JAVA基础学习笔记
1.Java中new和Class.forName的区别
首先:
New = Class.forName("pacage.A").newInstance();
new是关键字,直接创建对象。
Class.forName()是一个方法,要求JVM查找并加载指定的类,类装载到虚拟机上之后,静态方法和静态块中的处理被执行。
这时候还没有创建对象。newInstance()是创建对象。
我们最常用的jdbc, 经常会用Class.forName来加载数据库驱动。
jdbc接口中,会存在各种数据库的驱动,不在在接口中写死,一般都写在配置文件里,
所以需要我们调用的时候通过Class.forName来加载驱动。这时候不需要创建对象,所有没有调用newInstance()。
2.遍历循环
1)for循环
for循环用于遍历数据。可用于一遍一遍的循环处理数据,直到获得期望的结果。
比如,冒泡排序的两次遍历,第一次遍历找到最大值,之后使用外层for循环一遍一遍遍历,找到每一个次级的最大值。
注意:内循环和外循环的遍历次数可以通过定义两个指针控制。比如,往数组中添加元素时候的用法。
1)for循环和while的使用区别
for:知道遍历的次数。while:不知道遍历的次数。
2)while和do while
while语句是先判断是否满足条件,满足的话就执行循环语句。执行完循环语句之后,再判断一次while条件,通过后再执行一遍。#while(true){}
do while语句是,不管条件如何,先执行循环代码。之后判断while条件语句,通过的话,再执行一遍。#do{}while(true);
3.数据类型
1)char类型
char 在Java中是2个字节。Java采用unicode,2个字节(16位)来表示一个字符。
Java中没有数据库中的varchar类型,string和varchar相同。包括null和“”的意义。
2)int类型和double类型除法
int intTest=44;
double result1=intTest/10;
double doubleTest=44;
double result2=doubleTest/10;
System.out.println(result1+" and "+result2); //the result is 4.0 and 4.4
3)null和空字符串的区别
String str = null ; 表示声明一个字符串对象的引用,但指向为null,也就是说还没有指向任何的内存空间;
String str = ""; 表示声明一个字符串类型的引用,其值为""空字符串,这个str引用指向的是空字符串的内存空间;
八种基本数据类型
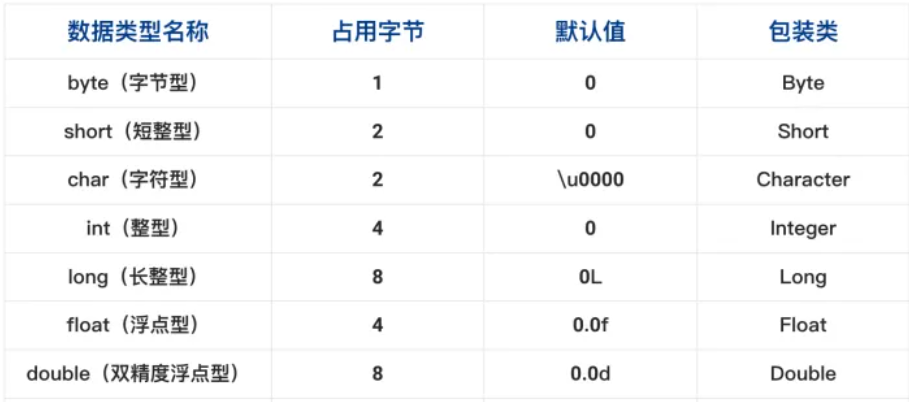
注:
Java是面向对象语言,其概念为一切皆为对象,但基本数据类型是个例外
基本数据类型大多是面向机器底层的类型,它是“值” 而不是一个对象,对于声明在方法中的基本类型变量,它存放于“栈”中而不是存放于“堆”中。
这有很多好处,例如不需要和对象一样需要在堆中分配内存,然后搞个引用指向它。不需要GC,因为是直接在栈上分配空间,方法运行结束就出栈回收掉了。
可以放心的使用最基本的运算符进行比较和计算等等。
没有什么是完美无缺的,数据类型也有缺点,例如会自动设置默认值(这是双刃剑,一些场景下会增加额外的处理逻辑),不支持泛型等。
Java希望使用一切皆为对象的理念来统一语言设计,但基本类型确实有很多优点和使用场景,鱼和熊掌我就要兼得之!
所以它为每一个基本类型都提供了相应的包装类,封装了很多实用的方法,最重要的是,提供了自动装箱和自动拆箱的语法糖,
让开发者可以无感知的在包装类型和基础类型之间来回切换。
4.数组
数组是引用类型。array1=array2的意思是两个数组指向了堆内存中同一值。
person p1=p2
5.形参和实参
引用类型传递的是值地址,可以通过形参影响实参。
基本类型传递的是值,形参影响不了实参。
class ComPractice{
public static void main(String[] args) {
int arr[]={1,2,3};
System.out.println(arr[0]);//1
ArayClass arrayCl = new ArayClass();
arrayCl.arrayTest(arr);
System.out.println(arr[0]);//200
}
}
class ArayClass{
public void arrayTest(int[] arr){
arr[0]=200;
}
}
下面的例子中,在方法中把对象=null,意味着在方法内切断了指向堆中的值地址,并没有清空小王指向的在堆中的具体值。
class ComPractice{
public static void main(String[] args) {
Persion xiaowang=new Persion();
PersionChange PChange=new PersionChange();
xiaowang.age=21;
System.out.println(xiaowang.age);//21
PChange.change(xiaowang);
System.out.println(xiaowang.age);//21
}
}
class Persion{
int age;
String name;
}
class PersionChange{
public void change(Persion a){
a=null;
}
}
6.递归
递归就是方法嵌套方法,一直执行到最后参数的方法,然后顺次往外返回方法中获得的值。#就像套娃一样。
采用递归方式,需要有一个已知数值,这个数值是最终参数执行方法的计算结果。这个结果作为最内部的套娃。
public class Recursion{
public static void main(String[] args) {
PeachTest Pt= new PeachTest();
int peachNum=Pt.peachMethod(8);
System.out.print(peachNum);
}
}
//小猴子吃桃子。每天吃掉所剩桃子的一半,之后再多吃一个。
class PeachTest{
public int peachMethod(int day){
int peachNum=0;
if(day==10){
peachNum=1;
}
else{
peachNum=(peachMethod(day+1)+1)*2;
}
return peachNum;
}
}
7.作用域
| 本类 | 子孙类 | 同一package | 其他package | |
| public | ✔ | ✔ | ✔ | ✔ |
| protected | ✔ | ✔ | ✔ | |
|
friendly(不写时候默认) |
✔ | ✔ |
|
|
| private | ✔ |
类的属性(全局变量)可以不设定初始值,直接使用即可,因为有默认值。
方法中的变量(局部变量)必须得赋值,之后才能使用,因为没有默认值。
class Persion{
int i;
public void Ptest(){
System.out.println("i is "+i);
}
public void vertest(){
int t=1;
int f=0;
System.out.println("t is "+t);
System.out.println("f is "+f);
}
}
8.==和equals的区别
==是判断两个变量或实例是不是指向同一个内存空间,equals是判断两个变量或实例所指向的内存空间的值是不是相同。
==是指对内存地址进行比较 , equals()是对字符串的内容进行比较。
==指引用是否相同, equals()指的是值是否相同
10.构造器
创建有参构造器,将覆盖无参构造器。
9.继承
1)子类在执行自己的构造器之前,先执行父类的构造器。
2)在子类中使用super()来调用父类的构造器。默认调用父类的无参构造器。有参构造器必须使用super(a,b)显式的调用。
3)super()使用的时候必须放在构造器的第一行。
4)父类构造器调用不限于直接父类,将一直往上追溯到Object类(最上级父类)。
5)父类的非私有方法可以被子类的对象看到和执行,非私有属性会被子类继承。需要使用公有方法调用私有方法或是属性,来暴露私有方法或属性。
6)子类必须调用父类的构造器,完成父类的初始化。
7)子类和父类中有相同名字的字段的话,先调用子类的该字段的值。子类中没有的所调用的字段的话,依次往父类追踪该字段。
8)this(参数)和super()不能同时存在。因此以下实例中,B(String name){}中隐式调用super(),
原因是无参构造器中有了tihs,因此不能隐式调用super。那super的调用变成了有参构造器。
class B Extends A{
B() {this("abc");System.out.println("b")}
B(String name){System.out.println("b name")}
}
9)创建对象的时候,括号内带的参数,是因为定义了有参的构造函数。该构造函数将数值传递到类中,用于处理使用。
10.方法重写(Override)
1)子类的方法的参数和名称要和父类的相同。
2)子类方法的返回类型和父类方法的返回类型一样,或者是父类返回类型的子类。
比如 父类 返回类型是object,子类方法的返回类型是String。
3)子类方法不能缩小父类方法的权限。
比如,父类的修饰符是public,子类的修饰符不能使protected。(编译不会通过)
方法重载(overload)和方法重写(Override)的比较
| 名称 | 发生范围 | 方法名 | 形参列表 | 返回类型 | 修饰符 |
| 重载 | 本类 | 必须一样 | 类型,个数或者顺序至少有一个不同 | 无要求 | 无要求 |
| 重写 | 子类 | 必须一样 | 一致 | 一致或父类返回类型的子类 | 子类不能缩小父类权限。可以增大 |
・多态有方法的多态。#方法重载和方法重写都是方法多态的表现
・对象的多态。
1)向上转型
多态本身是子类类型向父类类型向上转换的过程,这个过程是默认的。当父类引用指向一个子类对象时,便是向上转型。
使用格式:
父类类型 变量名= new 子类类型();
如:Animal a = new Cat( );
上转型对象可以操作和使用子类继承或者重写的方法。
调用方法的时候先调用子类中override的方法。子类中没有的话,追溯到父类中的该方法。可以调用父类中的所有成员(属性和方法)。(要遵守访问权限)
Animal A = new Dog();该例子中,A.feed();执行的是子类中的方法。
※当调用对象属性的时候,没有动态绑定机制,哪里声明就在哪里使用。
上转型对象丧失了对子类新增成员变量或新增的方法的操作和使用。
#因为在编译阶段能调用哪些成员,编译器已经帮助定义好了。
2)向下转型
父类类型向子类粪型向下转换的过程,这个过程是强制的。
一个已经向上转型的子类对象,将父类引用转为子类引用,可以使用强制类型转换的格式,便是向下转型。
使用格式:
子类类型变量名= (子类类型)父类变量名;
如:Cat c =(Cat)animal;
3)instanceof运算符
为了避免classCastException的发生,Java提供了instanceof 关键字,
给引用变量做类型的校验,只要用instanceof判断返回true的,那么强转为该类型就一定是安全的,不会发生classcastxception异常。
public class Test {
public static void main(String[] args) {
//向上转型
Animal a = new Cat();
a.eat();//调用的是Cat 的eat
//向下转型
if (a instanceof Cat){
Cat C = (Cat)a;
c.catchMouse();//调用的是 Cat的catchMouse
}else if (a instanceof Dog){
Dog d = (Dog)a;
}
}
d.watchHouse();//调用的是Dog的watchHouse
12.静态方法和静态变量
1)静态方法中不能使用非静态属性和方法。
2)非静态方法中可以使用所有。包括静态和非静态。
3)静态方法中不能使用和对象相关的关键字,比如:this,super:(直接使用类名点就可以)
4)静态变量在JDK8以前是在方法区里,JDK8以后是在堆里的这个类对应的class对象的最后。
5)如果在构造函数内给静态属性赋值,不创建对象的话,静态方法的值,不会改变。
因为只有在类加载的时候才会执行构造函数。类名调用静态方法的时候构造函数还没有执行。

