
【Python】Python 变量类型(变量赋值,数据类型,数据转换)
目录
Pythone变量类型
变量赋值
标准数据类型
数据类型转换
Python 变量类型
变量存储在内存中的值。这就意味着在创建变量时会在内存中开辟一个空间。基于变量的数据类型,解释器会分配指定内存,并决定什么数据可以被存储在内存中。因此,变量可以指定不同的数据类型,这些变量可以存储整数,小数或字符。
变量赋值
Python 中的变量赋值不需要类型声明。每个变量在内存中创建,都包括变量的标识,名称和数据这些信息。每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建。等号(=)用来给变量赋值。等号(=)运算符左边是一个变量名,等号(=)运算符右边是存储在变量中的值。
[root@tanbaobao myPy]# vi variable.py #!/usr/bin/python3.8 # -*- conding:UTF-8 -*- name = "thy" sex = 20; weight = 100.0; print(name) print(sex) print(weight) [root@tanbaobao myPy]# python3.8 variable.py thy 20 100.0
另外还有多个变量一起赋值(多变量赋值)。
# 创建一个整型对象,值为2,三个变量被分配到相同的内存空间上。 >>> a=b=c=2 >>> print a 2 # 两个整型对象 1 和 2 分别分配给变量 a 和 b,字符串对象 "thy" 分配给变量 c。 >>> a,b,c=1,2,"thy" >>> print(a) 1 >>> print(b) 2 >>> print(c) thy
标准数据类型
Python 定义了一些标准类型,用于存储各种类型的数据。
Python有五个标准的数据类型:
是不可改变的数据类型,这意味着改变数字数据类型会分配一个新的对象。当你指定一个值时,Number对象就会被创建。
可以使用del语句删除对象的引用
del var1[,var2[,var3[....,varN]]]]
# 删除单个或多个 del var del var_a, var_b
数字类型有四种:
- int(有符号整型)
- long(长整型[也可以代表八进制和十六进制])
- float(浮点型)
- complex(复数)
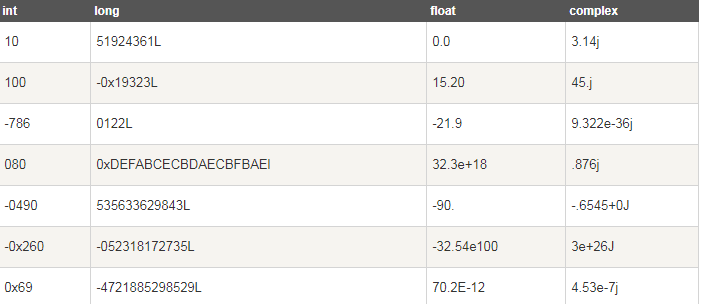
- 长整型也可以使用小写 l,建议使用大写 L,避免与数字 1 混淆。Python使用 L 来显示长整型。
- Python 还支持复数,复数由实数部分和虚数部分构成,可以用 a + bj,或者 complex(a,b) 表示, 复数的实部 a 和虚部 b 都是浮点型。
PS:long 类型只存在于 Python2.X 版本中,在 2.2 以后的版本中,int 类型数据溢出后会自动转为long类型。在 Python3.X 版本中 long 类型被移除,使用 int 替代。
字符串或串(String)是由数字、字母、下划线组成的一串字符。
s="a1a2···an"(n>=0)
python的字串列表有2种取值顺序:
- 从左到右索引默认0开始的,最大范围是字符串长度少1
- 从右到左索引默认-1开始的,最大范围是字符串开头
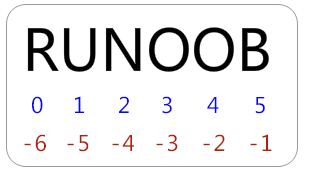
如果你要实现从字符串中获取一段子字符串的话,可以使用 [头下标:尾下标] 来截取相应的字符串,其中下标是从 0 开始算起,可以是正数或负数,下标可以为空表示取到头或尾。[头下标:尾下标] 获取的子字符串包含头下标的字符,但不包含尾下标的字符。
>>> s = 'abcdef' >>> s[1:5] 'bcde'
上面的结果包含了 s[1] 的值 b,而取到的最大范围不包括尾下标,就是 s[5] 的值 f。

