
OO第一单元总结
一、 基于度量对程序结构的分析
- 参考度量介绍
(1)Complexity Metrics(复杂度分析)
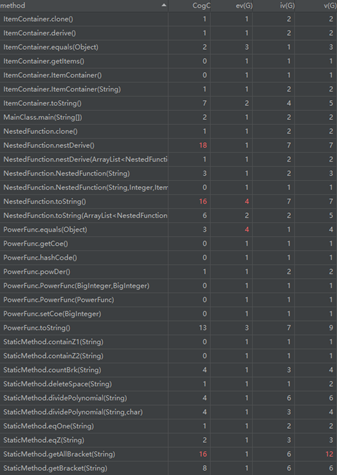
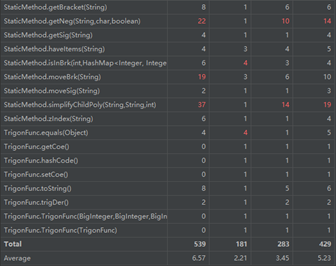
这部分我们需要使用的主要是方法和类的复杂度分析。方法的复杂度分析主要基于循环复杂度的计算。循环复杂度是一种表示程序复杂度的软件度量,由程序流程图中的“基础路径”数量得来。
(a) ev(G):即Essentail Complexity,用来表示一个方法的结构化程度,范围在[1,v(G)]之间,值越大则程序的结构越“病态”,其计算过程和图的“缩点”有关。
(b) iv(G):即Design Complexity,用来表示一个方法和他所调用的其他方法的紧密程度,范围也在[1,v(G)]之间,值越大联系越紧密。
(c) v(G):即循环复杂度,可以理解为穷尽程序流程每一条路径所需要的试验次数。
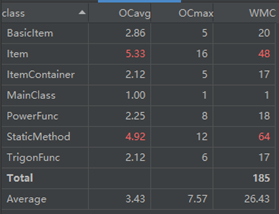
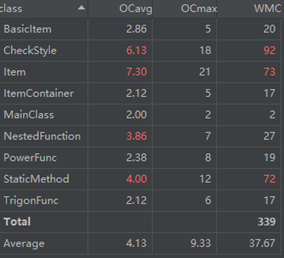
对于类,有OCavg和WMC两个项目。
(a) OCavg:类的方法的平均循环复杂度。
(b) WNC:类的方法的总循环复杂度。
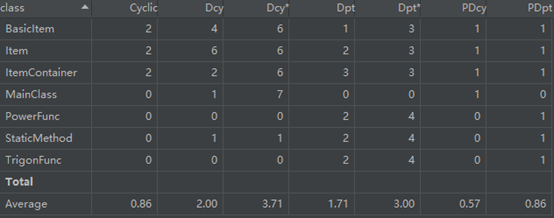
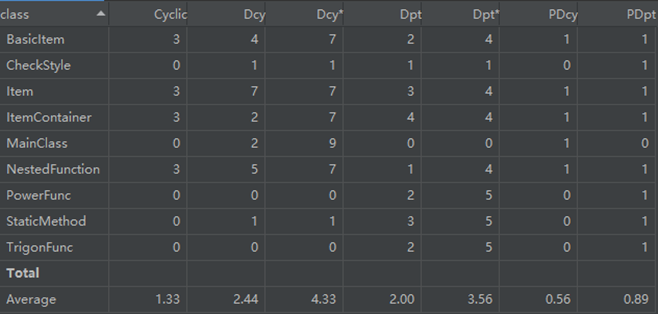
(2)Dependency Metrics(依赖度分析)
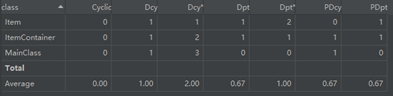
(a) Cyclic:指和类直接或间接相互依赖的类的数量。这样的相互依赖可能导致代码难以理解和测试。
(b) Dcy:计算了该类直接依赖的类的数量,带表示包括了间接依赖的类。
(c) Dpt:计算了直接依赖该类的类的数量,带表示包括了间接依赖的类。
2.作业分析
(1)第一次作业
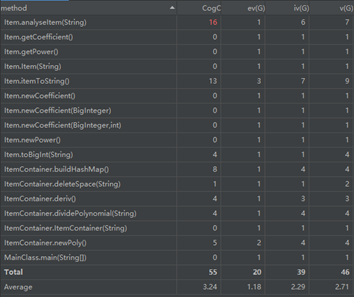
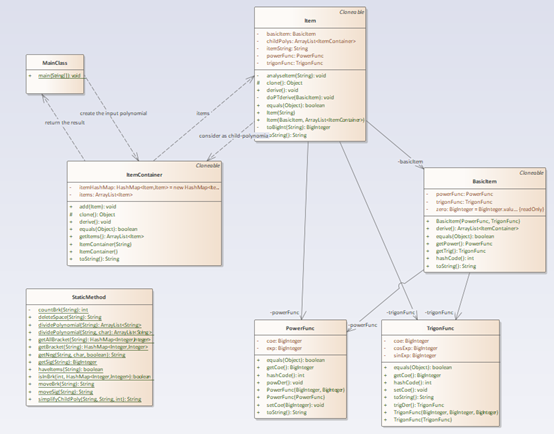
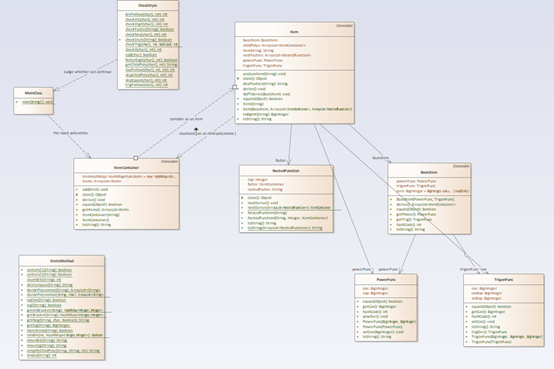
第一次作业只考虑了简单的幂函数,故只设计了三个类,ItemContainer储存多项式,Item储存单一项。
但在ItemContainer中保留了过多的方法,将拆分多项式、去除空格都留在了这个类中,功能冗余。
在Item这个类中,对系数进行了较多的操作,影响较大,似乎失去了private的独立性。