14.static 和final
static 和final一起使用性能较好。加上final的话,类不加载,只调用常量。
测试类
在测试类中调用静态成员
public class Test {
public static void main(String[] args) {
System.out.println(FinalDetail.test_value);
}
}
static和final一起使用的时候,只输出100。
去掉final的时候,会输出100和"把我打印出来"。
public class FinalDetail {
public static final int test_value = 100;
static {
System.out.println("把我打印出来");
}
}
15.抽象方法
抽象方法不能和Private、final、static来修饰,因为这些关键字都和重写相违背。
16.接口中的成员属性
interface A{
int x=0 // 相当于在 public static final int x = 0;
}
当实现的接口和继承的类中有相同的成员变量的话,在子类中调用的时候需要明文化调用。
调用接口中的成员变量,接口名字直接点出成员变量即可。使用super的方式调用父类的成员变量。
17.内部类
如果定义类在局部位置(方法中/代码块) :(1) 局部内部类 (2) 匿名内部类
定义在成员位置: (1) 成员内部类 (2)静态内部类
1)每个内部类都可以独立的继承一个类,所以无论外部类是否继承了某个类,内部类依然可以继承其他类,这就完美的解决了java没有多继承的问题。
2)可以有效的将有一定关系的类组织在一起,
3)又可以对外界有所隐藏。
4)方便编写事件驱动程序 方便编写多线程代码
#还是不理解,把代码搞得这么复杂真有价值吗 。
匿名内部类
匿名内部类可以使你的代码更加简洁,定义一个类的同时对其进行实例化,它与局部内部类很相似,
不同的是它没有类名,如果某个局部类你只需要使用一次,那么就可以使用匿名内部类。
animal northTiger = new animal() {};animal是接口,一般情况下new animal()形式会有语法错误,但是后面跟着{};的话就是内部匿名类的写法。
可以在{}内部实现接口的方法。JVM内部会自动定义一个名为OutClass$1的类。
class OutClass{ animal northTiger = new animal() { @Override public void cry() { System.out.println("老虎会叫"); } }; Tiger eastTiger = new Tiger("东部虎"){ public void eat(){ System.out.println("我是大老虎,我要吃肉,哈哈"+name); } }; } interface animal{ void cry(); } class Tiger{ String name; Tiger(String name){ this.name = name; } public void eat(){ } }
内部匿名类的实际使用
在本例中,如果不适用内部匿名类的话,需要Cellphone类中定义两个方法alarmClock,一个输出“懒猪起床了 ”,另一个输出“小伙伴到时间了”。
创建Cellphone类的对象之后,在需要的时候调用不同的方法。这样的坏处是,如果将来增加闹钟种类的话,需要修改Cellphone类。
使用内部匿名类的话,可以在不修改Cellphone类的前提下,根据需要创建Bell类型的参数。
实现步骤如下:
1.定义Bell接口,创建ring方法作为规范。
2.定义Cellphone类,类内部的方法使用Bell接口作为参数。
3.在main方法中创建Cellphone类的对象,并调用ring方法。#需要给方法传递参数。
4.给ring方法传入匿名内部类,在类中重写ring方法。
(可以理解为,给ring方法传入一个Bell类型的对象。该对象的类实现了Bell接口,并重写了ring方法)
public class InnerClassExercise { public static void main(String[] args) { Cellphone cp = new Cellphone();//给ring方法传入匿名内部类,在类中重写ring方法。 cp.alarmClock(new Bell() {//可以理解为,给ring方法传入一个Bell类型的对象。该对象的类实现了Bell接口,并重写了ring方法
@Override public void ring() { System.out.println("懒猪起床了 !"); } }); cp.alarmClock(new Bell() { @Override public void ring() { System.out.println("小伙伴到时间了,快去上学!"); } }); } } interface Bell{ void ring(); } class Cellphone{ void alarmClock(Bell b){ b.ring(); } }
成员内部类
1)多重继承。Java 提供的两种方法让我们实现多重继承:接口和内部类。

