【论文阅读】ALBERT: A Lite BERT for Self-supervised Learning of Language Representations[arXiv2019]
论文地址:https://arxiv.org/abs/1909.11942v1
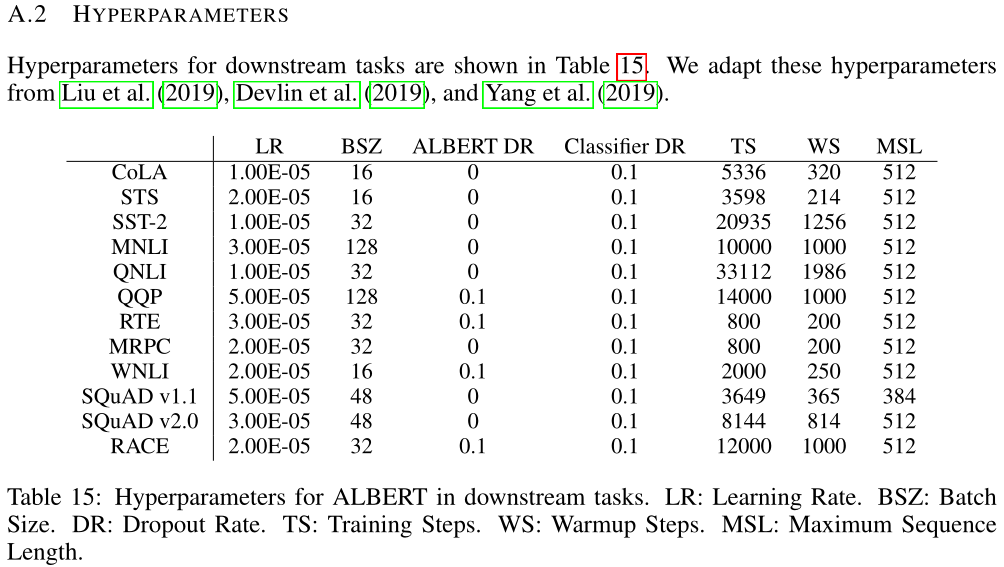
代码地址:
ABSTRACT
提出减少BERT参数的方法,我们还使用了一个自我监督 loss,专注于建模句间连贯focuses on modeling inter-sentence coherence,并表明它始终有助于多句输入的下游任务。因此,我们的最佳模型在GLUE、RACE和SQuAD基准上建立了新的最先进的结果,而与$BERT_{LARGE}$相比,参数更少。
1 INTRODUCTION
虑到模型大小的重要性,我们要问:拥有更好的NLP模型是否与拥有更大的模型一样容易?
Is having better NLP models as easy as having larger models?
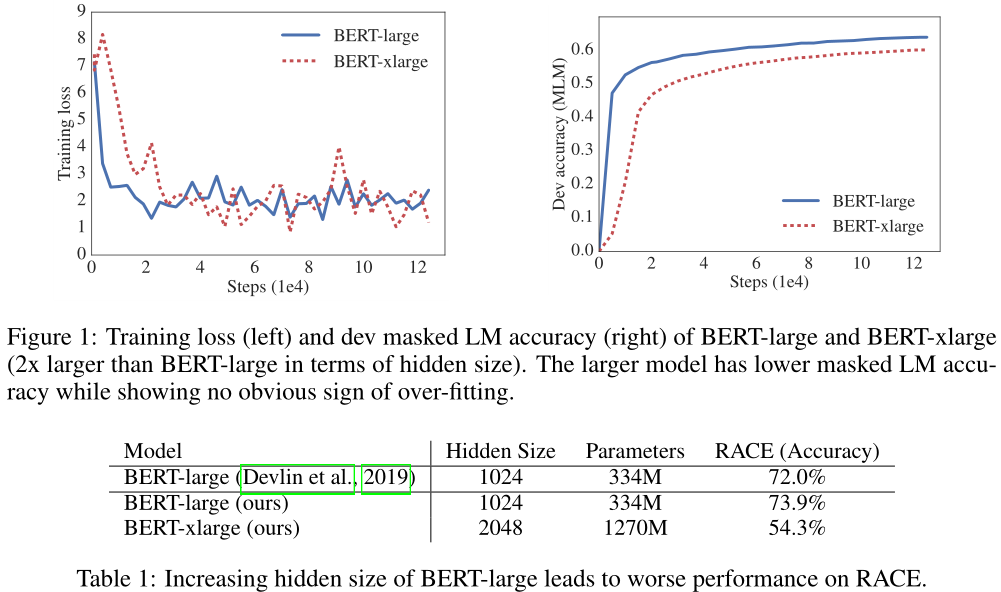
回答这个问题的一个障碍是可用硬件的内存限制。考虑到当前最先进的模型通常有数亿甚至数十亿个参数,当我们试图缩放模型时,很容易遇到这些限制。在分布式训练中,由于通信开销与模型中的参数数量成正比,训练速度也会受到显著的阻碍。我们还观察到,简单地增加模型的隐藏尺寸,如$BERT_{LARGE}$(Devlin et al., 2019),可能导致更差的性能。表1和图1展示了一个典型的例子,我们简单地将BERT-large的隐藏大小增加2倍,然后使用这个BERT-xlarge模型得到更差的结果。
ALBERT采用了两种参数缩减技术,消除了预训练模型缩放的主要障碍。第一个是因式嵌入参数化factorized embedding parameterization。通过将大的词汇嵌入矩阵分解为两个小的矩阵,将隐藏层的大小与词嵌入的大小分离开来。这种分离使得在不显著增加词嵌入的参数大小的情况下更容易增加隐藏的大小。第二种技术是跨层参数共享。这种技术可以防止参数随网络深度的增加而增大。这两种技术都在不严重影响性能的情况下显著减少了BERT参数的数量,从而提高了参数效率。类似于BERT-large的ALBERT配置参数少18倍,训练速度快1.7倍。参数缩减技术还作为一种正则化形式,稳定训练并有助于泛化。
