
【PostgreSQL 17】11 窗口函数
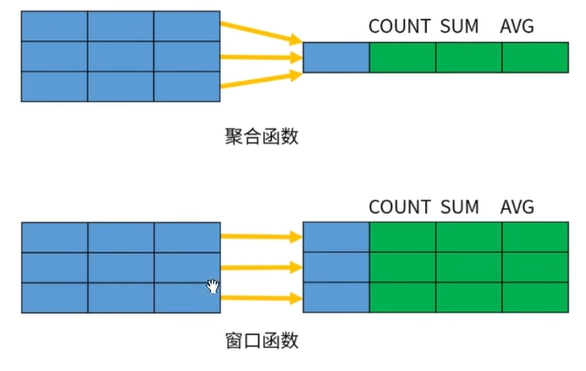
和聚合函数的区别
窗口函数不是将一组数据汇总为单个结果,而是针对每一行数据,基于和它相关的一组数据计算出一个结果。
直接这么写会报错,缺少GROUP BY
SELECT
employee_id,
first_name,
last_name,
salary,
AVG(salary)
FROM employees
;

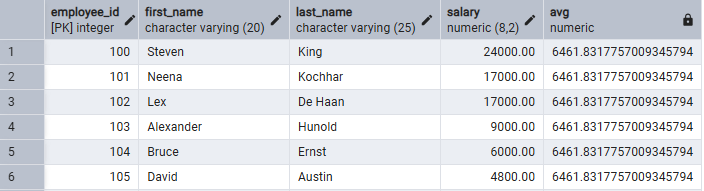
添加OVER()
空括号表示将所有数据作为整体进行分析,所以得到的数值和聚合函数一样。
SELECT
employee_id,
first_name,
last_name,
salary,
AVG(salary) OVER()
FROM employees
;
窗口函数的定义
window_function (expression, ...) OVER (
PARTITION BY ...
ORDER BY ...
frame_clause
)
分区选项 PARTITION BY
用于定义分区,作用类似于 GROUP BY。
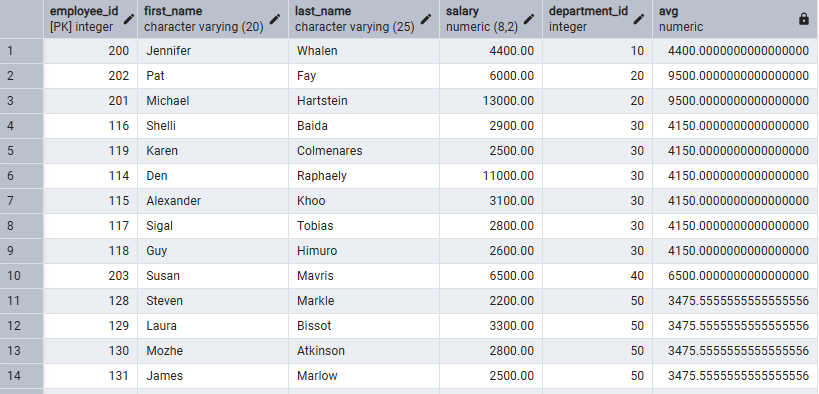
如下代码含义:基于不同部门,分别计算平均值。
SELECT
employee_id,
first_name,
last_name,
salary,
department_id,
AVG(salary) OVER(PARTITION BY department_id)
FROM
employees
;
排序选项 ORDER BY
指定分区内的排序方式
如下代码含义:在部门内部按salary降序排名
SELECT
employee_id,
first_name,
last_name,
salary,
department_id,
RANK() OVER(PARTITION BY department_id ORDER BY salary DESC)
FROM
employees
;

窗口大小
求累计和:从对应分区的第一行一直累计到当前行
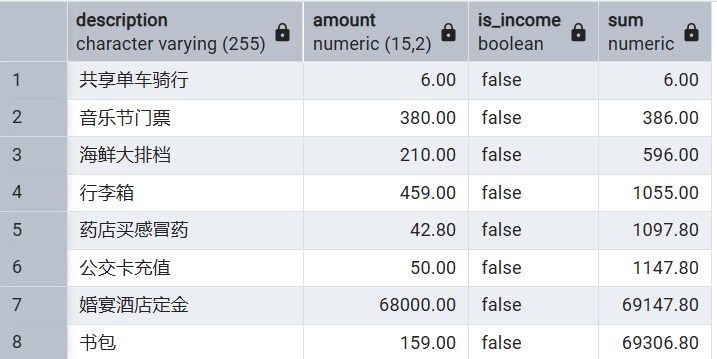
SELECT
description, amount, is_income,
SUM(amount) OVER(PARTITION BY is_income ORDER BY expense_time
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
FROM expenses
;
