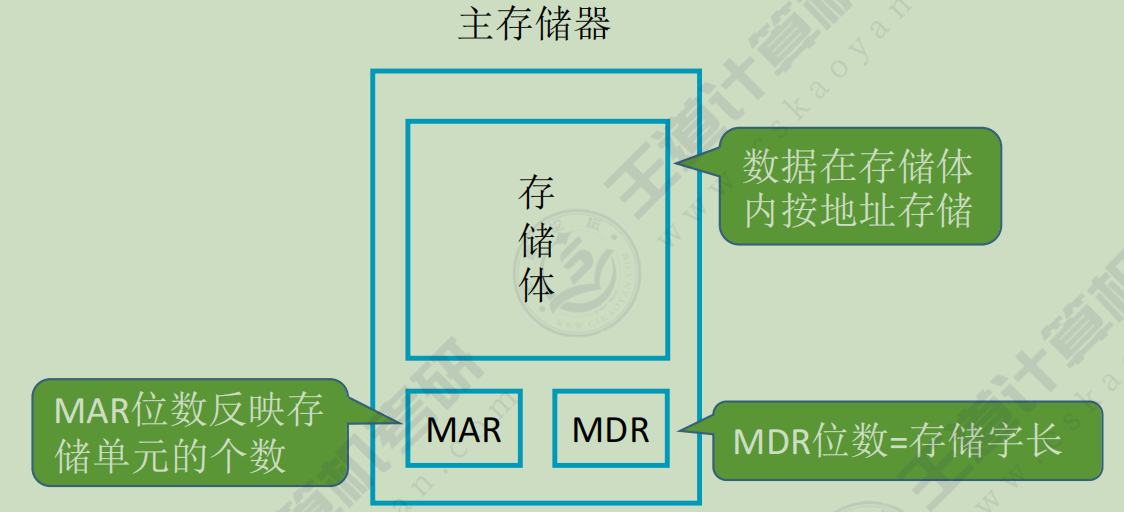
主存储器


存储单元:每个存储单元存放一串二进制代码
存储字(word):存储单元中二进制代码的组合
存储字长:存储单元中二进制代码的位数
存储元:即存储二进制的电子元件,每个存储元可存1bit
运算器

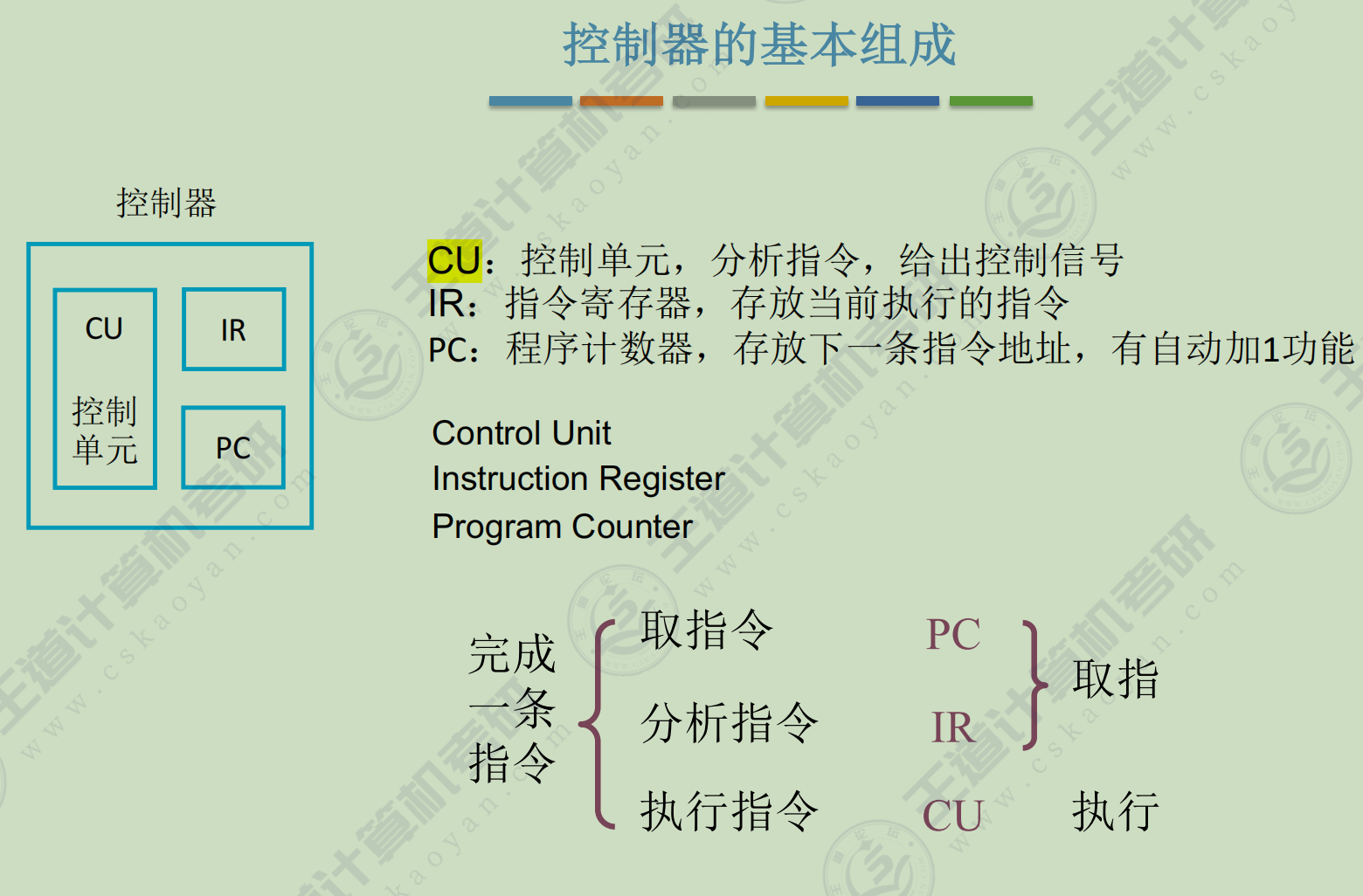
控制器
机械字长
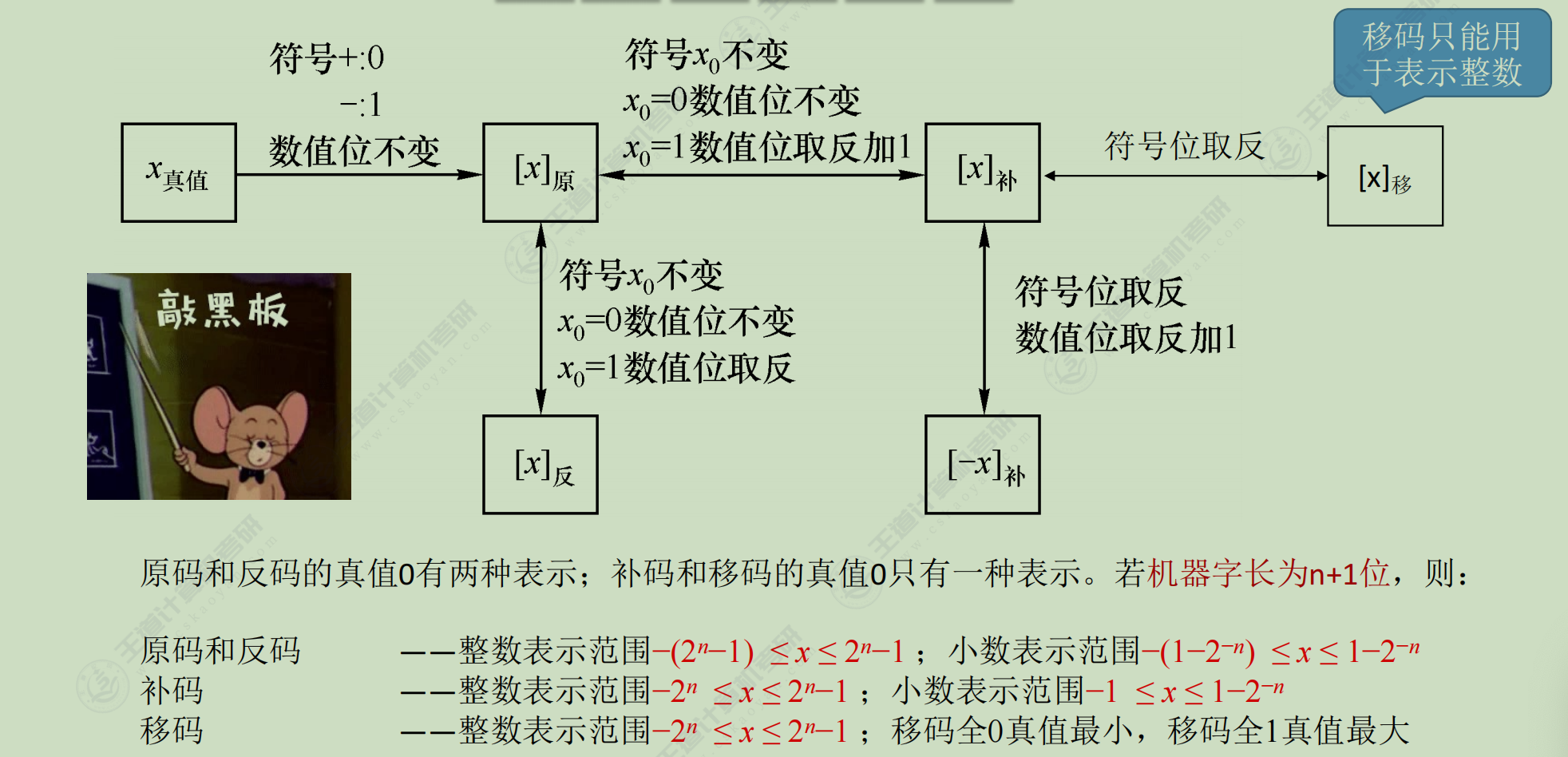
数据的表示和运算
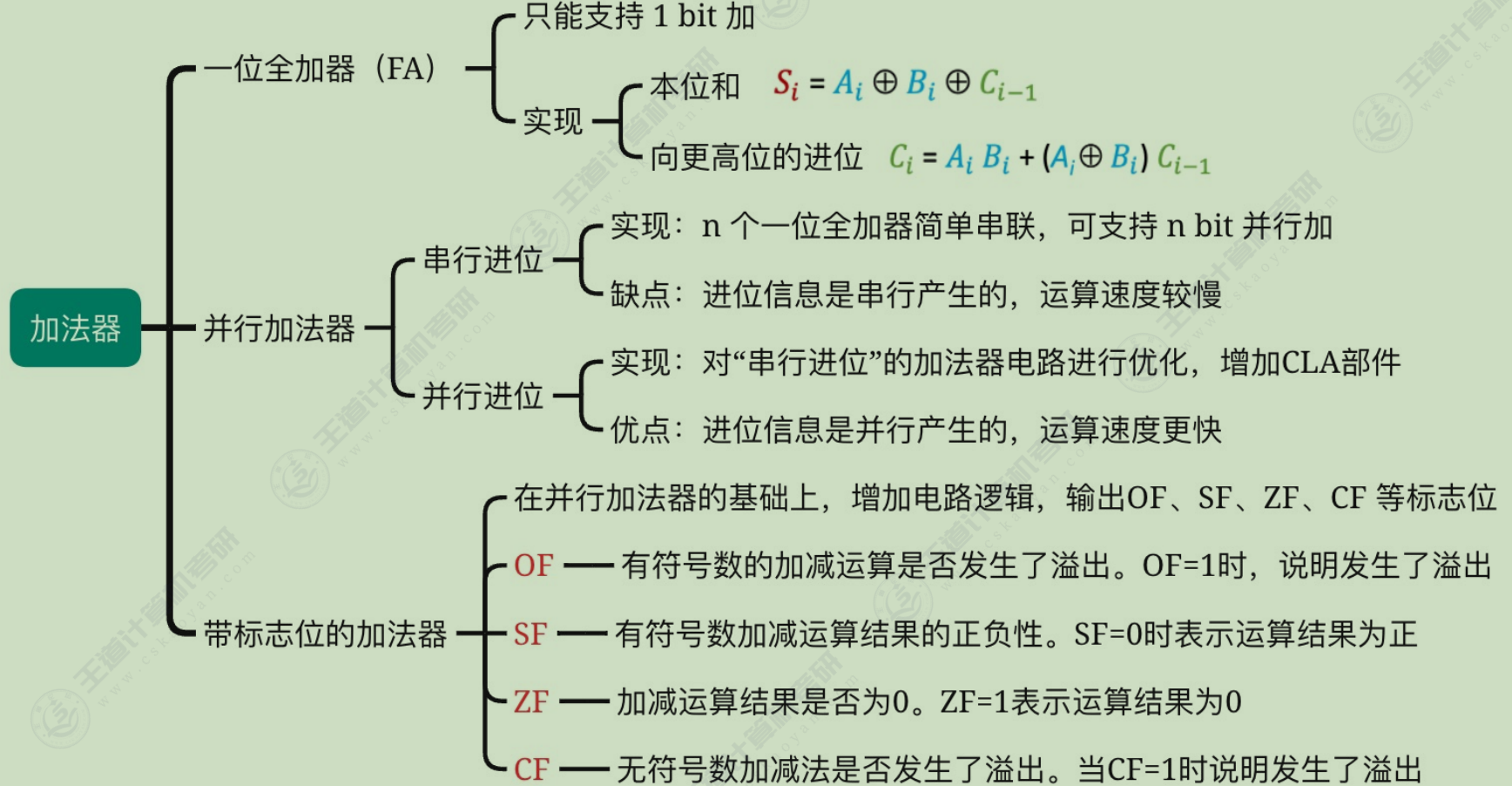
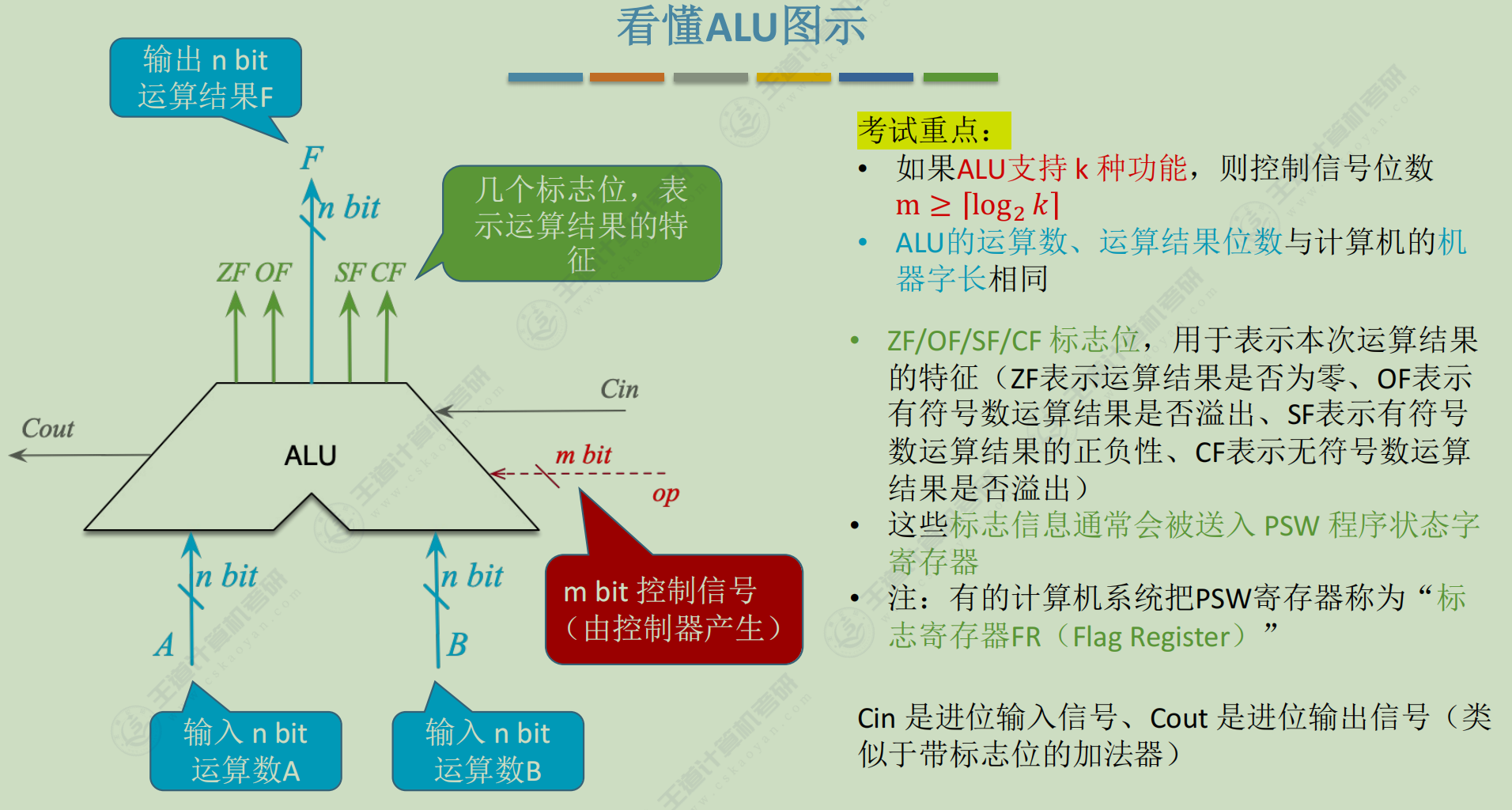
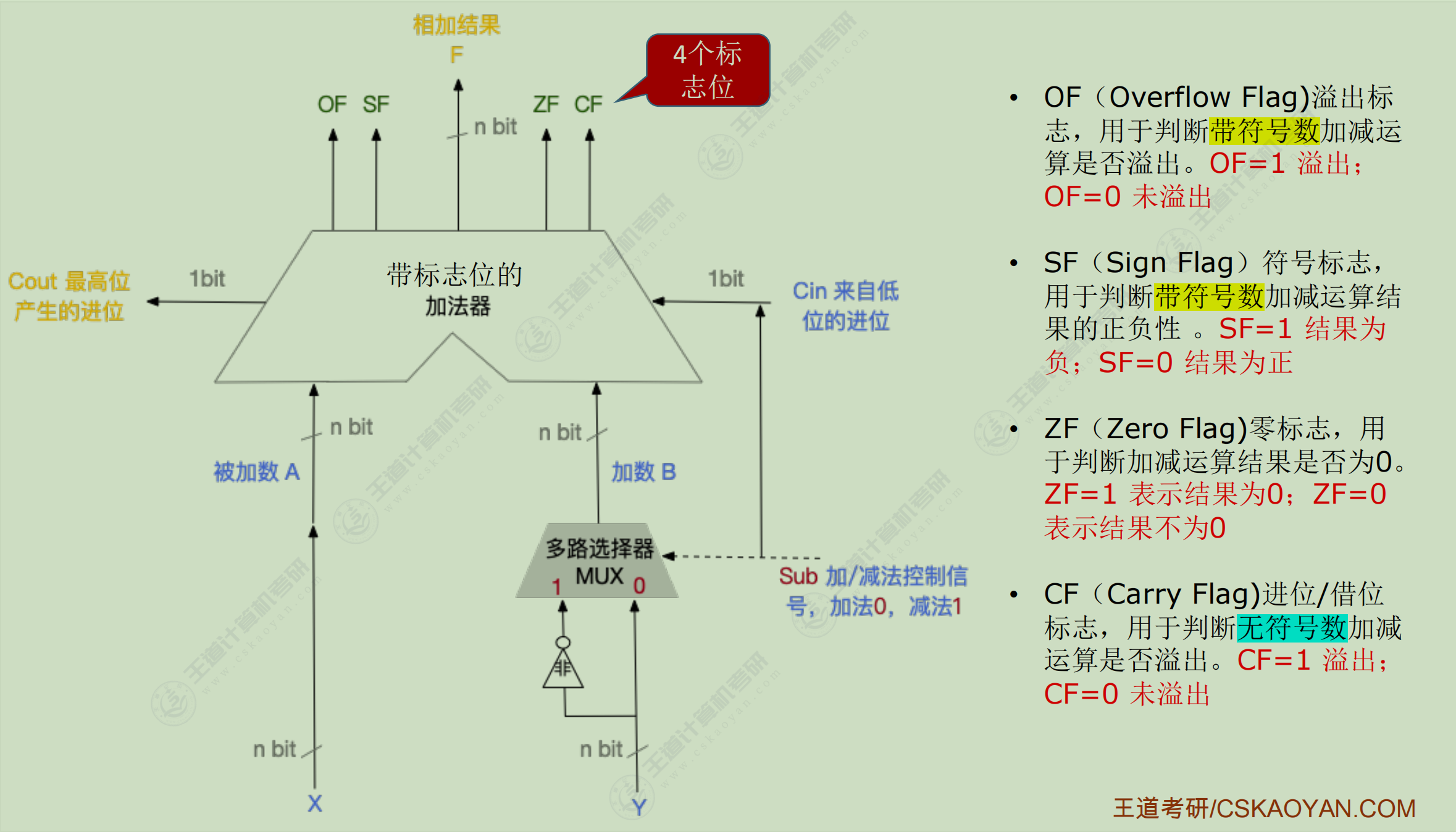
基本运算部件
加法器
ALU
定点数-加减
定点数-乘除
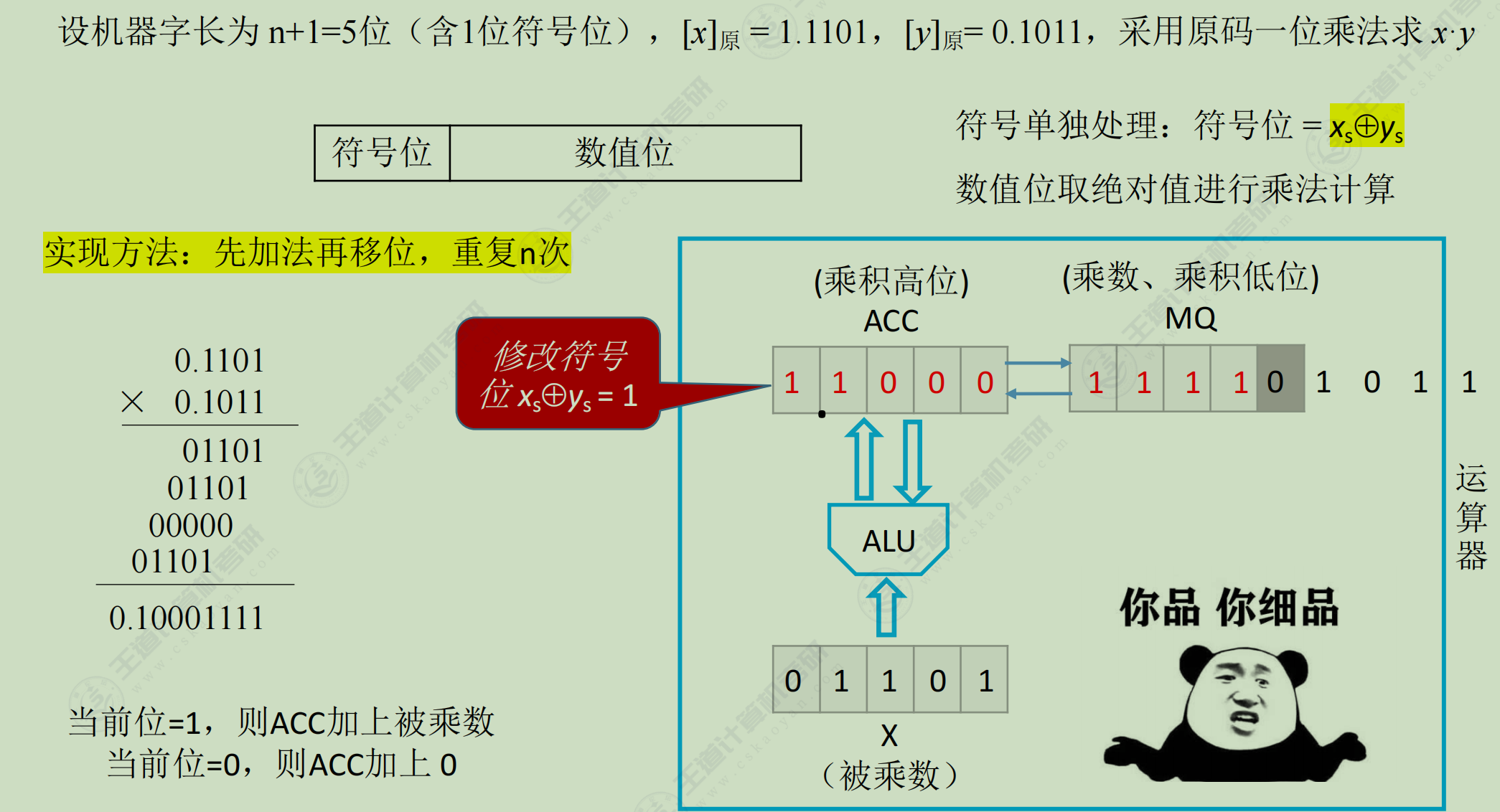
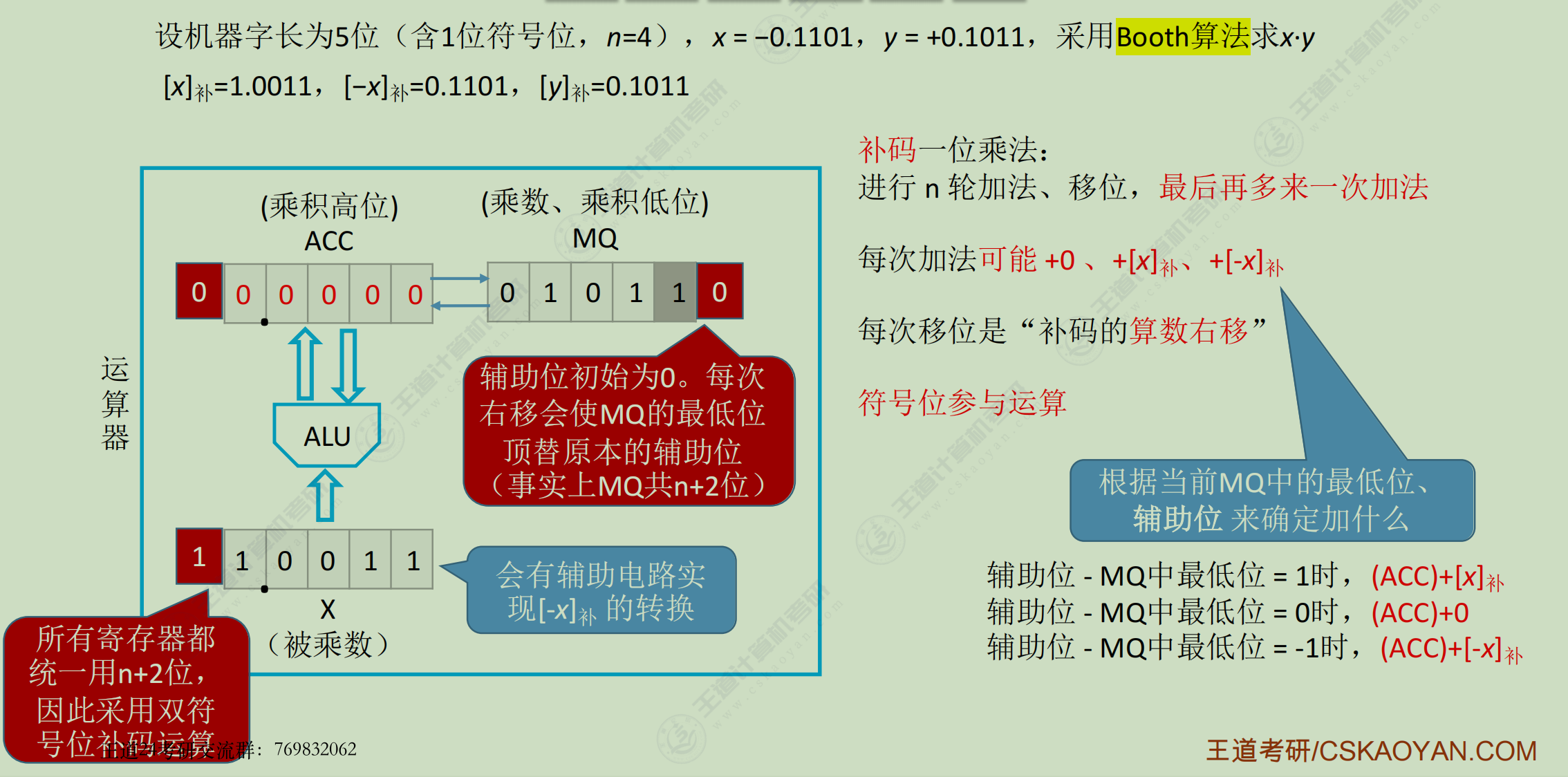
原码-乘
手动