内部类可以继承一个与外部无关的类,从而保证内部类的独立性,正是这一点,多重继承才得以实现。
从实现代码和输出结果可以发现,儿子继承父类,变得比父亲更加强壮;同时也继承了母类,只不过友好指数下降。
内部成员类的调用方式有两种(Person外部类,Man内部类):
1.Person.Man M = person.new Man();//Person类的对象点new 内部类。
2.Man getinnerClass(){ return new Man(); }//在外部类中写一个创建内部类的方法。
person.getinnerClass().ai();
18.异常处理
1) try/catch/finally:程序员在代码中捕获发生的异常,自行处理。
try{
捕获异常,当异常发生时系统将异常封装成Exception对象e,传递给catch。
}catch(Exception e )
{得到异常之后程序员自己写如何处理。比如,报出异常信息。System.out.print("异常信息:"+e.getmessage())。不发生异常的时候,catch内的代码不执行。
}finally{
不管是否抛出异常都执行该区域的代码。所以通常将释放资源的代码放到finally内。
}
2)throws:
发生异常之后会逐级往上Throw。可以选择处理最下层方法抛过来的异常。如果最终抛给main方法的话,main方法将会交给JVM,抛出异常信息,程序终止。
try catch的最佳实践
判断输入的数值是否是整数。
是整数的话,就会break出去。不是的话就会抛出异常(进catch)。这样就会在while循环内无限执行,直到输入整数。
知识点1:使用while做无线循环,break跳出。
知识点2:Integer.parseInt(Str),将整型数据Integer转换为基本数据类型int。Integer.parseInt(”3“)+1=4。”3“+1=31;
知识点3:有异常进catch,程序不终止,留下log之后,继续执行。

19.自定义异常类
知识点1:继承Exception或它的子类,自定义异常类。在里面写想要的信息,目前还没有理解具体价值是什么。大概是出现问题时方便调查吧。
知识点2:关于throw new AgeException,Throwable的子类可以使用throw关键字,其他类不可以。

