【论文阅读】Inter-sentence Relation Extraction with Document-level Graph Convolutional Neural Network[ACL2019]
论文地址:https://arxiv.org/abs/1906.04684
代码地址:未找到
这篇文章我参考的博客内容丰富又全面,我原文略读就够了,大部分理解来自各位博主链接我贴在下方。
Background
文档级关系抽取的难点在于:我们往往需要抽取的entity pair是span across multi-sentences,所以我们必须对entity的local、non-local、semantic、dependency等信息进行提取和建模。这篇paper提出的GCNN,正是以word为node,words之间的local与non-local dependency作为edge,来构建document-level graph,从而解决文档级关系抽取问题。
Abstarct
为了抽取文档级别的关系,许多方法使用远程监督(distant supervision )自动地生成文档级别的语料,从而用来训练关系抽取模型。最近也有很多多实例学习(multi-instance learning)的方法被提出来解决这个问题。
跨句子的关系抽取不仅需要句子内部的依赖关系还需要句子之间的依赖关系。依存语法树(Dependency trees)可以很好处理句子内的关系抽取,但是无法处理跨句子的关系抽取。如下图,这是一个命名实体之间的非局部依赖关系,Oxytocin和Oxt之间是共指关系,也就是红色箭头表示的。而黄色箭头代表语义依赖关系。

文档级别的关系抽取需要处理各种各样的特征,局部的,非局部的,句法的,语法的信息。而已有的方法并没有充分利用这些信息,所以作者提出了一种基于图卷积神经网络(Graph Convolutional Neural Network)的模型去做文档级别的关系抽取。作者首先对文档进行图的构建,其中图中的节点代表单词,图中的边代表局部或非局部的特征。然后使用GCNN提取图的特征,最后使用多实例学习进行关系分类。
-
依赖树(Sunil Kumar Sahu,2019)
- 一个句子一个依赖树
- 无法捕捉非局部依赖
- 不适用于句子间关系抽取
-
句子间关系提取
- 依赖于局部和非局部依赖关系
- 使用远程监控来自动生成文档级语料库(Peng et al., 2017;Song et al., 2018)。
- MIL:Verga等(2018)引入了多实例学习(multi-instance learning, MIL) 【上一篇读的论文】(Riedel et al,2010;(Surdeanu et al., 2012)处理文档中多次提到的目标实体。—关系分类
-
贡献
- 提出了一种利用GCNN捕获局部和非局部依赖关系的句子间转换模型。
- 其次,将该模型应用于两个生物化学语料库,并验证了其有效性。
- 最后,我们从PubMed摘要中开发了一个具有化学反应物-生成物关系的新型远程监控数据集。
2 Proposed Model
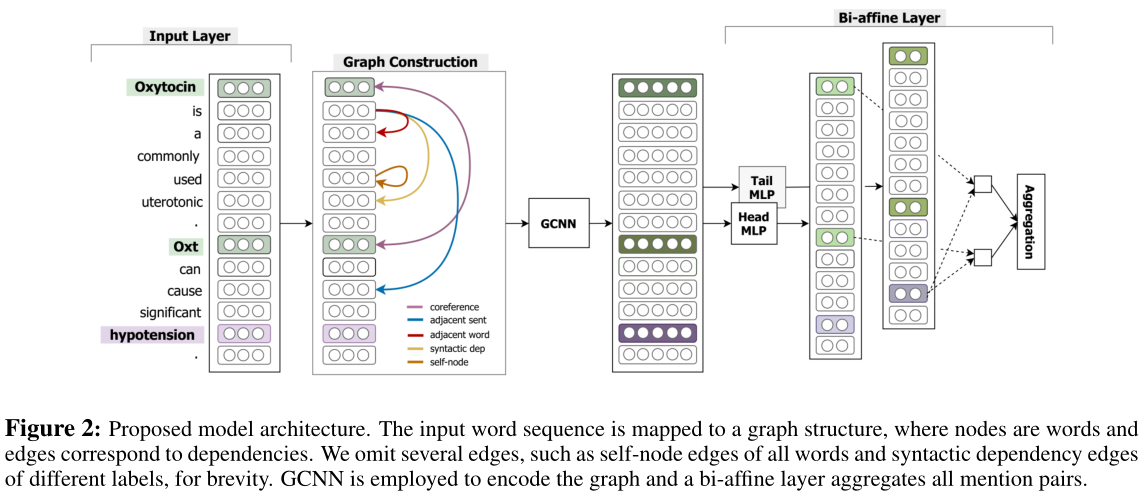
GCNN模型分为4部分:input layer、graph construction、GCNN layer、MIL-based relation classification。
task definition:给定一个document $t: [w1,w2,…,wn]$,$e_1$,$e_2$是$t$中的两个entity,我们的目标是:提取出$e_1$与$e_2$之间的relation。
input layer:对于document中的每一个word $i$,我们将它本身以及它与我们target entity pair的的相对位置分别编码为三个向量:$w_i,d_i^1,d_i^2$,如果一个entity有多个mention的话,那么就选择与当前word最接近的mention来计算相对位置。最后,每一个word的representation为:$x_i=[w_i;d_i^1;d_i^2]$。