为了进一步提高ALBERT算法的性能,我们还引入了句子顺序预测的自我监督损失(self-supervised loss for sentence-order prediction, SOP)。SOP主要关注句间连贯,旨在解决无效(Yang et al., 2019;Liu et al., 2019)的下一个句子预测(NSP)损失在原始BERT中提出。
由于这些设计决策,我们能够扩展到更大的ALBERT配置,这些配置仍然拥有比BERT-large更少的参数,但获得显著更好的性能。我们在著名的GLUE、SQuAD和RACE基准上建立了新的最先进的结果,用于自然语言理解。具体来说,我们将RACE的准确度提升到89.4%,GLUE基准提升到89.4,SQuAD 2.0的F1得分提升到92.2。
3 THE ELEMENTS OF ALBERT
在本节中,我们给出了ALBERT的设计决策,并提供了与原始BERT架构的相应配置的量化比较(Devlin et al., 2019)。
3.1 MODEL ARCHITECTURE CHOICES
$ALBERT$架构的主干与$BERT$类似,它使用了一个带有GELU非线性的变压器编码器transformer encoder(V aswani等人,2017)(Hendrycks & Gimpel, 2016)。我们遵循BERT符号约定和表示的词汇嵌入大小$E$、$L$编码器层的数量,和隐藏的大小如下$H$, Devlin et al. (2019),我们设置了前馈/过滤器feed-forward/filter大小为$4H$, the number of attention heads to be $H/64$.
关于BERT的设计选择,ALBERT做出了三个主要贡献。
Factorized embedding parameterization.