补码-乘

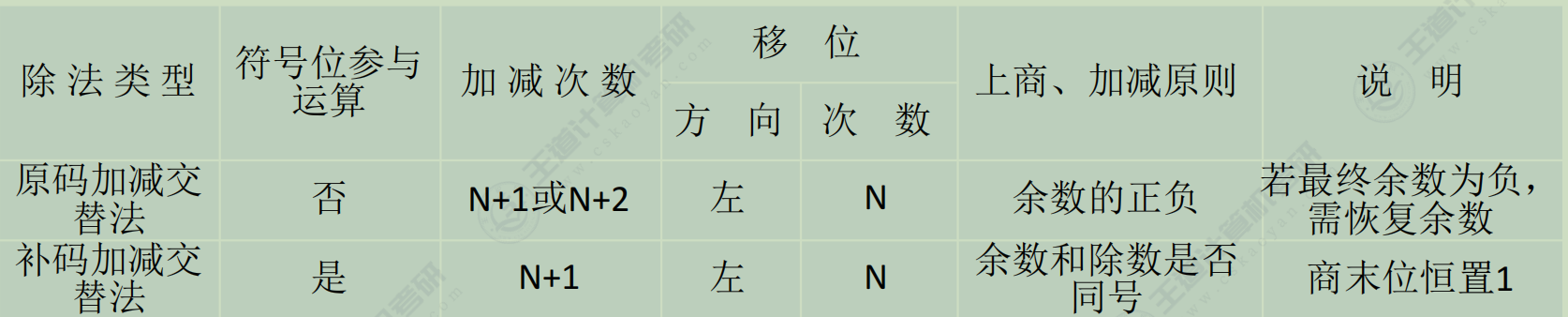
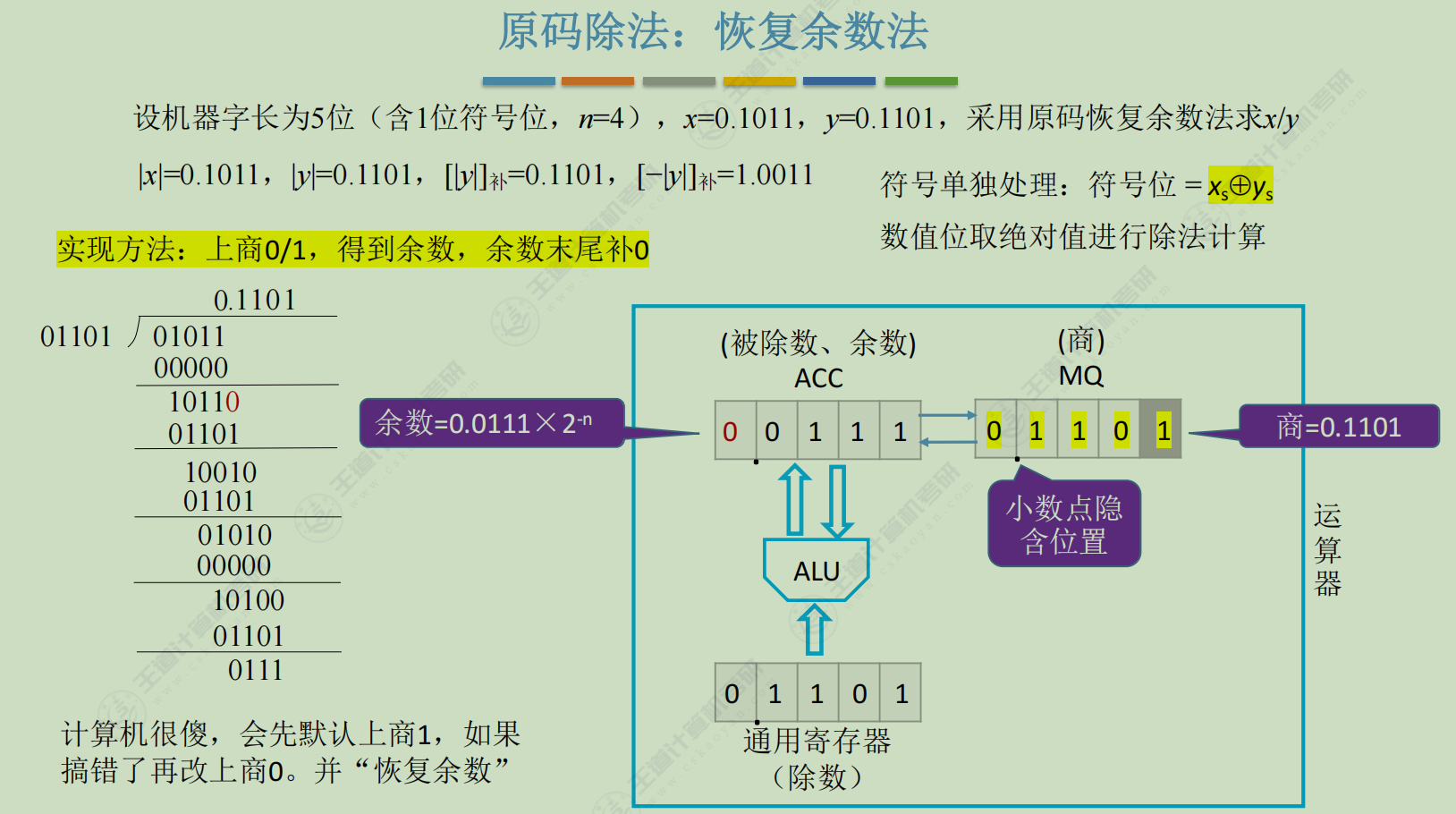
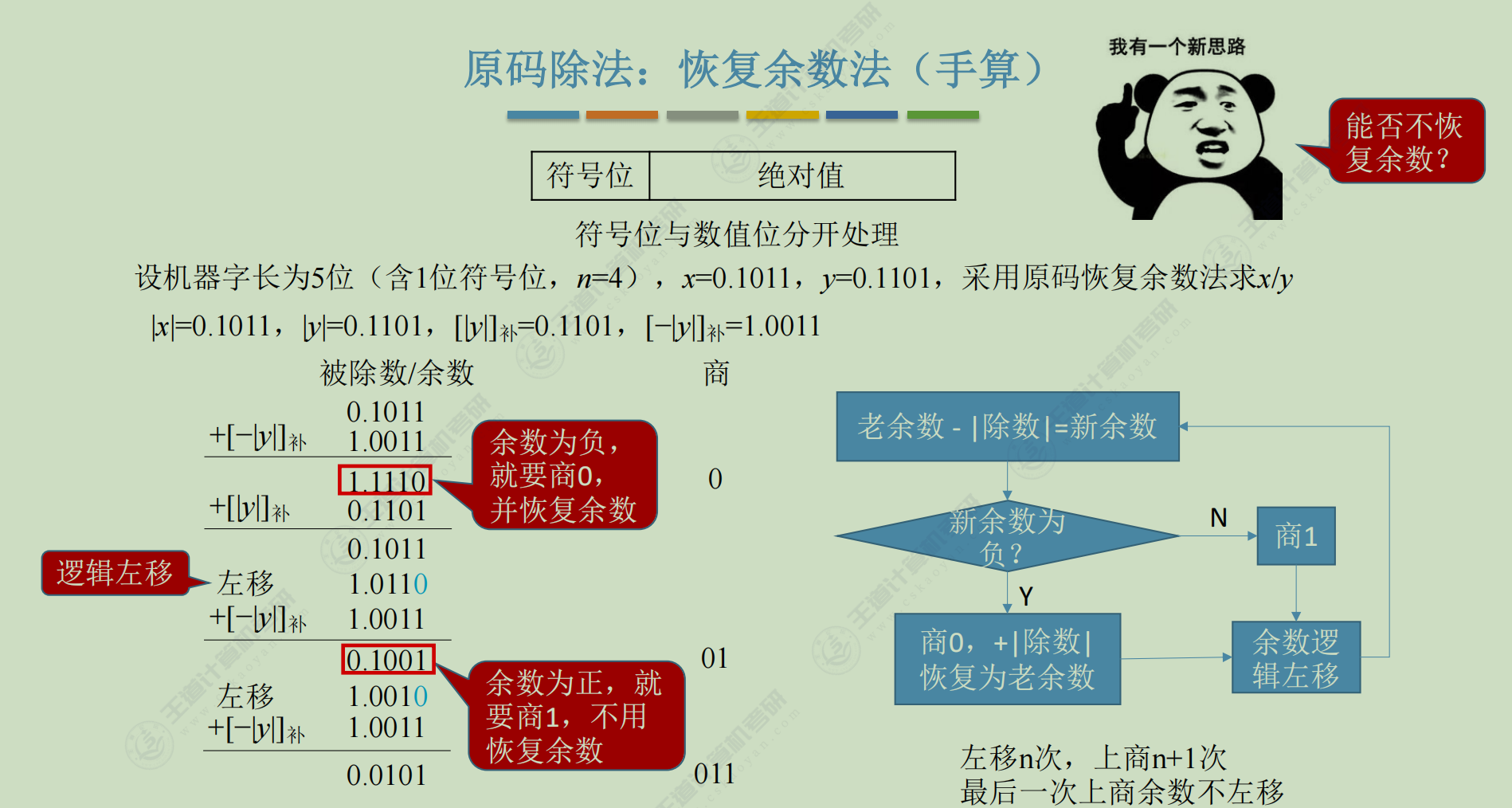
原码-除
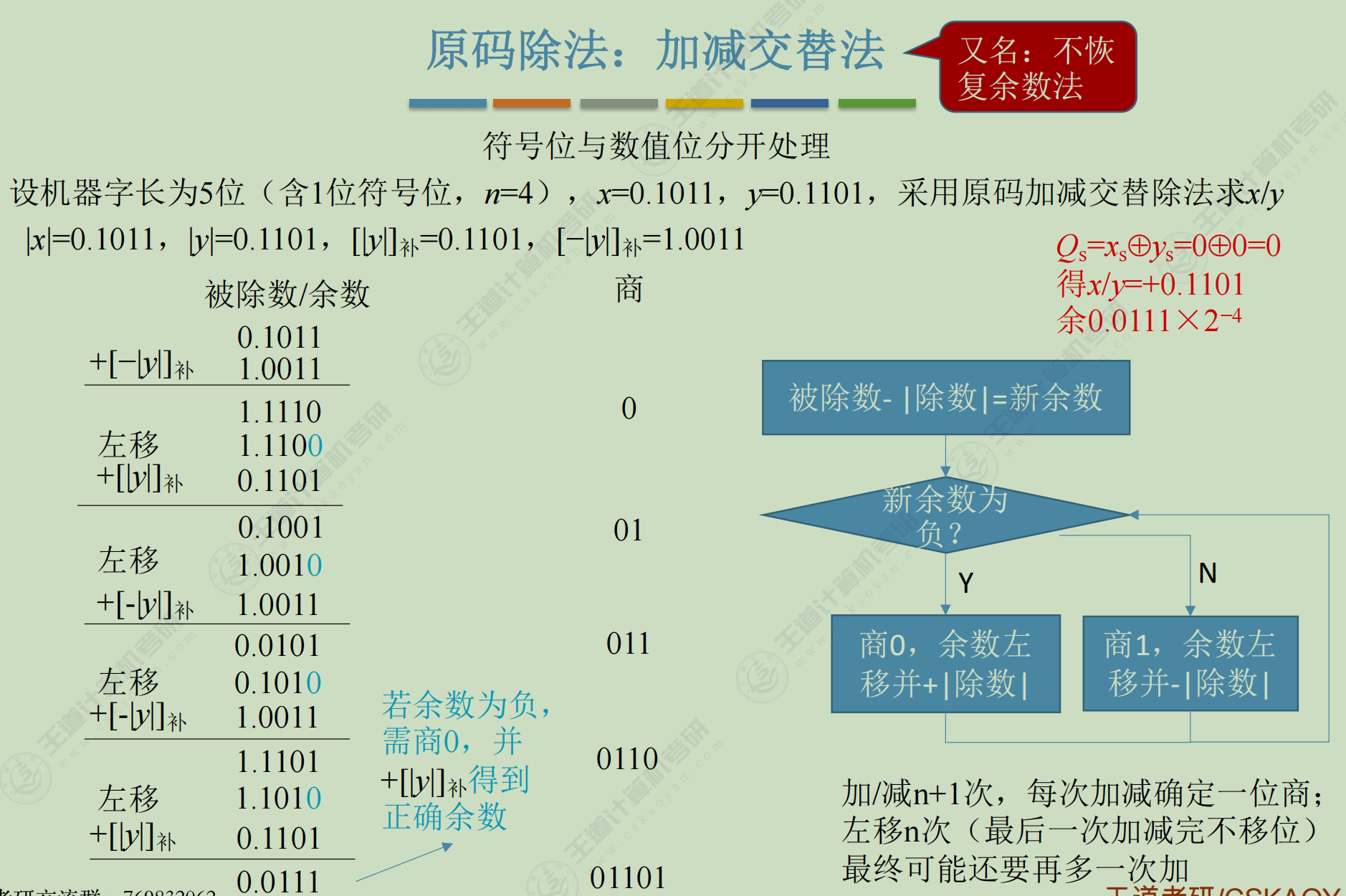
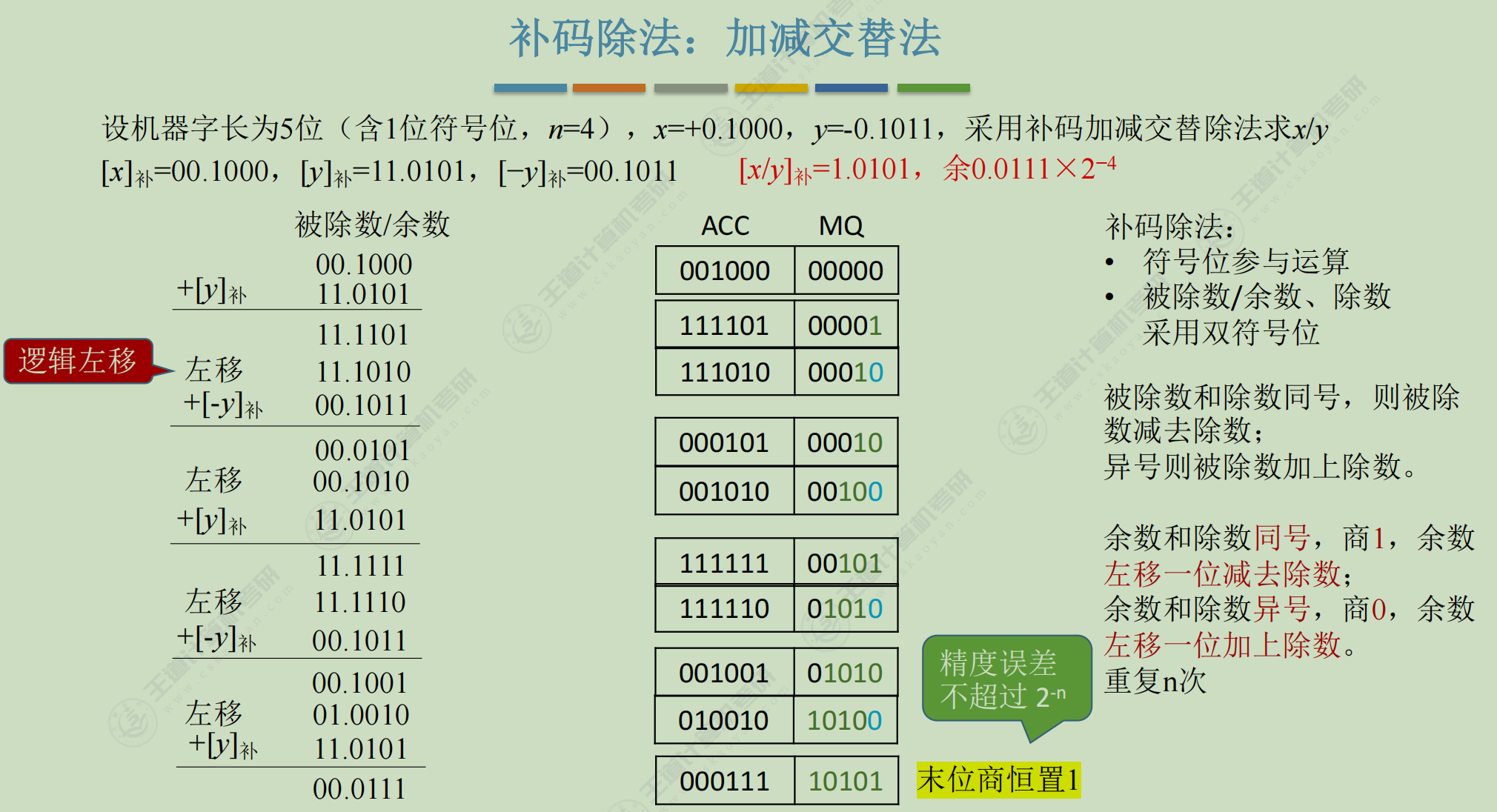
补码-除
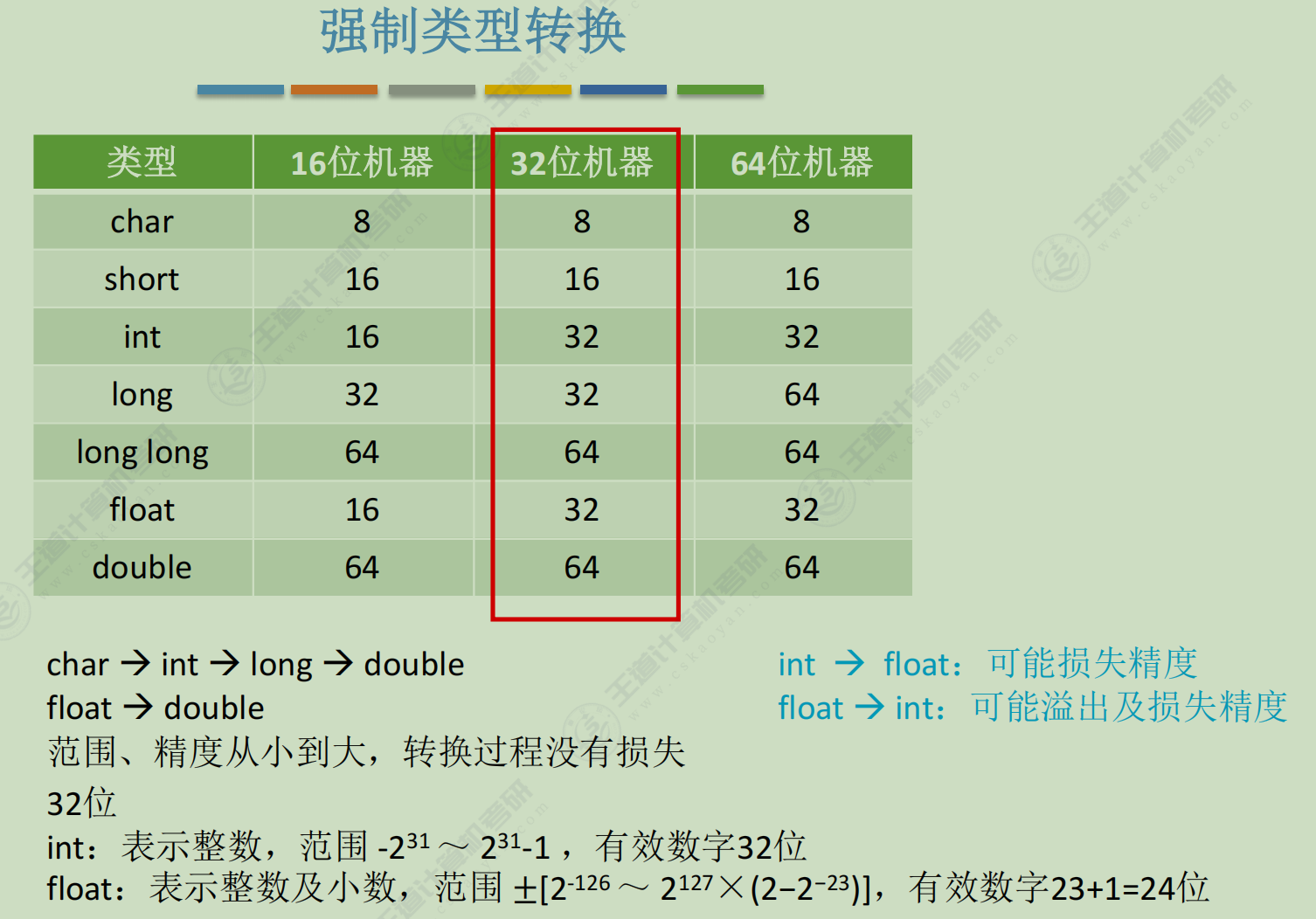
浮点数
规格化


IEEE 754 标准


加减


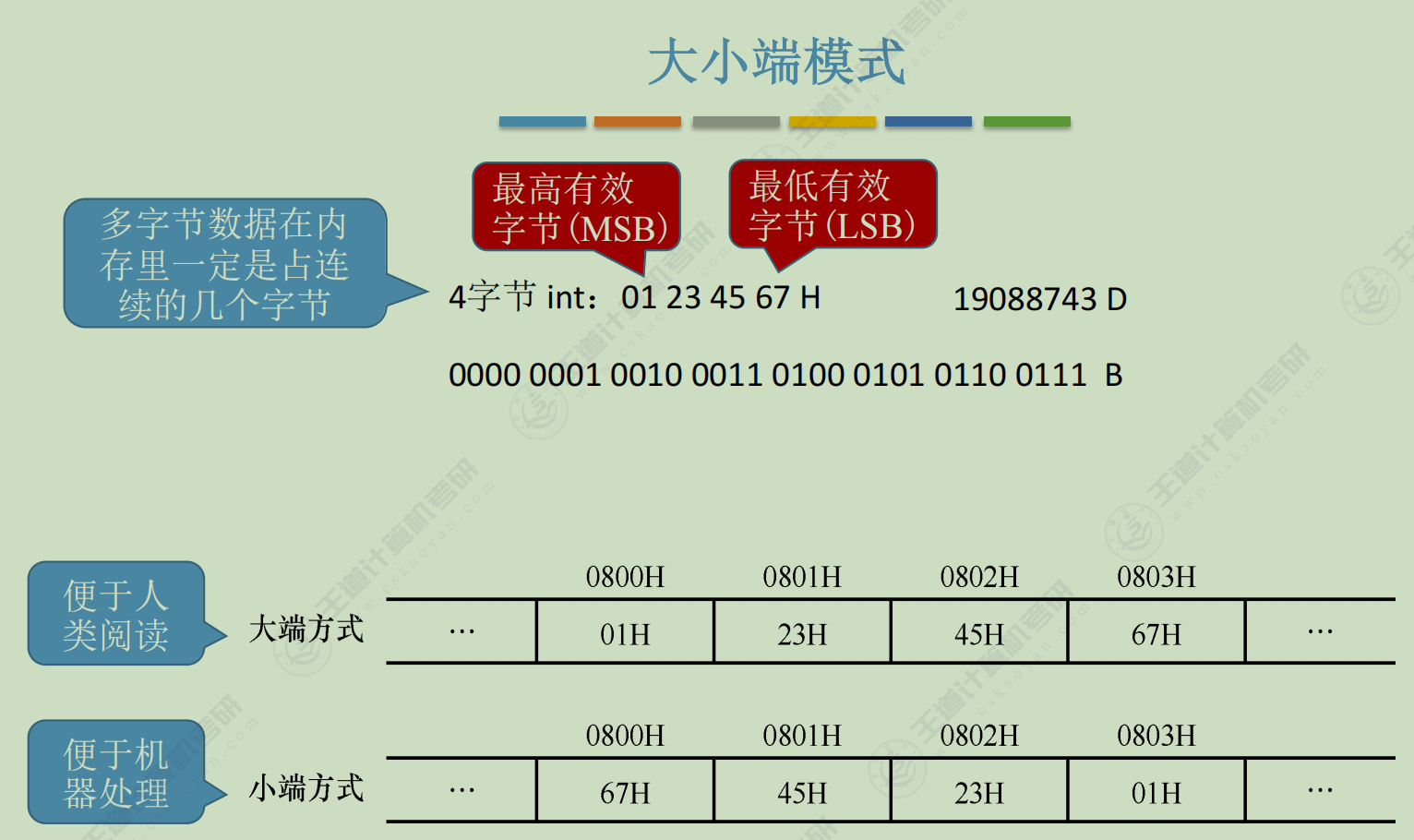
数据的存储和排列
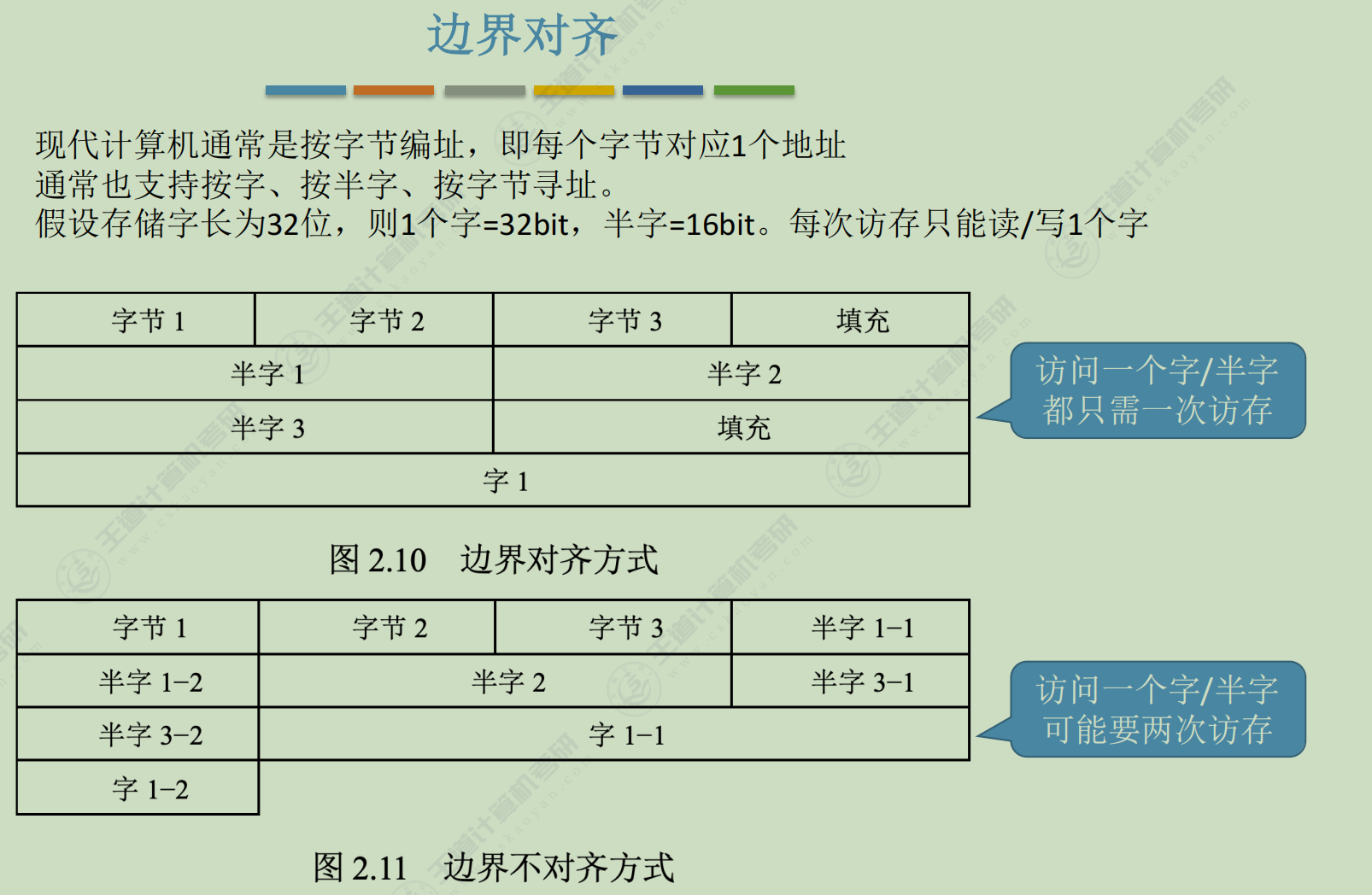
存储系统
概述
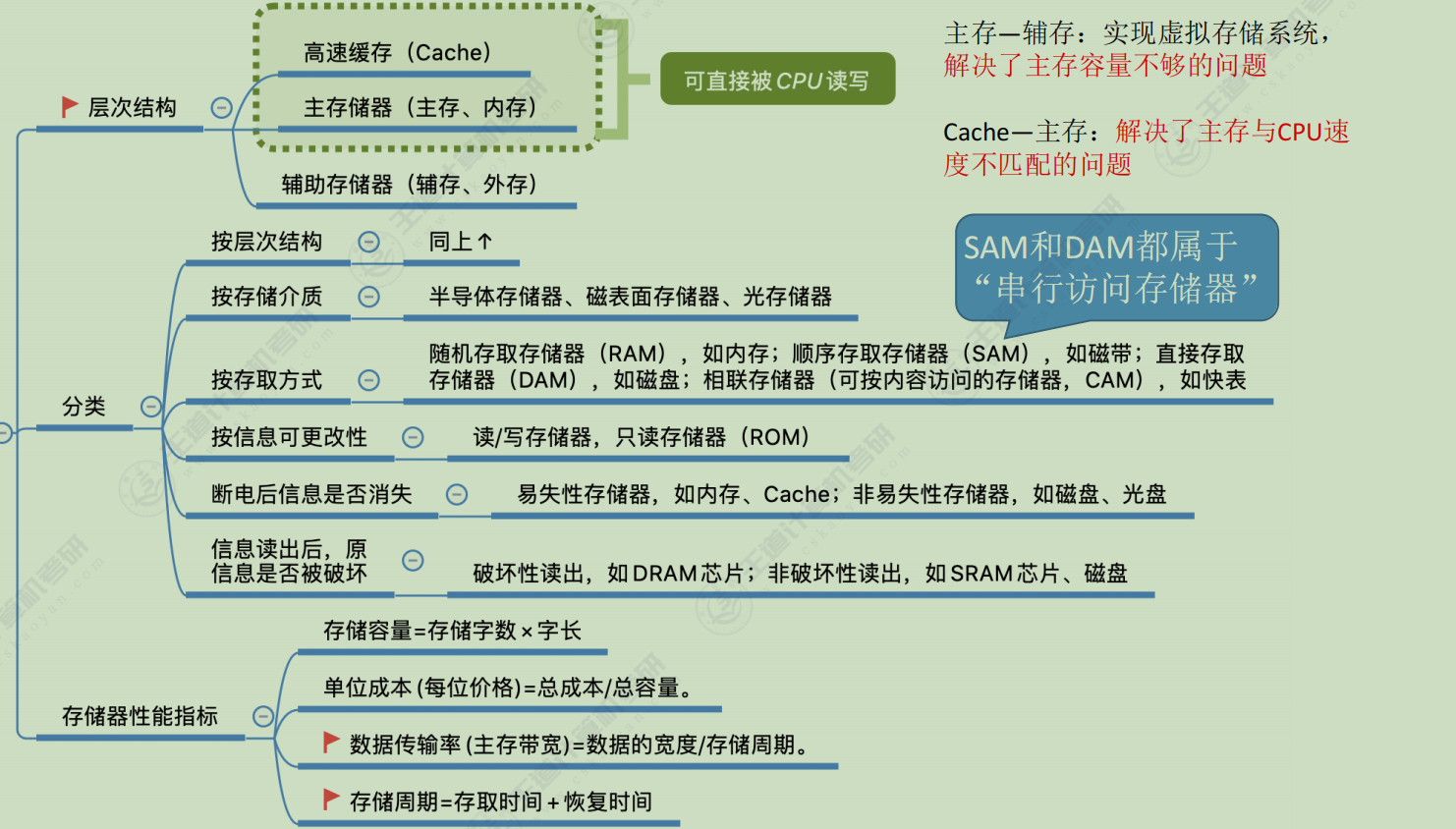
主存储器
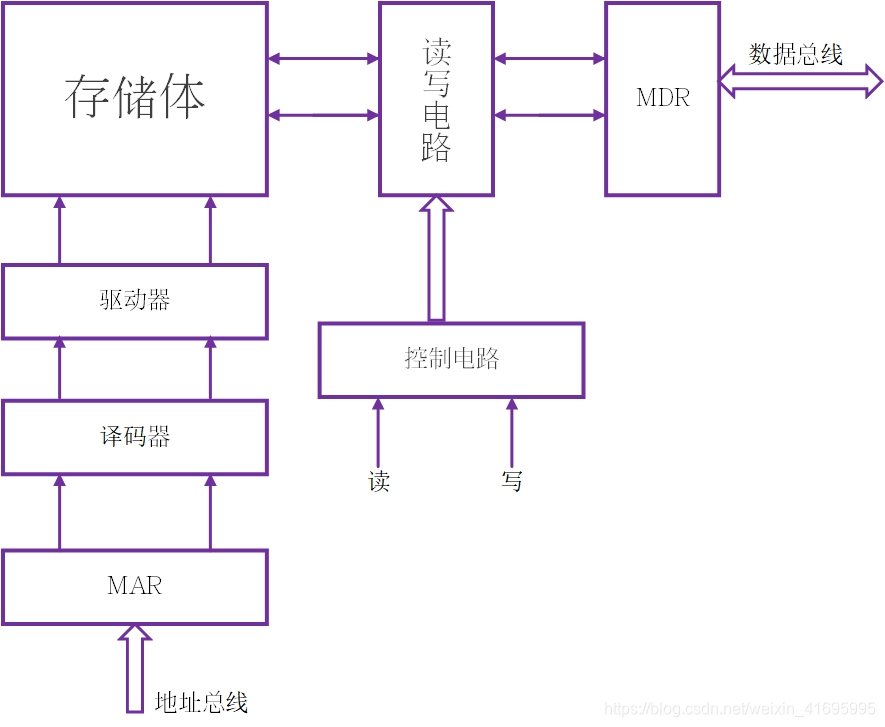
存储单元
表示存储二进制代码的容器,一个存储单元可以存储一连串的二进制代码,这串二进制代码被称为一个存储字,代码的位数为存储字长。
在存储体中,存储单元是有编号的,这些编号称为存储单元的地址号。而存储单元地址的分配有两种方式,分别是大端、大尾方式、小端、小尾方式。
存储单元是按地址寻访的,这些地址同样都是二进制的形式。
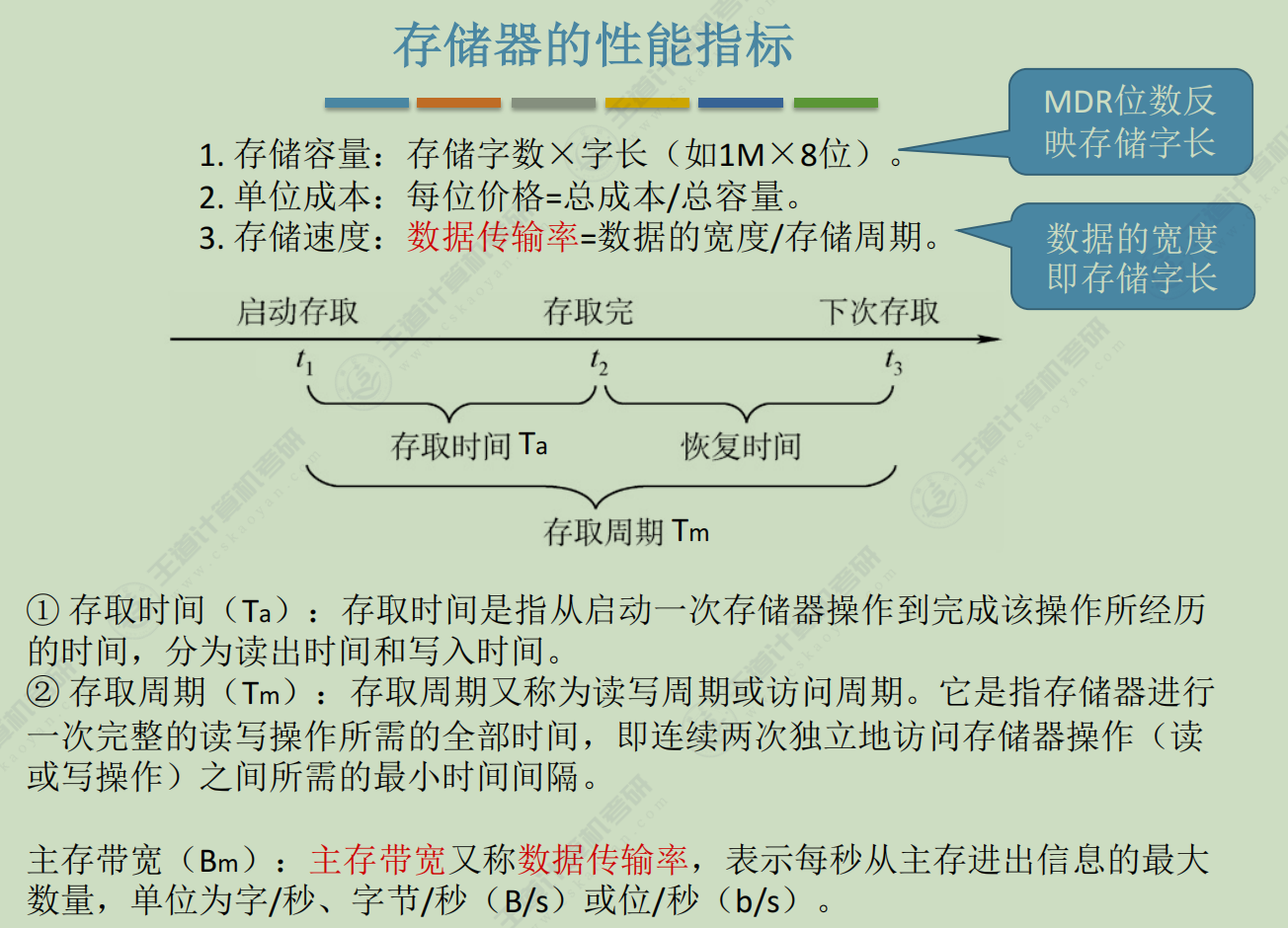
MAR
存储地址寄存器, 保存存储单元的地址, 位数反应了存储单元, 地址线的个数
e.g. 有32个存储单元,而存储单元的地址是用二进制来表示的,那么5位二进制数就可以32个存储单元。那么,MAR的位数就是5位
MDR
存储数据寄存器,其位数反映存储字长 数据线位数
存放的是从存储单元读出, 或者要写入某存储原件的数据
e.g. MDR=16,,每个存储单元进行访问的时候,数据是16位,那么存储字长就是16位
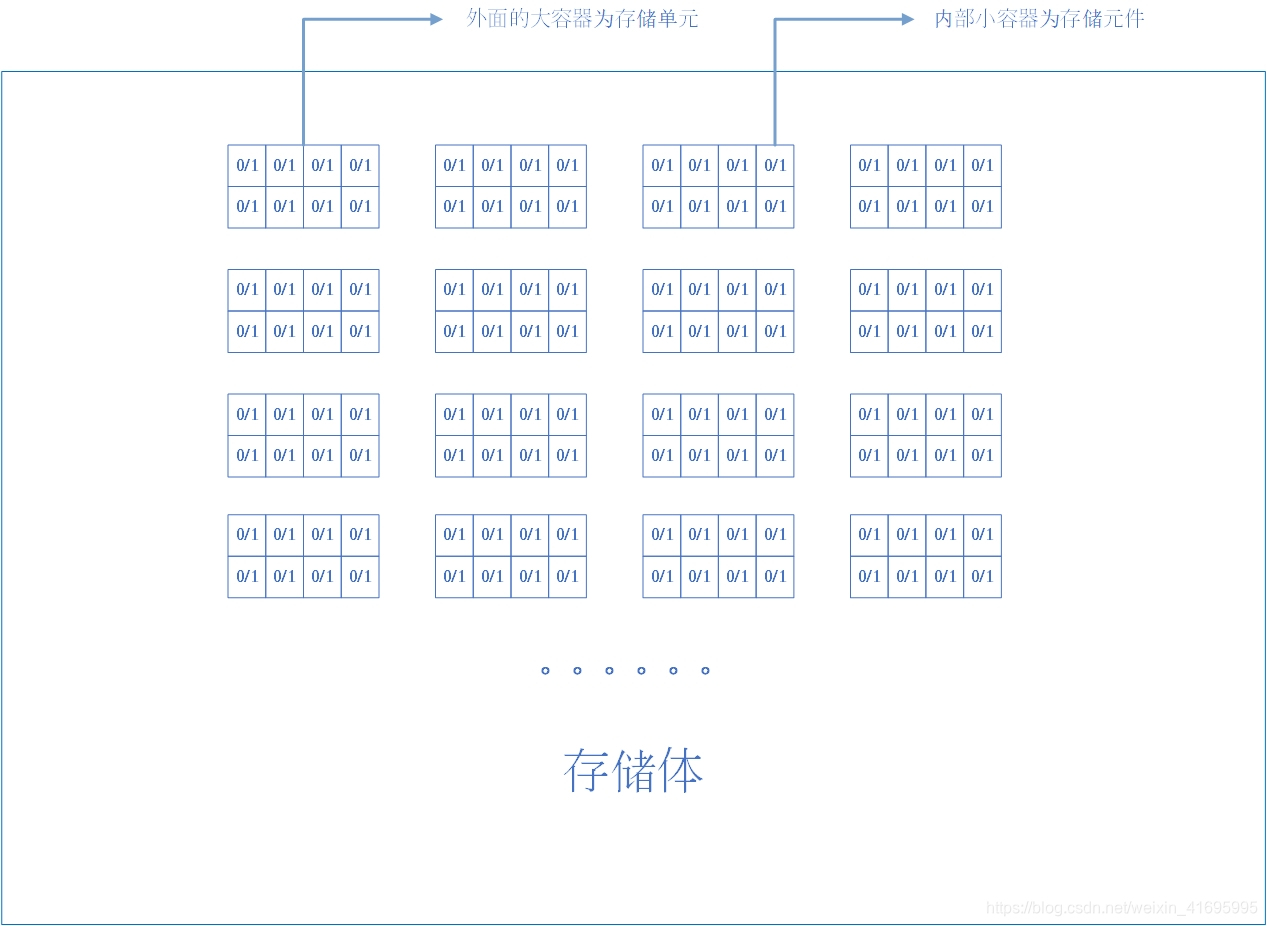
存储体,相当于一栋大楼,大楼内有很多个房间(存储单元),每个房间又有很多个床位(存储元件),二进制代码0表示一个对象,1表示另一个对象(事实上0表示低电平,1表示高电平)
1.主存由半导体元件和电容器件组成。
2.驱动器、译码器、读写电路均位于主存储芯片中。
3.MAR、MDR位于CPU的内部芯片中
4.存储芯片和CPU芯片通过系统总线(数据总线、系统总线)连接。
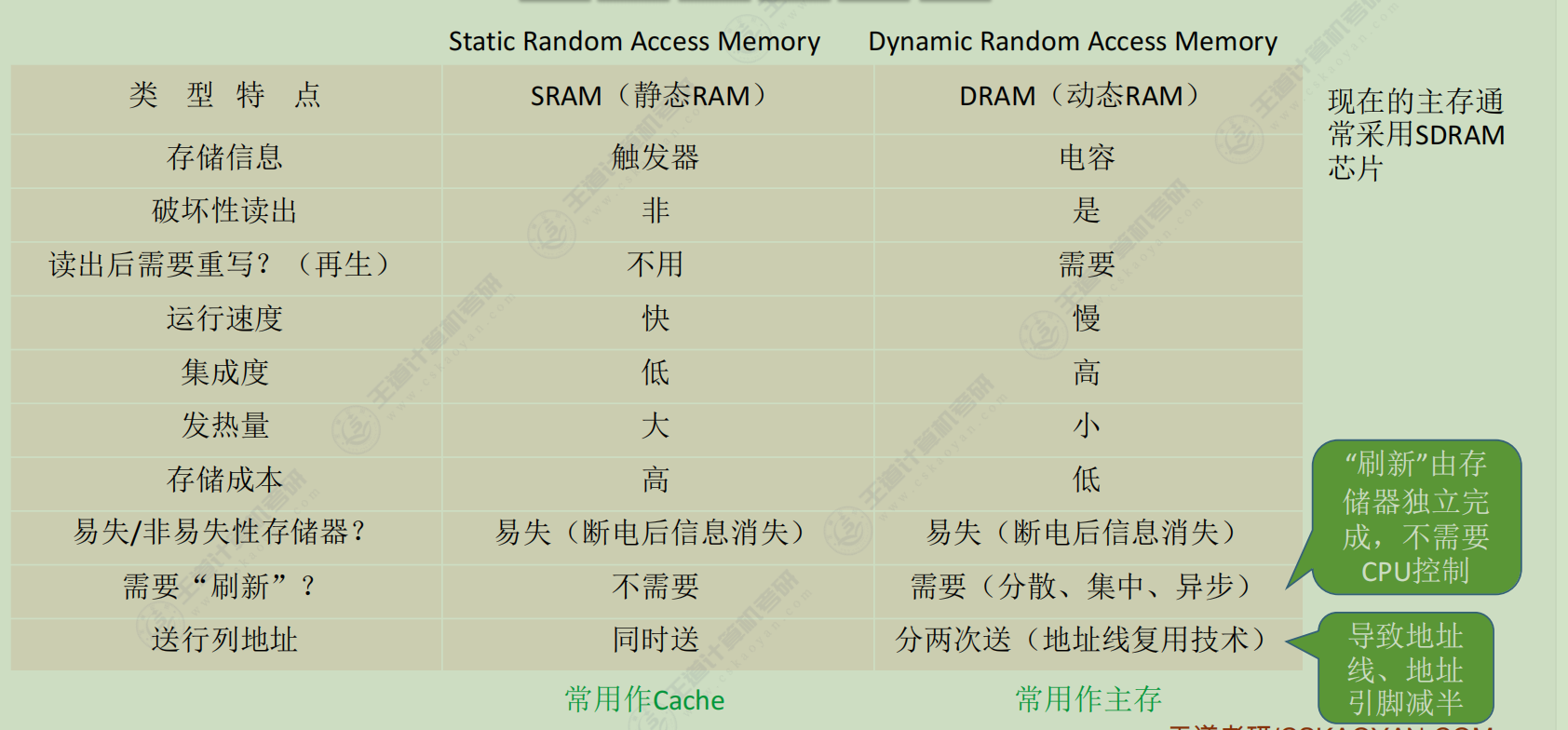
SRAM, DRAM
ROM