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW 是默认值,不加也可以有同样的效果。
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING 处理前面1行~后面1行
例如处理到这边第4行时,则计算3~5行
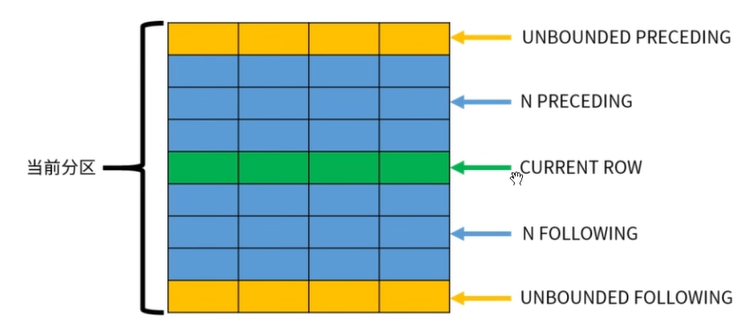
窗口选项 frame_clause
在当前分区内指定一个计算窗口。
指定了之后,分析函数不再基于分区计算,而是基于窗口内的数据进行计算。
例题:1321. 餐馆营业额变化增长
计算以 7 天(某日期 + 该日期前的 6 天)为一个时间段的顾客消费平均值。
-- 外层查询:获取最终结果,包含日期、7天总营业额和平均营业额
SELECT
DISTINCT visited_on, -- 去重后的访问日期
amount, -- 子查询计算的7天累计营业额
-- 计算7天平均营业额并保留2位小数
ROUND(amount::NUMERIC / 7, 2) AS average_amount
FROM (
-- 子查询:计算每个日期往前7天(含当天)的累计营业额
SELECT
visited_on,
-- 使用窗口函数计算滚动总和
SUM(amount) OVER (
ORDER BY visited_on -- 按日期排序
-- 定义窗口范围:当前行及之前6天(共7天)
RANGE BETWEEN INTERVAL '6 days' PRECEDING AND CURRENT ROW
) AS amount
FROM Customer -- 从顾客消费表获取数据
) t -- 子查询别名
-- 过滤条件:只保留有完整7天数据的日期
-- 即当前日期减去6天后的日期必须存在于表中
WHERE visited_on - INTERVAL '6 days' IN (SELECT visited_on FROM Customer)
ORDER BY visited_on; -- 按日期升序排列结果
聚合窗口函数
SELECT
*,
AVG(amount) OVER(),
SUM(amount) OVER(),
COUNT(*) OVER(),
MIN(amount) OVER()
FROM
sales_monthly
;
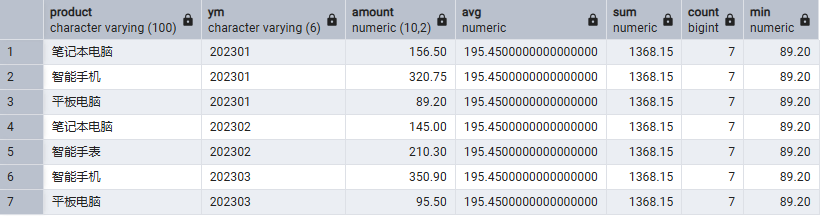
SELECT
*,
AVG(amount) OVER(PARTITION BY product),
SUM(amount) OVER(PARTITION BY product),
COUNT(*) OVER(PARTITION BY product),
MIN(amount) OVER(PARTITION BY product)