BERT,以及后续建模的改进如XLNet (Yang et al ., 2019)和RoBERTa(Liu et al ., 2019),字块嵌入大小WordPiece embedding $E$与隐藏层大小$H$相关联,即$E≡ H$出于建模和实际原因,该决策似乎不太理想,如下所示。
从建模的角度来看,单词块嵌入WordPiece embeddings是为了学习上下文无关的表示,而隐藏层嵌入是为了学习上下文相关的表示。正如上下文长度的实验所表明的(Liu等人,2019),类BERT表示的力量来自于使用上下文为学习此类上下文相关表示提供信号。the power of BERT-like representations comes from the use of context to provide the signal for learning such context-dependent representations因此,从隐藏层大小$H$中取消字词嵌入大小 WordPiece embedding size $E$允许我们根据建模需求更有效地使用总模型参数,这表明$H$远远大于$E$
从实用的角度来看,自然语言处理通常要求词汇量$V$较大如果$E≡ H$、 然后,增加H会增加嵌入矩阵的大小,其大小为$V×E$。这很容易产生一个具有数十亿个参数的模型,其中大多数参数在训练期间仅进行少量更新。
因此,对于ALBERT,我们使用嵌入参数的因式分解,将它们分解为两个较小的矩阵。我们不是将one-hot向量直接投影到大小为$H$的隐藏空间,而是首先将它们投影到大小为$E$的低维嵌入空间,然后将其投影到隐藏空间。通过这种分解,我们将嵌入参数从$O(V×H)$减少到$O(V×E+E×H)$。当$H$远远大于$E$,这一参数的减少意义重大。
Cross-layer parameter sharing
对于ALBERT,我们提出跨层参数共享作为提高参数效率的另一种方法。共享参数有多种方式,例如,仅跨层共享前馈网络(FFN)参数,或仅共享注意参数。ALBERT的默认决定是跨层共享所有参数。我们在Sec.4的实验中将此设计决策与其他策略进行了比较。
Dehghani et al.(2018)(Universal Transformer,UT)和Bai et al.(2019)(深度平衡模型Deep Equilibrium Models,DQE)对Transformer网络进行了类似的策略探索。与我们的观察不同,Dehghani等人(2018年)表明UT优于普通变压器Dehghani et al. (2018) show that UT outperforms a vanilla Transformer。Bai et al(2019)表明,他们的DQE达到了一个平衡点,在这个平衡点上,某一层的输入和输出嵌入保持不变。我们对L2距离和余弦相似性的测量表明,我们的嵌入是振荡的,而不是收敛的。
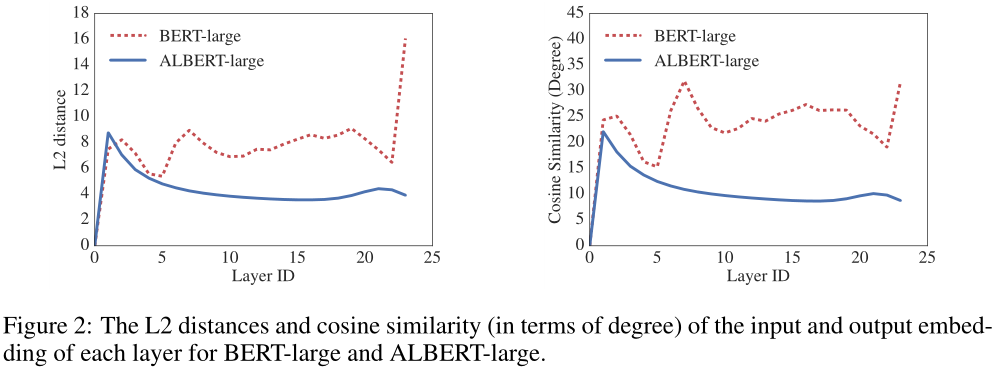
图2显示了使用BERT-large和ALBERT-large配置的每层输入和输出嵌入的L2距离和余弦相似性(见表2)。我们观察到,对于ALBERT来说,层与层之间的转换要比对于BERT平滑得多。这些结果表明,权值共享对稳定网络参数有影响。尽管与BERT相比,这两个指标都有所下降,但即使在24层之后,它们也不会收敛到0。这表明ALBERT参数的解空间与DQE发现的解空间非常不同。
Inter-sentence coherence loss.
