【代码精读】DocRED: A Large-Scale Document-Level Relation Extraction Dataset(2)
现在我们有了预处理好的数据,本篇主要介绍如何进行dataload,train过程需要的shell命令如下:
Training:
CUDA_VISIBLE_DEVICES=0 python3 train.py --model_name BiLSTM --save_name checkpoint_BiLSTM --train_prefix dev_train --test_prefix dev_dev
指定cuda=0(第0块GPU)
--model_name 指定模型名字
--save_name 保存的模型checkpoint名字
--train_prefix 要训练的文件名称
--test_prefix 训练过程中顺便进行验证工作,验证集文件名
代码文件简要介绍
Chekpoint文件夹用来保存训练的最好的模型的参数
Config文件夹Config.py是关系抽取任务相关设置内容
EviConfig.py是证据抽取相关设置内容
Data文件与通过gen_data.py生成的prepro_data在这篇博客介绍过了,
https://www.cnblogs.com/Harukaze/p/14201689.html 感兴趣的读者可以看下。
Models文件夹包含四种论文中提到的模型其中LSTM_sp是证据抽取相关任务用到的
逻辑思路:先train,并在训练过程中验证,保存得到的验证效果最好的模型,再执行test.py文件(--test_prefix dev_dev for dev set, dev_test for test set)对验证集做测试文件名dev_dev,对测试集做测试文件名dev_test,
执行证据抽取任务同上(文件名后缀带sp的均为证据抽取相关文件)
下面阅读train.py文件的主要代码
1 import argparse#1导入模块 2 parser = argparse.ArgumentParser()#2建立解析对象 3 parser.add_argument('--model_name', type = str, default = 'CNN3', help = 'name of the model')#3增加属性,给xx实例增加一个model_name属性 xx.add_argument(“model_name”) 4 parser.add_argument('--save_name', type = str,default ='checkpoint_CNN3') 5 parser.add_argument('--train_prefix', type = str, default = 'dev_train') 6 parser.add_argument('--test_prefix', type = str, default = 'dev_dev') 7 args = parser.parse_args()# 4属性给与args实例: 把parser中设置的所有"add_argument"给返回到args子类实例当中, 那么parser中增加的属性内容都会在args实例中,使用即可。
然后调用自定义config包的Config.py文件中的方法
1 con = config.Config(args) 2 con.set_max_epoch(200) 3 con.load_train_data() 4 con.load_test_data() 5 # con.set_train_model() 6 model = { 7 'CNN3': models.CNN3, 8 'LSTM': models.LSTM, 9 'BiLSTM': models.BiLSTM, 10 'ContextAware': models.ContextAware, 11 } 12 con.train(model[args.model_name], args.save_name)
Config.py文件中共有两个类,尽管train.py中先调用的Config,我们先来看第一个计算正确率的类
1 class Accuracy(object): 2 def __init__(self): 3 self.correct = 0 4 self.total = 0 5 def add(self, is_correct): 6 self.total += 1 7 if is_correct: 8 self.correct += 1 9 def get(self): 10 if self.total == 0: 11 return 0.0 12 else: 13 return float(self.correct) / self.total 14 def clear(self): 15 self.correct = 0 16 self.total = 0
首先声明了这个类中需要的变量self.correct,self.total
接下来add( )函数,作用是统计correct的数目以及数据总数total(每被调用一次total+1)
接下来get( )函数,显而易见计算正确率
最后clear( )函数,将两个变量清零
下面详细介绍Config类的详细内容:Class Config(object):
1 def __init__(self, args): 2 self.acc_NA = Accuracy() 3 self.acc_not_NA = Accuracy() 4 self.acc_total = Accuracy() 5 #实例化三个计算正确率的对象 6 self.data_path = './prepro_data' 7 self.use_bag = False 8 self.use_gpu = True 9 self.is_training = True 10 self.max_length = 512 11 self.pos_num = 2 * self.max_length #????? 12 self.entity_num = self.max_length #?????? 13 self.relation_num = 97 #原论文共有97中关系 14 self.coref_size = 20 #解决共指的dim,设置为有20维 15 self.entity_type_size = 20 #实体类型映射为向量的维度也设置为20维 16 self.max_epoch = 20 17 self.opt_method = 'Adam' 18 self.optimizer = None 19 self.checkpoint_dir = './checkpoint' 20 self.fig_result_dir = './fig_result' 21 self.test_epoch = 5 22 self.pretrain_model = None 23 self.word_size = 100 #???? 24 self.epoch_range = None 25 self.cnn_drop_prob = 0.5 # for cnn 26 self.keep_prob = 0.8 # for lstm 27 self.period = 50 28 self.batch_size = 40 29 self.h_t_limit = 1800 #实体对最多1800对 30 self.test_batch_size = self.batch_size 31 self.test_relation_limit = 1800 #???? 32 self.char_limit = 16 #每个单词的最大长度限制16 33 self.sent_limit = 25 #每句话最多有25个单词 34 self.dis2idx = np.zeros((512), dtype='int64') 35 #初始化一个512长度的0矩阵 36 self.dis2idx[1] = 1 37 self.dis2idx[2:] = 2 38 self.dis2idx[4:] = 3 39 self.dis2idx[8:] = 4 40 self.dis2idx[16:] = 5 41 self.dis2idx[32:] = 6 42 self.dis2idx[64:] = 7 43 self.dis2idx[128:] = 8 44 self.dis2idx[256:] = 9 45 #[0,1,2,2,3,3,3,3,4,4,4,4,4,4,4,4,5,5,5,5,5,5,5,5,5,5,5,5,5,5,5,5,6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,8,8,8,8,8,8,8,8,8,8,8,8,8…] 46 self.dis_size = 20 47 self.train_prefix = args.train_prefix 48 self.test_prefix = args.test_prefix 49 #训练与测试文件名获取 50 if not os.path.exists("log"): 51 os.mkdir("log") 52 #创建一个记录日志文件的文件夹