加号(+)是字符串连接运算符,星号(*)是重复操作。
[root@tanbaobao myPy]# cat demo02.py #!/usr/bin/python3.8 # -*- conding:UTF-8 -*- str = 'Hello World!' print(str) print(str[0]) print(str[2:5]) print(str[2:]) print(str[:-2]) print(str * 2) print(str + "test") [root@tanbaobao myPy]# python3.8 demo02.py Hello World! H llo llo World! Hello Worl Hello World!Hello World! Hello World!test
>>> str1 = 'hello tanbaobao' >>> str1[:6] 'hello ' >>> str1[6] 't' >>> str1[:6] + 'add' + str1[6:] 'hello addtanbaobao'
str()常用函数:
a)字符串处理字母的函数:
.upper() #全部转为大写字母 .lower() #全部转为小写字母 .title() #首字母大写 .capitalize() #首字母大写 .swapcase() #大小写相互转换
.lstrip() #去掉左边的空格
.rstrip() # 删除右边,也就是末尾的空格
.strip([chars]) # 去掉左右两边的空格,中间的空格不作处理。默认不带参数是去掉空格,如果带参数,则去掉指定的chars
实例
# capitalize()将首字母转换为大写 >>> str2 = 'xiaoxiao' >>> str2.capitalize() 'Xiaoxiao' # casefold()将字符串转换为小写 >>> str2 = "DFNCDOSVNxncn" >>> str2.casefold() 'dfncdosvnxncn' # center(width)将字符串填充,使用空格来填充至长度width的新字符串
# ljust(width)左对齐,rjust(width)右对齐
>>> str2.center(20) ' DFNCDOSVNxncn ' # endswith(sub)检查字符是否是以sub字符结束,如果是返回True,不是则返回False
# startswith(prefix[,start][,end])检测是否以什么开始
>>> str2.endswith('c') False >>> KeyboardInterrupt >>> str2.endswith('n') True # expandtabs(tabsize=8)将字符中的\t符转换为空格,不指定参数,默认空格数为8 >>> str3 = 'i\tlove\tanbaobao!' >>> str3.expandtabs() 'i love anbaobao!'
b)关于查找字符串相关的函数:
.find(sub,start[,end]) #查找指定的字符串,没有则返回-1,找到会返回索引位置 ,find(sub,start,end) .rfind(sub,start[,end]) #从字符串的右边开始查找
.lfind(sub,start[,end]) # 从字符串左边开始查找
.count() #获取指定字符在该字符串中出现的次数
.index() #和find()功能类似,但是找不指定字符会报错,而find()则会返回-1 (也有rindex,lindex)
find方法和index方法有三个参数, sub=想查找的字符,start=指定位置,end=结束位置
实例