除了蒙面语言建模(MLM)损失(Devlin等人,2019年),BERT还使用了一种称为下一句预测(NSP)的额外损失。NSP是一种二元分类损失,用于预测两个片段是否连续出现在原始文本中,如下所示:通过从训练语料库中提取连续的片段创建正面示例;通过将来自不同文档的片段配对,创建负面示例;正反两个例子的抽样概率相等。NSP目标旨在提高下游任务的性能,例如需要对句子对之间的关系进行推理的自然语言推理。然而,随后的研究(Yang等人,2019年;Liu等人,2019)发现NSP的影响不可靠,并决定消除它,这一决定得到了多个任务下游任务性能改善的支持。
我们推测,与MLM相比,NSP效率低下的主要原因是它作为一项任务缺乏难度。如前所述,NSP将主题预测和连贯性预测topic prediction and coherence prediction合并到一个任务中。然而,与连贯性预测相比,主题预测更容易学习,并且与使用MLM损失学习的内容重叠更多。
[由于负面示例是使用不同文档中的材料构建的,因此负面示例部分从主题和连贯性角度都不一致。]
我们认为句子间建模是语言理解的一个重要方面,但我们提出了一个主要基于连贯性的损失。也就是说,对于ALBERT,我们使用了一种句子顺序预测(SOP)损失,它避免了主题预测,而是侧重于句子间连贯的建模。SOP损失使用与BERT相同的技术(来自同一文档的两个连续段)作为正面示例,使用相同的两个连续段(但顺序交换)作为负面示例。这迫使模型学习关于语篇层面连贯特性的更细粒度的区别。如我们在第二节中所示。4.6,结果表明,NSP根本无法解决SOP任务(即,它最终学习更容易的主题预测信号,并在SOP任务上以随机基线水平执行),而SOP可以在合理程度上解决NSP任务,可能是基于分析不一致的连贯性线索presumably based on analyzing misaligned coherence cues.。因此,ALBERT模型持续改善了多句子编码任务的下游任务性能。
3.2 MODEL SETUP
我们在表2中给出了具有可比超参数设置的BERT和ALBERT模型之间的差异。由于上面讨论的设计选择,与相应的BERT模型相比,ALBERT模型具有更小的参数大小。

例如,与BERT-large相比,ALBERT-large的参数少约18倍,分别为18M和334M。如果我们将BERT设置为具有一个超大尺寸,H=2048,我们最终得到一个具有12.7亿个参数且性能不足的模型(图1)。相比之下,H=2048的ALBERT-xlarge配置只有59M个参数,而H=4096的ALBERT xxlarge配置有233M个参数,即大约70%的BERT large参数。请注意,对于大型网络,我们主要报告12层网络上的结果,因为24层网络(具有相同的配置)获得类似的结果,但计算成本更高。
参数效率的提高是ALBERT设计选择的最重要优势。在量化这一优势之前,我们需要更详细地介绍我们的实验装置。
4 EXPERIMENTAL RESULTS
4.1 EXPERIMENTAL SETUP
为了使比较尽可能有意义,我们遵循BERT(Devlin et al.,2019)设置,使用BOOKCORPUS(Zhu et al.,2015)和英语维基百科(Devlin et al.,2019)进行预训练基线模型。这两个语料库由大约16GB的未压缩文本组成。我们将输入格式化为“$[CLS]x_1[SEP]x_2[SEP]$”,其中$x_1=x_{1,1},x_{1,2}··$和$x_2=x_{1,1},x_{1,2}··$是两段。我们始终将最大输入长度限制为512,并以10%的概率随机生成短于512的输入序列。与BERT一样,我们使用30000个词汇量,使用SentencePiece(Kudo&Richardson,2018)进行标记,如XLNet(Yang等人,2019年)。tokenized using SentencePiece (Kudo & Richardson, 2018) as in XLNet (Y ang et al., 2019).
我们使用n-gram掩蔽(Joshi et al., 2019)为MLM目标生成掩码输入,每个n-gram掩码的长度都是随机选择的。长度$n$的概率是:
$p(n)=\frac{1/n}{\sum_{k=1}^N1/k}$
我们将n-gram(即n)的最大长度设置为3(即MLM目标可以由最多3-gram的完整单词组成,如“白宫通讯员White House correspondents”)。
所有模型更新均使用批量4096和学习率为0.00176的$LAMB$优化器(You等人,2019)。除非另有规定,我们对所有型号进行125000步的训练。训练是在云TPU V3上完成的。用于培训的TPU数量从64到1024不等,具体取决于型号大小。
除非另有规定,本节所述的实验装置适用于我们自己的所有版本的BERT模型和ALBERT模型。
4.2 EVALUATION BENCHMARKS
4.2.1 INTRINSIC EVALUATION 内在评价
为了监控训练进度,我们使用与第4.1节相同的程序,基于来自SQuAD和RACE的开发集创建一个开发集。4.1. 我们报告MLM和句子分类任务的准确性。请注意,我们仅使用此集合来检查模型是如何收敛的;其使用方式不会影响任何下游评估的绩效,例如通过模型选择。
4.2.2 DOWNSTREAM EVALUATION 下游评估
继Yang et al.(2019)和Liu et al.(2019)之后,我们在三个流行的基准上评估了我们的模型:通用语言理解评估(GLUE)基准(Wang et al.,2018),斯坦福问答数据集的两个版本(SQuAD;Rajpurkar等人,2016年;2018),以及考试阅读理解(RACE)数据集(Lai等人,2017年)。为完整起见,我们在附录A.1中提供了这些基准的说明。与(Liu等人,2019年)一样,我们对开发集执行提前停止,在此基础上,我们报告所有比较,但基于任务排行榜的最终比较除外,我们还报告测试集结果。
4.3 OVERALL COMPARISON BETWEEN BERT AND ALBERT
我们现在已经准备好量化第3节中描述的设计选择的影响。特别是关于参数效率的。参数效率的提高展示了ALBERT的设计选择的最重要优势,如表3所示:ALBERT xxlarge的参数仅占BERT large的70%左右,与BERT large相比,ALBERT xxlarge实现了显著的改进,根据几个具有代表性的下游任务的发展集得分差异来衡量:SQuAD v1.1 (+1.7%), SQuAD v2.0 (+4.2%), MNLI (+2.2%), SST-2 (+3.0%), and RACE (+8.5%).
