
Spark-Unit2-Spark交互式命令行与SparkWordCount
一、Spark交互式命令行
启动脚本:spark-shell
先启动spark:./start-all.sh
本地模式启动命令:/bin/spark-shell
集群模式启动命令:/bin/spark-shell --master spark://spark-1:7077 --total-executor-cores 2 --executor-memory 500mb //注释:spark集群模式默认使用全部的核心数,默认使用内存大小为1024Mb
1.用shell的集群模式去执行一个本地wordcount程序:
sc.textFile("/root/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
注意:1)当使用集群模式对本地文件进行wordcount时,会报找不到文件的异常,在执行前要保证在每个节点上的对应路径有被执行的文件(将文件从主节点分发到从节点即可)。
2)本地模式对本地文件进行wordcount时就不需要,因为本地模式是使用master主节点跑任务,而集群模式是使用workers去计算。
2.用shell的集群模式去对一个hdfs上的文件执行wordcount:
sc.textFile("hdfs://192.168.50.186:9000/words.txt").flatMap(_.split(" ")).map((_._)).reduceByKey(_+_).collect
二、用Idea写Spark-WordCount
1.在Idea端创建maven工程,将pom文件所需要的配置命令代码粘贴到pom文件,并自动导入相关依赖包。
2.在main文件夹中创建scala文件夹(注意:要将其转为可用的文件夹 ”source root“)
3.创建一个object单例对象,代码如下:
object SparkWordCount {
def main(args:Array[String]):Unit ={
//1.定义并设置配置信息
val conf:SparkConf = new SparkConf().setAppName("SparkWordCount").setMaster("local[2]")
//2.定义spark程序入口sparkcontext,并接收配置conf
val sc:SparkContext = new SparkContext(conf)
//3.调用sc加载数据、处理数据、存储数据
sc.textFile(args(0))
.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
.saveAsTextFile(args(1))
//4.关闭资源
sc.stop()
}
}
4.添加配置信息Add Configuration
分别添加主类名:Main class、 程序参数:Program arguments

确定然后运行程序。
注意:程序产生的结果文件有两个,而且结果可能随机分布在两个文件中,这是由于spark的自定义分区造成的(后面笔记会专门总结自定义分区)
***将写好的程序打包提交到spark集群中运行:
1.在maven工程中package打包,会出现两个jar包(大的包含依赖包环境,小的只有代码);
2.将大的jar包上次到集群,运行命令:
bin/spark-submit --master spark://spark-1:7077 \
--class SparkWordCount /root/SparkWC-1.0-SNAPSHOT.jar \
hdfs://192.168.50.186:9000/wc.txt hdfs://192.168.50.186:9000/sparkwc
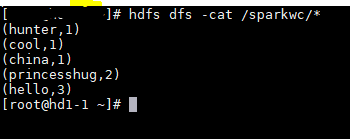
3.运行完成后查看hdfs端产生的结果文件。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号