多模块存储器

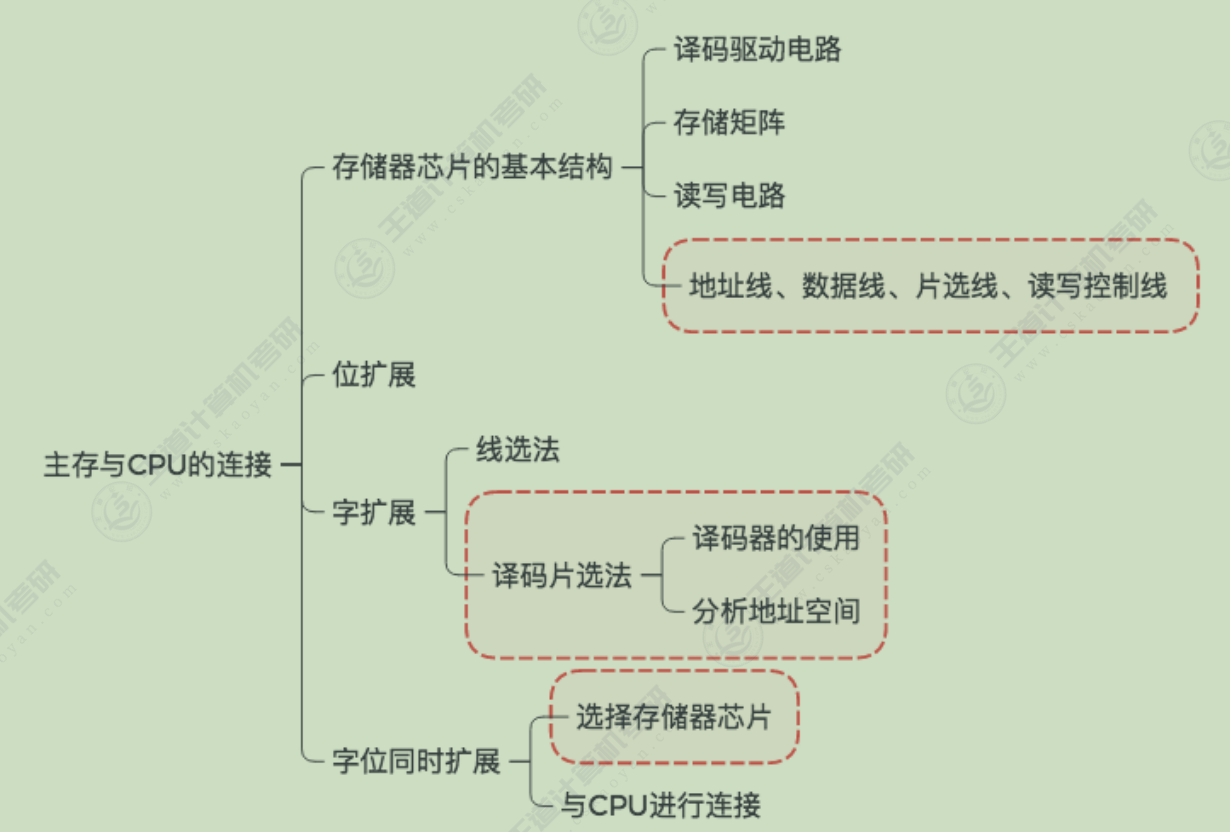
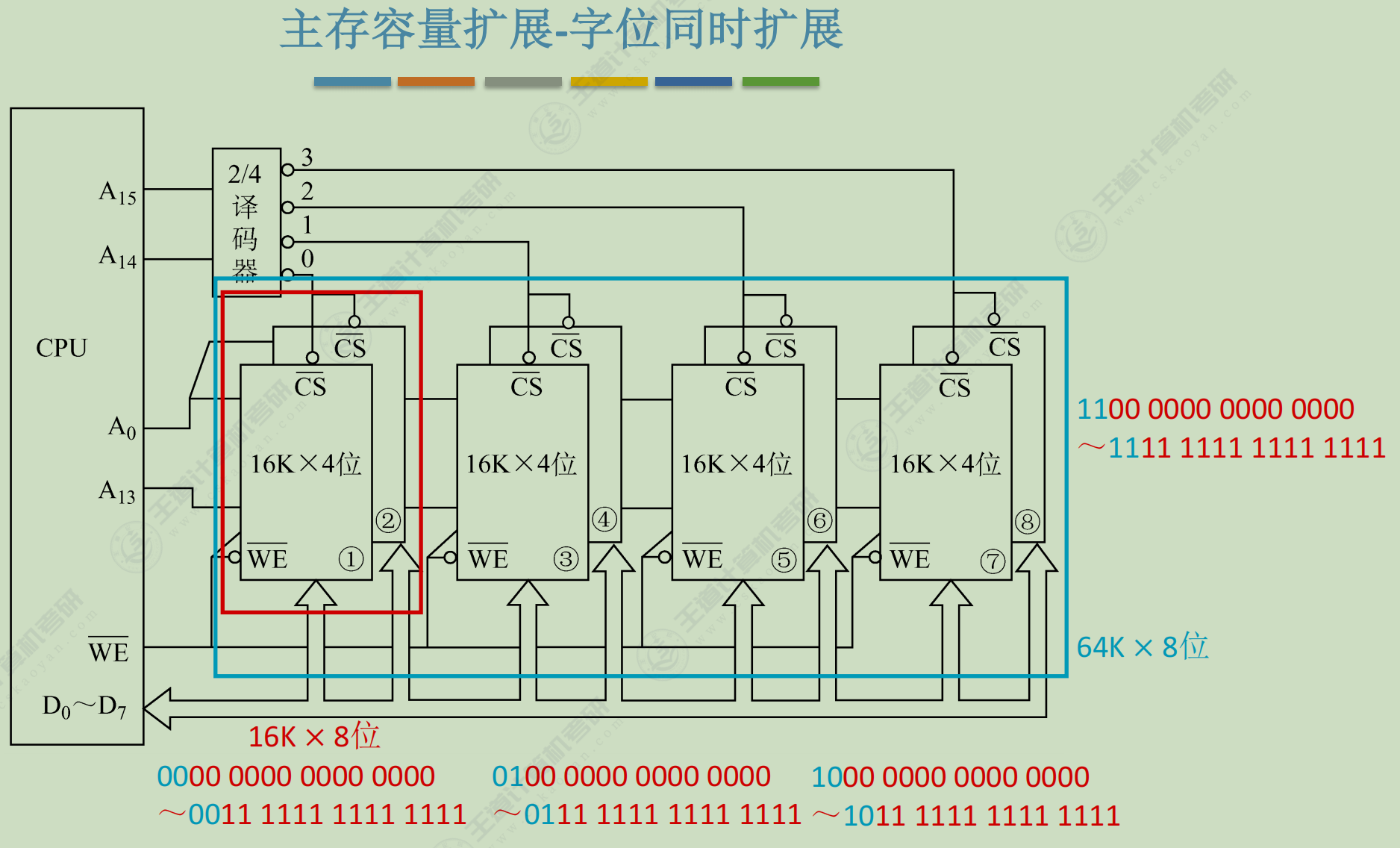
主存储器与CPU的连接
外部存储器
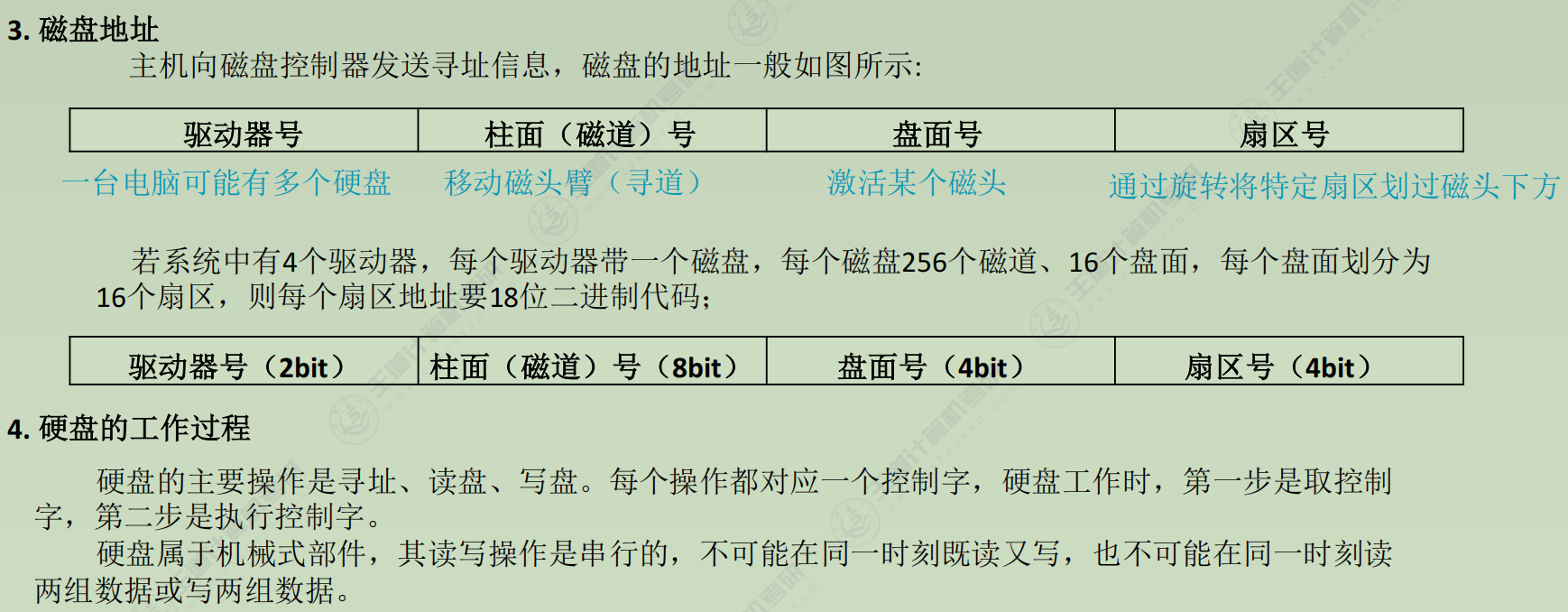
磁盘存储器


磁盘阵列

固态硬盘

cache

与主存映射
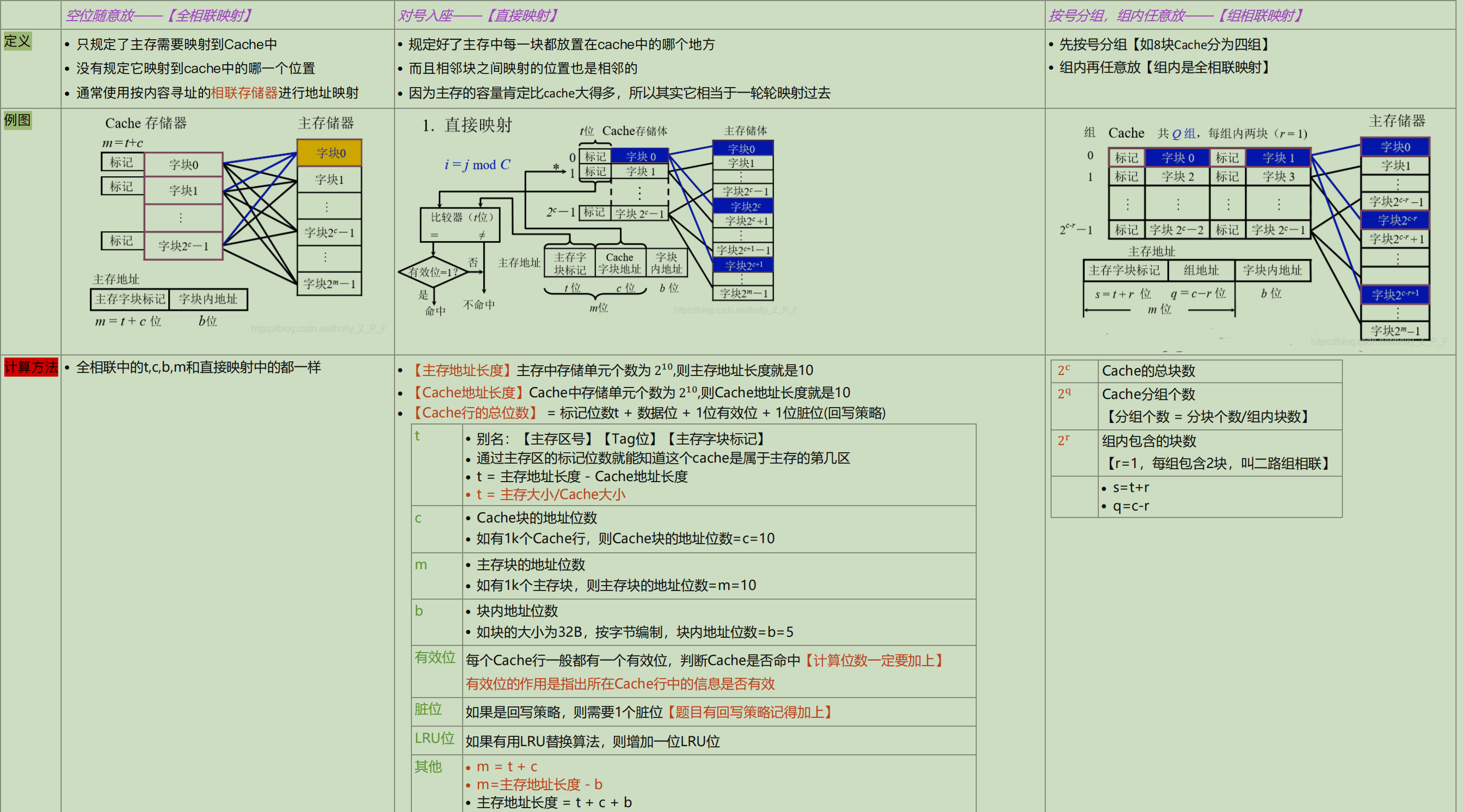
主存和cache是以数据块为单位进行数据交换的,因此主存块大小≡cache块大小
数据块大小64B(26B),以字节编址,占 6 位;
主存大小256MB(228B),以字节编址,共占28位;
- 直接映射
每个主存块只能放到某个固定的cache行,每个主存块所属的cahe行是 主存块号 % cache总行数
助记:一家公司员工每天都是不假思索直接去自己所属的公司
缺点:所以多个块会映射到同一行,这样会产生不必要的换入换出,因为即使cache有空行,也不能利用。
助记:公司有特定技能的人员需要,恰好当前团队没有这样的人才,但是刚好公司人员已经饱和了,那么就得有人先离开,新人再进来,这真是一个悲伤的故事
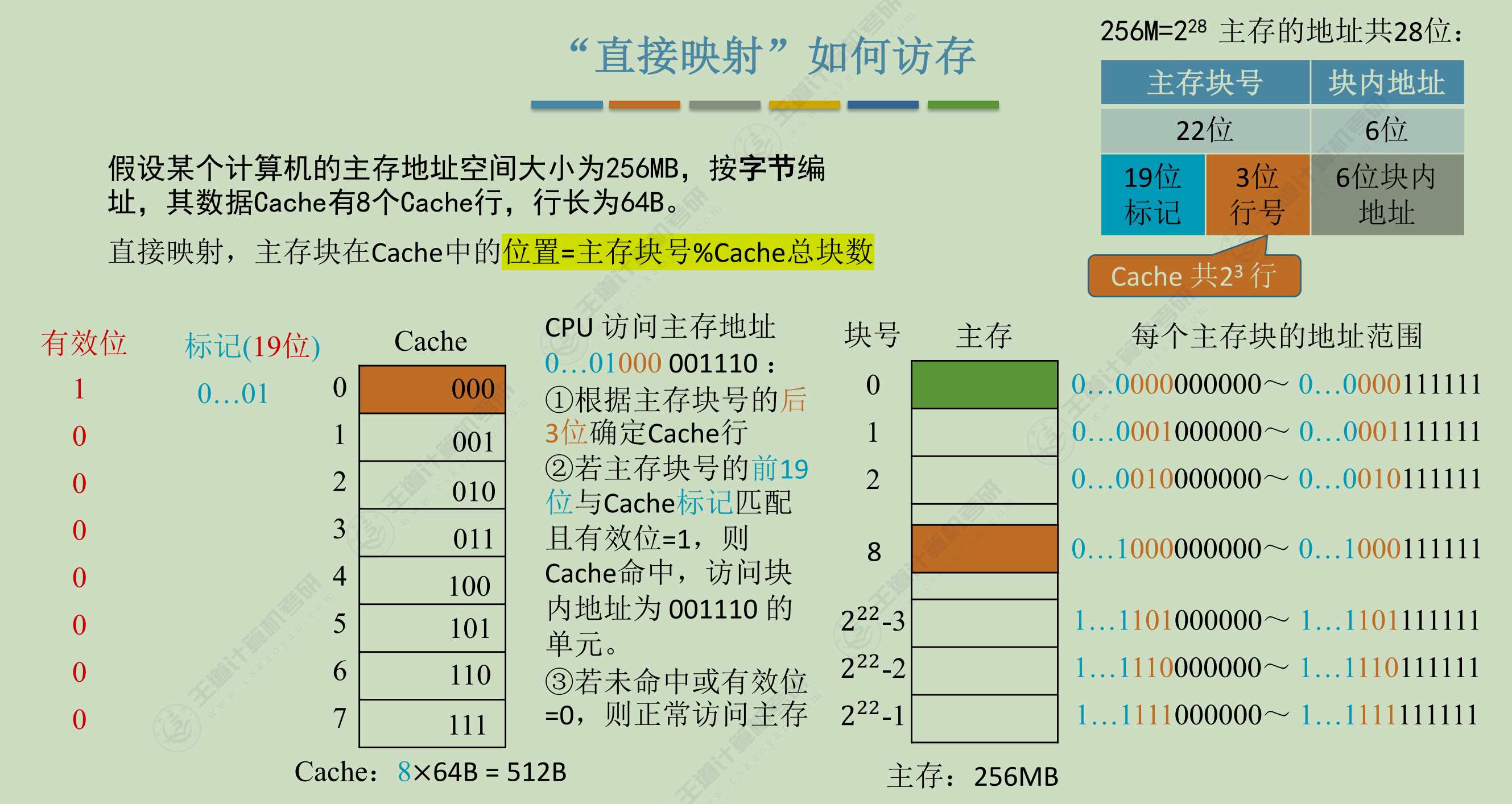
| 主存块号 | ||
|---|---|---|
| 主存字块标记 | cache字块地址 | 字块内地址 |
| 19位 | 3位 | 6位 |
 |
- 全相联映射
cache的所有行均可用于存放主存任何一块数据
(助记:空位子全都可以坐)
主存地址结构划分:
| 主存块号 | 块内地址 |
|---|---|
| 22位 | 6位 |

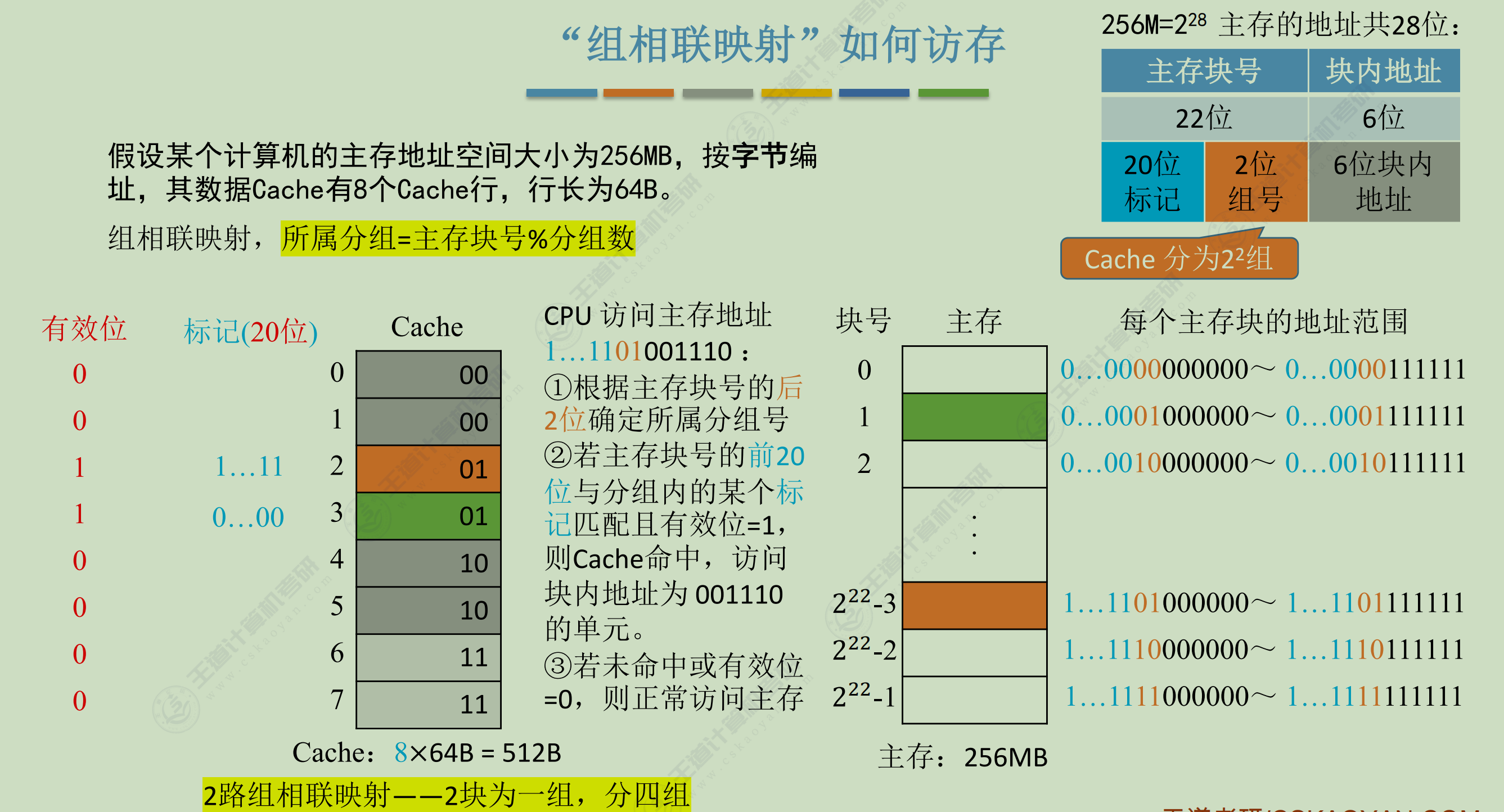
- 组相联映射
以 2 路组相联为例,cache行可被划分为8/2=4组(22),组号占 2 位
「0号,4号,8号……」主存块被映射到0号cache组,「1号,5号,9号……」主存块被映射到1号cache行,以此类推……
而恰好主存块号22位的后 2 位跟cache组号是一致的,于是主存块号就有了另外一种划分方式:
| 主存块号 | 块内地址 |
|---|---|
| 主存字块标记(20位) + cache组号(2位) = 22位 | 6位 |

替换

写策略

容量计算
- 先计算cache行标记项位数
每个cache行都会对应一个标记项,用于标记当前cache行保存的数据状态,cache行标记项包含:
| 有效位 | 标记位 | 脏位 | 替换控制位 |
|---|---|---|---|
| 1bit | 主存字块标记 | 1bit | 与替换算法有关 |
- 有效位:(一定有)固定占 1 位,由于cache未装进数据块时,主存字块标记默认为0,所以有效位是为了区分当前cache块是没装数据还是装了一个主存第0的数据
- 标记位:(一定有)主存字块标记位数,标识当前cache行存放的主存哪一行数据,计算方法见上
- 脏位:(特定条件下才有)也叫一致性维护位,只有当cache写策略采用 写回法 时,该位生效并且占 1 位
- 替换控制位: (特定条件下才有)或叫替换算法位,用于标记替换cache哪一行会被换出,在cache替换策略中,当采用 LRU和LFU替换算法 时,这个控制位会作为被换出的依据。
-
再计算cache块位数
题目中一般会以各种方式较为直观的给出,cache块大小和主存块大小是一致的,很方便算出一个块所占据的位数。
数据位:由于主存块和cache块的交换是以 块 为单位,所以数据位即就是一个数据块的数据位数。 -
计算cache行的位数
$$cache行的位数=cache行标记项位数+cache块位数$$
- 最后计算cache总容量
根据cache总容量和cache块大小求得cache行数,最后
$$c a c h e 总容量 = c a c h e 行数 × c a c h e 行的位数 $$
即$$ c a c h e 总容量 = c a c h e 行数 × ( c a c h e 行标记项位数 + c a c h e 块位数 ) $$
例题1
假设主存容量为512KB,Cache容量为4KB,每个字块为16个字,每个字为32位
(1)Cache地址为多少位,可容纳多少块
(2)主存地址为多少位,可容纳多少块
(3)在直接映射方式下,主存的第几块映射到Cache中的第五块(设起始字块号为1)
(4)画出直接映射方式下主存地址字段中各段的位数
例题2
假设主存容量为512K*16位,Cache容量为4096 * 16位,块长为4个16位的字,访存地址为字
(1) 在直接映射下,设计主存的地址格式
(2)在全相联映射下,设计主存的地址格式
(3)在二路组相联映射方式下,设计主存的地址格式
(4)若主存容量为512KB*32位,块长不变,在四路组相联映射下,设计主存的地址格式
指令系统
基本格式
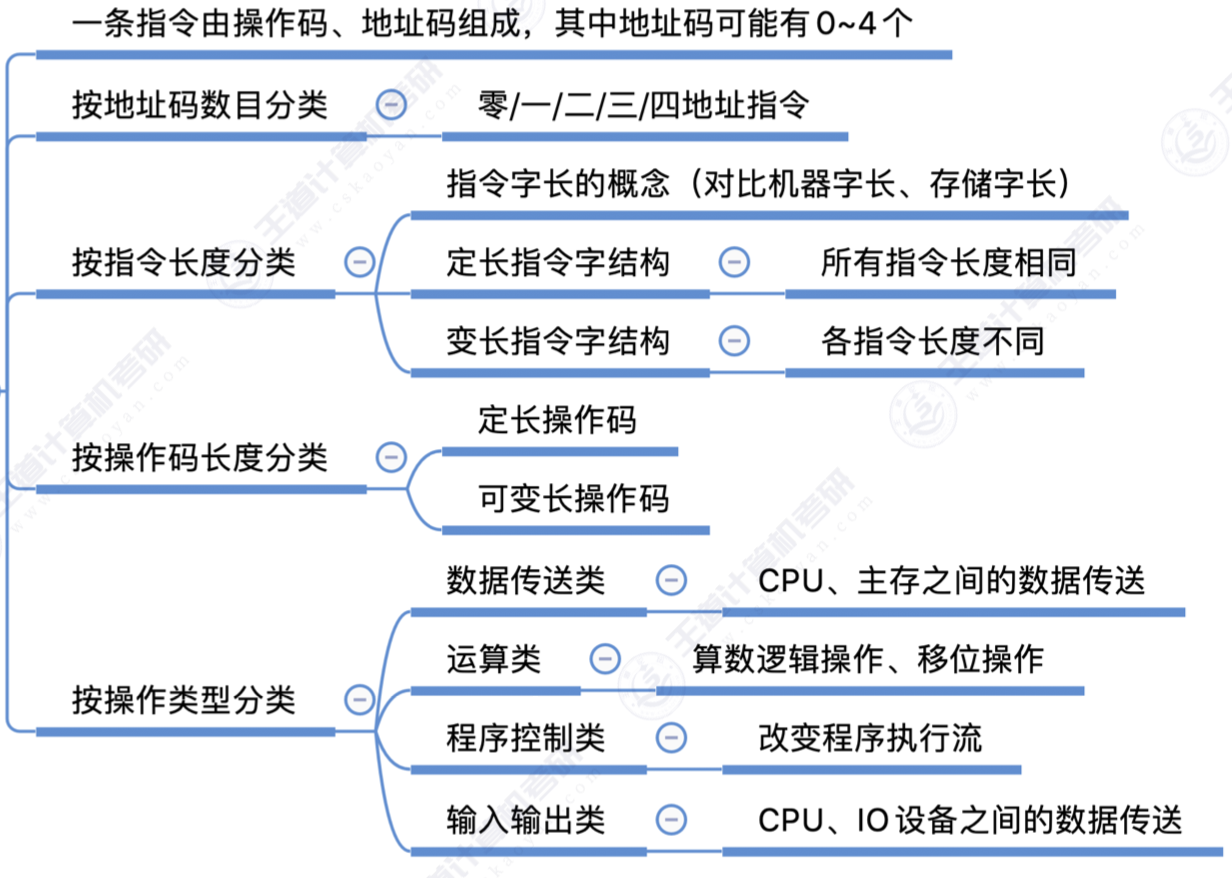
寻址
指令寻址
- 顺序寻址
PC+一条指令长度 - 跳跃寻址
绝对转移, 相对转移
数据寻址
| 寻址方式 | 有效地址 | 访问次数(指令执行期间) | 特点, 用途 | 常考 |
|---|---|---|---|---|
| 立即 | 0 | 给寄存器赋初值 | 数值 | |
| 直接 | EA=A | 1 | ||
| 隐含 | 0 | 缩短指令字长 | ||
| 一次间接 | EA=(A) | 2 | 扩大寻址范围, 易于完成子程序返回 | |
| 寄存器 | EA=$R_i$ | 0 | 指令字较短, 指令执行速度较快 | |
| 寄存器间接 | EA=A+(BR) | 1 | 扩大寻址范围 | 寄存器编号 |
| 偏移 | ||||
| 基址 | EA=A+(BR) | 1 | 扩大操作数寻址范围 终于多道程序设计, 为程序或数据分配存储空间 |
|
| 变址 | EA=A+(IX) | 1 | 数组, 循环程序 | |
| 相对 | EA=A+(PC) | 1 | 转移指令, 程序内部浮动(相对下一条指令的偏移) | |
| 堆栈 | 入栈/出栈EA的方向不同 | 硬堆栈不访存 软堆栈1次 |
机器代码表示
| dword ptr | 双字, 32bit |
|---|---|
| word ptr | 单字, 16bit |
| byte ptr | 字节, 8bit |
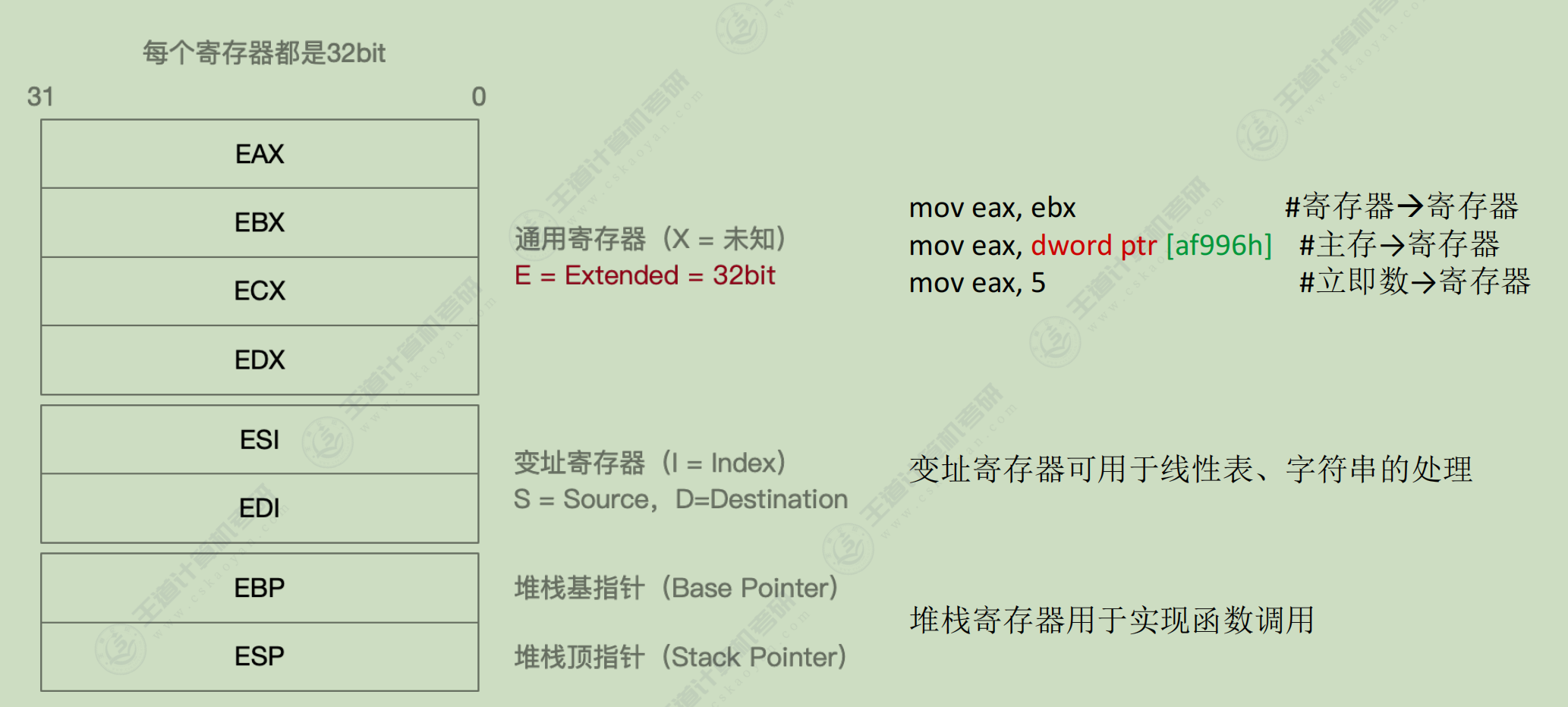
mov 目的操作数d,源操作数S ; mov指令:将源操作数s复制到目的操作数d所指的位置
mov eax, ebx ; 将寄存器 ebx 的值复制到寄存器 eax
mov eax, 5 ; 将立即数5复制到寄存器 eax
mov eax, dword ptr [af996h] ; 将内存地址 af996h 所指的32bit值复制到寄存器 eax
mov byte ptr [af996h], 5 ; 将立即数5复制到内存地址 af996h 所指的一字节中
mov eax, dword ptr [ebx] ; 将 ebx 所指主存地址的 32-bit 数据复制到 eax 寄存器中
mov dword ptr [ebx], eax ; 将 eax 的内容复制到 ebx 所指主存地址的 32-bit
mov eax, byte ptr [ebx] ; 将 ebx 所指主存地址的 8-bit 数据复制到 eax 寄存器中
mov eax, [ebx] ; 若未指明主存读写长度,默认为 32-bit mov [af996h], eax # 将 eax 的内容复制到 af996h 所指的地址(未指明长度默认 32-bit)
mov eax, dword ptr [ebx+8] ; 将 ebx+8 所指主存地址的 32-bit 数据复制到 eax 寄存器中
mov eax, dword ptr [af996-12h] ; 将 af996-12h 所指主存地址的 32-bit 数据复制到 eax 寄存器中
算数运算
目的操作数d不能是常量
| 功能 | 英文 | 汇编指令 | 注释 |
|---|---|---|---|
| 加 | add | add d, s |
计算 d+s,结果存入d |
| 减 | subtract | sub d, s |
计算 d-s,结果存入d |
| 乘 | multiply | mul d, simul d, s |
无符号数 ds,乘积存入d 有符号数 ds,乘积存入d |
| 除 | divide | div sidiv s |
无符号数除法 edx:eax/s,商存入eax,余数存入edx(被除数放到eax里) 有符号数除法 edx:eax/s,商存入eax,余数存入edx |
| 取负数 | negative | neg d |
将d取负数,结果存入d |
| 自增++ | increase | inc d |
将d++,结果存入d |
| 自减-- | decrease | dec d |
将d--,结果存入d |
逻辑运算
| 功能 | 英文 | 汇编指令 | 注释 |
|---|---|---|---|
| 与 | and | and d, s |
将 d、s 逐位相与,结果放回d |
| 或 | or | or d, s |
将 d、s 逐位相或,结果放回d |
| 非 | not | not d |
将 d 逐位取反,结果放回d |
| 异或 | exclusive or | xor d, s |
将 d、s 逐位异或,结果放回d |
| 左移 | shift left | shl d, s |
将 d 逻辑左移 s 位,结果放回 d(通常 s 是常量) |
| 右移 | shift right | shr d, s |
将 d 逻辑右移 s 位,结果放回 d(通常 s 是常量) |
AT&T VS Intel
| 项目 | AT&T 格式 | Intel 格式 |
|---|---|---|
| 目的操作数d、源操作数s | op s, d注:源操作数在左,目的操作数在右 |
op d, s注:源操作数在右,目的操作数在左 |
| 寄存器的表示 | mov %ebx, %eax注:寄存器名之前必须加 % |
mov eax, ebx注:直接写寄存器名即可 |
| 立即数的表示 | mov $985, %eax注:立即数之前必须加 $ |
mov eax, 985注:直接写数字即可 |
| 主存地址的表示 | mov %eax, (af996h)注:用“小括号” |
mov [af996h], eax注:用“中括号” |
| 读写长度的表示 | movb $5, (af996h)movw $5, (af996h)movl $5, (af996h)addb $4, (af996h)注:指令后加 b、w、l 分别表示读写长度为 byte、word、dword |
mov byte ptr [af996h], 5mov word ptr [af996h], 5mov dword ptr [af996h], 5add byte ptr [af996h], 4注:在主存地址前说明读写长度 byte、word、dword |
| 主存地址偏移量的表示 | movl -8(%ebx), %eax注:偏移量(基址) movl 4(%ebx, %ecx, 32), %eax注:偏移量(基址, 变址, 比例因子) |
mov eax, [ebx - 8]注:[基址+偏移量] mov eax, [ebx + ecx*32 + 4]注:[基址+变址*比例因子+偏移量] |
控制流
转移, 选择
| 指令格式 | 描述 | 示例 |
|---|---|---|
jmp <地址> |
PC(程序计数器)无条件转移到指定的 <地址> |
|
jmp 128 |
<地址> 用常数直接给出,表示跳转到内存地址 128 处执行 |
jmp 128 |
jmp eax |
<地址> 来自于寄存器,eax 的值作为目标地址 |
jmp eax |
jmp [999] |
<地址> 来自主存,内存地址 999 处的值为目标地址 |
jmp [999] |
jmp NEXT |
<地址> 通过标号锚定,NEXT 是预先定义的位置 |
jmp NEXT |
cmp a, b ; 比较a和b两个数, a、b两个数可能来自寄存器/主存/常量
je <地址> ; jump when equal,若a==b则跳转
jne <地址> ; jump when not equal,若a!=b则跳转
jg <地址> ; jump when greater than,若a>b则跳转
jge <地址> ; jump when greater than or equal to,若a>=b则跳转
jl <地址> ; jump when less than,若a<b则跳转
jle <地址> ; jump when less than or equal to,若a<=b则跳转
e.g.
cmp eax, ebx ; 比较寄存器eax和ebx里的值
jg NEXT ; 若 eax > ebx,则跳转到 NEXT
e.g.
mov eax, 7 ; 假设变量a=7,存入eax
mov ebx, 6 ; 假设变量b=6,存入ebx
cmp eax, ebx ; 比较变量a和b
jg NEXT ; 若a>b,转移到NEXT:; else 部分的逻辑
mov ecx, ebx ; 假设用ecx存储变量c,令c=b
jmp END ; 无条件转移到END:
NEXT:
mov ecx, eax ; if 部分的逻辑, 假设用ecx存储变量c,令c=a
END:
循环
; 求 1+2+3+...+100
① 循环前的初始化
mov eax, 0 ; 用 eax 保存 result,初值为0
mov edx, 1 ; 用 edx 保存 i,初始值为1
② 是否直接跳过循环
cmp edx, 100 ; 比较 i 和 100
jg L2 ; 若 i>100,转跳到 L2 执行
L1:
③ 循环主体
add eax, edx ; 实现 result += i
inc edx ; inc 自增指令,实现 i++
④ 是否继续循环?
cmp edx, 100 ; i 和 100
jle L1 ; 若 i<=100,转跳到 L1 执行
L2: ; 跳出循环主体
; for(int i = 500; i>0; i--) {
; 做某些处理;
; } //循环500轮
mov ecx, 500 ; 用 ecx 作为循环计数器
Looptop: ; 循环的开始
...
做某些处理
...
loop Looptop ; ecx--,若 ecx!=0,跳转到 Looptop
等价于:
dec ecx
cmp ecx, 0
jne Looptop
loopx 指令——如 loopnz, loopz
loopnz——当 ecx!=0 && ZF==0 时,继续循环
loopz——当 ecx!=0 && ZF==1 时,继续循环
函数调用
栈帧: 保存函数大括号内定义的局部变量, 保存函数调用相关信息
局部变量集中在栈帧底部区域
调用参数-栈帧顶部
最底部一定是上一层栈帧基址(ebp旧值)
最顶部一定是返回地址(当前函数栈帧除外)
| 指令 | 功能 | 作用 |
|---|---|---|
| call <函数名> | 调用 | 将IP旧值压栈保存在函数的栈帧顶部 设置IP新值, 无条件转移到被调用函数的第一条指令 |
| ret | 返回 | 从函数的栈帧顶部找到IP旧值, 让他出栈并恢复IP寄存器 |
- 访问栈帧
x86架构默认以4字节做栈的操作单位
ebp: 指向当前栈帧的底部(高地址)
esp: 指向当前栈帧的顶部(低地址)
push ; 先让esp-4, 再将压入, 狗可以试立即数, 寄存器, 主存地址
Pop ; 栈顶元素出栈写入, 再esp+4 , 可以试寄存器, 主存地址
或者
mov ; 结合esp, ebp指针访问栈帧数据
- 切换栈帧
; 保存上一层函数栈帧, 设置当前函数栈帧
push ebp
mov ebp esp
或者
enter
; 恢复上一层函数的栈帧
mov esp, ebp
pop ebp
或者
leave

