数据结构期末复习(4)查找

静态查找:顺序查找、折半查找

动态查找:二叉排序树查找、哈希表查找
衡量查找算法效率的主要标准:平均查找长度ASL

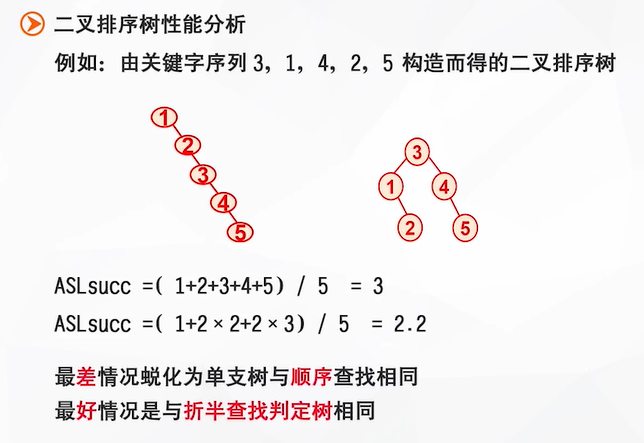
【各种查找的ASL】
顺序查找:

二分查找:
(↓二分查找的判定树,其深度为⌊log n⌋+1)
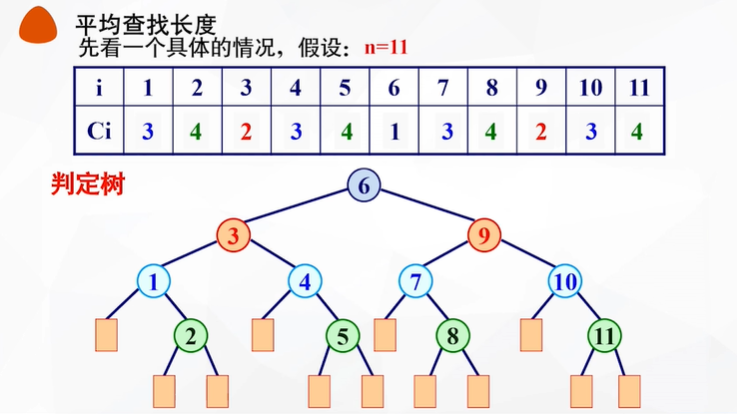
(橙色矩形:查找失败的情况)

二分查找对于插入和删除来说是困难的(因为要保证整个表的有序性)
因此二分查找适用于常常需要查找(ASL在n>50时已经达到了对数级别),且很少改动的有序查找表
二分查找/折半查找
时间复杂度:o(log(n))
查找一个元素的最大比较次数:1~[ log2 n ] + 1 ( n为元素的个数)(因为二分法每次都会把范围缩小一半,因为最后剩一个元素时,也要执行查找过程,所以+1)
仅当列表是有序的时候,二分查找才管用。
步骤:
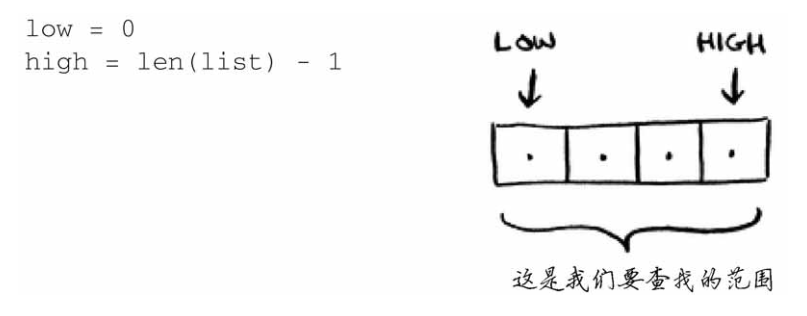
每一次都要检查中间的元素mid = (low+high)/2,当mid不是整数时,将mid向下取整

每一次都把list[mid]与要查找的数guess对比:
①list[mid]>guess:high = mid - 1

②list[mid]<guess:low = mid + 1
③list[mid] = guess:mid就是要查找的数的位置

二分查找是典型的分治类算法,所以也可以用递归实现:
https://www.cnblogs.com/128-cdy/p/11716438.html
分块查找
https://www.cnblogs.com/ciyeer/p/9067048.html
二叉排序树(BST)

