【论文阅读】End-to-End Relation Extraction using LSTMs on Sequences and Tree Structures[ACL2016]
论文地址:https://arxiv.org/pdf/1601.00770.pdf
代码地址(TensorFlow):https://github.com/Sshanu/Relation-Classification-using-Bidirectional-LSTM-Tree
这篇论文应该算是利用神经网络进行实体和关系联合抽取的开山鼻祖。
Abstarct
我们提出了一种新的端到端神经模型来提取实体和实体之间的关系。我们基于递归神经网络的模型通过在双向顺序LSTM-RNNs上叠加双向树结构LSTM-RNNs来捕获单词序列和依赖树子结构信息。这使得我们的模型能够在一个模型中用共享参数联合表示实体和关系。我们进一步鼓励在训练期间检测实体,并通过实体预训练和计划抽样在关系提取中使用实体信息。We further encourage detection of entities during training and use of entity information in relation extraction via entity pretraining and scheduled sampling. 我们的模型改进了现有的基于特征的端到端关系提取模型,在ACE2005和ACE2004上,F1score的相对误差分别降低了12.1%和5.7%。我们还表明,基于LSTM-RNN的模型在名词关系分类(SemEval-2010 task8)方面优于基于CNN的最新模型(F1分数)。最后,我们对几个模型部件进行了广泛的烧蚀分析。
1 Introduction
实体和关系的(联合)建模对于高性能非常重要, 因为关系与实体信息密切相关。
例如,要了解Toefting和Bolton中有一个Organization Affiliation(ORG-AFF)关系(Toefting transferred to Bolton),Toefting和Bolton是个人和组织实体的实体信息是很重要的。这些实体的提取反过来又受到上下文单词trasferred to的鼓励,表示雇佣关系。以前的联合模型都采用基于特征的结构化学习。这种端到端关系提取任务的另一种方法是通过基于神经网络(NN)的模型采用自动特征学习。
我们能够通过基于更丰富的LSTM-RNN架构(包含互补的语言结构incorporate complementary linguistic structures)的实体和关系的端到端建模来实现对最先进模型的改进。
已知词序和树结构是提取关系的互补信息。例如,在句子“This is ... ”, one U.S. source said中,单词之间的依赖性不足以预测source和U.S.之间存在ORG-AFF关系。这个预测需要上下文。许多传统的基于特征的关系分类模型从序列和解析树中提取特征(Zhouetal,2005)。然而,以前的基于RNN的模型只关注其中一种语言结构(Socher et al.,2012)。
我们提出了一种新的端到端模型来提取单词序列和依赖树结构上实体之间的关系。我们的模型通过使用双向顺序(从左到右和从右到左)和双向树结构(自底向上和自顶向下)LSTM-RNNs,允许在单个模型中对实体和关系进行联合建模。我们的模型首先检测实体,然后使用一个增量解码的神经网络结构incrementally-decoded NN structure提取实体之间的关系,并使用实体和关系标签联合更新神经网络参数the NN parameters are jointly updated using both entity and relation labels。与传统的增量incremental端到端关系抽取模型不同,我们的模型进一步将两个增强功能到训练过程中incorporates two enhancements into training: 实体预训练,用于预训练实体模型和计划采样entity pretraining, which pretrains the entity model, and scheduled sampling,以一定的概率用黄金标签代替(不可靠的)预测标签which replaces (unreliable) predicted labels with gold labels in a certain probability。这些增强在训练的早期阶段缓解了低性能实体检测的问题,并且允许实体信息进一步帮助下游关系分类。