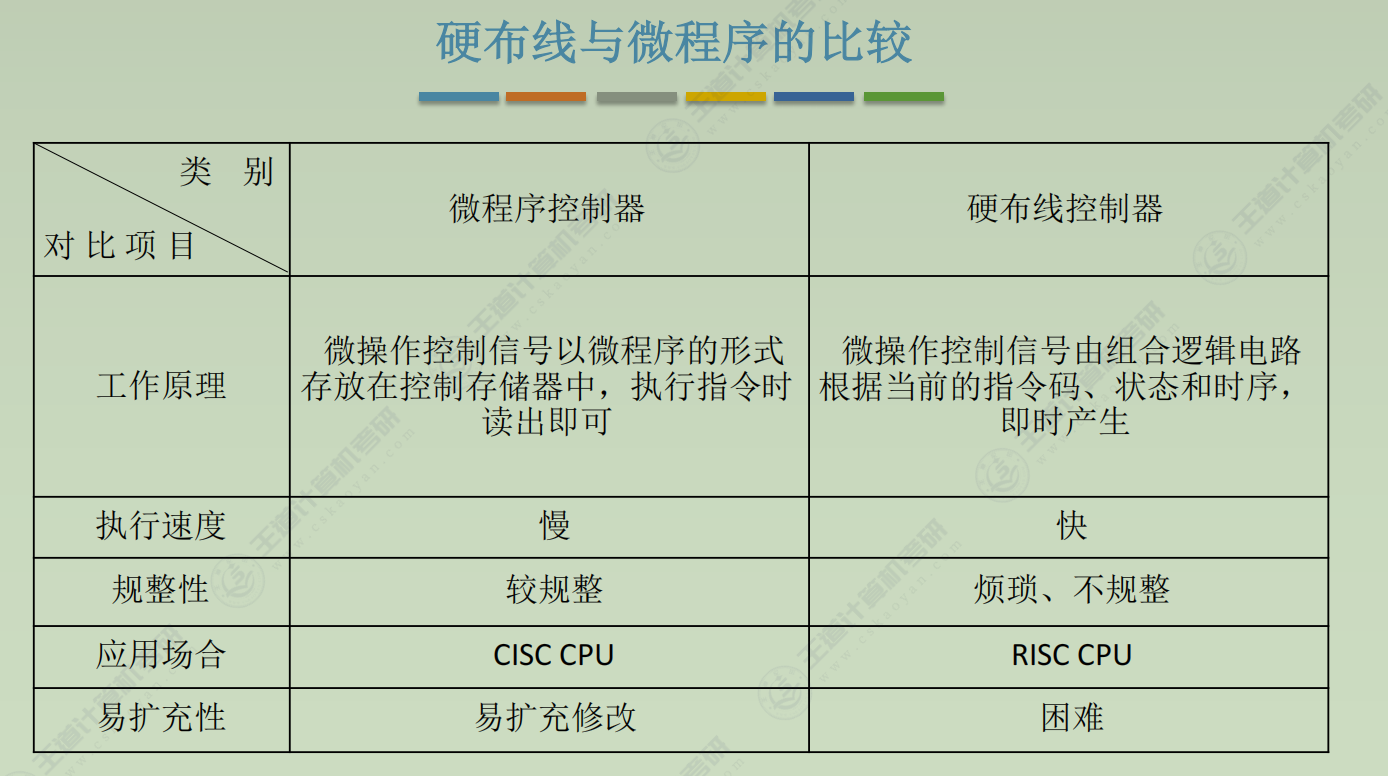
CISC, RISC
| 对比项目 | CISC | RISC |
|---|---|---|
| 指令系统 | 复杂,庞大 | 简单,精简 |
| 指令数目 | 一般大于200条 | 一般小于100条 |
| 指令字长 | 不固定 | 定长 |
| 可访存指令 | 不加限制 | 只有Load/Store指令 |
| 各种指令执行时间 | 相差较大 | 绝大多数在一个周期内完成 |
| 各种指令使用频度 | 相差很大 | 都比较常用 |
| 通用寄存器数量 | 较少 | 多 |
| 目标代码 | 难以用优化编译生成高效的目标代码程序 | 采用优化的编译程序,生成代码较为高效 |
| 控制方式 | 绝大多数为微程序控制 | 绝大多数为组合逻辑控制 |
| 指令流水线 | 可以通过一定方式实现 | 必须实现 |
中央处理器
CPU的功能和结构
-
功能
-
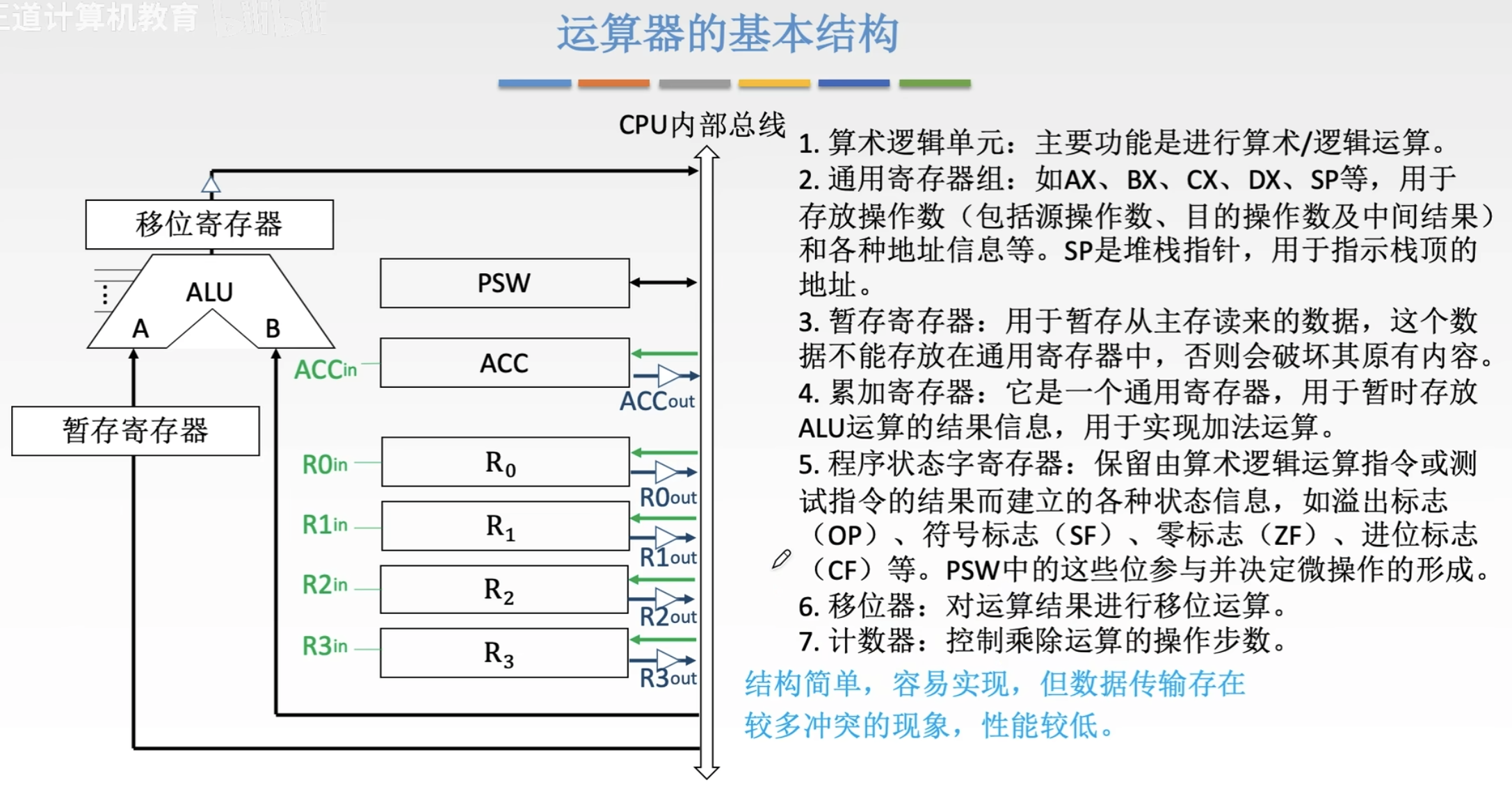
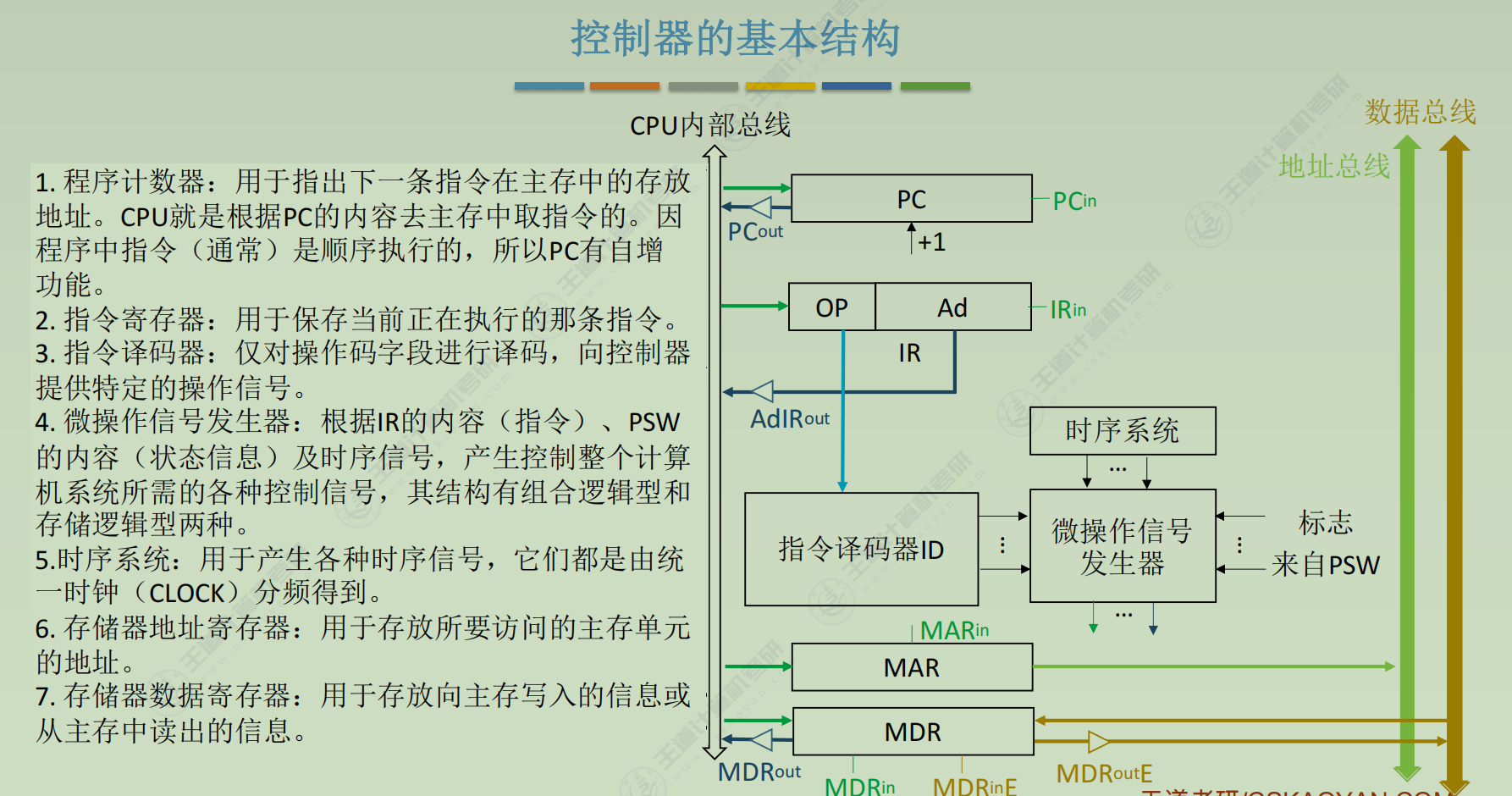
基本结构
指令执行过程
指令周期
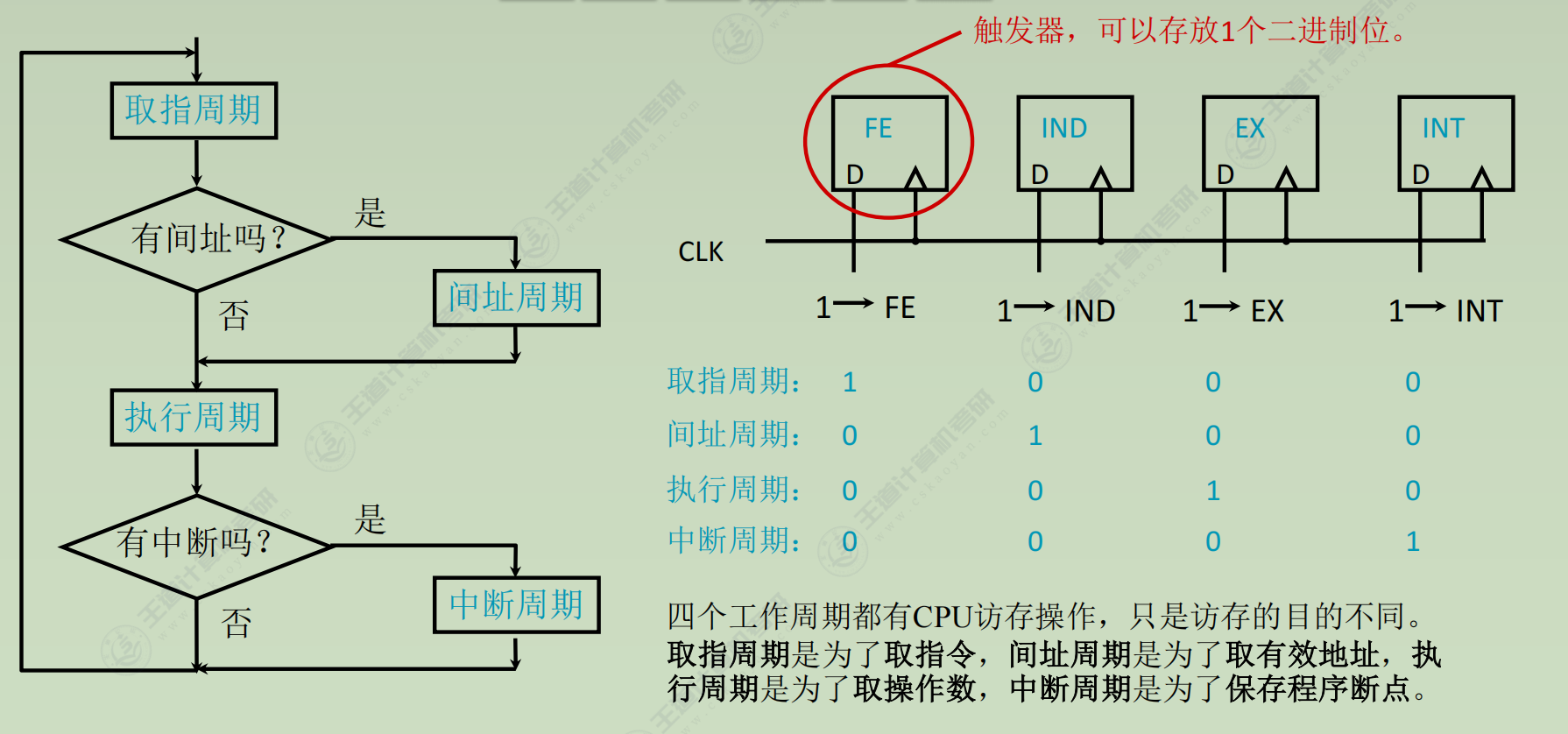
数据流
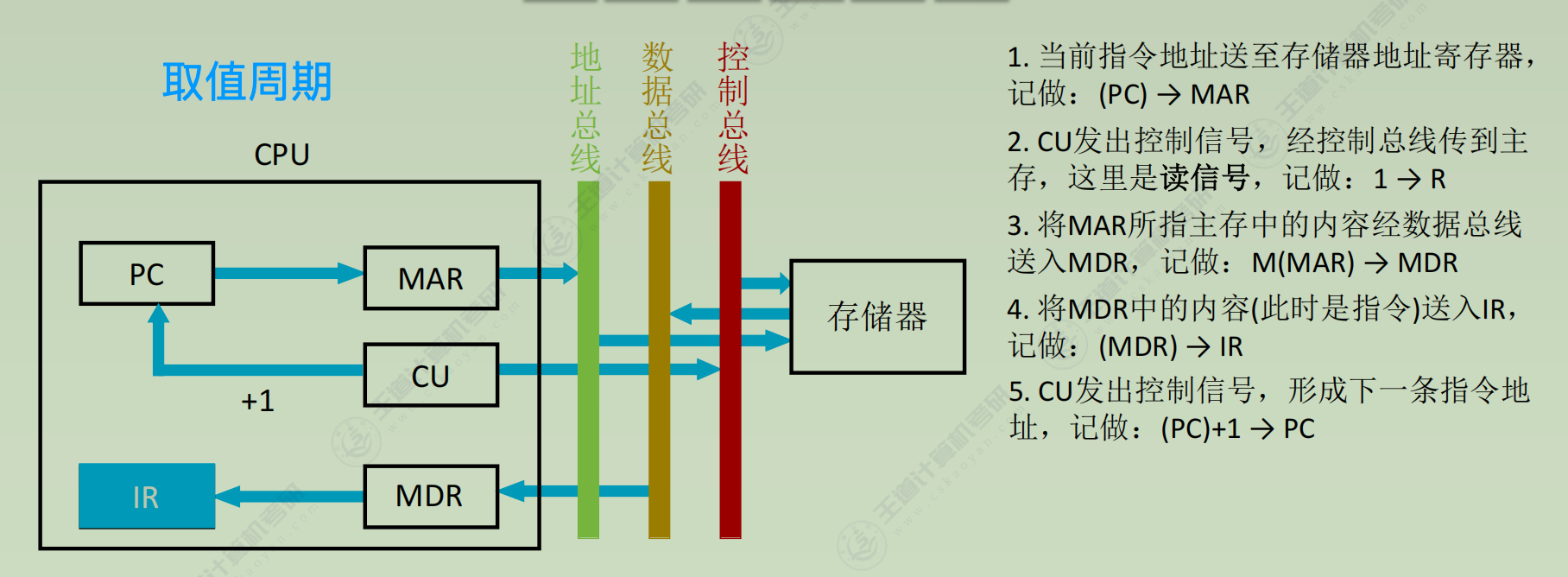
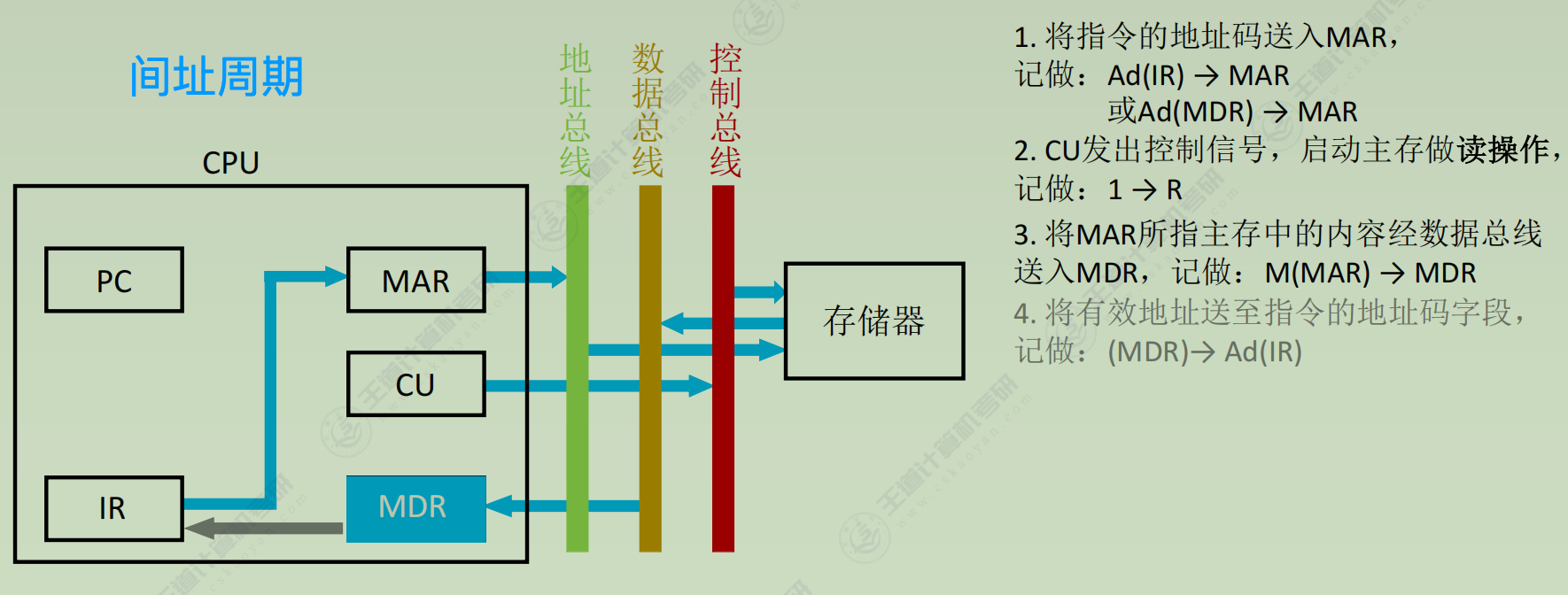
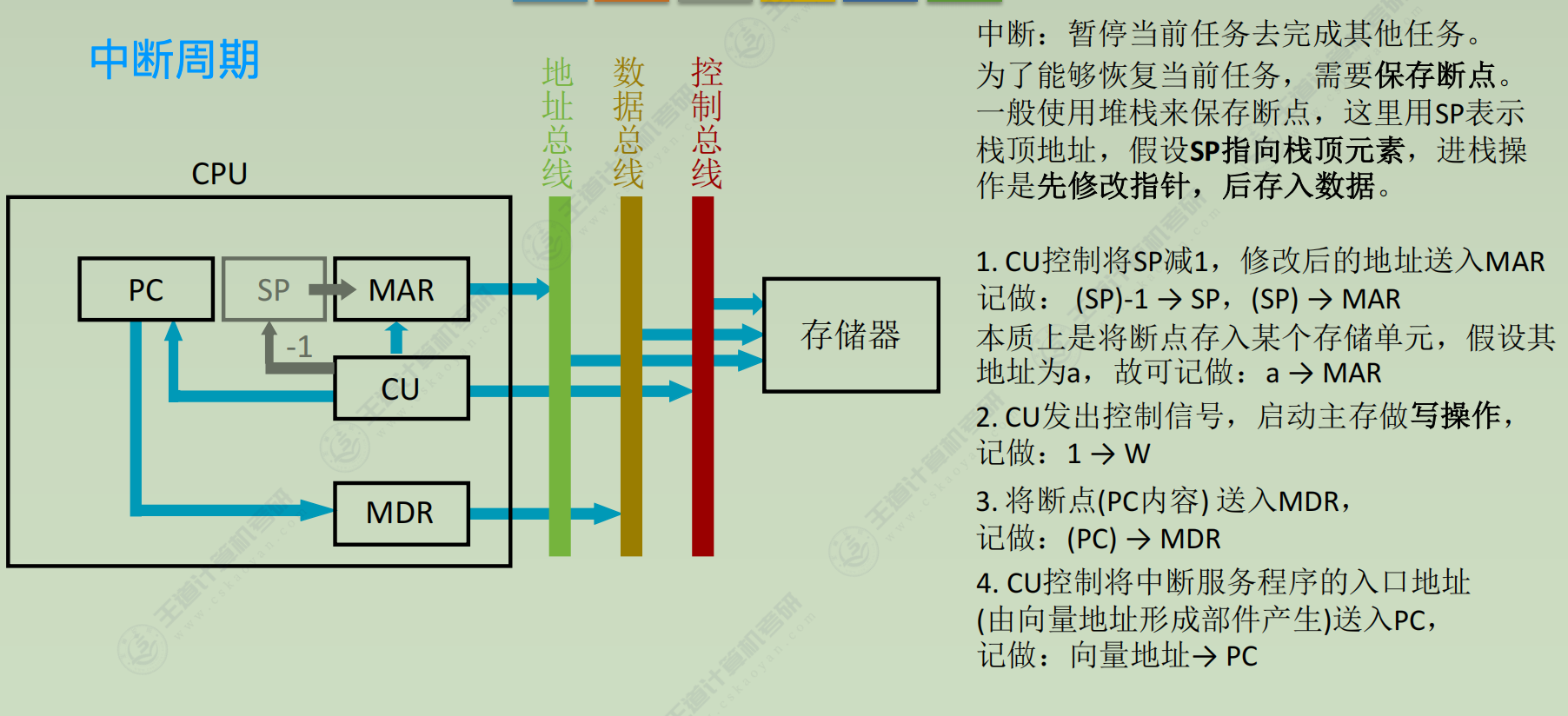
数据通路
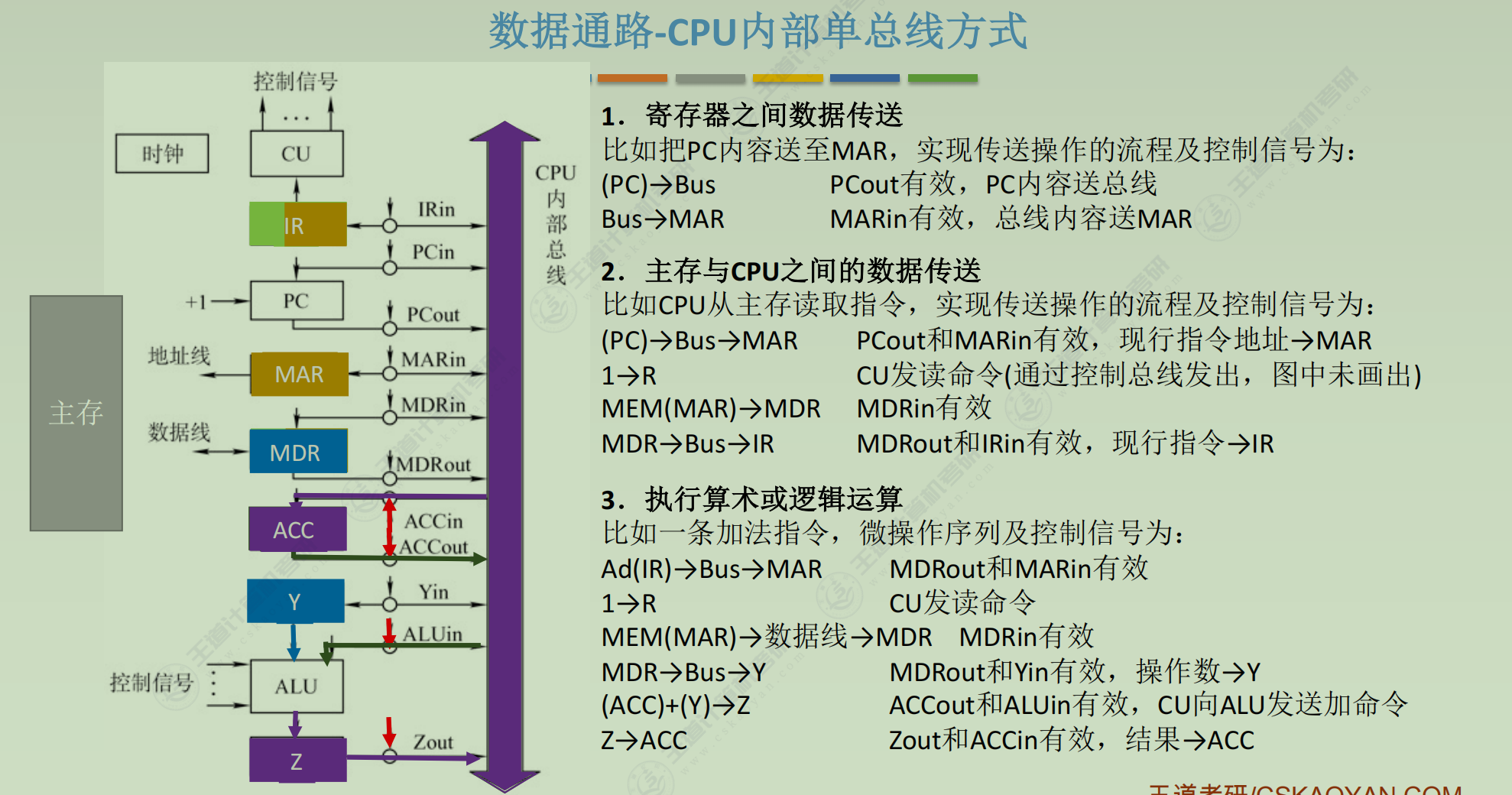
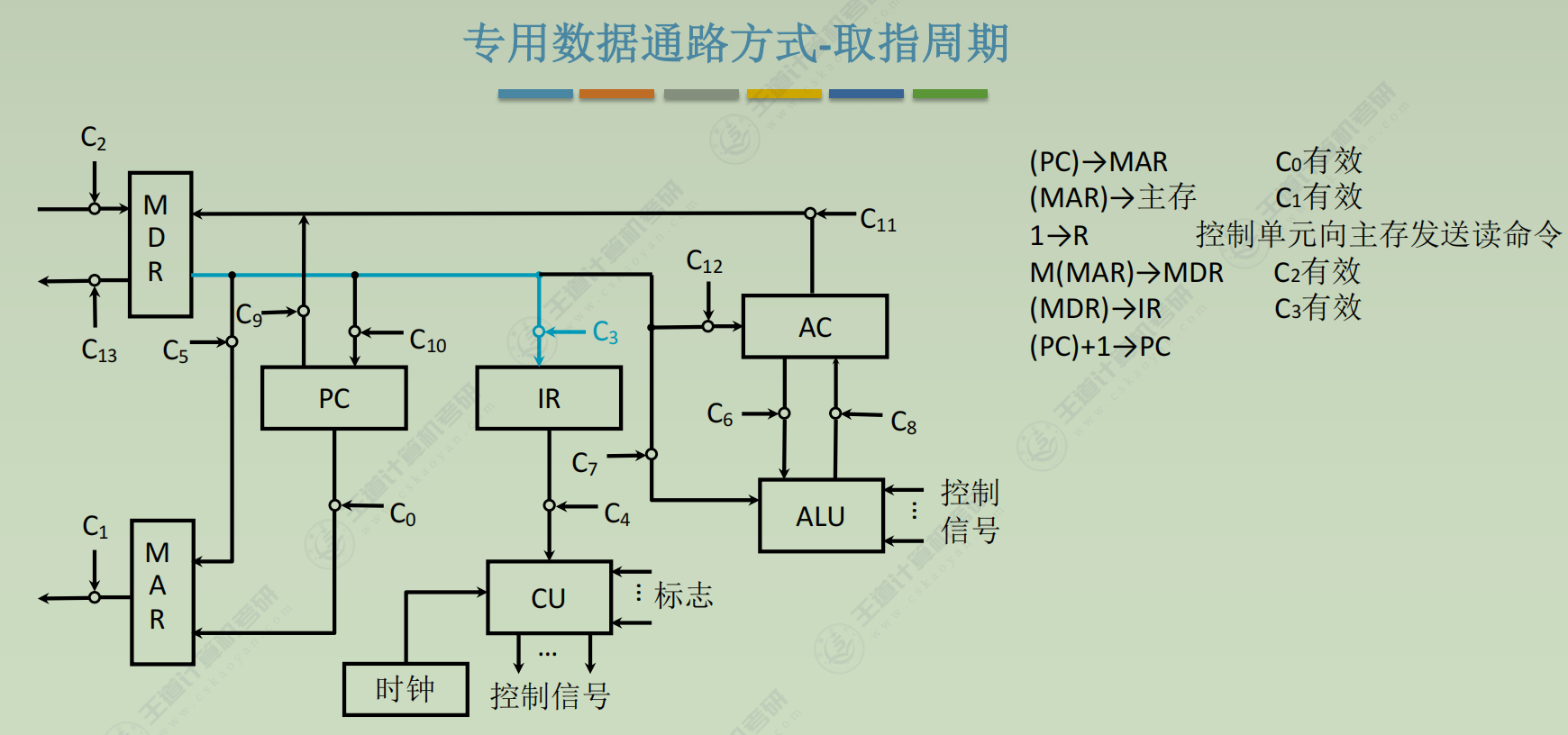
控制器
硬布线控制器
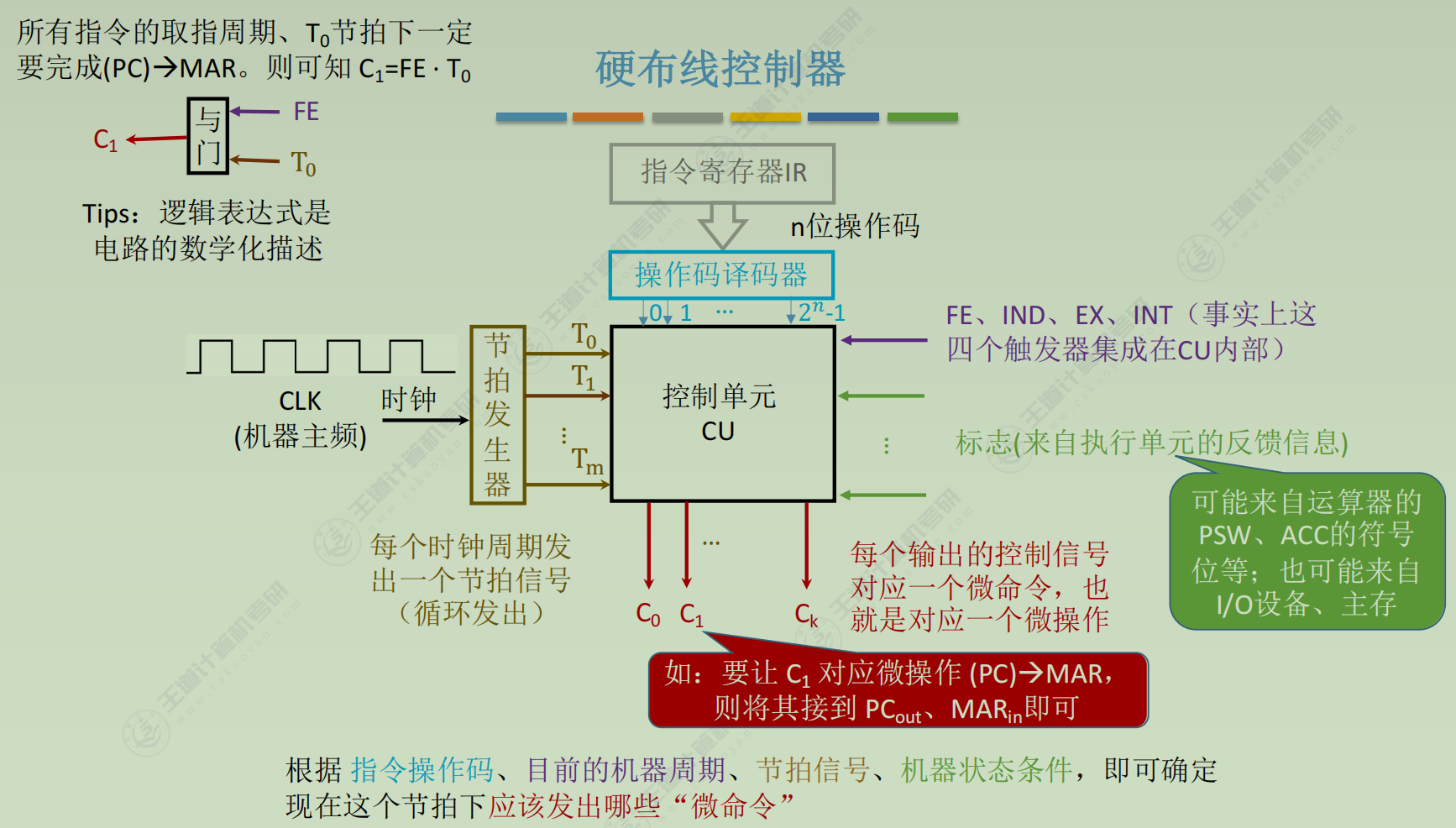
设计(假设采用同步控制方式(定长机器周期),一个机器周期内安排3个节拍)
-
分析每个阶段的微操作序列(取值、间址、执行、中断四个阶段)
确定哪些指令在什么阶段、在什么条件下会使用到的微操作
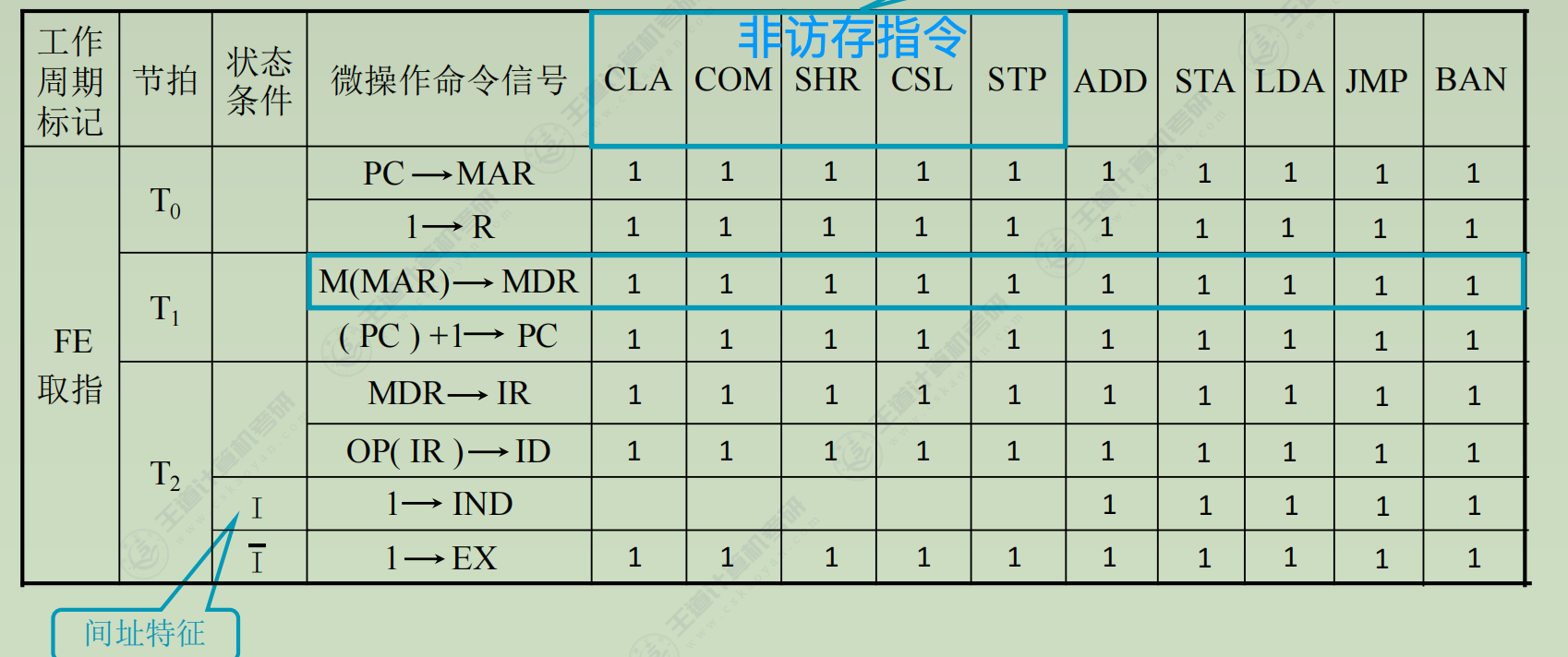
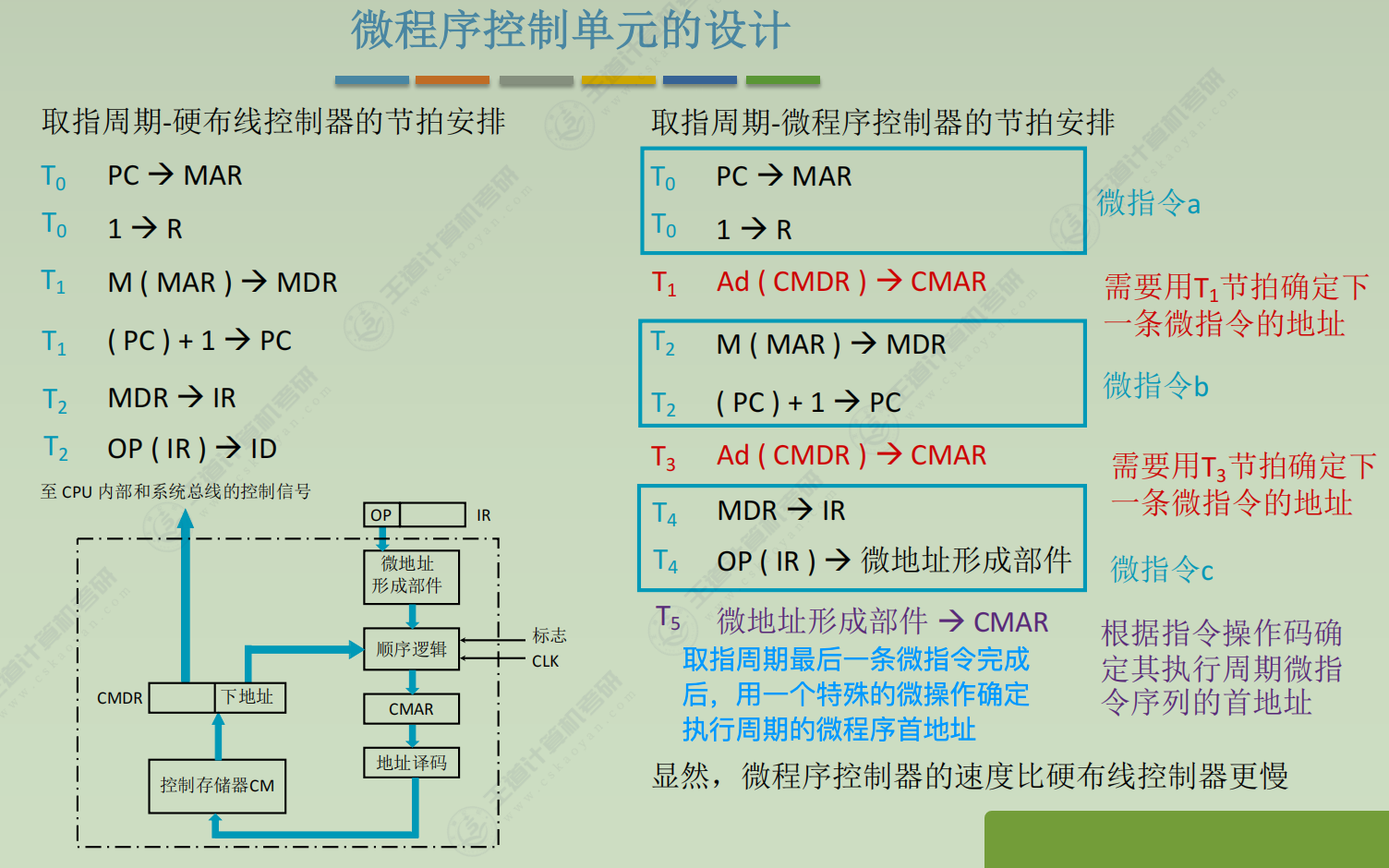
(1) 取指周期(所有指令都一样)- PC → MAR
- 1 → R
- M(MAR) → MDR
- MDR → IR
- OP(IR) → ID (ID是指令译码器Instruction Decoder)
- (PC) + 1 → PC
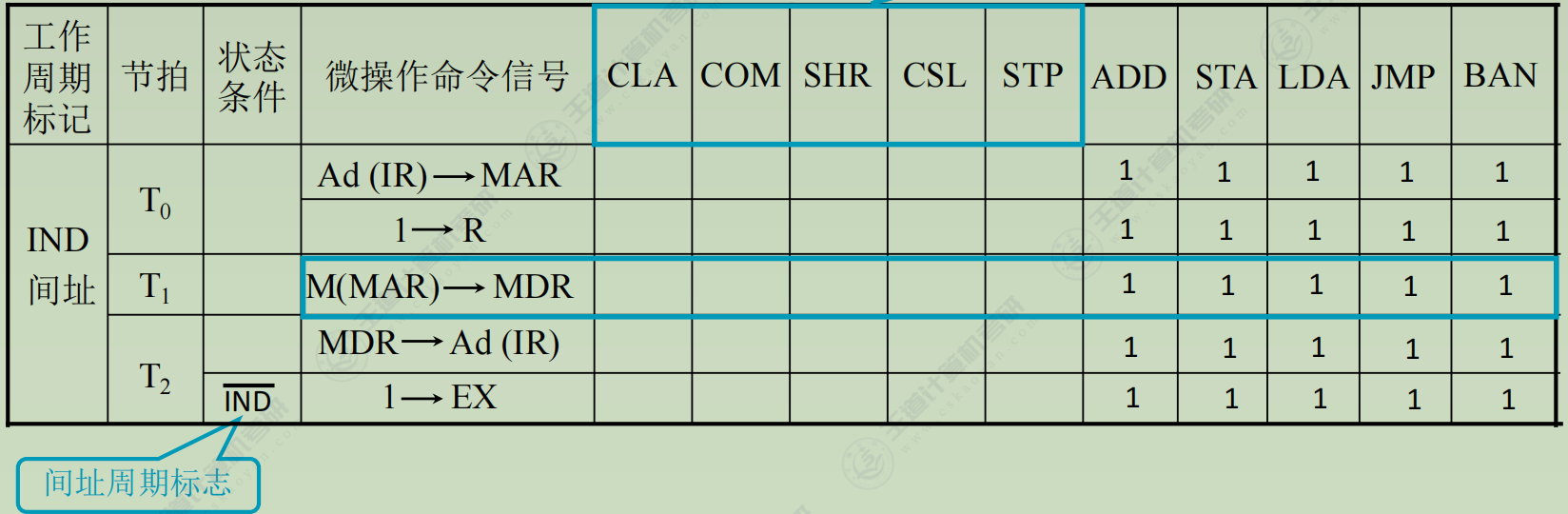
(2) 间址周期(所有指令都一样) - Ad(IR) → MAR
- 1 → R
- M(MAR) → MDR
- MDR → Ad(IR)