静态查找表不能为空;而二叉排序树作为动态查找的一种,它允许为空。

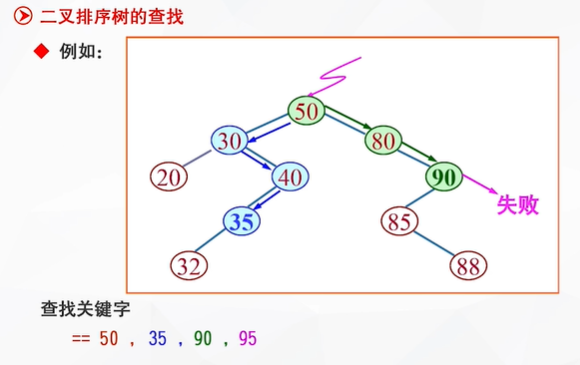
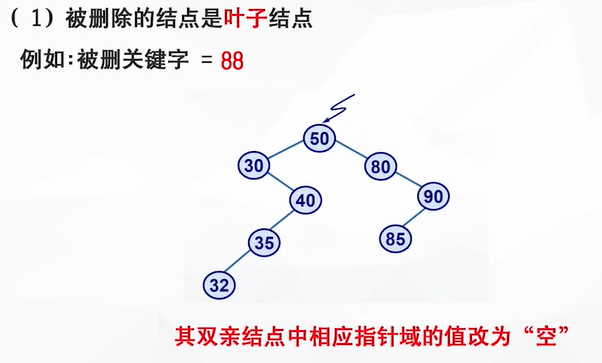
查找为空时——失败
(如:查找关键字为90时,首先与根节点50比较,大了,走右枝;与80比较,大了,走右枝;与90比较,大了,走右枝,但是发现此时没有右枝了,故查找失败。一共比较了3次。)

这是一个尾递归算法,可以转化为效率更高的非递归的循环算法实现。
二叉排序树的插入
插入位置:原来是查找失败的位置
eg:
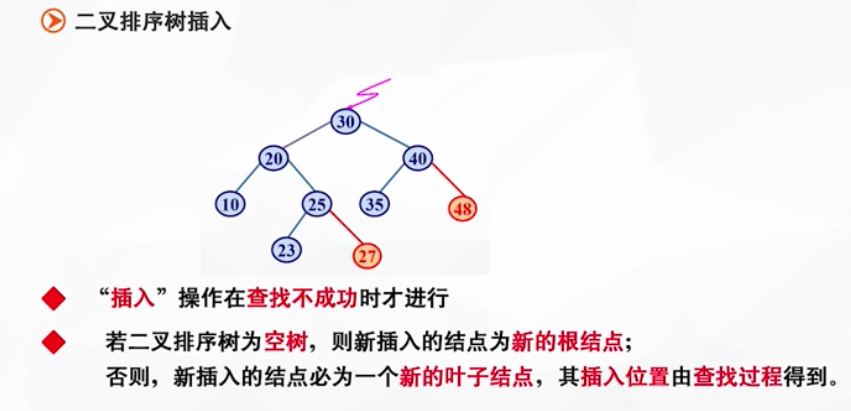
假设要插入27:
首先比较30与27,27<30,故走左枝;
27>20,走右枝;
27>25,走右枝;此时右枝为空,故为插入的地方。
假设要插入48:
首先比较30与48,48>30,故走右枝;
48>40,走右枝;此时右枝为空,故为插入的地方。

二叉排序树的生成
二叉排序树的形态完全由关键字的输入顺序决定。
eg:以下两棵二叉排序树的关键字都相同,但是输入顺序不同,二叉排序树的形态也就不同
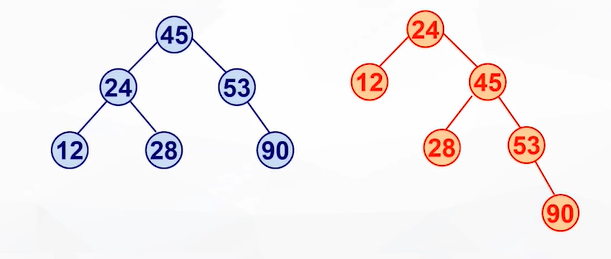

