第二周个人作业--单词计数
第二周个人作业----单词计数
(1)第二周个人作业的github地址:[1]https://github.com/chen153217/word_count
(2)PSP表格记录
| PSP2.1 | PSP阶段 | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| .Estimate | .估计这个任务开发需要多少时间 | 30 | 30 |
| Development | 开发 | 60*11.5 | 60*13.5 |
| .Analysis | .需求分析 | 60 | 60*1.5 |
| .Design Spec | .生成设计文档 | 20 | 20 |
| .DesignReview | .设计复审(和同事审核设计文档) | 20 | 20 |
| .Coding Standard | .代码规范(为目前开发指定合适规范) | 20 | 20 |
| .Design | .具体设计 | 30 | 30 |
| .Coding | .具体编码 | 60*6 | 60*6 |
| .Code Review | .代码复查 | 60 | 60 |
| .Test | .测试(自我测试,修改代码,提交代码) | 60*2 | 60*4 |
| Reporting | 报告 | 60 | 60 |
| .Test Report | .测试报告 | 60*1.5 | 60*2 |
| .Size Measurement | .计算工作量 | 30 | 60 |
| .Postmortem & Process Improvement Plan | .时候总结,并提出过程改进计划 | 60 | 60 |
| 合计 | 60*12.5 | 60*16 |
(3)解题思路:
拿到题目后,首先读题可以看到,这题主要涉及到对文件的操作,因为好久没有写些读写文件的代码,于是花了点时间去看了下java编程思想第四版第十八章关于文件操作的内容,算是复习一下吧.因为涉及到统计行数,需要用到readline()这个函数,所以我选用了BufferedReader和BufferedWriter这两个类来进行文件读写操作.
题目包含基本功能和扩展功能,基本功能比较简单,基本上只需要用readline()和split()这两个函数就可以搞定,基本功能实现后,就可以考虑如何将类打包成jar包以及转化为.exe文件.百度一下,因为我用的idea,所以参考教程
[2]jar转exe
这篇教程基本就可以知道如何弄了,当然,在使用exe4j打包时,到最后我也遇到了,它提示需要包含32位jdk或者jre这个错误(忘记截图了),最后去网上查说是因为它默认是生成32位的可执行程序,但是我的jre,jdk都是64位的,它检测不到,所以报了这个错,如图
只要在exe4j执行时,勾上这个就可以了.

完成了基本功能并且实现了可以打包成exe文件时,接下来便可以去实现扩展功能,扩展功能就稍微有点难度了,当然,对我来说,单单是实现扩展功能并不难.让我思考了好久的是,如何去处理各种可能的错误的输入情况,在这时,我又发现Java里面的System.out.print()这个函数打印出来的东西在将jar转换成exe后,输出结果并不会显示在控制台,这就让人很头疼了,
用户输错了之后,如何在控制台给出错误提示?我查了好久,还是没解决这个问题.只知道输出可以重定向到一个文本文件,但这对于用户来说,不能直观看到提示的话,这样做也没什么用.于是我去linux上故意输入了一些的命令,看它怎么解决,发现它的除了错误提示做的好外,容错处理,也做的很好,比如 ls –l,是显示文件目录,但输入ls –ll时,它也可以正确输出.于是借用了它的思想(可能算是一种偷懒的做法),如果用户输入了一些不合法的输入,只要不是文件名弄错,统统给它忽略掉,比如用户如果多输入了一个-t(不存在的参数),因为我不知道如何在控制台提示用户,所以,类似错误我就直接忽略,只输出正确的参数对应的内容.于是,我便开始设计扩展功能的处理算法了.