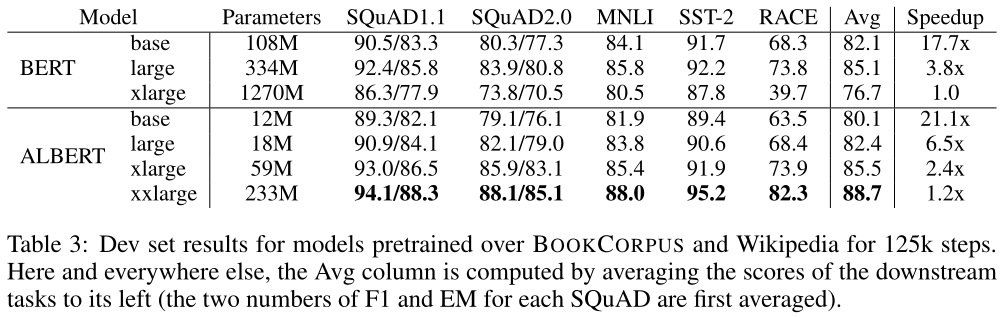
我们还观察到,在所有指标上,BERT-xlarge得到的结果明显比BERT更差。这表明像BERT-xlarge这样的模型比参数较小的模型更难训练。另一个有趣的观察结果是,在相同的训练配置(相同数量的TPU)下,训练时的数据吞吐量速度。由于通信量和计算量较少,与相应的BERT模型相比,ALBERT模型具有更高的数据吞吐量。最慢的是BERT-xlarge模型,我们将其用作基线。随着模型变大,BERT和ALBERT模型之间的差异变大,例如,ALBERT xlarge的训练速度比BERT xlarge快2.4倍。
接下来,我们进行烧蚀实验,量化每个设计选择对ALBERT的个人贡献。
4.4 FACTORIZED EMBEDDING PARAMETERIZATION
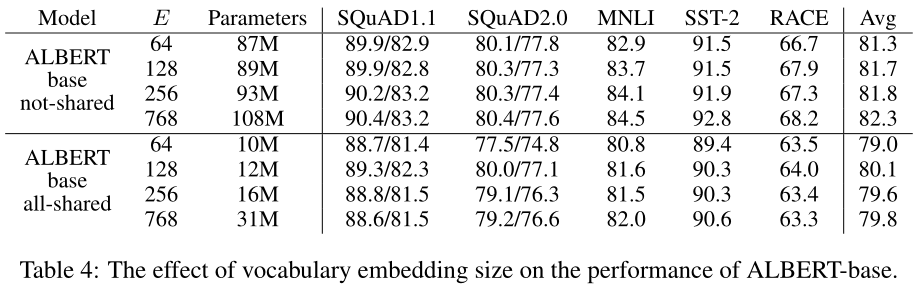
表4显示了使用ALBERT基本配置设置(见表2)改变词汇嵌入大小vocabulary embedding size $E$的效果,使用相同的代表性下游任务集。在非共享条件(BERT风格)下Under the non-shared condition (BERT-style),较大的嵌入大小可以提供更好的性能,但不会太大。在全共享条件下(ALBERT-style),大小为128的嵌入似乎是最好的。基于这些结果,我们在未来的所有设置中使用嵌入大小$E=128$,作为进一步扩展的必要步骤。
4.5 CROSS-LAYER PARAMETER SHARING
表5给出了各种跨层参数共享策略的实验,使用了具有两种嵌入大小($E=768$和$E=128$)的ALBERT-base配置(表2)。我们比较了全共享策略(ALBERT风格)、非共享策略(BERT风格)和只共享注意参数(但不共享FNN参数)或只共享FFN参数(但不共享注意参数)的中间策略。
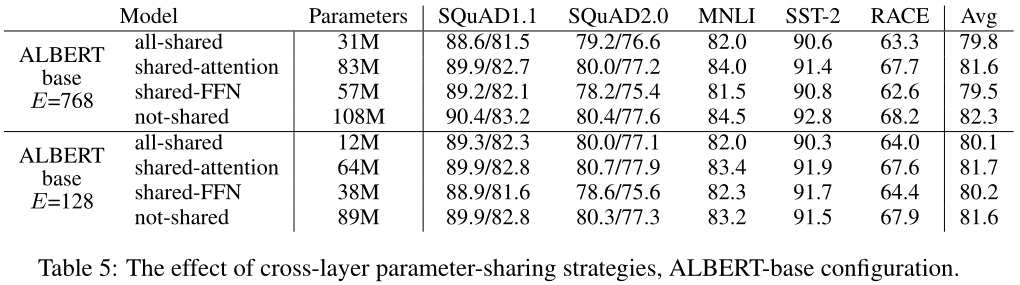