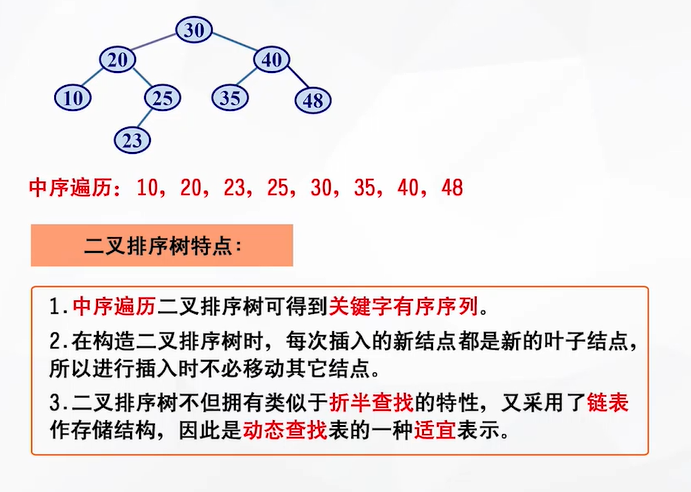
二叉排序树是如何起到排序作用的?——中序遍历二叉排序树,得到一个有序序列
二叉排序树的删除

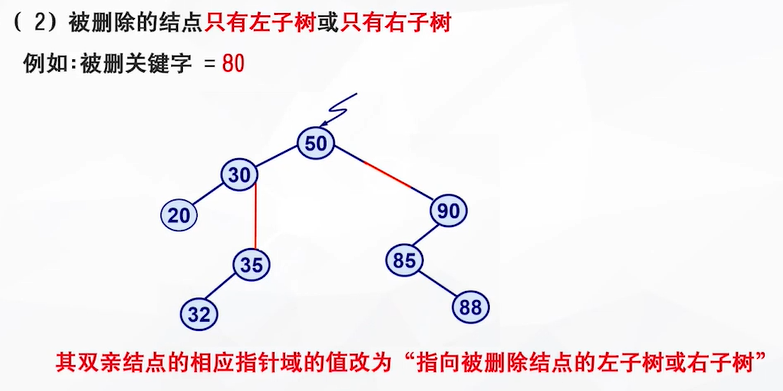
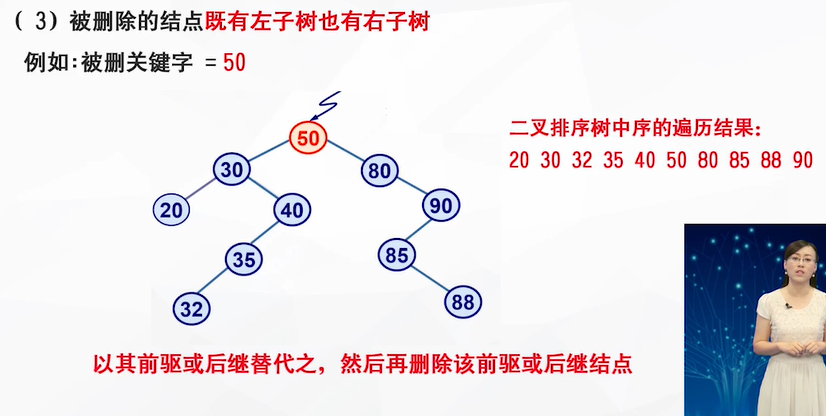
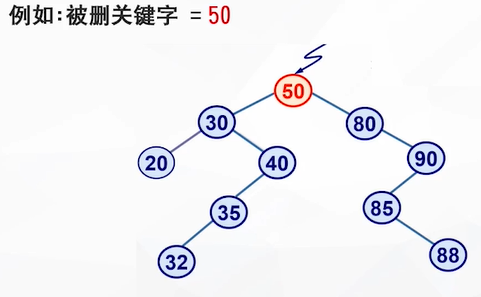
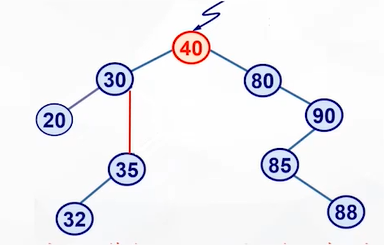
当被删除的结点既有左子树也有右子树时,可以替换被删除结点的结点是:左子树最右下角的结点 or 右子树最左下角的结点
为什么要这样呢,根据二叉查找树的性质,父节点的指针一定比所有左子树的节点值大而且比右子树的节点的值小,为了删除父节点不破坏二叉查找树的平衡性,应当把左子树最大的节点或者右子树最小的节点放在父节点的位置,这样的话才能维护二叉查找树的平衡性。
 →
→ 
ASL计算
