【论文阅读】Double Graph Based Reasoning for Document-level Relation Extraction[EMNLP2020]
论文地址:https://www.aclweb.org/anthology/2020.emnlp-main.127/
代码地址(Pytorch):https://github.com/DreamInvoker/GAIN
Background
这篇paper也是继承了EoG模型,主要解决三个问题:1.一个relation的subject与object可能位于不同的sentence,不能仅仅利用一个句子来得到relation;2.同一个entity可能会出现在不同的sentence当中,因此需要利用cross-sentence context information,从而更好的表示entity;3.很多relation需要logical reasoning(main issue)。为此提出了GAIN模型。个人认为这篇paper的模型比较优雅,挺好的。
Abstract
在本文中,我们提出了图聚合和推理网络Graph Aggregation-and-Inference Network (GAIN),一种识别长段落中这种关系的方法。GAIN构造了两个图,一个是层次图(MG),一个是实体层次图(EG)a heterogeneous mentionlevel graph (MG) and an entity-level graph (EG).。前者捕获不同提及之间的复杂交互,后者聚合相同实体的潜在提及。基于这些图,我们提出了一种新的路径推理机制来推断实体之间的关系。在公共数据集DocRED上的实验表明,GAIN比以前的最新技术有了显著的性能改进(F1上为2.85)。
1 Introduction
最近, Yao et al. (2019) 提出了一个大规模的人工注释文档级RE数据集DocRED,将句子级RE推进到文档级,其中包含大量的关系事实。我们从DocRED dev集合中随机抽取100个文档,并手动分析Yao et al. (2019)提出的基于BiLSTM的模型预测的不良案例bad cases。
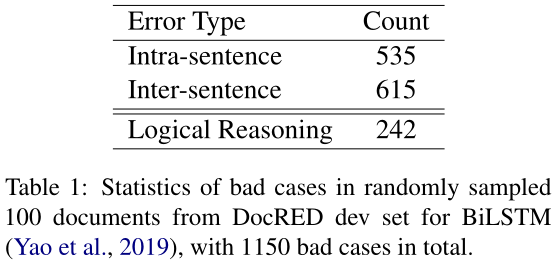
如表1所示,句间错误类型和逻辑推理错误类型在所有不良案例中所占比例较大,分别为53.5%和21.0%。因此,本文旨在解决这些问题,更好地从文档中提取关系。
文档级RE中以前的工作不考虑推理,或仅使用基于图的或分层的神经网络以隐式方式进行推理。本文提出了一种用于文档级关系抽取的图聚合推理网络。它旨在直接应对上述挑战。GAIN构建了一个异构的提级图,该图具有两种类型的节点,即mention节点和文档节点,以及三种不同类型的边,即实体内边、实体间边和文档边,以获取文档中实体的上下文信息。然后,我们将图形卷积网络应用于HMG,以获得每次mention的文档感知表示。实体级图(EG)是通过合并HMG中引用同一实体的提及来构建的,在此基础上,我们提出了一种新的路径推理机制。这种推理机制允许我们的模型推断实体之间的多跳关系。
总之,我们的主要贡献如下:
- 我们提出了一种新的方法——图聚合推理网络,它采用了双图设计。
- 我们引入了一个异构的Mention-level Graph (MG),它带有一个基于图的神经网络,用于对文档中不同提及之间的交互进行建模,并提供文档感知提及表示document-aware mention representations。
- 我们引入了实体级图Entity-level Graph (EG),并为实体间的关系推理提出了一种新的路径推理机制
2 Task Formulation
task definition:给定一篇含有N个sentence的documnt:$D= \{s_i\}^N_{i=1}$,$s_i=\{w_j\}^M_{j=1}$,以及P个entity:$\xi=\{e_i\}^P_{i=1}$,$e_i=\{m_j\}^Q_{j=1}$,其中$e_i$表示第$i$个entity,$m_j$表示第$i$个entity的第$j$个mention。我们的目标是提取$\xi$中entity之间的relation。$\{(e_i, r_{ij}, e_j)|e_i, e_j∈ \xi, r_{ij}∈ R\}$,其中$R$是预定义的关系类型集。
本文将实体$e_i$与$e_j$之间的关系$r_{ij}$定义为句间关系,当且仅当$S_{e_i}∩S_{e_j}=∅$,其中$S_{e_i}$表示含有$e_i$提及的句子。$S_{e_i}∩S_{e_j}\ne ∅$时$r_{ij}$定义为句内关系。We also define K-hop relational reasoning as predicting relation $r_{ij}$ based on a K-length chain of existing relations,with $e_i$ and $e_j$ being the head and tail of the reasoning chain, i.e., $e_i → (r_1)e_m →(r_2) . . . e_n → (r_K)e_j⇒ ei→ (r_{ij})e_j$.
