Request类源码分析,序列化组件介绍,序列化类的基本使用,常用字段类和参数,反序列化之校验,反序列化之保存
Request类源码分析:
总结:
1 新的request有个data属性,以后只要是在请求body体中的数据,无论什么编码格式,无论什么请求方式
2 取文件还是从:request.FILES
3 取其他属性,跟之前完全一样 request.method ....
-原理是:新的Request重写了__getattr__,通过反射获取老的request中的属性
4 request.GET 现在可以使用 request.query_params
@property
def query_params(self):
return self._request.GET
序列化组件介绍:
1. 序列化,序列化器会把模型对象(queryset,单个对象)转换成字典,经过response以后变成json字符串
2. 反序列化,把客户端发送过来的数据,经过request.data以后变成字典,序列化器可以把字典转成模型
3. 反序列化,完成数据校验功能
序列化类的基本使用:
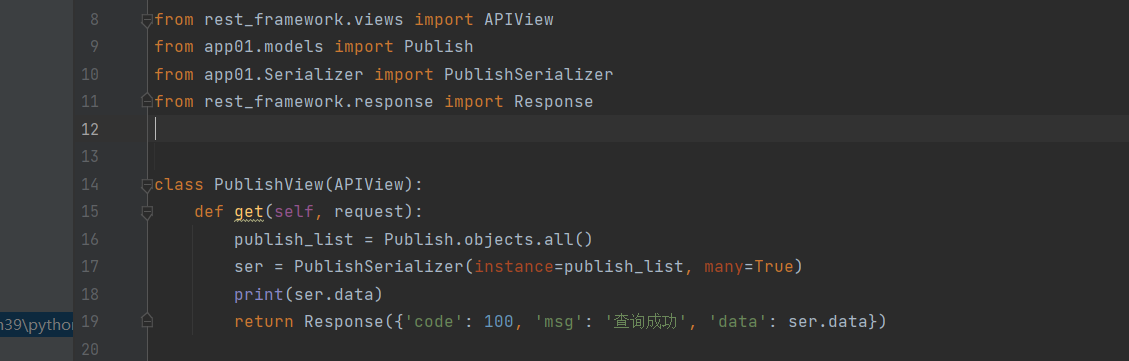
查询所有:
view内:
使用序列化类,完成序列化 两个很重要参数: instance:实例,对象
data:数据
如果是多条many=True 如果是queryset对象,就要写
如果是单个对象 many=False,默认是False
url内:

序列化内:
查询单条:
view内:

url内:

