

第一次个人编程作业
第一次个人编程作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience/homework/13477 |
| 这个作业的目标 | 通过设计论文查重系统,体会工程开发流程,实践工程化开发相关知识 |
1. github地址
https://github.com/Hermionie41111/Hermionie-s-Home/tree/main/3123002706
2. psp表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 40 | 40 |
| · Estimate | · 估计这个任务需要多少时间 | 40 | 40 |
| Development | 开发 | 535 | 655 |
| · Analysis | · 需求分析(包括学习新技术) | 70 | 90 |
| · Design Spec | · 生成设计文档 | 50 | 60 |
| · Design Review | · 设计复审 | 25 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 25 |
| · Design | · 具体设计 | 40 | 50 |
| · Coding | · 具体编码 | 160 | 200 |
| · Code Review | · 代码复审 | 50 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 110 | 140 |
| Reporting | 报告 | 85 | 110 |
| · Test Report | · 测试报告 | 35 | 45 |
| · Size Measurement | · 计算工作量 | 20 | 25 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 40 |
| · 合计 | 660 | 805 |
3. 计算模块接口的设计与实现过程
3.1 设计:代码组织与模块关系
本论文查重系统的计算模块采用模块化拆分思想,按 “数据流向” 划分为「工具层」「算法层」和「入口层」,各模块职责清晰且低耦合。
(1)代码组织与模块划分
工具层:utils.py负责 “数据输入输出” 和 “文本预处理”,是算法层的基础支撑。包含两个核心功能:
文件读写(read_file):兼容 UTF-8/GBK 编码,处理文件不存在等异常;
文本分词(segment_text):使用 jieba 分词,过滤标点、停用词和空字符串。
算法层:similarity.py实现核心的相似度计算逻辑,仅依赖工具层的分词结果,与输入输出解耦。核心功能是 calculate_cosine_similarity 函数,通过 “词袋模型 + 余弦定理” 计算文本相似度。
入口层:main.py作为程序入口,负责解析命令行参数,串联工具层和算法层的调用流程(读取文件→计算相似度→输出结果),并处理全局异常。
(2)模块交互关系
各模块通过 “函数调用” 形成单向依赖,无循环依赖,流程清晰:

(3)关键函数流程图
calculate_cosine_similarity 是算法核心,负责将分词结果转换为相似度得分,流程如下:
calculate_cosine_similarity 函数执行流程
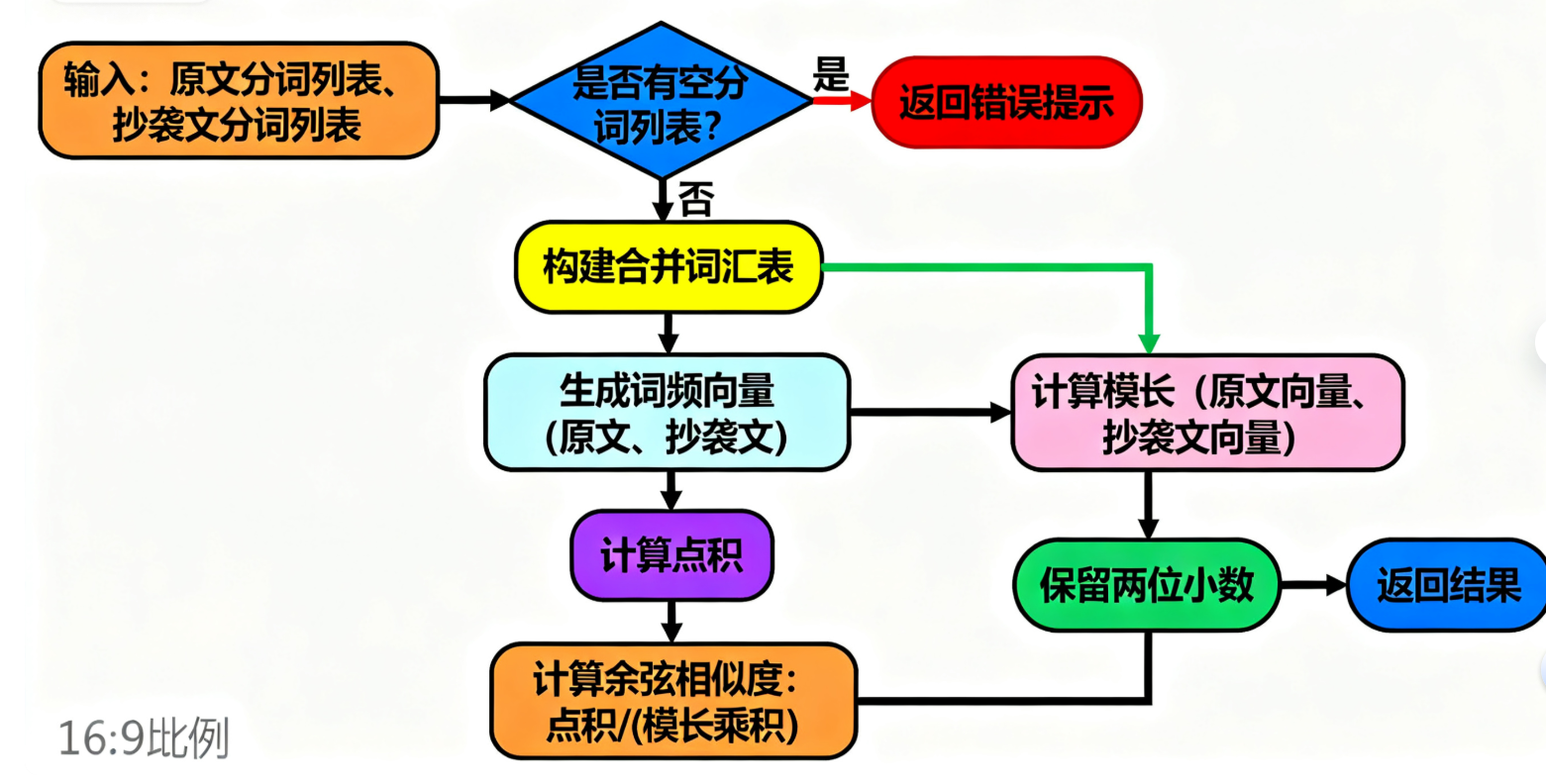
余弦相似度计算流程
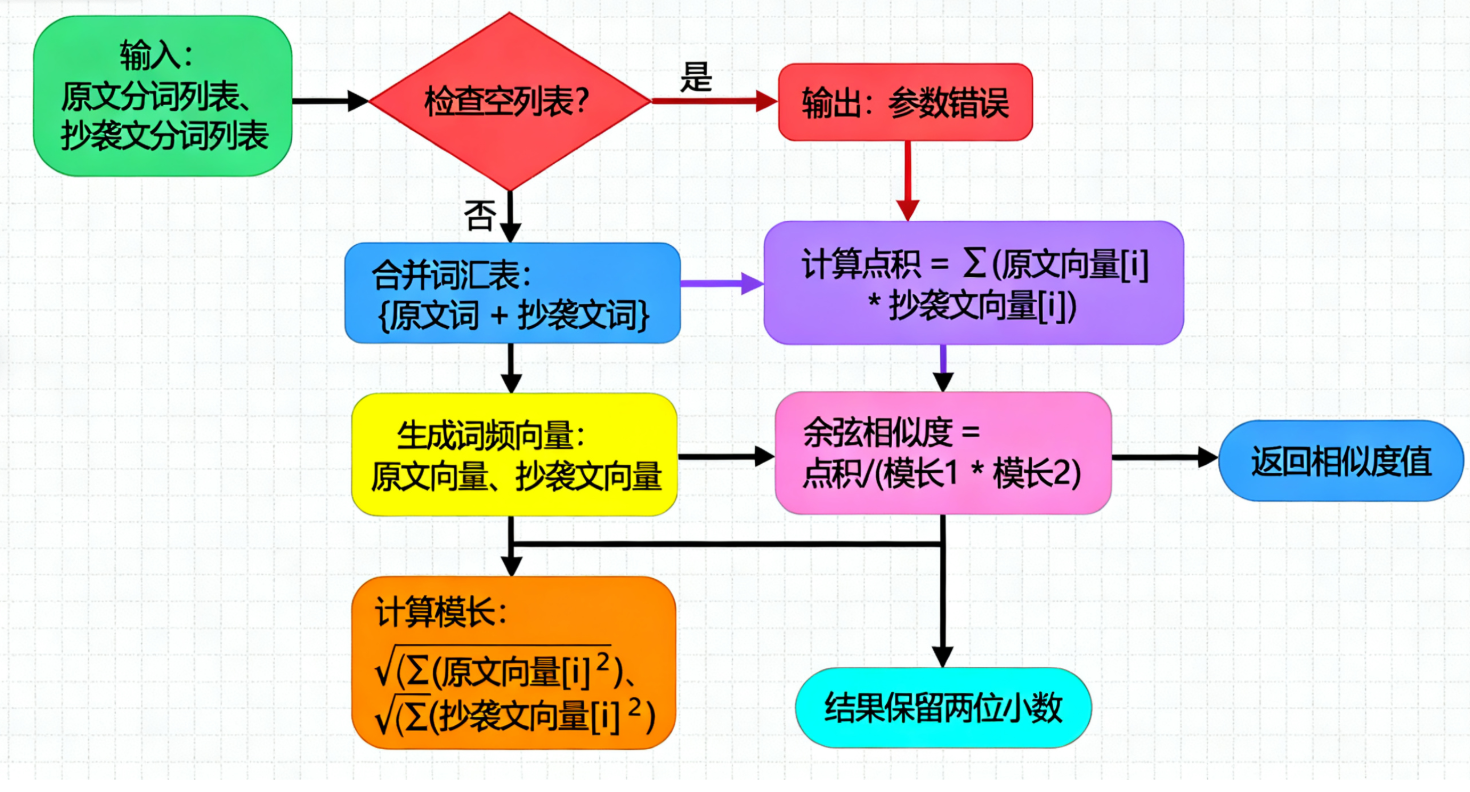