3 Graph Aggregation and Inference Network (GAIN)
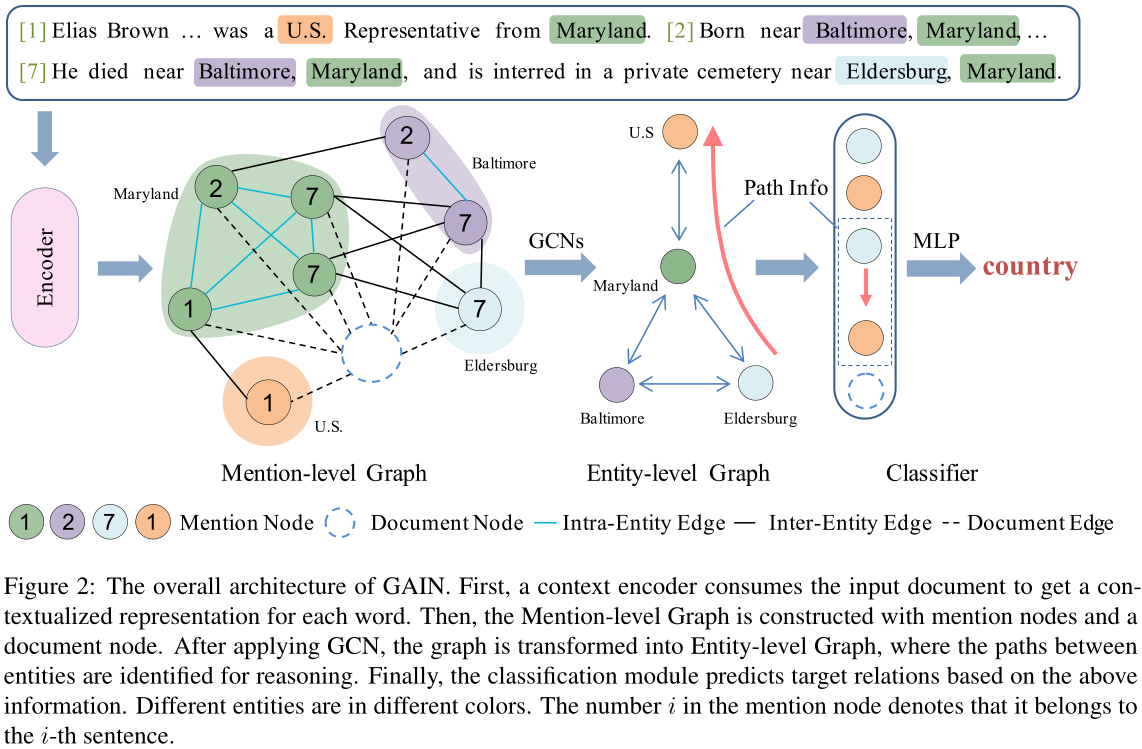
图2:GAIN的总体架构。首先,上下文编码器使用输入文档来获得每个单词的上下文表示。然后,利用提及节点和文档节点构造提及层次图。应用GCN后,将图转化为实体级图,在实体级图中识别实体间的路径进行推理。最后,分类模块根据上述信息对目标关系进行预测。不同的实体有不同的颜色。提及节点中的数字$i$表示它属于第$i$句。
GAIN模型分为四部分:encoding module、mention-level graph aggregation module、entity-level graph aggregation module、classification module。
encoding module:这一部分主要是将document中的word经过编码,得到contextual representation。给定有n个word的document:$\cal D=\{w_i\}_{i=1}^{n}$,然后将word embedding与type embedding以及coreference embedding进行concat,得到final word embedding,即:
$x_i=[E_w(w_i);E_t(t_i);E_c(c_i)]$
其中,$t_i$与$c_i$是$w_i$对应的named entity type id与entity id,对于那些不属于任何entity的word,我们引入None type。得到final word embedding之后,我们将其输入到一个encoder当中(BISLTM/BERT etc),得到这一层的输出:
$[g_1,...,g_n]=Encoder([x_1,...,x_n])$
mention-level graph aggregation module:这个graph的构建主要是对mention之间的关系进行建模。在mention-level graph当中,node set:mention node与document node。mention node就是表示每一个mention,document node是一个虚拟节点,主要是为了对document information进行建模,同时也是视其为一个中继节点,让不同mention之间的交互变得更加容易。edge set:intra-entity edge、inter-entity edge、document edge。intra-entity edge是让同一个entity的mention彼此连接;inter-entity edge是让一个句子内的不同entity的mention之间进行连接;document edge是让所有的mention与document node进行连接。
构建好graph之后,GAIN模型使用与GCNN中同样的GCN,如下:
$h^{(l+1)}_{u}=\sigma(\sum_{k\in{\cal K}}\sum_{v\in \cal N_k(u)}W^{(l)}_kh^{(l)}_v+b^{(l)}_k)$
where $\cal K$ are different types of edges,$\cal N_k(u)$ denotes neighbors for node u connected in k-th type edge