graph construction:我们需要根据document来构建graph。在GCNN中,node set就是每一个word,edge set有5种:
Syntactic dependency edge:句法依赖,也就是使用每一个sentence中的word之间的句法关系建立edge;
Coreference edge:指代,对于表示同一个含义的phrase,进行连接;
Adjacent sentence edge:将sentence的根结点鱼上下文sentence的根结点进行连接;
Adjacent word edge:对于同一个sentence,我们去连接当前word的前后节点;
self node edge:word与本身进行连接;【GCN特性为了将节点信息本身包含到表示中,我们在图的所有节点上形成自节点型边】
GCNN layer:在构建好doucment graph的基础上,使用GCNN来计算得到每一个node的representation。这里使用的GCNN与普通的GCN不同,这里在aggregate node representation的时候,只使用了其邻域的信息,并且对于不同类型的edge,分别使用GCN(毕竟GCN只能用于同质图),最终的结果是所有类型的graph的结果的加和。我认为这里是GCNN模型最出彩的地方了,虽然现在来看并没有什么很新颖的,不过这种GCN的使用方法并不是很好,参见how power GNN这篇论文。公式如下:
$x_i^{k+1}=f(\sum_{u∈v(i)}(W_{l(i,u)}^kx_u^k+b_{l(i,u)}^k))$
其中,$f()$表示某种encoder(e.g. relu)。$x_i^{k+1}$ is the $i$-th word representation resulted from the $k-th$ GCNN block, $ν(i)$ is a set of neighbouring nodes to $i$,$W_{l(i,u)}^k$ and $b_{l(i,u)}^k$ are the parameters of the $k$ -thblock for edge type l between nodes $i$ and $u$.与Marcheggiani和Titov(2017)类似,我们为每个边的方向保留单独的参数。但是,我们通过仅为前n个类型保留单独的参数,并为所有剩余的边缘类型使用相同的参数来调整模型参数的数量,这些边缘类型称为“罕见”类型边缘。这可以避免由于不同边缘类型的过参数化而导致的可能的过拟合。【减少参数,避免拟和】
MIL-based relation classification:这里使用MIL。因为在一篇document中,每一个entity会有多个mention,我们希望能够去聚合target entity所有的mention,并通过bi-affine pairwise scoring来进行最终的关系分类。具体公式如下:
$x_i^{head}=W_{head}^{(1)}(RELU(W_{head}^{(0)}x_i^K))$
$x_i^{tail}=W_{tail}^{(1)}(RELU(W_{tail}^{(0)}x_i^K))$
$scores(e^{head},e^{tail})=log\sum_{i∈E^{head},j∈E^{tail}}exp((x_i^{head}R)x_j^{tail})$
$R∈R^{(d,r,d)}$,$r$是关系的类目数量$E^{head}$、$E^{tail}$分别表示$e^{head}$和$e_{tail}$实体的一组提及。(mention:同一实体的文字表述,可以有多个)
3 Experimental Settings
我们首先简要地描述数据集,在数据集中,对所提出的模型及其预处理进行评估。然后介绍用于比较的基线模型。最后,我们展示了训练设置
3.1 Data Sets
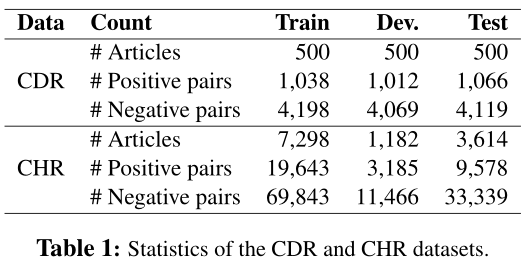
- 化学-疾病关系数据集(CDR):