在端到端关系提取方面,我们改进了现有的基于特征的模型,F1得分的相对误差降低了12.1%(ACE2005)和5.7%(ACE2004)。在名词关系分类(SemEval-2010 task8)上,我们的模型在F1得分上优于最先进的CNN模型。最后,我们还对我们的各种模型组件进行了消融和比较,得出了关于不同RNN结构、输入依赖关系结构、不同解析模型、外部资源和联合学习设置的贡献和有效性的一些关键发现(正面和负面)。
2 Related Work
对树型结构的LSTM-RNNs的研究(Tai et al.,2015)从下到上确定了信息传播的方向,也不能像类型化依赖树那样处理任意数量的类型化子节点。此外,没有一种基于RNN的关系分类模型同时使用词序列和依赖树信息。我们提出了几个这样的新模型结构和训练设置,研究了同时使用双向顺序和双向树形LSTM-RNNs来联合捕获线性和依赖上下文,以端到端提取实体之间的关系。
对于实体间关系的端到端(联合)提取,现有的模型都是基于特征的系统(没有基于nn的模型)。在一些语料库上,结构化预测方法structured prediction methods是最先进的。我们提出了一种改进的、基于神经网络的端到端关系提取方法。
3 Model
我们用LSTM-RNN来设计我们的模型,它既表示单词序列又表示依赖树结构,并在这些RNNs上执行实体之间的关系的端到端提取。图1显示了模型的overview。
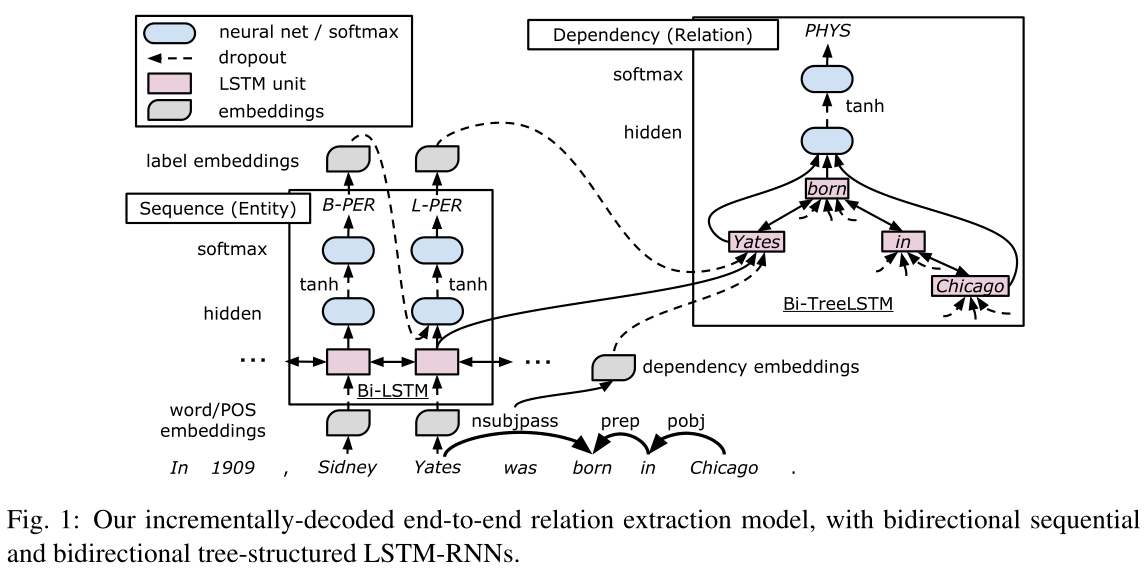
该模型主要由三个表示层组成:词嵌入层(embedding layer)、基于词序列的LSTM-RNN层(sequence layer)和基于依赖子树的LSTM-RNN层 (dependency layer)。解码过程中,我们在序列层上构建贪婪的、从左到右的实体检测,在依赖层上实现关系分类,每个基于LSTM-RNN的子树对应两个被检测实体之间的候选关系。在对整个模型结构进行解码后,我们通过时间反向传播(BPTT)同时更新参数(Werbos, 1990)。依赖层叠加在序列层上,使得嵌入层和序列层在实体检测和关系分类中都能共享,共享的参数同时受到实体和关系标签的影响。
3.1 Embedding Layer
首先将词(words),词性(part-of-speech POS),依存关系(dependency types),实体标签(entity labels)分别映射为distributed representations$v^{(w)}$,$ v^{(p)}$,$ v^{(d)}$和$ v^{(e)}$维度为$ n_w $、$ n_p $、$ n_d $和$n_e$。这些distributed represntations作为模型的训练参数的一部分。
3.2 Sequence Layer
序列层使用嵌入层的表示来表示线性序列中的单词。这一层表示句子上下文信息并维护实体,如图左下角所示。
我们用双向LSTM-RNNs表示句子中的词序列。第$t$个字的LSTM单元由一组$n_{l_s}$维向量组成:一个输入门$i_t$,一个遗忘门$f_t$,一个输出门$o_t$,一个存储单元$c_t$和一个隐藏状态$h_t$。单元接收一个n维输入向量$x_t$,之前的隐藏状态$h_{t−1}$,以及存储单元$c_{t−1}$,并使用以下公式计算新的向量:
$i_t=\sigma(W^{(i)}x_{t}+ U^{(i)}h_{t-1}+b^{(i)})$
$f_t=\sigma(W^{(f)}x_{t}+ U^{(f)}h_{t-1}+b^{(f)})$
$o_t=\sigma(W^{(o)}x_{t}+ U^{(o)}h_{t-1}+b^{(o)})$
$u_t=tanh (W^{(u)}x_{t}+ U^{(u)}h_{t-1}+b^{(u)})$
$c_t=i_t\bigodot u_t+f_t\bigodot c_{t-1}$