但是这种虽然很接近WL-test,但是会存在范数不收敛的情况,这个真的不需要考虑一下吗?🧐在stack N层GCN之后,对于每一个node,我们去concat所有layer的representation,来作为每一个node的final representation,即:$m_u=[h^{(0)}_u;h^{(1)}_u;…,h^{(N)}_u]$
where $h^{(0)}_u$ is the initial representation of node $u$.For a mention ranging from the s-th word to the t-th word in the document,$h_u^{(0)}=\frac{1}{t-s+1}\sum_{j=s}^tg_j$
entity-level graph inference module:这一步就是进行inference,得到entity-entity的表示,用于最终的分类,所以path reasoning mechanism很重要。在entity-level graph中,我们将同一个entity的所有mention的表示的平均作为此entity的表示,即:$e_i=\frac{1}{N}\sum_n m_n$。entity node之间的边表示:$e_{ij}=\sigma(W_q[e_i;e_j]+b_q),\sigma \text{是激活函数}$。对于entity pair之间不同的路径,其表示是:$p^i_{h,t}=[e_{ho};e_{ot};e_{to};e_{oh}]$,当然了,entity pair之间的path会有多个,我们使用attention机制,如下:
$s_i=\sigma ([e_h;e_t]W_lp^i_{h,t})$
$\alpha_i=\frac{exp(s_i)}{\sum_jexp(s_j)}$
$p_{h,t}=\sum_i\alpha_ip^i_{h,t}$
其中,σ是某一个激活函数。这里只使用了2-hop,如果使用multi-hop,效果会不会更好?🧐
有了这个模块,一个实体可以通过融合其提及的信息来表示,这些信息通常以多个句子的形式传播。此外,潜在的推理线索由实体之间的不同路径来建模。然后将它们与注意机制相结合,从而考虑潜在的逻辑推理链来预测关系。
classification module:这里就是最终的分类。但是这里借用了ESIM中表示,对于enitty pair $(e_h,e_t)$,其综合的inferential path information是:
$I_{h,t}=[e_h;e_t;|e_h-e_t|;e_h\odot e_t;m_{doc};p_{h,t}]$
其中,$m_{doc}$就是document node,然后我们将其看作一个多标签分类问题,使用sigmoid函数,来完成分类,如下:
$P(r|e_h,e_t)=sigmoid(W_b\sigma(W_aI_{h,t}+b_a)+b_b)$
最终的loss使用CE。We use binary cross entropy as the classification loss to train our model in an end-to-end way:
$\cal L=-\sum_{\cal D \in \cal S}\sum_{h \ne t}\sum_{r_i\in \cal R}\cal I(r_i=1)logP(r_i|e_h,e_t)+\cal I(r_i=0)log(1-P(r_i|e_h,e_t))$
where $\cal S$ denotes the whole corpus, and $\cal I(·)$ refers to indication function.