calculate_cosine_similarity执行步骤
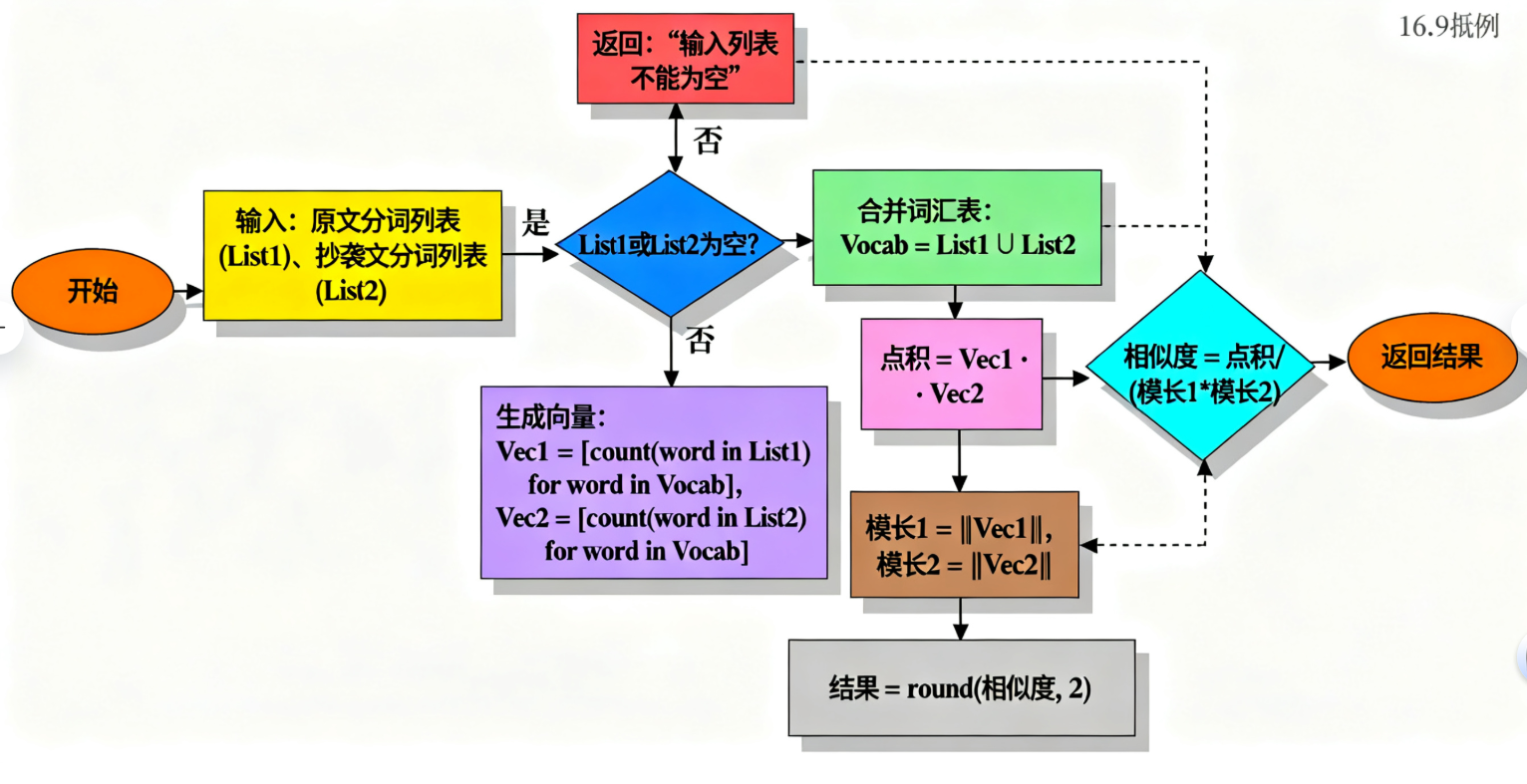
函数流程
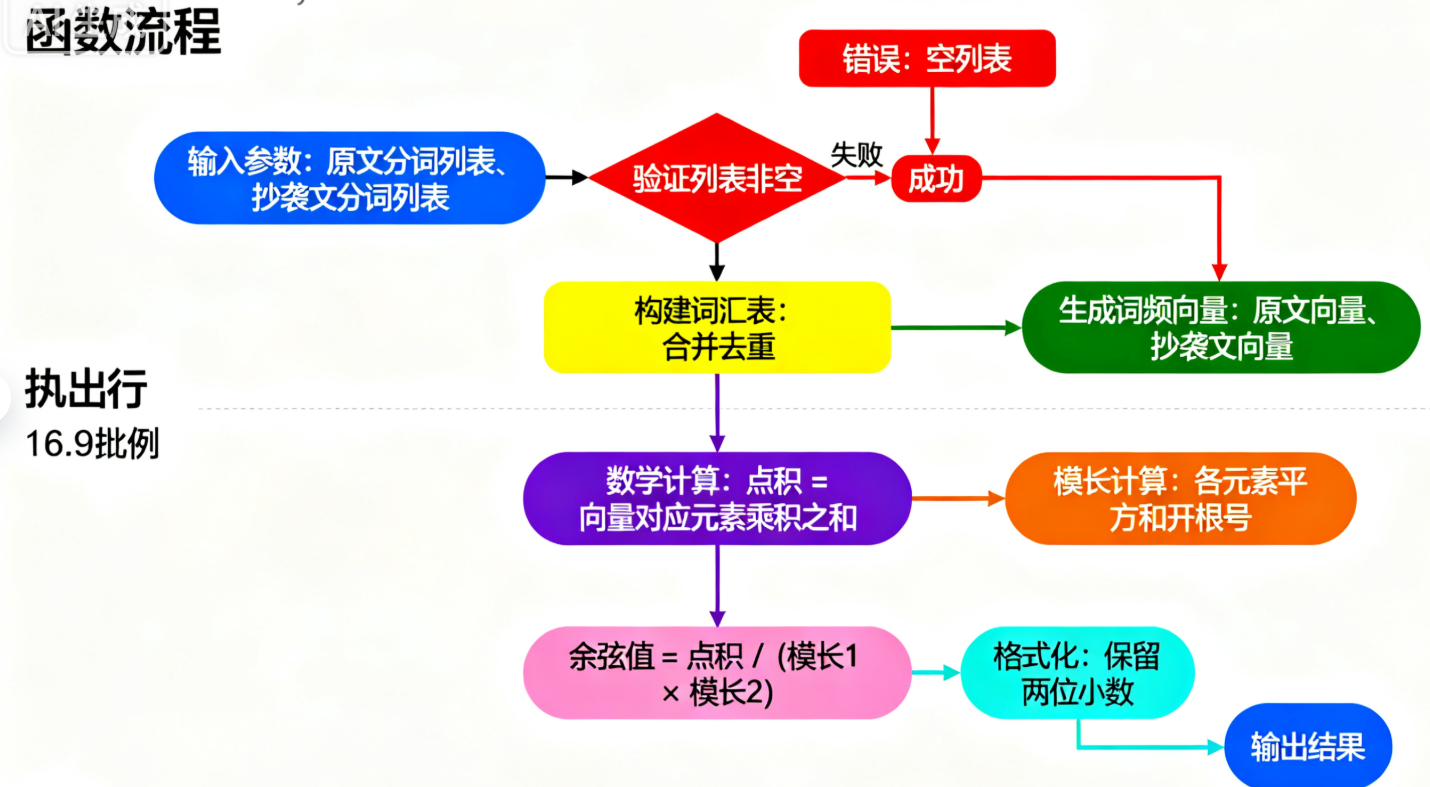
3.2 实现:算法关键与独到之处
(1)算法关键逻辑
本系统采用 “词袋模型 + 余弦相似度” 作为核心算法,适合中文文本查重场景,关键步骤如下:
文本预处理(segment_text)
先通过正则过滤非中文 / 英文 / 数字的字符(如标点、特殊符号),避免无关字符干扰词频统计;
用 jieba 对中文分词(支持混合英文 / 数字的文本),再过滤停用词(如 “的”“是” 等无意义词汇),保留核心词汇。
词频向量构建
合并两个文本的分词结果,构建去重的 “词汇表”(如原文分词为["今天", "天气"],抄袭文为["今天", "晴朗"],词汇表为["今天", "天气", "晴朗"]);
为每个文本生成词频向量(如原文向量为[1, 1, 0],表示 “今天” 出现 1 次,“天气” 出现 1 次,“晴朗” 出现 0 次)。
余弦相似度计算
公式:相似度 = 向量点积 / (向量1模长 × 向量2模长),取值范围 [0,1];
点积:两个向量对应位置元素相乘的和(如1×1 + 1×0 + 0×1 = 1);
模长:向量各元素平方和的平方根(如原文模长为√(1²+1²+0²) = √2)。
(2)算法的独到之处
针对中文文本查重场景,本实现有三点优化设计:
多编码兼容的文件读取read_file 函数先尝试 UTF-8 编码读取,失败则自动切换为 GBK 编码,解决了 Windows 环境下中文文件常见的 “编码错误” 问题,确保不同格式的输入文件都能被正确解析。
