【论文阅读】Relation classification via multi-level attention CNNs[ACL2016]
原文链接:https://www.aclweb.org/anthology/P16-1123.pdf
代码实现:https://github.com/dgai91/pytorch-acnn-model
关系抽取中我们会遇到很多表达同一种关系的不同方式。这种具有挑战性的变异性在本质上可以是词汇的lexical、语法的syntactic,甚至是语用pragmatic的。一个有效的解决方案需要能够考虑到有用的语义semantic和句法特征syntactic,不仅要考虑目标实体在词汇层面lexical的意义,而且要考虑它们的直接上下文immediate和整个句子结构sentence structure。
因此,人们提出了大量基于特征numerous feature和内核kernal-based的方法也就不足为奇了,其中许多方法都依赖于一个成熟的NLP堆栈stack,包括POS标记、形态分析morphological analysis、依赖解析dependency parsing,偶尔还有语义分析semantic analysis,以及捕捉词法lexical和语义特征semantic feature的知识资源。近年来,我们已经看到了深入架构的发展,它能够学习相关的表示和特性,而不需要大量的手工特性工程或使用外部资源。大量的卷积神经网络(CNN)、递归神经网络(RNN)等神经结构被提出用于关系分类(Zeng et al.2014; dos Santos et al., 2015; Xu et al., 2015b)尽管如此,这些模型常常不能识别关键线索,其中许多模型仍然需要外部依赖解析器。
提出了一个新的CNN架构,解决了以前方法的一些缺点。我们的主要贡献如下:
1. 我们的CNN架构依赖于一种新颖的多级注意机制来捕获特定于实体的注意entity-specific attention(在输入层针对于target entities的attention)和特定于关系池化的注意relation-specific pooling attention(针对于target relations的attention)。尽管输入句子的结构heterogeneous structure各不相同,但这使它能够检测到更微妙的线索,使它能够自动学习哪些部分与给定的分类相关。
2.我们介绍了一种新的pair-wise margin-based objective function并证明优于标准损失函数standrad loss functions。
3.我们在SemEval 2010 Task 8数据集上获得了最新的关系分类结果,F1得分为88.0%,优于依赖于更丰富先验知识的方法。
These kernels methods thus all depend either on carefully handcrafted features, often chosen on a trial-and-error basis(通常是在试错的基础上选择的), or on elaborately designed kernels, which in turn are often derived from other pre-trained NLP tools or lexical and semantic resources. Although such approaches can benefit from the external NLP tools to discover the discrete structure of a sentence, syntactic parsing is error-prone and relying