
林沁---第二次作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzzcxy/ZhichengSoftengineeringPracticeFclass |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzzcxy/ZhichengSoftengineeringPracticeFclass/homework/12532 |
| 这个作业的目标 | 通过自身学习,初步掌握网络爬虫技术 |
| Github 地址 | https://gitee.com/xi-guaqin/GoodsPUPU.git |
一、【必做】基础:使用 fiddler 抓包工具+代码,实时监控朴朴上某产品的详细价格信息
-
了解任务流程
在看到任务的第一眼,首先是迷茫,因为本身没有学习过python语言,并且从未了解过网上爬虫的任何信息。后只能经同学们的讨论中得知,python对于网上爬虫有着很好的效果,但是其他语言也不是不可以。于是我开始从爬虫最基本的步骤开始做起。首先就是抓包,从云班课上面下载下Fiddler的ppt文件,开始了解Fiddler软件的一些配置信息以及通过哔哩哔哩以及网上的教程来用Fiddler软件。
-
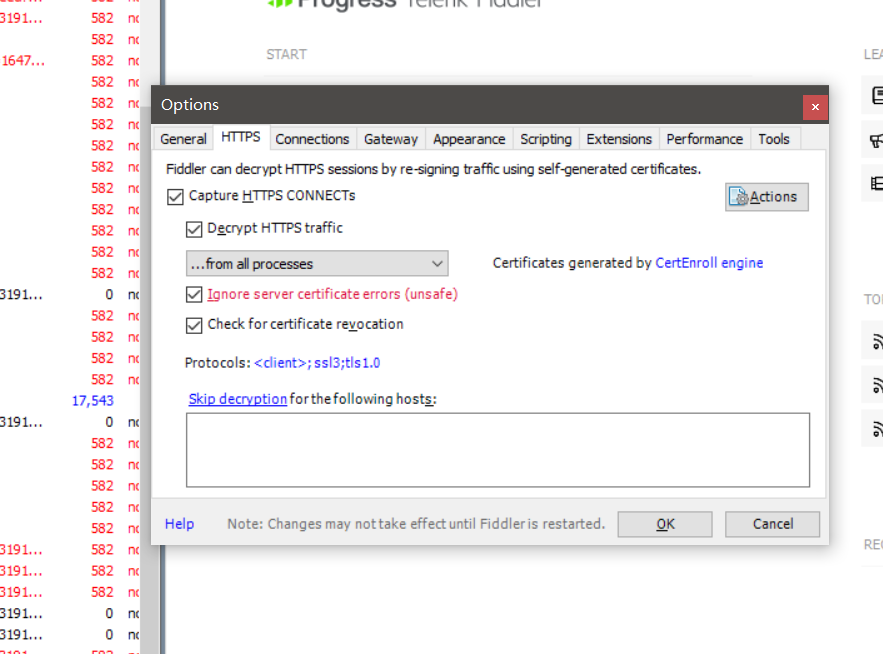
开始配置Fiddler软件
通过PPT了解到,需要完成配置如下图:
-
抓包
-