总结:
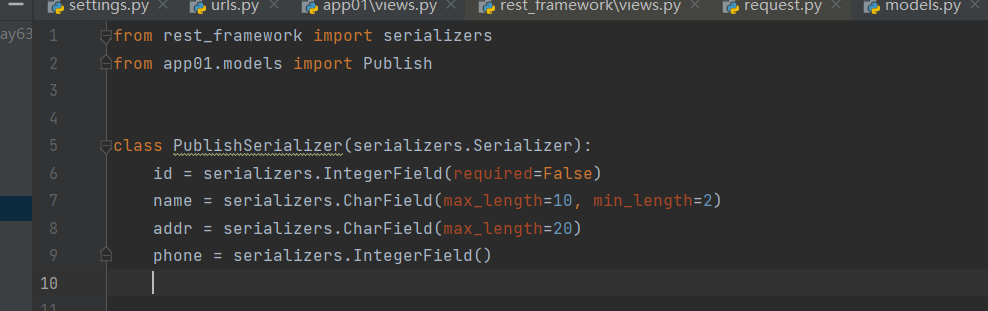
1 写一个类,继承serializers.Serializer
2 在类中写字段,要序列化的字段
3 在视图类中使用:(多条,单条)
serializer = PublishSerializer(instance=book_list, many=True)
serializer =PublishSerializer(instance=book)
常用字段类和参数:
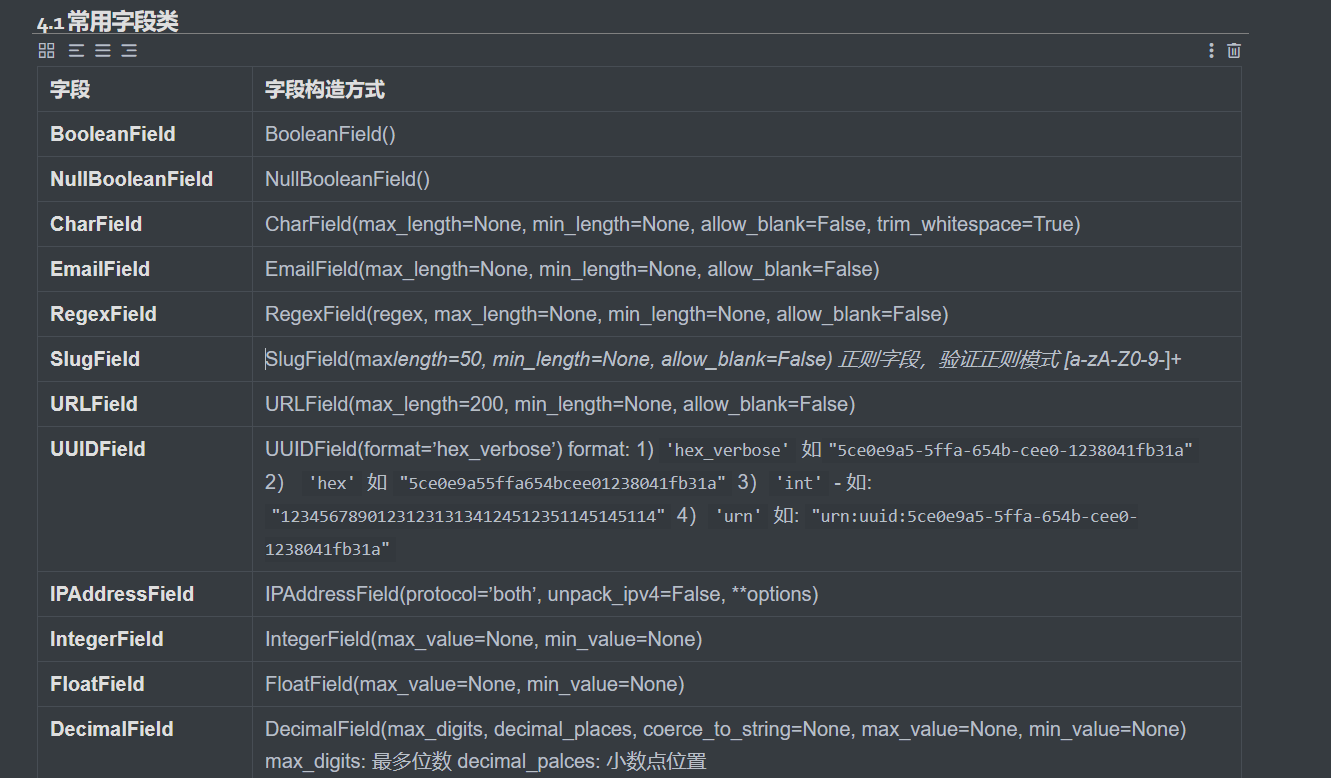
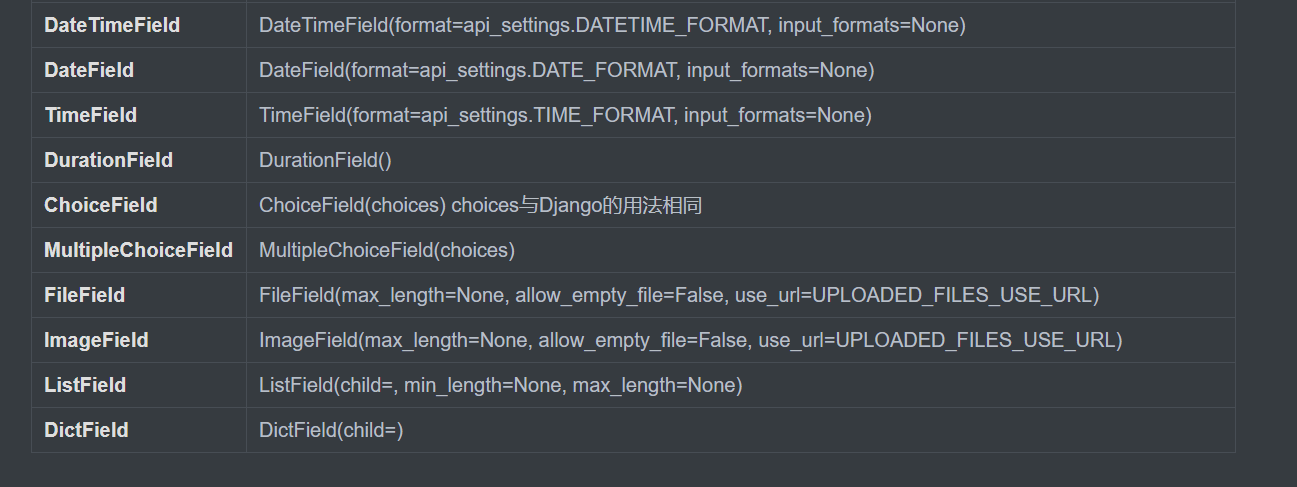
字段参数(校验数据来用的):
选项参数:
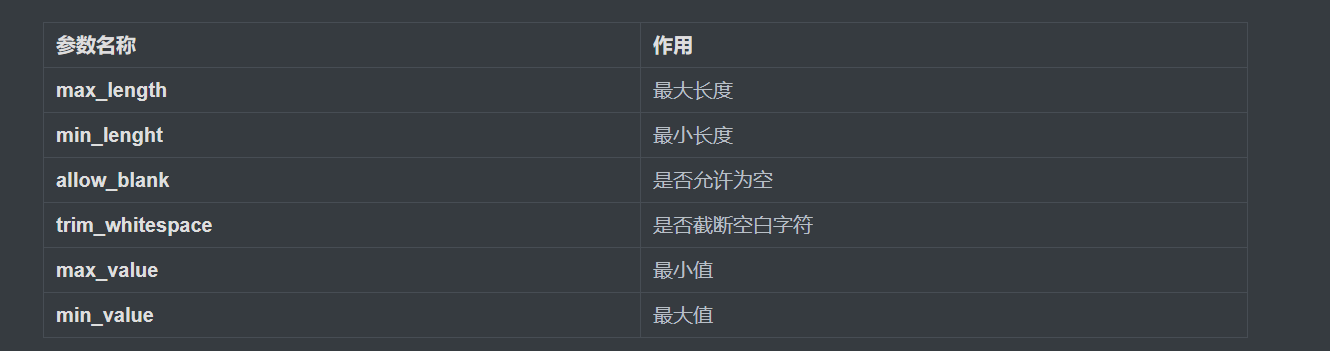
通用参数:
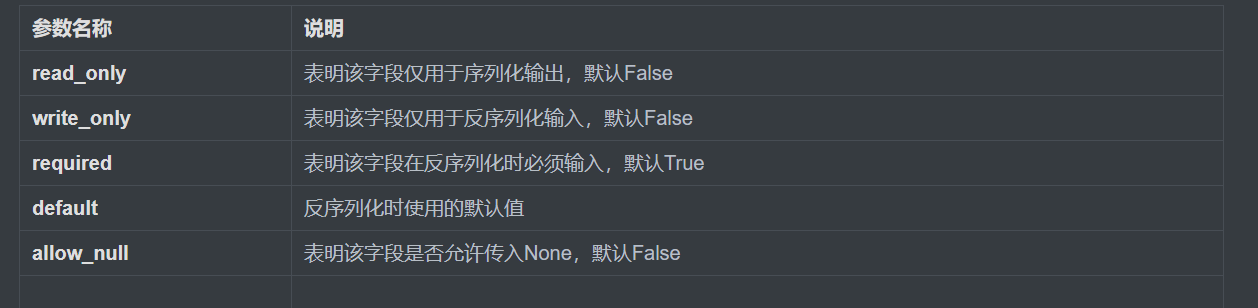