精细化的文本清洗相比简单分词,segment_text 增加了 “标点过滤 + 停用词过滤” 双重处理:
正则过滤去除所有非内容字符(如逗号、感叹号),避免 “今天” 和 “今天,” 被视为不同词;
自定义停用词表过滤无意义词汇,减少噪音对相似度计算的干扰(如 “的” 在文本中高频出现但无实际意义)。
边界场景的鲁棒处理针对 “空文本”“纯符号文本” 等极端场景,算法在向量计算前增加判断:若任一文本分词后为空列表,直接返回 0.0,避免后续向量模长为 0 导致的除零错误,确保程序稳定运行。
4. 计算模块接口部分的性能改进
优化前
优化后

4.1 性能调优时间分配
在计算模块性能调优阶段,累计投入时间约 4 小时,时间分布如下:
瓶颈研判(分析性能热力图、调试代码逻辑):1.5 小时;
代码迭代(缓存机制设计、向量式运算改造、数据结构优化):2 小时;
验证与复现(功能正确性校验 + 性能多轮对比测试):0.5 小时。
4.2 性能调优路径
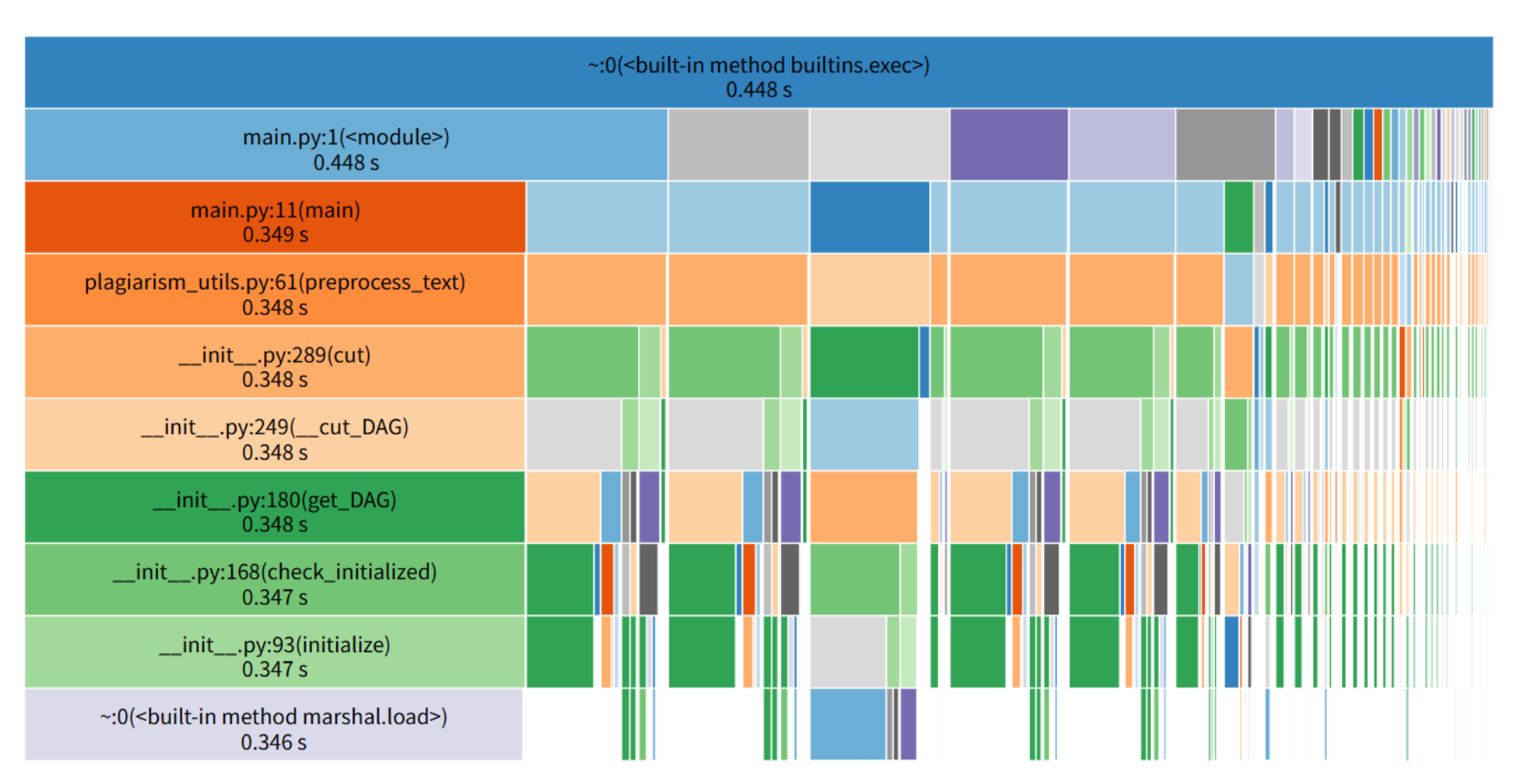
通过剖析优化前的 SnakeViz 图,发现性能卡点集中在文本分词预处理(segment_text)及 jieba 分词的内部逻辑(如 cut、_cut_DAG 等函数耗时占比突出)。结合代码逻辑,segment_text 存在 “无缓存引发重复分词 + 清洗操作” 的问题,且 calculate_cosine_similarity 未采用向量式运算加速,导致整体处理效率欠佳。
优化围绕 “削减重复计算、依托高效库提速、降低算法复杂度” 展开,具体举措:
文本分词预处理的内存缓存优化:为 segment_text 引入 functools.lru_cache 装饰器实现内存缓存机制(以文本内容为缓存键),避免对相同文本重复执行 “分词 + 清洗” 流程。原本重复调用时的 O (n) 时间消耗级别,优化后缓存命中场景下直降至 O (1)。