20.枚举
枚举的优点:
・增强代码可读性,枚举可以让你代码看起来很舒服,而且常量统一管理起来,当项目很大的时候很容易管理。
・传递参数错误,可以减少参数传递的错误性。
1)使用关键字enum代替class。
2)public static final Person ZHANGSAN = new Person("zhangsan",20);直接使用ZHANGSAN("zhangsan",20)代替。
3)有多个常量名字的话,使用逗号隔开。
4)将定义常量对象写在最前面。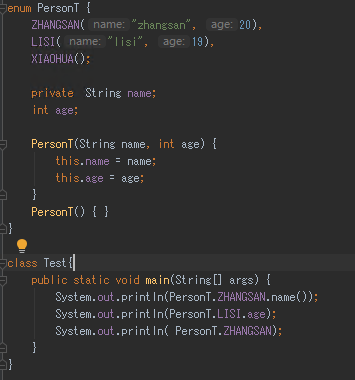
1)该段代码的输出结果为1.0。因为在三元运算符中输出的结果以精度高的为准,在该运算符中Double的精度大于Integer所以输出1.0。

2)在包装类中实际是在底层使用Integer.valueOf()方法进行比较,如果值在-128 ~ 127之间,那么取存放在内存里的值,在内存中只存了-128~127之间的数值。
如果不在-128~127范围内的话,在valueOf方法中,是New一个Integer。这样I3和I4比较就相当于两个对象比较,因此结果为false。

Integer.JAVA中的代码:

3)输出结果是true的因为是,P1.name的数值和P2.name的数值都指向了存放在静态变量池中的“nametest”。
4)被方法内修改的数据

22.String和StringBuffer
String保存的是字符串常量,不能进行变更。每次变更相当于更改地址。效率较低。
String实际上是在堆中创建一个value,并在静态变量池内创建字符串,Value指向静态变量池中的字符串。
每次String发生变化的时候,会在静态变量池内生成新的字符串,将Value指向新的字符串。
StringBuffer字符变量,里面的值可以更改。
StringBuffer的实质是在堆中创建了一个char数组类型的vaule,每次更新Stringbuffer的值实际上都是在更新数组的内容,
在堆中的地址没有变化,因此是实质意义上的更新,因此和String相比,效率较好。
String,StringBuffer,Stringbuilder的使用区别
Sting是不可变字符序列,因此效率最低,但是复用率高。适合字符串修改较少,被多个对象引用,比如配置信息等。
1)如果试图改变String的内容,其实是重新创建一个字符串。
2)比如第一次定义一个Sting A = “abc”因为会存到静态变量池中,因此创建B=“abc”的时候,不会创建一个新的abc,会使用静态变量池里已经有的abc)
StringBuffer是可变字符串,效率较高,线程安全。适合多线程的时候使用。
Stringbuilder是可变字符串,效率较高,线程不安全。适合单线程的时候使用
23.线程
线程有两种实现方式:
1)继承Thread类。创建对象后,调用start方法。
2)因为Java只能单继承,因此通过实现Runnable接口,借助Thread类,通过代理模式,执行run方法。
start0()是实现多线程的方法。start0是Native方法(本地方法),是JVM调用,底层是C/C++实现。
private native void start0();
在main方法中直接调用run方法是无效的,run方法内的处理会在main的线程中处理。必须使用Thread.start()。

24.线程-互斥锁
1.JAVA语言中引入了对象互斥的概念,来保证共享数据操作的完整性。
#下记代码中,多个据点同时售票的话,会出现剩余票数混乱的问题,会超卖,导致剩余票数为负数。
这时可以使用互斥锁,当一个据点(线程)占用对象的时候,让其他据点让路。
2.使用关键字synchronized来实现互斥锁。当某个对象被synchronized来修饰时,表明该对应在同一时刻只能被一个线程访问。
#在main方法中,如同被注释掉的部分,如果每个线程创建一个对象的话,不能实现同步代码的作用。因为形成了一个线程=一个对象的状态,谈不上线程之间互斥。
3.同步的局限性“导致程序的执行效率低。
4.同步的方法(非静态)的锁可以是this,也可以是其他对象,但是要求是同一对象。
#synchronized(this){ }的写法同步代码块。
5.同步的方法(静态)的锁为当前类本身。锁对象为当前类.class。
#下记代码例子中,如果run是静态方法的话(当然run是实现接口方法,假如是静态方法的话),synchronized(this)会出错,需要写成synchronized(TicketBy.class)。
总结:访问静态方法syn相当于锁了当前的类。而非静态方法是相当于锁的是当前实例对象。
6.实现的落地步骤:1)分析需要上锁的代码。2)选择同步代码块和同步方法。3)要求多个现场的锁对象为同一个即可。


处理数据量较大的时候int型和decimal型位数不够,处理不了。
可以使用BigInteger和BigDecimal,Bigteger用于较大的整数。BigInteger用于精度较高的浮点型。
都有相对应的加减乘除的方法。实现原理是在类内部把数字转换成字符串进行处理。
因此是new BigInteger(“12345678999999”)的写法。
26.增强for循环和迭代器
掌握两种循环的写法。
27.集合
1)ArrayList和LinkList的比较
| 底层结构 | 增删效率 | 改查效率 | |
| ArrayList | 可变数组 | 较低(数组扩容) | 较高 |
| LinkList | 双向链表 | 较高(通过链表追加) | 较低 |
#两者都是非线程安全。
2)HashSet
・HashSet实现了Set接口,HashSet实际上是HashMap。在源码中是这样写的。public HashSet() { map = new HashMap }
HashMap底层是(数组+链表+红黑树)。
・HashSet中不能有重复元素或对象。可以存放null,但是同样不能存放两个null
・HashSet不博征元素是有序的,取决于hash后,在确定索引的结果。
・链表的数据达到8个以上的话,就形成了红黑树。
【关于数据+链路】

3)HashSet.add()判断两个数据/对象是否相同
内部逻辑是先看两个对象的HashCode是否一样,如果不同的话,处理结束,判断可以往HashSet里添加数据。
如果HashCode相同的话,equals方法判断数据是否一样,不一样的话,判断可以往HashSet里添加数据。一样的话,处理结束,不往HashCode里添加数据。
HashCode()和equals()在HashSet.add()被执行的时候在父类中被调用,基于动态调用机制,执行被添加对象的类中的实体方法。
#如果下面实例中的age的类型是自定义类型的话,需要在该自定义类中重写HashCode()和equals()。
添加重写HashCode()和equals()的快捷键:ALT+Insert,之后选择equals()。或鼠标右键选择Generate;