on its success may also impede performance 但句法分析是容易出错的,依赖于它的成功也可能会阻碍性能(Bach and Badaskar, 2007). Further downsides include their limited lexical generalization abilities for unseen words and their lack of robustness when applied to new domains, genres,or languages.
理想情况下,我们需要一个简单而有效的体系结构,它不需要依赖解析或训练多个模型。我们在第4节的实验表明,我们确实可以做到这一点,同时也获得了F1得分方面的实质性改进。
3 The Proposed Model
由于唯一的输入是一个带有两个标记的原始句子,因此获得做出准确预测所需的所有词汇、语义和句法线索是非常重要的。(作者出发点太理想了,不借助除实体标记以外的其他外部特征)模型图如图:
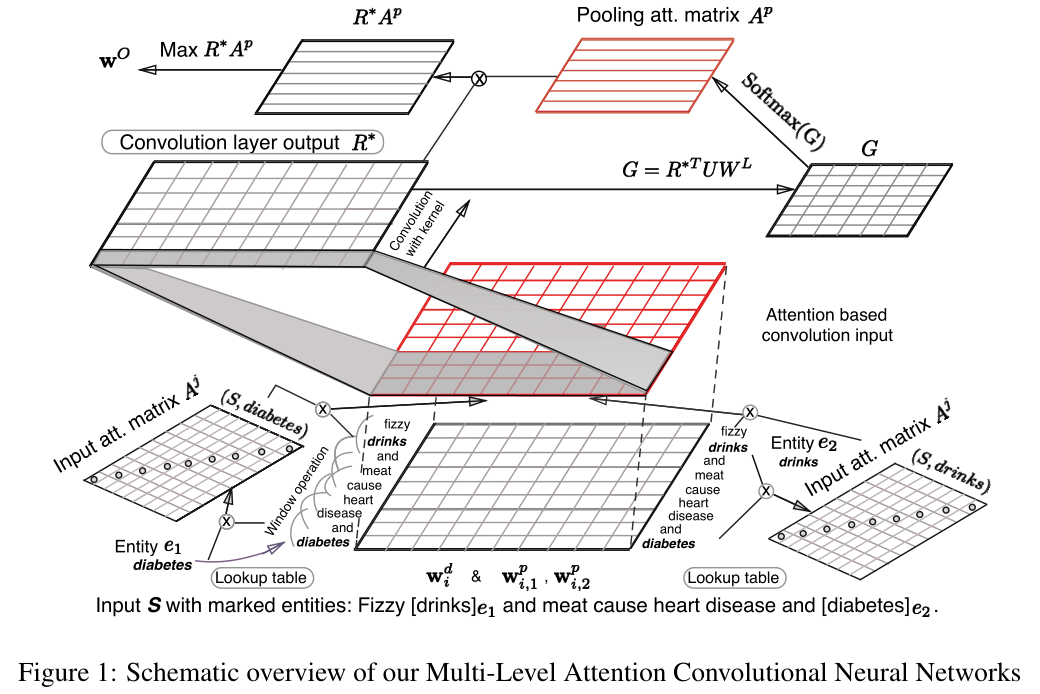
配合作者给的符号说明表食用:
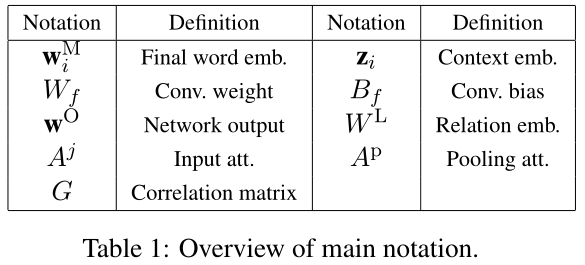
输入句子首先使用词向量表示进行编码,利用上下文context和位置编码来更好地捕捉词序。输入层attention基于对角线矩阵diagonal matrices来捕获单词相对于目标实体的相关性relevance。然后,对结果输出矩阵应用卷积操作convolution operation,以捕获上下文信息,例如relevant n-grams,然后跟一个最大池化max-pooling。第二个attention pooling layer用于根据注意池化矩阵attention pooling matrix从输出中确定最有用的卷积特征用于关系分类。
3.1 Classification Objective
关系分类体系结构的自顶向下设计考虑开始。句子$S$,network最终输出$\vec{w}^O$,对于每个输出关系output relation$y∈Y$,我们都假设有一个相应的network自动学习的output embedding$W_y^L$对应,设计了一个新的距离函数$\delta_{\theta}(S)$来测量预测network输出$w^O$与一个候选关系y的接近度:
$\delta_{\theta}(S,y)=||\frac{\vec{w}^O}{\vec{w}^O}-W_y^L||$
相减前均使用$L_2$正则化(注意$W_y^L$已经normalized),再次距离函数的基础上,设计了a margin-based pairwise loss function L:
$L=[\delta_{\theta}(S,y)+(1-\delta_{\theta}(S,\hat{y}^-))]+\beta||\theta||^2=[1+||\frac{\vec{w}^O}{\vec{w}^O}-W_y^L||-||\frac{\vec{w}^O}{\vec{w}^O}-W_{\hat{y}^-}^L||]+\beta||\theta||^2$
1是margin,$\beta$是一个参数,$\delta_{\theta}(S,y)$是预测标签嵌入predicted label embedding$W^L$与真实值标签ground truth label$y$之间的距离,$\delta_{\theta}(S,\hat{y}^-)$指的是$\vec{w}^O$与不正确关系标签$\hat{y}^-$之间的距离。$\hat{y}^-$被选为所有错误类中得分最高的一个(TMD makedown语法y^{'}要加上大括号才能识别'):