$h_t=o_t\bigodot tanh(c_t)$
$\sigma$表示logistic 函数,$\bigodot$表示element-wise 乘法,表示两个向量对应元素相乘的操作,$W$和$U$为权重矩阵,b为偏置向量。第$t$个单词的LSTM单元接收单词和POS embedding的拼接作为其输入向量 : $x_t=[v_t^{(w)};v_t^{(p)}]$,我们还将每个单词对应的两个方向LSTM单位的隐藏状态向量(表示为$\vec{h_t};\overleftarrow{h_t}$)连接起来作为其输出向量,
$s_t=[\vec{h_t};\overleftarrow{h_t}]$ 并将其传递给后续层。
3.3 Entity Detection
我们将实体检测视为一个序列标记任务。我们使用一种常用的编码方案BILOU (Begin, Inside, Last, Outside, Unit)为每个单词分配一个实体标签,其中每个实体标签表示实体类型和单词在实体中的位置。我们将B-PER和L-PER(分别表示person实体类型的开头和结尾单词)分配给Sidney Yates中的每个单词,以将该短语表示为PER (person)实体类型。我们在序列层上执行实体检测。我们使用一个两层的神经网络,包含一个$n_{h_e}$维隐藏层$h^{(e)}$和一个softmax输出层进行实体检测。
$h_t^{(e)}=tanh(W^{(e_h)}[s_t;v_{t-1}^{(e)}]+b^{(e_h)})$
$y_t=softmax(W^{(e_y)}h_t^{(e)}+b^{(e_y)})$
$W$为权重矩阵,b为偏置向量。
我们以一种贪婪的、从左到右的方式为单词分配实体标签。在解码过程中,我们使用一个单词的预测标签来预测下一个单词的标签,从而考虑标签相关性。上面的神经网络接收序列层对应的输出与上一时刻单词预测标签embedding的拼接。
3.4 Dependency Layer
【Dependency层用于描述依存树中一对目标词的关系,这一层主要关注这对目标词在依存树上的最短路径。文中采用了双向树结构的LSTM-RNN来抓住目标词对周围的依存结构,信息可以从根节点传到叶节点,也可从叶节点传到跟节点。对于需要利用页节点附近的argument节点的关系分类任务来说,双向信息传递可以取得更好的效果。Tai 2015也采用了tree-structural的LSTM-RNN,但他们的方法限定类型子节点的数目必须固定。
作者提出了tree-structural LSTM-RNN的变种,对于类型相同的子节点共享相同的权重$U_s$,并且允许子节点的数目是可变的。对于有$C(t)$子节点的LSTM单元,其定义如下:】
依赖层表示依赖树中两个目标词对(对应于关系分类中的关系候选词)之间的关系,并负责关系特定的表示,如图1的右上部分所示。这一层主要关注依赖树中一对目标词之间的最短路径(即,最小公共节点到两个目标词之间的路径)(i.e., the path between the least common node and the two target words),因为这些路径在关系分类中被证明是有效的(Xu et al,2015a)。例如,我们在图1的底部显示了Yates 和 Chicago之间的最短路径,这条路径很好地抓住了他们关系的关键短语,i.e., born in。
我们采用双向树形结构的LSTM-RNN(即自底向上和自顶向下),通过捕获目标词对周围的依赖结构来表示候选关系。这种双向结构不仅向每个节点传播来自叶子的信息,还向每个节点传播来自根的信息。这对于关系分类尤其重要,因为关系分类使用树的底部附近的参数节点,而我们的自顶向下的LSTM-RNN从树的顶部向这种近叶节点发送信息与标准自底向上LSTM RNN不同)。请注意,Tai et al (2015)提出的树型结构LSTM-RNNs的两种变体不能表示我们的目标结构,因为它有可变数量的typed children孩子节点:Child-Sum Tree-LSTM不处理类型,N元树假设有固定数量的孩子。因此,我们提出了一种新的树结构LSTM-RNN,它为同一类型的子对象共享权重矩阵$U$,并且允许孩子节点数目可变。对于这种变体,我们使用下列公式计算在有$C(t)$个子节点的第t个LSTM单元中的$n_{l_t}$维向量:
$i_t=\sigma(W^{(i)}x_t+\sum_{l∈C(t)}U_{m(l)}^{(i)}h_{tl}+b^{(i)})$
$ f_{tk}=\sigma(W^{(f)}x_t+\sum_{l∈C(t)}U_{m(k)m(l)}^{(f)}h_{tl}+b^{(f)})$
$ o_t=\sigma(W^{(o)}x_t+\sum_{l∈C(t)}U_{m(l)}^{(o)}h_{tl}+b^{(o)})$
$ u_t=tanh (W^{(u)}x_t+\sum_{l∈C(t)}U_{m(l)}^{(u)}h_{tl}+b^{(u)})$
$c_t=i_t\bigodot u_t+\sum_{l∈C(t)}f_{tl}\bigodot c_{tl}$
$h_t=o_t\bigodot tanh(c_t)$
$m(·)$是一个类型映射函数
为了研究合适的结构来表示两个目标词对之间的关系,我们实验了三种结构选项。
我们主要采用最短路径结构(SPTree),它捕获目标词对之间的核心依赖路径,广泛应用于关系分类模型,我们还尝试了另外两种依赖结构:SubTree和FullTree。SubTree是目标词对的最低共同祖先下的子树。这为SPTree中的路径和词对提供了额外的修饰符信息。FullTree是完整的依赖树,这就抓住了整个句子的上下文。当我们为SPTree使用一种节点类型时,我们为SubTree和FullTree定义了两种节点类型,即,一种用于最短路径上的节点,另一种用于所有其他节点。我们使用类型映射函数m(·)来区分这两种节点类型。
【三种表示目标词对的结构:1)SPTree(最短路径结构);2)SubTree(最近公共祖先);3)Full-Tree(整棵依存树)
one node type:采用SPTree
two node types:采用subTree和SPTree】
3.5 Stacking Sequence and Dependency Layers
我们将依赖层(对应于关系候选层)堆叠在序列层之上,将单词序列和依赖树结构信息合并到输出中。第t个单词的依赖层LSTM单元接收作为输入$x_t=[s_t;v_t^{(d)};v_t^{(e)}]$。在序列层对应的hidden state 向量$s_t$,依赖类型embedding$v_t^{(d)}$( 表示对父类的依赖类型)[ 我们使用对父节点的依赖,因为子节点的数量是不同的。]和label embedding$v_t^{(e)}$( 对应于预测的实体标签)。
【其中$s_t$是sequence层的hidden state向量,$v_t^{(d)}$是dependency标签的embeding,$v_t^{(e)}$对应实体预测得到的标签。】
3.6 Relation Classification
在解码过程中,我们使用检测到的实体的最后一个单词的所有可能组合,即BILOU方案中带有L或U标签的单词,增量地构建候选关系。例如,在图1中,我们使用带有L-PER标签的Yates和带有U-LOC标签的Chicago来构建候选关系。对于每个候选关系,我们实现对应于候选关系中单词对p之间路径的依赖层$d_p$(如上所述),神经网络接收由依赖树层的输出构造的候选关系向量,并预测其关系标签。当检测到的实体错误或没有关系时,我们将一对视为负关系(negative relation)。我们通过类型和方向来表示关系标签,除了没有方向的负关系。
关系候选向量被构造为连接(concatenation)$d_p=[↑h_{pA};↓h_{p1};↓h_{p2}]$,其中$↑h_{pA}$为自底向上LSTM-RNN中最高LSTM单元的隐藏状态向量(表示目标词对p的最低共同祖先),$↓h_{p1}$、$↓h_{p2}$为自上而下LSTM-RNN中表示第一目标词和第二目标词的两个LSTM单元的隐藏状态向量[注意,目标单词的顺序与关系的方向相对应,而不是与句子中的位置相对应]。相应的箭头如图1所示
【1)对于两个带有L或U标签(BILOU schema)的词,可以构建一个候选的关系
2)NN为每一个候选关系预测一个关系标签,并带有方向(除了负关系外,negative relation)