二叉搜索树查找失败时的ASL计算
参考:https://zhidao.baidu.com/question/525842299.html
查找失败时,计算的关键字数=题目所给的关键字数+1
eg.
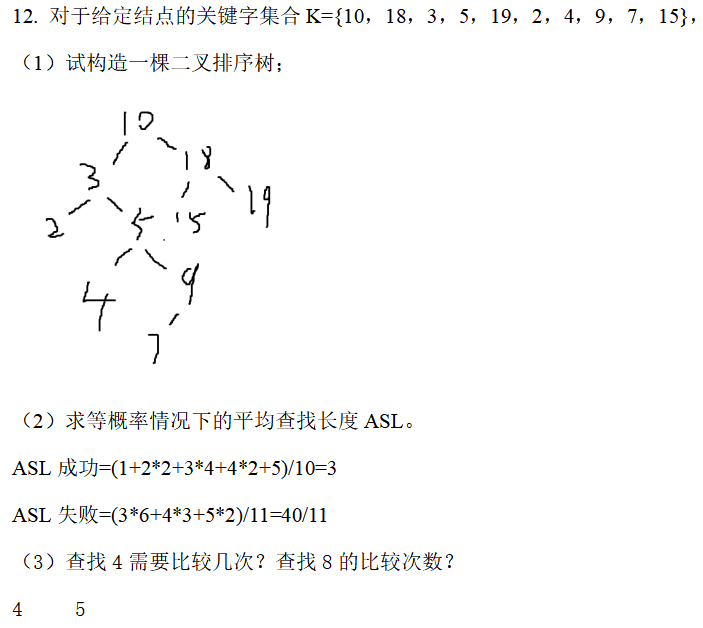
看题(2)查找失败的情况:
步骤:
(1)将叶子结点为空的地方补上(这些空的叶子结点就是要计算的)
(2)接下来计算ASL和成功时的ASL计算同理,只不过计算的是空叶子结点:
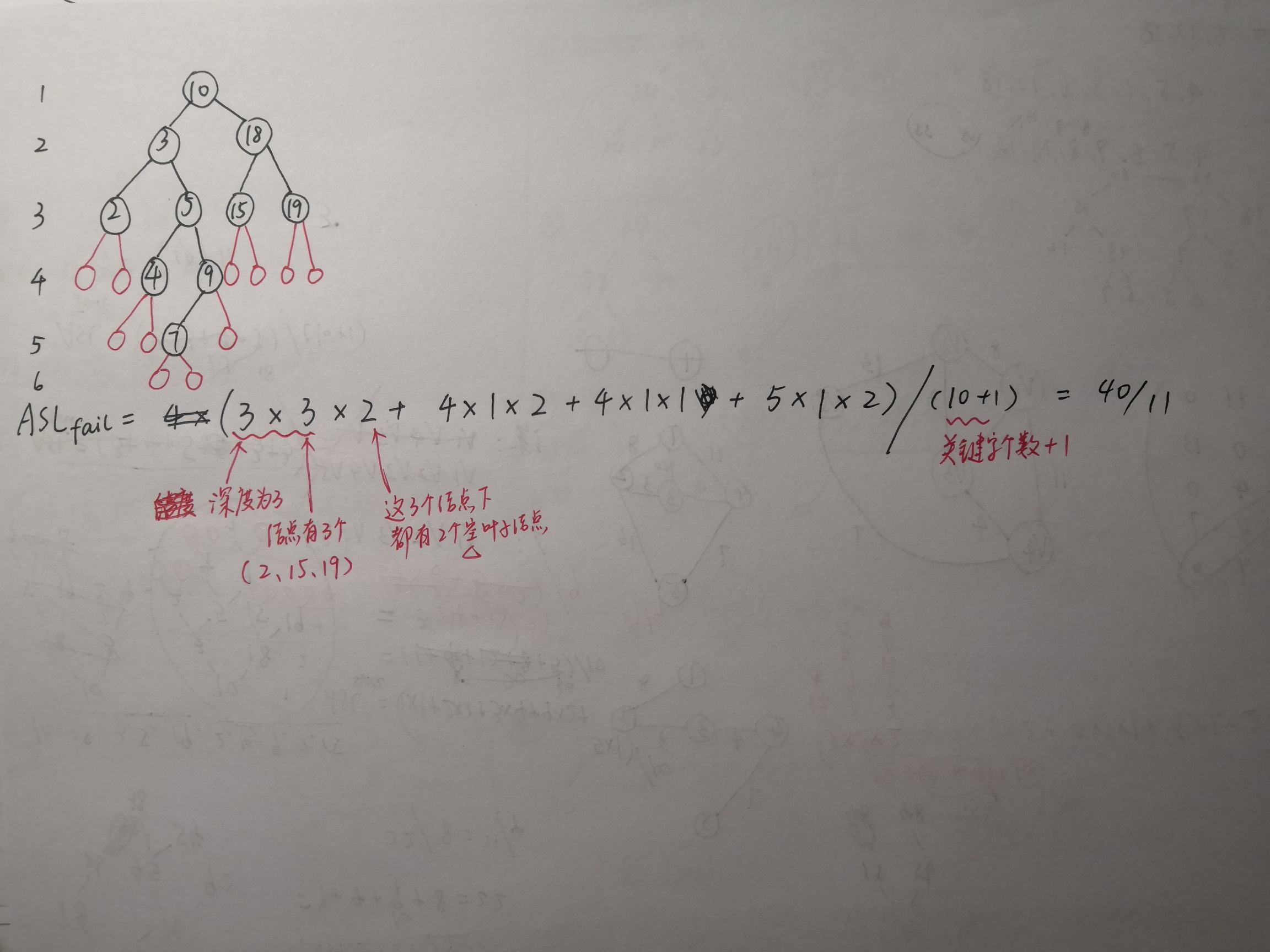
哈希表 / 散列表
实质:前面提到的几种查找都需要通过比较来查找关键字,ASL都不可能等于0;而我们希望直接通过关键字的值进行查找,而不需要进行多余的查找,使得ASL=0(平均查找长度最优)
步骤:
根据给出的关键字,用哈希函数计算出的Hash值(就是地址),查找该地址的元素是否与需要查找的关键字相同,
如果是,则查找成功;如果查找为空,则查找失败。
