【代码精读】Context-Aware Representations for Knowledge Base Relation Extraction
这篇并不是我阅读的这篇文章的代码,https://www.cnblogs.com/Harukaze/p/14242000.html
而是在文档级关系抽取中使用Context-Aware机制的一个实例,代码如下:
1 class ContextAware(nn.Module): 2 def __init__(self, config): 3 super(ContextAware, self).__init__() 4 self.config = config 5 self.word_emb = nn.Embedding(config.data_word_vec.shape[0], config.data_word_vec.shape[1]) 6 self.word_emb.weight.data.copy_(torch.from_numpy(config.data_word_vec)) 7 self.word_emb.weight.requires_grad = False 8 self.ner_emb = nn.Embedding(7, config.entity_type_size, padding_idx=0) 9 self.coref_embed = nn.Embedding(config.max_length, config.coref_size, padding_idx=0) 10 hidden_size = 128 11 input_size = config.data_word_vec.shape[1] + config.coref_size + config.entity_type_size #+ char_hidden 12 self.rnn = EncoderLSTM(input_size, hidden_size, 1, True, True, 1 - config.keep_prob, False) 13 self.linear_re = nn.Linear(hidden_size * 2, hidden_size) 14 self.self_att = SelfAttention(hidden_size, 1.0) 15 self.bili = torch.nn.Bilinear(hidden_size+config.dis_size, hidden_size+config.dis_size, hidden_size) 16 self.dis_embed = nn.Embedding(20, config.dis_size, padding_idx=10) 17 self.linear_output = nn.Linear(hidden_size * 2, config.relation_num) 18 19 def forward(self, context_idxs, pos, context_ner, context_char_idxs, context_lens, h_mapping, t_mapping, relation_mask, dis_h_2_t, dis_t_2_h): 20 sent = torch.cat([self.word_emb(context_idxs), self.coref_embed(pos), self.ner_emb(context_ner)], dim=-1) 21 context_output = self.rnn(sent, context_lens) #(b,512,2*128) 22 context_output = torch.relu(self.linear_re(context_output)) #(b,512,2*128)->(b,512,128) 23 start_re_output = torch.matmul(h_mapping, context_output) #(b,1800,512)*(b,512,128)->(b,1800,128) 24 end_re_output = torch.matmul(t_mapping, context_output) #(b,1800,512)*(b,512,128)->(b,1800,128) 25 s_rep = torch.cat([start_re_output, self.dis_embed(dis_h_2_t)], dim=-1) #(b,1800,128+20) 26 t_rep = torch.cat([end_re_output, self.dis_embed(dis_t_2_h)], dim=-1) #(b,1800,128+20) 27 re_rep = self.bili(s_rep, t_rep) #(b,1800,128) 28 29 re_rep = self.self_att(re_rep, re_rep, relation_mask) #[b,1800,128+128] 30 return self.linear_output(re_rep) #(b,1800,128*2)->(b,1800,97)
其中,b=batch_size,512是超参数最大单词长度,128是设置的hidden_size超参数。
21行代码调用了EncoderLSTM( ),实际上是通过一个BiLSTM,这部分代码段其实与之前https://www.cnblogs.com/Harukaze/p/14227071.html 这篇文章的EncoderLSTM相同:
1 class EncoderLSTM(nn.Module): 2 #(input_size, hidden_size, 1, True, False, 1 - config.keep_prob, False) 3 def __init__(self, input_size, num_units, nlayers, concat, bidir, dropout, return_last): 4 super().__init__() 5 self.rnns = [] 6 for i in range(nlayers): 7 if i == 0: 8 input_size_ = input_size 9 output_size_ = num_units 10 else: 11 input_size_ = num_units if not bidir else num_units * 2 12 output_size_ = num_units 13 self.rnns.append(nn.LSTM(input_size_, output_size_, 1, bidirectional=bidir, batch_first=True)) 14 self.rnns = nn.ModuleList(self.rnns) 15 self.init_hidden = nn.ParameterList([nn.Parameter(torch.Tensor(2 if bidir else 1, 1, num_units).zero_()) for _ in range(nlayers)]) 16 self.init_c = nn.ParameterList([nn.Parameter(torch.Tensor(2 if bidir else 1, 1, num_units).zero_()) for _ in range(nlayers)]) 17 self.dropout = LockedDropout(dropout) 18 self.concat = concat 19 self.nlayers = nlayers 20 self.return_last = return_last 21 # self.reset_parameters() 22 23 def reset_parameters(self): 24 for rnn in