# count(sub,start[,end])返回sub中重现的字符次数,start和end表示参数范围 >>> str2.count('n') 2 # find(sub,start[,end])检查sub是否包含在字符串中,如果有则返回索引值,没有则返回-1 >>> str3.find('cr') -1 >>> str3.find('ao') 10 # index(sub,start[,end])和find方法一样,但是如果sub不在字符串内会报异常 >>> str3.index('b') 9 >>> str3.index('t') Traceback (most recent call last): File "<pyshell#22>", line 1, in <module> str3.index('t') ValueError: substring not found
c)与字符串判断相关:
.isalnum() #判断字符串是否全部是数字或者字母 .isupper() #判断是否全是大写 .islower #判断是否全是是小写 .isalpha() #判断是否全是字母 .isdecamal() #判断字符串是都只包含十进制字符 定义一个十进制字符串,只需要在字符串前面加个“u”前缀即可 .isdigit() #判断是否全部是数字 .isidentifier() #判断变量名是否是python的标识符 .isspace() #判断是否全是空格
.istitle() # 符合标题,首字母大写,返回True,否则返回False
PS:返回是布尔类型
注意:
join():以字符串作为分隔,插入到sub中所有字符之间
>>> str4 = 'Tanbaobao' >>> str4.join('123') '1Tanbaobao2Tanbaobao3'
partition():找到子字符串sub,把字符分为3个元组(pre_sub,sub,fol_sub),如果字符串不包含sub则返回源字符串('原字符串','','')
>>> str6 = 'i love tanbaobao' >>> str6.partition('ve') ('i lo', 've', ' tanbaobao')
replace(old,new[,count]):将旧字符串替换为新字符串
>>> str6.replace('i','I') 'I love tanbaobao'
split(sep=None,maxsplit=-1):不带参数默认以空格为分隔符切片字符串,如果maxsplit有设置则仅分隔maxsplit个子字符串,返回切片后的子字符串拼接列表
>>> str6 'i love tanbaobao' # 默认按空格切 >>> str6.split() ['i', 'love', 'tanbaobao'] # 按i切,将i去除了 >>> str6.split('i') ['', ' love tanbaobao'] # 按a来切,a去除 >>> str6.split('a') ['i love t', 'nb', 'ob', 'o']
translate(table):根据table的规则(可以由str.maketrans('a','b')定制),转换字符串中的字符
>>> str7 ' aaaassss ddff' # 将s转换为b >>> str7.translate(str.maketrans('s','b')) ' aaaabbbb ddff' # 输出的是ASCII编码 >>> str.maketrans('s','b') {115: 98}
zfill(width):返回长度为width的字符串,原字符串右对齐,前边用0填充
>>> str3.zfill(30) '00000000000000i\tlove\tanbaobao!'
字符串格式化
a)位置参数
>>> "{0} love {1}.{2}".format("I","Love","tanbaobao") 'I love Love.tanbaobao'
b)关键字参数
>>> "{a} love {b}.{c}".format(a="I",b="Love",c="tanbaobao") 'I love Love.tanbaobao'
c)将位置、关键字参数综合使用(位置参数一定要在关键字参数之前)
>>> "{0} love {b}.{c}".format("I",b="Love",c="tanbaobao") 'I love Love.tanbaobao'
d)格式化符号意义
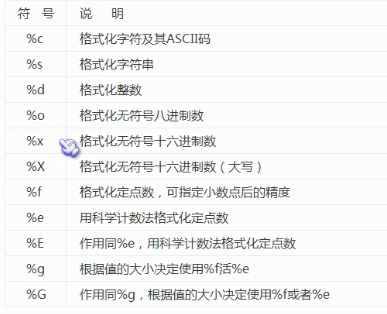