经常会出现冲突现象:虽然关键字不同,但Hash值相同(不同关键字对应相同的存储地址)
策略:选取恰当的哈希函数,让冲突尽可能少的产生
哈希函数的构造
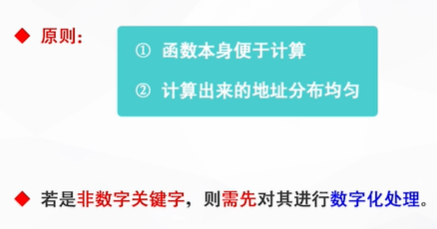
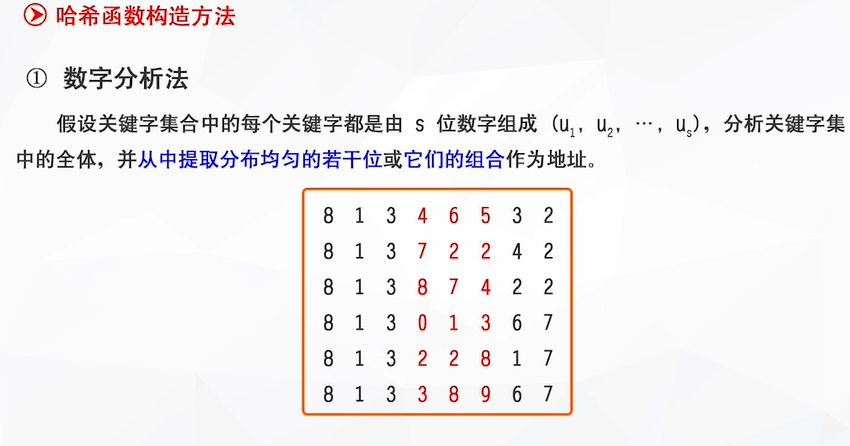
看上图:前三位因为都一样,所以不能选取为哈希地址
中间三位的数字分布均匀(也就是重复率低),可以选取为哈希地址
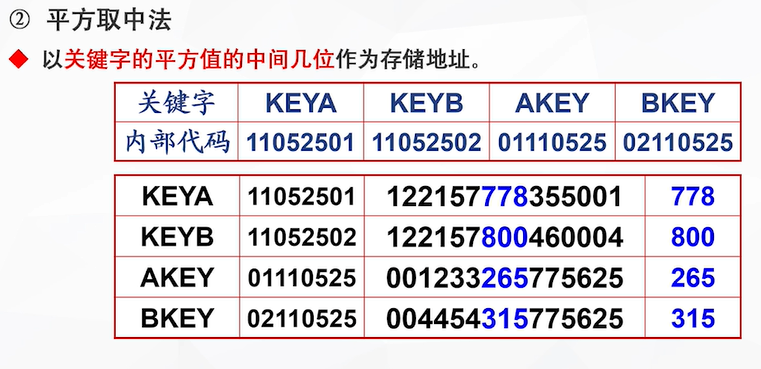
平方取中法适用于关键字内部代码相差不明显,但平方后明显的情况,在平方后选取分布平均的几位数作为存储地址(蓝色字)
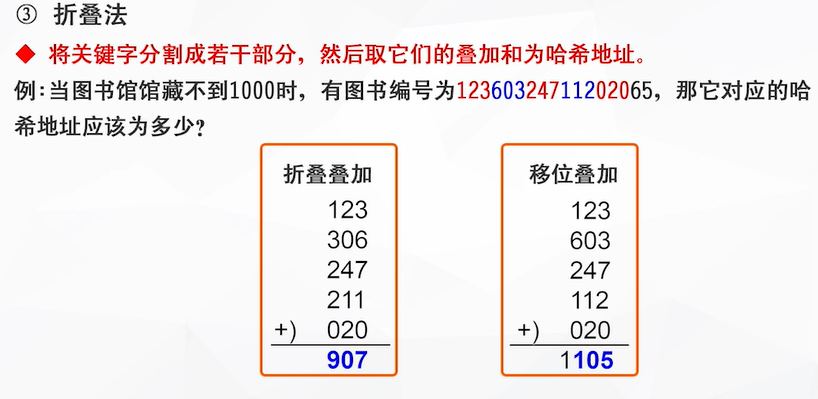
将关键词分为若干部分,其中分出的奇数部分不变,偶数部分整体反向(如:603变为306),然后相加
右列式的情况:多了一位(千位),舍去千位直接取后三位作为哈希地址即可

