【论文阅读】Global-to-Local Neural Networks for Document-Level Relation Extractionp[EMNLP2020]
论文地址:https://www.aclweb.org/anthology/2020.emnlp-main.303/
代码地址(Pytorch):https://github.com/nju-websoft/GLRE
Background
这篇文章的核心思想是:通过从粗粒度、细粒度、context information的角度对entity之间的relation进行建模。具体解决的问题是:第一:怎么对document中的复杂语义进行建模?(使用BERT);第二:怎么学习有效地entity representation?(使用RGCN);第三:其他的relation也对于当前目标entity之间的relation产生影响,如果有效的利用?(context-aware)。将这三个方面聚合起来,就是GLRE模型。
目前在doucment-level RE中,存在着三方面的问题:logical reasoning、coreference reasoning、common-sense reasoning。
Abstract
在本文中,我们提出了一种新的文档级RE模型,通过对文档信息进行实体全局和局部表示以及上下文关系表示来进行编码。实体全局表示对文档中所有实体的语义信息进行建模,实体局部表示对特定实体多次提及的上下文信息进行聚合,上下文关系表示对其他关系的主题信息进行编码。实验结果表明,该模型在两个公共数据集上都取得了较好的性能。它在提取远距离实体之间的关系和多次提及方面特别有效。
1 Introduction
总之,我们的主要贡献有两个方面:
•我们提出了一个新的模型,称为GLRE,用于文档级RE。为了预测实体之间的关系,GLRE综合了实体全局表示、实体局部表示和上下文关系表示。
•我们在两个公共文档级RE数据集上进行了广泛的实验。我们的结果证明了GLRE与许多最先进的竞争对手相比的优越性。我们的详细分析进一步显示了它在提取远距离实体之间的关系和具有多个提及方面的优势。
3 Proposed Model
首先用BERT对输入文档以句子为单位编码,然后采用和19年EMNLP中的EoG模型一样的方式构建一个异质图,在异质图上使用R-GCN进行特征传播,接着使用一个本地表示层,最终拼接多个向量(局部表示和全局表示)得到实体对的表示,在对文档主体信息求注意力后进行关系分类。
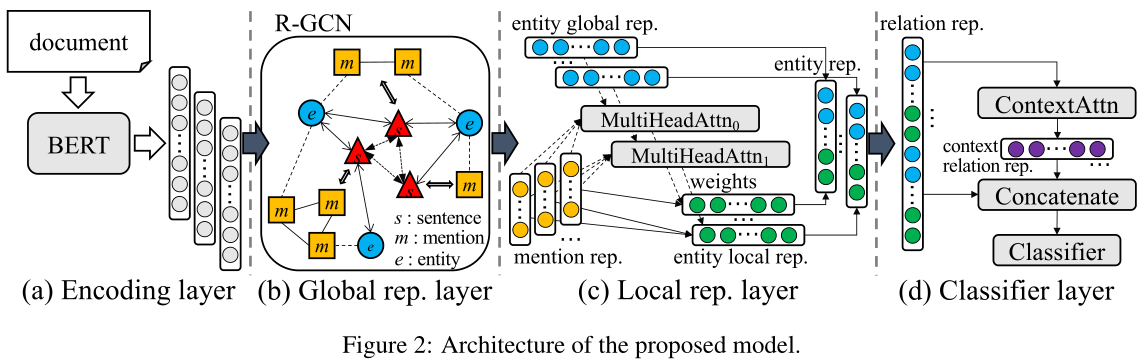
GLRE模型分为四部分:encoding layer、global representation layer、local representation、classifier layer。
encoding layer:假设输入的document表示为:$\cal D=\{w_1,w_2,…,w_k\}$,其中$w_i$表示的是第$i$个word,我们使用BERT来对其进行编码,如下:
$H=[h_1,h_2,...,h_k]=BERT([w_1,w_2,...,w_k])$
where $h_j∈ R^{d_w}$ is a sequence of hidden states at the output of the last layer of BERT.受BERT输入长度的限制,我们将一个长文档按顺序编码为短段落。
global representation layer:GLRE模型同样是基于graph的模型。同样是继承EoG模型,其中有三种node:mention node、entity node与sentence node。对于三种node的表示,我们都是将其本身的avg embedding与各自的type embedding进行conat。具体来说,对于mention node:$n_{m_i}=[avg_{w_j\in m_i}(h_j);t_m]$;对于entity node:$n_{e_i}=[avg_{m_j\in e_i}(n_{m_j});t_{e}]$;对于sentence node:$n_{s_i}=[avg_{h_j\in s_i}(h_j);t_s]$。