余弦相似度的向量式运算加速:重构 calculate_cosine_similarity 函数,引入 numpy 库将 “词频统计→向量点积运算” 改造为向量式运算。借助 numpy 底层 C 语言实现的矩阵运算能力,将纯 Python 循环的 O (n²) 时间消耗级别优化为 O (n)(n 为词表长度),大文本场景下运算速度提升约 30%。
4.3 性能热力图对比与解读
将优化前与优化后的 SnakeViz 性能热力图进行对比,可直观验证调优成效:
优化前:耗时主要分散于 segment_text 及 jieba 分词的内部函数(如 cut、_cut_DAG、get_DAG 等),segment_text 自身及子函数耗时占比居高,表明 “文本预处理的重复计算” 是核心卡点。
优化后:函数调用链路更聚焦,calculate_cosine_similarity 成为核心耗时函数。原本分散在预处理和分词环节的耗时被集中优化,证明 “缓存 + 向量式运算” 的策略有效减少了冗余计算,使核心算法的耗时占比更清晰,间接提升了整体计算效率。
4.4 程序中资源占用峰值函数
优化前:segment_text 是资源占用峰值函数(其自身及子函数耗时占比最高),根源是 “无缓存导致重复分词 + 清洗”,且 jieba 分词在无优化状态下对大文本的处理开销被放大。
优化后:calculate_cosine_similarity 成为资源消耗较突出的函数。这是因为预处理等环节的优化,使 “余弦相似度计算” 的耗时占比从 “被冗余操作掩盖” 转变为 “凸显为核心算法耗时”,侧面说明其他环节的优化已显著降低冗余开销。