要注意:左边的情况是可行的,右边的情况是不行的(p=9时,哈希地址冲突太多了,究其根本还是因为9不是<=10的最大素数)
哈希处理冲突


(1) 线性探测再散列:
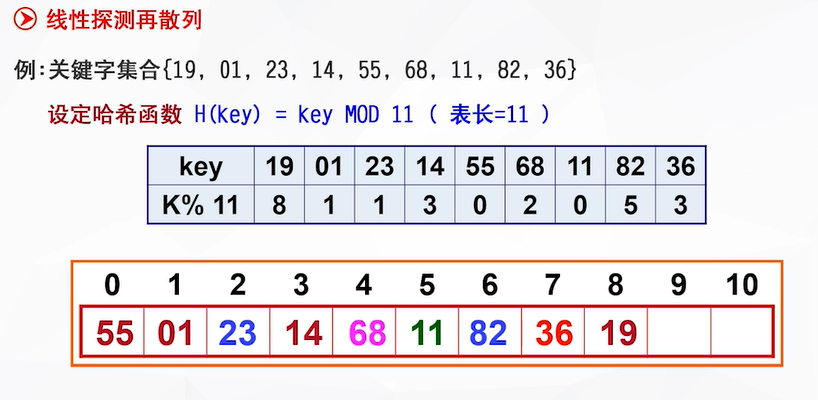
(1)存储空间分布:
①求余:关键字key % 表长(结果为蓝色表格的内容)
求余的结果将作为各个关键字的哈希地址
②将关键字依次填入到存储空间中(红色表格):
填19到地址8处
→填01到地址1处
→想填23到地址1处,但地址1处已经被占了,于是关键字23的地址+1(此时设c=1),即将23填到地址2处
→填14到地址3处
→填55到地址0处
→想填68到地址2处,但地址2处已经被占了,于是关键字68的地址+1=3(此时设c=1),但地址3也被占了,地址再+1=4,即将68填到地址4处
(后面几位同理:只要自己原有地址被占,就不断后移,直到找到空间存储)
(2)查找关键字,求ASL(查找成功or失败两种情况)
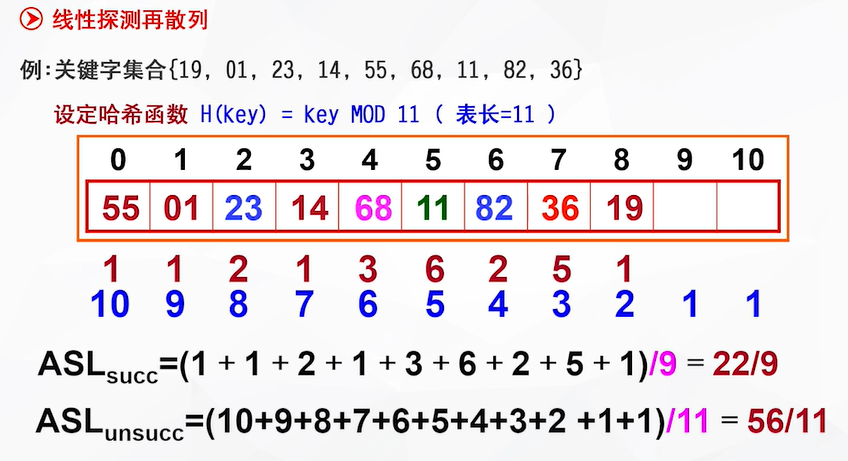
1、查找成功的情况:(因为是查找成功,所以只考虑从地址0-8的情况)
(此处假设要查找的是19)
一开始,关键字19通过哈希函数计算出地址为8,对比地址为8的内容,发现的确与19吻合,于是标记比较次数为1(红色数字)
(假设要查找的是23)
关键字23通过哈希函数计算出地址为1,对比地址为1的内容,发现23不与地址为1的01吻合,于是将关键字23与地址为2(1+1)的关键字比较,发现吻合,于是标记比较次数为2(红色数字)
……(其余同理)
2、查找失败的情况(查找失败时,需要考虑所有情况。如有11个地址空间,则要考虑11种情况)