一大堆设置函数,方便后面实验进行设置更改:
1 def set_data_path(self, data_path): 2 self.data_path = data_path 3 def set_max_length(self, max_length): 4 self.max_length = max_length 5 self.pos_num = 2 * self.max_length 6 def set_num_classes(self, num_classes): 7 self.num_classes = num_classes 8 def set_window_size(self, window_size): 9 self.window_size = window_size 10 def set_word_size(self, word_size): 11 self.word_size = word_size 12 def set_max_epoch(self, max_epoch): 13 self.max_epoch = max_epoch 14 def set_batch_size(self, batch_size): 15 self.batch_size = batch_size 16 def set_opt_method(self, opt_method): 17 self.opt_method = opt_method 18 def set_drop_prob(self, drop_prob): 19 self.drop_prob = drop_prob 20 def set_checkpoint_dir(self, checkpoint_dir): 21 self.checkpoint_dir = checkpoint_dir 22 def set_test_epoch(self, test_epoch): 23 self.test_epoch = test_epoch 24 def set_pretrain_model(self, pretrain_model): 25 self.pretrain_model = pretrain_model 26 def set_is_training(self, is_training): 27 self.is_training = is_training 28 def set_use_bag(self, use_bag): 29 self.use_bag = use_bag 30 def set_use_gpu(self, use_gpu): 31 self.use_gpu = use_gpu 32 def set_epoch_range(self, epoch_range): 33 self.epoch_range = epoch_range
接下来介绍load训练数据的函数:
1 def load_train_data(self): 2 print("Reading training data...") 3 prefix = self.train_prefix 4 print ('train', prefix) 5 self.data_train_word = np.load(os.path.join(self.data_path, prefix+'_word.npy')) #(3053,512) 6 self.data_train_pos = np.load(os.path.join(self.data_path, prefix+'_pos.npy')) 7 self.data_train_ner = np.load(os.path.join(self.data_path, prefix+'_ner.npy')) 8 self.data_train_char = np.load(os.path.join(self.data_path, prefix+'_char.npy')) #3053,512,16 9 self.train_file = json.load(open(os.path.join(self.data_path, prefix+'.json'))) 10 print("Finish reading") 11 self.train_len = ins_num = self.data_train_word.shape[0] 12 assert(self.train_len==len(self.train_file)) 13 self.train_order = list(range(ins_num)) #[0,...3052] 14 self.train_batches = ins_num // self.batch_size #计算有多少个训练用的batches 15 if ins_num % self.batch_size != 0: 16 self.train_batches += 1 #除不尽剩下的放入最后一个batch中
接下来介绍load测试数据的函数:
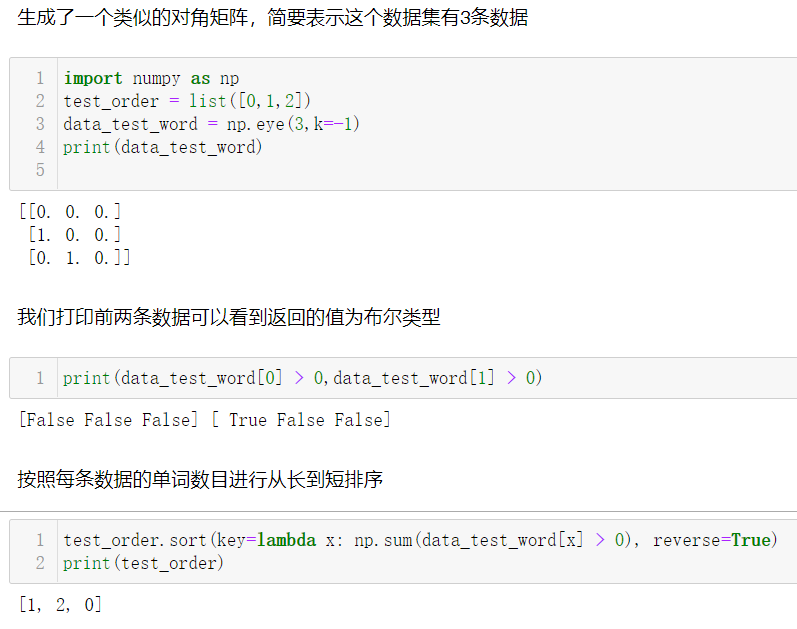
1 def load_test_data(self): 2 print("Reading testing data...") 3 self.data_word_vec = np.load(os.path.join(self.data_path, 'vec.npy')) #这两句代码还没发现在哪用上 4 self.data_char_vec = np.load(os.path.join(self.data_path, 'char_vec.npy')) 5 self.rel2id = json.load(open(os.path.join(self.data_path, 'rel2id.json'))) 6 self.id2rel = {v: k for k,v in self.rel2id.items()} 7 # items( ) 方法的遍历:items() 方法把字典中每对 key 和 value 组成一个元组,并把这些元组放在列表中返回 8 prefix = self.test_prefix 9 print (prefix) 10 self.is_test = ('dev_test' == prefix) #判断是否为测试,文件名等于dev_test时为测试返回True值 11 self.data_test_word = np.load(os.path.join(self.data_path, prefix+'_word.npy')) 12 self.data_test_pos = np.load(os.path.join(self.data_path, prefix+'_pos.npy')) 13 self.data_test_ner = np.load(os.path.join(self.data_path, prefix+'_ner.npy')) 14 self.data_test_char = np.load(os.path.join(self.data_path, prefix+'_char.npy')) 15 self.test_file = json.load(open(os.path.join(self.data_path, prefix+'.json'))) 16 self.test_len = self.data_test_word.shape[0] 17 assert(self.test_len==len(self.test_file)) 18 print("Finish reading") 19 self.test_batches = self.data_test_word.shape[0] // self.test_batch_size 20 if self.data_test_word.shape[0] % self.test_batch_size != 0: 21 self.test_batches += 1 22 self.test_order = list(range(self.test_len)) 23 self.test_order.sort(key=lambda x: np.sum(self.data_test_word[x] > 0), reverse=True) 24 #data_test_word[x]>0 表示第x条数据有多少个单词(word2id.json中“BLANK”:0),True/false调用sum自动转换成1/0求和计算,按照句子长度由长到短排序
使用jupyter notebook简要介绍说明第23行代码段:
在介绍下一个模块之前,先介绍collections包的 defaultdict的使用:
1 from collections import defaultdict 2 d = defaultdict(list) 3 d['a'].append(1) 4 d['a'].append(2) 5 d['a'].append(4) 6 >>> d 7 defaultdict(<class 'list'>, {'a': [1, 2, 4]})
接下来看get_train_batch( )模块:
1 def get_train_batch(self): 2 random.shuffle(self.train_order) 3 #打乱训练文章的顺序 self.train_order=[0,1,2,…,3052] 4 context_idxs = torch.LongTensor(self.batch_size, self.max_length).cuda() 5 context_pos = torch.LongTensor(self.batch_size, self.max_length).cuda() 6 h_mapping = torch.Tensor(self.batch_size, self.h_t_limit, self.max_length).cuda() 7 t_mapping = torch.Tensor(self.batch_size, self.h_t_limit, self.max_length).cuda()#h_mapping,t_mapping均为实体映射矩阵 8 relation_multi_label = torch.Tensor(self.batch_size, self.h_t_limit, self.relation_num).cuda()#每个batch中,限制最多有1800对关系对,每个关系有97种关系对应的值 9 relation_mask = torch.Tensor(self.batch_size, self.h_t_limit).cuda()#关系mask矩阵,第X对实体无论是有关系实体对,还是na_triple实体对,遍历过都标记为1 10 pos_idx = torch.LongTensor(self.batch_size, self.max_length).cuda() 11 context_ner = torch.LongTensor(self.batch_size, self.max_length).cuda() 12 context_char_idxs = torch.LongTensor(self.batch_size, self.max_length, self.char_limit).cuda() 13 relation_label = torch.LongTensor(self.batch_size, self.h_t_limit).cuda() 14 ht_pair_pos = torch.LongTensor(self.batch_size, self.h_t_limit).cuda() 15 #以下为一个大循环,一直到函数结束 16 for b in range(self.train_batches):#b表示遍历到第几组batch了 17 start_id = b * self.batch_size 18 cur_bsz = min(self.batch_size, self.train_len - start_id) #最后一个batch可能没这么多 19 cur_batch = list(self.train_order[start_id: start_id + cur_bsz]) 20 cur_batch.sort(key=lambda x: np.sum(self.data_train_word[x]>0) , reverse = True) 21 #按照当前取的batch中的batch_size篇文档,按照文档长度进行排序 22 for mapping in [h_mapping, t_mapping]: 23 mapping.zero_() 24 for mapping in [relation_multi_label, relation_mask, pos_idx]: 25 mapping.zero_() 26 ht_pair_pos.zero_() 27 #将Tensor初始化为零Tensor 28 29 relation_label.fill_(IGNORE_INDEX)#使用-100填充relation_label矩阵 30 max_h_t_cnt = 1 31 for i, index in enumerate(cur_batch):#遍历当前batch中的数据项 32 context_idxs[i].copy_(torch.from_numpy(self.data_train_word[index, :])) 33 context_pos[i].copy_(torch.from_numpy(self.data_train_pos[index, :])) 34 context_char_idxs[i].copy_(torch.from_numpy(self.data_train_char[index, :])) 35 context_ner[i].copy_(torch.from_numpy(self.data_train_ner[index, :])) 36 #对应的numpy中的word,pos,char,ner数据全部拷贝到tensor中 37 for j in range(self.max_length): #记录这个batch中的第i篇(0~39)文档,第j个单词的位置,如果为0表示没有单词,结束循环 38 if self.data_train_word[index, j]==0: 39 break 40 pos_idx[i, j] = j+1#记录一个句子的所有单词位置序号,如 I Love you 1 2 3 41 ins = self.train_file[index] #第index数据包括 vertexset labels title na_triple ls sents项 42 labels = ins['labels'] 43 idx2label = defaultdict(list) 44 for label in labels: 45 idx2label[(label['h'], label['t'])].append(label['r']) 46 #遍历第index文章的所有标签项,将(头实体,尾实体)对应的关系填入defaultdict(list)中,连一对实体可能有多种关系都可以便捷表示,{(2,3):4,(1,2):6,7} 47 train_tripe = list(idx2label.keys())#训练的元组自然是字典对应的key项 48 #研究第index篇文章获取的所有有关系的实体对 49 for j, (h_idx, t_idx) in enumerate(train_tripe): 50 hlist = ins['vertexSet'][h_idx] #有一些entity有两个或以上的mentions,大部分都是一个mention 51 tlist = ins['vertexSet'][t_idx] 52 for h in hlist: #遍历一个entity节点的所有mentions 53 h_mapping[i, j, h['pos'][0]:h['pos'][1]] = 1.0 / len(hlist) / (h['pos'][1] - h['pos'][0])#h_mapping.shape=[40,1800,512], 54 #填充这个batch中的第i篇(0~39)文章,第j对实体对位置对应到h_mapping矩阵中的值 55 '''我们假设这有一个entity,他有两个mentions,{pos:(29,31),name:North Korea;pos:(40,42),name:North Korea},那么第一个mention在h_mapping[i,j,29:31]=1/4,''' 56 '''第二个mention在h_mapping[i,j,40:42]=1/4,看到两个mention被用相同值表示了,但这只是特殊情况,还是有很多同一entity的mentions在文中单词表示不同。这个数值表示很容易重复,''' 57 '''大部分实体h[‘pos’][1]-h[‘pos’][0]都处于2~3之间''' 58 #1/2/3 = 1/6 59 for t in tlist: 60 t_mapping[i, j, t['pos'][0]:t['pos'][1]] = 1.0 / len(tlist) / (t['pos'][1] - t['pos'][0]) 61 label = idx2label[(h_idx, t_idx)] #获取我们研究的这对实体的关系 62 delta_dis = hlist[0]['pos'][0] - tlist[0]['pos'][0] #头实体的第一个mention(也是头实体在文章中第一次出现)的位置减去尾实体的第一个mention第一次出现的位置 63 if delta_dis < 0: 64 ht_pair_pos[i, j] = -int(self.dis2idx[-delta_dis]) #记录h,t两实体节点绝对位置做差得到的距离 65 else: 66 ht_pair_pos[i, j] = int(self.dis2idx[delta_dis]) 67 '''头减去尾巴,如果距离近一般来说是小-大=小负数 ,小负数运算得到-1(小负数),如果距离远,小减大 = 大负数,运算得到-7/-8,(大负数)''' 68 '''dis_h_2_t = ht_pair_pos+10 dis_t_2_h = -ht_pair_pos+10''' 