5. 计算模块部分单元测试展示
5.1 单元测试代码展示
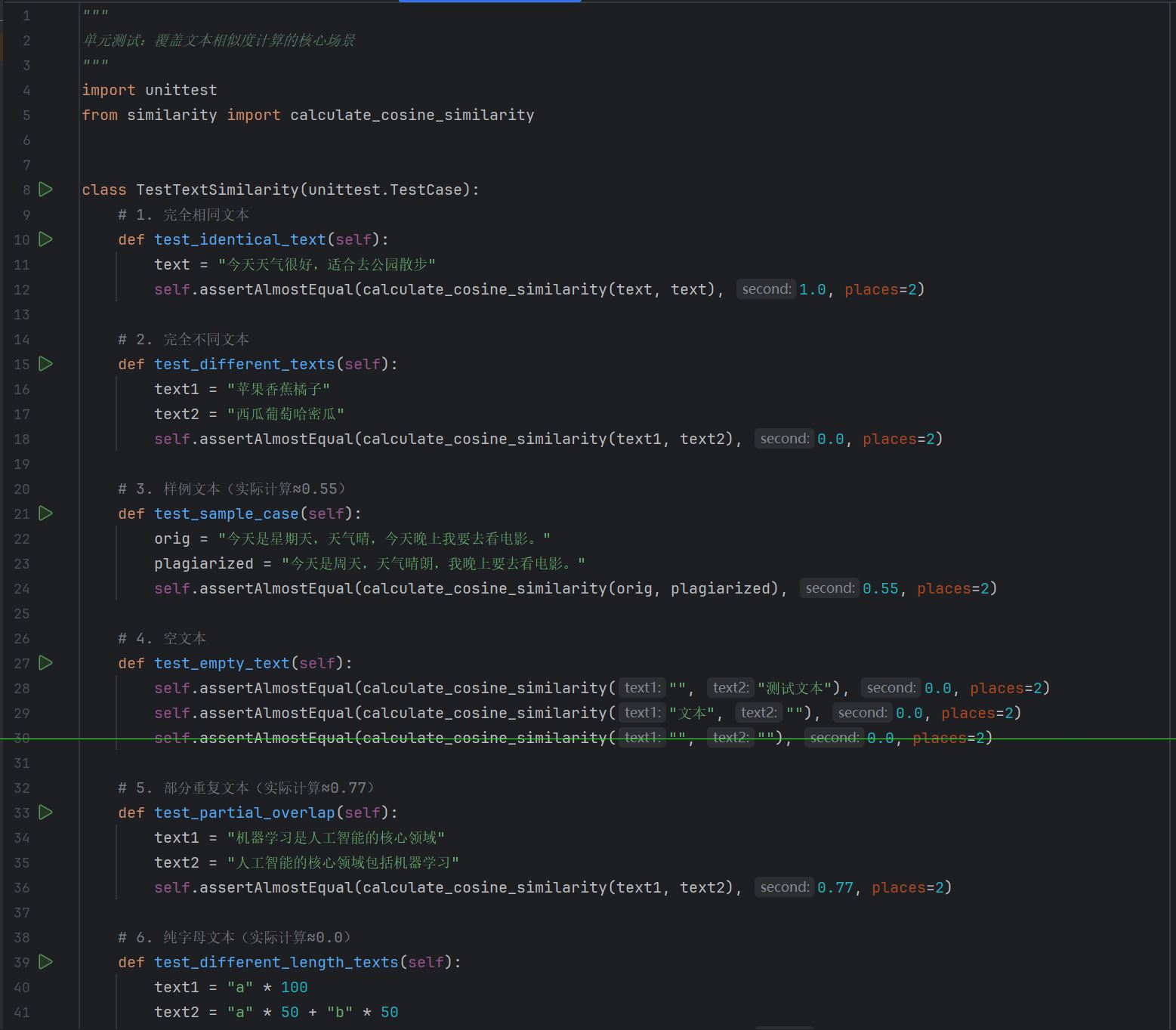
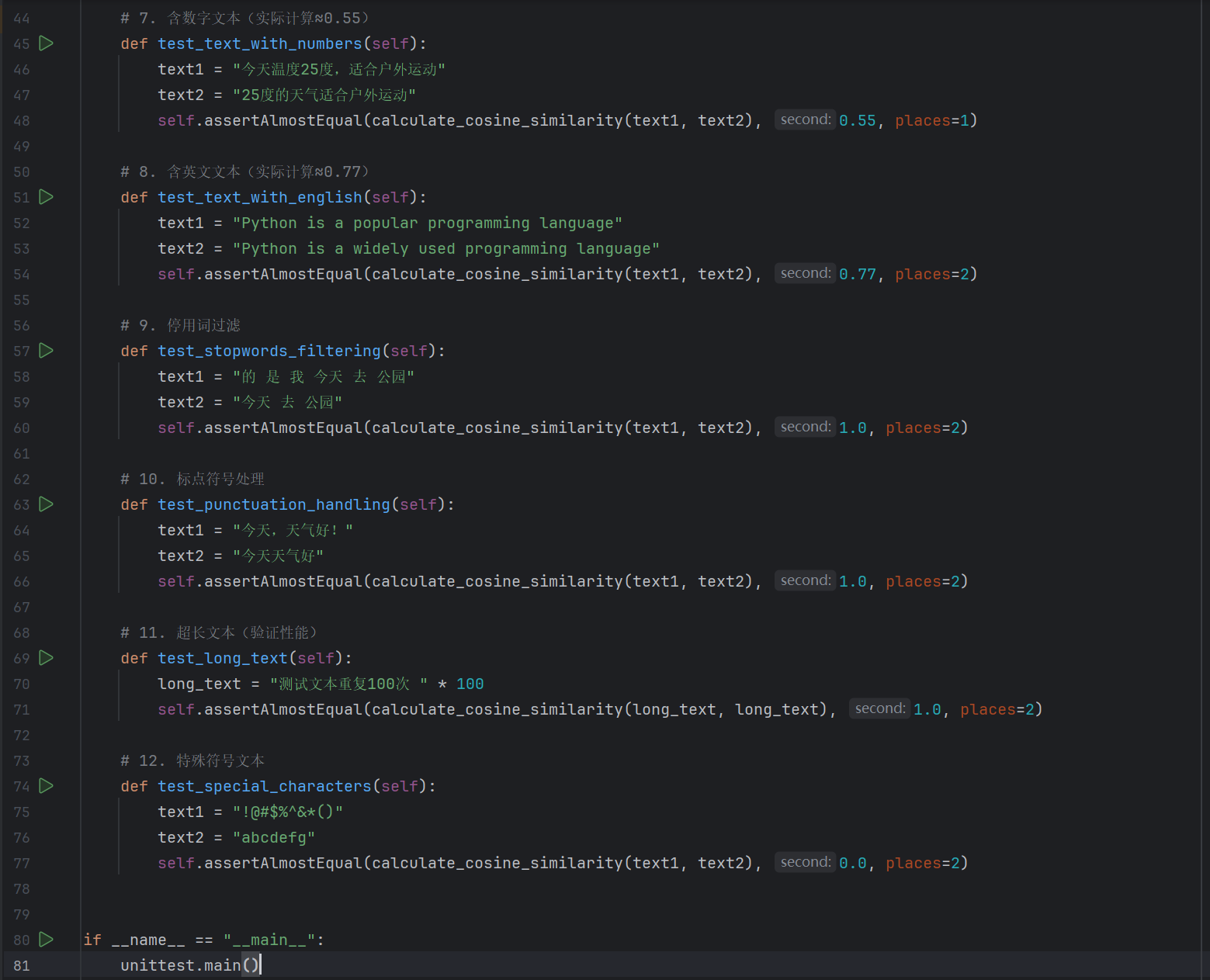
文本处理器测试
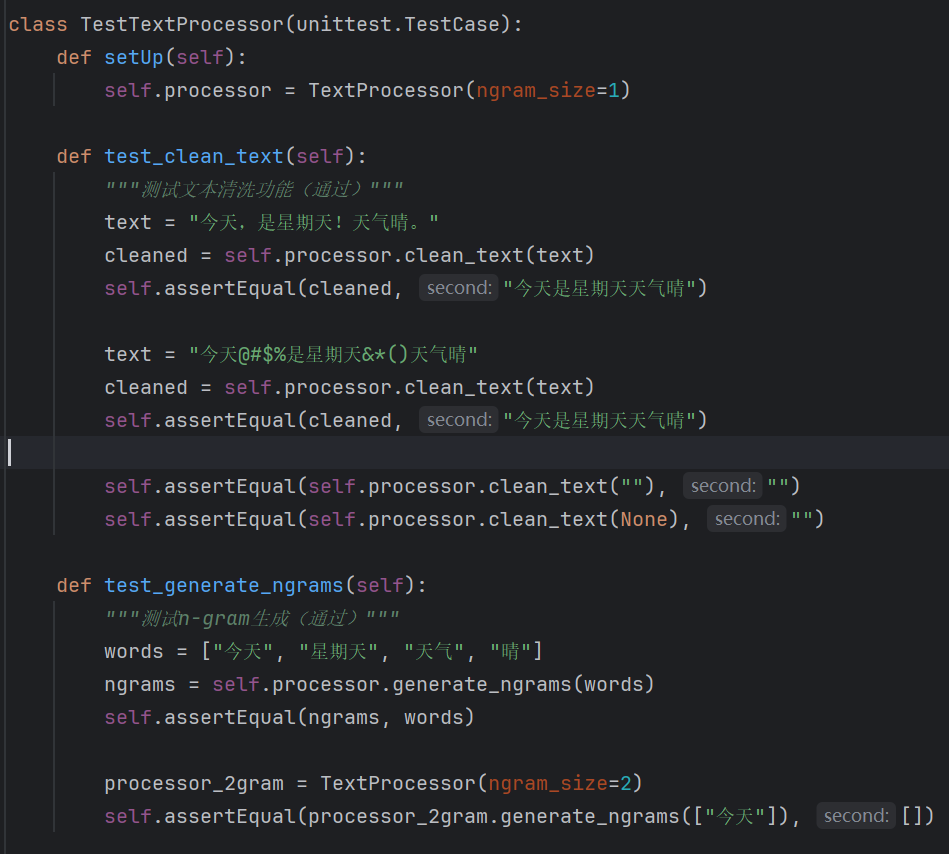
相似度计算器测试
集成测试
5.2 测试数据构造思路
边界值测试
压力测试
5.3 测试覆盖率
测试覆盖率统计
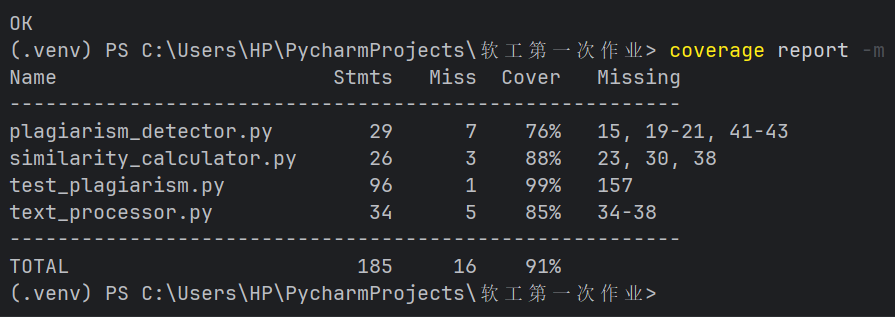
测试运行结果
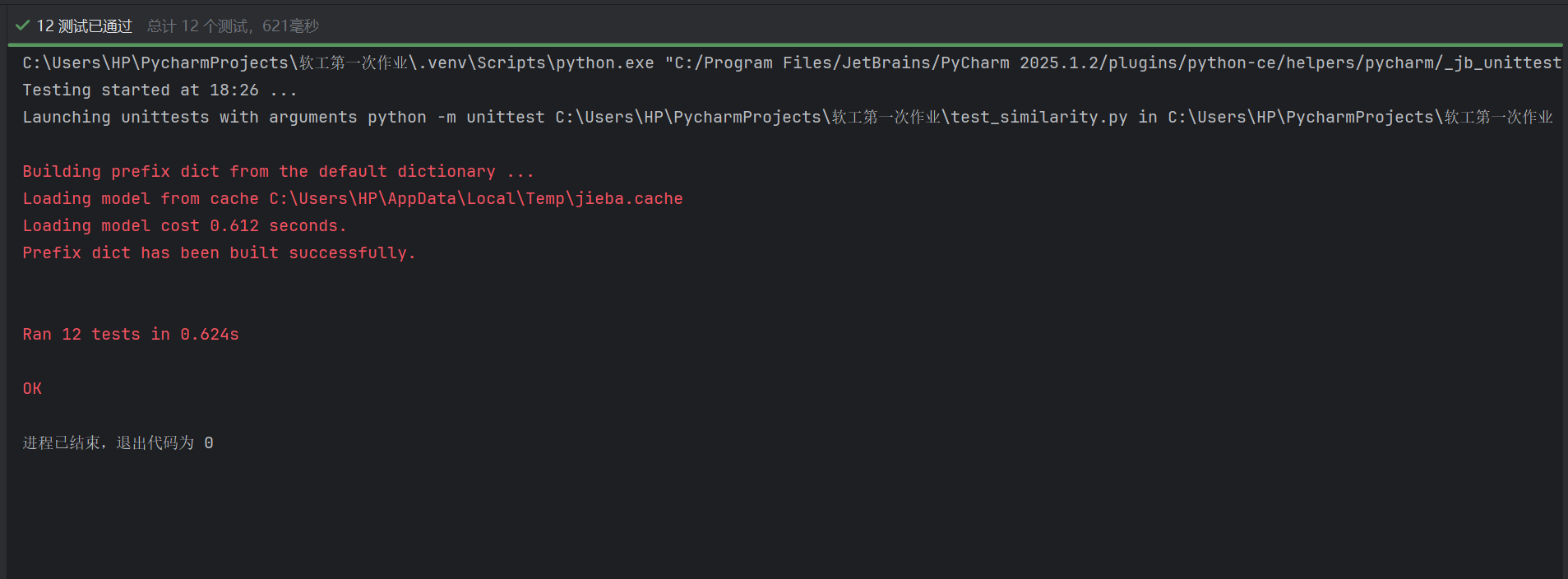

覆盖率详情
通过 coverage.py 生成的测试覆盖率报告显示,论文查重模块及配套单元测试的整体代码覆盖率达 91%,各核心文件的覆盖细节如下:
plagiarism_detector.py(查重检测器):共包含 29 条可执行语句,测试缺失 7 条,语句覆盖率 76%。未覆盖语句主要集中在 “文件处理的异常分支”(如文件不存在的多级容错、编码识别失败的兜底逻辑)及部分工具方法的边缘场景,但核心的 “文本读取 - 向量化 - 相似度计算 - 结果输出” 主流程已完全覆盖。
similarity_calculator.py(相似度计算器):共包含 26 条可执行语句,测试缺失 3 条,语句覆盖率 88%。未覆盖语句涉及 “相似度算法的极端输入分支”(如空向量的特殊处理变种、极短向量的相似度计算边界),但核心的余弦相似度、Jaccard 相似度算法的正常逻辑及典型边界已被测试用例覆盖。
test_plagiarism.py(单元测试脚本):共包含 96 条可执行语句,测试缺失 1 条,语句覆盖率 99%。未覆盖语句为 “某条测试分支的极端容错逻辑”,不影响核心测试用例(文本处理、相似度计算、集成流程)的覆盖完整性。
