LeetCode刷题笔记
LeetCode刷题笔记
记录一下自己在刷LEETCODE时踩过的一些坑和刷题心得,督促自己更好的学习,不定期更新
动态规划
152.乘积最大数组(2020.5.18)
public int maxProduct(int[] nums) {
int min_n=nums[0],max_n=nums[0],ans = nums[0];
for(int i=1;i<nums.length;i++){
int min = min_n,max = max_n;//保证两次计算时使用的是上次的的数据而不是更新后的数据
max_n=Math.max(Math.max(nums[i],nums[i]max),nums[i]min);
min_n=Math.min(Math.min(nums[i],nums[i]max),nums[i]min);
ans = Math.max(max_n,ans);
}
return ans;
}
一开始自己考虑的是动态规划,可感觉和最大子串和不太一样,采用了暴力的方法,时间复杂度O(n^2),这里的动态规划采取了分类的方法,记录前n-1项的最大和最小,如果是负的和最小×得到最大值,正数和最大的×得到最大值最大最小值要另外声明在循环中,如果直接用会导致第二个参数更新使用的是上一个更新过的值,造成结果不对
最初状态转移方程: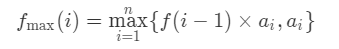
分类后的状态转移方程: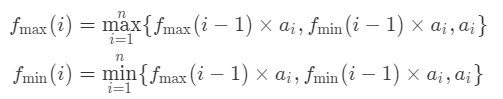
5.最长回文子串
给定一个字符串 s,找到 s 中最长的回文子串。你可以假设 s 的最大长度为 1000

Ⅰ.动态规划
public String longestPalindrome(String s) {
int length = s.length();
boolean[][] P = new boolean[length][length];
int maxLen = 0;
String maxPal = "";
for (int len = 1; len <= length; len++) //遍历所有的长度
for (int start = 0; start < length; start++) {
int end = start + len - 1;
if (end >= length) //下标已经越界,结束本次循环
break;
P[start][end] = (len == 1 || len == 2 || P[start + 1][end - 1]) && s.charAt(start) == s.charAt(end); //长度为 1 和 2 的单独判断下
if (P[start][end] && len > maxLen) {
maxPal = s.substring(start, end + 1);
}
}
return maxPal;
状态转移方程: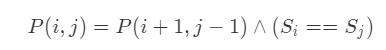
对于字符串长度为1和2时单独进行讨论:
从长度较小的字符串开始遍历,时间复杂度为O(n^2) 空间复杂度为O(n^2)
Ⅱ.中心扩展算法
考虑上面的状态转移方程,可以看到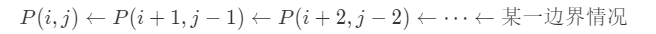
即所有的状态都可以由边界状态唯一得到,所以我们并不妨循环回文中心,再逐次向两边扩展,如果不相等则说明此回文中心已经达到最大
public String longestPalindrome(String s) {
if (s == null || s.length() < 1) return "";
int start = 0, end = 0;
for (int i = 0; i < s.length(); i++) {
int len1 = expandAroundCenter(s, i, i);
int len2 = expandAroundCenter(s, i, i + 1);
int len = Math.max(len1, len2);
if (len > end - start) {
start = i - (len - 1) / 2;
end = i + len / 2;
}
}
return s.substring(start, end + 1);
}
private int expandAroundCenter(String s, int left, int right) {
int L = left, R = right;
while (L >= 0 && R < s.length() && s.charAt(L) == s.charAt(R)) {
L--;
R++;
}
return R - L - 1;
}
和被K整除的子数组

考虑到时间复杂度与数据输入不能采用暴力贪心求解
因为是子数组问题,所以考虑采用哈希表(HashMap)+前缀和解决问题,考虑到整除考虑余数定理,所以维护dq[]保存前n项的余数和
注意:对于负数的项目将取余数之后变为正值再进行计算
状态转移方程:dq[i] = dq[i-1]+abs(num[i]%K)
核心代码same = record.getOrDefault(modulus, 0); ans+=same;
ORans += entry.getValue() * (entry.getValue() - 1) / 2;
public int subarraysDivByK(int[] A, int K) {
Map<Integer, Integer> record = new HashMap<>();
