[论文阅读]Dependency-driven Relation Extraction with Attentive Graph Convolutional Networks[ACL2021]
论文地址:https://aclanthology.org/2021.acl-long.344/
代码地址:https://github.com/cuhksz-nlp/RE-AGCN
依赖关系标注工具:https://stanfordnlp.github.io/CoreNLP/
ACE2005处理参考:https://github.com/tticoin/LSTM-ER/tree/master/data/ace2005/split
数据集:ACE2005,SemEval-2010
本篇论文首先从现成的工具箱中获取输入句子的依赖树,然后在依赖树上构建图形,并为任意两个单词之间不同的标记依赖关系分配不同的权重,权重根据连接及其依赖类型计算,最后根据学习到的权值,用A-GCN预测关系。这样一来,A-GCN不仅能够区分重要的上下文信息和依赖树,并相应地利用它们,因此不必依赖剪枝策略,但A-GCN也可以利用以前大多数研究(尤其是同样使用注意机制的研究AGGCN)忽略的依赖类型信息。
论文地址:https://www.aclweb.org/anthology/P19-1024/
代码地址:https://github.com/Cartus/AGGCN
数据集:TACRED,SemEval-2010
另:https://www.cnblogs.com/Harukaze/p/14372953.html
ACL2020:GCN+剪枝论文+反思机制
论文地址:https://aclanthology.org/2020.coling-main.341/
代码地址:空着
数据集:TACRED,SemEval-2010
这是一颗依赖树:
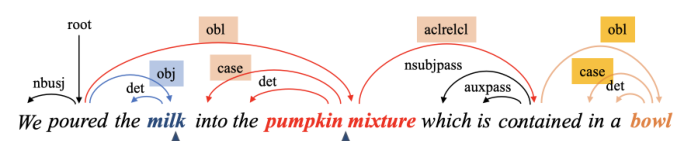
分为两种依赖关系,与主语实体或宾语实体有直接关系的定义为局部依赖;通过SDP最短依赖路径指向主语宾语实体的路径定义为全局依赖:
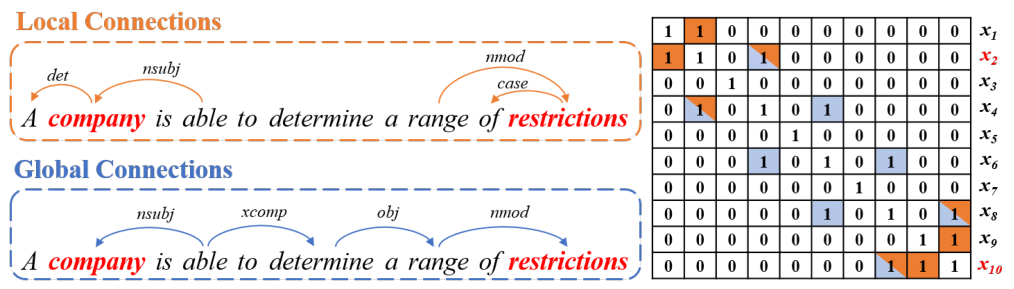
两种依赖共用一个矩阵,不做区分。
模型总览
