【论文阅读】A Discourse-Level Named Entity Recognition and Relation Extraction Dataset for Chinese Literature Text[CoRRabs2017]
论文地址:https://arxiv.org/pdf/1711.07010.pdf
数据集地址:https://github.com/lancopku/Chinese-Literature-NER-RE-Dataset
中文文本的语篇级实体识别与关系抽取数据集
Abstract
中文文献文本命名实体识别和关系抽取一直是一个非常困难的问题,其中一个原因是缺乏标注集。为了改进这一任务,本文从数百篇中文文献中构建了一个语篇层面的数据集。为了建立一个高质量的数据集,我们提出了两种标记方法来解决数据不一致的问题,包括启发式标记方法和机器辅助标记方法。在此基础上,我们还介绍了几种常用的模型进行实验。实验结果不仅证明了该数据集的有效性,而且为进一步的研究提供了依据。
1. Introduction
命名实体识别的最新研究(林和武,2009;Collobert等人,2011年;Huang等人,2015)和关系提取(RE)(Kambhatla,2004;曾等,2014;Nguyen和Grishman,2015)专注于新闻报道,取得了良好的业绩。然而,对于一部复杂而重要的作品《中国文学》,由于缺乏数据集,这项工作变得更加困难。因此,本文从数百篇中国文献中构建了一个NER和RE数据集。不同于以往句子之间相互独立的句子级数据集,我们构建了一个语篇级数据集,其中来自同一篇文章的句子提供了额外的上下文信息。
然而,与传统的实体类和显式关系的数据集相比,在中文文本中标记实体和关系更加困难。各种修辞手段对建立一个高一致性的数据集提出了巨大的挑战。人格化personification的一个简单例子如图1所示。”“哈姆雷特”是一个人的名字,但指的是一只兔子。一些注释者用“Person”标签来标记它,另一个注释者用“Thing”标签来标记它。因此,如何处理大量不明确的情况以保证数据的一致性成为当前的主要难题。
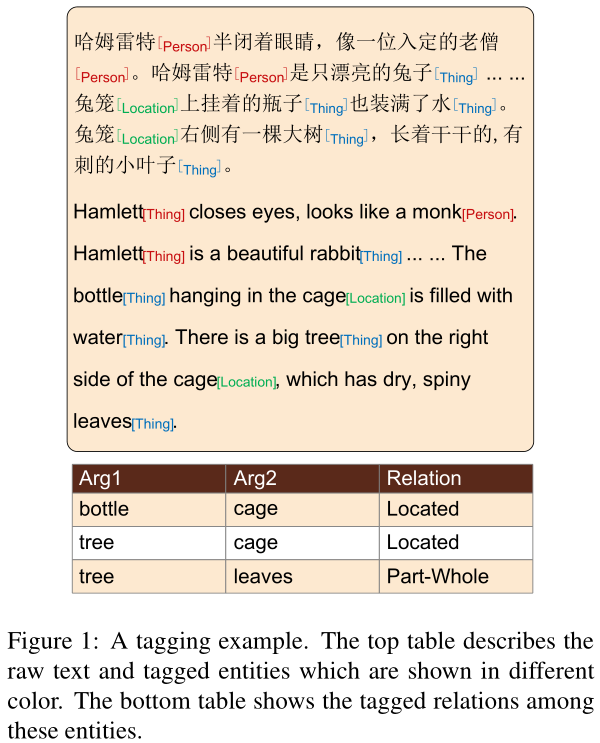
图1:标记示例。上表描述了以不同颜色显示的原始文本和标记实体。下表显示了这些实体之间的标记关系。
本文提出了两种解决这一问题的方法。一方面,我们定义了一些通用的消歧规则来处理最常见的情况。另一方面,由于这些启发式规则过于通用,无法处理所有的歧义情况,我们还引入了一种机器辅助标注方法,该方法使用从语料库子集学习的标注标准来预测剩余数据上的标注。注释者只关心预测标签与黄金标签不同的情况,这大大减少了注释者的工作量。
总的来说,我们总共手工注释了726篇文章,29096句话,超过100000个字符,这是在300人小时内完成的,跨越5个人3个月。
在此基础上,我们还介绍了一些广泛应用的模型进行实验。实验结果不仅证明了该数据集的有效性,而且为进一步的研究提供了依据。
我们的贡献如下:
为中文文献文本命名实体识别和关系抽取的联合学习提供了一个新的数据集。
与以往的句子级数据集不同,本文提出的数据集是基于语篇级的,它提供了额外的上下文信息。
在此基础上,我们介绍了一些被广泛应用的模型进行实验,这些模型可以作为进一步研究的基线。
2. Data Collections