有五种edge:mention-mention edge(同一个sentence中的所有mentions之间加一条边)、mention-entity edge(entity与其mention之间加一条边)、mention-sentence edge(如果mention node与sentence node加一条边)、entity-sentence edge(如果一个entity至少有一个mention出现在sentence中,那么entity node与sentence之间加一条边)、sentence-sentence edge(所有的sentence node之间加一条边)。⚠️和EoG模型一样,同样没有entity-entity edge!构建好graph之后,在GLRE模型中,stack了L层的R-GCN,具体的aggregate的公式如下:
$n^{l+1}_{i}=\sigma(\sum_{x\in {\cal X}}\sum_{j\in {\cal N_{i}^{x}}}\frac{1}{|\cal N_{x}^{i}|}W^l_xn^l_j+W^l_0n^l_i)$
其中,$\cal N_{i}^x$ 表示在$x$这种edge type下,node $i$的邻接节点的集合,$\cal X$ denotes the set of edge types.说到底,还是和GCN处理异质图的方式没啥区别。我们将L层之后的每一个node的representation称为entity global representation,记做:$e^{glo}_i$。
local representation layer:
通过将实体相关的提及表示与多头注意力结合,来学习实体针对特定实体对的局部表示。“局部”可以从两个角度来理解:
1.从编码层聚合原始提及信息。
2.对于不同的实体对,每个实体将具有与该实体对对应的一个局部表示。即假设一个实体 $e_1$,它能够和其他三个实体组成三个实体对,那么实体$e_1$将针对这三个实体对各有一个局部表示。
如果说global rep layer是想在document-level上对不同的entity之间的语义信息进行建模,那么local rep layer是在对同一个entity的不同的mention之间的信息进行建模,从而得到更加好的entity rep,因为在不同的entity pair中,entity的表示肯定是不同的,如果只用global rep layer的结果的话,那么entity的表示就是唯一的了,肯定对最后结果会有影响。怎么做呢?在GLRE中,采用的是multi-head self attention。多头注意使得重模型能够共同关注由来自不同表示子空间的多个提及组成的实体的信息。其计算涉及查询集Q和键值对(K,V):
$MHead(\cal Q,\cal K,\cal V)=[head_1;...;head_z]W^{out}$
$head_i=softmax(\frac{{\cal Q}W_i^{\cal Q}({\cal K}W_i^{\cal K})^{'}}{\sqrt{d_v}}){\cal V}W_i^{\cal V}$
where $W^{out}∈ R^{d_n×d_n}$ and $W^{\cal Q}_i$,$W^{\cal K}_i$,$W^{\cal V}_i ∈ R^{d_n×d_v}$ are trainable parameter matrices. $z$ is the number of heads satisfying that $z × d_v= d_n$.
In this paper $\cal Q$ is related to the entity global representations, $\cal K$ is related to the initial sentence node representations before graph convolution (i.e., the input features of sentence nodes in R-GCN), and $\cal V$ is related to the initial mention node representations.