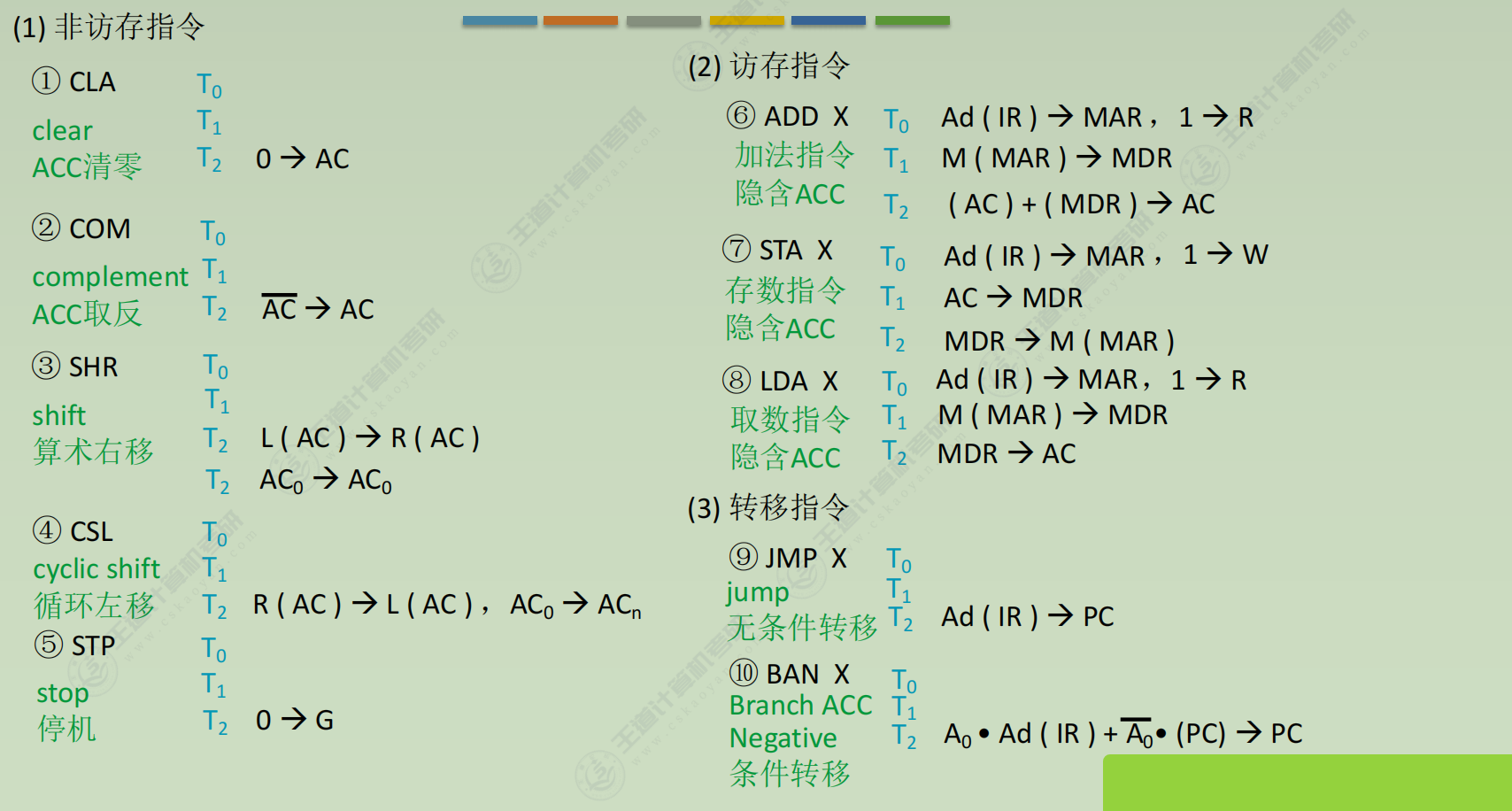
(3) 执行周期(各不相同)
① CLA
- 0 → AC (注:很多地方把ACC简写为AC)
- clear ACC 指令
- ACC清零
② LDA X
- 取数指令,把X所指内容取到ACC
- Ad(IR) → MAR
- 1 → R
- M(MAR) → MDR
- MDR → AC
③ JMP X
- 无条件转移
- Ad(IR) → PC
④BAN X
- Branch ACC Negative 条件转移,当ACC为负时转移
- A₀ • Ad(IR) + A₀ • (PC) → PC (注:负数符号位为1)
-
选择CPU的控制方式
采用定长机器周期还是不定长机器周期?每个机器周期安排几个节拍?
假设采用同步控制方式(定长机器周期),一个机器周期内安排3个节拍 -
安排微操作时序
如何用3个节拍完成整个机器周期内的所有微操作?
原则一 微操作的先后顺序不得随意更改
原则二 被控对象不同 的微操作, 尽量安排在一个节拍内完成
原则三 占用时间较短 的微操作, 尽量 安排在一个节拍内完成并允许有先后顺序
取值周期
T0
①PC → MAR
②1 → R (存储器空闲即可)
T1
③M(MAR) → MDR (在①之后)
④(PC) + 1 → PC (在①之后)
T2
⑤MDR → IR (在③之后)
⑥OP(IR) → ID (在④之后)
间址周期
T0
① Ad(IR) → MAR
② 1 → R (存储器空闲即可)
T1
③ M(MAR) → MDR (在①之后)
T2
④ MDR → Ad(IR) (在③之后)
执行周期
中断周期, 这些操作由中断隐指令[指中断周期由硬件完成的一系列操作]完成
T0
① a → MAR
② 1 → W (存储器空闲即可)
③ 0 → EINT (硬件关中断)
T1
④(PC) → MDR (内部数据通路空闲即可)
T2
⑤MDR → M(MAR) (在③之后)
⑥向量地址 → PC (在③之后)
- 电路设计
-
列出操作时间表
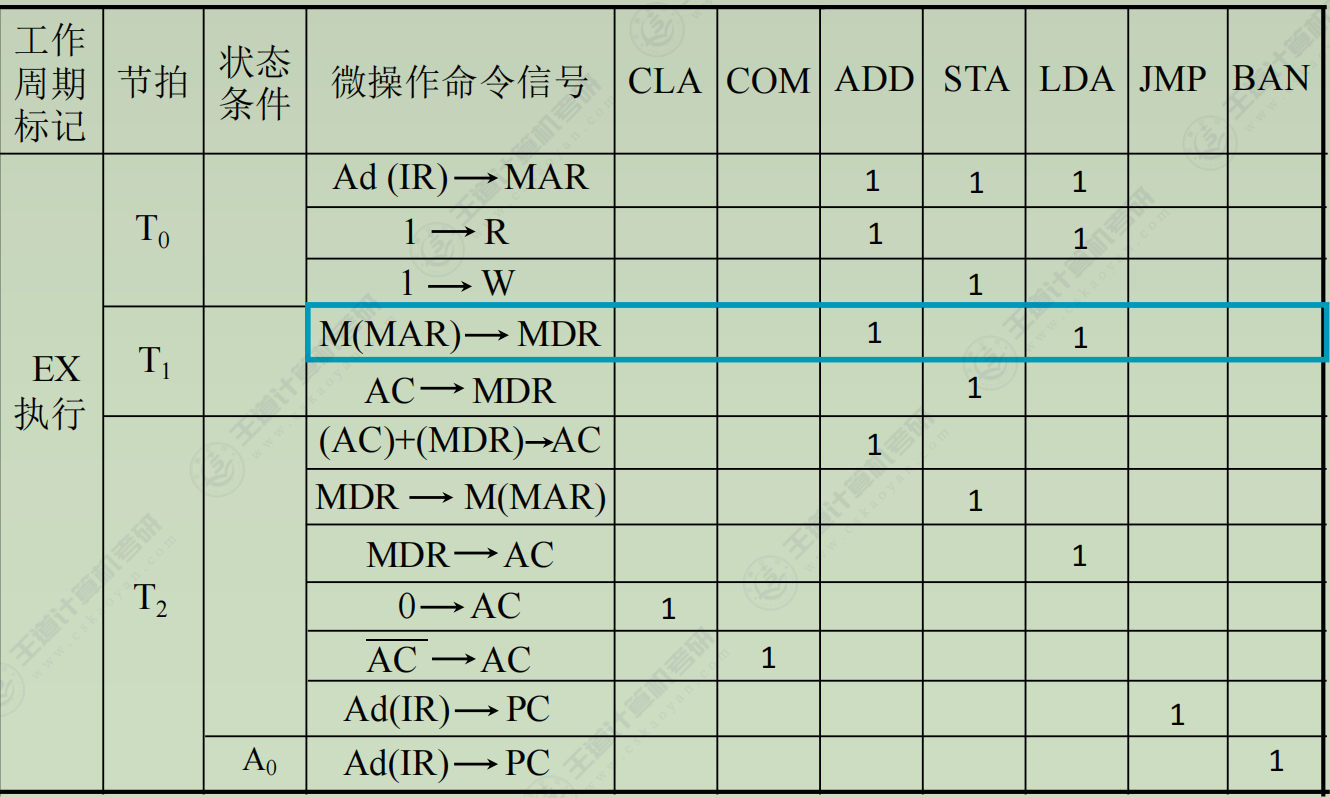
-
写出微操作命令的最简表达式
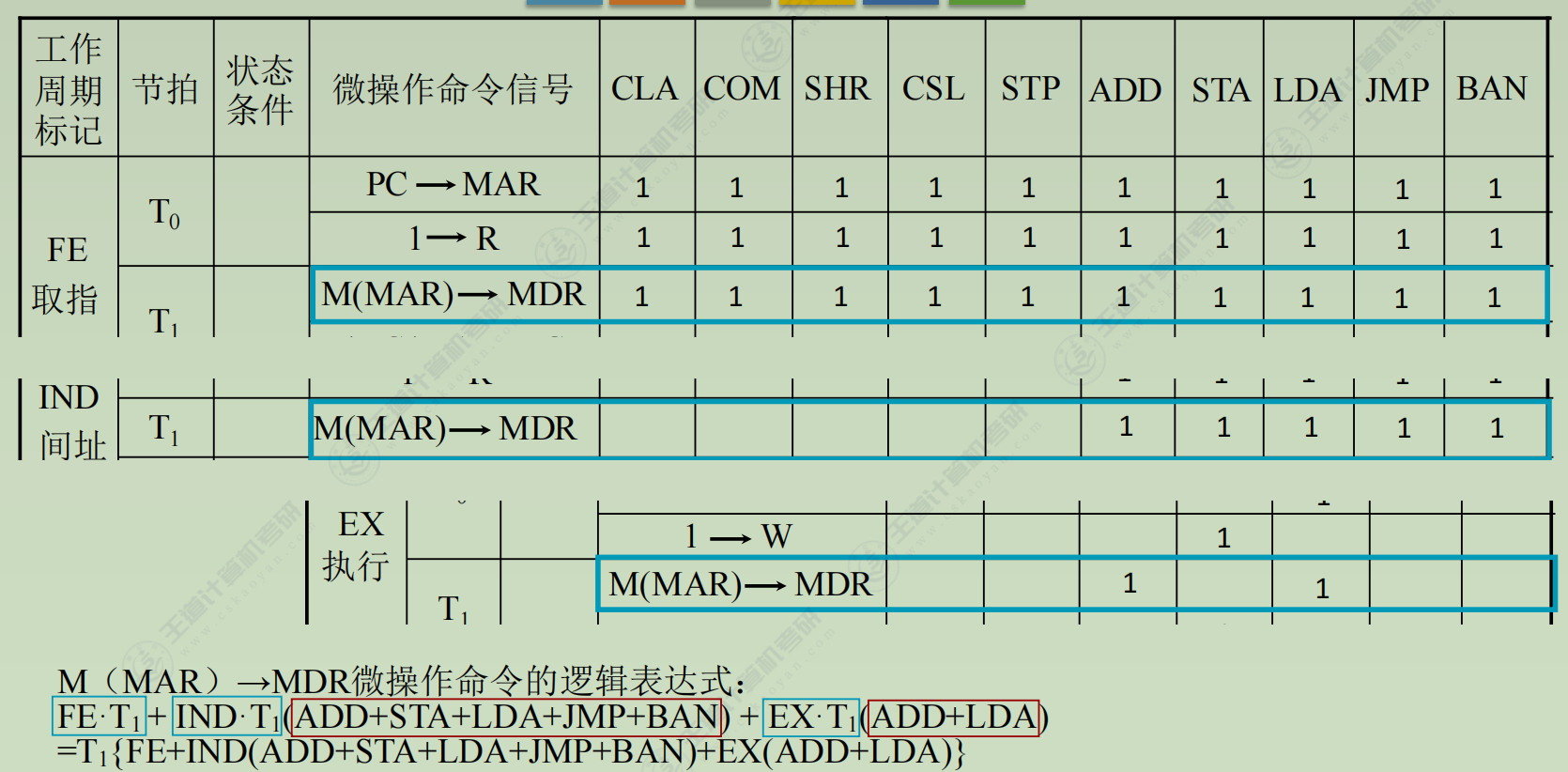
-
画出逻辑图
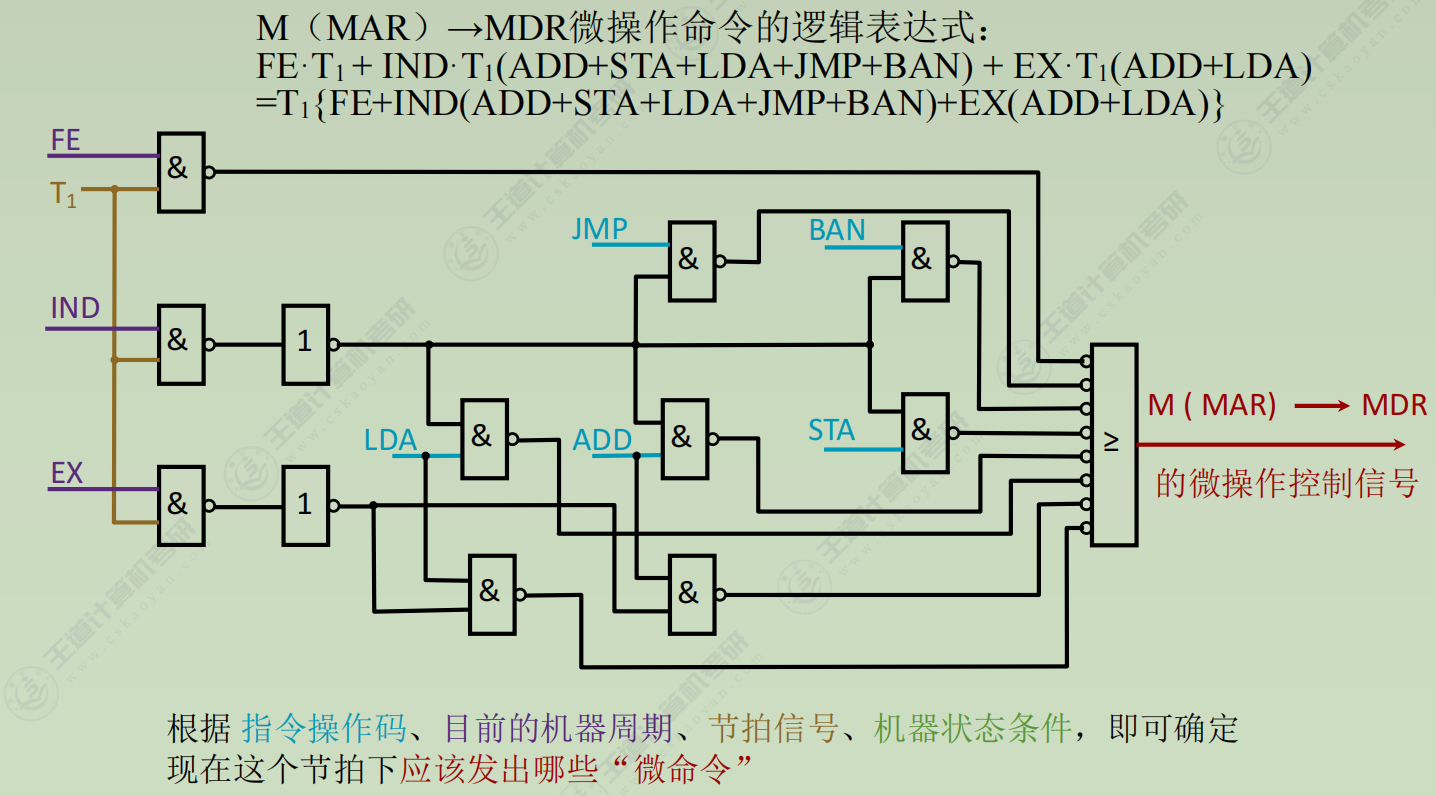
-
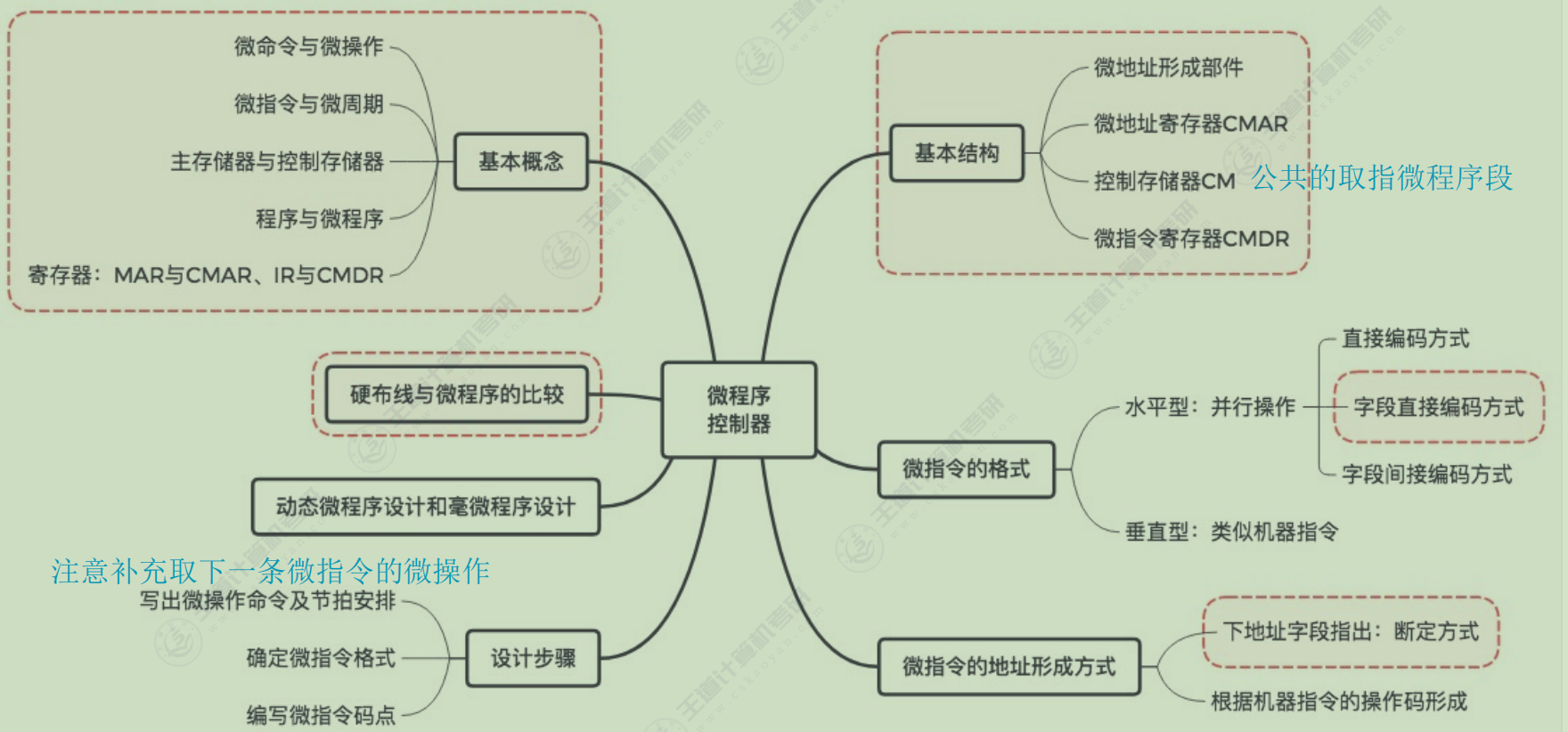
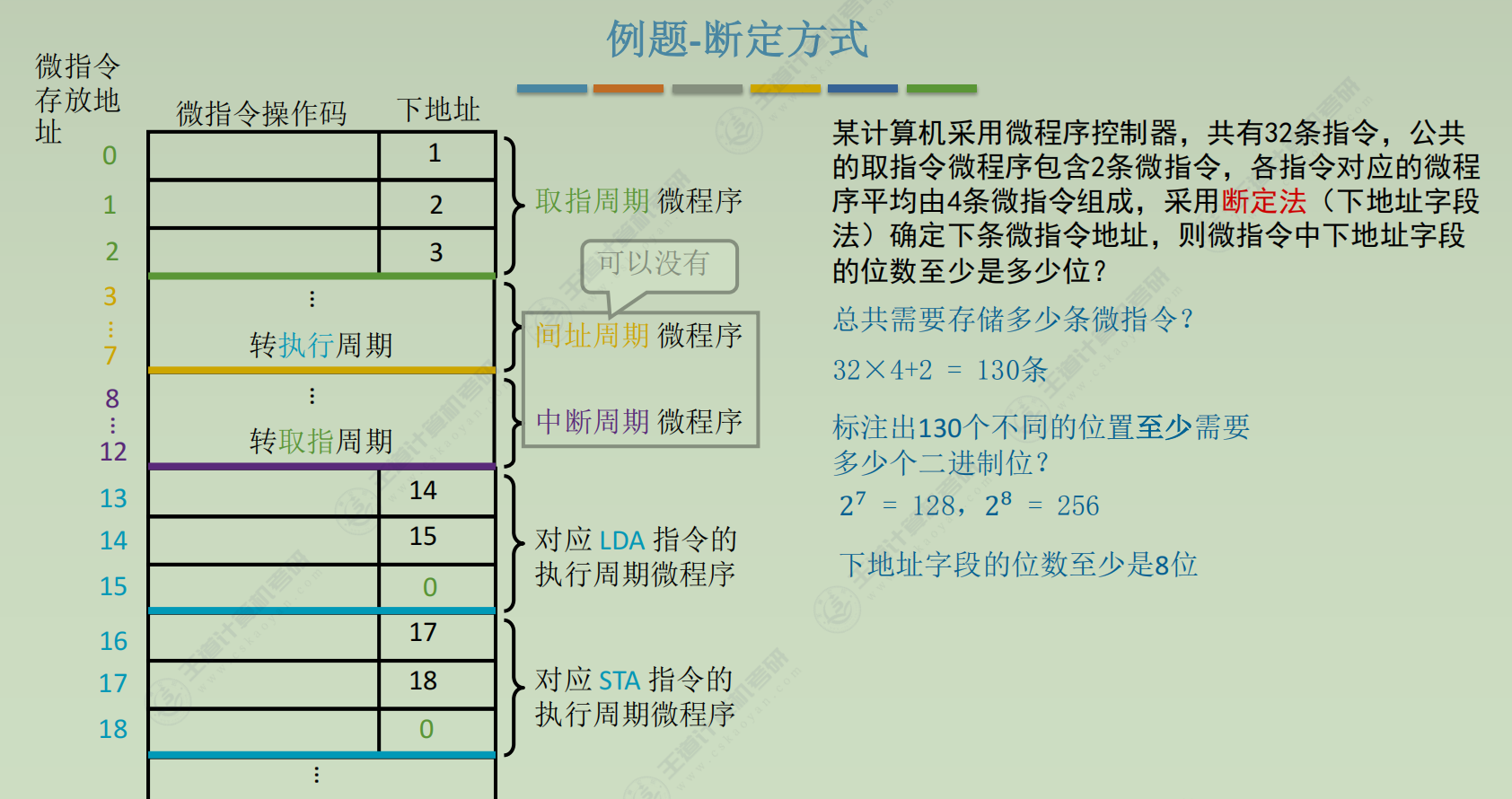
微程序控制器
程序>指令=微程序>微指令>微命令=微操作
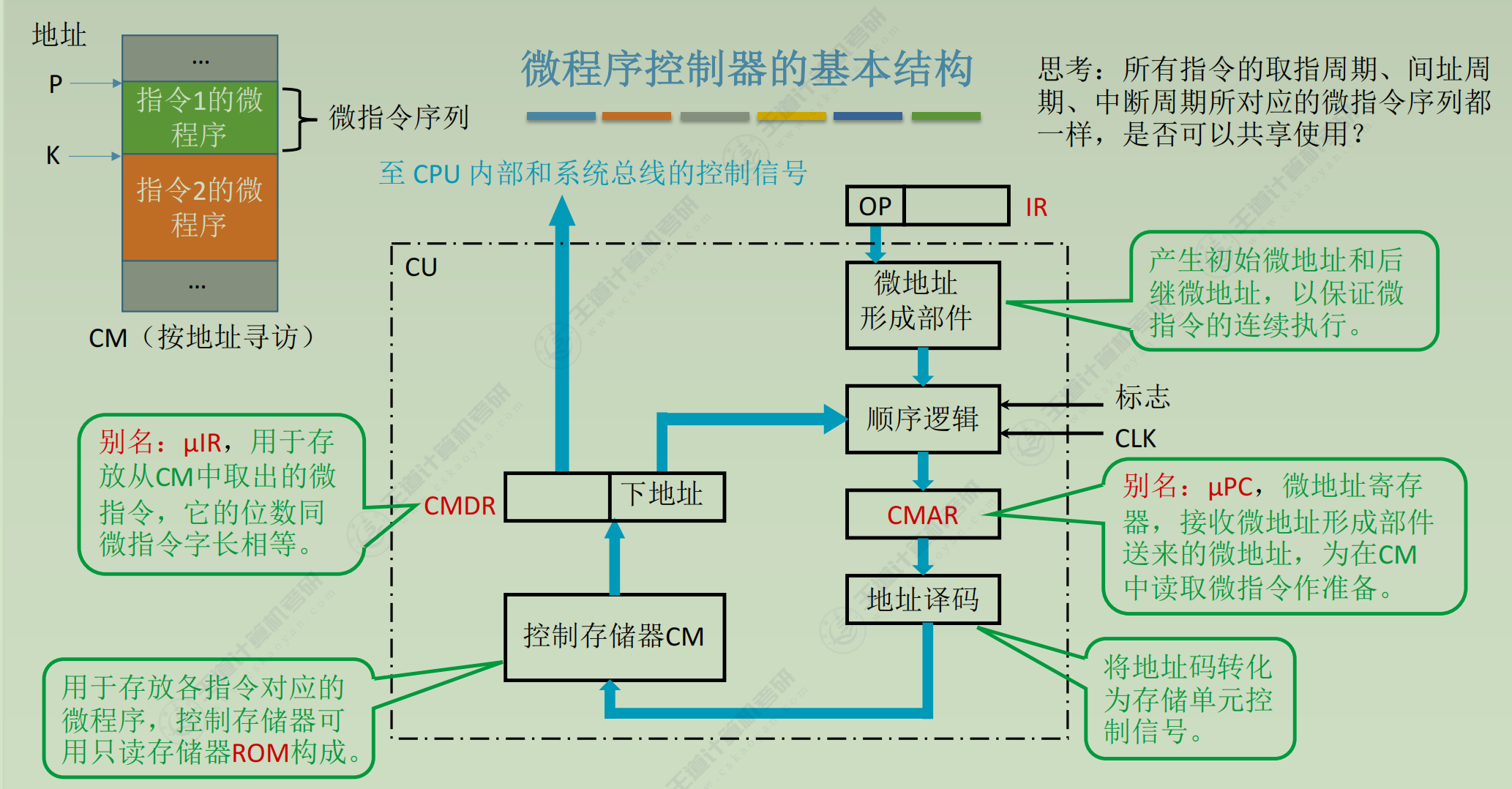
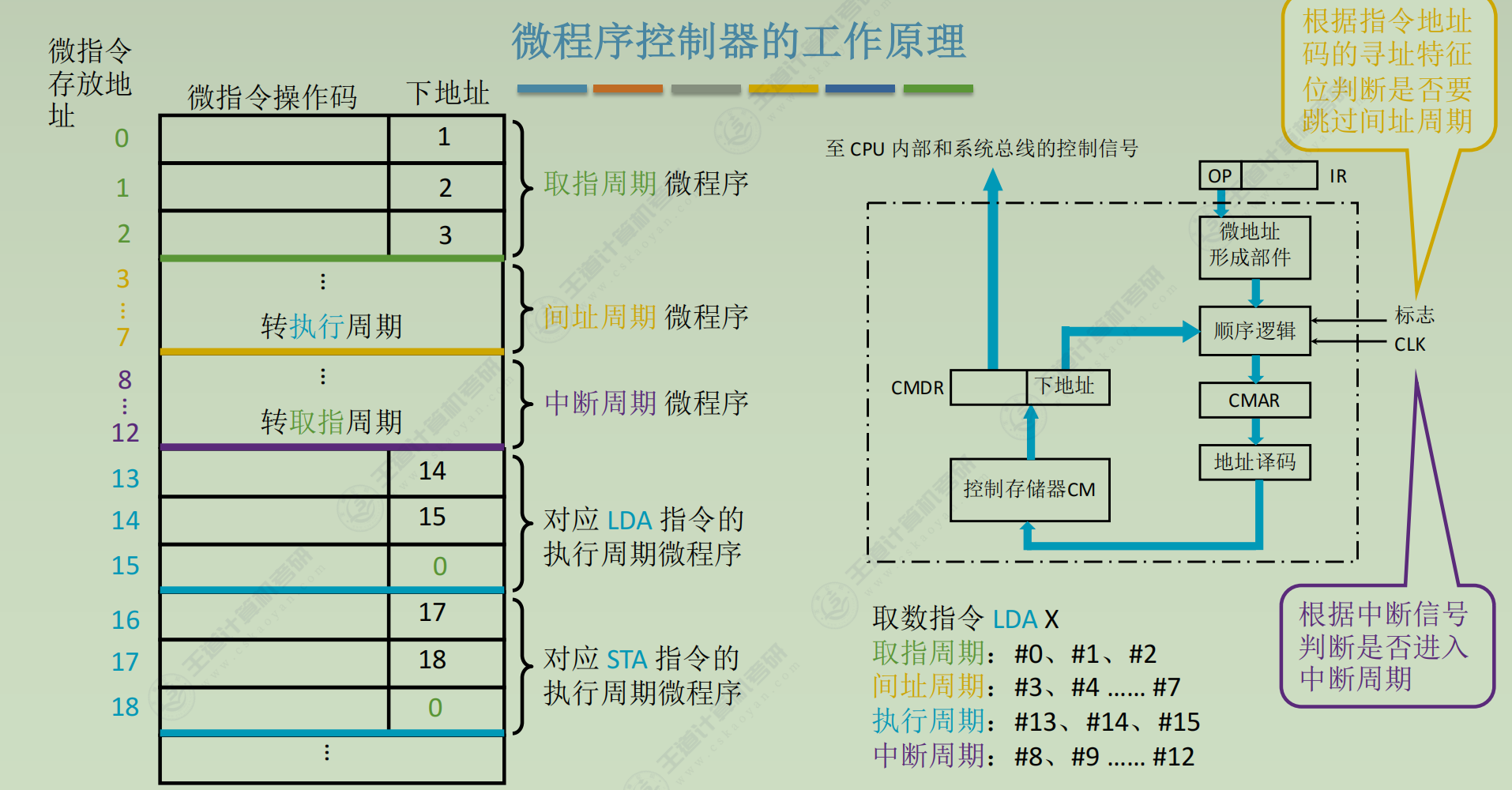