$\hat{y}^-=argmax\delta(S,y^{'})$,$y^{'}∈Y,y^{'}\not=y$
这种基于边际的目标具有很强的可解释性和有效性。我们最小化预测输出与ground-truth标签之间的差距,同时最大化与所选错误类之间的距离。$\delta_{\theta}(S,y)$被鼓励减小,$\delta_{\theta}(S,\hat{y}^-)$被鼓励增加。
3.2 Input Representation
给定句子$S=(w_1,w_2,...,w_n)$带有marked entity mentions $e_1(w_p)$和$e_2(w_t)$,$(p,t∈[1,n],p\not=t)$,我们首先将每个单词转化为一个实值向量real-valued vector来提供词汇语义特征exical-semantic features。给定一个词嵌入矩阵word embedding matrix $W_v$,维度$d_w*|V|$,$V$是input vocabulary,$d_w$是词汇向量维数(超参数),我们将每个$w_i$映射为一个列向量$\vec{w}_i^d∈R^{d_w}$。
为了进一步捕获与目标实体的关系信息,我们采用了单词位置嵌入(WPE)来反映第i个单词与两个标记实体提及的相对距离(Zeng et al., 2014),对于图中的句子单词“and”与实体$e_1$“drinks”和$e_2$“diabetes”的相对距离分别为−1和6。每个相对距离映射到一个随机初始化的位置向量$R^{d_p}$,$d_p$是超参数。【这里的意思是每个相对距离的数字都有对应的embedding,不过需要模型自己更新】对于给定的词$i$,我们得到两个位置向量$w_{i,1}^P$和$w_{i,2}^P$,分别对应着实体$e_1$和$e_2$。第$i$个单词的embedding表示为$w_i^M=[(w_i^d)^T,(w_{i,1}^P)^T,(w_{i,2}^P)^T]$。
使用大小为k的滑动窗口,以第$i$个单词为中心,我们连续编码k个单词成一个向量$z_i∈R^{(d_w+2d_p)k}$来结合上下文信息incorporate contextual information:
$z_i=[(w_{i-(k-1)/2}^M)^T,...,(w_{i+(k-1)/2}^M)^T]^T$
额外的填充标记在输入的开始和结束处重复多次以获得良好的定义An extra padding token is repeated multiple times for well-definedness at the beginning and end of the put.
3.3 Input Attention Mechanism
虽然基于位置的编码是有用的,但我们推测它们不足以完全捕获特定单词与目标实体的关系以及它们可能对目标关系产生的影响。我们设计了我们的模型,以便自动识别输入句子中与关系分类相关的部分。
注意机制已成功地应用于机器翻译等seqence-to-sequence学习任务,到目前为止,这些机制通常被用于允许输入和输出序列的对齐alignment。例如机器翻译中的源句子和目标句子,或在句子计算相似度sentence similarity scoring和问答中两个输入句子之间的对齐。
在我们的工作中,我们将注意力建模的思想应用到一种完全不同的场景中,这种场景涉及到异构对象heterogeneous objects,即一个句子和两个实体。基于此,我们试图让我们的模型能够确定句子的哪些部分对两个感兴趣的实体最有影响。考虑到在一个包含多个从句的长句中,可能只有一个动词或名词可能与给定的目标实体存在相关关系。如图2所示,输入表示层与对角注意矩阵和卷积输入合成结合使用the input representation layer is used in conjunction with diagonal attention matrices and convolutional input composition.。