2.局部钩子:写在序列化类中的方法,方法名必须是 validate_字段名

3.全局钩子:写在序列化类中的方法 方法名必须是 validate
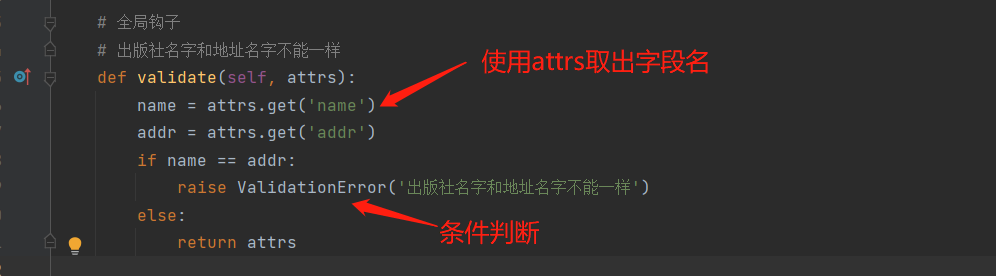
只有三层都通过,在视图类中:
ser.is_valid(): 才是True,才能保存
新增接口:
-序列化类的对象,实例化的时候:ser = BookSerializer(data=request.data)
-数据校验过后----》调用 序列化类.save()--->但是要在序列化类中重写 create方法
def create(self, validated_data):
book=Book.objects.create(**validated_data)
return book
修改接口:
-序列化类的对象,实例化的时候:ser = BookSerializer(instance=book,data=request.data)
-数据校验过后----》调用 序列化类.save()--->但是要在序列化类中重写 update方法
def update(self, book, validated_data):
for item in validated_data: # {"name":"jinping","price":55}
setattr(book, item, validated_data[item])
book.save()
return book

 浙公网安备 33010602011771号
浙公网安备 33010602011771号