4)Map
Map用于保存句有映射关系的数据,Key-Value。如果Key值相同就相当于Value值替换,下面的事例,li会覆盖zhang。
Map map = new Map;
map.put("no1","zhang");
map.put("no1","li");
★Map.Entry entrySet★
Map是java中的接口,Map.Entry是Map的一个内部接口。此接口为泛型,定义为Entry<K,V>。
它表示Map中的一个实体(一个key-value对)。接口中有getKey(),getValue方法。
Map提供了一些常用方法,如keySet()、entrySet()等方法,keySet()方法返回值是Map中key值的集合;
entrySet():将原有Map集合中的键值作为一个整体返回Set集合,此集合的类型为Map.Entry(内部接口)。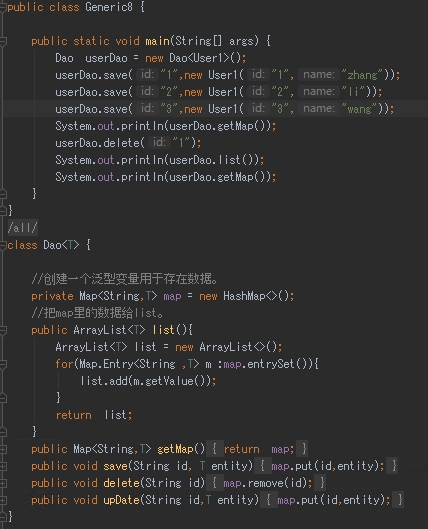
5)ArrayList,HashMap,LinkList的使用场景区别
28.关于Hash
Hash的主要优点是,它可以用于在相对较小的空间中存储任何大小的数据。
数据存储在“Hash表”中,它是数据值的集合,每个值都分配有唯一的键。当你想要检索数据时,你只需提供键,Hash表就会查找关联的值。
Hash的主要缺点是,如果你不知道用于存储数据的确切密钥,则可能难以检索数据。
如果你正在尝试恢复丢失的数据,或者如果你想找到所有符合特定标准的数据,这可能会成为一个问题。
此外,如果两条数据具有相同的键,则Hash表中只会存储一个,从而导致数据丢失。
Hash结构主要应用于以下场景:购物车,计数器,存储对象变化频繁的等场景。
29.泛型
泛型又称参数化类型,解决数据类型的安全性问题。ArrayList<String> arrayList = new ArrayList<String>();
ArrayList arrayList = new ArrayList();的默认泛型是Object。
泛型必须适应引用类型,不能用基本数据类型。Integer可以,int不可以。
泛型的作用是:可以在类声明时通过一个标识表示类中某个属性的类型。
下面示例中的E表示name的数据类型,该类型在定义Person的时候,即在编译期间,就确定E是什么类型。
1)泛型不具备继承性。
List<Object> list = new ArrayList<String>();因为不具有继承性,因此这种写法是错误的。
2)<?>支持任意泛型类型。public static void methodA (List<?> a){ }。可以接受任意类型的参数。
3)<? extend A> 支持A类以及A类的子类,规定了泛型的上线。public static void methodB (<? extend A> a){ }。可以A类的以及A类的子类。
4)<? super A> 支持A类以及A类的父类,不限于直接父类,规定了泛型的下限。
public static void methodC(<? super A> a){ }。可以A类的以及A类的父类。
★泛型练习★
知识点:
1)使用sort排序。Collections.sort或者employee.sort。
2)使用sort方法,通过Comparator内部类,重写compare方法自定义排序的规则。sort方法的两个参数,一个是需要排序的list,另一个是Comparator内部类。
想用哪个项目做排序,就在compare中对这个项目做大小比较,比较的结果传递给sort方法,进行排序。
在compare的源码中:
当compare的返回值小于0时,会将 t2 和 t1 (compare()中的两个参数)交换顺序,大于等于0不会变换顺序;可根据具体的排序需求来决定是否让他们交换顺序。
3)将年月日的比较处理封装到MyDate类中。
4)注意内部类的写法和使用场景。

★自定义泛型★
创建自定义泛型的接口和父类,在继承类或实现接口的时候确定类型。如果不指定类型的话 ,就默认为Object。
用途:实现松耦合。
在为多个业务类型创建父类或是接口的时候,不知道使用什么类型的时候,可以不定义类型,让继承/实现的时候确定类型。
泛型方法
泛型方法可以定义在普通类中,也可以定义在泛型类中。
public<T,F> void menthodName(T t , F f ){ }的形式定义泛型方法,在调用方法的时候明确类型。方法的参数是什么类型就默认定义成什么类型。
注意:上面的例子中的 sTest()不是泛型方法,是使用泛型。使用了泛型类的s类型而已,这和泛型方法不同。