候选关系是多个向量的连接$d_p=[↑h_{pA};↓h_{p1};↓h_{p2}]$, 其中$d_p$是在bottom-up LSTM-RNN中两个目标词对的最近公共祖先(选择top unit)的隐藏状态向量,$↓h_{p1}$和$↓h_{p2}$在top-down LSTM-RNN中两个目标词的隐藏状态向量。】
与实体检测类似,我们采用了两层神经网络,一层是$n_{h_r}$维隐层$h^{(r)}$,另一层是softmax输出层(权重矩阵$W$,偏差向量$b$)
$h_p^{(r)}=tanh(W^{(r_h)}d_p+b^{(r_h)})$
$y_p=softmax(W^{(r_y)}h_t^{(r)}+b^{(r_y)})$
我们将树结构的LSTM-RNNs叠加在序列LSTM-RNNs上,构造了关系分类的输入$d_p$,因此序列层对输入的贡献是间接的。此外,我们的模型使用词来表示实体,因此不能充分利用实体信息。为了缓解这些问题,我们直接将每个实体的隐藏状态向量的平均值从序列层连接到输入$d_p$来关系分类。
$d_p^{’}=[d_p;\frac{1}{|I_{p1}|}\sum_{i∈I_{p1}}s_i;\frac{1}{|I_{p2}|}\sum_{i∈I_{p2}}s_i]$ (Pair),$I_{p1}$,$I_{p2}$表示第一和第二实体中的单词索引集
此外,由于我们同时考虑了从左到右和从右到左的方向,所以我们在预测中为每个词对指定了两个标签。当预测的标签不一致时,我们选择积极和更自信的标签。
3.7 Training
我们使用梯度剪裁、参数平均和L2正则化(我们正则化权重W和U,而不是偏差项b)更新了BPTT和Adam(Kingma和Ba,2015)的模型参数,包括权重、偏差和嵌入。我们还将dropout(Srivastava et al.,2014)应用于嵌入层和最终隐藏层,用于实体检测和关系分类。
我们采用了两种增强方法,计划抽样和实体预训练scheduled sampling (Bengio et al., 2015) and entity pretraining,以缓解训练早期实体预测不可靠的问题,并鼓励从检测到的实体中建立正向关系实例。在计划抽样中,我们使用gold labels作为预测的概率$\epsilon_i$,如果gold labels是合法的,$\epsilon_i$取决于我在训练期间的历代次数$i$。对于$\epsilon_i$,我们选择the inverse sigmoid decay $\epsilon_i=k/(k+exp(i/k))$, 其中k(≥1)是一个超参数,它调整我们使用gold lables作为预测的频率。实体预训练的灵感来自(Pentina et al.,2015),在训练整个模型参数之前,我们使用训练数据对实体检测模型进行预训练。
模型训练采用了以下优化方法:
1)BPTT
2)Adam(Kingma & Ba,2015)with gradient clipping
3)parameter averaging
4)L2 regularization
5)embeding层和final hidden层之前都有dropout
6)scheduled sampling(Bengio 2015)
7)entity pretrain
4 Results and Discussion
4.1 Data and Task Settings
我们在三个数据集上进行评估:ACE05和ACE04用于端到端关系提取,SemEval2010 task 8用于关系分类。我们将前两个数据集作为主要目标,并利用后一个数据集对模型的关系分类部分进行深入分析和剔除。
ACE05定义了7种粗粒度实体类型和6种粗粒度实体间关系类型。我们使用与Li和Ji(2014)相同的数据分割、预处理和任务设置。为了更好地解释模型的性能,我们报告了实体和关系提取的主要微观F1分数以及微观精度和召回率。当一个实体的类型和头部区域正确时when its type and the region of its head are correct,我们将其视为正确的。当关系的类型和参数实体正确时when its type and argument entities are correct,我们将其视为正确的;因此,我们将错误实体上的所有非负性关系视为假阳性false positives。