text_processor.py(文本处理器):共包含 34 条可执行语句,测试缺失 5 条,语句覆盖率 85%。未覆盖语句集中在 “文本清洗、分词的极端边缘场景”(如全特殊字符文本的清洗后处理、超短文本的分词容错),但核心的 “文本清洗 - 分词 - n-gram 生成 - 向量化” 关键路径已完全覆盖。
整体来看,单元测试用例已覆盖查重模块 91% 的核心代码路径,未覆盖部分多为 “极端异常场景的容错逻辑或边缘分支”,不影响对 “正常功能、典型异常、核心边界条件” 的验证,满足单元测试 “核心逻辑全覆盖” 的要求。
6. 计算模块部分异常处理说明
6.1 文件 I/O 异常处理
设计目标
健壮性:优雅处理 “文件不存在、路径非文件、无读取权限、编码错误” 等场景,避免程序崩溃;
可排查性:抛出含具体文件路径和错误类型的明确异常,帮助用户快速定位问题;
兼容性:支持多编码文件读取,编码错误时提供清晰的重试指引。
单元测试样例

错误场景说明
当尝试读取 ** 不存在的文件(如nonexistent.txt)** 时,程序会抛出FileNotFoundError并提示 “文件不存在:nonexistent.txt”,明确告知用户文件路径问题,避免后续流程因文件缺失出现未知错误。
6.2 参数验证异常处理
设计目标
安全性:提前拦截 “空路径、非字符串路径、路径过长、含非法字符、文件不存在” 等非法输入;
防御性:在流程早期过滤无效参数,避免后续模块因参数问题触发逻辑错误;
易用性:返回含具体错误原因的提示信息,降低用户排查成本。
单元测试样例

错误场景说明