微指令设计
-
格式
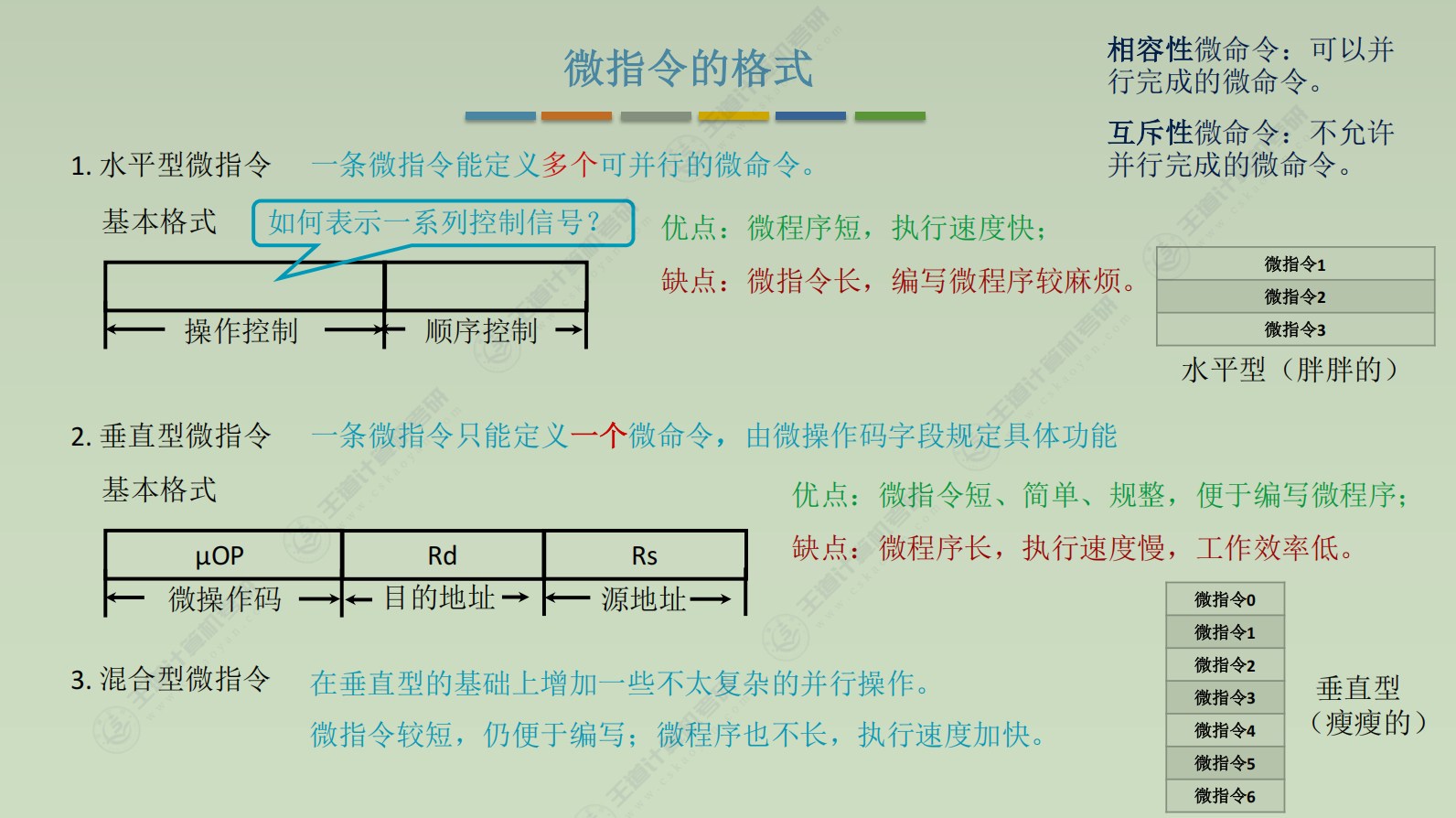
-
编码方式


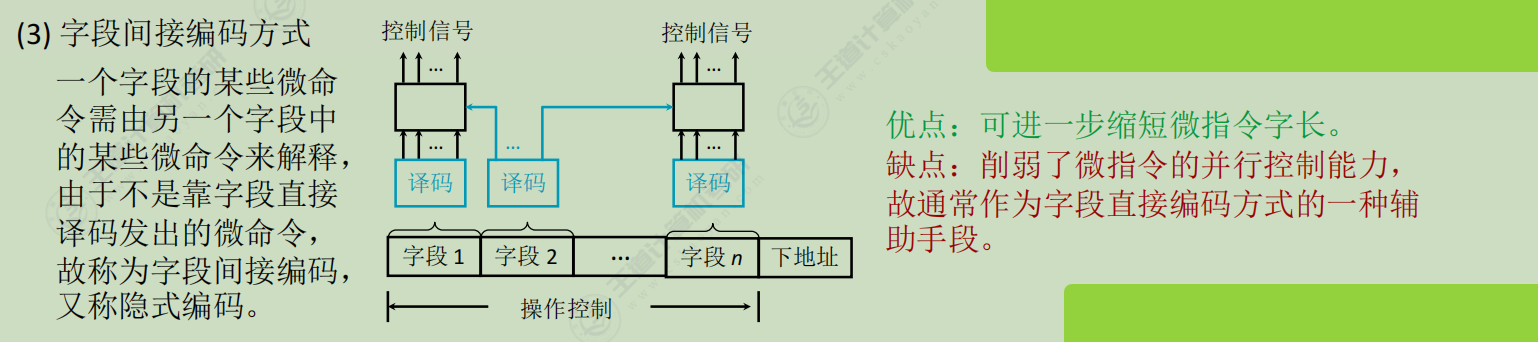
-
地址形成方式
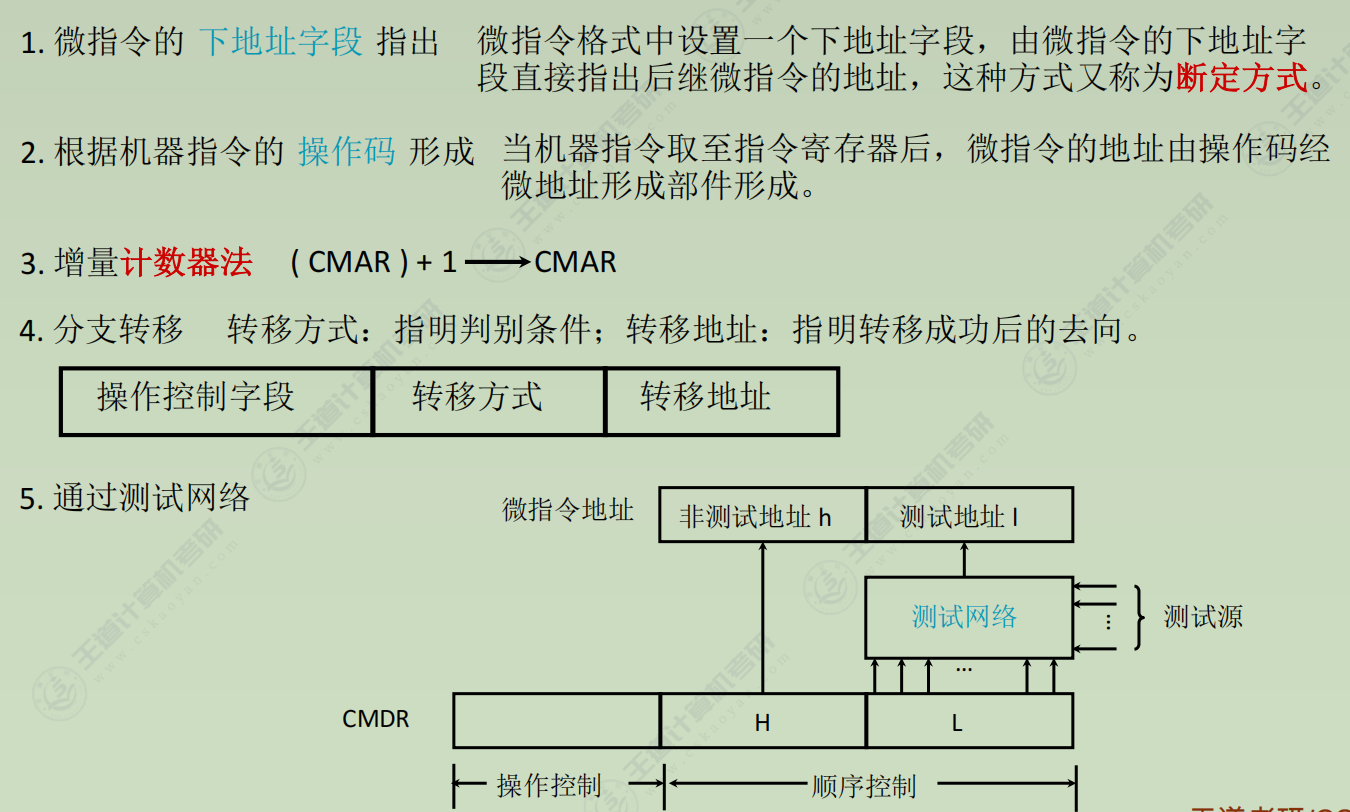

微程序控制单元的设计


异常和中断机制
指令流水线
基本概念
- 表示方法
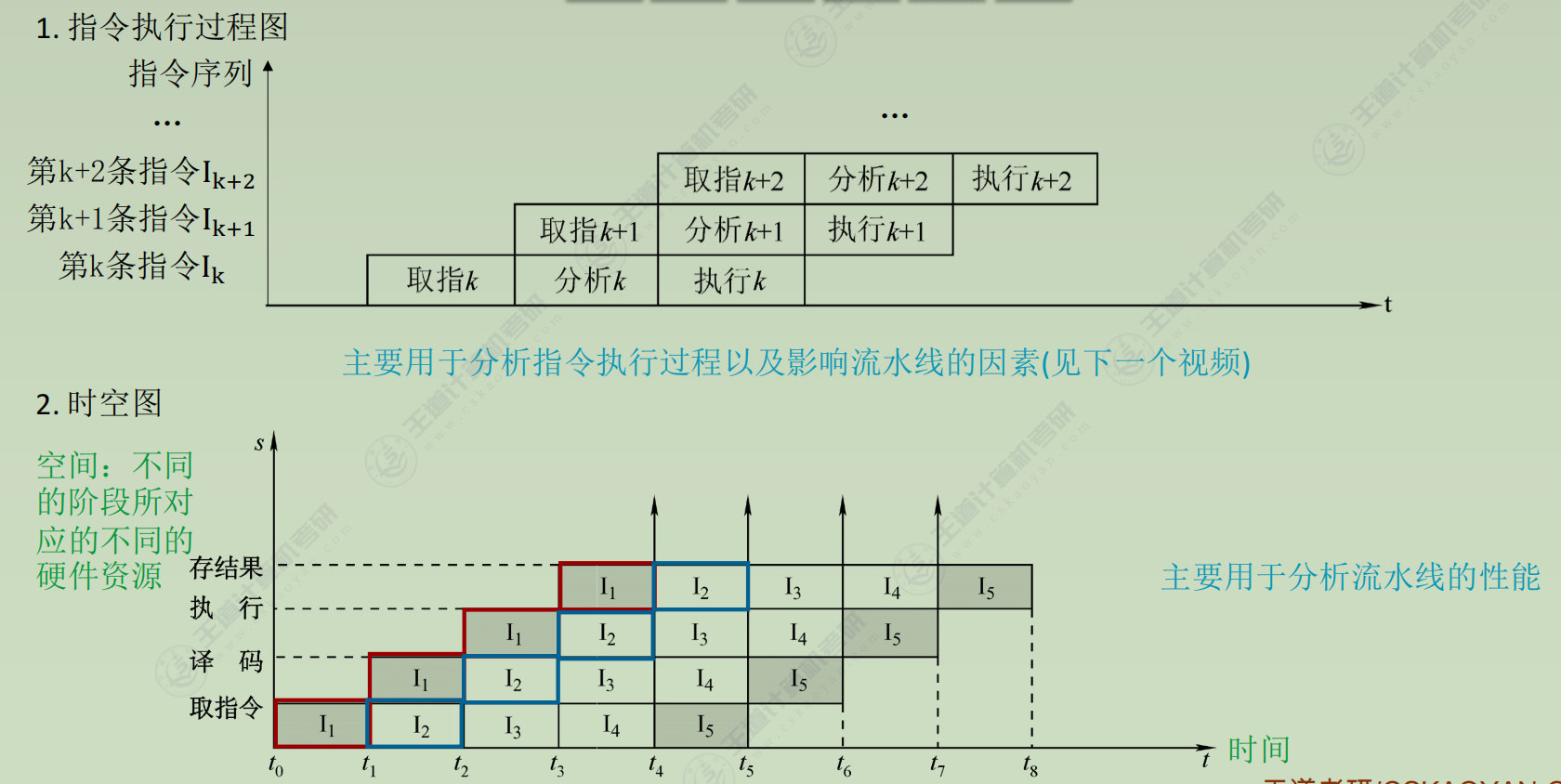
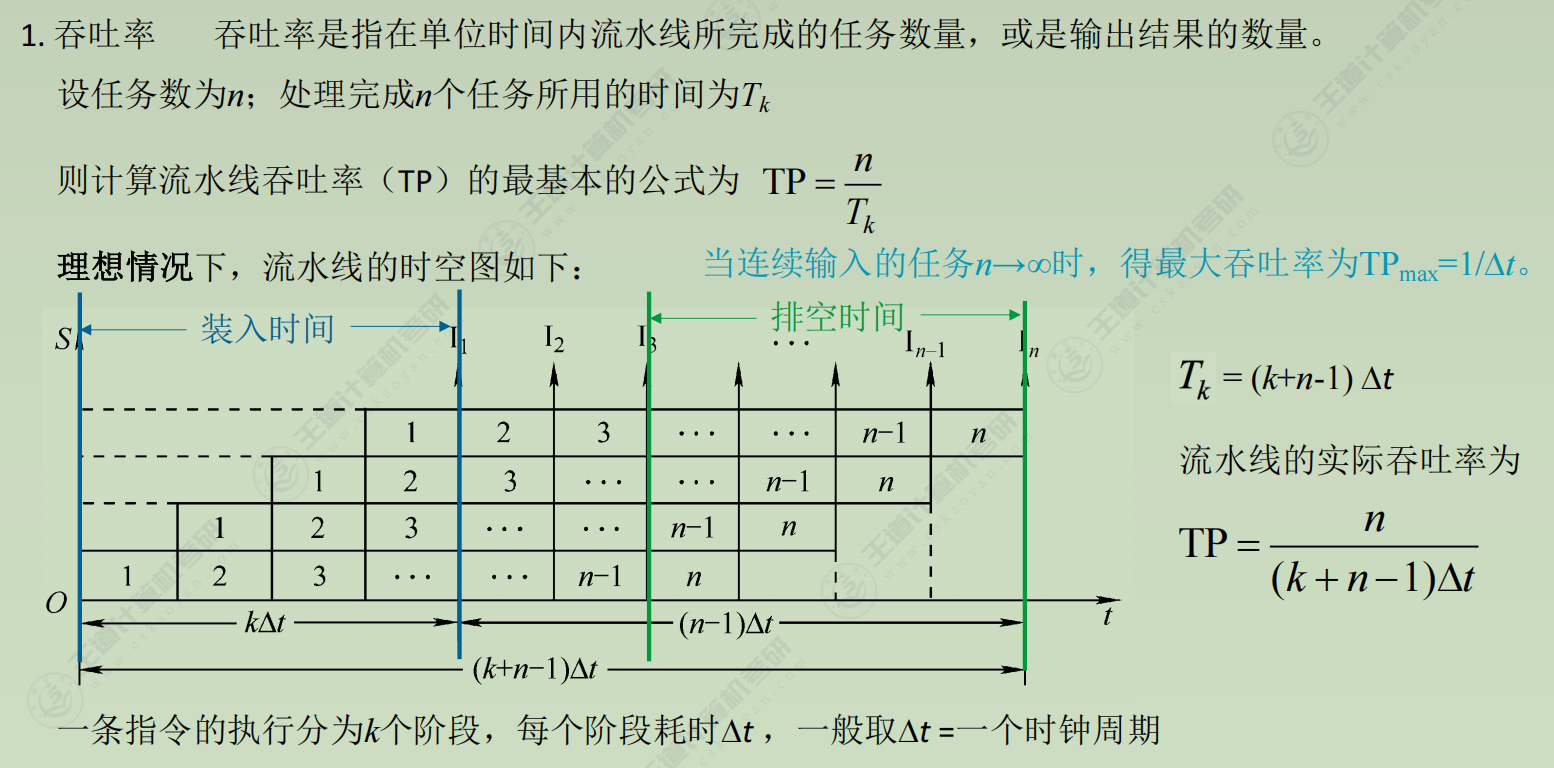
性能指标


影响因素
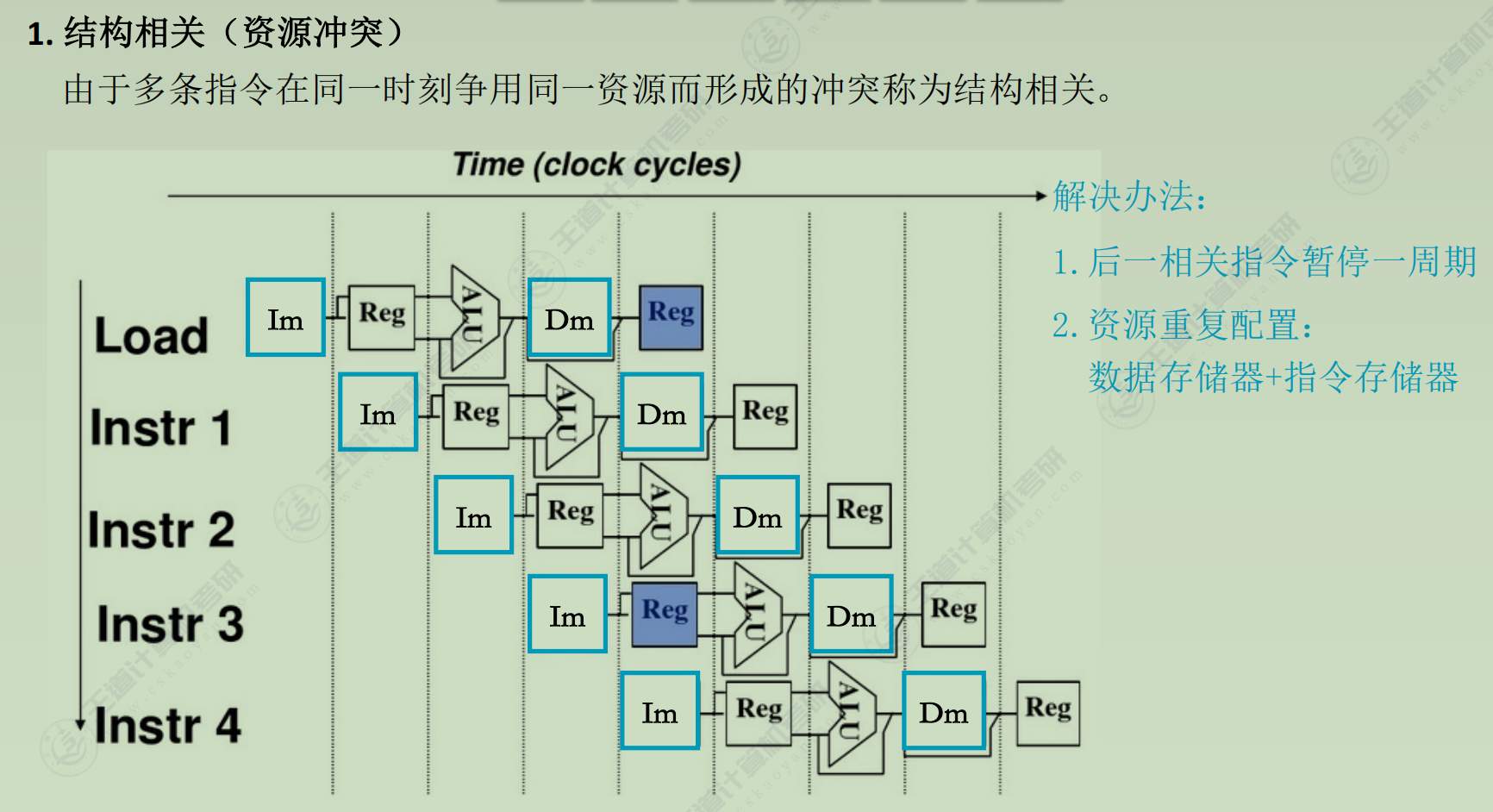
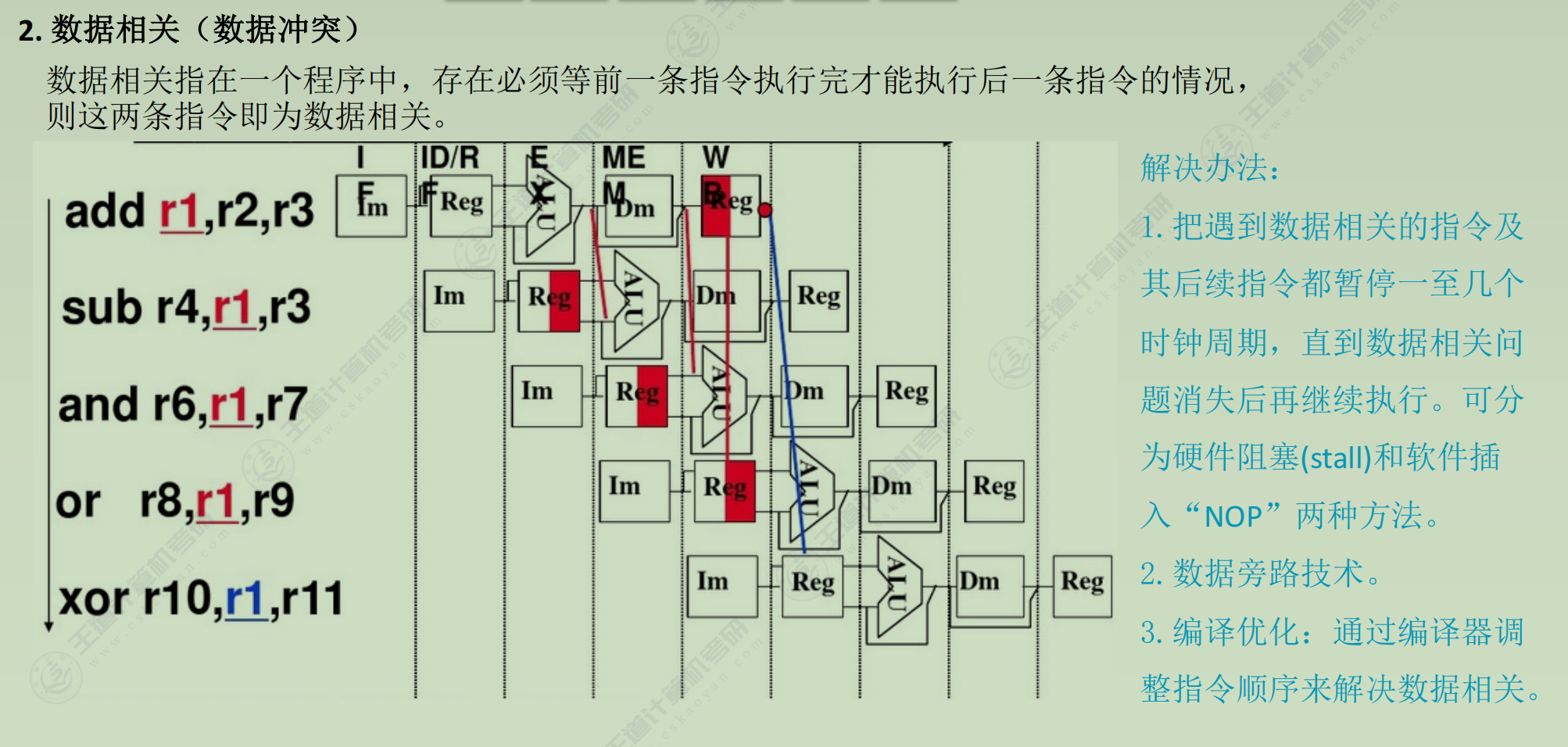
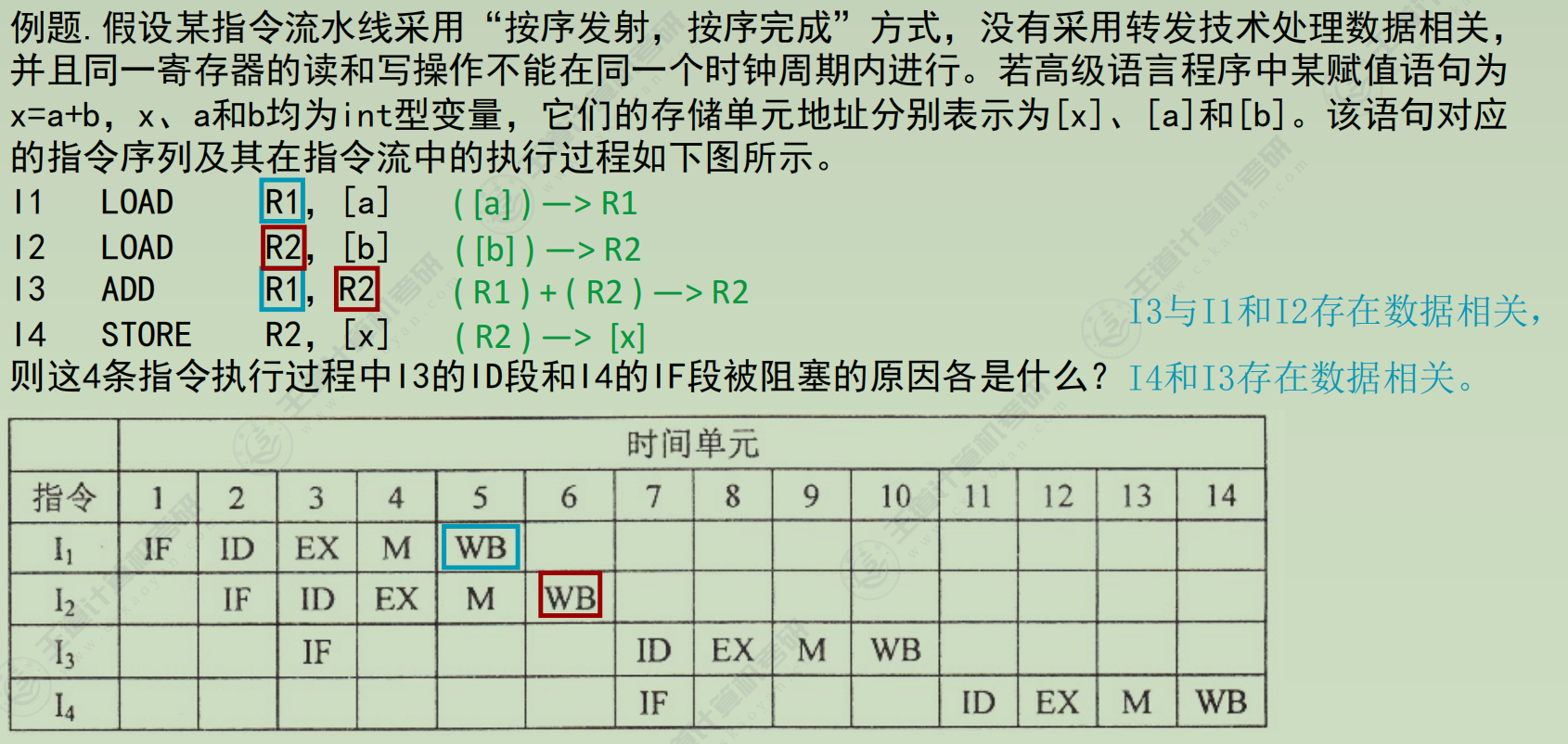