Contextual Relevance Matrices 上下文\语境关联矩阵
如图1,其中非实体词“cause”在确定关系时具有特殊意义。幸运的是,我们可以利用“cause”和“diabetes糖尿病”这两个词之间有着显著的联系,而且在语料库共现方面in terms of corpus cooccurrences也是如此。我们引入两个对角线注意矩阵diagonal attention matrices$A^j$,$A_{i,i}^j=f(e_j,w_i)$来描述实体$e_j$和单词$w_i$之间的上下文关联和连接强度contextual correlations and connections。评分函数scoring function$f$被计算为单词$w_i$和实体$e_j$的各自嵌入respective embeddings之间的内积the inner product,并被参数化到network中,并在训练过程中更新。给定一个矩阵$A^j$,我们定义:
$a_i^j=\frac{exp(A_{i,i}^j)}{\sum_{i^{'}=1}^nexp(A_{i^{'},i^{'}}^j)}$
量化quantify第$i$个单词相对于第$j$个实体($j∈\{1,2\}$)的相对关联度relative degree of relevance。
Input Attention Composition 输入注意组成
接下来,我们将两个相关因子relevance factors$\alpha_i^1$和$\alpha_i^1$通过简单的平均来模拟他们对于实别关系的共同影响joint impact。
$r_i=z_i\frac{\alpha_i^1+\alpha_i^2}{2}$
除了这个默认选择之外,我们还评估了另外两个变体。变体1(Variant-1)将单词向量连接为:
$r_i=[(z_i\alpha_i^1)^T,(z_i\alpha_i^2)^T]^T$
来为这个特定的单词获取一个信息丰富的输入注意成分component,该成分包含与实体1和实体2的关系相关性relation relevance。
变体2将关系解释为两个实体之间的映射,并将两个实体特定的entity-specific权重组合为:
$r_i=z_i\frac{\alpha_i^1-\alpha_i^2}{2}$
来捕捉它们之间的关系。
基于这些$r_i$,输入注意力分量component的最终输出是矩阵$R=[r_1,r_2,...,r_n]$,其中$n$为句子长度
3.4 Convolutional Max-Pooling with Secondary Attention 带有注意力的卷积最大池化
上述操作之后,在此之后,我们将卷积maxpooling与另一个sencondary注意模型结合起来,从上一层的输出矩阵$R$中提取更抽象的高级特征。
Convolution Layer
卷积层可以学习识别三元文法tirgrams之类的短语,考虑到我们新生成的基于注意力的输入$R$,我们对应地应用a filter大小为$d_c$,相应地权重矩阵$W_f$大小为$d^c*k(d_w+2d^P)$然后我们添加一个线性偏差bias$B_f$,然后跟一个非线性双曲正切变换,来表示特征:
$R^{*}=tanh(W_fR+B_f)$
Attention-Based Pooling