解释上图:(红表格下的蓝色数字:要比较n次才能知道查找失败)
假设现在有一个不属于所有关键字的一个数
首先与55比较,不吻合,接着和后一位比较,依旧不吻合……直到与地址为8的元素比较,也不吻合;再往后移动一位,到了空的地址9处,可知查找失败。(不管前面关键字的存储是否连续,只要与空的空间进行对比了,就已经是查找失败了),因此55需要对比10次才能知道查找失败;
后面地址0-8处的同理。
地址9-10处:假设哈希函数计算结果为9或10,直接分别与空的空间对比1次,就知道查找失败了。
( 2 )二次探测再散列:
(1)存储空间分布:

①求余
②将关键字按地址填入(填入时空间为空的情况与线性探测再散列的情况相同)
若是冲突(算出的地址空间已经被占了):
按12,-12,22,-22...的间隔跳跃(上一点中,线性探测再散列的间隔就是+1):
如果用哈希函数算出的地址被占,则看地址+1的空间是否被占,如果是,则看地址-1的空间是否被占;
如果是,则看地址+22的空间是否被占,如果是,则看地址-22的空间是否被占……
(在这个过程中,如果超出了表长空间,则将其对表长取余:如跳跃到了地址为-1的地方,但地址-1是非法的,则-1%11,应该将地址-1改为地址10)
(2)求ASL
大体上与上一点同理,唯一需要注意的是二次探测再散列的跳跃间隔(无论查找成功还是失败的情况都是)