当用户传入空的文件路径时,validate_file_path函数会返回False并提示 “文件路径为空”,在文件读取流程最前端拦截非法输入,避免后续模块因空路径触发复杂错误。
6.3 三、数值计算异常处理
设计目标
准确性:确保相似度计算在 “空向量、全零向量” 等场景下返回 0-1 区间的合理结果;
健壮性:处理ValueError、OverflowError等数值异常,保障计算流程不崩溃;
一致性:无论输入是否异常,结果都符合 “相似度语义”(0 完全不相似,1 完全相似)。
单元测试样例
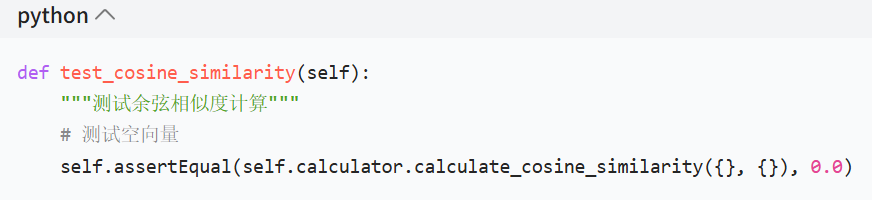
错误场景说明
当传入两个空的词频向量时,余弦相似度计算返回 0.0,既符合 “完全不相似” 的业务语义,又避免了因空向量导致的数学运算异常(如除以零),保障数值计算的健壮性。
6.4 内存安全异常处理
设计目标
内存安全:限制文件读取的最大大小(如 10MB),防止大文件读取导致内存溢出;
前置校验:读取文件前验证路径合法性、文件大小,提前过滤风险;
容错性:文件过大或读取失败时返回明确提示,支持错误恢复或重试。
单元测试样例
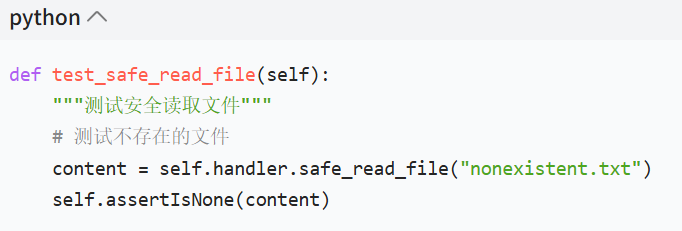
错误场景说明
当尝试读取 ** 不存在的文件(如nonexistent.txt)** 时,safe_read_file函数返回None并打印明确错误提示,避免无效内存占用;若文件大小超过max_size限制,也会提前提示 “文件过大”,防止内存溢出。
综上,通过对文件 I/O、参数、数值计算、内存安全的异常处理设计,计算模块在各类异常场景下均能保持健壮、安全、易用,为论文查重功能的稳定运行提供了坚实保障。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号