30 final修饰
final能修饰类,方法,成员字段。
final的本意是终了,意味着一旦被final修饰的话,就不能再被改变。
因此final修饰类,类不能被继承,典型的例子是String。修饰方法,方法不能被重写。修饰成员变量,成员变量不能被改变值。
static强调数据只存在一份,并且是属于类的,不属于对象。final强调数据不可变,且属于对象。
abstract:
1、abstract类不能用来创建abstract类的对象;
2、final类不能用来派生子类,因为用final修饰的类不能被继承;
3、如2所述,final不能与abstract同时修饰一个类,abstract类就是被用来继承的;
4、类中有abstract方法必须用abstract修饰,但abstract类中可以没有抽象方法,接口中也可以有abstract方法。
注意:abstract是用来修饰类和方法的:
1. 修饰方法:abstract不能和private、final、static共用。
2. 修饰外部类:abstract不能和final、static共用。(外部类的访问修饰符只能是默认和public)
3. 修饰内部类:abstract不能和final共用。(内部类四种访问修饰符都可以修饰)
★final,finally和finalize★
finally
是在异常处理时配合try-catch执行清理操作,需要清理的资源包括:打开的文件或网络连接等,
它会把内存之外的资源恢复到他们的初始状态。无论try中是否有异常出现,finally里的操作都会被执行。
finalize
这是Object基类的一个方法,垃圾收集器在将对象清除出内存之前调用的清理资源方法,
且此方法只会被系统调用一次,其实finalize能做的工作,try-finally能做的更好,《深入理解Java虚拟机》中建议大家忘掉这个方法的存在
★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★
31 如何创建开发语言
现实中你看到了一辆小汽车,这辆车里坐着两个人,那么如何用这门语言来表达这样的一个概念和场面?
首先要为这门语言横向定义一个“类型”的概念。
接下来在程序中就可以这样表示:有一个汽车类型,有一个人类型,在一个汽车类型的对象内包含着两个人类型的对象,
因为要表达出这个模型,你又引入了“对象”的概念 。而现在,你又看到,汽车里面的人做出了开车的这样一个动作,由此你又引入了“动作指令”这样一个概念。
接着,你又恍然大悟总结出一个定理,无论是什么样的“类型”,都只会存在这样一个特征,即活着的 带生命特征的(如人) 和 死的 没有生命特征的(如汽车) 这两者中的一个。
最后,随着思想模型的成熟,你发现,这个“类型”就相当于一个富有主体特征的一组指令的集合。
好,然后你开始照葫芦画瓢。你参考其它程序语言,你发现大家都是用class来表示类的含义,用struct表示结构的含义,用new来表示 新建一个对象的含义,
于是,你对这部分功能的语法也使用class和new关键字来表示。然后你又发现,他们还用很多关键字来更丰富的表示这些现实模型,比如override、virtual等。
于是,在不断的思想升级和借鉴后,你对这个设计语言过程中思想的变化仔细分析,对这套语言体系给抽象归纳,最终总结出一套体系。
于是你对其它人这样说,我总结出了一门语言很多必要的东西如两种主要类别:值类别和引用类别,五个主要类型:类、接口、委托、结构、枚举,我还规定了,
一个类型可以包含字段、属性、方法、事件等成员,我还指定了每种类型的可见性规则和类型成员的访问规则,等等等等,只要按照我这个体系来设计语言,
设计出来的语言它能够拥有很多不错的特性,比如跨语言,跨平台等,C#和VB.net之所以能够这样就是因为这两门语言的设计符合我这个体系。
32 画图
JFrame类:可以理解为画外层框。JPanl类:可以理解为外框内的画板(白板)。
1)定义Mypanel类,继承JPanl,重写paint方法,定义中间图形的大小和位置。
2)初始化画板,并将该画板放到(add)最外层的框内。
3)设置外框的大小等因素。
4)在main方法中启动外框。#将定义和设置外框的处理写到了构造函数中,因此在main方法中创建本类的对象,以此来执行构造函数。
33.witch case与if else
switch case会生成一个跳转表来指示实际的case分支的地址,而if…else却需要遍历条件分支直到命中条件。
switch case的优缺点
1)优点
当分支较多时,用switch的效率是很高的。因为switch是确定了选择值之后直接跳转到那个特定的分支。
2)缺点
switch…case占用较多的代码空间,因为它要生成跳表,特别是当case常量分布范围很大但实际有效值又比较少的情况,switch…case的空间利用率将变得很低。
switch…case只能处理case为常量的情况。
基本数据类型:byte, short, char, int
包装数据类型:Byte, Short, Character, Integer
枚举类型:Enum
字符串类型:String(Jdk 7+ 开始支持)
switch(score){
case 0:
System.out.println(“0”);
break;
case 1:
System.out.println(“1”);
break;
}
if else的优缺点
1)if else的优点:if else能应用于更多的场所以if else比较灵活。
2)if else的缺点:if else必须遍历所以得可能值。
34.创建文件
使用File类创建文件。获取文件的路径,根路径,文件名等等。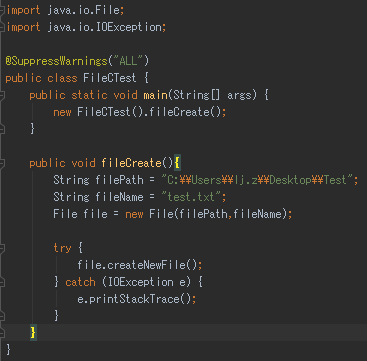
35.Java之IO流
| (抽象基类) | 字节流(8bit)二进制文件 | 字符流(按字符) |
| 输入流 | InputStream | Reader |
| 输出流 | OutputStream | Writer |
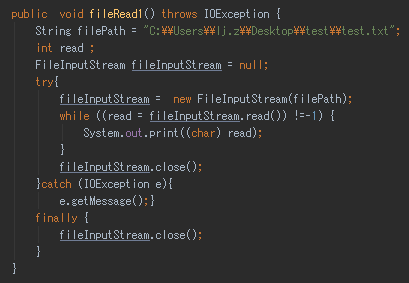
FileInputStream类的read方法读取指定路径下的文件。文件是一个字节一个字节的读取,因此需要使用While循环,直到读完所有内容。
注意知识点:1.(read = fileInputStream.read()) != -1的写法。2.要关闭IO流。
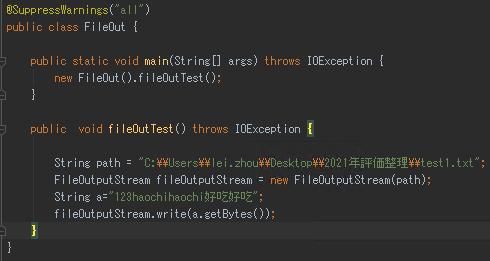
FileOutputStream.write()实现数据写入到文件内。
FileOutputStream.write()和FileInputStream.read()方法实现一边读一边写。