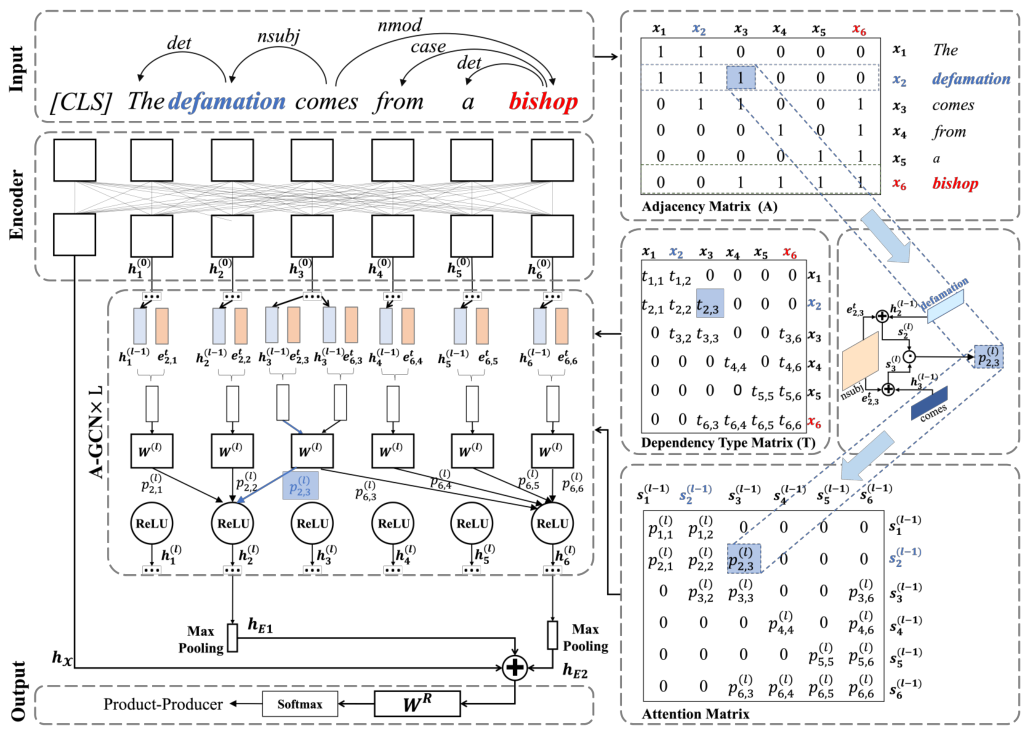
Encoder:
使用BERT将输入Input编码成为\(h_i^{(0)}\)
A-GCN:
通过\(L\)层A-GCN后,\(h_i^{(0)}\)对应于输出向量\(h_i^{(L)}\)
细节如下:
首先,将依赖类型\(t_{i,j}\)映射为向量:\(e^t_{i,j}\)
然后在第\(l\)层计算\(x_i\)和\(x_j\)之间的连接权重:\(p_{i, j}^{(l)}=\frac{a_{i, j} \cdot \exp \left(\mathbf{s}_{i}^{(l)} \cdot \mathbf{s}_{j}^{(l)}\right)}{\sum_{j=1}^{n} a_{i, j} \cdot \exp \left(\mathbf{s}_{i}^{(l)} \cdot \mathbf{s}_{j}^{(l)}\right)}\)
其中\(a_{i,j} \in A\),\(s_i^{(l)}\)与\(s_j^{(l)}\)分别为\(x_i\)与\(x_j\)的中间向量产物:
\(\mathbf{s}_{i}^{(l)}=\mathbf{h}_{i}^{(l-1)} \oplus \mathbf{e}_{i, j}^{t}\)
\(\mathbf{s}_{j}^{(l)}=\mathbf{h}_{j}^{(l-1)} \oplus \mathbf{e}_{i, j}^{t}\)
\(\oplus\)是向量拼接。
GCN更新公式为:\(\mathbf{h}_{i}^{(l)}=\sigma\left(\sum_{j=1}^{n} p_{i, j}^{(l)}\left(\mathbf{W}^{(l)} \cdot \widetilde{\mathbf{h}}_{j}^{(l-1)}+\mathbf{b}^{(l)}\right)\right)\)
\(\mathbf{h}_{j}^{(l-1)}\)为添加了单词\(x_j\)依赖信息的增强表示法:\(\widetilde{\mathbf{h}}_{j}^{(l-1)}=\mathbf{h}_{j}^{(l-1)}+\mathbf{W}_{T}^{(l)} \cdot \mathbf{e}_{i, j}^{t}\)
