爬取新浪新闻热搜
首先,我们打开新浪新闻的官网,找到新闻页面。按一下F12或者点击鼠标右键,然后点击检查,就会到达以下这个页面。
然后我们点击上方的network选项,就会跳转到一个有很多网络请求的页面,我们看看都有什么请求。
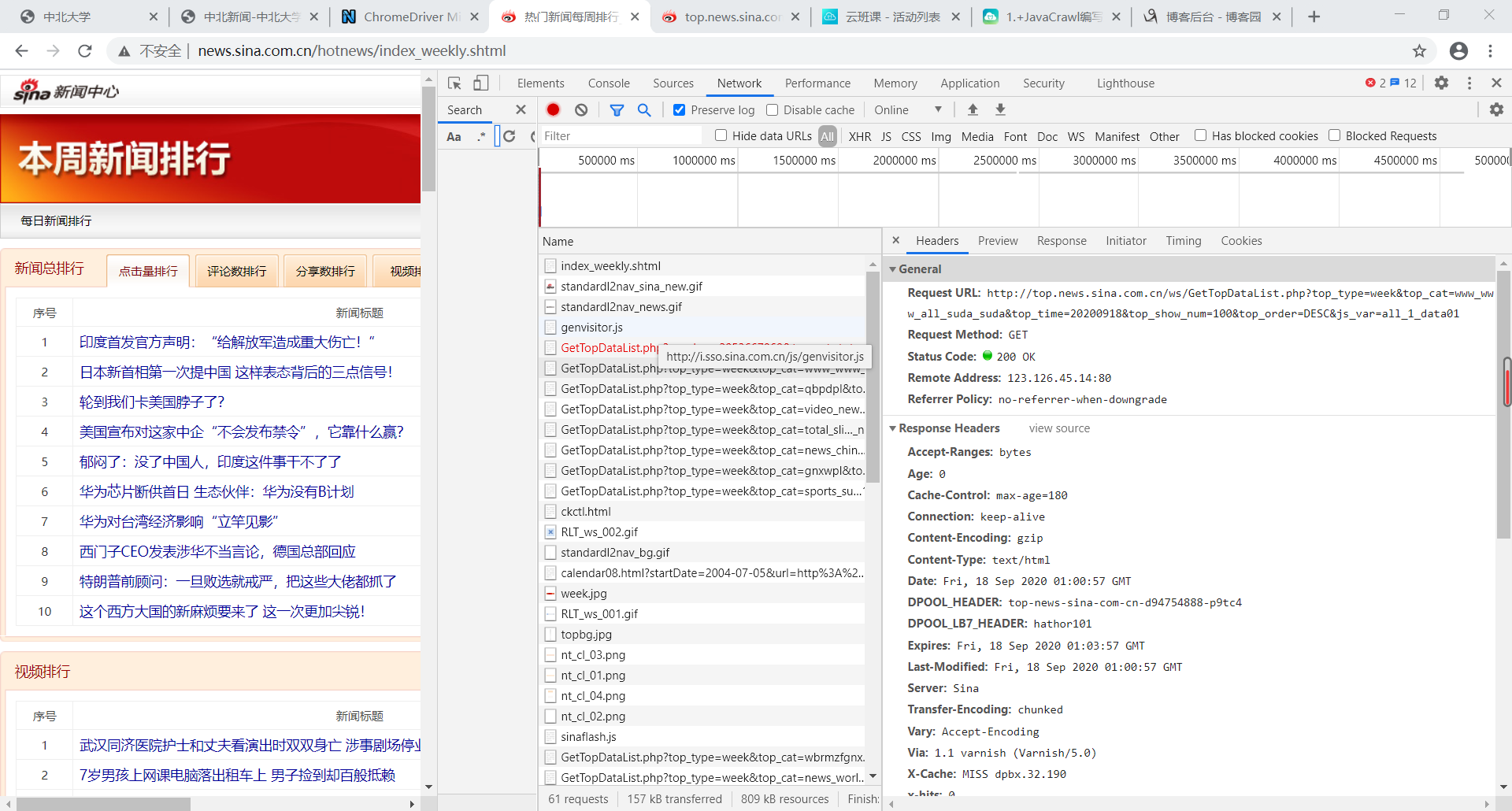
我们随便点击几个,然后选择右上角的Header选项,看看他的Request URL,我们直接转到这个网址上,看看他是个什么内容。如果是我们需要的内容,我们就可以给他爬下来。这里我们看到有一堆什么GetTopDataList请求,我们点进去看看是个什么。打开之后我们会发现这个网址就是一堆json数据,里边有很多新闻信息,那我们就决定爬这个吧。

我们用requests获取这个网页的json字符串,加以处理将其处理为合法的json格式数据,就可以使用json.loads()将其转换为一个map,然后我们获取键为data的值,新闻信息就在这里边了。然后我们通过map的操作获取自己想要的数据即可。通过观察刚才的那个链接,我们可以发现,那个网址就是在http://top.news.sina.com.cn/ws/GetTopDataList.php?的基础上加了很多xxx=yyy这种东西,这种东西我们可以通过字典直接构建,如下图。
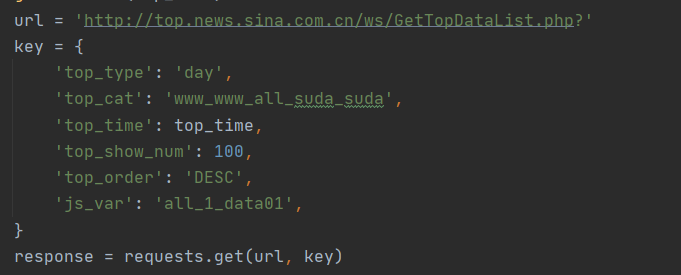
这样当我们使用requests的get方法时,会将key这个map的内容以上述形式加在url后边,就可以构建出这个网址,那么我们想要获取不同日期的新闻时,只用修改top_time这个变量的值即可。我们可以通过datetime的datetime类来构建出这种格式化时间字符串,先设置一个起始时间,再设置一个终止时间,使用datetime.delta这个方法,我们可以设置时间间隔为一天,这样就可以获取到start-end之间所有日期的格式化字符串,最后通过循环就可以一次获取一段连续时间的新闻信息。以下是代码:
import requests import json import datetime def getHtmlText(top_time): url = 'http://top.news.sina.com.cn/ws/GetTopDataList.php?' key = { 'top_type': 'day', 'top_cat': 'www_www_all_suda_suda', 'top_time': top_time, 'top_show_num': 100, 'top_order': 'DESC', 'js_var': 'all_1_data01', } return requests.get(url, key).content def getTopTimeList(): top_time_list = [] start = datetime.datetime(2020, 1, 1) end = datetime.datetime(2020, 9, 19) now = start delta = datetime.timedelta(days=1) while now != end: temp = now.strftime('%Y') + now.strftime('%m') + now.strftime('%d') top_time_list.append(temp) now = now + delta return top_time_list def getNews(top_time): json_text = getHtmlText(top_time).decode('raw_unicode-escape').replace('var all_1_data01 = ', '').replace(';', '') # 至此,json_text已经被处理为了一个合法的json文本,接下来可以用json_text进行转换为一个字典 data = json.loads(json_text)['data'] # 获取到一个json_map, 取出map中的data,用于数据的获取 newsList = [] for d in data: # 遍历每一个数据 title = d['title'] # 获取新闻标题 create_date = d['create_date'] # 获取创建时间 newsList.append((create_date, title)) return newsList def main(): top_time_list = getTopTimeList() newsList = [] for top_time in top_time_list: for news in getNews(top_time): newsList.append(news) with open('news.txt', 'w') as f: for news in newsList: print(news[0] + ' ' + news[1], file=f) main()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号