FROM
sales_monthly
;
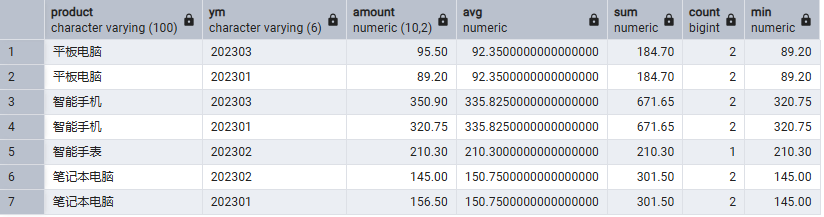
SELECT
*,
AVG(amount) OVER(PARTITION BY product ORDER BY ym),
SUM(amount) OVER(PARTITION BY product ORDER BY ym),
COUNT(*) OVER(PARTITION BY product ORDER BY ym),
MIN(amount) OVER(PARTITION BY product ORDER BY ym)
FROM
sales_monthly
;
加了ORDER会有默认值 ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW

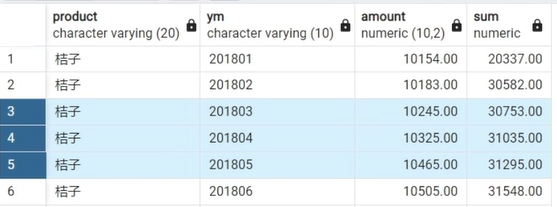
移动平均值
SELECT
*,
AVG(amount) OVER(
PARTITION BY product
ORDER BY ym
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING
)
FROM
sales_monthly
;
例:厂房温度检测器获取每秒钟的温度。计算前5分钟内的平均温度。
AVG(temperature) OVER(ORDER BY ts RANGE BETWEEN interval '5 minute' PRECEDING AND CURRENT ROW)
排名窗口函数
用于对数据进行分组排名。
ROW_NUMBER 为分区中的每行数据分配一个序列号,从1开始分配
RANK 计算分区内数据名次。名次相同的话后续排名会产生跳跃
DENSE_RANK 计算分区内数据名次。名次相同的话后续排名不会产生跳跃
PERCENT_RANK 以百分比形式显示名称,名次相同的话后续排名会产生跳跃
SELECT
description, amount,
ROW_NUMBER() OVER(PARTITION BY is_income ORDER BY amount DESC),
RANK() OVER(PARTITION BY is_income ORDER BY amount DESC),
DENSE_RANK() OVER(PARTITION BY is_income ORDER BY amount DESC),
PERCENT_RANK() OVER(PARTITION BY is_income ORDER BY amount DESC)
FROM expenses
;
简洁写法
SELECT
description, amount,