\(\mathbf{W}_{T}^{(l)}\)将依赖类型的嵌入向量\(\mathbf{e}_{i, j}^{t}\)映射为与\(\mathbf{h}_{j}^{(l-1)}\)相同的维度
最后通过最大池化方法,得到实体表示向量\(\mathbf{h}_{E_{k}}\):\(\mathbf{h}_{E_{k}}=\operatorname{MaxPooling}\left(\left\{\mathbf{h}_{i}^{(L)} \mid x_{i} \in E_{k}\right\}\right)\)
Output:
整个句子表示由BERT中\(CLS\)标签直接得到,未输入至A-GCN,整句向量表示为:\(\mathbf{h}_{\mathcal{X}}\)
然后将\(\mathbf{h}_{\mathcal{X}}\)与两个实体向量拼接起来得到输出向量\(\mathbf{o}\):\(\mathbf{o}=\mathbf{W}_{R} \cdot\left(\mathbf{h}_{\mathcal{X}} \oplus \mathbf{h}_{E_{1}} \oplus \mathbf{h}_{E_{2}}\right)\)
\(\mathbf{W}_{R}\)是一个可训练矩阵,\(\mathbf{o}\)是一个\(R\)维的向量,其每个值都表示关系类型集合\(\mathcal{R}\)中的关系类型。
最后通过softmax函数预测两个实体之间的关系。
\(\widehat{r}=\arg \max \frac{\exp \left(o^{u}\right)}{\sum_{u=1}^{|\mathcal{R}|} \exp \left(o^{u}\right)}\)
其中\(o^u\)表示\(o\)中维度\(u\)的值。
result
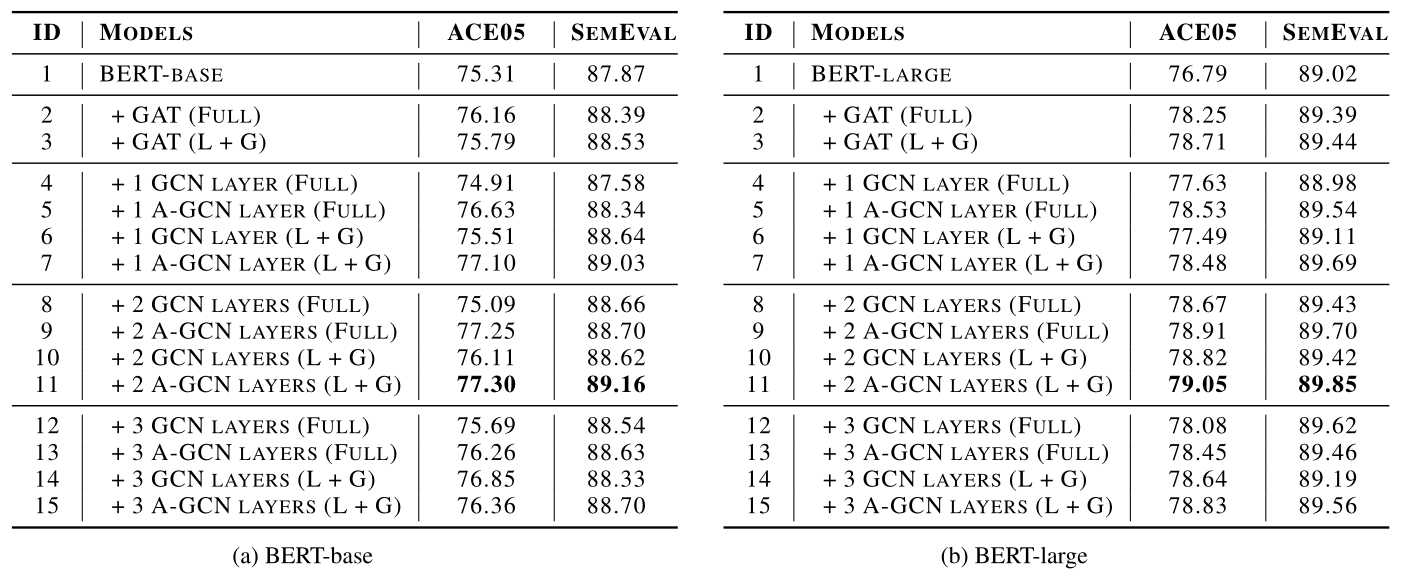
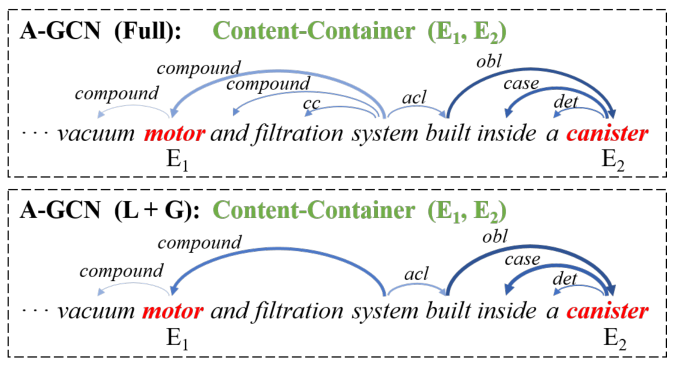
如图所示,作者对比了1,2,3层GCN的情况;每一层采用两种依赖路径链接方式做对比(FULL:全部保留;L+G:局部+全局依赖)
下图中,线越粗颜色越深代表权重更大,可以看到L+G模式权重分布更集中:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号