>>> "{{0}}".format("a") '{0}' >>> "{{0}}".format("不打印") '{0}' # .1f保留1位小数,f表示四舍五入 >>> '{0:.1f}{1}'.format(22.222,'GB') '22.2GB' >>> '{0:.1f}{1}'.format(22.252,'GB') '22.3GB'
实例
# 格式化字符 >>> '%c' %97 'a' >>> '%c %c %c' %(97,98,99) 'a b c' # 格式化字符串 >>> '%s' % 'i love tanbaobao' 'i love tanbaobao' # 格式化整数 >>> '%d + %d = %d' % (4,5,4+5) '4 + 5 = 9'
e)格式化操作辅助命令
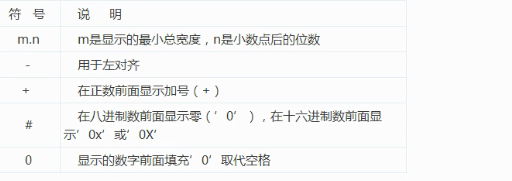
# m总长度,n保留多少位 >>> '%5.1f' % 22.222 ' 22.2' >>> '%.2e' % 22.222 '2.22e+01' >>> '%10d' % 5 ' 5' # 左边对齐 >>> '%-10d' % 5 '5 ' >>> '%+10d' % 5 # 右边对齐 ' +5' >>> '%+10d' % +5 ' +5' >>> '%+10d' % -5 ' -5'
f)字符串转义字符
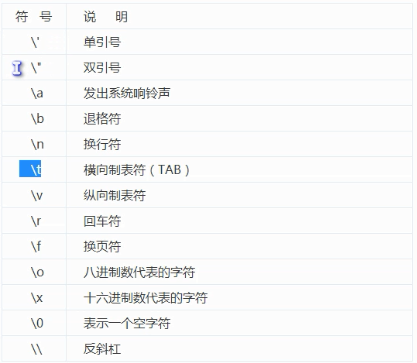
List(列表) 是 Python 中使用最频繁的数据类型。列表可以完成大多数集合类的数据结构实现。它支持字符,数字,字符串甚至可以包含列表(即嵌套)。
列表用 [ ] 标识,是 python 最通用的复合数据类型。列表中值的切割也可以用到变量 [头下标:尾下标] ,就可以截取相应的列表,从左到右索引默认 0 开始,从右到左索引默认 -1 开始,下标可以为空表示取到头或尾。
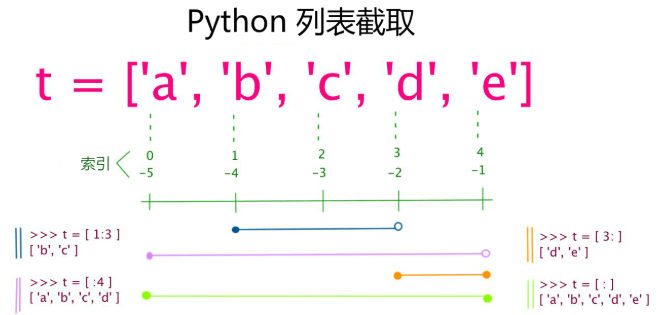
加号 + 是列表连接运算符,星号 * 是重复操作。和字符串的类似。
实例1
[root@tanbaobao myPy]# vi demo03.py #!/usr/bin/python3.8 # -*- conding:UTF-8 -*- list = ['Hello',20,155.50,'thy',100.5] addlist = ['123','thy'] print(list) print(list[0]) print(list[1:3]) print(list[2:]) # 输出第三个及后面所有 print(list[:-2]) # 从左边开始打印,不包括结尾索引-2(也就是到结尾-2索引截止) print(list[-2:]) # 从右边开始打印,包括开始索引-2 print(addlist * 2) # 输出addlist两次 print(list + addlist) # 打印组合列表 [root@tanbaobao myPy]# python3.8 demo03.py ['Hello', 20, 155.5, 'thy', 100.5] Hello [20, 155.5] [155.5, 'thy', 100.5] ['Hello', 20, 155.5] ['thy', 100.5] ['123', 'thy', '123', 'thy'] ['Hello', 20, 155.5, 'thy', 100.5, '123', 'thy']
实例2
>>> member = ['thy','谭宝宝',3.1415926,[1,3,5]] >>> member ['thy', '谭宝宝', 3.1415926, [1, 3, 5]] >>> member.append('zs') >>> member ['thy', '谭宝宝', 3.1415926, [1, 3, 5], 'zs'] >>> len(member) 5
向列表添加元素:append(),extend(),insert()
a)append():一次只能添加一个元素,添加一个以上的元素会报错