ACE04定义了与ACE05相同的7种粗粒度实体类型(Doddington et al,2004),但定义了7种粗粒度关系类型。我们遵循Chan and Roth(2011)和Li and Ji(2014)的交叉验证设置,以及ACE05的预处理和评估指标。
SemEval-2010 task 8定义了9种名词之间的关系类型,当两个名词没有这些关系时,定义了第十种类型(Hendrickx et al.,2010)。我们将另一种类型视为负关系类型,不考虑方向。数据集由8000个训练句子和2717个测试句子组成,每个句子都用两个给定名词之间的关系进行标注。我们从训练集中随机抽取了800个句子作为我们的发展集。我们遵循官方的任务设置,并报告了9种关系类型的官方宏平均F1分数(macro-F1)。
1)实验采用了ACE04和ACE05两个数据集用于end-to-end关系抽取,每个数据集包含7个实体类型和6~7个关系类型。
2)采用SemEval-2010 Task 8数据集做关系分类,该数据集包含9类名词之间的关系,8000个句子用作训练,2717个句子用作测试。
4.2 Experimental Settings
我们使用cnn库实现了我们的模型https://github.com/clab/dynet
我们使用斯坦福神经依赖分析器分析文本 http://nlp.stanford.edu/software/stanford-corenlp-full-2015-04-20.zip
在初步调整的基础上,我们将嵌入维数$n_w$: 200,$n_p$、$n_d$、$n_e$: 25和中间层($n_{l_s}$、$n_{lt}$ of LSTM-RNNs和$n_{h_e}$、$n_{h_r}$ of 隐藏层)的维数固定为100。我们通过在维基百科上训练的word2vec (Mikolov et al.,2013)初始化词向量。 随机初始化所有其他参数。我们使用开发集development sets对ACE05和SemEval2010 task 8的超参数进行了调整,以获得较高的初级(微观和宏观)f1分数。 对于ACE04,我们直接采用了ACE05的最佳参数。超参数设置在补充材料中显示。对于SemEval-2010 task 8,我们还忽略了实体检测和标签嵌入entity detection and label embeddings,因为只有目标名词被标注,而且任务没有定义实体类型。我们的统计显著性结果是基于近似随机化(AR)检验(Noreen, 1989)。
4.3 End-to-end Relation Extraction Results
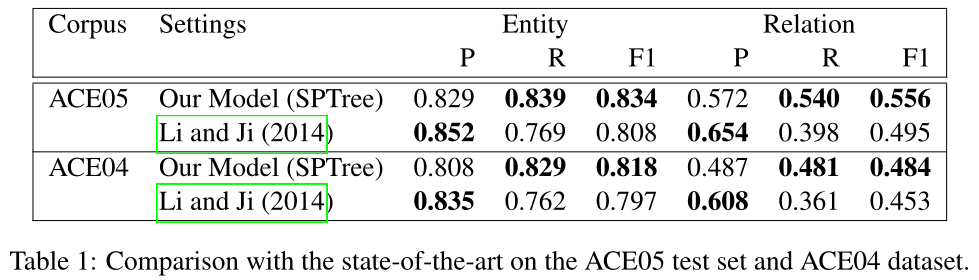
为了分析我们的端到端关系提取模型的各个组成部分的贡献和影响,我们在ACE05开发集上进行了消融试验(表2)。在没有scheduled sampling的情况下,系统的性能稍有下降,在去除实体预训练或两者同时去除的情况下,系统的性能明显下降(p<0.05)。这是合理的,因为模型只能在找到两个实体时创建关系实例,如果没有这些增强功能,找到某些关系可能为时已晚。删除标签嵌入label embeddings不会影响实体检测性能,但会降低关系分类的召回率。这表明实体标签信息有助于检测关系。
我们还展示了在没有共享参数(即嵌入层和序列层)的情况下检测实体和关系(共享参数)的性能;我们首先训练实体检测模型,使用该模型检测实体,并使用检测到的实体构建单独的关系提取模型,即没有实体检测。由于两个单独的模型是按顺序训练的,因此可以将此设置视为管道模型。在没有共享参数的情况下,实体检测和关系分类的性能都略有下降,但差异不显著。当我们去掉所有的增强,即scheduled sampling、实体预训练、标签嵌入和共享参数时,性能明显低于SPTree(p<0.01),表明这些增强为端到端关系提取提供了互补的好处。
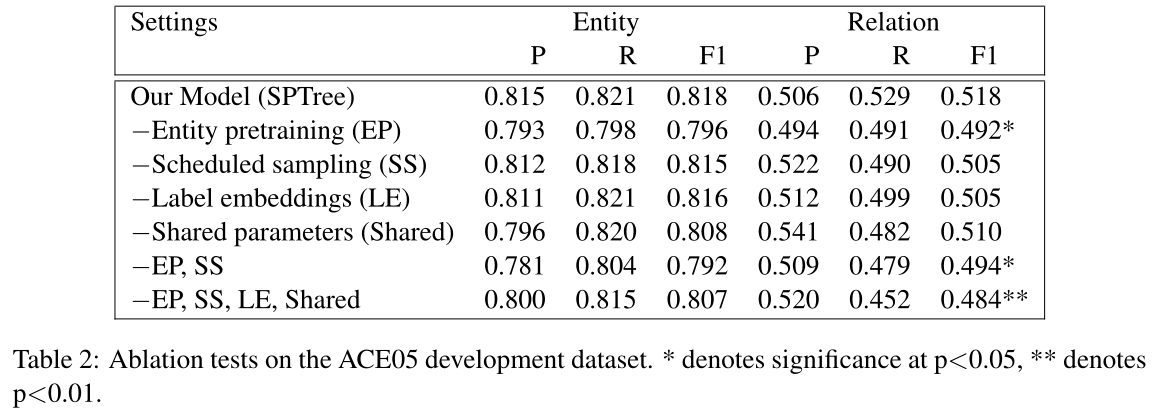
