mysql join大小表
本质上是循环、索引查询、缓存三个因素决定的
Nested-Loop Join 嵌套循环联接算法(NLJ)
当然了,MySQL 优化器其实会对驱动表有一个选择的过程,并不会固定说就是 user 或者就是 depart,为了便于下面的分析,我们可以用 straight_join 来固定驱动表,左侧为驱动表,右侧为被驱动表。
select * from user straight_join depart
on user.name = depart.name;
for r1 in user reference range :
for r2 in depart reference range:
if r1.xx == r2.xx:
send row to client
前提
驱动表通过全表扫描,被驱动表使用所以索引进行定位
时间复杂度
假设驱动表的行数是 N,执行过程就要扫描驱动表 N 行,然后对于每一行,到被驱动表上匹配一次。时间复杂度 N假设被驱动表的行数是 M。每次在被驱动表查一行数据,要先搜索 name 的辅助索引树,然后再回表搜索主键索引树,搜索一棵树的近似复杂度是 log2M,所以在被驱动表上查一行的时间复杂度就是 2 * log2M
时间复杂度为N + N * 2 * log2M
显然,驱动表行数 N 对扫描行数的影响更大,因此应该让小表来做驱动表
Block Nested-Loop Join
带缓存的简单循环连接
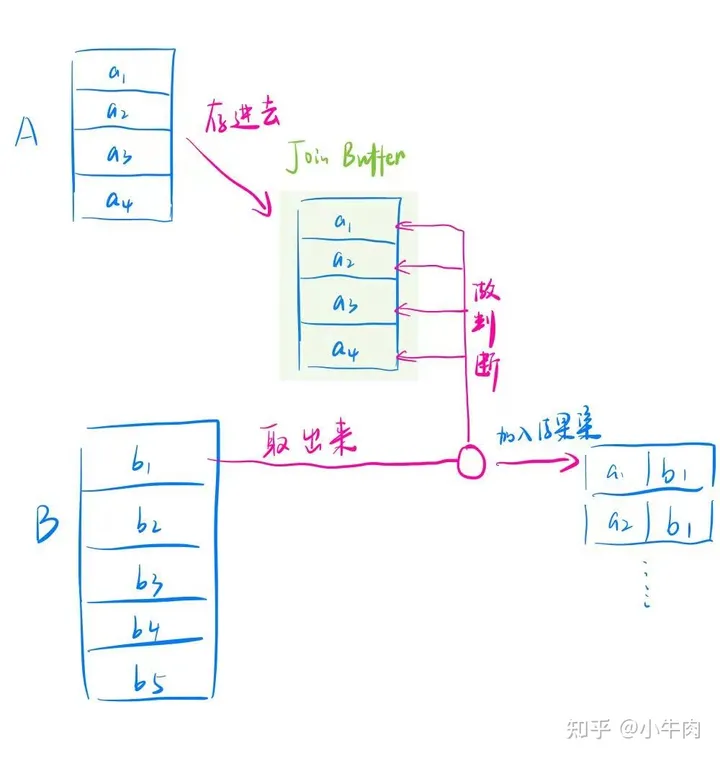
把表 user 中的数据读入线程内存 join_buffer 中,由于我们这个语句中写的是 select *,因此是把整个表 user 都放入了内存扫描表 depart,把表 depart 中的每一行取出来,跟 join_buffer 中的数据做对比,满足 on 条件的,就作为结果集的一部分返回
内存判断 N * M 次。显然,内存判断次数是不受选择哪个表作为驱动表影响的 扫描行数是 N + K * M。另外,N 越大 K 就越大,所以可以把 K 表示为 λ * N,λ 取值范围是 0~1,也即扫描行数是 N + λ * N * M 在 M 和 N 大小确定的情况下,N 越小,整个算式的结果越小。所以结论是,应该让小表当驱动表。 另外,λ 作为式子的参数其实也非常重要,这个值越小就代表分的段越少,即一次可以放入 join_buffer 的行越多,这样,对被驱动表的全表扫描次数就越少。所以,调大 join_buffer_size 也是一个明智的选择。
--这里时间复杂度和使用小表的进行驱动的方式存疑,以公式来看并没有明确的结论--
引用申明:
作者:知乎用户
链接:https://www.zhihu.com/question/35906621/answer/2810132509
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号