分析:
如一个不存在与关键字的数用哈希函数算出结果为0,
则首先与地址0处的55比较,不吻合;
接着跳跃间隔+12,则与地址1的01比较,不吻合;
接着跳跃间隔-12,则与地址10(-1%11=10)的11比较,不吻合;
接着跳跃间隔+22,则与地址4(0+22)的36比较,不吻合;
接着跳跃间隔-22,则与地址7(-4%11=7)比较,为空,证明查找失败;
( 3 )链地址法 / 拉链法:
基本思路:
将全部具有同样哈希地址的而不同keyword的数据元素连接到同一个单链表中。
假设选定的哈希表长度为m,则可将哈希表定义为一个有m个头指针组成的指针数组T[0..m-1]。
凡是哈希地址为i的数据元素,均以节点的形式插入到T[i]为头指针的单链表中。而且新的元素插入到链表的前端,这不仅由于方便。还由于常常发生这种事实:新近插入的元素最优可能不久又被訪问。
特点
(1)拉链法处理冲突简单。且无堆积现象,即非同义词决不会发生冲突,因此平均查找长度较短;
(2)因为拉链法中各链表上的结点空间是动态申请的。故它更适合于造表前无法确定表长的情况。
(3)开放定址法为降低冲突。要求装填因子α较小。故当结点规模较大时会浪费非常多空间。而拉链法中可取α≥1,且结点较大时,拉链法中添加的指针域可忽略不计,因此节省空间;
(4)在用拉链法构造的散列表中,删除结点的操作易于实现。仅仅要简单地删去链表上对应的结点就可以。而对开放地址法构造的散列表,删除结点不能简单地将被删结点的空间置为空,否则将截断在它之后填人散列表的同义词结点的查找路径。这是由于各种开放地址法中,空地址单元(即开放地址)都是查找失败的条件。
因此用开放地址法处理冲突的散列表上运行删除操作,仅仅能在被删结点上做删除标记,而不能真正删除结点。
一定要注意:链表法在添加结点时,一定要用头插法!即后面添加的结点应该插在先添加的结点前面!(后来的补充:插在前面还是插在后面好像没有强制性orz)
求ASL:
eg:
将关键字序列{1 13 12 34 38 33 27 22} 散列存储到散列表中。散列函数为:H(key)=key mod 11,处理冲突采用链地址法,求在等概率下查找成功和查找不成功的平均查找长度
1mod11=1,所以数据1是属于地址1
13mod11=2,所以数据13是属于地址2
12mod11=1,所以数据12也是属于地址1(这个数据是数据1指针的另一个新数据)
34mod11=1,所以数据34是属于地址1(这个数据是数据12指针的另一个新数据)
38mod11=5,所以数据38是属于地址5
33mod11=0,所以数据33是属于地址0
27mod11=5,所以数据27是属于地址5,(这个数据是数据38指针的另一个新数据)
22mod11=0,所以数据22是属于地址0,(这个数据是数据33指针的另一个新数据)
链地址法处理冲突构造所得的哈希表如下:
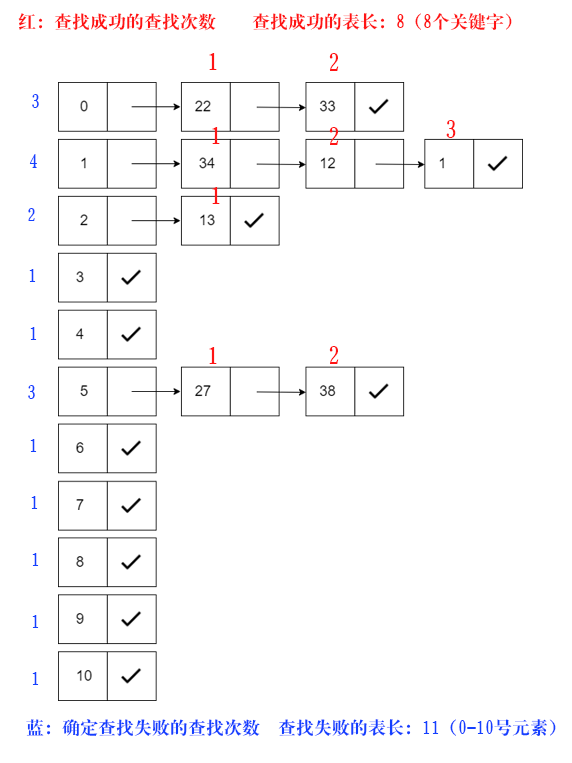
查找成功时: ASL=(3×1+2×3+1×4)/8=13/8, 其中红色标记为查找次数。也就是说,需查找1次找到的有4个,其它以此类推…
查找不成功时:ASL=(3+4+2+1+1+3+1+1+1+1+1)/11=19/11;或者 ASL=(7×1+1×2+2×3+1×4 )/11=19/11,其中红色标记为查找次数。以第一个3为例,其对应于0地址位,确定查找不成功需比较3次,其它以此类推…
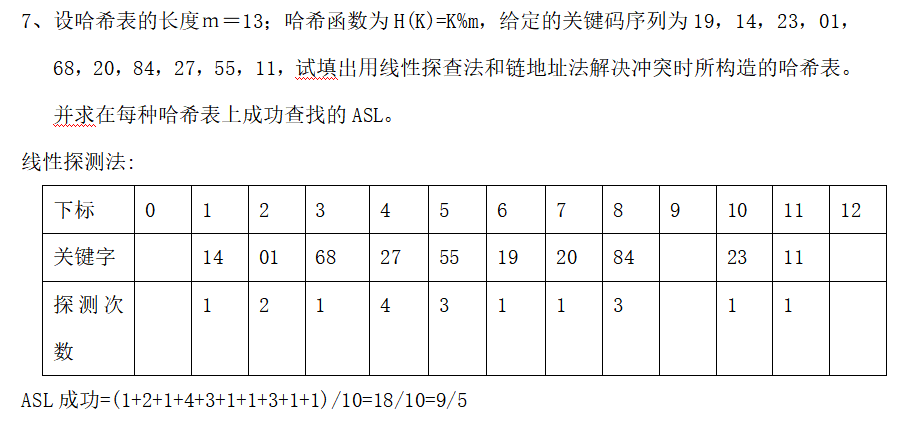
eg2.


哈希表的装填因子
装填因子 = (哈希表中的记录数) / (哈希表的长度)
装填因子是哈希表装满程度的标记因子。值越大。填入表中的数据元素越多,产生冲突的可能性越大。
部分内容为转载,感谢:(如有侵权,请联系我删除)
https://www.cnblogs.com/gavanwanggw/p/7307596.html
https://blog.csdn.net/ecnuThomas/article/details/69666559

 浙公网安备 33010602011771号
浙公网安备 33010602011771号