69 '''如果头实体在尾实体后面,大减小,如果距离近,小正数,运算得到1/2,如果距离远,大正数,运算得到7/8''' 70 for r in label: 71 relation_multi_label[i, j, r] = 1 #这个batch中的第i篇(0~39)文章的第j对有关系的实体存在关系类型r在矩阵中表示为1 72 relation_mask[i, j] = 1 #这个batch中的第i篇(0~39)文章的第j对实体对,标记为1 73 rt = np.random.randint(len(label)) #产生小于这对顶点关系数目的随机数,比如这对顶点对应N中关系,产生(0~N) 74 relation_label[i, j] = label[rt] #选一个关系放入关系标签矩阵中 75 lower_bound = len(ins['na_triple']) #无关系的实体对数 76 # random.shuffle(ins['na_triple']) 77 # lower_bound = max(20, len(train_tripe)*3) 78 for j, (h_idx, t_idx) in enumerate(ins['na_triple'][:lower_bound], len(train_tripe)): #下标从有关系实体对的数目开始 79 hlist = ins['vertexSet'][h_idx] 80 tlist = ins['vertexSet'][t_idx] 81 #无关系实体对mapping计算公式同上文 82 for h in hlist: 83 h_mapping[i, j, h['pos'][0]:h['pos'][1]] = 1.0 / len(hlist) / (h['pos'][1] - h['pos'][0]) 84 for t in tlist: 85 t_mapping[i, j, t['pos'][0]:t['pos'][1]] = 1.0 / len(tlist) / (t['pos'][1] - t['pos'][0]) 86 #这个batch中的第i篇(0~39)文章的第j对无关系实体,在0处标记为1(0代表97种关系类型中无关系的下标) 87 relation_multi_label[i, j, 0] = 1 88 relation_label[i, j] = 0 #rel2id中"Na": 0,代表无关系 89 relation_mask[i, j] = 1 90 delta_dis = hlist[0]['pos'][0] - tlist[0]['pos'][0] 91 if delta_dis < 0: #如果相對距離是負數,-512 -> -1; -128->-2;....-1->-9 92 ht_pair_pos[i, j] = -int(self.dis2idx[-delta_dis]) 93 else: 94 ht_pair_pos[i, j] = int(self.dis2idx[delta_dis]) 95 max_h_t_cnt = max(max_h_t_cnt, len(train_tripe) + lower_bound) #计算这个batch中40篇文章有关系的实体对加无关系的实体对的最大数量 96 input_lengths = (context_idxs[:cur_bsz] > 0).long().sum(dim=1) #这个batch中有cur_bsz条数据 其512维数据长度,有单词的位置>0记录为true,反之记录为false,取长整型,将值变为0/1,在第一维度上求和从而得到,这句话的单词长度 97 max_c_len = int(input_lengths.max()) #获得这个batch最大句子长度数值 98 99 yield {'context_idxs': context_idxs[:cur_bsz, :max_c_len].contiguous(), 100 'context_pos': context_pos[:cur_bsz, :max_c_len].contiguous(), 101 'h_mapping': h_mapping[:cur_bsz, :max_h_t_cnt, :max_c_len], 102 't_mapping': t_mapping[:cur_bsz, :max_h_t_cnt, :max_c_len], 103 'relation_label': relation_label[:cur_bsz, :max_h_t_cnt].contiguous(), 104 'input_lengths' : input_lengths, 105 'pos_idx': pos_idx[:cur_bsz, :max_c_len].contiguous(), 106 'relation_multi_label': relation_multi_label[:cur_bsz, :max_h_t_cnt], 107 'relation_mask': relation_mask[:cur_bsz, :max_h_t_cnt], 108 'context_ner': context_ner[:cur_bsz, :max_c_len].contiguous(), 109 'context_char_idxs': context_char_idxs[:cur_bsz, :max_c_len].contiguous(), 110 'ht_pair_pos': ht_pair_pos[:cur_bsz, :max_h_t_cnt], 111 }
yield是用于生成器。什么是生成器,你可以通俗的认为,在一个函数中,使用了yield来代替return的位置的函数,就是生成器。它不同于函数的使用方法是:函数使用return来进行返回值,每调用一次,返回一个新加工好的数据返回给你;yield不同,它会在调用生成器的时候,把数据生成object,然后当你需要用的时候,要用next()方法来取,同时不可逆。你可以通俗的叫它"轮转容器",可用现实的一种实物来理解:水车,先yield来装入数据、产出generator object、使用next()来释放;好比水车转动后,车轮上的水槽装入水,随着轮子转动,被转到下面的水槽就能将水送入水道中流入田里
return:做一件事,做到A节点的时候,碰到 ‘’return 拿出成果‘’,那你就把成果拿出来,并且停止之后的事情。
yield:做一件事,做到A节点的时候,碰到 ‘’yield 拿出成果‘’,那你就把成果拿出来,拿出来之后,接着做后面的事情
而在调用contiguous()之后,PyTorch会开辟一块新的内存空间存放变换之后的数据,并会真正改变Tensor的内容,按照变换之后的顺序存放数据
接下来获取test的batch基本和get_train_batch差不多,不做过多介绍:
1 def get_test_batch(self): 2 context_idxs = torch.LongTensor(self.test_batch_size, self.max_length).cuda() 3 context_pos = torch.LongTensor(self.test_batch_size, self.max_length).cuda() 4 h_mapping = torch.Tensor(self.test_batch_size, self.test_relation_limit, self.max_length).cuda() 5 t_mapping = torch.Tensor(self.test_batch_size, self.test_relation_limit, self.max_length).cuda() 6 context_ner = torch.LongTensor(self.test_batch_size, self.max_length).cuda() 7 context_char_idxs = torch.LongTensor(self.test_batch_size, self.max_length, self.char_limit).cuda() 8 relation_mask = torch.Tensor(self.test_batch_size, self.h_t_limit).cuda() 9 ht_pair_pos = torch.LongTensor(self.test_batch_size, self.h_t_limit).cuda() 10 for b in range(self.test_batches): 11 start_id = b * self.test_batch_size 12 cur_bsz = min(self.test_batch_size, self.test_len - start_id) 13 cur_batch = list(self.test_order[start_id : start_id + cur_bsz]) 14 for mapping in [h_mapping, t_mapping, relation_mask]: 15 mapping.zero_() 16 ht_pair_pos.zero_() 