ROW_NUMBER() OVER w,
RANK() OVER w,
DENSE_RANK() OVER w,
PERCENT_RANK() OVER w
FROM expenses
WINDOW w AS (PARTITION BY is_income ORDER BY amount DESC)
;
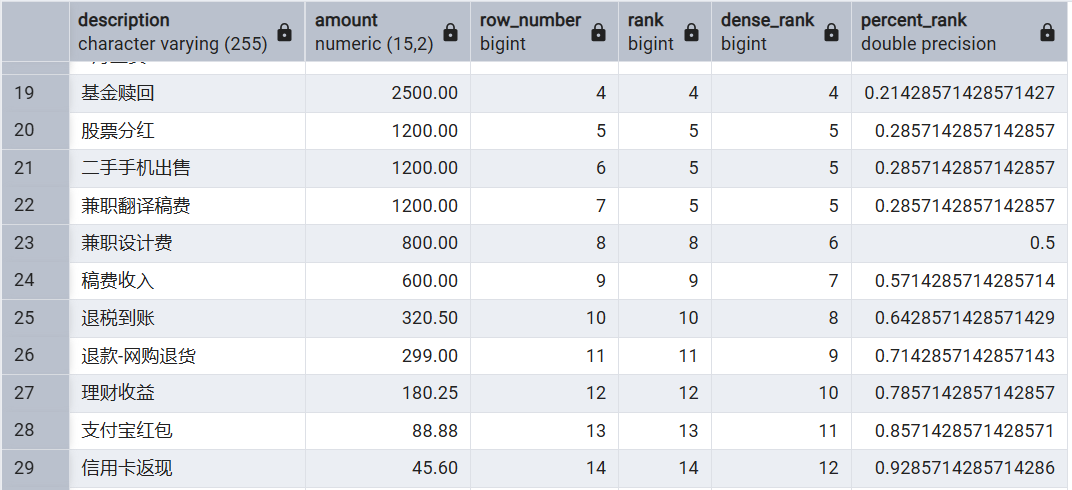
CUME_DIST: 计算每行数据在其分区内的累积分布,即该行数据及其之前的数据比率;取值范围大于0小于等于1。
NTILE:将分区内数据分为N等分,为每行数据计算其所在的位置。
SELECT
description, amount,
CUME_DIST() OVER w,
NTILE(5) OVER w
FROM expenses
WINDOW w AS (PARTITION BY is_income ORDER BY amount DESC)
;
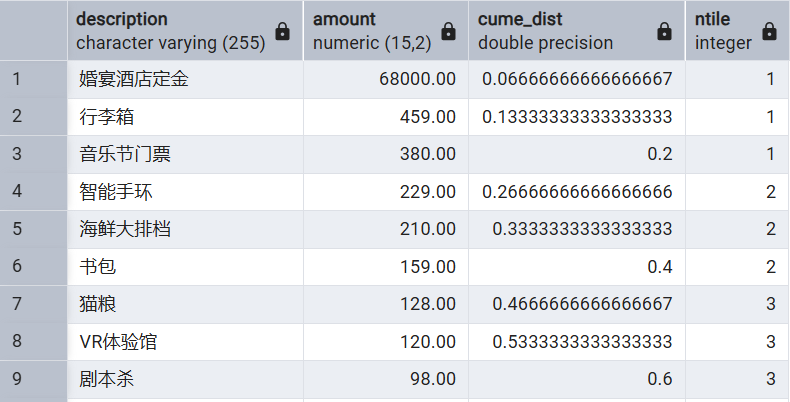
取值窗口函数
FIRST_VALUE 返回窗口内第一行数据
LAST_VALUE 返回窗口内最后一行数据
NTH_VALUE 返回窗口内第 N 行数据
SELECT
description, amount, expense_time,
FIRST_VALUE(amount) OVER(PARTITION BY is_income ORDER BY amount DESC),
LAST_VALUE(amount) OVER w,
NTH_VALUE(amount, 2) OVER w
FROM expenses
WINDOW w AS (PARTITION BY is_income ORDER BY amount DESC
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING)
;
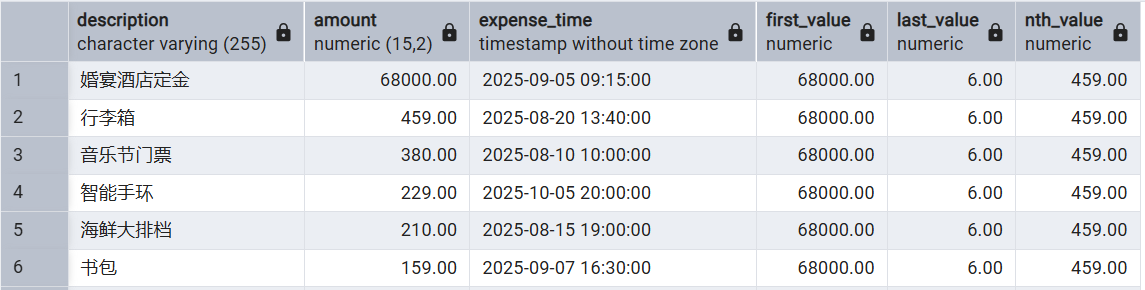
LAG 返回分区中,当前行之前的第 N 行数据
LEAD 返回分区中,当前行之后第 N 行数据
这俩不支持动态的窗口大小(frame_clause),而是以当前分区作为分析的窗口。
SELECT
description, amount, expense_time,
LAG(amount, 1) OVER w,
LEAD(amount, 1) OVER w
FROM expenses
WINDOW w AS (PARTITION BY is_income ORDER BY amount)
;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号