4.6 SENTENCE ORDER PREDICTION (SOP)
我们使用ALBERT-base配置,比较了三种实验条件下额外的句子间缺失:无(XLNet和RoBERTa-style)、NSP(BERT-style)和SOP(ALBERT-style)。结果如表6所示,包括内部 both over intrinsic(MLM、NSP和SOP任务的准确度)和下游任务。

内在任务的结果表明,NSP loss对SOP任务没有辨别力(准确率为52.0%,类似于“无”条件下的随机猜测性能)。这使我们可以得出结论,NSP最终只对主题转移进行建模。相比之下,SOP损失确实较好地解决了NSP任务(准确率为78.9%),而SOP任务则更好(准确率为86.5%)。更重要的是,SOP损失似乎持续改善了多句编码任务的下游任务性能(SQuAD1.1为+1%,SQuAD2.0为+2%,RACE为+1.7%),平均得分提高了约+1%。
4.7 EFFECT OF NETWORK DEPTH AND WIDTH
在本节中,我们将检查深度(层数)和宽度(隐藏大小)如何影响ALBERT的性能。表7显示了使用不同层数的ALBERT大型配置(见表2)的性能。3层或3层以上的网络通过使用之前深度的参数进行微调进行训练(例如,12层网络参数从6层网络参数的检查点进行微调)。如果我们比较3层ALBERT模型和1层ALBERT模型,尽管它们的参数数量相同,性能显著提高。然而,当继续增加层数时,回报会逐渐减少:12层网络的结果与24层网络的结果相对接近,48层网络的性能似乎会下降。
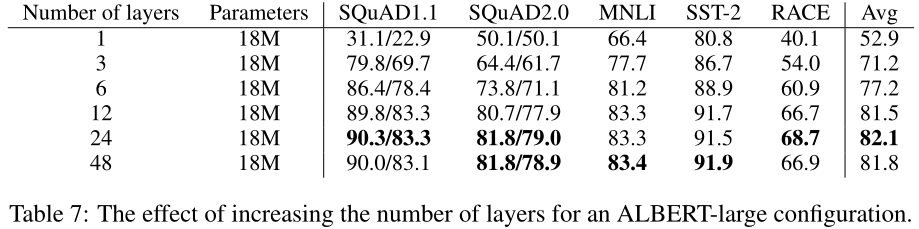
对于3层ALBERT大型配置,在表8中可以看到类似的现象,这一次是宽度。当我们增加隐藏大小时,我们得到的性能会随着回报的减少而增加。在6144的高密度下,性能似乎显著下降。我们注意到,这些模型似乎都没有过度拟合训练数据,与性能最好的ALBERT配置相比,它们都有更高的训练和发展损失training and development loss。