我们先从网站上获得1000多篇中文文献,然后过滤、提炼出726篇。不包括太短或太吵的文章。由于中文文献文本标注的困难,本文将标注过程分为三个步骤。详细的标记过程如图2所示。
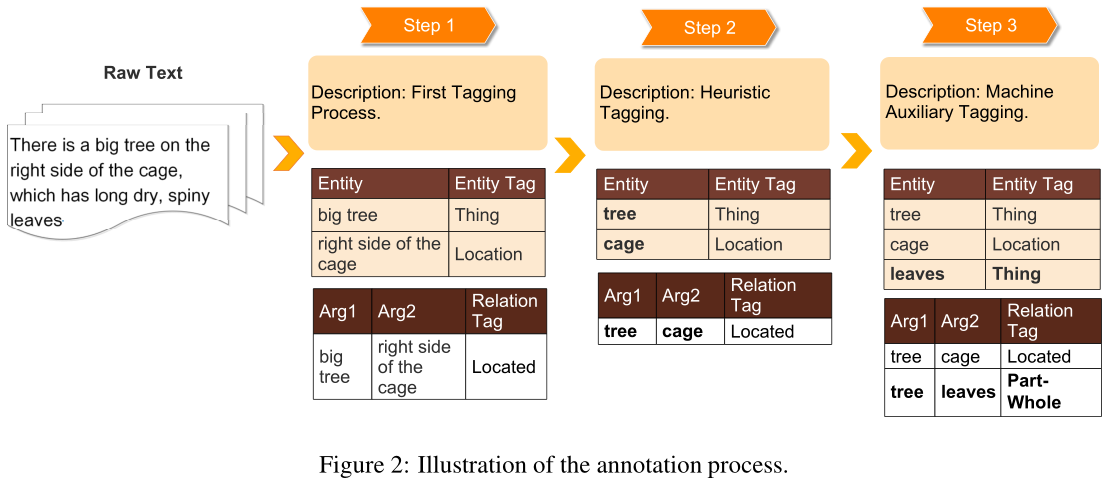
第一步:First T agging Process.第一次打包过程。我们首先尝试根据已定义的实体和关系标记对原始文章进行注释。在标注过程中,我们发现了数据不一致的问题。为了解决这个问题,我们设计了以下两个步骤。
第二步:Heuristic Tagging Based on Generic disambiguating Rules.基于一般消歧规则的启发式聚类。为了保证注释准则的一致性,我们设计了几种通用的消歧规则。例如,删除所有形容词,在标记实体时只标记“实体标题”(例如,将“穿红布的女孩”改为“女孩”)。在这一阶段,我们将根据启发式规则对所有文章进行重新注释,并纠正所有不一致的实体和关系。
第三步:Machine Auxiliary T agging.机器辅助打包。尽管启发式标记过程显著地提高了数据集的质量,但是基于有限的启发式规则处理所有不一致的情况是非常困难的。因此,我们介绍了一种机器辅助标注方法。其核心思想是训练一个模型来学习语料库子集上的标注准则,并在剩余数据上生成预测标签。将预测的标签与gold标签进行比较,发现不一致的实体和关系,大大减少了注释者的工作量。具体来说,我们将语料库分为10个部分,并根据对其余部分训练的模型对每个部分进行预测。我们在本文中使用的模型是CRF与一个简单的二元特征模板。
在所有的标注步骤之后,我们还要检查所有的实体和关系,以确保数据集的正确性。
3. Data Properties
我们将详细描述标记集和注释格式。
3.1. Tagging Set
我们定义了7个实体标签和9个关系标签的基础上,几个可用的NER和RE数据集,但一些额外的类别特定于中国文学文本。标签的详细信息如表1和表2所示。
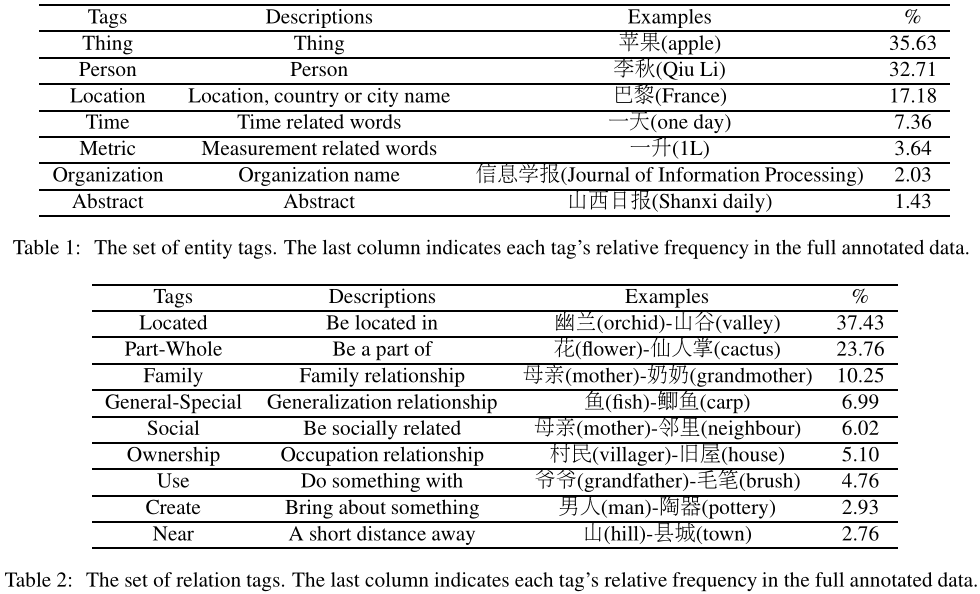
我们添加了三个新的实体标签,专门用于理解文学文本,包括“Thing”、“Time”和“Metric”,“Thing”是文章主要描述的捕捉对象,如“flower”、“tree”等,“Time”是用来捕捉故事的时间线,如“one day”、“one mouth”等,“Metric”用于捕捉与测量相关的单词,如“1L”、“1mm”等。
对于关系标记,我们设置了9个不同的类来更好地理解元素之间的连接,包括“Located”、“Near”、“Part-all”、“Family”、“Social”、“Create”、“Use”、“Ownership”、“General-Special”。为了建立文学作品中的人际关系,我们使用了“Socail”标签,这在其他语料库中并不常见。
3.2. Annotation Format
每个实体由“T”标记标识,它具有多个属性。
Id:标识文档中实体的唯一编号。它从0开始,每次在同一文档中标识新实体时都会递增。
Type:实体标记之一。
Begin Index:实体的开始索引。它从0开始,每增加一个字符。the begin index of an entity. It starts at 0, and is incremented every character.