b)extend():一个列表来扩展一个列表。需要注意格式要用[]列表的标识符括起来


c)insert():在指定位置插入元素,索引从0开始

从列表中获取元素单个():通过索引值来获取对应的元素,列表索引值都是从0开始
实例3
# 一个简单的数据交换 >>> member ['thy', '谭酱', '谭宝宝', 3.1415926, [1, 3, 5], 'zs', 'xw', 'zl'] >>> member[0] 'thy' >>> member[1] '谭酱' >>> temp = member[0] >>> member[0] = member[1] >>> member ['谭酱', '谭酱', '谭宝宝', 3.1415926, [1, 3, 5], 'zs', 'xw', 'zl'] >>> member[1] = temp >>> member ['谭酱', 'thy', '谭宝宝', 3.1415926, [1, 3, 5], 'zs', 'xw', 'zl']

从列表删除元素:remove(),del(),pop():
a)remove():前提是知道要移除的元素在列表中有存在:
>>> member ['谭酱', 'thy', '谭宝宝', 3.1415926, [1, 3, 5], 'zs', 'xw', 'zl'] >>> member.remove(3.1415926) >>> member ['谭酱', 'thy', '谭宝宝', [1, 3, 5], 'zs', 'xw', 'zl'] # 如果不存在,会报错 >>> member.remove(2.1415926) Traceback (most recent call last): File "<pyshell#21>", line 1, in <module> member.remove(2.1415926) ValueError: list.remove(x): x not in list
b)del()语句:del不是方法,是一个语句:
# del后面直接跟member对象,会直接将member列表才能够内存中删除 >>> member ['谭酱', 'thy', '谭宝宝', [1, 3, 5], 'zs', 'xw', 'zl'] >>> del member[3] >>> member ['谭酱', 'thy', '谭宝宝', 'zs', 'xw', 'zl']
c)pop():从列表中取出元素并返回给你,默认从最后一个元素删除,如果要指定删除元素,在pop()中指定参数索引
# 默认从元素最后一个删除,每次只删除一个元素 >>> member ['谭酱', 'thy', '谭宝宝', 'zs', 'xw', 'zl'] >>> member.pop() 'zl' >>> member ['谭酱', 'thy', '谭宝宝', 'zs', 'xw'] # 赋值删除 >>> name = member.pop() >>> name 'xw' # 指定索引删除 >>> member.pop(1) 'thy' >>> member ['谭酱', '谭宝宝', 'zs']
列表切片(分片slice):可以一次获取多个元素
# member[0:2]左边数包括,右边的数不包括在内 >>> member ['谭酱', '谭宝宝', 'zs', 'thy'] >>> member[0:2] ['谭酱', '谭宝宝'] # 获取索引3签名的所有数 >>> member[:3] ['谭酱', '谭宝宝', 'zs'] # 获取索引1后面的所有数 >>> member[1:] ['谭宝宝', 'zs', 'thy'] # 相当于拷贝列表 >>> member[:] ['谭酱', '谭宝宝', 'zs', 'thy'] 或 >>> member2 = member[:] >>> member2 ['谭酱', '谭宝宝', 'zs', 'thy']
列表操作符:列表尽量不使用+号添加元素,最好使用extend()方法来添加
# 单个元素比较 >>> a = [123] >>> b = [234] >>> a > b False # 多个元素比较(只要第一个元素比另一个列表的第一个元素大,就不会再比较后面的元素) >>> list = [123,456] >>> list2 = [234,123] >>> list > list2 False # 用and进行比较,在上面的基础,添加list3 >>> list3 = [123,456] >>> (list < list2) and (list == list3) True # 拼接字符 +。类似列表的extend()扩展列表方法。 # +号两边的类型必须一致 >>> list4 = list + list2 >>> list4 [123, 456, 234, 123] # *号 >>> list3 * 3 [123, 456, 123, 456, 123, 456] >>> list3 *= 5 >>> list3 [123, 456, 123, 456, 123, 456, 123, 456, 123, 456] # in包含和not in不包含 >>> 123 in list3 True >>> 241 in list3 False >>> 241 not in list3 True # 只能判断列表中的元素,如果要判断列表中列表的元素还需要进行其他操作指定列表的索引 >>> list5 = [123,['谭宝宝','谭酱'],456] >>> '谭酱' in list5 False >>> '谭酱' in list5[1] True # 对于列表中列表的值的访问,相当于二元数组的操作 >>> list5[1][1] '谭酱'
列表的内置函数:

>>> list3 [123, 456, 123, 456, 123, 456, 123, 456, 123, 456] # 查看列表中元素出现的次数 >>> list3.count(123) 5 # 查看指定元素在指定索引内出现的位置,其中第二个参数表示开始索引,第三个参数表示结束索引 >>> list3.index(123) 0 >>> list3.index(123,3,7) 4 # 逆序输出reverse >>> list3.reverse(); >>> list3 [456, 123, 456, 123, 456, 123, 456, 123, 456, 123] # 排序sort(从小到大),使用sort从小到大之后可以使用reverse从大到小排序哈 >>> list6 = [1,3,5,1,2,3,6,8,2] >>> list6.sort() >>> list6 [1, 1, 2, 2, 3, 3, 5, 6, 8] # sort带参数sort(reverse=True),从大到小,默认是False,从小到大 >>> list6.sort(reverse=True) >>> list6 [8, 6, 5, 3, 3, 2, 2, 1, 1] >>> list6.sort(reverse=False) >>> list6 [1, 1, 2, 2, 3, 3, 5, 6, 8] # 另外如果将list6赋值给list7,然后将list6进行排序,会改变两个列表的顺序,如果加上切片方式进行拷贝,则不会修改两个列表的值,只会修改指定排序的列表值 # 即使用=号只是多添加一个标签,使用切片进行的拷贝,会开辟一个内存 >>> list6 [1, 1, 2, 2, 3, 3, 5, 6, 8] >>> list7 = list6 >>> list7 [1, 1, 2, 2, 3, 3, 5, 6, 8] >>> list8 = list6[:] >>> list8 [1, 1, 2, 2, 3, 3, 5, 6, 8] >>> list6.sort(reverse=True) >>> list6 [8, 6, 5, 3, 3, 2, 2, 1, 1] >>> list7 [8, 6, 5, 3, 3, 2, 2, 1, 1] >>> list8 [1, 1, 2, 2, 3, 3, 5, 6, 8]

实例
>>> a = list() >>> a [] # 将字符串转换为列表 >>> b = 'i love tanbaobao' >>> b = list(b) >>> b ['i', ' ', 'l', 'o', 'v', 'e', ' ', 't', 'a', 'n', 'b', 'a', 'o', 'b', 'a', 'o'] # 将元组转换为列表 >>> c = (1,22,33,11,56) >>> c = list(c) >>> c [1, 22, 33, 11, 56]
# 返回长度 >>> len(b) 16 >>> b ['i', ' ', 'l', 'o', 'v', 'e', ' ', 't', 'a', 'n', 'b', 'a', 'o', 'b', 'a', 'o'] >>> max(b) 'v' # 返回最大值(数据类型需要一致) >>> max(c) 56 # 返回序列或参数集合中的最小值(数据类型需要一致) >>> min(c) 1
# sum(iterable[,start=0]):返回序列iterable和可选参数start总和。也需要同类型
>>> tuple2 = (3.2,3.1,3.4
>>> dum(tuple2)
>>> sum(tuple2)
9.700000000000001



元组是另一个数据类型,类似于 List(列表)。元组用 () 标识。内部元素用逗号隔开。但是元组不能二次赋值,相当于只读列表。列表可以二次赋值。
实例
[root@tanbaobao myPy]# cat demo04.py #!/usr/bin/python3.8 # -*- conding:UTF-8 -*- tuple = ('Hello',20,155.50,'thy',100.5) addtuple = ('123','thy') print(tuple) print(tuple[0]) print(tuple[1:3]) print(tuple[2:]) print(tuple[:-2]) print(tuple[-2:]) print(addtuple * 2) print(tuple + addtuple) [root@tanbaobao myPy]# python3.8 demo04.py ('Hello', 20, 155.5, 'thy', 100.5) Hello (20, 155.5) (155.5, 'thy', 100.5) ('Hello', 20, 155.5) ('thy', 100.5) ('123', 'thy', '123', 'thy') ('Hello', 20, 155.5, 'thy', 100.5, '123', 'thy')
这里讲下元组和列表的不同:

区分元组不能仅仅看()来识别,“,”逗号才是关键,如:
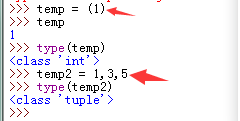
创建空列表,和空元组:
>>> temp = [] >>> type(temp) <class 'list'> >>> temp =() >>> type(temp) <class 'tuple'>
注意*号操作:
>>> 8 * (1) 8 >>> 8 * (1,) (1, 1, 1, 1, 1, 1, 1, 1) # 列表 >>> 8 * [1] [1, 1, 1, 1, 1, 1, 1, 1]
# 可以通过以下这种方法进行添加元素 >>> temp1 = ('谭酱', '谭宝宝', '哔', '周小狮') >>> temp1 = temp1[:2] + ('小林',) + temp1[2:] >>> temp1 ('谭酱', '谭宝宝', '小林', '哔', '周小狮')
不能用del语句来删除元组,机制会在过段时间来清理一些没有被指定的标签。
字典(dictionary)是除列表以外python之中最灵活的内置数据结构类型。列表是有序的对象集合,字典是无序的对象集合。
两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。字典用"{ }"标识。字典由索引(key)和它对应的值value组成。
实例demo05.py
[root@tanbaobao myPy]# vi demo05.py #!/usr/bin/python3.8 # -*- conding:UTF-8 -*- dict = {} dict['one'] = "This is one" dict[2] = "This is two" adddict = {'name':'thy','age':'20','sex':'女'} print(dict['one']) print(dict[2]) print(adddict) print(adddict.keys()) print(adddict.values()) [root@tanbaobao myPy]# python3.8 demo05.py This is one This is two {'name': 'thy', 'age': '20', 'sex': '女'} dict_keys(['name', 'age', 'sex']) dict_values(['thy', '20', '女'])
创建和访问字典:
>>> brand = ['李宁', '耐克', '阿迪达斯', '谭酱'] >>> slogan = ['Impossible is nothing', 'Just do it', 'Let\'s go', 'OK'] >>> slogan ['Impossible is nothing', 'Just do it', "Let's go", 'OK'] >>> print('谭酱:', slogan[brand.index('阿迪达斯')]) 谭酱: Let's go >>> >>> dict = {'李宁':'Impossible is nothing', '耐克':'Just do it', '阿迪达斯':'Let\'s go', '谭酱':'OK'} >>> print('谭酱:', dict['谭酱']) 谭酱: OK >>>

由于之前定义了dict变量,当我后面调用dict函数时回报错误:

解决:将之前定义的dict变量删除:del(dict)

fromkeys()创建新的字典
以序列 seq 中元素做字典的键,value 为字典所有键对应的初始值。
语法
dict.fromkeys(seq[, value])
实例:
>>> dict1 = {} >>> dict1.fromkeys((1,2,3)) {1: None, 2: None, 3: None} >>> dict1.fromkeys((1,2,3),'an') {1: 'an', 2: 'an', 3: 'an'} # 如果是向修改值,可能并不是修改,而是直接赋值了 >>> dict1.fromkeys((1, 3), '数字') {1: '数字', 3: '数字'}
获取字典的键,值,键值对:
# 定义32个字典元素 >>> dict1 = dict1.fromkeys(range(32), '赞') >>> dict1 {0: '赞', 1: '赞', 2: '赞', 3: '赞', 4: '赞', 5: '赞', 6: '赞', 7: '赞', 8: '赞', 9: '赞', 10: '赞', 11: '赞', 12: '赞', 13: '赞', 14: '赞', 15: '赞', 16: '赞', 17: '赞', 18: '赞', 19: '赞', 20: '赞', 21: '赞', 22: '赞', 23: '赞', 24: '赞', 25: '赞', 26: '赞', 27: '赞', 28: '赞', 29: '赞', 30: '赞', 31: '赞'} # for遍历获取键,值,键值对,这里的end=" "是不换行输出,""双引号之间的字符是以什么换行,我这里是以空格 >>> for eachKey in dict1.keys(): print (eachKey, end=" ") 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 >>> for eachValue in dict1.values(): print (eachValue, end=" ") 赞 赞 赞 赞 赞 赞 赞 赞 赞 赞 赞 赞 赞 赞 赞 赞 赞 赞 赞 赞 赞 赞 赞 赞 赞 赞 赞 赞 赞 赞 赞 赞 >>> for eachItem in dict1.items(): print (eachItem, end=" ") (0, '赞') (1, '赞') (2, '赞') (3, '赞') (4, '赞') (5, '赞') (6, '赞') (7, '赞') (8, '赞') (9, '赞') (10, '赞') (11, '赞') (12, '赞') (13, '赞') (14, '赞') (15, '赞') (16, '赞') (17, '赞') (18, '赞') (19, '赞') (20, '赞') (21, '赞') (22, '赞') (23, '赞') (24, '赞') (25, '赞') (26, '赞') (27, '赞') (28, '赞') (29, '赞') (30, '赞') (31, '赞')
PS:使用in可以查询字典中是否包含这个元素(get(索引,设置没有包含或包含的提示信息)也可以)