8bit(位)=1Byte(字节) ;1024Byte(字节)=1KB ;1024KB=1MB;1024MB=1GB;1024GB=1TB
一个字节表示的范围0~255。
37 网络基础
・IP地址的组成 = 网络地址 + 主机地址 192.168.16.69
・IPV6是IPV4的下一代,用于解决IP v网络地址资源有限的问题,同时IP v6也解决了多种接入设备连入互联网的障碍。
38 反射
通过外部文件配置,在不修改源码的情况下,来控制程序,也符合设计模式的OCP原则(关闭原则:不修改代码,扩容功能)。
xml或者properties里面写上了配置,然后在Java类里面解析xml或properties里面的内容,得到一个字符串,然后用反射,
根据这个字符串获得某个类的实例,这样就可以动态配置一些东西,不用每一次都要在代码里面去new或者做其他的事情,
以后要改的话直接改配置文件,代码维护起来就很方便了,同时有时候要适应某些需求,Java类里面不一定能直接调用另外的方法,这时候也可以通过反射机制来实现。
使用场景:
用于某些模块集成场合。当不能在开发时即得到其目标类完整接口定义,只能根据命名规则去进行集成时。
并可以延伸到包装、动态代理等模式的应用中。有时候也干些hack的事情,比如绕过private保护机制啥的。
优点:
反射提高了Java程序的灵活性和扩展性,降低耦合性,提高自适应能力。
缺点:
性能问题,使用反射基本上是一种解释操作,用于字段和方法接入时要远慢于直接代码。
因此Java反射机制主要应用在对灵活性和扩展性要求很高的系统框架上,普通程序不建议使用。
使用反射会模糊程序内部逻辑,
程序人员希望在源代码中看到程序的逻辑,反射等绕过了源代码的技术,因而会带来维护问题。反射代码比相应的直接代码更复杂。
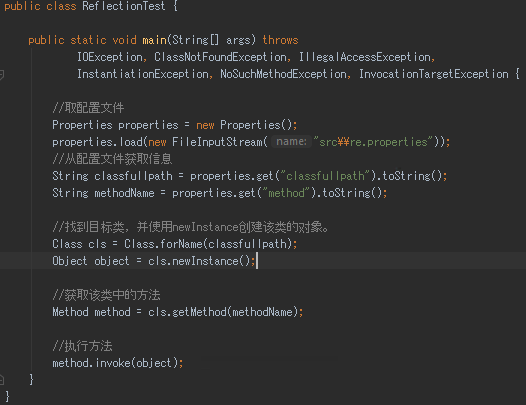
★反射代码实践★
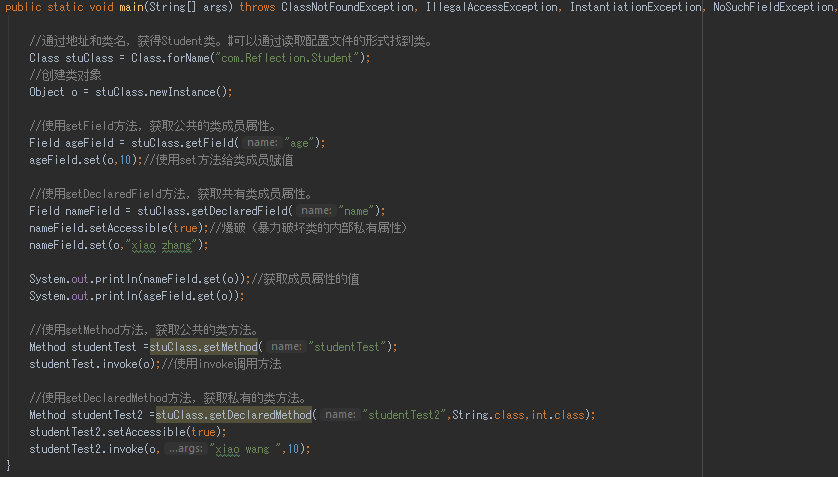
类本身,以及该类包含的所有的成员属性和方法都是对象。
首先找到类,赋给Class类型的stuClass对象,之后通过该对象的newInstance方法创建该类的对象o。
之后通过stuClass对象的getField方法,找到Student类的成员属性和方法。
把成员属性赋给Field类型的ageField对象,把方法赋给Method类型的studentTest对象。#目前为止都是对Student类的操作,和o对象没有关系。
通过Field的set方法,指定具体要修改的哪个对象的属性,以及具体的值。调用方法也是一样,通过Method类的invoke方法。
1.java.lang.Class:代表一个类,Class对象表示某个类加载后在堆中的对象
2.java.lang.reflect.Method: 代表类的方法,Method对象表示某个类的方法
3.java.lang.reflect.Field:代表类的成员变量,Field对象表示某个类的成员变量
4.java.lang.reflect.Constructor:代表类的构造方法,Constructor对象表示构造器
这些类在java.lang.reflection
39.正则表达式
正则表达式就是用某种模式去匹配字符串的一个公式。正则表达式看似复杂,掌握之后大大提高处理文本的效率。
例如,验证输入的邮件是否符合电子邮件格式。验证输入的手机号,是否符合手机号格式。
如果要想灵活的运用正则表达式,必须了解其中各种元字符的功能,元字符从功能上大致分为:
1.限定符
2.选择匹配符
3.分组组合和反向引用符
4.特殊字符
5.字符匹配符
6.定位符
元字符(Metacharacter) -转义号\\
在我们使用正则表达式检索某些特殊字符的时候,需要用到转义符号,否则检索不到结果,甚至会报错。
用$去匹配“abc$ (”什么都找不到。需要使用\\$匹配。
应用实例:
1. [a-z]表示可以匹配a到z中任意一个字符,比如[a-z] 去匹配a11c8,会得到a和c。使用[A-Z]去匹配a11c8的话, 什么也得不到,因为区分大小写。
2. JAVA正则表达式默认区分大小写,如下实现不区分大小写:
(?i)abc表示abc都不区分大小写
例:如下得到ABC和abc
String content ="a11c8ABCabc";
String regStr = "( ?i)abc";
a(?i)bc 表示bc都不区分大小写
例:如下得到abc,aBC
String content ="abcAaBC" ;
String regStr = "a(?i)bc";
a((?i)b)c 只有b都不区分大小写
区分大小写的写法: Pattern pattern = Pattern. compile(regStr);
不区分大小写的写法: Pattern. compile(regStr, Pattern. CASE_ INSENSITIVE);