接下来,我们在表3中展示了不同LSTM-RNN结构的性能。我们首先比较了树结构LSTM-RNN的三种输入依赖结构(SPTree、SubTree、FullTree)。当我们区分最短路径中的节点和其他节点时,这三种结构的性能几乎相同,但是当我们不区分它们时,最短路径之外的信息,例如FullTree(-SP)显著地影响表现(p<0.05)。然后,我们将我们的树结构LSTM-RNN(SPTree)与Tai et al(2015)的最短路径上的子和树结构LSTM-RNN进行比较。Child-Sum的性能比我们的SPTree模型差,但是没有上面那样大的下降幅度。这可能是因为模型中的差异仅出现在具有多个children的节点上,并且除最小公共节点the least common node外的所有节点都具有一个子节点(children)。
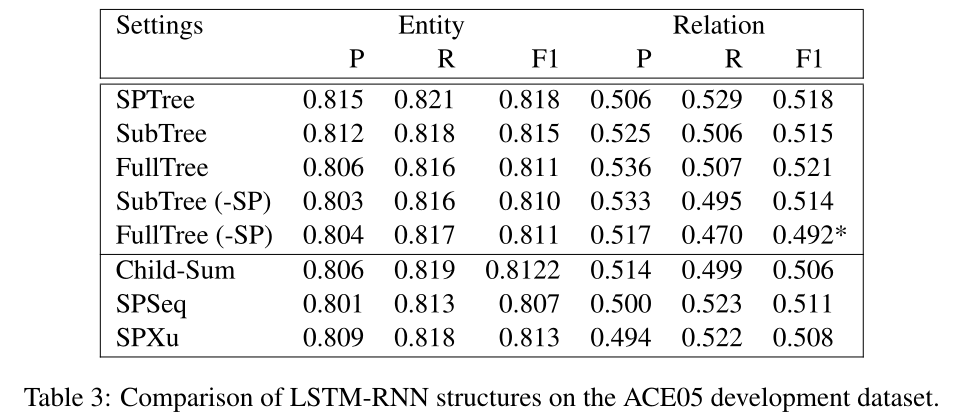
最后,我们使用最短路径(表最后两行)显示了两种基于序列的LSTM-RNNs的对应结果。SPSeq是一个基于最短路径的双向LSTM-RNN。LSTM单元从序列层接收输入,并连接周围依赖类型和方向的嵌入。我们将两个RNNs的输出连接到关系候选项。SPXu是我们对Xu et al. (2015b)提出的最短路径LSTM-RNN进行自适应,以匹配我们的基于序列层的模型[这与原来的不同之处在于,我们使用序列层,并为输入连接嵌入,而原来的LSTM-RNN为不同的输入准备单独的LSTM-RNN,并连接它们的输出。]。它有两个LSTM-RNN用于最短路径的左子路径和右子路径。我们首先为这两个RNNs计算LSTM单元的最大池化max pooling,然后连接关系候选者的池的输出。通过与这些基于序列的LSTM-RNN的比较,可以看出,树形结构的LSTM-RNN在最短路径表示方面与基于序列的LSTM-RNN具有相似性。
总的来说,表3中LSTM-RNN结构的性能比较表明,在端到端关系提取中,选择合适的输入树结构表示(例如最短路径)比选择该输入的LSTM-RNN结构(例如顺序的还是基于树的)更为重要。
4.4 Relation Classification Analysis Results
为了单独深入分析关系分类部分,例如比较不同的LSTM结构、隐含层和输入信息等体系结构组件以及分类任务设置,我们使用了SemEval-2010 task 8。该数据集通常用于评估用于关系分类的神经网络模型,它只标注与关系相关的名称(不像ACE数据集),因此我们可以清晰地聚焦于关系分类部分。
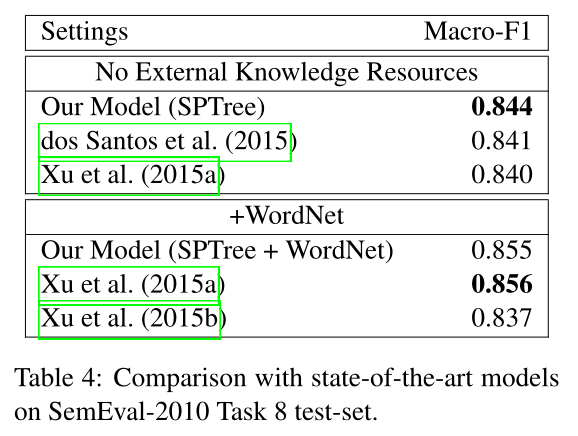
我们首先在表4中报告官方测试集的结果。与之前最好的LSTM-RNN模型不同,我们的新LSTM-RNN模型在这项任务上与最先进的基于CNN的模型(有外部源或没有外部资源,即WordNet)都具有相似性(Xu et al., 2015b)。
其次,我们在表5中比较了不同的LSTM-RNN结构。对于三种输入依赖结构(SPTree, SubTree, FullTree),无论我们是否将最短路径中的节点与其他节点进行区分,FullTree的性能都明显低于其他结构,这暗示了最短路径之外的信息对性能的显著影响(p<0.05)。我们还比较了树结构的LSTM-RNN (SPTree)与基于序列的LSTM-RNN (SPSeq和SPXu)和树结构的LSTM-RNN (Child-Sum)。所有这些LSTM-RNNs的性能都比我们的SP-Tree模型稍差,但差异很小。
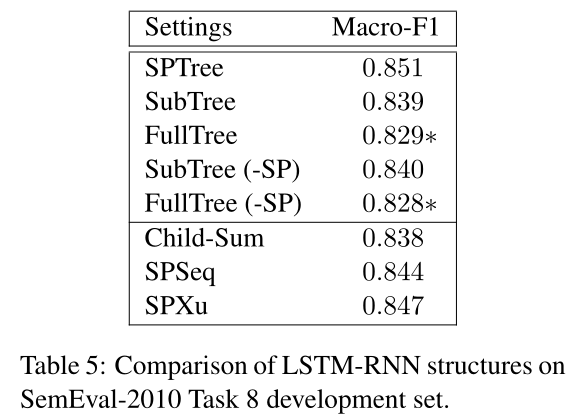
总体而言,对于关系分类,尽管表5中LSTM-RNN结构的性能比较在FullTree上产生的结果与表3中ACE05上的结果不同,趋势仍然认为,选择适当的输入树结构表示比选择输入的LSTM-RNN结构更重要。
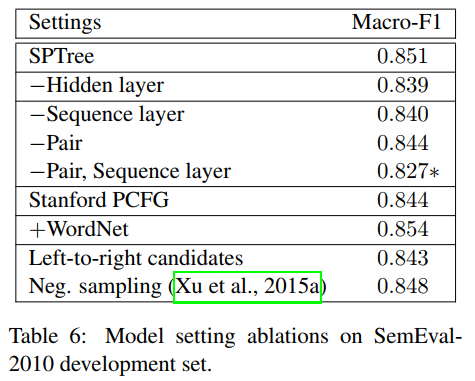
最后,表6总结了几个模型组件和训练设置对SemEval关系分类的贡献。我们首先通过将LSTM-RNN层直接连接到softmax层来去除隐藏层,发现这种性能略有下降,但差别很小。然后我们跳过序列层,直接使用word和POS嵌入作为依赖层。从序列层(−Pair)中删除序列层或实体相关信息会略微降低性能,并且在删除两者后,性能会显著下降(p<0.05)。这表明序列层是必要的,但名词的最后一个词几乎足以表达这个任务中的关系。