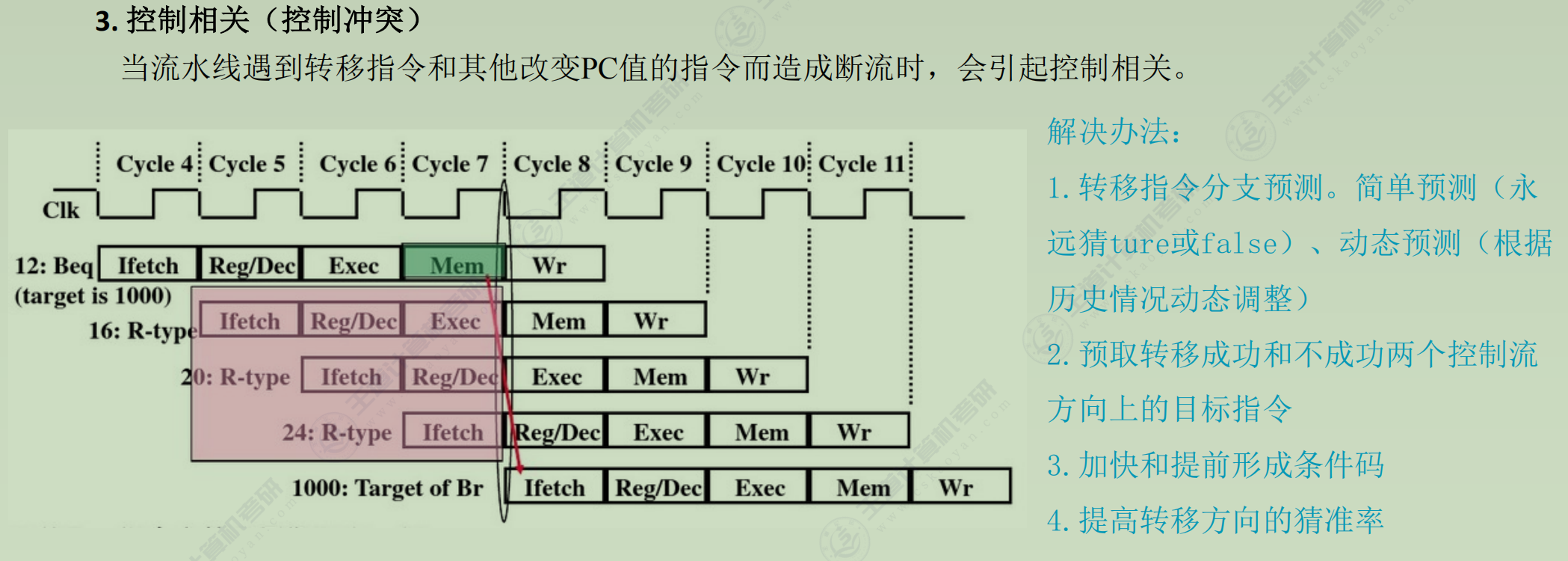
分类
-
根据流水线使用的级别
部件功能级流水就是将复杂的算术逻辑运算组成流水线工作方式。例如,可将浮点加法操作分成求阶差、对阶、尾数相加以及结果规格化等4个子过程。
处理机级流水是把一条指令解释过程分成多个子过程,如前面提到的取指、译码、执行、访存及写回5个子过程
处理机间流水是一种宏流水,其中每一个处理机完成某一专门任务,各个处理机所得到的结果需存放在与下一个处理机所共享的存储器中 -
可实现的功能
单功能
仅支持一种固定功能的流水线(如专用浮点运算单元)。
多功能
通过动态配置各段连接方式,支持多种功能(如既可做浮点加法又能做乘法)。 -
同一时间内各段之间的连接方式
静态流水线指在同一时间内,流水线的各段只能按同一种功能的连接方式工作
动态流水线指在同一时间内,当某些段正在实现某种运算时,另一些段却正在进行另一种运算。这样对提高流水线的效率很有好处,但会使流水线控制变得很复杂 -
流水线的各个功能段之间是否有反馈信号
线性流水线中,从输入到输出,每个功能段只允许经过一次,不存在反馈回路。
非线性流水线存在反馈回路,从输入到输出过程中,某些功能段将数次通过流水线,这种流水线适合进行线性递归的运算。
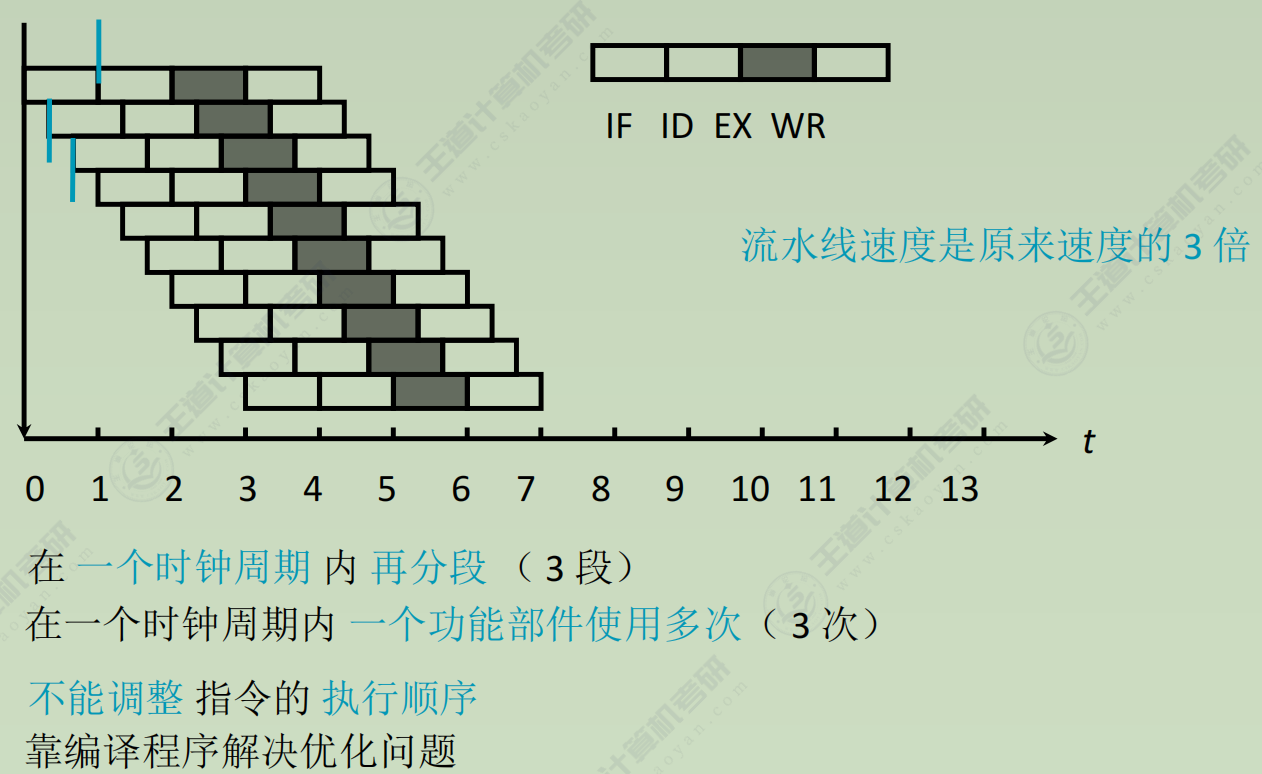
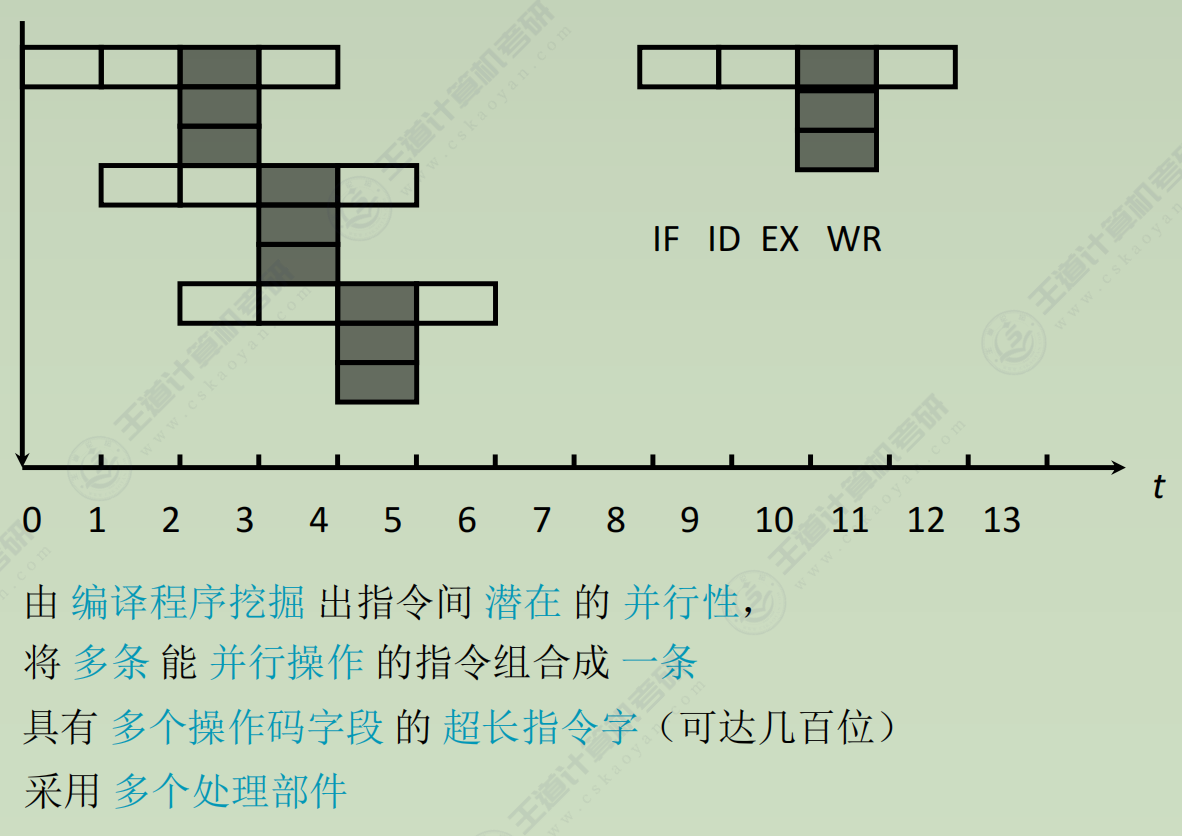
多发技术
- 超标量技术
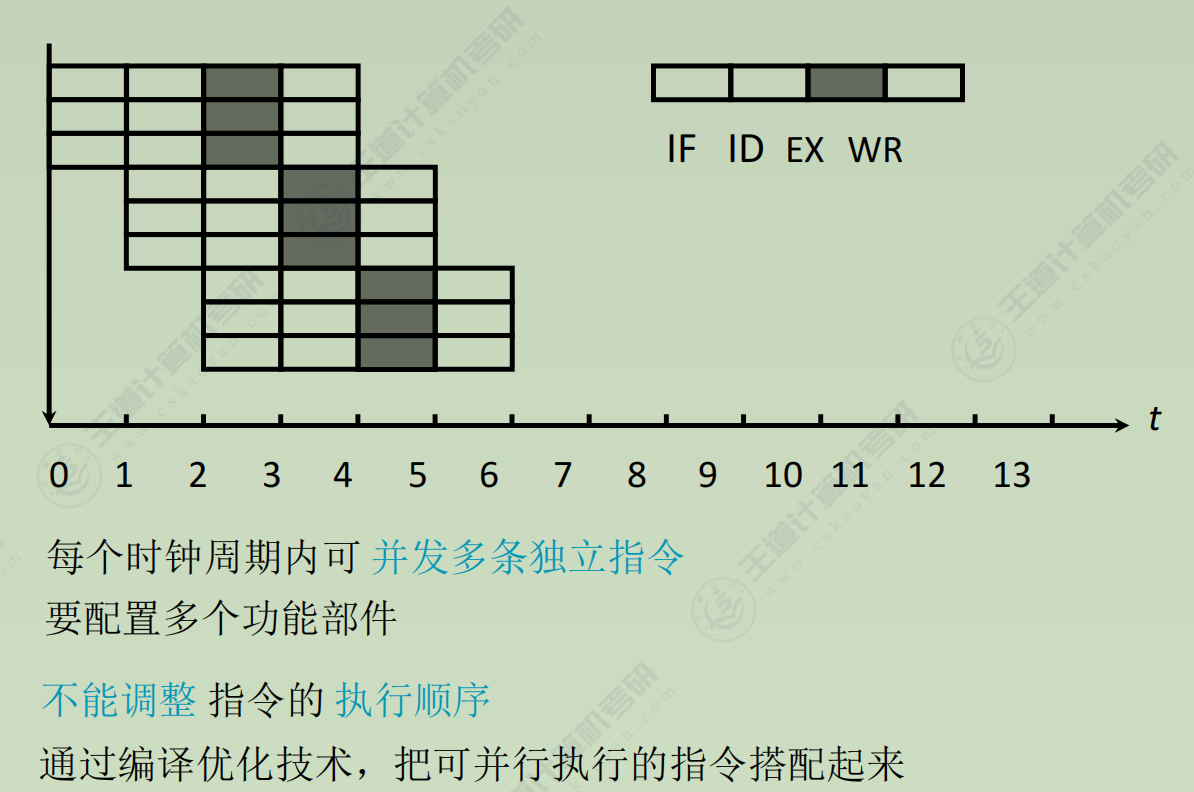
- 超流水技术
- 超长指令字
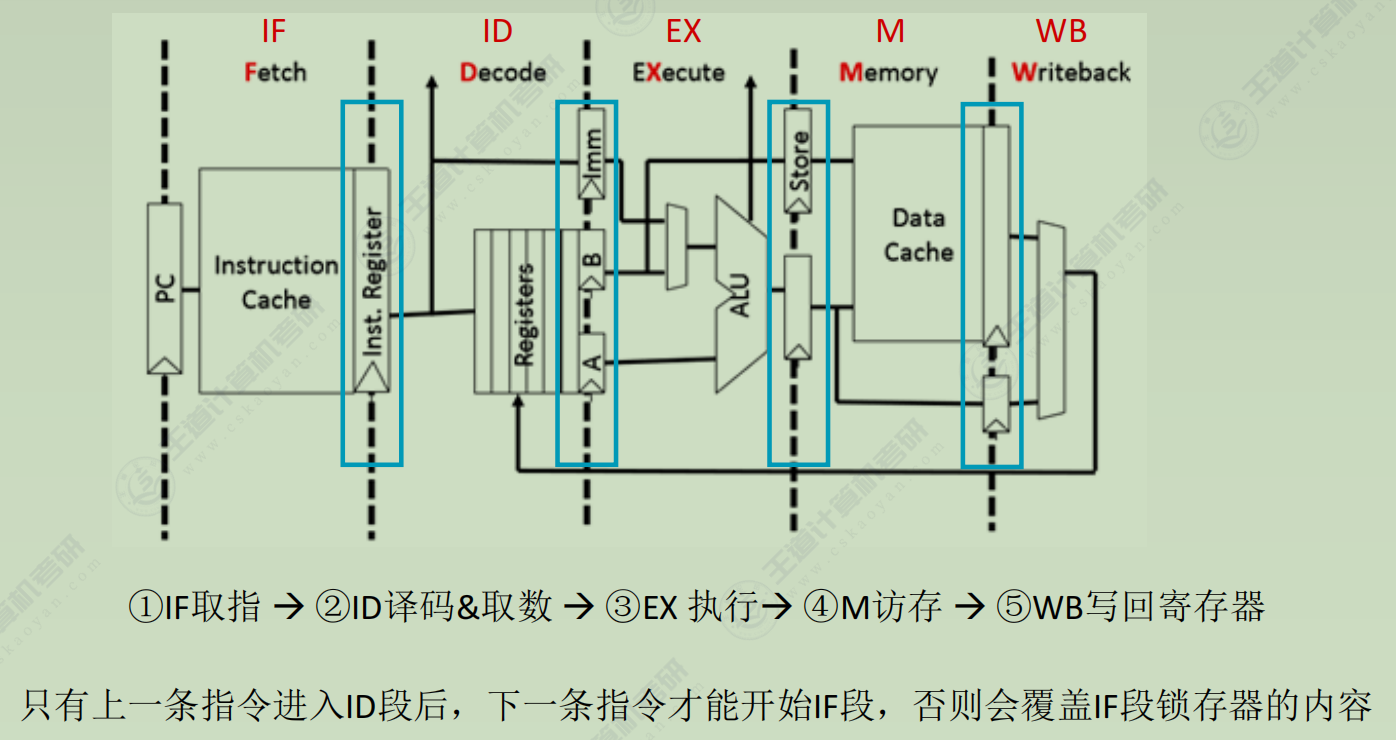
五段式
-
运算类指令
- IF:根据PC从指令Cache取指令至IF段的锁存器
- ID:取出操作数至ID段锁存器
- EX:运算,将结果存入EX段锁存器
- M:空段
- WB:将运算结果写回指定寄存器
-
LOAD指令
- IF:根据PC从指令Cache取指令至IF段的锁存器
- ID:将基址寄存器的值放到锁存器A,将偏移量的值放到Imm
- EX:运算,得到有效地址
- M:从数据Cache中取数并放入锁存器
- WB:将取出的数写回寄存器
-
STORE指令
- IF:根据PC从指令Cache取指令至IF段的锁存器
- ID:将基址寄存器的值放到锁存器A,将偏移量的值放到Imm。将要存的数放到B
- EX:运算,得到有效地址。并将锁存器B的内容放到锁存器 Store。
- M:写入数据Cache
- WB:空段
-
条件转移指令[相对寻址]
(PC) + 指令字长 + (偏移量 * 指令字长) -> PC- IF:根据PC从指令Cache取指令至IF段的锁存器
- ID:进行比较的两个数放入锁存器A、B;偏移量放入Imm
- EX:运算,比较两个数
- M:将目标PC值写回PC(左图没画全)
- WB:空段
-
无条件转移指令
- IF:根据PC从指令Cache取指令至IF段的锁存器
- ID:偏移量放入Imm
- EX:将目标PC值写回PC
- M:空段
- WB:空段
| 流水阶段 | 运算类指令 | LOAD指令 | STORE指令 | 条件转移指令(相对寻址) | 无条件转移指令 |
|---|---|---|---|---|---|
| IF | 根据PC从指令Cache取指令至IF段锁存器 | 同左 | 同左 | 同左 | 同左 |
| ID | 取出操作数至ID段锁存器 | 基址寄存器值→锁存器A 偏移量→Imm |
基址寄存器值→锁存器A 偏移量→Imm 数据→锁存器B |
比较数→锁存器A,B 偏移量→Imm |
偏移量→Imm |
| EX | 运算,结果存入EX段锁存器 | 计算有效地址 | 计算有效地址,锁存器B内容→锁存器Store | 比较运算,计算目标PC值 | 计算目标PC值并写回PC |
| M | 空段 | 从数据Cache取数→锁存器 | 数据Cache写入锁存器Store内容 | 目标PC值写回PC | 空段 |
| WB | 结果写回寄存器 | 取数写回寄存器 | 空段 | 空段 | 空段 |
多处理器
| 处理器 | SISD | SIMD | MISD | MIMD | 向量处理机 |
|---|---|---|---|---|---|
| 特性 | 各指令序列只能并发,不能并行,每条指令处理一两条数据 不是数据级并行技术 |
各指令序列只能并发,不能并行,每条指令可同时处理有很多相同特征的数据 是数据级并行技术 |
各指令序列并行执行,处理一条数据 | 并行执行,分别处理不同数据 线程级甚至以上技术 |
|
| 硬件组成 | 一个处理器+一个存储器 若采用指令流水线,需设置多个功能部件, 采用多模块交叉存储器 |
CU+多个处理/执行单元+多个局部存储器 | 分多处理器系统, 多计算机系统 | 一主存储器应采用“多个端口同时读取”的交叉多模块存储器 |

| 硬件多线程 | 细粒度多线程 | 粗粒度多线程 | 同时多线程 (SMT) |
|---|---|---|---|
| 指令发射 | 轮流发射各线程的指令 (每个时钟周期发射一个线程) |
连续几个时钟周期,都发射同一线程的指令序列 流水线阻塞时,切换另一个线程 |
一个时钟周期内,同时发射多个线程的指令 |
| 线程切换频率 | 每个时钟周期切换一次线程 | 只有流水线阻塞时才切换一次线程 | NULL |
| 线程切换代价 | 低 | 高,需要重载流水线 | NULL |
| 并行性 | 指令级并行,线程间不并行 | 指令级并行,线程间不并行 | 指令级并行,线程级并行 |
总线
概述
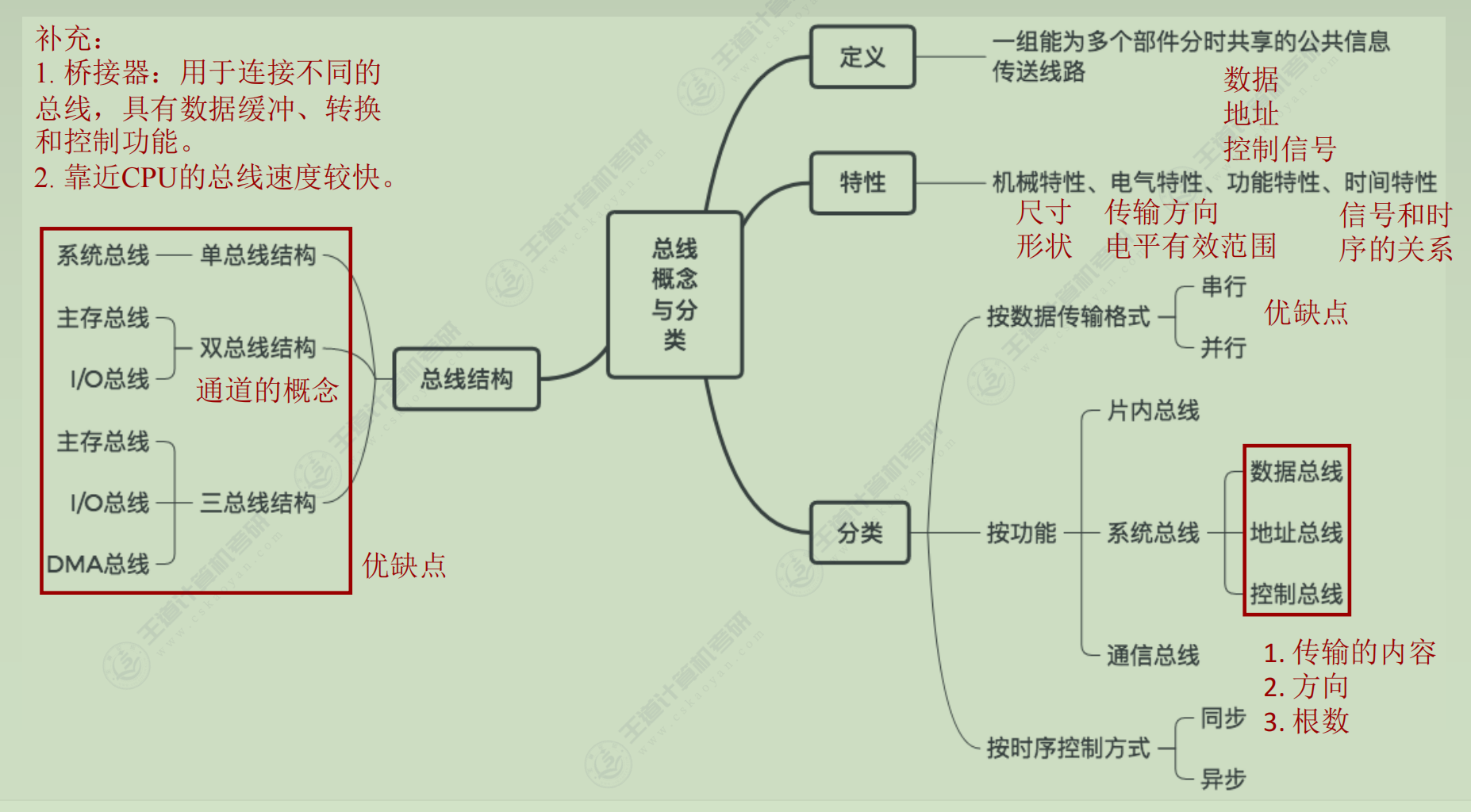

操作和定时
-
四个阶段
1) 申请分配阶段:由需要使用总线的主模块(或主设备)提出申请,经总线仲裁机构决定将下一传输周期的总线使用权授予某一申请者。也可将此阶段细分为传输请求和总线仲裁两个阶段。
2) 寻址阶段:获得使用权的主模块通过总线发出本次要访问的从模块的地址及有关命令,启动参与本次传输的从模块。
3) 传输阶段:主模块和从模块进行数据交换,可单向或双向进行数据传送。
4) 结束阶段:主模块的有关信息均从系统总线上撤除,让出总线使用权。 -
定时
1) 同步定时-读命令
2) 异步定时
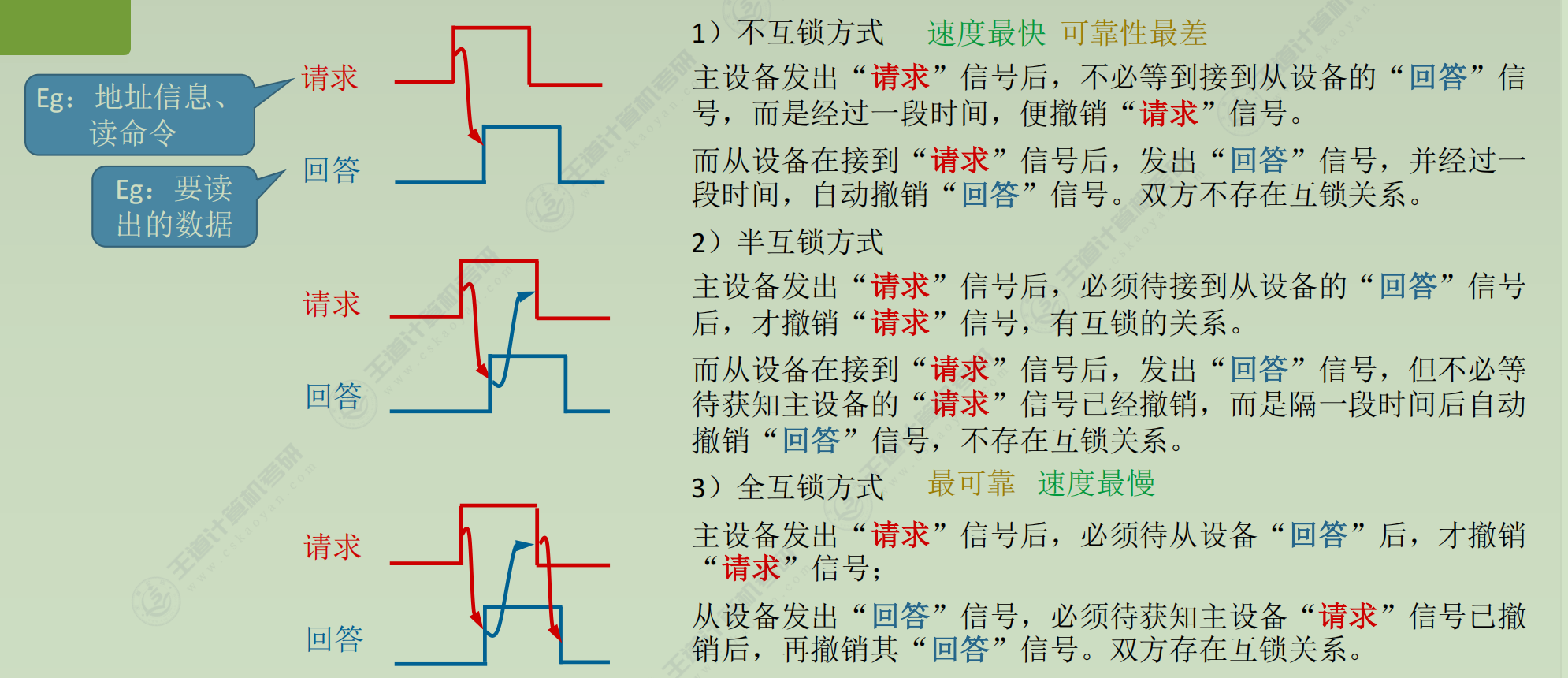
3) 半同步通信
4) 分离式通信
I/O系统
I/O接口
-
作用
• 数据缓冲:通过数据缓冲寄存器(DBR)达到主机和外设工作速度的匹配
• 错误或状态监测:通过状态寄存器反馈设备的各种错误、状态信息,供CPU查用
• 控制和定时:接收从控制总线发来的控制信号、时钟信号
•数据格式转换:串-并、并-串等格式转换
• 与主机和设备通信:实现 主机-1/0接口一1/0设备 之间的通信 -
工作原理
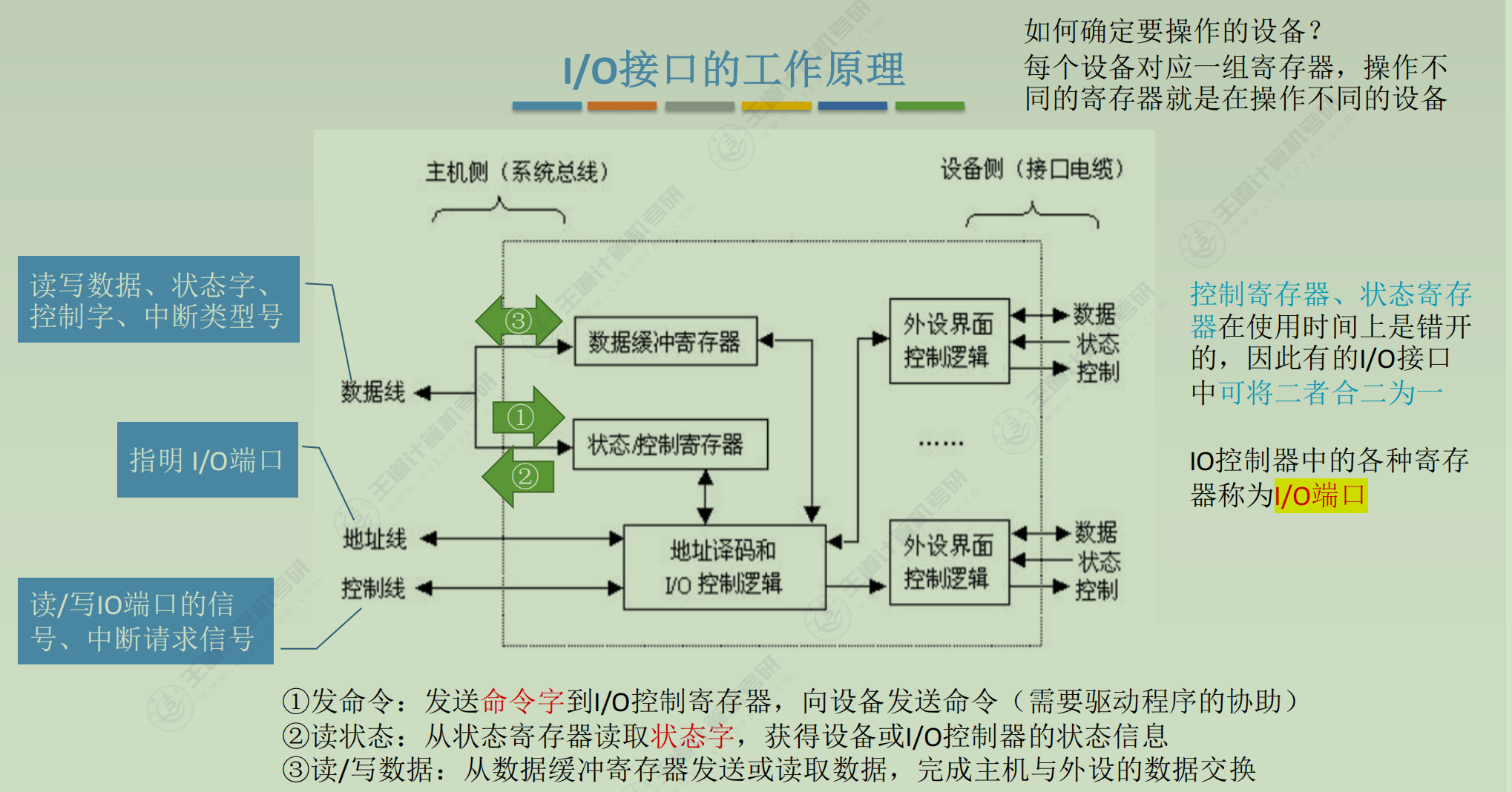
-
端口
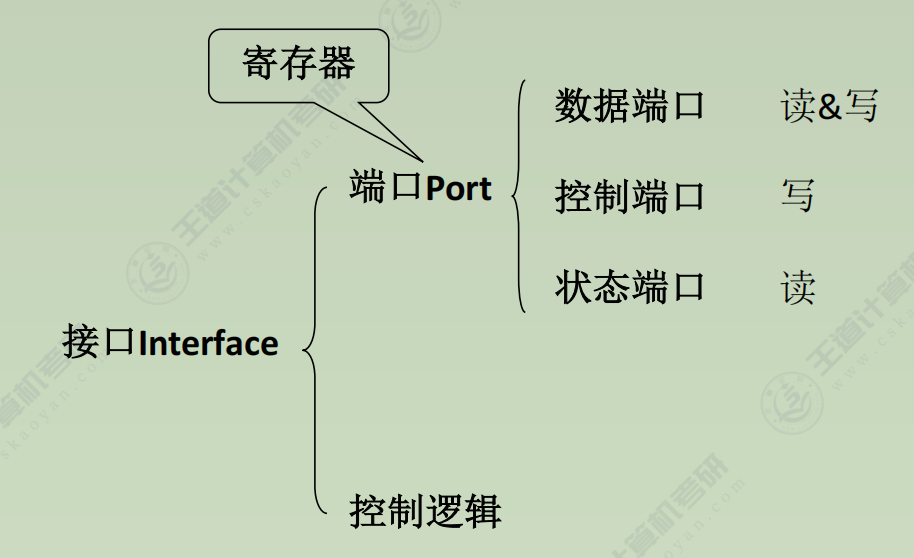
I/O端口要想能够被CPU访问,必须要有端口地址,每一个端口都对应着一个端口地址