对于entity pair $(e_a,e_b)$,公式如下:
$e^{loc}_a=LN(MHead_a(e^{glo}_b,\{n_{s_i}\}_{s_i\in \cal S_a},\{n_{m_j}\}_{m_j\in \cal M_a}))$
$e^{loc}_b=LN(MHead_b(e^{glo}_a,\{n_{s_i}\}_{s_i\in \cal S_b},\{n_{m_j}\}_{m_j\in \cal M_b}))$
where $LN(·)$ denotes layer normalization.其中,$\cal S_a$表示的是entity a 的mentions所在的sentence的集合,$\cal M_a$表示的是enity a的mention的集合。$\cal M_b$ and $\cal S_b$ are similarly defined for $e_b$. Note that $MHead_0$ and $MHead_1$ learn independent model parameters for entity local representations
直观地说,如果一个句子包含两个分别对应于$e_a$、$e_b$的提到$m_a$、$m_b$,那么提到节点表示$n_{m_a}$、$n_{m_b}$对预测$(e_a、e_b)$的关系有更大的贡献,在获得$e^{loc}_a$、$e^{loc}_b$时,注意权重应该更大。更普遍地说,包含$m_a$和$e^{glo}_b$ 的句子的节点表示之间的语义相似度越高,说明这个句子和$m_b$在语义上的关联性越大,$n_{m_a}$应该对$e^{loc}_a$ 有更高的注意权重。
【因此,enity a 的 local representation 是对 encoder 得到的所有与 a 相关的 mention 进行加权得到的。用什么作为加权的分数呢?用 entity pair 的对方 attn 所有句子:在不同句子(语境)里面,如果句子跟 entity b 越接近(语境更对),那么这里的 mention a 在构成 entity a 时也就越重要。这样一来,每个 entity 在不同的 entity pair 中都有不同的表示。】
classifier layer:得到$e^{glo}$与$e^{loc}$之后,我们将两者聚合。对于entity pair$ (e_a,e_b)$,具体来说:
$\tilde e_a=[e^{glo}_a;e^{loc}_a;\Delta(\delta_{ab})]$
$\tilde e_b=[e^{glo}_b;e^{loc}_b;\Delta(\delta_{ba})]$
$o_r = [\hat{e}_a;\hat{e}_b]$
这里$\delta$指的是 entity 之间的相对距离, $\triangle(·)$是将这个距离通过$[2^0,2^1,…,2^n]$这样映射成 one-hot 向量。
接下来,作者提出一个想法:文档的主题和关系分布是有关系的。因此,为了隐式地表示文档主题,作者将一篇文档中的所有关系表示 attn 加权求和,得到文档的主题表示:
$o_c = \sum_{i=0}^p\theta_io_i = \sum_{i=0}^p\frac{\exp(o_iWo_r’)}{\sum_{j=0}^p \exp(o_jWo_r’)}o_i$
where $W ∈ R^{d_r×d_r}$ is a trainable parameter matrix. dris the dimension of target relation representations. $o_i(o_j)$ is the relation representation of the ith(jth) entity pair. $θ$ is the attention weight for $o_i$. $p$ is the number of entity pairs.
最后,利用前向神经网络(FFNN)对目标关系表示$o_r$和上下文关系表示$o_c$进行预测。此外,考虑到一个实体对可能包含多个关系,我们将多分类问题转化为多个二元分类问题。所有关系集合$\cal R$上的预测概率分布$r$定义如下:
$y_r=sigmoid(FFNN([o_r;o_c]))$
where $y_r∈ R^{|R|}$