17 max_h_t_cnt = 1 18 cur_batch.sort(key=lambda x: np.sum(self.data_test_word[x]>0) , reverse = True) 19 #data_test_word[x]>0 表示第x条数据有多少个单词,True/false调用sum自动转换成1/0求和计算,按照句子长度由长到短排序 20 labels = [] 21 L_vertex = [] 22 titles = [] 23 indexes = [] 24 for i, index in enumerate(cur_batch): 25 context_idxs[i].copy_(torch.from_numpy(self.data_test_word[index, :])) 26 context_pos[i].copy_(torch.from_numpy(self.data_test_pos[index, :])) 27 context_char_idxs[i].copy_(torch.from_numpy(self.data_test_char[index, :])) 28 context_ner[i].copy_(torch.from_numpy(self.data_test_ner[index, :])) 29 idx2label = defaultdict(list) 30 ins = self.test_file[index] #第index数据包括 vertexset labels title na_triple ls sents项 31 for label in ins['labels']: 32 idx2label[(label['h'], label['t'])].append(label['r']) 33 L = len(ins['vertexSet']) 34 titles.append(ins['title']) 35 j = 0 36 #双重循环遍历第index篇文章的所有实体节点 37 '''这个部分训练和测试写法不一样,训练遍历实体对要分有关系的情况,无关系的情况''' 38 '''分别为relation_multi_label[i, j, 0],relation_label[i, j],relation_mask[i, j]进行标记''' 39 '''而测试可以暴力循环''' 40 for h_idx in range(L): 41 for t_idx in range(L): 42 if h_idx != t_idx: 43 hlist = ins['vertexSet'][h_idx] 44 tlist = ins['vertexSet'][t_idx] 45 for h in hlist: 46 h_mapping[i, j, h['pos'][0]:h['pos'][1]] = 1.0 / len(hlist) / (h['pos'][1] - h['pos'][0]) 47 for t in tlist: 48 t_mapping[i, j, t['pos'][0]:t['pos'][1]] = 1.0 / len(tlist) / (t['pos'][1] - t['pos'][0]) 49 relation_mask[i, j] = 1 50 delta_dis = hlist[0]['pos'][0] - tlist[0]['pos'][0] 51 if delta_dis < 0: 52 ht_pair_pos[i, j] = -int(self.dis2idx[-delta_dis]) 53 else: 54 ht_pair_pos[i, j] = int(self.dis2idx[delta_dis]) 55 j += 1 56 max_h_t_cnt = max(max_h_t_cnt, j)#记录这一个batch中文章中出现的最多的实体对数 57 label_set = {} 58 for label in ins['labels']: 59 label_set[(label['h'], label['t'], label['r'])] = label['in'+self.train_prefix] 60 #把dev_dev.json文件的每一个label的每个关系对是否在"远程监督数据集/人工标注训练数据集(intrain/indev_train)"True/false,以键值对的形式放进label_set中 61 labels.append(label_set) 62 L_vertex.append(L) #这个batch中的每篇文章的节点数都加入到L_vertex列表中 63 indexes.append(index)#这个batch到底是原文的哪几篇文章的index序号记录 64 input_lengths = (context_idxs[:cur_bsz] > 0).long().sum(dim=1) #这个batch中40篇文章的长度 65 max_c_len = int(input_lengths.max()) 66 yield {'context_idxs': context_idxs[:cur_bsz, :max_c_len].contiguous(), 67 'context_pos': context_pos[:cur_bsz, :max_c_len].contiguous(), 68 'h_mapping': h_mapping[:cur_bsz, :max_h_t_cnt, :max_c_len], 69 't_mapping': t_mapping[:cur_bsz, :max_h_t_cnt, :max_c_len], 70 'labels': labels, 71 'L_vertex': L_vertex, 72 'input_lengths': input_lengths, 73 'context_ner': context_ner[:cur_bsz, :max_c_len].contiguous(), 74 'context_char_idxs': context_char_idxs[:cur_bsz, :max_c_len].contiguous(), 75 'relation_mask': relation_mask[:cur_bsz, :max_h_t_cnt], 76 'titles': titles, 77 'ht_pair_pos': ht_pair_pos[:cur_bsz, :max_h_t_cnt], 78 'indexes': indexes 79 }
介绍下一段train( )函数之前,先补充下预备知识,关于argmax的使用:
1 import torch 2 predict_re = torch.rand(3,4,5) 3 output = torch.argmax(predict_re, dim=-1) 4 print(predict_re.shape,output.shape) 5 #torch.Size([3, 4, 5]) torch.Size([3, 4])
可以看到执行argmax最后一维消失了,下标记录在了[3,4]的矩阵中。
介绍F1值得计算过程:
F1 = 2 * (precision * recall) / (precision + recall)
precision = true_positives / (true_positives + false_positives)
recall = true_positives / (true_positives + false_negatives)

AUC的计算过程:

将数据划分训练集、验证集和测试集。在训练集上训练模型,在验证集上评估模型,找到的最佳的参数,测试集上的误差作为泛化误差的近似
1 def train(self, model_pattern, model_name): 2 #model_pattern = model[args.model_name] model_name = checkpoint_BiLSTM 参数需自己指定 3 #model_pattern = models.BiLSTM 这里实际上是通过属性实例args调用model.name属性,再通过字典找到key对应的value , 4 #value实际上等于从models包中调用BiLSTM模块,这也解释了下一句代码为什么需要传递参数。 