4.8 WHAT IF WE TRAIN FOR THE SAME AMOUNT OF TIME?如果我们训练的时间相同怎么办?
表3中的速度speed-up结果表明,与ALBERT-xxlarge相比,BERT-large的数据吞吐量大约高出3.17倍。由于较长的训练通常会带来更好的性能,因此我们进行了一次比较,在比较中,我们不控制数据吞吐量(训练步骤的数量),而是控制实际训练时间(即,让模型训练相同的小时数)。在表9中,我们比较了一个BERT-large在400k个训练步骤(训练34h)后的性能,大致相当于一个具有125k个训练步骤(训练32h)的ALBERT-xxlarge训练所需的时间。

经过大致相同的训练时间后,ALVERT-xxlarge明显优于BERT-large:+1.5%的平均运动成绩,在RACE中的差异高达+5.2%。
4.9 DO VERY WIDE ALBERT MODELS NEED TO BE DEEP(ER) TOO?
在第4.7节中,我们展示了对于ALBERT-large(H=1024),12层和24层配置之间的差异很小。对于更宽的ALBERT配置,如ALBERT-xxlarge(H=4096),此结果是否仍然适用?

表10的结果给出了答案。12层和24层大型配置在下游精度方面的差异可以忽略不计,平均分数相同。我们得出结论,当共享所有跨层参数(ALBERT-style)时,不需要比12层配置更深的模型。
4.10 ADDITIONAL TRAINING DATA AND DROPOUT EFFECTS
到目前为止所做的实验仅使用维基百科和图书语料库数据集,如(Devlin等人,2019年)。在本节中,我们报告了XLNet(Y ang等人,2019)和RoBERTa(Liu等人,2019)使用的额外数据的影响测量结果。
图3a绘制了在没有和有额外数据的两种情况下dev set MLM accuracy,后者提供了一个显著的提升。我们还在表11中观察到下游任务的性能改进,除了SQuAD基准测试(基于wikipedia,因此受到领域外培训材料的负面影响)。
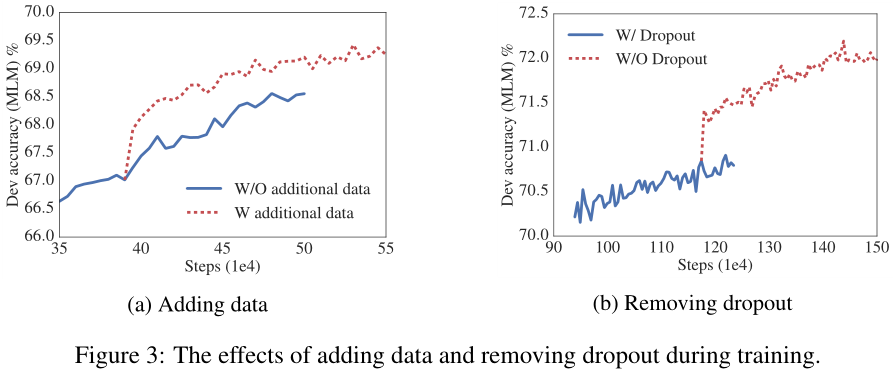

我们还注意到,即使在1M步训练之后,我们的最大模型仍然没有过度拟合它们的训练数据。因此,我们决定去掉dropout,进一步增加我们的模型容量。从图3b中可以看出,去除dropout显著提高了MLM的准确性。在1M左右的训练步骤上对ALBERT-xxlarge进行中期评估(表12)也证实,去除dropout有助于下游任务。实证(Szegedy et al., 2017)和理论(Li et al., 2019)证据表明,卷积神经网络中批次归一化和dropout的结合可能会产生有害的结果。据我们所知,我们是第一个证明dropout会损害大模型Transformer-based的性能的人。

4.11 CURRENT STATE-OF-THE-ART ON NLU TASKS
我们在本节中报告的结果使用了Devlin等人(2019)使用的训练数据,以及Liu等人(2019)和yang等人(2019)使用的额外数据。我们报告了两种微调设置下的最先进的结果:单模型和集成。在这两种设置中,我们只进行单任务微调[Following Liu et al. (2019), we fine-tune for RTE, STS, and MRPC using an MNLI checkpoint.]。继Liu等人(2019)之后,关于开发集,我们报告了五次运行的中值结果。