- CDR数据集是为BioCreative V challenge开发的文档级、句间关系提取数据集(Wei et al., 2015)。
- CHR数据集
- 来自PubMed摘要和题目名
- 数据集由来自PubMed的12094篇摘要及其标题组成。化学品的注释是使用语义分面搜索引擎Thalia的后端执行的。化合物是从注释实体中选择的,并与图形数据库Biochem4j保持一致,Biochem4j是一个免费可用的数据库,集成了UniProt、KEGG和NCBI分类法等多种资源。如果在Biochem4j中识别出两个相关的化学实体,则它们将被视为数据集中的阳性实例,否则将被视为阴性实例。
- 总的来说,语料库包含超过100,000个注释的化学物质和30,000个反应。
- 如果两个化学实体在Biochem4j中有关系,我们认为它们是数据集中的积极实例,否则就是消极实例
3.2 Data Pre-processing
表1显示了CDR和CHR数据集的统计数据。对于这两个数据集,带注释的实体可以有多个关联知识库(KB) ID。如果提及之间至少有一个公共知识库ID,那么我们认为所有这些提及都属于同一个实体。这种方法可以减少负向配对。我们忽略了没有基于已知KB ID的实体,并删除了同一实体之间的关系(自关系)。对于CDR数据集,我们进行了hypernym滤波,类似于Gu等人(2017)和Verga等人(2018)。在CHR数据集中,两个方向都是为每个候选化学对生成的,因为在交互作用中,化学物质既可以是反应物(第一个参数),也可以是产物(第二个参数)。
我们使用GENIA Splitter4和GENIA tagger (Tsuruoka et al., 2005)处理数据集,分别用于句子拆分和单词标记。使用带有谓词-参数结构的Enju语法分析器(Miyao and Tsujii, 2008)获得了句法依赖关系。使用Stanford CoreNLP软件构建指代类型边缘(Manning et al., 2014)。
处理数据集
- mention归属哪个实体
- 看对应的是否有相同的KB的id
- 忽略无KB ID的实体,并删除自关系
- 句子拆分:GENIA Splitter
- 句子标记:GENIA tagger (Tsuruoka et al., 2005)
- 句法依赖:使用带有谓词-参数结构的Enju语法分析器(Miyao and Tsujii, 2008)获得了句法依赖关系。
- 指代消解:使用Stanford CoreNLP软件构建Coreference类型边缘(Manning et al., 2014)。
3.3 Baseline Models
CDR
- 得分函数:bi-affine pairwise scoring to detect relations.
- model
- SVM (Xu et al., 2016b),
- ensemble of feature-based and neural-based models (Zhou et al., 2016a),
- CNN and Maximum Entropy (Gu et al., 2017),
- Piece-wise CNN (Li et al., 2018)
- Transformer (Verga et al., 2018)
- CNN-RE, a re-implementation from Kim (2014) and Zhou et al. (2016a)
- RNN-RE, a reimplementation from Sahu and Anand (2018).
3.4 Model Training
我们使用在PubMed上培训的100维嵌入式单词(Pennington et al., 2014;TH等人,2015)。与Verga等人(2018)不同的是,我们使用预先训练好的词嵌入来代替子词嵌入来与我们的词图对齐。由于CDR数据集的大小,我们合并了训练和开发集来训练模型,类似于Xu et al. (2016a)和Gu et al.(2017)。我们用不同参数初始化种子的5次运行的平均值来报告性能,包括精度P、R和F1分数。我们使用训练集中边缘类型的频率来选择2.3节中的top-N边。关于训练和超参数设置的细节,请参阅补充资料