当我们用斯坦福词汇化PCFG解析器(Stanford-PCFG)替换Stanford神经依赖解析器时,性能略有下降,但差异很小。这表明解析模型的选择并不重要。我们还包括WordNet,这稍微提高了性能(+WordNet),但是差别很小。最后,对于关系候选者的生成,仅生成从左到右的候选者略微降低了性能,但差异很小,因此从右到左候选者的创建并不重要。将反向关系候选者视为负实例(负采样)也与我们模型中的其他生成方法具有相似的性能(与Xu et al(2015a)不同,Xu et al(2015a)显示出仅生成从左到右候选者的显著改进)。
5 Conclusion
我们提出了一种新的端到端关系抽取模型,该模型利用双向顺序和双向树结构的LSTM-RNNs来表示单词序列和依赖树结构。这使得我们能够在一个模型中表示实体和关系,在端到端关系提取(ACE04和ACE05)上实现了对最先进的基于特征的系统的改进,并显示出与最近基于名义关系分类的最先进CNN模型(SemEval-2010 task 8)相当的性能。
我们的评估和消融导致了三个关键的发现。首先,单词序列和依赖树结构的使用都是有效的。第二,使用共享参数进行训练可以提高关系提取的准确性,尤其是在使用实体预训练、定时采样和标签嵌入时entity pretraining, scheduled sampling, and label embeddings。最后,在关系分类中被广泛应用的最短路径也适用于表示神经LSTM模型中的树结构。
实验结果表明:1)词序和依存树的结构对关系抽取非常有用;2)共享实体发现的参数对于关系抽取是有效的,特别是加入了entity pretrain、scheduled sampling和label embeding等优化之后;3)常用于关系分类的“最短路径”结构在Tree-Structural LSTM-RNN的表示方面也非常有效。
实验结论和分析
1. 关系抽取(联合模型)
1)实验最终结果与现有的基于特征的方法相当,在recall和F1-score上更优,在precision上稍弱
2)分析了entity pretrain、schedule sampling、label embeding、和share parameter对模型性能的影响,实验结果表明entity pretrain对性能影响比较显著,主要是不加这个优化的话,entity的信息还没训练好,会对后面关系抽取有比较大的影响。
3)论文进一步分析了dependency层的LSTM-RNN的结构对关系抽取性能的影响。实验发现:选树结构和序列结构的差别不是特别大,树本身的结构对性能影响比较大,如SPTree(最短路径树)、SubTree(子树)、FullTree(整棵依存树)、SubTree-SP(不对最短路径做特殊考虑)和FullTree-SP(不对最短路径做特殊考虑)。
2. 关系分类
1)论文的方法与现有基于CNN的方法相当,比现有LSTM-RNN的方法要好
2)合理的树结构表示比LSTM-RNN的结构更重要
3)网络结构对模型的影响:
A.移除隐藏层没啥影响
B.溢出sequence层或实体相关信息无太大影响,但同时移除会有较大的性能下降,这说sequence层有必要,但实体最后一个词所表述的信息对关系分类也差不多足够了
C.dependency parser不是特别关键
D.加入WordNet的信息对性能有所帮助
E.生成关系候选(左-->右或右-->左),双向同时选对性能提升不大
F.把inverse关系的候选作为负样本能够有效提升性能
参考:
论文阅读笔记:https://zhuanlan.zhihu.com/p/26381714?from_voters_page=true
什么是 end-to-end 神经网络:https://www.zhihu.com/question/51435499
论文总结:https://blog.csdn.net/bobobe/article/details/82867239
论文阅读:https://zhuanlan.zhihu.com/p/22773196


 浙公网安备 33010602011771号
浙公网安备 33010602011771号