(4)程序设计实现过程:
因为功能比较简单,所以我就把所有的功能都写在一个类里面了,首先是基本功能,记录行数,词数和字符数,我写了lineCount(),wordCount()和charCount()三个函数来实现.至于-o输出到指定文件.,只需在main函数里做个判断就好了.然后就是扩展功能,首先是-s实现递归目录下符合条件的文件,我写了个searchFile()函数来实现,主要涉及到正则表达式和遍历时,对其是文件还是文件夹的判断的处理,然后是-a 返回更复杂的数据(代码行/空行/注释行)我用了一个otherCount()函数来实现,这个的难点在于读懂(代码行/空行/注释行)的定义,把各种情况考虑到了代码就很容易写了,-e就比较简单了包含这个参数,就去读它后面的文件,把停用词表包含在一个List
对于按照字符数/单词数/行数/(代码行/空行/注释行)的顺序输出到指定文件中,我用的treemap来实现,具体实现见函数getResukt()
(5)代码说明:
先给出几个主要函数的实现
public static int[] otherCount(BufferedReader reader) throws IOException {
int[] others = new int[3];
String str;
while ((str = reader.readLine()) != null) {
str = str.replaceAll(" ", "");//每读取一行,先去掉空格
//首先判断是否为空行
if (str.length() <= 1)//本行字符数不多于1,说明是空行
others[1]++;
//接下来考虑多行注释与代码行
else if (str.indexOf("/*") >= 0) {//如果包含“/*”,说明开始多行注释,否则继续判定是代码行还是单行注释
if (str.indexOf("*/") > 0) {//说明多行注释只注释一行
if (str.indexOf("*/") == str.length() - 2) {//说明是注释行
others[2]++;
} else {
others[0]++;
}
} else {
if (str.indexOf("/*") == 0)//说明该行没有代码
others[2]++;
else if (str.indexOf("/*") == 1)//少于一个字符,为空行
others[1]++;
else
others[0]++;//说明在代码行后面开启多行注释
while ((str = reader.readLine()) != null) {//说明该行属于注释行
str = str.replaceAll(" ", "");
if (str.indexOf("*/") < 0)
others[2]++;
else {
if (str.indexOf("*/") == (str.length() - 2))//说明该行没有代码
others[2]++;
else
others[0]++;//说明注释后面后面还有代码
break;
}
}
}
}//不是多行注释,看是否为单行注释
else if (str.indexOf("//") == 0 || str.indexOf("//") == 1) {
others[2]++;
} else {
others[0]++;
}
}
return others;
}
public static String getResult(String exepath, String filename, List<String> inputs, List<String> stoplists) throws IOException {
int line_count = 0;//记录行数
int word_count = 0;//记录单词数
int char_count = 0;//记录字符数
int[] other_count = new int[3];//代码行 / 空行 / 注释行的数目
String result = "";//保存统计结果
Map<Integer, String> per_result = new TreeMap<Integer, String>();//保存每一条的统计结果
String absPath = exepath + filename;
int length = inputs.size();//获取输入字符的长度
//String filename=inputs.get(length-1);//需要统计的文件名
for (int i = 0; i < length - 1; i++) {//循环遍历输入的参数,并将操作的结果放在result中。
String arg = inputs.get(i);
reader = new BufferedReader(new FileReader(absPath));
switch (arg) {
case "-c"://读取字符数
char_count = charCount(reader);
result = filename + "," + "字符数: " + char_count + "\r\n";
per_result.put(1, result);
break;
case "-w"://读取单词数
word_count = wordCount(reader, stoplists);
result = filename + "," + "单词数: " + word_count + "\r\n";
per_result.put(2, result);
break;
case "-l"://读取行数
line_count = lineCount(reader);