不采用常规的pooling,我们依靠一个基于注意力的池策略来确定在$R^{*}$中各个窗口的重要性,这些窗口由卷积核编码as encoded by the convolutional kernel。其中一些窗口可以表示输入中有意义的n-grams。这里的目标是选择在第3.1节中与我们的objective相关的$R^{*}$部分The goal here is to select those parts of R∗that are relevant with respect to our objective from Section 3.1,这本质上是call for一个关系编码过程,而忽略与这个过程无关的句子部分。
我们首先创建一个相关建模矩阵G,该矩阵捕获句子中的卷积上下文窗口与前面第3.1节中介绍的关系类embedding$W^L$之间的相关联系pertinent connections:
$G={R^{*}}^TUW^L$
$U$是一个权重矩阵,由network学习得到。
然后采用$softmax$函数对该相关建模矩阵G进行处理,得到注意池矩阵attention pooling matrix$A^P$:
$A_{i,j}^P=\frac{exp(G_{i,j})}{\sum_{i^{'}=1}^nexp(G_{i^{'},j})}$
$G_{i,j}$是$G$的第$(i,j)$项,$A_{i,j}^P$是$A^P$的第$(i,j)$项。
最后,我们将该注意池矩阵与卷积输出$R^{*}$相乘,以突出显示重要的单个短语级组件individual phrase-level components,并应用max运算选择对于给定的输出维度最显著的一个,输出$w^O$如下:
$w_i^O=\max_j(R^{*}A^P)_{i,j}$
$w_i^O$是$w^O$中第i个条目entry,$(R^{*}A^P)_{i,j}$是$R^{*}A^P$中第$(i,j)$项。
3.5 Training Procedure
loss函数中的参数使用SGD更新,$\lambda$,$\lambda_1$是学习率,$\beta$是上方loss函数中的(公式2):
$\theta^{'}=\theta+\lambda\frac{d(\sum_{i=1}^{|S|}[\delta_{\theta}(S_i,y)+(1-\delta_{\theta}(S_i,\hat{y}_i^-))])}{d\theta}+\lambda_1\frac{d(\beta||\theta||^2)}{d\theta}$
4 Experiments
4.1 Experimental Setup
Dataset and Metric
我们在常用的SemEval-2010 Task 8数据集(Hendrickx et al., 2010)上进行实验,该数据集包含10,717个句子,用于9种标注关系类型,以及额外的“Other”类型。九种类型是:Cause-Effect, Component-Whole, Content-Container, Entity-Destination, Entity-Origin, Instrument-Agency, Member-Collection, Message-Topic, and ProductProducer,而关系类型“Other”表示句子中表达的关系不在这九种类型之中。但是,对于上述的每一种关系类型,这两个实体也可以以相反的顺序出现,这意味着这句话需要被视为表达了不同的关系,即各自的相反关系。所以$|Y|$总数可以认为是19。SemEval-2010 Task 8数据集由8000个示例的训练集,以及包含其余示例的测试集test组成。我们使用官方评分器official scorer对九个关系对(不包括other关系对)的Macro-F1得分来评估模型。
Settings
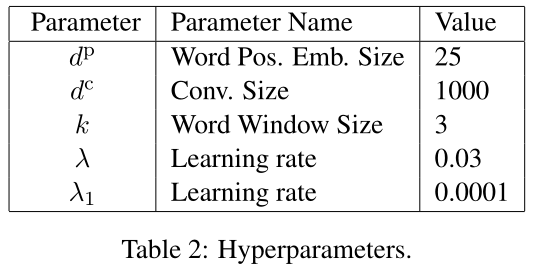