record.put(0, 1);
int sum = 0;
for (int elem: A) {
sum += elem;
// 注意 Java 取模的特殊性,当被除数为负数时取模结果为负数,需要纠正
int modulus = (sum % K + K) % K;
record.put(modulus, record.getOrDefault(modulus, 0) + 1);
}
int ans = 0;
for (Map.Entry<Integer, Integer> entry: record.entrySet()) {
ans += entry.getValue() * (entry.getValue() - 1) / 2;
}
return ans;
}
198.打家劫舍
动态转移方程:dq[i]=MAX(dq[i-2]+num[i],dq[i-1]);
public int rob(int[] nums) {
if (nums == null || nums.length == 0) {
return 0;
}
int length = nums.length;
if (length == 1) {
return nums[0];
}
int[] dp = new int[length];
dp[0] = nums[0];
dp[1] = Math.max(nums[0], nums[1]);
for (int i = 2; i < length; i++) {
dp[i] = Math.max(dp[i - 2] + nums[i], dp[i - 1]);
}
return dp[length - 1];
}
字符串
14. 最长公共前缀

//方法一,考虑将最初的字符串作为初始化的前缀,然后定义一个i循环遍历strs中的
//各个字符串的位于j的元素是否相同,如果相同就继续遍历,知道找出最长的公共子串
//java
public String longestCommonPrefix(String[] strs) {
if(strs.length == 0)
return "";
String ans = strs[0];
for(int i =1;i<strs.length;i++) {
int j=0;
for(;j<ans.length() && j < strs[i].length();j++) {
if(ans.charAt(j) != strs[i].charAt(j))
break;
}
ans = ans.substring(0, j);
if(ans.equals(""))
return ans;
}
return ans;
}
//c++
/*
public:
string longestCommonPrefix(vector<string>& strs) {
if(strs.size()==0) return "";
string ans=strs[0];
for(int i = 0;i<strs.size();i++){
int j=0;
for(;j<ans.length()&&j<strs[i].length();j++){
if(ans[j]!=strs[i][j]) break;
if(ans == "") return ans;
}
ans = ans.substr(0,j);
if(ans == "") return ans;
}
return ans;
}
*/
680.回文字符串
给定一个非空字符串 s,最多删除一个字符。判断是否能成为回文字符串。

int del = 0; //记录删除的字符次数
public boolean validPalindrome(String s) {
int i = 0,j = s.length()-1;
while(i < j){
if(s.charAt(i) == s.charAt(j)){
i++;
j--;
}else{
//不相等的话,若没有删除字符,则删除左边或右边的字符再判断;若删除过一次,则不是回文串
if(del == 0){
del++;
return validPalindrome(s.substring(i,j)) || validPalindrome(s.substring(i+1,j+1));
}
return false;
}
}
return true;
}
本题是一道简单题,记录的原因是我自己一开始写的比较麻烦,把所有的判断写在一起,比较复杂,如果采用递归的思想,代码会比较简介(substring(i,j)截取从i到j-1的字符串,即去掉左端字符后判断剩下的字符串是否为回文串)同时类似的还有下面这道题,练习的是双指针和各类字符串函数
125.回文字符串
给定一个字符串,验证它是否是回文串,只考虑字母和数字字符,可以忽略字母的大小写。

public boolean isPalindrome(String s) {
if (s.length() == 0)
return true;
String low = s.toLowerCase();
int i = 0;
int j = low.length() - 1;
while (i < j){
if (!Character.isLetterOrDigit(low.charAt(i))){
i++;
continue;
}
if (!Character.isLetterOrDigit(low.charAt(j))){
j--;
continue;
}
if (low.charAt(i) != low.charAt(j))
return false;
else{
i++;
j--;