例:
String content ="abcABC";
String regStr = "bc";
Pattern pattern = Pattern. compile( regStr, Pattern. CASE_ INSENSITIVE);
Matcher matcher = pattern . matcher( content) ;
while (matcher. find()){
System. out. print1n("找到:" + matcher . group(0));
执行结果:
找到: bc
找到: BC
[A-Z] 匹配A-Z中任意一个字符。
[0-9] 匹配0-9中任意一个数字。
\\d匹配0-9中的任意一个数值,和[0-9]一样。
\\D匹配不是0-9中的任意一个数字,和[A0-9]一样。
\\w匹配任意英文字符,数值和下划线,和[a-zA-Z0-9]一样。
\\W是\\w的反方向。
\\s匹配任何空白字符(空格、制表符等)
\\S匹配任何非空白字符,是\\s的反方向。
.匹配\n以外的所有字符。※\\.则匹配出.本身。
|是选择匹配符。例:如下输出ab AB CD
String content ="abcABCDD";
String regStr = "ab|cd";
Patternl类和Matcher类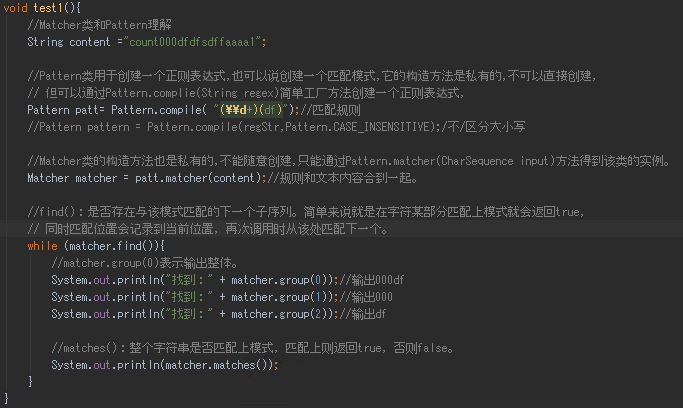
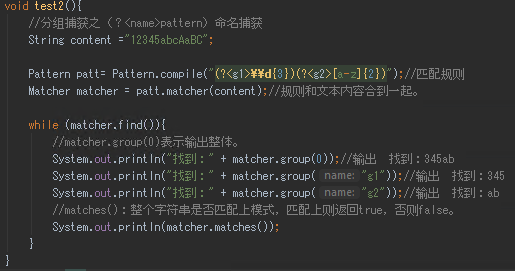
分组捕获
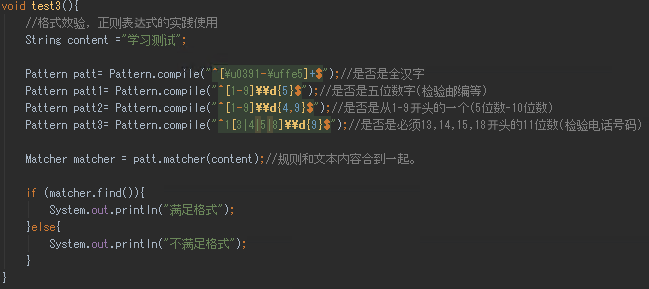
格式效验
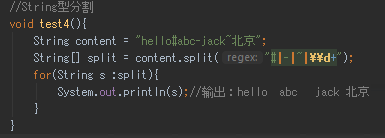
String型分割
40.JMS
JMS(java消息服务)是规范,它定义了一些规则,一些接口。具体实现由各种做这个产品的厂家或开源组织来实现。
在JMS还没有诞生前,每个企业都会有自己的一套内部消息系统,
比如项目组A需要调用到项目组B的系统,项目组B也有可能会调用到项目组C的系统。这样每个公司都有自己的一套实现。很不规范。
Java定义了消息服务的规范,不管哪个厂商做的消息服务的中间件,我们应用程序开发的时候都一样的去拿消息、读消息、生成消息。
是一种与厂商无关的API,用来访问消息收发系统消息,类似于JDBC。
JMS的元素:
JMS提供者:连接面向消息中间件的,JMS接口的一个实现。提供者可以是Java平台的JMS实现,也可以是非Java平台的面向消息中间件的适配器。
JMS客户:生产或消费基于消息的Java的应用程序或对象。
JMS生产者:创建并发送消息的JMS客户。
JMS消费者:接收消息的JMS客户。
JMS消息:包括可以在JMS客户之间传递的数据的对象
JMS队列:一个容纳那些被发送的等待阅读的消息的区域。与队列名字所暗示的意思不同,消息的接受顺序并不一定要与消息的发送顺序相同。
一旦一个消息被阅读,该消息将被从队列中移走。
JMS主题:一种支持发送消息给多个订阅者的机制。
41.Java SDK和JDK的区别
1)从字面意思进行区别:
① SDK是Software Development Kit的缩写,中文意思是“软件开发工具包”。
② JDK(Java Development Kit,Java开发工具包)是Sun Microsystems针对Java开发员的产品。
2)从应用范围进行区别:
① SDK是一个覆盖面相当广泛的名词,辅助开发某一类软件的相关文档、范例和工具的集合都可以叫做“SDK”。
SDK是一系列文件的组合,它为软件的开发提供一个平台(它为软件开发使用各种API提供便利)。因此,SDK包括JDK。
② JDK是使用最广泛的Java SDK,也就是说JDK属于SDK。
42.JAVA Bean
在Java中Bean是一个普遍的概念,代表一个简单的Java对象,用于封装数据和业务逻辑。Bean可以理解为一个可重用的组件。
1.具有私有属性和公共getter/setter方法。
2.实现了可序列化接口(Serializable)。
3.具有无参构造函数。
通过创建和使用Bean,可以实现代码的模块化和可重用性,将业务逻辑和数据封装在一个对象中,方便管理和维护。
Bean可以用于表示各种概念,例如用户、订单、产品等,通过创建不同的Bean实例,可以对应不同的数据和业务操作。
在框架和库中,例如Spring Framework,Bean更具体地指代由Spring容器管理的对象。
Spring 的 IoC(控制反转)容器负责创建和管理 Bean 实例,通过配置文件或注解来定义和配置 Bean。
Spring Bean 具有更丰富的功能,例如依赖注入、面向切面编程等,可以帮助开发者更方便地开发和管理应用程序。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号