4 Experiments
4.2 Experimental Settings
2 layers of GCN;dropout rate to 0.6;learning rate to 0.001;optimizer:AdamW with weight decay 0.0001;
three settings for our GAIN:
1.GAIN-GloVe uses GloV e (100d) and BiLSTM (256d) as word embedding and encoder
2.3 $GAIN-BERT_{base}$ and $GAIN-BERT_{large}$ use $BERT_{base}$ and $BERT_{large}$ as encoder respectively and the learning rate is set to 1e−5
4.4 Results
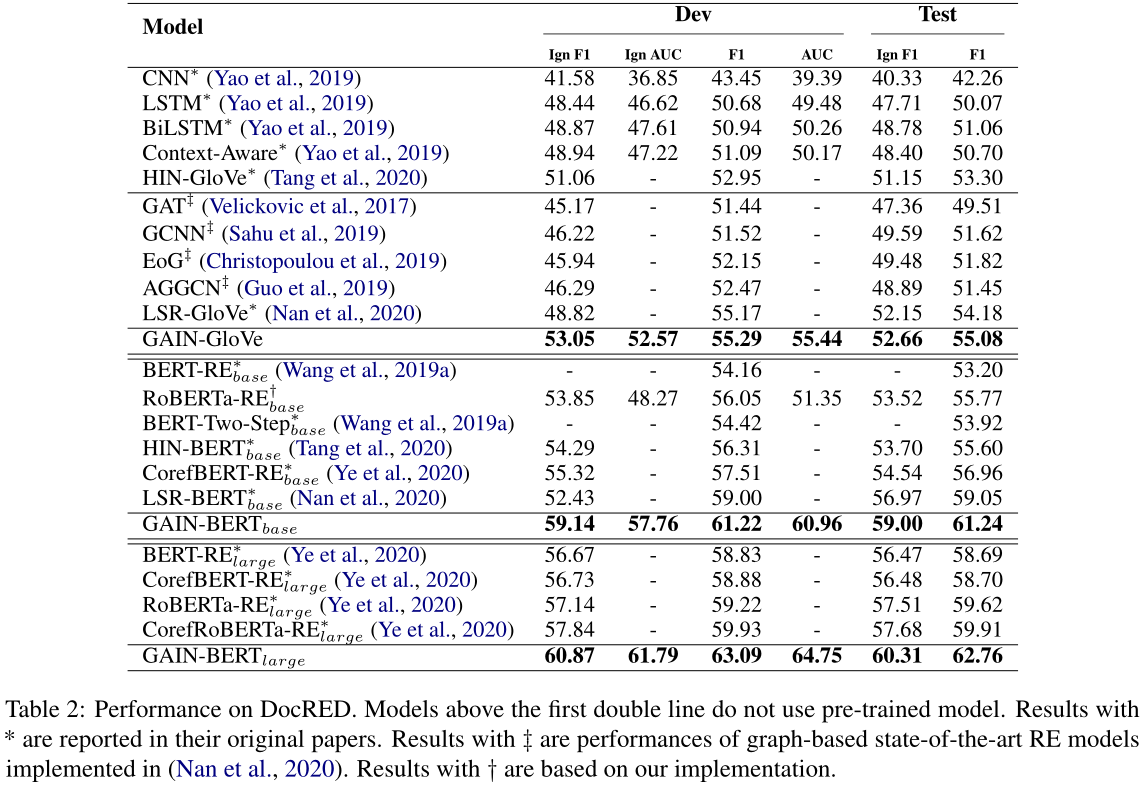
表2:DocRED上的性能。第一条双线以上的模型不使用预训练的模型。他们的原始论文中报告了*的结果。带有‡的结果是在(Nan et al,2020)中实施的基于图的SOTA RE模型的性能。使用†的结果基于我们的实施。
4.5 Ablation Study
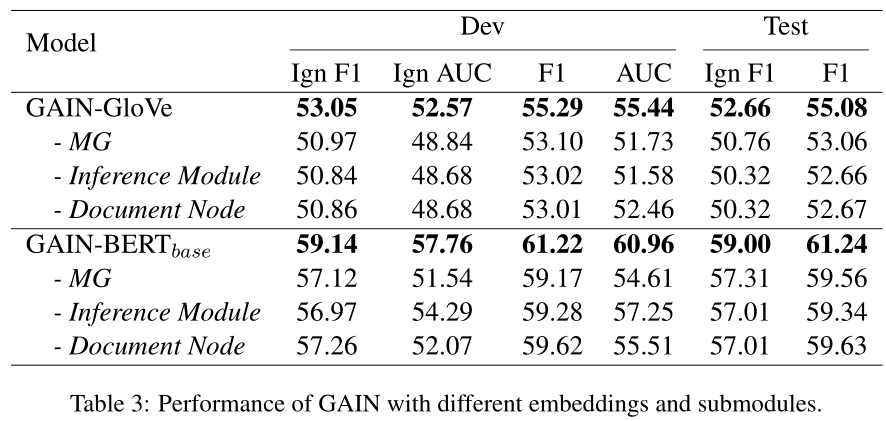
- hmg 不要(entity 直接用 mention 平均得到,然后在 EG 上用 GCN):drop 2%,hmg 可以捕捉 mention 之间的信息和 document-aware features;对 inter 影响更大