5 ori_model = model_pattern(config = self) #给模型传递设置参数 6 if self.pretrain_model != None: 7 ori_model.load_state_dict(torch.load(self.pretrain_model)) 8 ori_model.cuda() 9 model = nn.DataParallel(ori_model) #多GPU训练使用 10 optimizer = optim.Adam(filter(lambda p: p.requires_grad, model.parameters())) #filter(a,b)前者为判断函数,后者是可迭代对象 11 # nll_average = nn.CrossEntropyLoss(size_average=True, ignore_index=IGNORE_INDEX) 12 BCE = nn.BCEWithLogitsLoss(reduction='none') #reduction有可选参数mean 13 if not os.path.exists(self.checkpoint_dir): 14 os.mkdir(self.checkpoint_dir) 15 best_auc = 0.0 16 best_f1 = 0.0 17 best_epoch = 0 18 model.train() 19 global_step = 0 20 total_loss = 0 21 start_time = time.time() 22 def logging(s, print_=True, log_=True): 23 if print_: 24 print(s) 25 if log_: 26 with open(os.path.join(os.path.join("log", model_name)), 'a+') as f_log: #生成文件名 log/checkpoint_BiLSTM 27 f_log.write(s + '\n') 28 '''使用’w’写入模式,或者’w+'读写模式,不行。虽然文件不存在会创建文件,但是如果文件存在会将其覆盖。也就是说无论文件是否存在, 29 都会重新开一个新文件然后处理。还有’a’追加写模式,和’a+'追加读写模式。这是我需要的。文件存在,则打开该文件;文件不存在,则新建一个空白文件。 30 但是还要注意,打开文件后指针是在文件末尾的。如果要读取文件的内容,需要将指针移动到开头,并且只能用’a+’。写模式是只能写,无法读取的''' 31 plt.xlabel('Recall') 32 plt.ylabel('Precision') 33 plt.ylim(0.3, 1.0) #xmin:x轴上的显示下限 , xmax:x轴上的显示上限 34 plt.xlim(0.0, 0.4) 35 plt.title('Precision-Recall') 36 plt.grid(True) ## 生成网格 37 for epoch in range(self.max_epoch): 38 self.acc_NA.clear() 39 self.acc_not_NA.clear() 40 self.acc_total.clear() 41 #每次训练开始前上一轮的self.correct,self.total不保存 42 for data in self.get_train_batch(): 43 #模型forward需要的数据 44 context_idxs = data['context_idxs'] 45 context_pos = data['context_pos'] 46 context_ner = data['context_ner'] 47 context_char_idxs = data['context_char_idxs'] 48 input_lengths = data['input_lengths'] 49 h_mapping = data['h_mapping'] 50 t_mapping = data['t_mapping'] 51 relation_mask = data['relation_mask'] 52 ht_pair_pos = data['ht_pair_pos'] 53 # ht_pair_pos[:cur_bsz, :max_h_t_cnt] 54 dis_h_2_t = ht_pair_pos + 10 # tensor中的值全部加10 55 dis_t_2_h = -ht_pair_pos + 10 56 #计算loss函数需要的预测值与真实值 57 relation_multi_label = data['relation_multi_label'] 58 predict_re = model(context_idxs, context_pos, context_ner, context_char_idxs, input_lengths, h_mapping, t_mapping, relation_mask, dis_h_2_t, dis_t_2_h) 59 loss = torch.sum(BCE(predict_re, relation_multi_label)*relation_mask.unsqueeze(2)) / (self.relation_num * torch.sum(relation_mask)) 60 #BCE(predict_re, relation_multi_label),计算得到一个loss值,该loss值*[batch_size,max_h_t_cnt,1]矩阵,所有记录过的实体对都考虑到了,再求和, 61 # 除以97(所有可能的关系情况)*所有记录过的实体对 62 output = torch.argmax(predict_re, dim=-1) #predict_re=[batch_size,max_h_t_cnt,97]-> output = [batch_size,max_h_t_cnt] 获取最可能关系的下标 63 output = output.data.cpu().numpy() 64 optimizer.zero_grad() 65 loss.backward() 66 optimizer.step() 67 #获取数据集的真实值 relation_label=[batch_size,max_h_t_cnt] 68 relation_label = data['relation_label'] 69 relation_label = relation_label.data.cpu().numpy() 70 for i in range(output.shape[0]): 71 for j in range(output.shape[1]): 72 label = relation_label[i][j] 73 if label<0: 74 break 75 if label == 0: 76 self.acc_NA.add(output[i][j] == label) 77 #真实值是“Na”:0,预测值也为0,记录无关系的对象acc_NA中correct与total都加1,如果预测值不为0,则只有total加1 78 else: 79 self.acc_not_NA.add(output[i][j] == label) 80 #真实关系与预测关系相同,记录有关系的对象acc_not_NA中correc与total都加1,如果预测的关系与真实值不同,则只有total加1 81 self.acc_total.add(output[i][j] == label) 82 #只要预测对了,不管实体对有没有关系,total,correct都加1,预测不对,只有total加1 83 global_step += 1 84 total_loss += loss.item() 85 if global_step % self.period == 0 : 86 cur_loss = total_loss / self.period 87 elapsed = time.time() - start_time 88 logging('| epoch {:2d} | step {:4d} | ms/b {:5.2f} | train loss {:5.3f} | NA acc: {:4.2f} | not NA acc: {:4.2f} | tot acc: {:4.2f} '.format(epoch, global_step, elapsed * 1000 / self.period, cur_loss, self.acc_NA.get(), self.acc_not_NA.get(), self.acc_total.get())) 89 total_loss = 0 90 start_time = time.time() 91 #每个epoch对所有数据过了一遍,进行一次模型测试,看现在模型训练有没有达到最佳效果 92 if (epoch+1) % self.test_epoch == 0: 93 logging('-' * 89) 94 eval_start_time = time.time() 95 model.eval() 96 f1, auc, pr_x, pr_y = self.test(model, model_name) 97 model.train() 98 logging('| epoch {:3d} | time: {:5.2f}s'.format(epoch, time.time() - eval_start_time)) 99 logging('-' * 89) 100 #效果最好的一次,保存模型 101 if f1 > best_f1: 102 best_f1 = f1 103 best_auc = auc 104 best_epoch = epoch 105 path = os.path.join(self.checkpoint_dir, model_name) 106 torch.save(ori_model.state_dict(), path) 107 plt.plot(pr_x, pr_y, lw=2, label=str(epoch)) 108 #x: x轴上的数值;y: y轴上的数值;lw:折线图的线条宽度;label:标记图内容的标签文本 109 plt.legend(loc="upper right") #plt.legend()函数主要的作用就是给图加上图例,plt.legend([x,y,z])里面的参数使用的是list的的形式将图表的的名称喂给这和函数。 110 plt.savefig(os.path.join("fig_result", model_name)) 111 print("Finish training") 112 print("Best epoch = %d | auc = %f" % (best_epoch, best_auc)) 113 print("Storing best result...") 114 print("Finish storing")