self.rnns: 25 for name, p in rnn.named_parameters(): 26 if 'weight' in name: 27 p.data.normal_(std=0.1) 28 else: 29 p.data.zero_() 30 31 def get_init(self, bsz, i): 32 return self.init_hidden[i].expand(-1, bsz, -1).contiguous(), self.init_c[i].expand(-1, bsz, -1).contiguous() 33 34 def forward(self, input, input_lengths=None): 35 bsz, slen = input.size(0), input.size(1) 36 output = input 37 outputs = [] 38 #获取输入batch的所有数据的长度 39 if input_lengths is not None: 40 lens = input_lengths.data.cpu().numpy() 41 42 for i in range(self.nlayers): 43 hidden, c = self.get_init(bsz, i) 44 output = self.dropout(output) #输入input进行dropout 45 if input_lengths is not None: 46 output = rnn.pack_padded_sequence(output, lens, batch_first=True) 47 #pack_padded_sequence 是先补齐到相同长度 再压紧,详见下方学习链接,batch_first = True只对input与output起作用 48 output, hidden = self.rnns[i](output, (hidden, c)) 49 if input_lengths is not None: 50 output, _ = rnn.pad_packed_sequence(output, batch_first=True) 51 #反过来,对压紧后的序列,进行扩充补齐操作。 52 if output.size(1) < slen: # used for parallel 53 padding = Variable(output.data.new(1, 1, 1).zero_()) 54 #output.data.new(1, 1, 1)意义:继承output维度的新Tensor,shape为(1,1,1) 55 output = torch.cat([output, padding.expand(output.size(0), slen-output.size(1), output.size(2))], dim=1) 56 #从数据长度那维度(第二维)padding,把pack,pad过程损失的output.shape还原出来 57 if self.return_last: 58 outputs.append(hidden.permute(1, 0, 2).contiguous().view(bsz, -1)) 59 #shape:[seq_len,bsz,count_dim]->[bsz,seq_len,count_dim]->[b,seq_len*count_dim] 60 #另外如果这里没有contiguous(),View无法工作,因为permute操作将重新定义下标与元素的对应关系 61 #内部数据的布局方式和从头开始创建一个这样的常规的tensor的布局方式不一样了 62 else: 63 outputs.append(output) 64 if self.concat: 65 return torch.cat(outputs, dim=2) #需要拼接,将每一层得到的output的最后一维hidden进行拼接 66 return outputs[-1] #返回最后一层的output input.shape = [40,512,100+20+20] output.shape = [40,512,hidden_size=128]
最后是Attention部分:
1 class SelfAttention(nn.Module): 2 def __init__(self, input_size, dropout): 3 super().__init__() 4 # self.dropout = LockedDropout(dropout) 5 self.input_linear = nn.Linear(input_size, 1, bias=False) 6 self.dot_scale = nn.Parameter(torch.Tensor(input_size).uniform_(1.0 / (input_size ** 0.5))) #[128] 7 #1.0 / (input_size ** 0.5)) 在计算机中取值范围 1.0 / (input_size ** 0.5)) < x < 1 8 #uniform从这个范围用均匀分布中抽样得到的值填充 9 10 #input.shape (b,1800,128);memory.shape (b,1800,128) ;mask = (b,1800) 11 def forward(self, input, memory, mask): 12 # input = self.dropout(input) 13 # memory = self.dropout(memory) 14 input_dot = self.input_linear(input) # (b,1800,1) 将每对实体包含的文档信息压缩到1个维度当中 15 cross_dot = torch.bmm(input * self.dot_scale, memory.permute(0, 2, 1).contiguous()) 16 '''[(b,1800,128) * (128)] * [b,128,1800] =[b,1800,128] * [b,128,1800] = [b,1800,1800]''' 17 '''input * self.dot_scale 注意力权重参数*输入''' 18 '''[b,1800,1800]这个矩阵表示1800对实体之间互相有什么影响''' 19 20 21 att = input_dot + cross_dot #广播机制 [b,1800,1800] 22 att = att - 1e30 * (1 - mask[:,None]) 23 '''mask[:, None].shape = [b,1,1800] ->因为mask中标记值为1,用1-mask之后,矩阵里值只有1与0(标记过的j对实体)''' 24 '''1e30=1.0*10^30 ''' 25 '''最后att = att - 1e30 * (1 - mask[:,None])表明无关系的矩阵对应的值都被减去了,留下的都是有关系的位置的值''' 26 weight_one = F.softmax(att, dim=-1) #每对实体对都可以看看和另外1800对关系哪对关系权重数值最大 27 output_one = torch.bmm(weight_one, memory) #[b,1800,1800]*[b,1800,128] = [b,1800,128] 28 return torch.cat([input, output_one], dim=-1) #[b,1800,128+128]
第6行代码关于Parameter内容,库中代码如下:
1 class Parameter(Tensor): 2 def __init__(self, data: Tensor=..., requires_grad: builtins.bool=...): ... 3 4 ...