- inference 不要(整体拼接时不用 path):drop 2%,inference 对 2-hop 有帮助(但是帮助这么小,我也是没想到的,看来原来不考虑推理的关系抽取,其实也能抽出大部分需要推理的关系?)
- hmg 里面不要 document node:drop 2%,document 可以作为 pivot,缩短距离
4.6 Analysis & Discussion
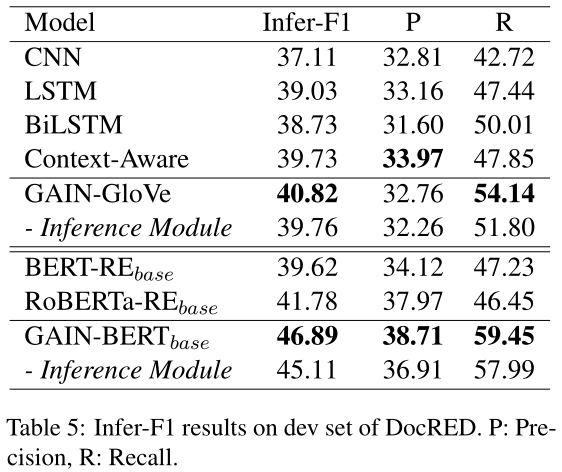
在这一小节中,我们进一步分析了dev集上的句间和推理表现。与Nan et al(2020年)相同,我们在表4中报告了F1内/F1间得分,其中仅分别考虑句内或句间关系。同样,为了评估模型的推理能力,表5中给出了Infer-F1分数,其中只考虑了参与关系推理过程的关系。例如,在计算Infer-F1时,如果存在$e_h→( r_1)e_o →(r_2)e_t$和$e_h→(r_3)e_t$,我们将考虑黄金关系事实golden relation facts$r_1$、$r_2$和$r_3$
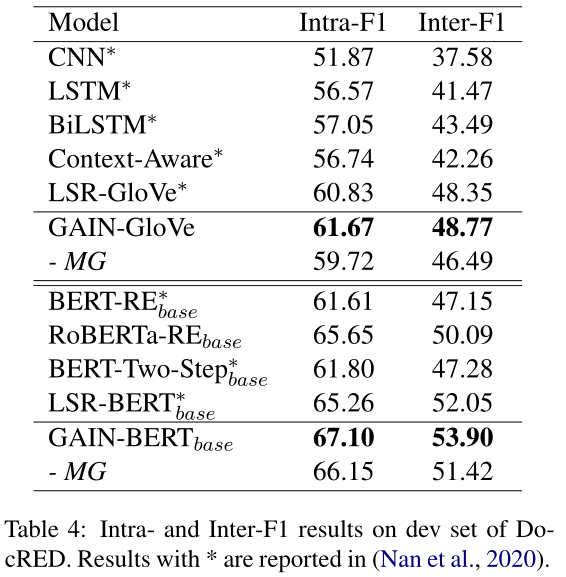
如表4所示,GAIN不仅在F1内,而且在F1间都优于其他基线,去除MG会导致F1间的下降幅度比F1内的下降幅度更大,这表明我们的MG确实有助于提及之间的互动,特别是那些分布在不同句子中的长距离依赖的提及。
此外,表5表明,GAIN可以更好地处理关系推理。例如,与RoBERTa-REbase相比,GAIN-BERTbase改进了5.11 Infer-F1。推理模块在捕获实体之间的潜在推理链方面也发挥着重要作用,如果没有这些推理链,Gainbertbase将减少1.78个推断-F1。
4.7 Case Study