在train( )函数中,每个epoch都对所有数据过了一遍,需要进行一次模型测试,执行test( )函数,看现在模型有没有达到最佳效果:
1 def test(self, model, model_name, output=False, input_theta=-1): 2 data_idx = 0 3 eval_start_time = time.time() 4 # test_result_ignore = [] 5 total_recall_ignore = 0 6 test_result = [] 7 total_recall = 0 8 top1_acc = have_label = 0 9 def logging(s, print_=True, log_=True): 10 if print_: 11 print(s) 12 if log_: 13 with open(os.path.join(os.path.join("log", model_name)), 'a+') as f_log: 14 f_log.write(s + '\n') 15 for data in self.get_test_batch(): 16 with torch.no_grad(): 17 #forward需要的数据 18 context_idxs = data['context_idxs'] 19 context_pos = data['context_pos'] 20 context_ner = data['context_ner'] 21 context_char_idxs = data['context_char_idxs'] 22 input_lengths = data['input_lengths'] 23 h_mapping = data['h_mapping'] 24 t_mapping = data['t_mapping'] 25 relation_mask = data['relation_mask'] 26 ht_pair_pos = data['ht_pair_pos'] 27 dis_h_2_t = ht_pair_pos + 10 28 dis_t_2_h = -ht_pair_pos + 10 29 30 labels = data['labels'] #[第i篇文章的所有在不在训练集中的标签集((1,2,96):True,(2,4,65):False...),第i+1篇文章的...,....] 31 L_vertex = data['L_vertex'] #这个batch中的每篇文章的节点数都加入到L_vertex列表中 32 titles = data['titles'] 33 indexes = data['indexes'] #这个batch中所有文章原来的序号[23,57,890,1334,....] 34 predict_re = model(context_idxs, context_pos, context_ner, context_char_idxs, input_lengths, 35 h_mapping, t_mapping, relation_mask, dis_h_2_t, dis_t_2_h) 36 predict_re = torch.sigmoid(predict_re) 37 predict_re = predict_re.data.cpu().numpy() 38 for i in range(len(labels)): #i的取值范围实际上是0~40 39 label = labels[i] 40 index = indexes[i] 41 total_recall += len(label) #每个batch中所有label项数目累加 42 for l in label.values(): 43 if not l: #如果l为False,说明该关系三元组(如:1,2,66)不在训练集中 44 total_recall_ignore += 1 45 L = L_vertex[i] 46 j = 0 47 for h_idx in range(L): 48 for t_idx in range(L): 49 if h_idx != t_idx: 50 r = np.argmax(predict_re[i, j]) #取这个batch中第i篇文章的第j对实体,预测出的关系(数值例如1) 51 if (h_idx, t_idx, r) in label: #如果这个关系三元组在label中,正确加1 52 top1_acc += 1 53 flag = False 54 for r in range(1, self.relation_num): 55 intrain = False 56 57 if (h_idx, t_idx, r) in label: #遍历这对实体节点关系r以及还有其他关系在label中 58 flag = True 59 if label[(h_idx, t_idx, r)]==True: #如果该关系三元组还在训练集中出现过,则满足这个if语句 60 intrain = True 61 # if not intrain: 62 # test_result_ignore.append( ((h_idx, t_idx, r) in label, float(predict_re[i,j,r]), titles[i], self.id2rel[r], index, h_idx, t_idx, r) ) 63 test_result.append( ((h_idx, t_idx, r) in label, float(predict_re[i,j,r]), intrain, titles[i], self.id2rel[r], index, h_idx, t_idx, r) ) 64 #(关系三元组是否在label中,预测的关系的float值为多少,是否在训练集中出现过,titles,关系代码PXX,这篇文章原序号,头实体序号,尾实体序号,关系代码) 65 #这里一对(h_idx,t_idx)进行所有关系遍历,看作是进行了多次预测,只不过大多数都预测错误了,因为(h_idx, t_idx, r) in label大多数情况下都是False 66 if flag: #有关系的实体对数目加1 67 have_label += 1 68 j += 1 69 data_idx += 1 70 if data_idx % self.period == 0: #每50个batch看下测试用的时间 71 print('| step {:3d} | time: {:5.2f}'.format(data_idx // self.period, (time.time() - eval_start_time))) 72 eval_start_time = time.time() 73 # test_result_ignjore.sort(key=lambda x: x[1], reverse=True) 74 test_result.sort(key = lambda x: x[1], reverse=True) 75 #按照预测的关系的float值为多少,由大到小排序 76 print ('total_recall', total_recall) 77 # plt.xlabel('Recall') 78 # plt.ylabel('Precision') 79 # plt.ylim(0.2, 1.0) 80 # plt.xlim(0.0, 0.6) 81 # plt.title('Precision-Recall') 82 # plt.grid(True) 83 pr_x = [] 84 pr_y = [] 85 correct = 0 86 w = 0 87 if total_recall == 0: 88 total_recall = 1 # for test 89 for i, item in enumerate(test_result): 90 correct += item[0] # 0+1+1+0+1+... 