首先将校园网改成自己的热点(校园网网络与Fiddler代理冲突)
-
然后打开Fiddler
-
登入微信打开朴朴小程序中的商品链接

-
通过Fiddler软件的抓捕,得到该商品的网站以及头部文件
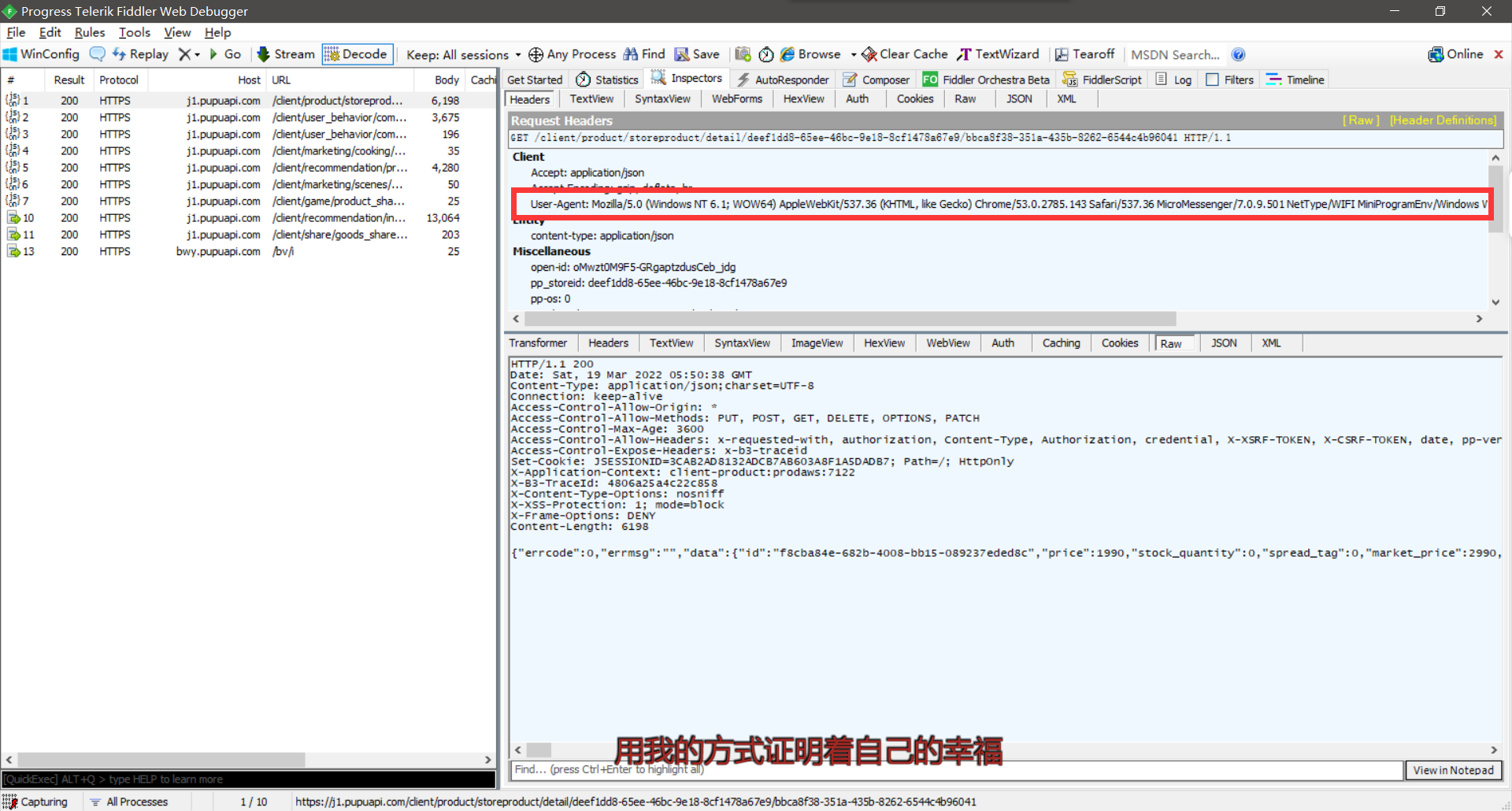
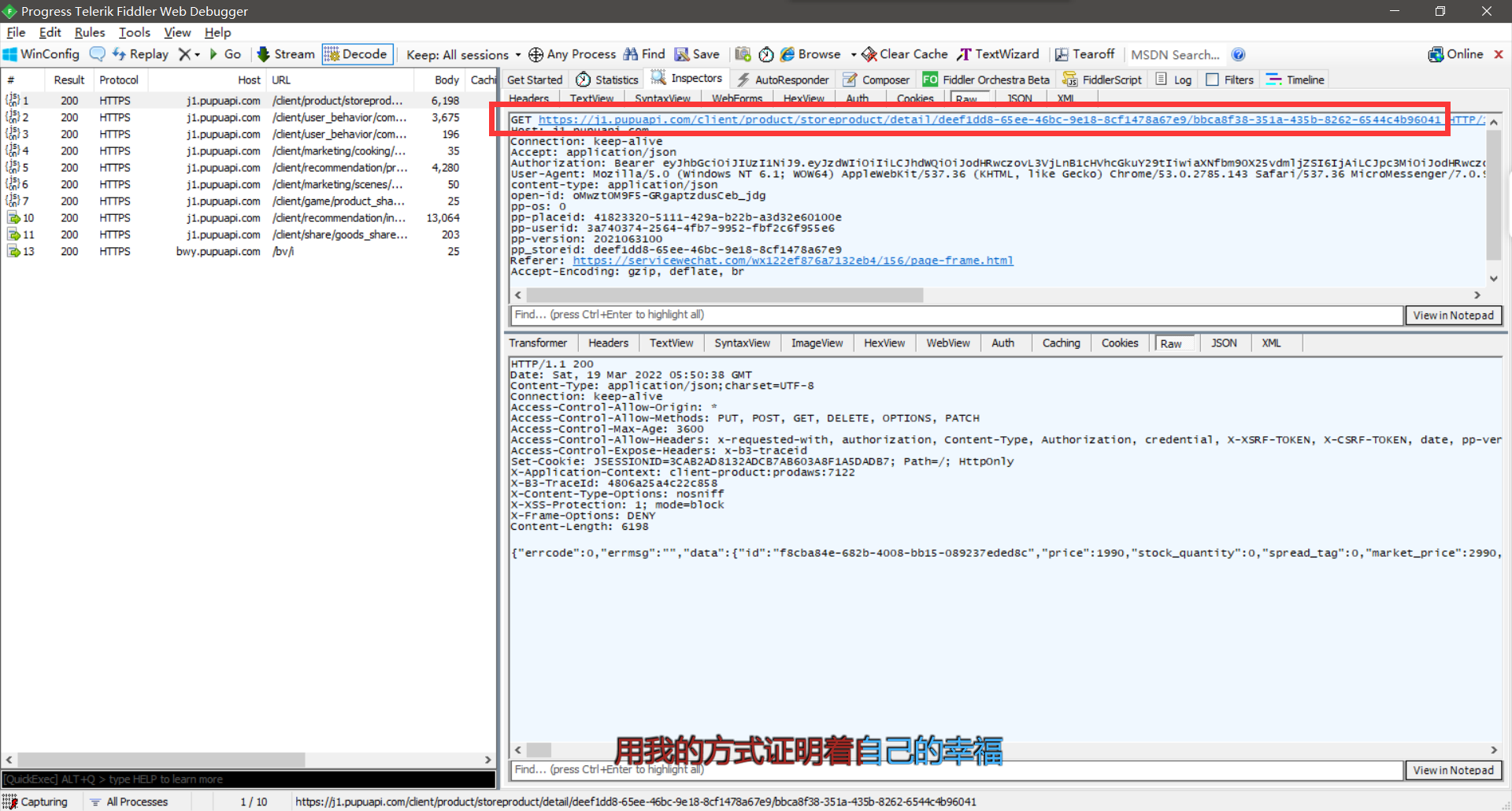
-
-
下定决心使用Java语言爬虫
抓包完毕后开始纠结使用python语言爬虫还是Java,python语言需要自己再进行学习,而Java语言并没有python语言爬取数据用起来方便,后来经过思考认为我们现在主学的是Java,应当先主要学好一门语言,最后选择了Java语言来进行爬虫。
-
开始网上翻阅有关Java爬虫方面的资料*