We define the loss function(CE) as follows:
$\cal L=-\sum_r\in {\cal R}(y_r^{*}log(y_r)+(1-y_r^{*})log(1-y_r))$
where $y^{∗}_r∈ [0,1]$ denotes the true label of $r$. We employ Adam optimizer (Kingma and Ba, 2015) to optimize this loss function.
4 Experiments and Results
4.1 Datasets
dataset: CDR,DocRED
4.4 Main Results
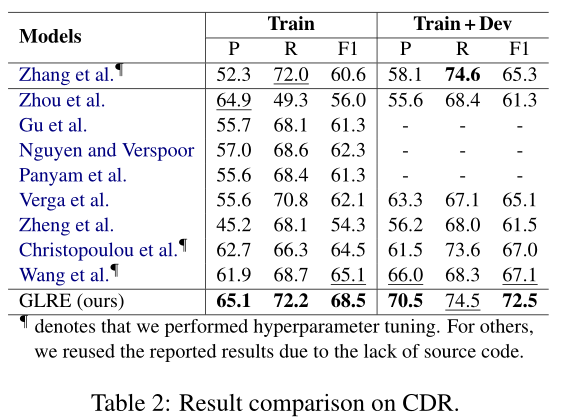
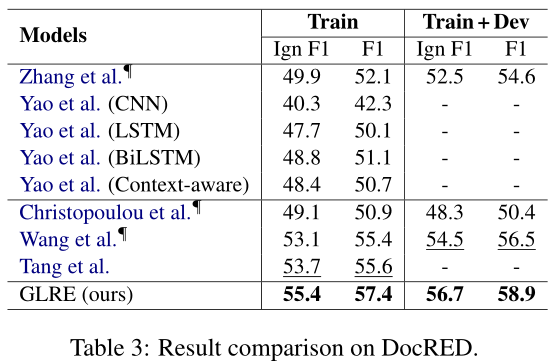
说实话,这个结果一般。但是这篇论文的ablation与error analysis很有意思。GLRE在长距离的entity pair的关系抽取上取得了比较好的结果(>=3),paper中给它归因于global rep layer的构建,同时local rep layer的构建减少了噪音。
4.5 Detailed Analysis
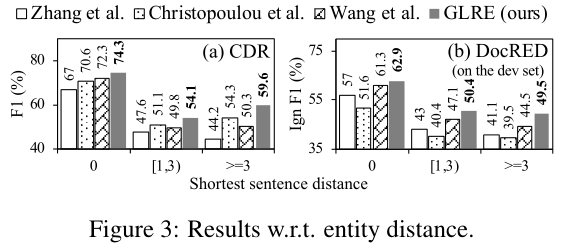
我们从实体距离的角度考察了开放源代码模型的性能,实体距离定义为两个实体的所有提及之间的最短句子距离。图3描述了仅使用训练集对CDR和DocRED的比较结果。
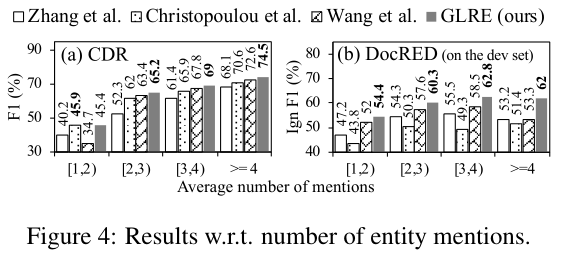
为了评估GLRE在聚合多个实体提及的信息方面的有效性,我们根据每个实体对的平均提及数目来衡量性能。与前面的分析类似,图4显示了仅使用训练集的CDR和DocRED的结果。事实上,当平均提及次数较少时,所有模型的性能都会下降,因为文档中提供的相关信息较少,这使得关系更难预测。我们将在今后的工作中考虑外部知识。
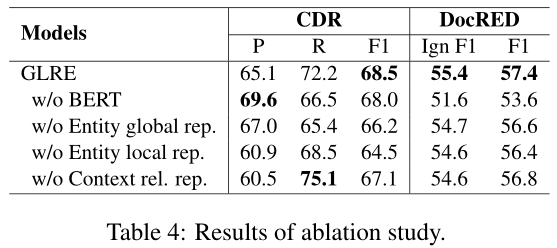
为了研究GLRE中各层的有效性,我们仅使用训练集进行了消融研究。表4显示了比较结果。我们发现:(1)BERT对DocRED的影响大于CDR。这主要是因为BERT在RE中引入了有价值的语言知识和常识知识,但在生物医学领域很难捕捉到潜在的知识。(2) 当我们删除实体全局表示、实体局部表示或上下文关系表示时,F1得分下降,这验证了它们在文档级RE中的有用性。(3) 特别是,当我们去掉实体的局部表示时,F1的分数下降得更明显。我们发现,在CDR和DocRED上,分别有超过54%和19%的实体在不同的句子中有多次提及。局部表示层利用多头注意有选择地聚集多个提及,可以减少大量的噪声。【当local rep layer被移除之后,F1值下降很快,这说明multi-head self attention能够有选择性的aggregatemention rep,过滤掉一些噪音,看来不是所有的mention都有entity rep都有用】
Case study
- Logical reasoning很重要,GLRE模型中,完全靠RGCN,没有另外再搞一套机制来结局logical reasoning;
- 当一个句子中,很多entity用
and这样的词连接的时候,往往模型无法对她们之间的关系进行建模,paper中说在GLRE模型中是靠context-aware来解决的,但是我觉得效果一般吧; - 怎么引入先验知识很重要,因为很多common sense不会出现在训练集里面,而很多relation的判断都需要用到先验知识,这个时候怎么做?GLRE也没有解决这个问题;
- 当一个句子的主语等部分缺失时,怎么处理?在GLRE中,是通过建立global rep layer来解决的,但是效果不是很好;
- 当代词有歧义的时候,怎么解决?
- paper统计了一下,logical reasoning(40.9%)、component missing error(28.8%)、prior knowledge missing error(13.6%)、coreference reasoning error?(12.9%)。
参考:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号