不过好处在于我第一次作业就没有用大正则,是按加减拆分,将项变成实例存储,求导和转换字符串输出都是对项的实例进行操作。

(2)第二次作业
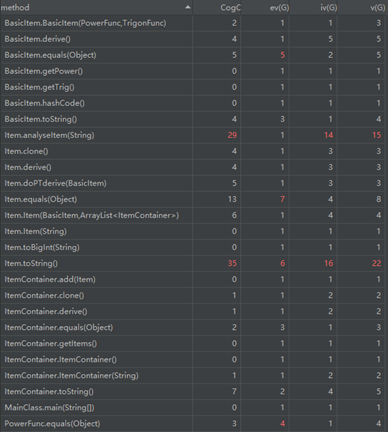
这次作业加入三角函数和支持括号嵌套的因子后我的设计就有一点乱了。我新加入了PowerFunc,TrigonFunc,BasicItem,其中BasicItem聚合了前两者,算是没有括号嵌套的基本内容,但在后面的程序中我还是在对PowerFunc和TrigonFunc直接进行操作,BasicItem只是单纯的在反复复制传递,造成了代码性能的下降。等我意识到这个问题的时候,对BasicItem的操作已经和对另外两个类的操作掺杂在一起了,有的方法是BasicItem整合过的,并且不适合归入Item类,单纯查找删除容易产生隐形问题,并且等我意识到的时候已经快截止了,遂没有进行重构。
在这次作业中,括号内的表达式被我当做新的多项式传给了ItemContainer,实例了新的对象,所以ItemContainer现在既是总结点又是分支结点,数据在Item和ItemContainer之间反复传递,耦合严重。
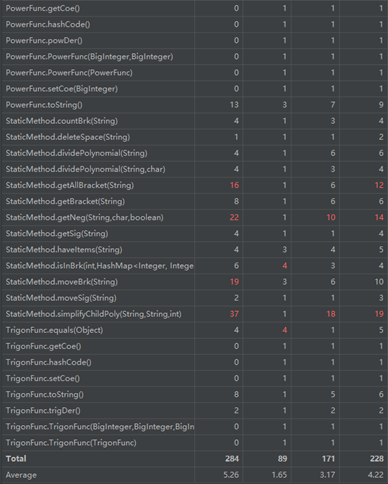
这次我整合出了StaticMethod类管理所有用到的比较有共性的方法,不过学习完工程化方法,这里应该建立接口和父类,让幂函数、三角函数、子多项式都继承加实现,这样就不用判断到底是哪个函数,直接链表遍历求导、转字符串就行。
(3)第三次作业
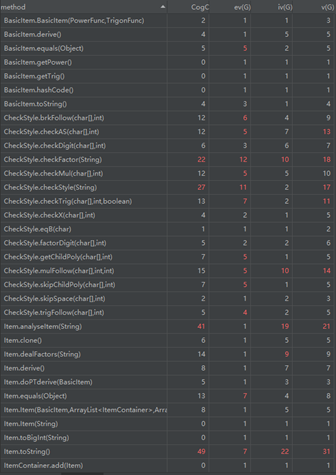
第三次加入支持嵌套因子的三角函数和格式判断,所以我加入了NestedFunc和CheckStyle类(越来越乱了)……if-else分支爆炸,除了第二次作业的情况还要判断这个项里有没有嵌套因子的三角函数,虽然这些类内聚效果都还不错,对象拿来可以直接用而不用考虑其中内容,但耦合越来越强,一个类内的方法间格外需要调用StaticMethod的方法,且对NestedFunc求导一定会连TrigonFunc和ItemContainer。
不得不提的是因为递归,所以求导还行,字符串输出的时候会因为层数过多,反复判断导致TLE,目前还没想到要怎么解决,之后大概只能慢慢想解决方法了。
关于格式判断,听说有的人是在后续处理字符串的时候抛出异常并直接退出,但我的程序因为Item和ItemContainer耦合严重,非常容易因为疏忽导致程序卡死,所以只能单独判断,用了很复杂的switch(+-、*、 、x、sin、cos、‘(’)。
二、 Bug分析
- 第一次作业
x**100000000000000000000000000000000输出了0……明明记得用了BigInteger应对指数超出int范围,结果Item.toString输出的时候直接BigInteger.valueofInt(),白搭。