通过B站搜索,并且网上的翻阅,发现该博主的方法能够通过网站http获取到其中的信息:https://www.cnblogs.com/peachh/p/13658125.html 并且了解到JSON的能够对获取到的信息进行更深层次的解析。
-
开始实践
打开IDEA,先是登入上方网站进行代码的测试,成功得能够在控制台输出出需要爬取网站的内容,后进行将得到的String类型的网站内容无法解析成JSON格式的字符串内容,于是通过百度了解到

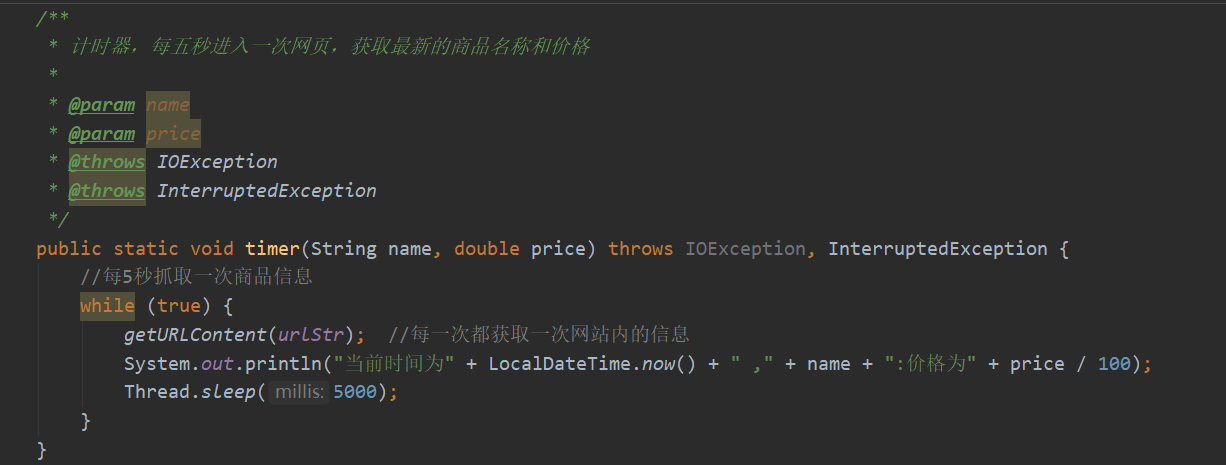
JSONSerializer.toJSON()能够完美的解决该问题。之后就是通过获取网站的data首部键值后相当于打开了网站信息的钥匙。通过作业内容我爬取出了商品名字信息、商品规格、商品价格、商品原价、商品详细信息等内容:

后根据计时器每五秒更新一次网站信息,获取实时价格:
-
主要代码展示
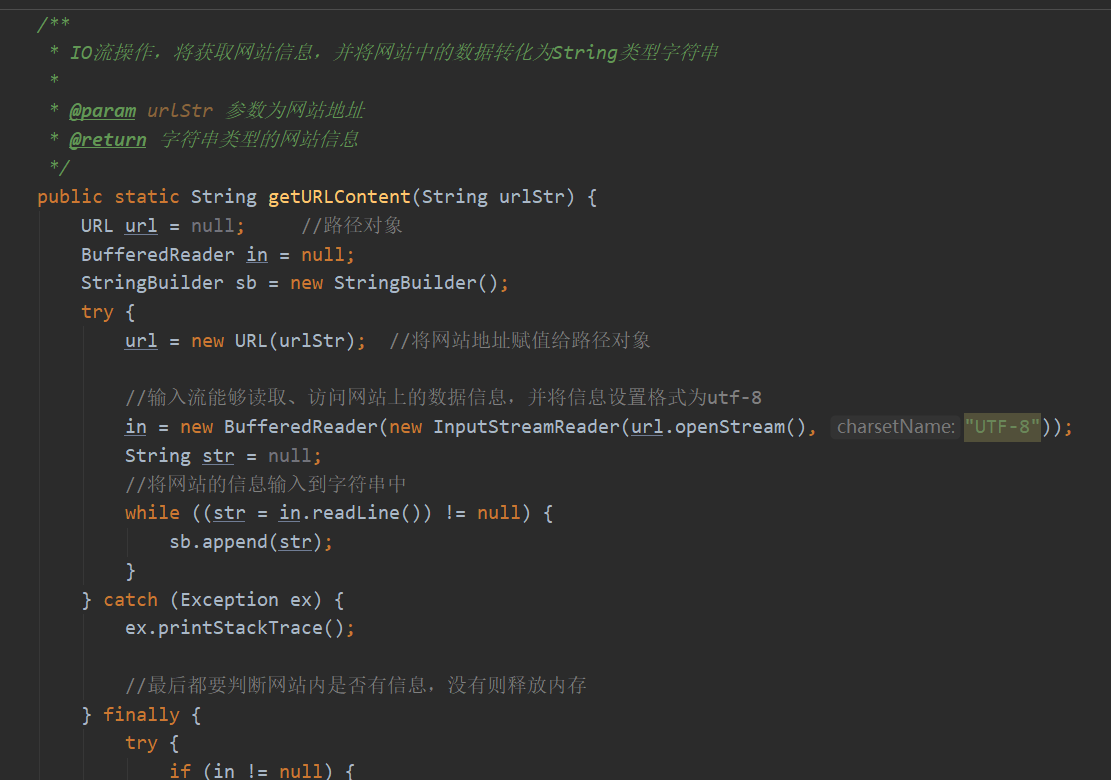

-
结果展示
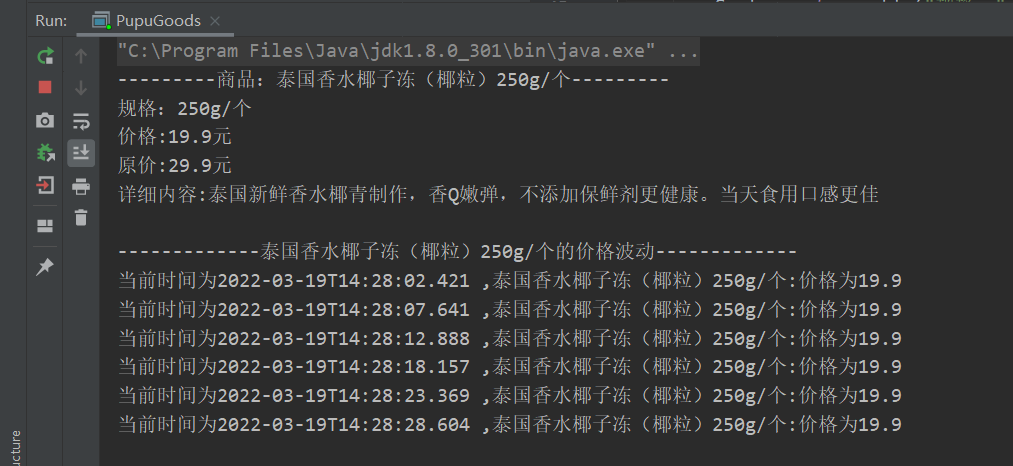
-
程序结构框架展示
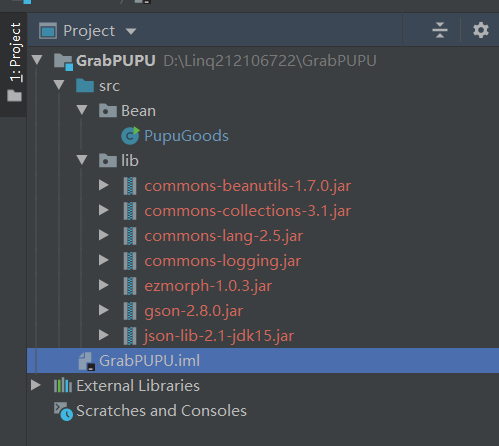
二、上传
-
采用gitee上传方式
此次采用gitee方式上传,通过IDEA连接gitee账号后将PupuGoods.java文件进行上传
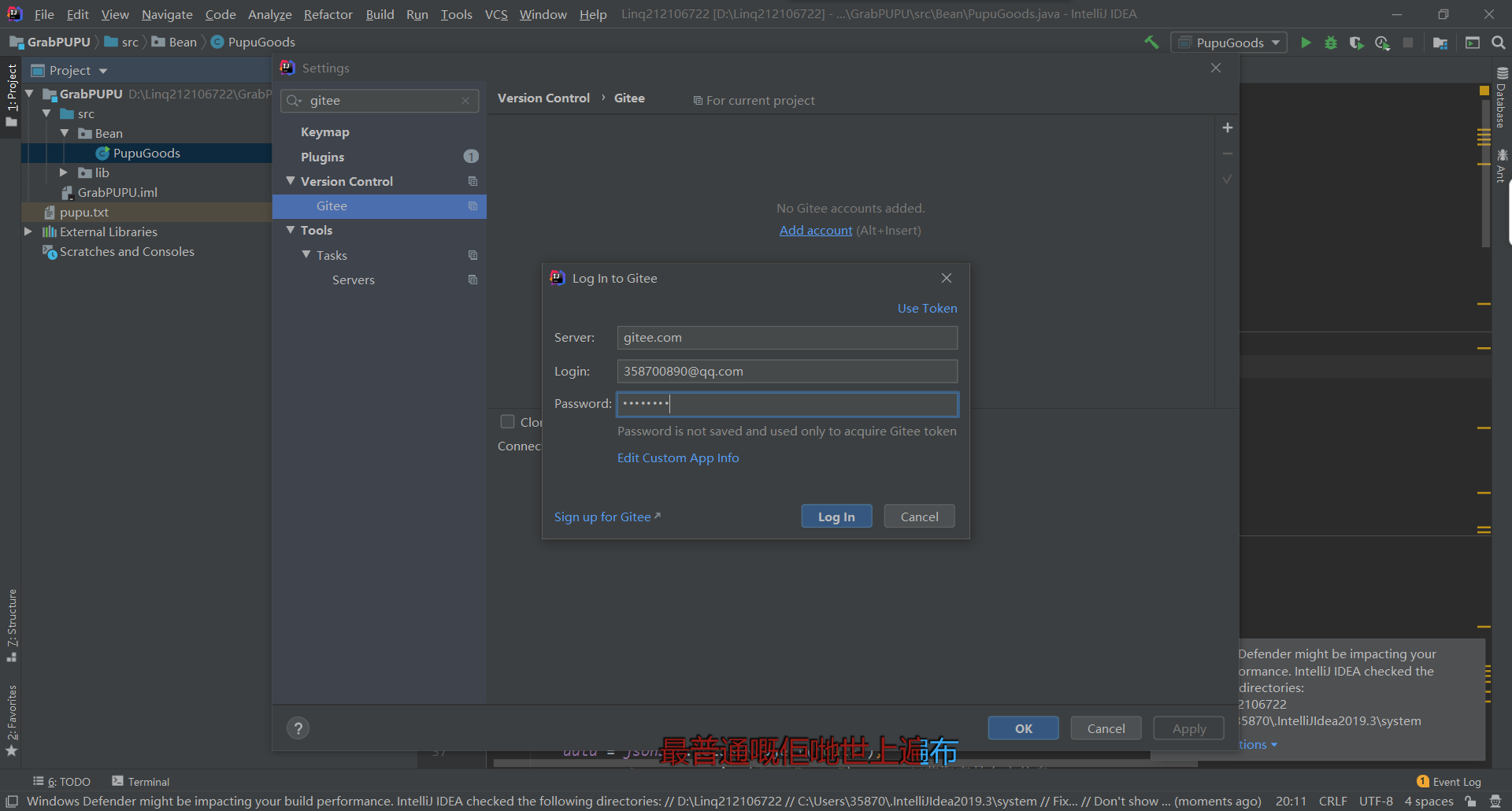
三、课后优化
本次作业只通过网站的http来对网站进行访问并且得到数据信息,但是没有通过User-Agent头部解密。后续如果需要再次访问更加机密的信息,可能就没法成功的进行访问。所以在课后,我认为需要改进代码,需要加上User-Agent,能够确保进入网站访问得到数据的可能性提高。
四、课后总结
本次作业通过自身学习,零基础开始学习网上爬虫技能。一开始是乏味的,畏惧的,毕竟在有限的课后时间里面需要做的事情太多太多,需要考证,需要继续打磨自身的Java代码水平,需要巩固课堂的知识……最后能够通过一步步得摸索,完成本次爬虫基础题,还是很自豪的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号