
shullfe机制详解
一、shuffle机制概述
shuffle机制就是发生在MR程序中,Mapper之后,Reducer之前的一系列分区排序的操作。shuffle的作用是为了保证Reducer收到的数据都是按键排序的。
二、shuffle机制的流程
还是按照上个随笔MR整体流程的需求来做参考:
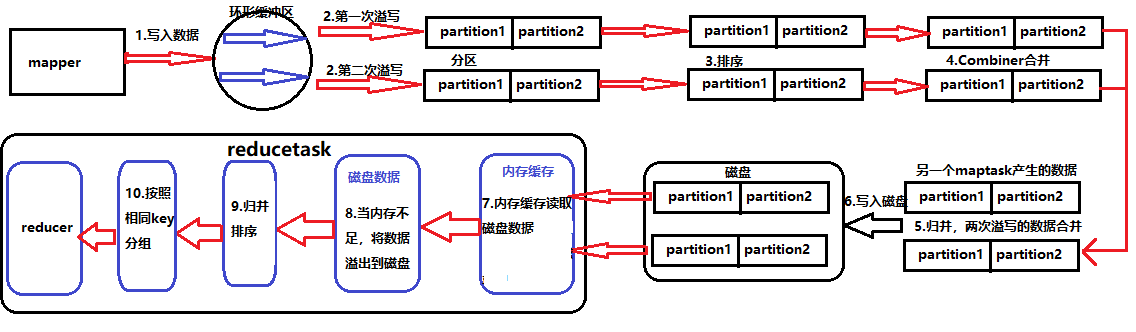
1.Mapper中context的write方法将数据写入环形缓冲区,当容量到达80%发生溢写;
2.按照一块数据为128M,那么应该会发生两次溢写,对溢写出的数据进行分区;
3.然后对完成分区的数据进行区内排序;
4.如果数据量到达一定规模可以使用Combiner合并,这是一个区内合并;
5.接着会将两次一次的数据进行归并操作,合二为一;
6.将归并后的数据写入磁盘;
7.maptask工作完成后,reducetask的内存会缓冲读取磁盘中的数据文件;
8.当内存不足时会将数据溢出到磁盘;
9.对存入磁盘的数据进行归并排序(辅助排序在这个阶段);
10.按照相同的key分组,然后一条一条读入reducer。
如图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号