思考:
- 这篇文章的推断只考虑到 2-hop 的情况。2-hop 就可以几乎覆盖大部分的关系,3-hop 几乎可以覆盖的所有关系。所以其实在这个数据集上,没有必要考虑多跳的情况?因此 GCN 不能有太多层(假如用 GCN 做推断的话),在文档级关系抽取的问题上,其实不算是特别重要的缺点(或者说,值得改进的点)?当然,对于 GCN 本身,这是最大的缺点。
- 对于 document node,我感觉很有意思。作者说,在 mention 图上,有了和所有 mention 都相连的 document node,这样 mention 之间最大距离就是 2 了。然后在他的试验里,GCN 就取了 2 层 —— 既然所有点之间最大距离就是 2,那信息传播两次,这不就将整张图都平均了吗?这还怎么 localize?
目前来看,主要的处理:encoding?怎么构建图,才能够利用好mention、entity、sentence、document的信息(edge-oriented or node-oriented)?heterogeneous graph的处理?logical reasoning的处理?长期建模很重要,怎么更好地处理?
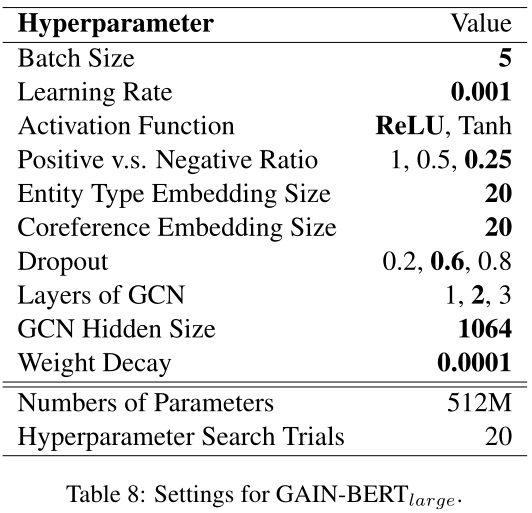
实验超参数设置:
我们最终采用的超参数值是粗体的。注意,我们并没有调优所有的超参数。


参考:
论文笔记:https://codewithzichao.github.io/2020/10/24/NLP-RE-Integrate-GNN-into-Document-level-RE-task/#more


 浙公网安备 33010602011771号
浙公网安备 33010602011771号