The single-model ALBERT配置采用了讨论过的最佳性能设置:ALBERT-XXlarge配置(表2),using combined MLM and SOP losses,且no drouput。根据开发集性能选择有助于最终集成模型的检查点;此选择考虑的检查点数量范围为6到17,具体取决于任务。对于GLUE(表13)和RACE(表14)基准,我们对集合模型的模型预测进行平均,其中候选模型使用12层和24层体系结构从不同的训练步骤进行微调。对于SQuAD(表14),我们对具有多个概率的跨度的预测分数取平均值;我们还计算了“无法回答”决策的平均分数。
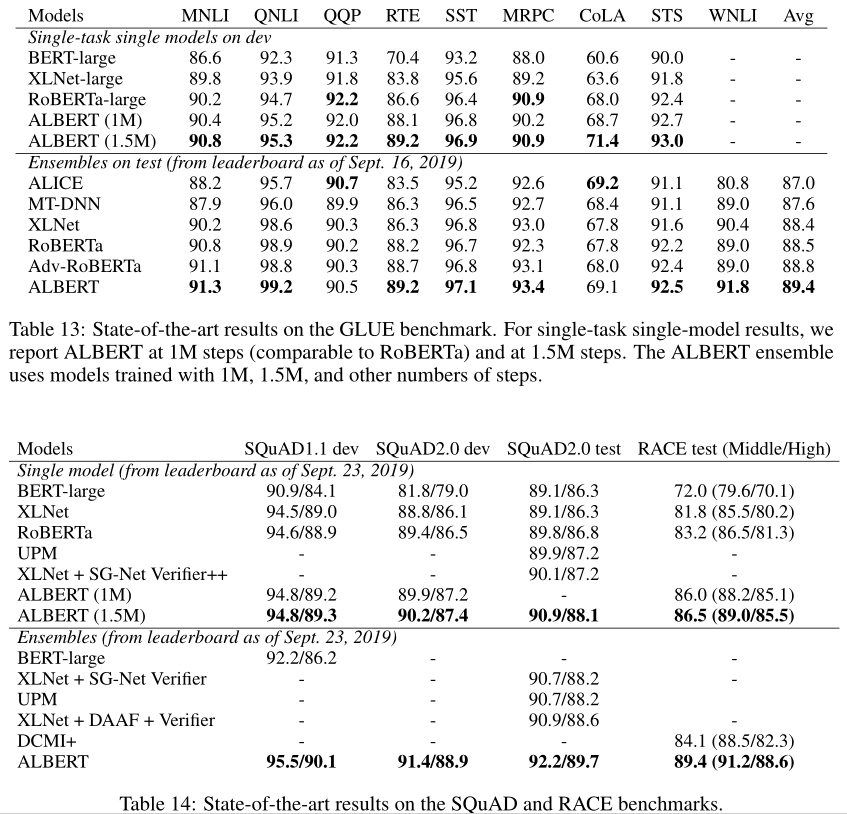
单模型single-model和ensemble测试结果均表明,ALBERT在所有三项基准测试中都显著提高了最新水平,获得了89.4分的GLUE分数、92.2分的SQuAD 2.0测试F1分数和89.4分的比RACE测试准确度。后者似乎是一个特别强大的改进,比BERT(Devlin等人,2019年)的绝对分数提高了+17.4%,比XLNet(Yang等人,2019年)的绝对分数提高了+7.6%,比RoBERTa(Liu等人,2019年)的绝对分数提高了+6.2%,比DCMI+(Zhang等人,2019年)的绝对分数提高了5.3%,DCMI+是专为阅读理解任务设计的多个模型的集合。我们的单一模型达到了86.5%的精度,仍然比最先进的集成模型高2.4%。
5 DISCUSSION
虽然ALBERT-xxlarge比BERT-large具有更少的参数,并且获得了显著更好的结果,但由于其更大的结构,它的计算成本更高。因此,下一个重要步骤是通过稀疏注意sparse attention(Child et al.,2019)和块注意 block attention(Shen et al.,2018)等方法加快ALBERT的训练和推理速度。可以提供额外表示能力的正交研究线包括硬示例挖掘(Mikolov等人,2013年)和更有效的语言建模培训(Yang等人,2019年)An orthogonal line of research, which could provide additional representation power, includes hard example mining (Mikolov et al., 2013) and more efficient language modeling training (Yang et al., 2019).。此外,尽管我们有令人信服的证据表明,语序预测是一项更为持续有效的学习任务,它能带来更好的语言表达,我们假设,目前的自我监督训练损失可能还没有捕捉到更多的维度,这可能会为产生的表征创造额外的表征能力。we hypothesize that there could be more dimensions not yet captured by the current self-supervised training losses that could create additional representation power for the resulting representations.


 浙公网安备 33010602011771号
浙公网安备 33010602011771号