2.第二次作业
这次作业的问题主要在于字符串输出和输出格式问题。
Item.toString的时候我是判断这个Item中的childPoly(即ItemContainer的实例)转化为字符串后的情况决定要怎么处理,但在每个条件判断中都写的是childPoly.toString,一层会向下递归3到5次,导致时间复杂度直线上升,极易TLE,但在方法一开始就得到一次字符串,这个问题就解决了。
输出的时候我的设计已经不支持合并优化了,所以只能在转换字符串的时候简单去掉乘0的项和乘±1的1,但忘记了乘的“-1”如果是在中间不能省略,所以导致了格式错误。
3.第三次作业
在自己debug的时候遇见了输入“+”没有输出格式错误,反而直接因为越界退出,看完代码发现我逐字符扫描的时候直接判断了下一个字符是什么,默认了“+”不可能是最后一个,所以感觉判断小于数组长度和取下一个元素必须锁死。
然后在提交的版本中,0*cos((x**1234567890))应该报错,但由于设计缺陷,先用0*判断了一次才求导(功能杂乱),整个数据被舍掉了,没有进入指数判断,就漏掉了它。
还有就是这次也有一个比较离谱的TLE,但目前还没找到原因,后续会再试试。
三、 Hack策略
由于我不会写自动测评机,自动生成的数据多且杂,所以我是根据题目中的表达式要求自己构造数据的,但就目前来看自己构造的数据强度不太够。
以第三次作业为例,为了测试到每种情况,我尝试了只有嵌套因子的三角函数,给它加上幂,结合一至多个带括号的表达式因子,括号嵌套,数据逐渐复杂。测试正确性的时候就随机输入,看程序输出。但有些情况,比如说我判断这个项的字符串如果含“0*”、“*0”就整体不输出,所以5*x**12会变成0,这个是在别人Hack我的过程中发现的。
至于Hack别人,我是大致通读代码,特别是观察条件判断,分析有无状况的遗漏,针对这种遗漏设计测试用例;如果没有分析到遗漏,就用和我自测一样的方式逐渐加强数据进行测试。
四、 心得总结
- 该重构就要重构!!!虽然不重构也不是写不下去,但幸亏只是三次迭代,如果有第四次肯定要推翻再来。事实上第三次写的已经挺费劲的了,因为第二次作业新增的类间的关系没有分清,在A加一条可能需要B、C配合十几条,几乎不独立。如果第二次没写完的时候就重构第三次肯定会轻松很多。
- 下次一定要工程化思想,多继承等,不要再疯狂if-else的判断了。
- 如果有时间还是要学一下怎么搭自动测评机,手测的强度逐渐不足以支撑代码要求了。
- 把需要计算的东西早点变成局部变量可以减轻递归压力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号