Coursera台大机器学习基础课程学习笔记2 -- 机器学习的分类
总体思路:
-
各种类型的机器学习分类
- 按照输出空间类型分Y
- 按照数据标记类型分yn
- 按照不同目标函数类型分f
- 按照不同的输入空间类型分X
按照输出空间类型Y,可以分为二元分类,多元分类,回归分析以及结构化学习等,这个好理解,离散的是分类,连续的是回归,到是结构化的学习接触的相对较少,以后有空可以关注下。

按照数据标记分可以分为:
- 监督;
- 非监督;
- 半监督;
- 增强学习;
下面这张ppt很好的总结了这点:

这是围绕标记yn的类型进行分类的,
监督和非监督很好理解,半监督和增强其实应用更加普遍,数据的标记大部分时候是需要人来做的,这个条件有时候很难满足(经费不足),那么半监督就有比较好的应用了。用人的学习过程来理解,人按照课本去学习,是监督,如果没有课本,按照自己发现的规律去解决问题,则是非监督,因为此,非监督学习的应用相对有限。有时候学习的事物特征到标记结果不是很好描述,例如搜索引擎的广告系统,针对不同用户信息以及query放什么广告,放在什么位置,这需要增强学习去不断的强化,让用户通过点击率反馈机器学习系统使得其不断优化,因为我们自己定义数据标记是很困难的,又例如机器学习开车。因此增强学习的关键在于反馈的存在。
按照不同的目标函数类型f,可以分为Batch,online以及active,课程中终于和人的学习过程做类比,其实和人一类比就很好理解了:


这三种学习类型分别可以类比为:填鸭式,老师教学以及主动问问题。
按照输入X分的话,主要是三种:
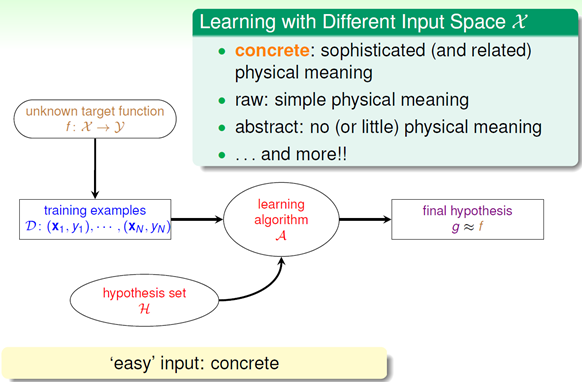
这里需要提到的是,把原始输入X转化为可以真正作为机器学习的输入的training examples的过程称为 feature engineering,也就是从Raw data --> concrete data的过程。
回顾下我们在哪?

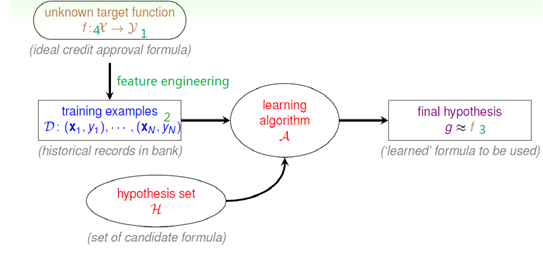
在回答何时可以用机器学习的时候,我确实需要知道机器学习有什么类型,其实这些类型正好是围绕最后这张图而来的,确定这些类型就是逐个确定机器学习算法各个要素应该选用哪种方法的过程,只有当每一个都确定了,我们才能知道这个问题是否可以用机器学习来解决(见下图1,2,3,4):
总结:
目前用的最多的分类是按照yn去分,课程给了个详细的分类,觉得很不错,有了全局观,后面就好易于理解了。
参考资料:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号