91 pr_y.append(float(correct) / (i + 1)) #precision precision = true_positives / (true_positives + false_positives) 92 pr_x.append(float(correct) / total_recall) #recall 当前轮数Ture关系三元组个数/验证集中所有关系三元组(在不在训练集中的三元组true/false都包含) 93 if item[1] > input_theta: 94 w = i 95 pr_x = np.asarray(pr_x, dtype='float32') 96 pr_y = np.asarray(pr_y, dtype='float32') 97 f1_arr = (2 * pr_x * pr_y / (pr_x + pr_y + 1e-20)) #F1 = 2 * (precision * recall) / (precision + recall) 98 f1 = f1_arr.max() 99 f1_pos = f1_arr.argmax() #从0~f1_pos条数据贡献了最好的f1 100 theta = test_result[f1_pos][1] #查看下那条测试结果的预测的关系的float值为多少 101 if input_theta==-1: 102 w = f1_pos 103 input_theta = theta 104 auc = sklearn.metrics.auc(x = pr_x, y = pr_y) 105 if not self.is_test: 106 logging('ALL : Theta {:3.4f} | F1 {:3.4f} | AUC {:3.4f}'.format(theta, f1, auc)) 107 else: 108 logging('ma_f1 {:3.4f} | input_theta {:3.4f} test_result F1 {:3.4f} | AUC {:3.4f}'.format(f1, input_theta, f1_arr[w], auc)) 109 if output: 110 # output = [x[-4:] for x in test_result[:w+1]] 111 output = [{'index': x[-4], 'h_idx': x[-3], 't_idx': x[-2], 'r_idx': x[-1], 'r': x[-5], 'title': x[-6]} for x in test_result[:w+1]] 112 json.dump(output, open(self.test_prefix + "_index.json", "w")) 113 # plt.plot(pr_x, pr_y, lw=2, label=model_name) 114 # plt.legend(loc="upper right") 115 if not os.path.exists(self.fig_result_dir): 116 os.mkdir(self.fig_result_dir) 117 # plt.savefig(os.path.join(self.fig_result_dir, model_name)) 118 pr_x = [] 119 pr_y = [] 120 correct = correct_in_train = 0 121 w = 0 122 for i, item in enumerate(test_result): 123 correct += item[0] 124 if item[0] & item[2]:#关系预测正确且在训练数据据中Ture 125 correct_in_train += 1 126 if correct_in_train==correct: 127 p = 0 128 else: 129 p = float(correct - correct_in_train) / (i + 1 - correct_in_train) 130 #不在训练集中的关系预测正确的关系三元组/不在训练集中的关系预测正确的关系三元组+在关系训练集中关系预测错误的关系三元组 131 pr_y.append(p) 132 pr_x.append(float(correct) / total_recall) 133 if item[1] > input_theta: 134 w = i 135 pr_x = np.asarray(pr_x, dtype='float32') 136 pr_y = np.asarray(pr_y, dtype='float32') 137 f1_arr = (2 * pr_x * pr_y / (pr_x + pr_y + 1e-20)) 138 f1 = f1_arr.max() 139 auc = sklearn.metrics.auc(x = pr_x, y = pr_y) 140 logging('Ignore ma_f1 {:3.4f} | input_theta {:3.4f} test_result F1 {:3.4f} | AUC {:3.4f}'.format(f1, input_theta, f1_arr[w], auc)) 141 return f1, auc, pr_x, pr_y 142 143 def testall(self, model_pattern, model_name, input_theta):#, ignore_input_theta): 144 model = model_pattern(config = self) 145 model.load_state_dict(torch.load(os.path.join(self.checkpoint_dir, model_name))) 146 model.cuda() 147 model.eval() 148 f1, auc, pr_x, pr_y = self.test(model, model_name, True, input_theta)
最后进行test:
testing (--test_prefix dev_dev for dev set, dev_test for test set): CUDA_VISIBLE_DEVICES=0 python3 test.py --model_name BiLSTM --save_name checkpoint_BiLSTM --train_prefix dev_train --test_prefix dev_test --input_theta 0.3601
1 parser = argparse.ArgumentParser() 2 parser.add_argument('--model_name', type = str, default = 'BiLSTM', help = 'name of the model') 3 parser.add_argument('--save_name', type = str) 4 parser.add_argument('--train_prefix', type = str, default = 'dev_train') 5 parser.add_argument('--test_prefix', type = str, default = 'dev_test') 6 parser.add_argument('--input_theta', type = float, default = -1) 7 # parser.add_argument('--ignore_input_theta', type = float, default = -1) 8 args = parser.parse_args() 9 model = { 10 'CNN3': models.CNN3, 11 'LSTM': models.LSTM, 12 'BiLSTM': models.BiLSTM, 13 'ContextAware': models.ContextAware, 14 # 'LSTM_SP': models.LSTM_SP 15 } 16 con = config.Config(args) 17 #con.load_train_data() 18 con.load_test_data() 19 # con.set_train_model() 20 con.testall(model[args.model_name], args.save_name, args.input_theta)#, args.ignore_input_theta)
参考:
Pytorch详解BCELoss和BCEWithLogitsLoss https://blog.csdn.net/qq_22210253/article/details/85222093
Tensorflow之batch的解释,采用yield方法解释 https://blog.csdn.net/r_m_aa/article/details/85316063
AUC值的计算 https://www.jianshu.com/p/50bd9def2224


 浙公网安备 33010602011771号
浙公网安备 33010602011771号