torch中Parameter函数其实什么都没有,可以看到Parameter( ),可以看作是多加了requires_grad的Tensor,真实的类型为<built-in method type of Parameter object>
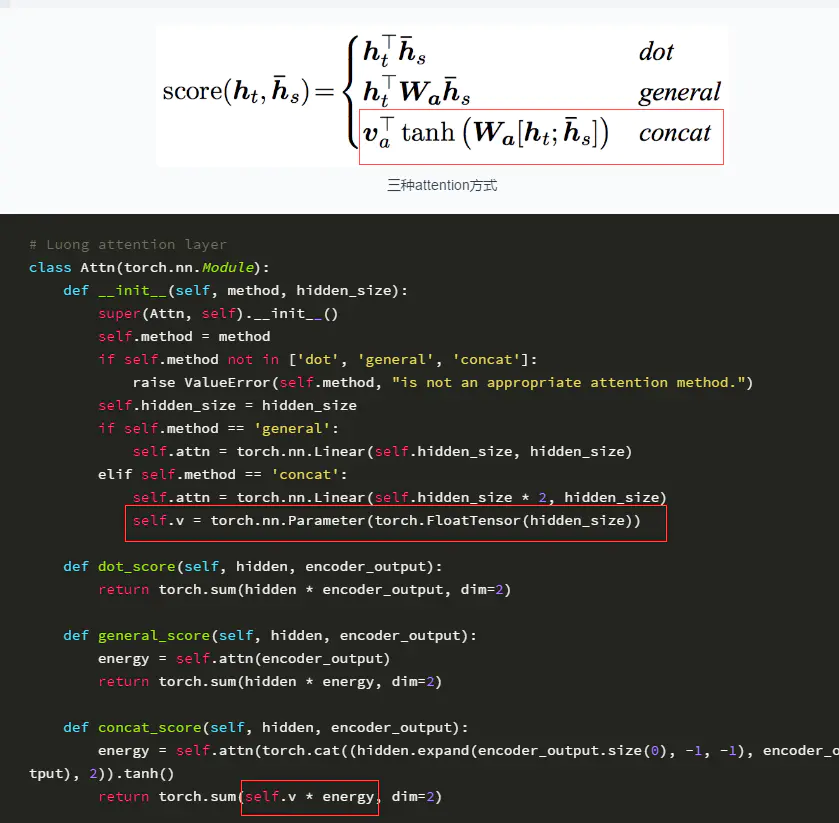
self.v = torch.nn.Parameter(torch.FloatTensor(hidden_size))。首先可以把这个函数理解为类型转换函数,将一个不可训练的类型Tensor转换成可以训练的类型parameter并将这个parameter绑定到这个module里面(net.parameter()中就有这个绑定的parameter,所以在参数优化的时候可以进行优化的),所以经过类型转换这个self.v变成了模型的一部分,成为了模型中根据训练可以改动的参数了。使用这个函数的目的也是想让某些变量在学习的过程中不断的修改其值以达到最优化。
我的理解还是比较浅薄的,暂且先放在这等我理解深刻后接续。
参考:
PyTorch里面的torch.nn.Parameter( ):https://www.jianshu.com/p/d8b77cc02410
PyTorch | tensor维度中使用 None: https://blog.csdn.net/jmu201521121021/article/details/103773501/


 浙公网安备 33010602011771号
浙公网安备 33010602011771号