我们使用word2vec skip-gram模型((Mikolov et al., 2013a)学习维基百科上的初始单词表示。其他矩阵用高斯分布的随机值初始化。我们在训练数据上应用交叉验证程序cross-validation procedure来选择合适的超参数。这个过程生成的选择在表2中给出:
4.2 Experimental Results
实验结果:
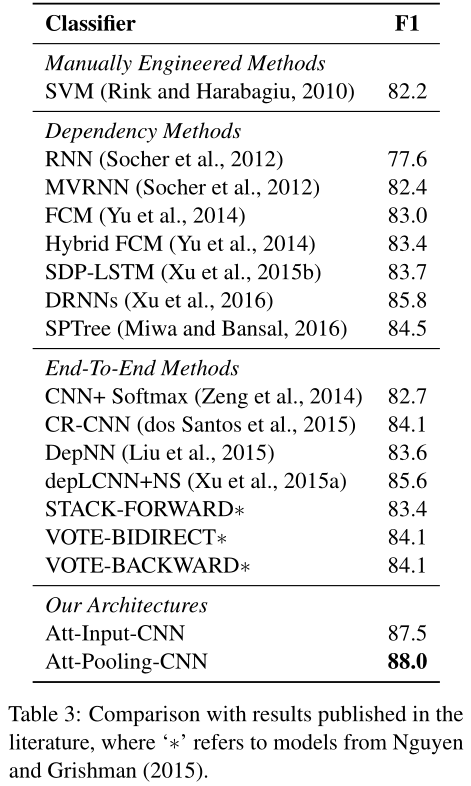
Att-Input-CNN,只依赖于输入层的原始注意,在卷积层之后执行标准的max-pooling来生成网络输出$w^O$,其中也用了新的目标函数。通过Att-input-CNN,我们获得了87.5%的F1分数,因此不仅超过了SemEval任务的最初赢家,基于支持向量机的方法(82.2%),而且还超过了众所周知的CR-CNN模型(84.1%),相对改善了4.04%,以及新发布的DRNNs(85.8%),相对改善了2.0%,尽管后一种方法依赖于Stanford解析器来获取依赖关系解析信息。
表4提供了由等式给出的模型的两个变体的实验结果。第3.3节中的等式(7)(8)。我们的主模型优于此数据集上的其他变体,尽管这些变体在应用于其他任务时可能仍然有用。为了更好地量化模型中不同组成部分的贡献,我们还进行了烧蚀研究ablation study,评估了几个简化模型。

最后一种不使用我们提出的新loss,使用基于内积的regular目标函数,$s=r·w$,$r$为一个句子表示a sentence representation,$w$关系类嵌入relation calss embedding。
4.3 Detailed Analysis
Primary Attention
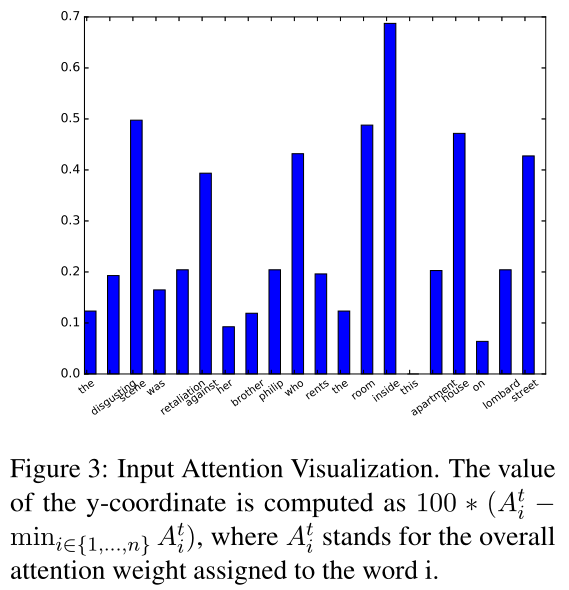
可以看出来,attention的表现确实是在重要的词上有更好的权重。
Most Significant Features for Relations
表5列出了每个关系类$y$的排名靠前的trigrams,由它们对确定关系分类的分数的贡献排名。
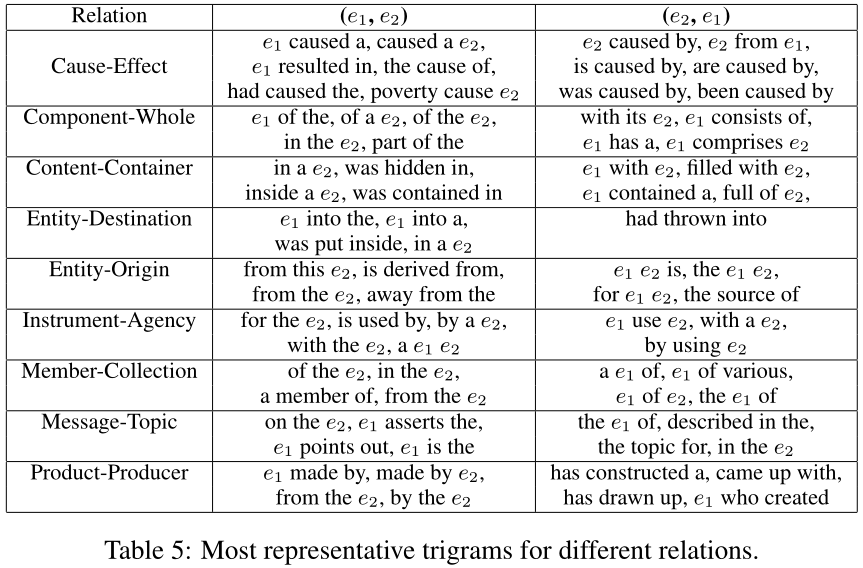
根据三元组对句子关系分类的贡献度进行排序后发现,排在前面的都是一些典型的“固定搭配”。
Error Analysis
1.语义隐式地表达关系分类会有错误,对于在训练集中未出现的,或者使用比喻性用法时,出错可能性比较大
2.推断实体之间关系的单词不够,一些上下文没有明显帮助的隐式关系,关系隐含在文本中,上下文并不是特别有用。在这种情况下,信息量更大的单词嵌入可能会有所帮助。
Convergence
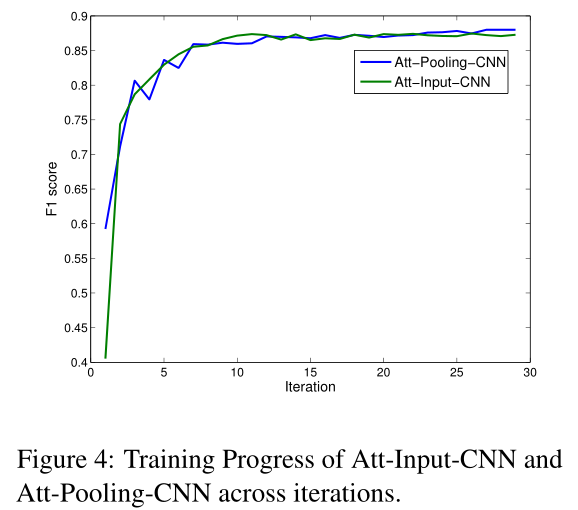
两个注意层的共同作用会产生更强的反向传播效应。一方面,这导致结果曲线出现跷跷板现象,但另一方面,它使我们能够获得更适合的模型,F1分数略高。
5 Conclusion
我们提出了一个CNN架构,它有一个新的目标和一种新的注意机制,应用于两个不同的层次。我们的结果表明,这个简单而有效的模型能够超越以往的工作依赖于更丰富的先验知识的形式,结构化模型和自然语言处理资源。我们期望这种体系结构在关系分类这一特定任务之外也能引起人们的兴趣,我们打算在未来的工作中对此进行探索。
相关阅读:
公式理解:https://blog.csdn.net/weixin_43959953/article/details/105281056
论文阅读:https://blog.csdn.net/xg123321123/article/details/53163257
论文笔记:https://blog.csdn.net/LAW_130625/article/details/77345925


 浙公网安备 33010602011771号
浙公网安备 33010602011771号