- 100-d embedding(在PubMed上训练的)(Pennington et al., 2014;TH等人,2015)
- 用预训练的词嵌入来代替子词嵌入来与我们的词图对齐。
- dev+train来训练
- 评估:
- 五次不同种子的初始化平均来报告性能
- P,R,F1
- top-N边:用边的类型的频率来选择。
4 Results
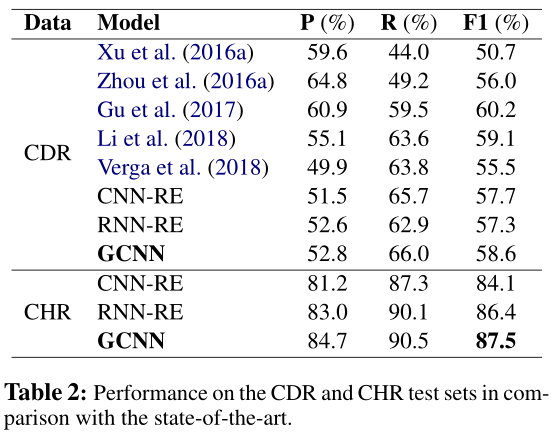
作者在Chemical-Disease Relations dataset (CDR)和CHemical Reactions dataset (CHR)上进行了实验,结果如下表所示。GCNN的在两个数据集上表现比CNN-RE和RNN-RE都要高,证明了这个模型的有效性。在CDR上GCNN比(Gu et al., 2017)的模型要低1.6个百分点,但是这个模型对局内和句间的关系使用了两个模型,GCNN仅使用了一个模型就搞定了。
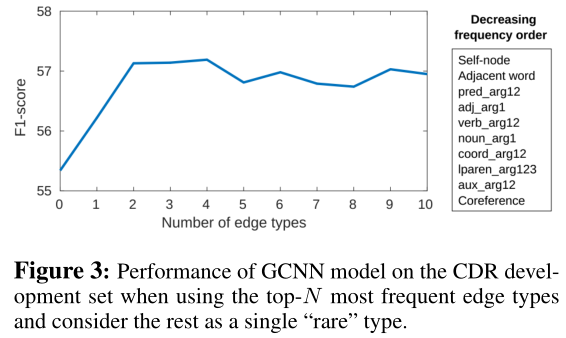
作者尝试对top-N这个参数进行调整,选取不同数量的类型的边进行对比。实验结果如下表,在边的类型数量等于4的时候F1分数达到峰值,再增加边的类型之后效果开始下降。所以作者使用top-4种边加上rare边进行后面的实验。这里有个问题是既然只选择了top-4种边,那是不是说明想排名第10的共指关系就没有用了?我觉得共指关系可以用来消歧,对于判断句间关系还是非常有用的。
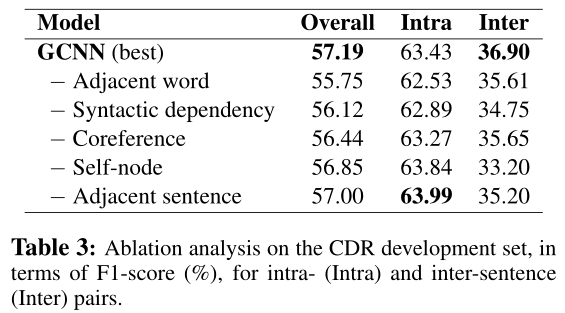
最后作者还做了ablation analysis,为了分析不同类型的边分别对句内和句间关系的影响,作者把数据集进行了拆分。Intra是句内关系数据集,Inter是句间关系数据集。结果如下表,其中所以的类型边对局内关系都有影响。对于句间关系来说,dependency这种类型的边比较关键。
6 Conclusion
作者提出了一种非常新颖的基于图方法的文档级别关系抽取模型。作者把文档中的单词作为节点,把依存关系、邻接关系、共指关系等等句内和句间的信息构建成节点和节点之间的边,然后使用带标签的GCNN对不同类型边的图提取特征,最终使用一种bi-affine模型对每一对节点进行关系打分,从而可以预测关系的类别。
这种GCNN关系抽取模型目前应该还没人做过,这篇文章给了我们另外一种角度来做关系抽取。同时我认为还有几点疑问,首先,对于节点的表示,作者只使用了单词本身加上position特征,是不是还可以加上其他的特征丰富节点的表示呢?其次,作者构建了很多种类型的边,最后只选择top-4,那是不是说模型本身过于复杂了呢?能不能再对这部分进行简化呢,把所有边融合成一个带权重的边?判断每种类型的关系所需要特征也是不同的,是不是应该对每种边区别对待? 另外一点,对所有文档所有的mention对都进行打分是不是浪费呢,我们只需要对我们关注的实体对进行打分就可以了。
总的来说,GCNN中规中矩吧,没有太出色的地方,缺点在于:构建了异质图,但是却没有考虑到不同类型的edge的作用;对于mention的处理不够好;logical reasoning几乎没有另外处理,纯靠GCNN;edge的构建需要其他的工具,不一定准确;对于word representation的表示不够。
参考:
NLP|RE-integrate-GNN:https://codewithzichao.github.io/2020/10/24/NLP-RE-Integrate-GNN-into-Document-level-RE-task/#more
论文阅读:https://blog.csdn.net/weixin_40485502/article/details/104294410
论文笔记:https://blog.csdn.net/u010960155/article/details/97890373


 浙公网安备 33010602011771号
浙公网安备 33010602011771号