清空字典使用clear()方法:

拷贝copy()方法:

直接赋值只是添加了一个标签,改变原来的字典内容,c也会跟着改变,但是b的内容不会改变
更新update()方法:
从另一个字典更新当前字典
>>> a {'1': 'one', '小': None} >>> b = {'nihao':'ncsn'} >>> a.update(b) >>> a {'1': 'one', '小': None, 'nihao': 'ncsn'}
补充:集合
以花括号标识但是没有映射关系的是集合。
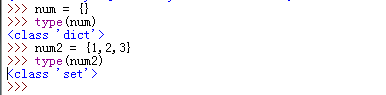
集合中的元素是唯一的,且会自动从小到大排序显示

创建集合的方法有两种:
1)直接把一堆元素使用{}花括号括起来,如上面所示
2)使用set()工厂函数,set()中可以传入字符,元组,列表类型。如下所示:
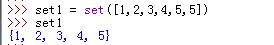
实例:去除列表中重复的元素
# 没有学集合之前,普通方法 >>> num1 = [1,2,3,4,5,5,3,1,0] >>> temp = [] >>> for each in num1: if each not in temp: temp.append(each) >>> temp [1, 2, 3, 4, 5, 0] # 学了集合之后处理的方法 >>> num1 = list(set(num1)) >>> num1 [0, 1, 2, 3, 4, 5]
访问集合中的值:
1)使用for把集合中的元素一个一个读取出来
2)使用in和not in判断一个元素是否在集合中已经存在

不可变集合:
>>> num3 = frozenset([1,2,3,4,5]) >>> num3 frozenset({1, 2, 3, 4, 5})

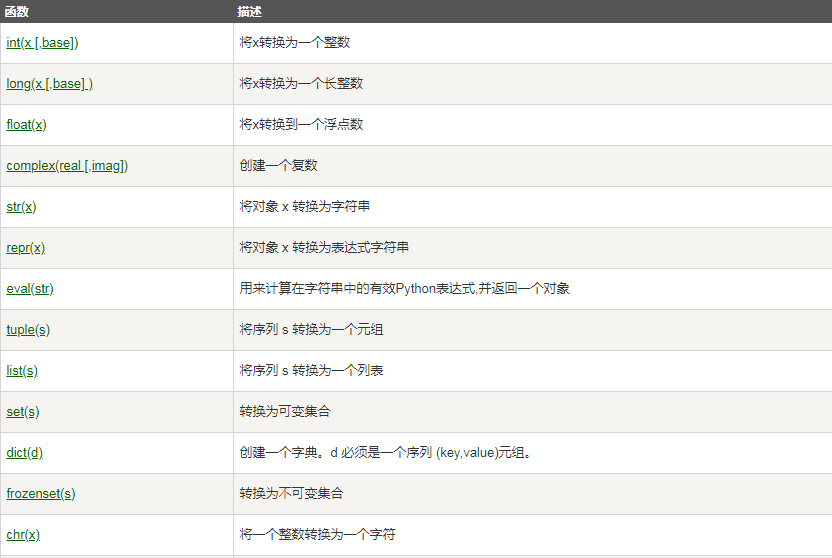
Python数据类型转换
有时候,我们需要对数据内置的类型进行转换,数据类型的转换,你只需要将数据类型作为函数名即可。以下几个内置的函数可以执行数据类型之间的转换。这些函数返回一个新的对象,表示转换的值。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号