result = filename + "," + "行数: " + line_count + "\r\n";
per_result.put(3, result);
break;
case "-a"://读取代码行 / 空行 / 注释行的数目
other_count = otherCount(reader);
result = filename + "," + "代码行/空行/注释行: " + other_count[0] + "/" + other_count[1] +
"/" + other_count[2] + "/" + "\r\n";
per_result.put(4, result);
break;
default://如果不是以上四种,则忽略
break;
}
}
result = "";
for (Map.Entry<Integer, String> entry : per_result.entrySet())
result += entry.getValue();
return result;
}
public static List<String> searchFile(String absPath, String lastPath) {//递归遍历当前目录以及子目录下符合要求的文件
String regex = lastPath.replace("?", "[0-9a-z]");
regex = regex.replace("*", "[0-9a-z]{0,}"); //正则匹配
List<String> matchFile = new ArrayList<String>();
File file = new File(absPath);
File[] files = file.listFiles();//获取当前路径下所有文件
for (int i = 0; i < files.length; i++) {
if (files[i].isDirectory()) {
List<String> matchs = searchFile(files[i].getAbsolutePath(), lastPath);
matchFile.addAll(matchs);
} else if (files[i].isFile()) {
String filename = files[i].getName();
if (filename.matches(regex))
matchFile.add(files[i].getAbsolutePath());
}
}
return matchFile;
}
下面贴出主程序的实现:
if (args.length == 0) {
return;
} else {
for (String arg : args) {//将控制台输入放到链表中,方便后面的输入检测
inputs.add(arg);
}
if (inputs.contains("-e")) {//如果输入包含”-e“,则记录停用单词
int index = inputs.indexOf("-e");
String stopFile = inputs.get(index + 1);
BufferedReader buffer = null;
try {
buffer = new BufferedReader(new FileReader(exepath + stopFile));
stop_words = getStopList(buffer);
} catch (FileNotFoundException e) {
System.out.println("stopFile Not Fount");
return;
} finally {
if (buffer != null)
buffer.close();
}
inputs.remove("-e");
inputs.remove(stopFile);
}
if (inputs.contains("-o")) {//如果输入包含”-o”,则writer指向指定输出文件名
int index = inputs.indexOf("-o");
resultFile = inputs.get(index + 1);
inputs.remove("-o");
inputs.remove(resultFile);
resultFile = exepath + resultFile;
writer = new BufferedWriter(new FileWriter(resultFile));
} else {//否则writer指向默认文件
writer = new BufferedWriter(new FileWriter(resultFile));
}
if (inputs.contains("-s")) {//如果输入包含“-s",则递归处理目录下符合条件的文件
inputs.remove("-s");
int length = inputs.size();
String filename = inputs.get(length - 1);
List<String> filelist = new ArrayList<String>();
//判断输入文件为绝对路径还是相对路径,如果filename中包含字符"/",则说明是绝对路径
if (filename.indexOf("\\") > 0) {
int index = filename.lastIndexOf("\\");
String absPath = filename.substring(0, index + 1);
String lastPath = filename.substring(index + 1);
filelist = searchFile(absPath, lastPath);
} else {