I/O方式
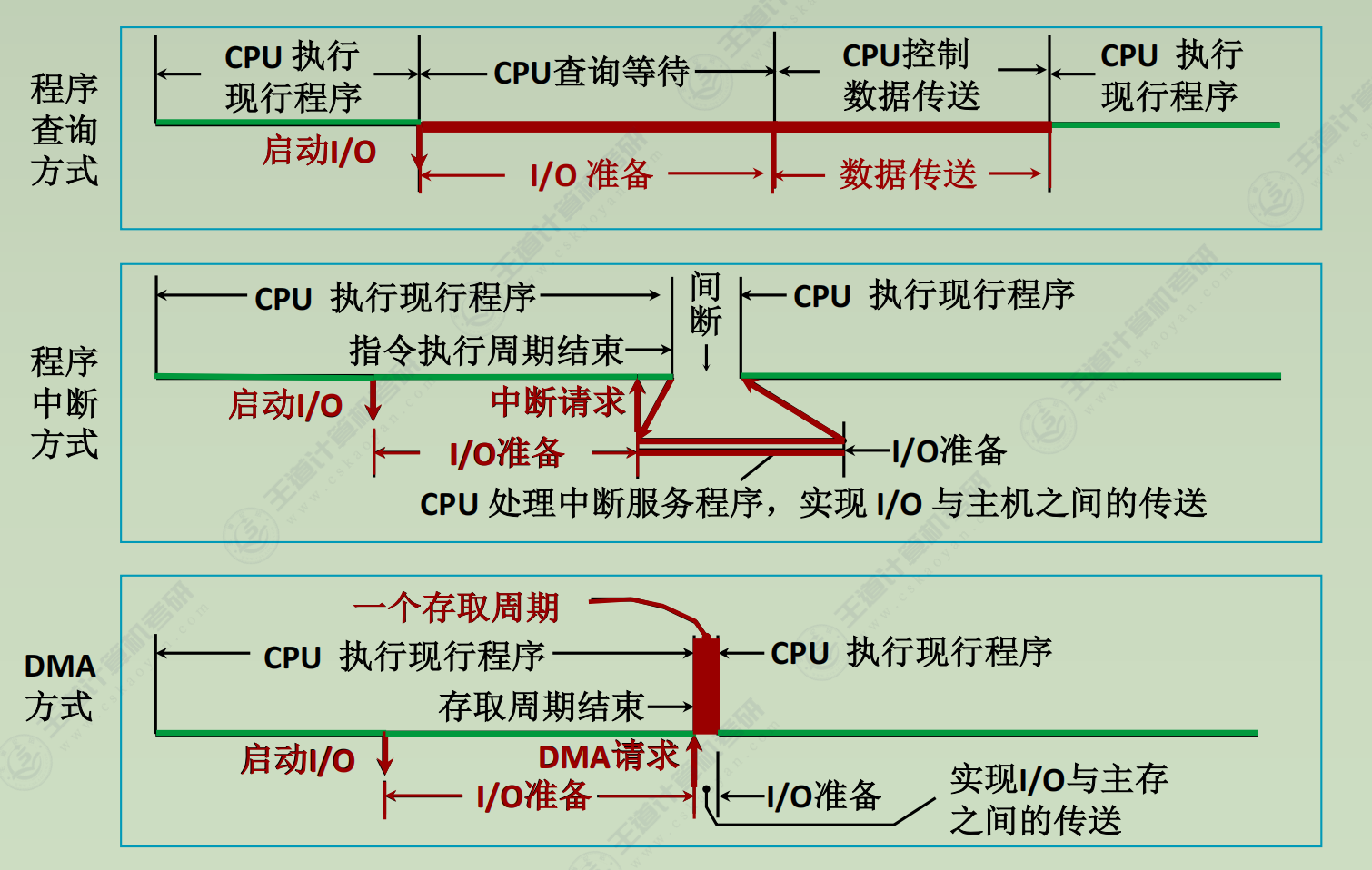
程序查询方式
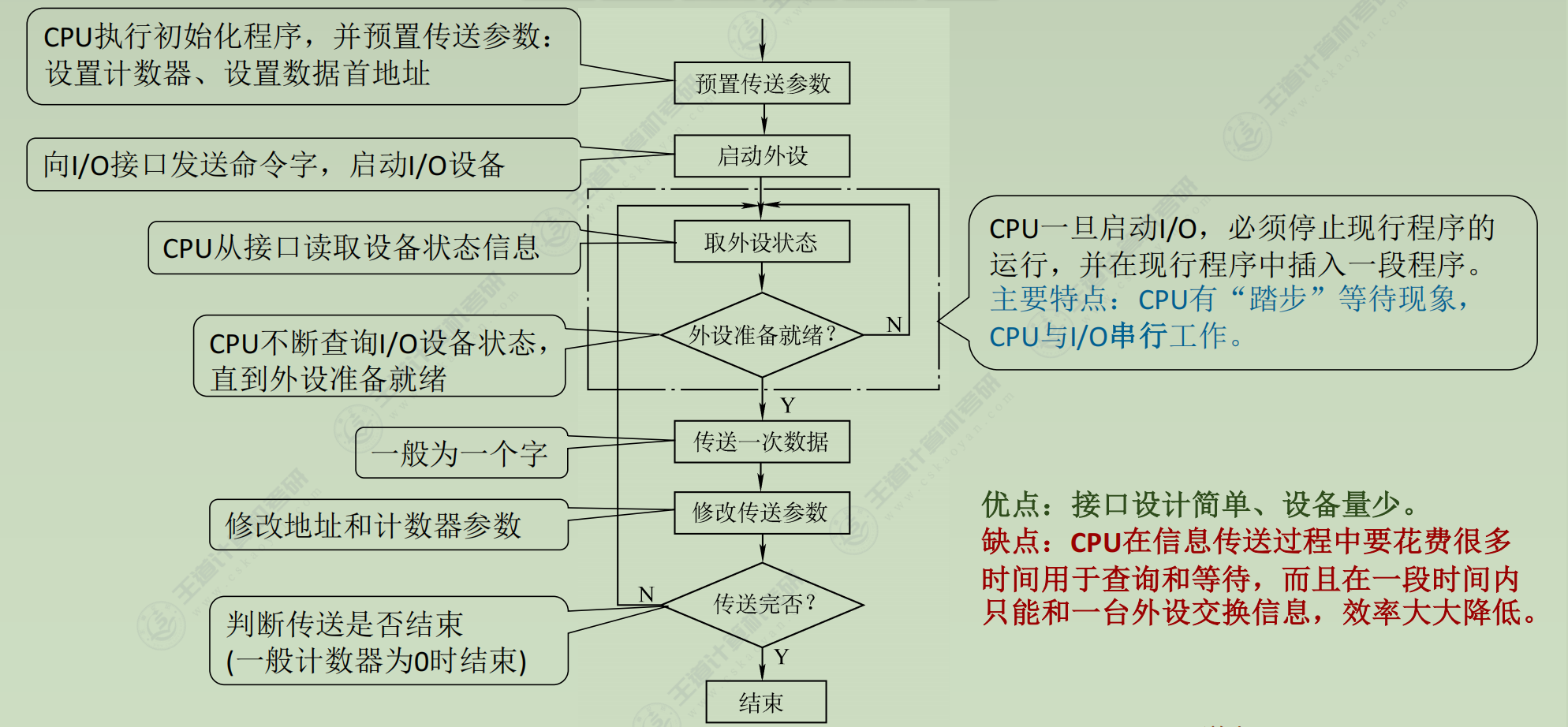
程序中断方式
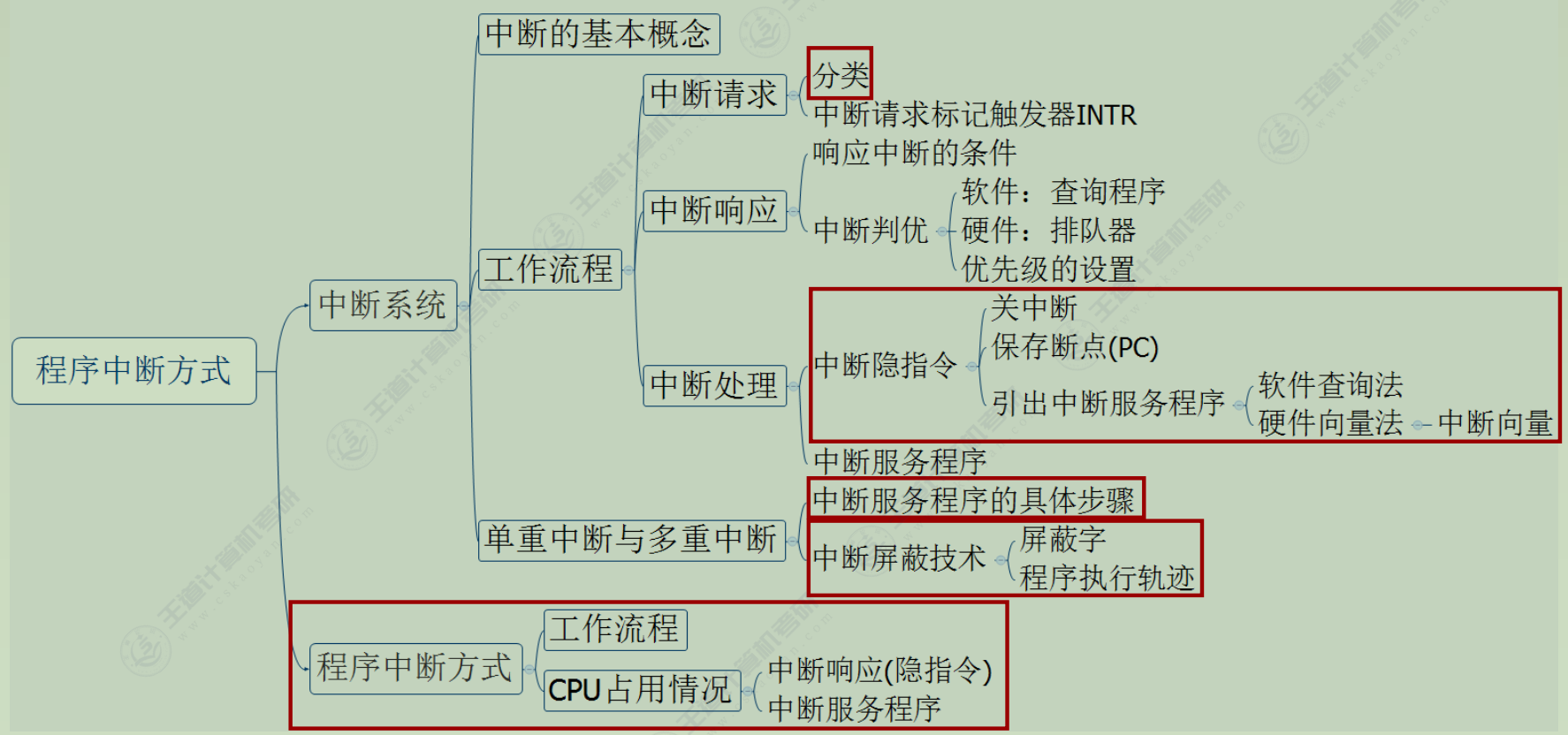
-
中断请求
中断源向CPU发送中断请求信号
中断请求标记触发器INTR: 记录中断时间, 区分不同的中断源 -
中断响应
when: 每条指令执行阶段的结束时刻
(1) 响应中断的条件- 中断源有中断请求
- CPU允许中断[开中断]
- 一条指令执行完毕, 且没有更紧迫的任务
(2) 中断判优:
多个中断源同时提出请求时通过中断判优逻辑响应一个中断源
硬件实现: 硬件排队器, 既可以设置在CPU中, 也可以分散在各个中断源中
软件实现: 查询程序
优先级设置:
硬件故障中断(最高优先级)
软件中断
非屏蔽中断 (NMI)>可屏蔽中断
DMA请求>普通1/0设备中断
高速设备>低速设备
输入设备>输出设备
实时设备>普通设备 -
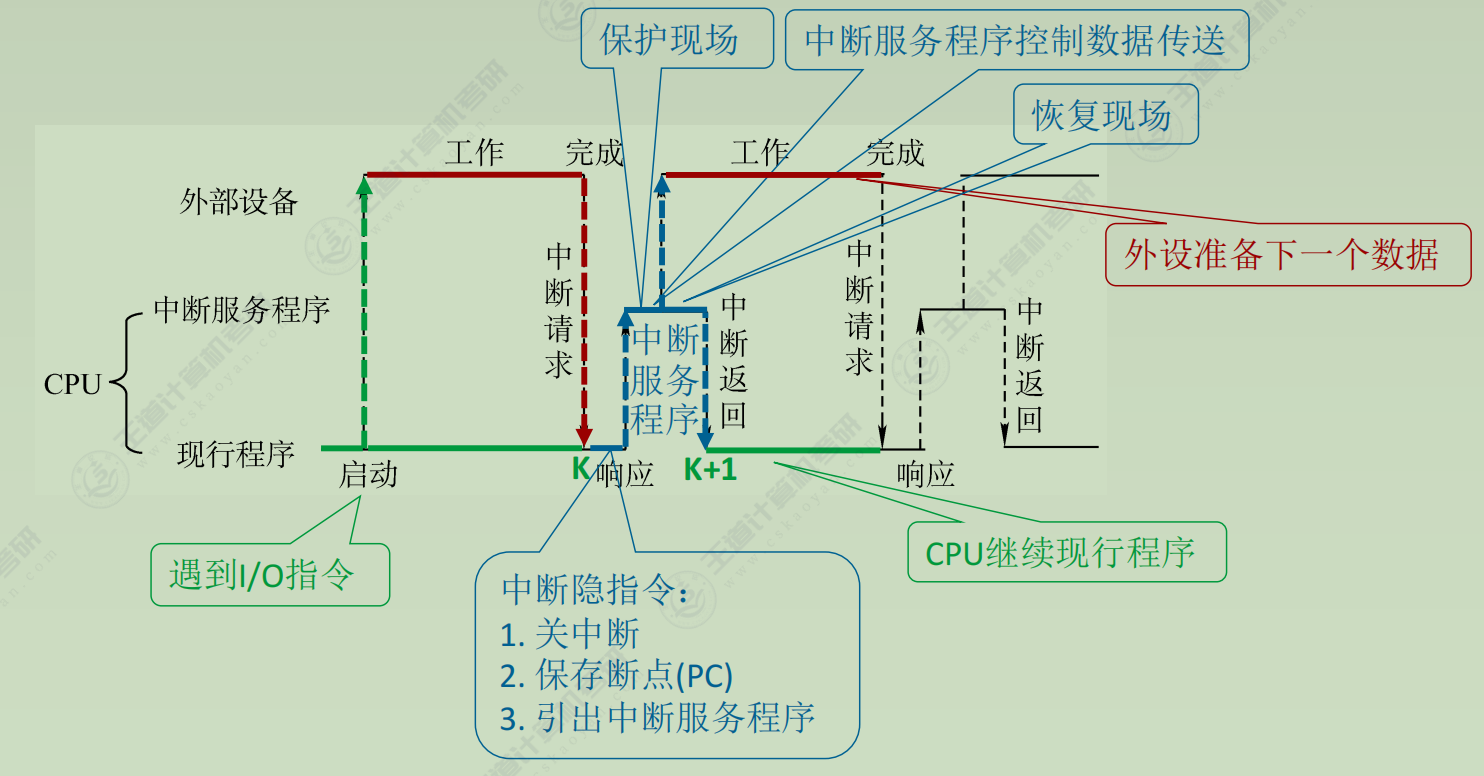
中断处理
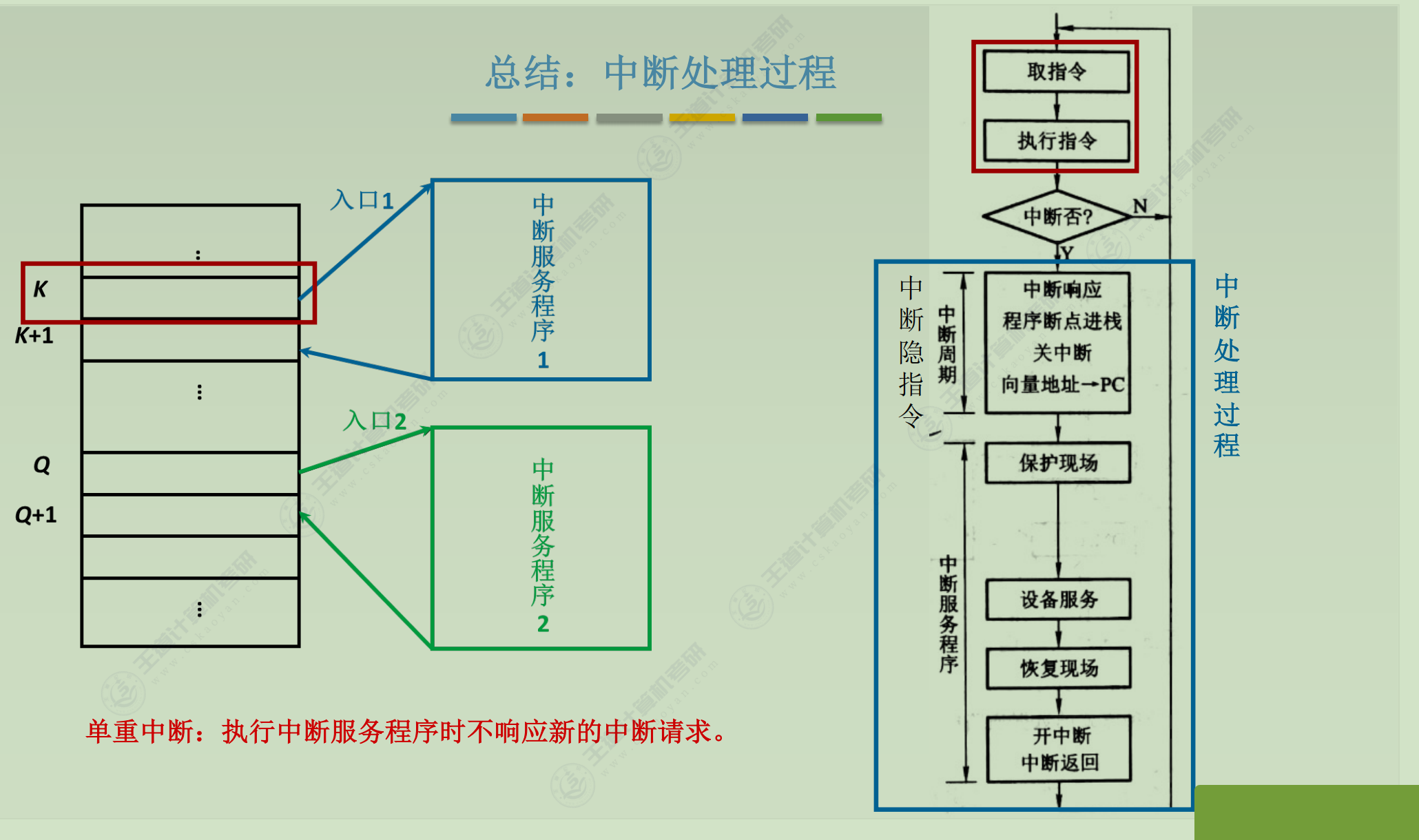
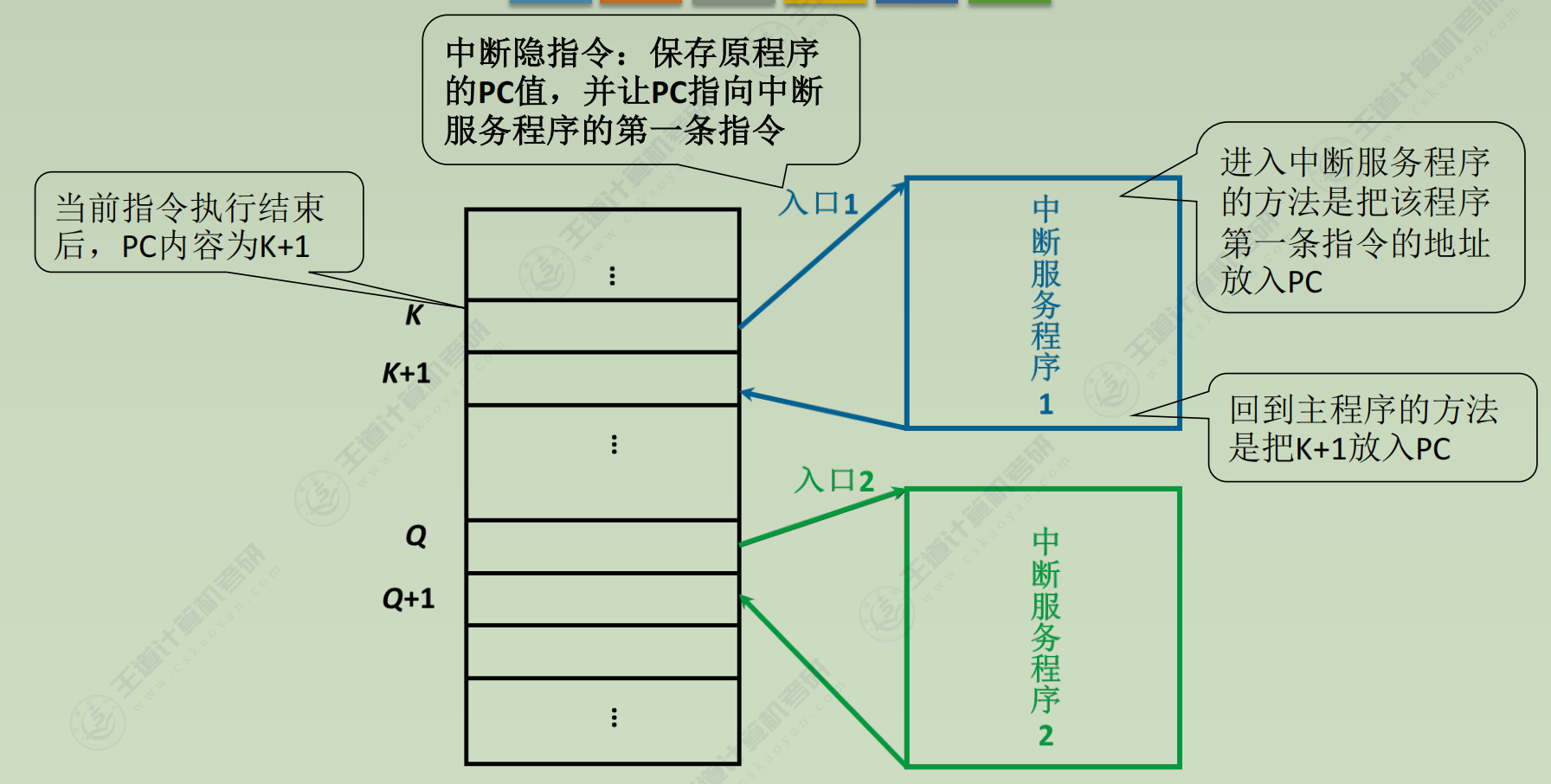
(1) 中断隐指令
并不是一条具体的指令, 而是CPU在检测到中断请求时自动完成的一系列动作
任务
① 关中断.为了保护中断现场(CPU主要寄存器中的内容)期间不被新的中断打断
② 保存断点.保证中断服务程序执行完毕后能正确返回到原来的程序, 可以存入堆栈. 可以存入制定单元
③ 引出中断服务程序. 取出中断服务程序的入口地址并且传送给PC
(2) 中断服务程序
由硬件产生向量地址, 再有向量地址找到入口地址
任务
① 保存现场. 保存通用寄存器和状态寄存器的内容, 以便返回原程序后可以恢复CPU环境.可使用堆栈, 也可以使用特定存储单元
② 中断服务(设备服务). e,g, 通过程序控制需打印的字符代码送入打印机的缓冲存储器
③ 恢复现场.通过出栈指令或取数指令把之前保存的信息送回寄存器中(eg:把原程序算到一般的ACC值恢复原样)
④中断返回
通过中断返回指令回到原程序断点处。
分类
| 单重中断 | 多重中断 | |
|---|---|---|
| 中断隐指令 | 关中断 | 关中断 |
| 保存断点(PC) | 保存断点(PC) | |
| 送中断向量 | 送中断向量 | |
| 中断服务程序 | 保护现场 | 保护现场和屏蔽字 |
| - | 开中断 | |
| 执行中断服务程序 | 执行中断服务程序 | |
| - | 关中断 | |
| 恢复现场 | 恢复现场和屏蔽字 | |
| 开中断 | 开中断 | |
| 中断返回 | 中断返回 |
DMA方式
-
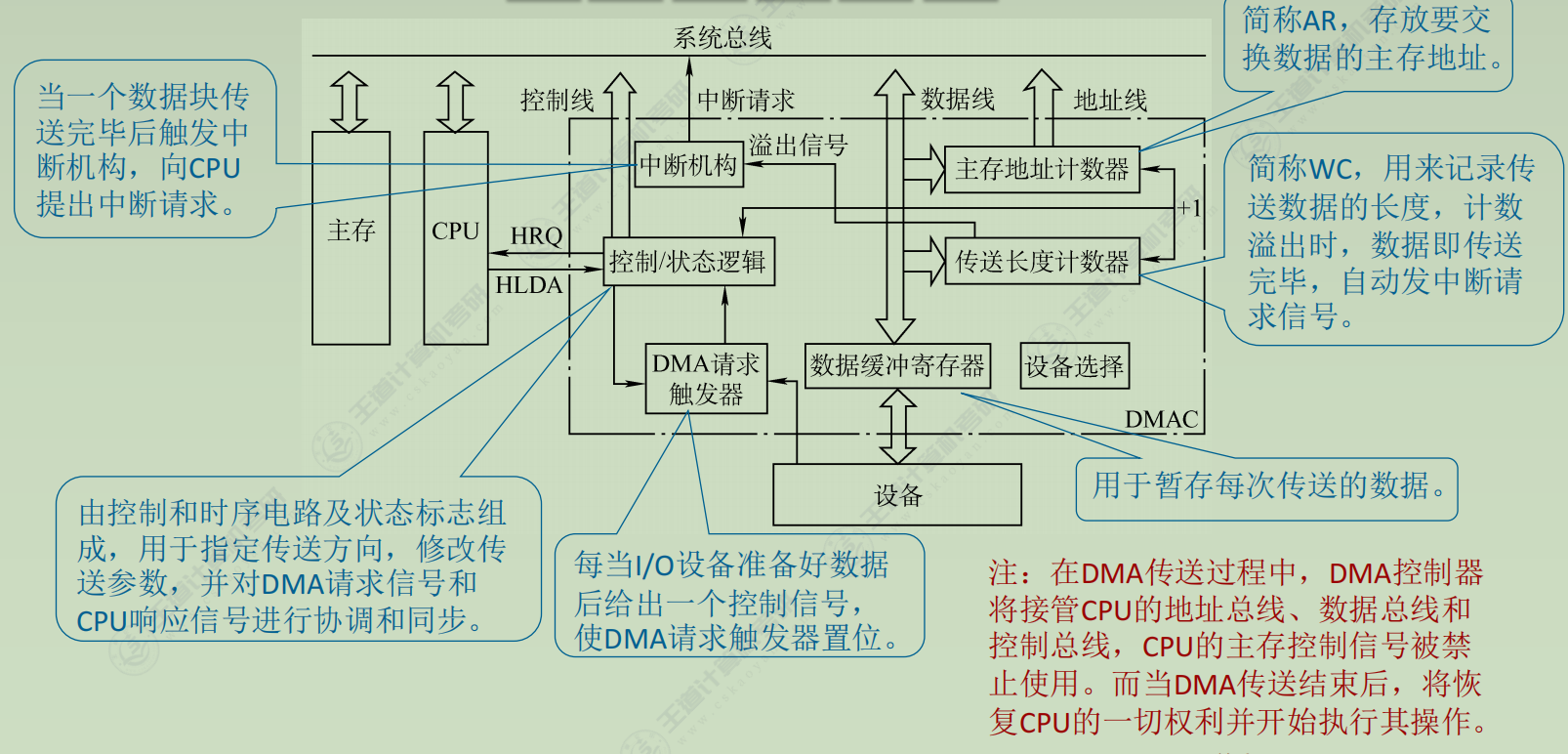
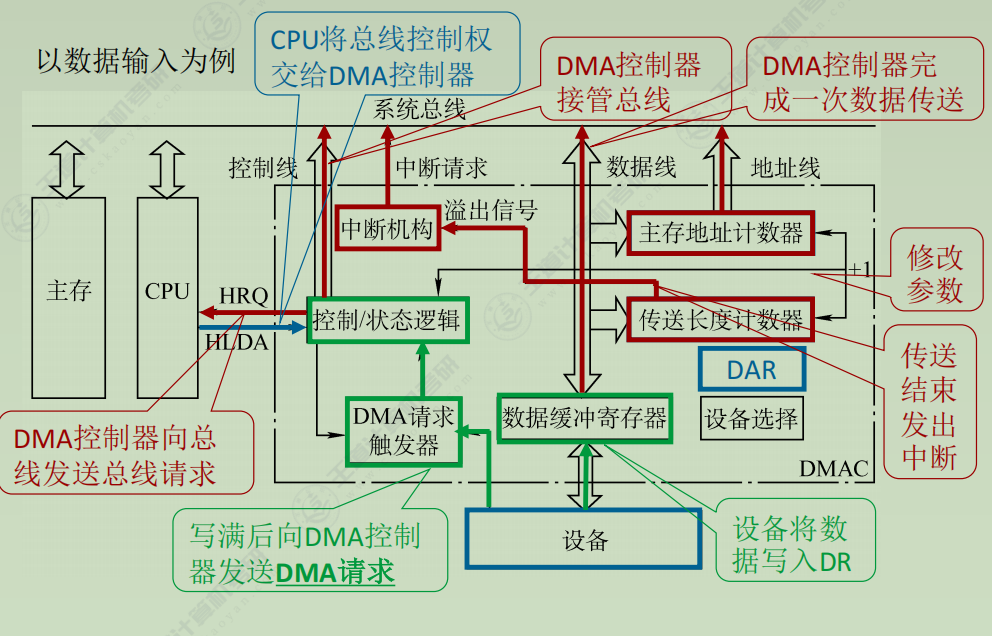
DMA控制器
1. 初始化阶段
CPU向DMA控制器指明:
数据传输方向(输入/输出)
要传送的数据量(数据长度)
数据在主存和外设中的地址
2. 传送前
接收外设的DMA请求:外设发出传送一个字的请求。
向CPU申请总线控制权, DMA控制器向CPU发送总线请求
CPU响应后,发出总线响应信号,释放总线控制权,进入DMA操作周期
3. 传送时
确定并管理数据地址:
设定主存地址和数据长度。
自动修改主存地址计数器和传送长度计数器。
执行数据传输:
控制数据传输方向(读/写)。
发出读写控制信号,完成数据在主存与外设间的传送。
4. 传送后
DMA控制器向CPU报告DMA操作完成,CPU恢复总线控制权。
-
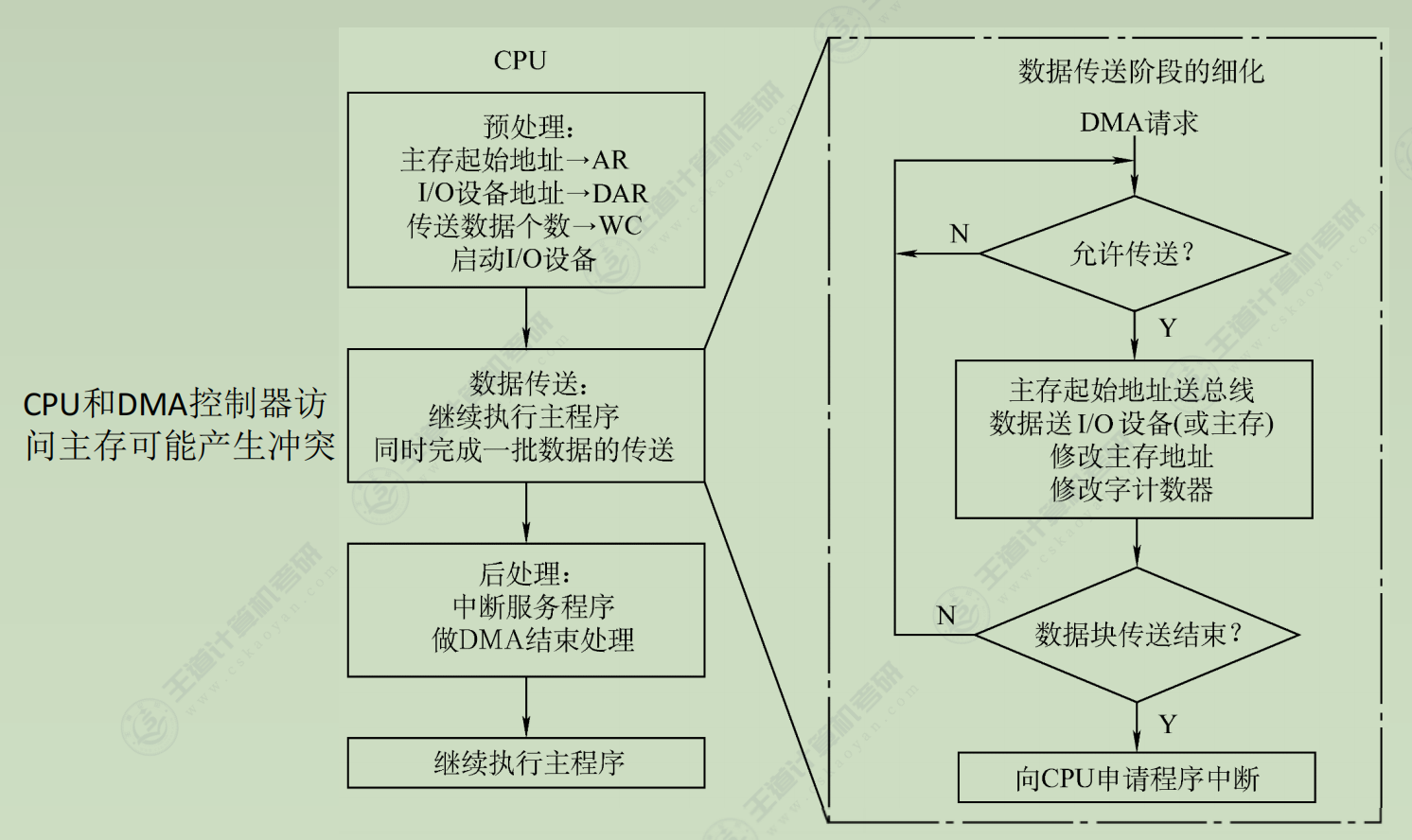
传送过程
-
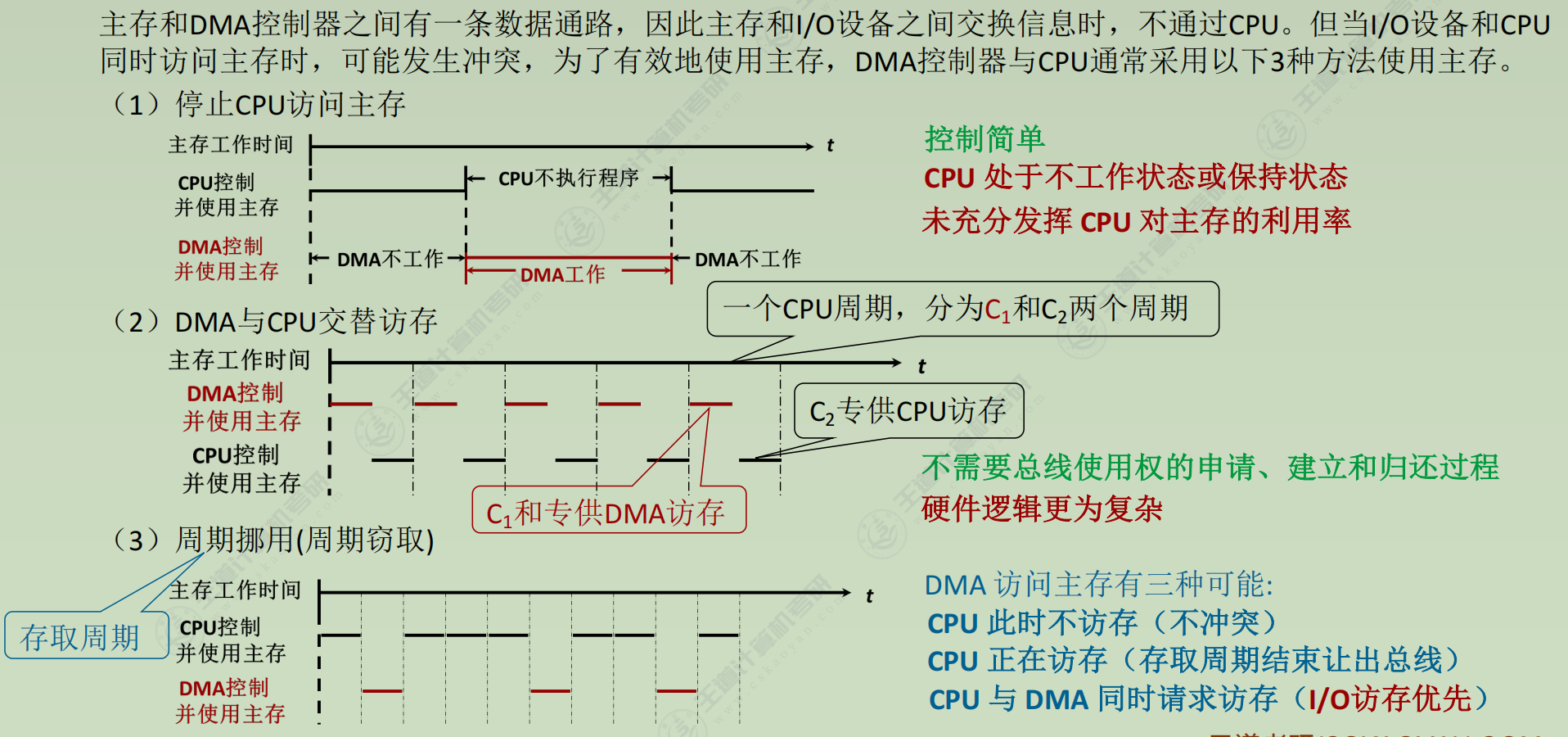
传送方式
-
特点
① 它使主存与CPU的固定联系脱钩,主存既可被CPU访问,又可被外设访问。
② 在数据块传送时,主存地址的确定、传送数据的计数等都由硬件电路直接实现。
③ 主存中要开辟专用缓冲区,及时供给和接收外设的数据。
④ DMA传送速度快,CPU和外设并行工作,提高了系统效率。
⑤ DMA在传送开始前要通过程序进行预处理,结束后要通过中断方式进行后处理 -
与中断方式的对比
| 中断 | DMA | |
|---|---|---|
| 数据传送 | 程序控制 程序的切换 → 保存和恢复现场 |
硬件控制 CPU只需进行预处理和后处理 |
| 中断请求 | 传送数据 | 后处理 |
| 响应 | 指令执行周期结束后响应中断 | 每个机器周期结束均可,总线空闲时即可响应DMA请求 |
| 场景 | CPU控制,低速设备 | DMA控制器控制,高速设备 |
| 优先级 | 优先级低于DMA | 优先级高于中断 |
| 异常处理 | 能处理异常事件 | 仅传送数据 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号