}
}
return true;
}
常用的字符串内容判断函数有
.isDigit() //判断是否是数字
.isUpperCase(); .isLowerCase(); .toUpperCase(); .toLowerCase() //对字母及其大小写的判断转化
.isLetterOrDigit() //判断是否是字母或数字
1371.每个元音包含偶数次的字符串长度(前缀和+状态压缩)
给你一个字符串 s ,请你返回满足以下条件的最长子字符串的长度:每个元音字母,即 'a','e','i','o','u' ,在子字符串中都恰好出现了偶数次。

1.暴力解法
遍历枚举所有子串并统计其中各字符出现的次数,更新最大长度,时间复杂度过高,故不予考虑
2.前缀和+状态压缩+hashMap
①通过前缀和避免对于子串的重复遍历,对于某个区间的子串采用前缀和的差值对其进行计算
考虑设计一个数组p[i][k]记录前i项子串中原因k出现的次数,然后采用一个for(int i,j)的时间复杂度为O(n^2)的嵌套循环完成对于各个元音都为偶数最大值的更新
②我们考虑枚举字符串的每个位置i ,计算以它结尾的满足条件的最长字符串长度。其实我们要做的就是快速找到最小的j∈(0,i),使得p[i][]-p[j][]的各项均为偶数,这里可以考虑使用hashMap进行优化,使用hashmap对我们需要查找的状态进行保存,五位符号的奇偶性共有2^5=32种状态,使用hashmap<各个元音字符的状态,最早出现位置>记录每种状态出现的最早位置即可,当p[i][k]与p[j][k]的奇偶性都相等的话就更新最大值
③对于各个元音的奇偶性,采用一个statue记录,如对于aiu,a:1 e:0 i:1 o:0 u:1 则status的编码为10101B,即21D
public int findTheLongestSubstring(String s) {
int n = s.length();
Map<Integer,Interger> pos=new HashMap<>() ;
int ans = 0,statue=0;
pos[0] = 0;
for (int i = 0; i < n; i++) {
char ch = s.charAt(i);
if (ch == 'a') {
status ^= (1 << 0);
} else if (ch == 'e') {
status ^= (1 << 1);
} else if (ch == 'i') {
status ^= (1 << 2);
} else if (ch == 'o') {
status ^= (1 << 3);
} else if (ch == 'u') {
status ^= (1 << 4);
}
if (pos.isContains(status)) {
ans = Math.max(ans, i + 1 - pos.get(status));
} else {
pos.put(status,i+1);
}
}
return ans;
}
数组
4.寻找有序数组的中位数(二分查找)
public double findMedianSortedArrays(int[] nums1, int[] nums2) {
if (nums1.length > nums2.length) {
int[] temp = nums1;
nums1 = nums2;
nums2 = temp;
}
int m = nums1.length;
int n = nums2.length;
// 分割线左边的所有元素需要满足的个数 m + (n - m + 1) / 2;
int totalLeft = (m + n + 1) / 2;
// 在 nums1 的区间 [0, m] 里查找恰当的分割线,
// 使得 nums1[i - 1] <= nums2[j] && nums2[j - 1] <= nums1[i]
int left = 0;
int right = m;
while (left < right) {
int i = left + (right - left + 1) / 2;
int j = totalLeft - i;
if (nums1[i - 1] > nums2[j]) {
// 下一轮搜索的区间 [left, i - 1]
right = i - 1;
} else {
// 下一轮搜索的区间 [i, right]
left = i;
}
}
int i = left;
int j = totalLeft - i;
int nums1LeftMax = i == 0 ? Integer.MIN_VALUE : nums1[i - 1];
int nums1RightMin = i == m ? Integer.MAX_VALUE : nums1[i];
int nums2LeftMax = j == 0 ? Integer.MIN_VALUE : nums2[j - 1];
int nums2RightMin = j == n ? Integer.MAX_VALUE : nums2[j];
if (((m + n) % 2) == 1) {
return Math.max(nums1LeftMax, nums2LeftMax);
} else {
return (double) ((Math.max(nums1LeftMax, nums2LeftMax) + Math.min(nums1RightMin, nums2RightMin))) / 2;
}
}
链表
146.LRU缓存机制