filelist = searchFile(exepath, filename);
}
for (String s : filelist) {
int index = s.lastIndexOf("\\");
String absPath = s.substring(0, index + 1);
String lastPath = s.substring(index + 1);
result += getResult(absPath, lastPath, inputs, stop_words);
}
writer.write(result);
} else {
int length = inputs.size();
String filename = inputs.get(length - 1);//读取文件名
result = getResult(exepath, filename, inputs, stop_words);
writer.write(result);
}
}
注释应该写的很详尽了!有问题可以去参考github上完整项目代码
。在这部分,接下来我会主要用文字方式解释下在某些问题上我的处理思路和解题流程。用图虽然很直观,但画
起来同时很耗时和麻烦。
首先
最有必要的是说下处理输入参数这部分,个人觉得这部分可能是最难的。
- 第一步:将输入字符串数组(args)保存在List
inputs当中(list中丰富的函数便于接下来的处理) - 第二步:判断输入中,是否包含"-e",包含则写个函数将停用词表中的单词保存在一个list中,同时从inputs中去掉
(remove)这两个字符串。 - 第三步,判断输入中,是否含有"-o",如果输入包含”-o”,则writer指向指定输出文件名(因为默认是result.txt)
同时在inputs中remove掉这两个参数, - 第四步,判断输入中是否含有“-s",有则,读入后面的文件名通配符(相对路径或绝对路径很容易判断,具体看上面代码)
- 第五步,从要求中可以看到,输入中的参数除了文件名共有七种,通过上面三步,我们已经去掉了三种以及部分文件名。
可以看到剩下的输入中,正常情况下,只剩下-c -w -l -a 以及需要处理的文件名(可能含通配符),这时候,把文件名读取
并remove掉后,inputs中就只剩下-c -w -l -a 这四个中的一个或者多个了,用写一个函数,主要把文件名以及inputs传进去
就可以依次遍历处理了,对于不符合要求的输入,比如输入了不存在的-b或者其它,我做了忽略处理,同时,这些错误参数的存在
并不会影响程序的执行,一定程度上,增加了程序的容错性和稳定性
其次
对于代码行/空行/注释行的处理是很考验逻辑的,因为可能的情况是在太多了,函数中我写了9个if,但我觉得可能的情况肯定
不止这些的,我用文字描述下我的设计过程(具体代码见上面),
- 每读一行(readline()),我都选择了去掉所有的空格,方便后面对每行字符串实际长度(可见字符数)的判断
- 首先判断是否为空行,因为这个最简单,只要不超过一个可显示的字符,例如“{”,就是空行,至于像a/或者/a这种,
我全当注释行处理了。。。(aa/*这种就是代码行了) - 剩下来的就只有代码行和注释行了。首先判断该行中是否有//或者/*同时如果都有,要比较它们在该行中出现的顺序。如果 都没有,直接
判断为代码行 - 如果/之前没有//,则首先判断该行中是否还有/,以判定为多行注释还是只有一行。
- 如果4中是单行注释比如(/aaaaaa/)则要继续判断,是否该行是否有多余一个的可见字符。
- 如果没有/则开始多行注释,依次读取接下来的若干行,知道找到/为止,同时还要判断*/后是否有多余一个的字符
- 如果//之前没有/*,则继续判断//之前是否有多于一个的可见字符,有,则为代码行,没有,则为注释行。
我能考虑到了差不多只有这些的,现在写这个时发现我的实现当中还有点瑕疵,没有考虑到/*之前可能还有//,其它的都是按照这个顺序判定的
(6)测试设计过程
由于之前没有写过单元测试,虽然以后肯定会学,但这次由于时间等原因,我就不打算写了,至于这部分的分数,我选择工作,所以并不在乎这些
也不会埋怨老师怎么评分。
下面我只会按照我自己的理解和想法简单写下我自己手工测试的过程和用例(实际上我手工已经测了n多次)。
作为对上面的文字描述的一点点补充,主要参考[3]白盒测试
这篇博客简单写一下。
首先给出主函数的流程图(判定节点较多)
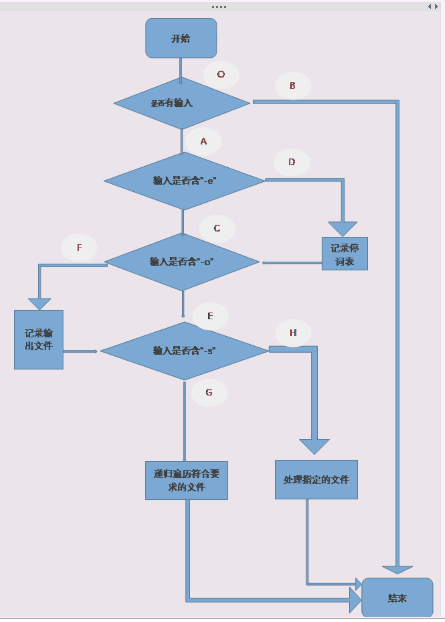
下面是五组用例,对应了五种路径(实际测了n多种,在此就不一一列出了)
| 用例序号 | 用例(输入) | 路径 |
|---|---|---|
| 1 | -c char.c | ACEH |
| 2 | –w –l wordtest.c -o output.txt | ACFH |
| 3 | –w stoptest.c –e stoplist.txt | ADEH |
| 4 | -s -a –w F:\codes\java\try\src*.c | ACFG |
| 5 | -s -a –w -l -c F:\codes\java\try\src*.c -e stoplist.txt -o output.txt | ADFH |
(7)参考文献链接
[1]https://github.com/chen153217/word_count
[2]http://blog.csdn.net/zxm1306192988/article/details/56852777
[3]http://blog.csdn.net/u010098159/article/details/50961635

 浙公网安备 33010602011771号
浙公网安备 33010602011771号