End Index:实体的结束索引。它从0开始,每增加一个字符。 the end index of an entity. It starts at 0, and is incremented every character.
Value:指可识别物体的词语。words being referred to an identifiable object.
每个关系都由“R”标记标识,该标记可以具有多个属性:
Id:标识文档中关系的唯一编号。它从0开始,每次在同一文档中标识新关系时,它都会递增。
Arg1和Arg2:与关系关联的两个实体。
Type: one of the relation tags
4. Experiments
我们引入几个基线来进行实验。在本节中,我们将详细描述实验设置、基线和实验结果。
4.1. Settings
实验是在一台商品化的64位Dell Precision T5810工作站上进行的,该工作站具有一个3.0GHz 16核CPU和64GB RAM。用F1评分评价了NER和RE模型的性能。对于训练,我们使用小批量随机梯度下降来最小化负对数似然。训练是用大小为32的shuffled小批量进行的。
4.2. Named Entity Recognition
我们引入LSTM(Hochreiter和Schmidhuber,1997)和CRF(Lafferty,2001)作为我们的基线,如下所述。
LSTM:我们将双向LSTM作为模型之一。字符嵌入维度和隐藏维度都设置为100。
CRF:是一种常用于模式识别和机器学习的统计建模方法。我们的功能模板包括unigram和bigram功能。结果见表3。可以清楚地看到,CRF在所有标签上都比Bilstm具有更好的性能,这可能是由于特征模板的缘故。所有模型在“Person”、“Thing”和“Time”标记上的性能都优于“Location”、“Organization”和“Metric”标记。它表明,“人”、“物”和“时间”标签是最容易识别的实体。数据稀疏的问题使得捕获“位置”、“组织”和“度量”标记变得困难。

较高的精度表明,模型预测的实体可能是正确的标记,反映了训练集和测试集数据的一致性。较低的召回率表明测试集中仍有许多未知实体。如何处理这些未知实体是一个亟待进一步研究的问题。
4.3. Relation Extraction
表4比较了几种最新的语料库方法。表中的第一项显示了传统的基于特征的方法实现的最高性能。Hendrickx等人(2010)将各种手工特征输入到SVM分类器中,并获得48.9的分数。

最近在关系分类任务上的性能改进主要是借助于神经网络实现的。Socher et al.(2011)构建了一个递归神经网络,该网络在连续树上运行,与Hendrickx et al.(2010)的性能相当。Xu et al.(2015)介绍了一种门控递归神经网络,可以将分数提高到55.3。通过减少其他类别的影响,Santos等人(2015)的分数为54.1。按照CNNs,Liu等人(2009年)的F1成绩为55.2分。
5. Conclusions
我们建立了一个语篇层次的中文文学文本实体识别与关系抽取数据集。为了解决标注过程中数据不一致的问题,本文提出了两种方法,一种是启发式标注方法,另一种是机器辅助标注方法。在此基础上,介绍了几种常用的模型进行实验,为进一步的研究提供了基础。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号