解决思路:构造一个hashMap<KEY,DLinkedNode>保存与方便查找对应得到节点,同时维护一个DLinkedNode维护访问顺序,将已经访问过的节点提到链表头部,当超过容量是将尾部的链表节点从cache中删除
class LRUCache {
class DLinkedNode {
int key;
int value;
DLinkedNode prev;
DLinkedNode next;
public DLinkedNode() {}
public DLinkedNode(int _key, int _value) {key = _key; value = _value;}
}
private Map<Integer, DLinkedNode> cache = new HashMap<Integer, DLinkedNode>();
private int size;
private int capacity;
private DLinkedNode head, tail;
public LRUCache(int capacity) {
this.size = 0;
this.capacity = capacity;
// 使用伪头部和伪尾部节点
head = new DLinkedNode();
tail = new DLinkedNode();
head.next = tail;
tail.prev = head;
}
public int get(int key) {
DLinkedNode node = cache.get(key);
if (node == null) {
return -1;
}
// 如果 key 存在,先通过哈希表定位,再移到头部
moveToHead(node);
return node.value;
}
public void put(int key, int value) {
DLinkedNode node = cache.get(key);
if (node == null) {
// 如果 key 不存在,创建一个新的节点
DLinkedNode newNode = new DLinkedNode(key, value);
// 添加进哈希表
cache.put(key, newNode);
// 添加至双向链表的头部
addToHead(newNode);
++size;
if (size > capacity) {
// 如果超出容量,删除双向链表的尾部节点
DLinkedNode tail = removeTail();
// 删除哈希表中对应的项
cache.remove(tail.key);
--size;
}
}
else {
// 如果 key 存在,先通过哈希表定位,再修改 value,并移到头部
node.value = value;
moveToHead(node);
}
}
private void addToHead(DLinkedNode node) {
node.prev = head;
node.next = head.next;
head.next.prev = node;
head.next = node;
}
private void removeNode(DLinkedNode node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
private void moveToHead(DLinkedNode node) {
removeNode(node);
addToHead(node);
}
private DLinkedNode removeTail() {
DLinkedNode res = tail.prev;
removeNode(res);
return res;
}
}
/**
* Your LRUCache object will be instantiated and called as such:
* LRUCache obj = new LRUCache(capacity);
* int param_1 = obj.get(key);
* obj.put(key,value);
*/
树
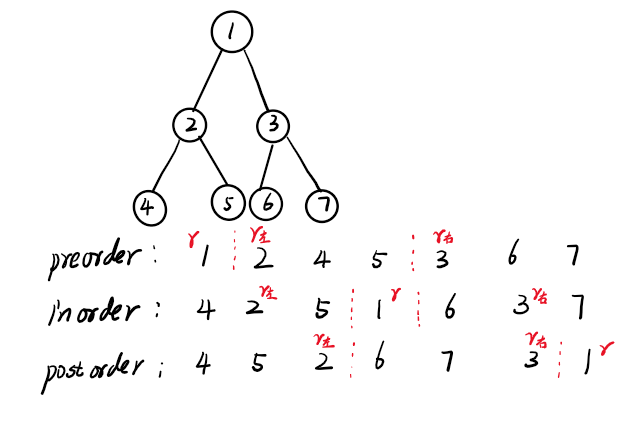
105.先序遍历中序遍历构造树&&106中序遍历后序遍历构造树
//先序中序遍历
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
private Map<Integer,Integer> map;
public TreeNode bulid(int[] pre, int[] in,int pre_l,int pre_r,int in_l,int in_r){
if(pre_l>pre_r) return null;
int pre_root = pre_l;
int in_root = map.get(pre[pre_root]);
int left_size = in_root-in_l;
int right_size = in_r-in_root;
TreeNode root = new TreeNode(pre[pre_root]);
root.left = bulid(pre,in,pre_l+1,pre_l+left_size,in_l,in_l+left_size-1);
root.right = bulid(pre,in,pre_r-right_size+1,pre_r,in_r-right_size+1,in_r);
return root;
}
public TreeNode buildTree(int[] preorder, int[] inorder) {
int len = preorder.length;
map = new HashMap<Integer,Integer>();
for(int i=0;i<len;i++){
map.put(inorder[i],i);
}
return bulid(preorder,inorder,0,len-1,0,len-1);
}
//中序后序遍历
private Map<Integer,Integer> map;
public TreeNode build(int[] in,int[] post,int in_l,int in_r,int post_l,int post_r){
if(post_r < post_l) return null;
int post_root = post_r;
int in_root = map.get(post[post_root]);
int left_size = in_root-in_l;
int right_size = in_r-in_root;
TreeNode root = new TreeNode(in[in_root]);
root.left = build(in,post,in_l,in_root-1,post_l,post_l+left_size-1);
root.right = build(in,post,in_root+1,in_r,post_l+left_size,post_root-1);
return root;
}
public TreeNode buildTree(int[] inorder, int[] postorder) {
int len = inorder.length;
map = new HashMap<Integer,Integer>();
for(int i=0;i<len;i++){
map.put(inorder[i],i);
}
return build(inorder,postorder,0,len-1,0,len-1);
}
总结
101.对称二叉树
核心思想:维护两个指针p,q,check函数()执行两次,迭代为 check(p->left,q->right) check(p->right,q->left)
//递归的方法
public:
bool check(TreeNode *p, TreeNode *q) {
if (!p && !q) return true;
if (!p || !q) return false;
return p->val == q->val && check(p->left, q->right) && check(p->right, q->left);
}
bool isSymmetric(TreeNode* root) {
return check(root, root);
}
};
//迭代的方法
public:
bool check(TreeNode *u, TreeNode *v) {
queue <TreeNode*> q;
q.push(u); q.push(v);
while (!q.empty()) {
u = q.front(); q.pop();
v = q.front(); q.pop();
if (!u && !v) continue;
if ((!u || !v) || (u->val != v->val)) return false;
q.push(u->left);
q.push(v->right);
q.push(u->right);
q.push(v->left);
}
return true;
}
bool isSymmetric(TreeNode* root) {
return check(root, root);
}
图
栈&&堆
字符串解码

考虑存在括号嵌套的问题,采用两个栈堆分别维护数字与字符串,考虑一下情况
1.当c是数字时,将multi*10+(int)c
2.当c是字母时,将其加到暂存的字符串中进行记录
3.当c是'['时,将当前保存的multi与暂存字符串全部压入相应的栈,同时初始化这两个量
4.当c是']'时,将两个栈的内容弹出并进行字符串的拼接
public String decodeString(String s) {
StringBuffer ans=new StringBuffer();
Stack<Integer> multiStack=new Stack<>();
Stack<StringBuffer> ansStack=new Stack<>();
int multi=0;
for(char c:s.toCharArray()){
if(Character.isDigit(c))multi=multi*10+c-'0';
else if(c=='['){
ansStack.add(ans);
multiStack.add(multi);
ans=new StringBuffer();
multi=0;
}else if(Character.isAlphabetic(c)){
ans.append(c);
}else if(c==']'){
StringBuffer ansTmp=ansStack.pop();
int tmp=multiStack.pop();
for(int i=0;i<tmp;i++)ansTmp.append(ans);
ans=ansTmp;
}
}
return ans.toString();
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号