伪多项式时间—复杂性分析
算法时间复杂度
算法复杂度分为时间复杂度和空间复杂度,一个好的算法应该具体执行时间短,所需空间少的特点。


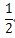 只剩下
只剩下 

|
排序法 |
最差时间分析 | 平均时间复杂度 | 稳定度 | 空间复杂度 |
| 冒泡排序 | O(n2) | O(n2) | 稳定 | O(1) |
| 快速排序 | O(n2) | O(n*log2n) | 不稳定 | O(log2n)~O(n) |
| 选择排序 | O(n2) | O(n2) | 稳定 | O(1) |
| 二叉树排序 | O(n2) | O(n*log2n) | 不一顶 | O(n) |
|
插入排序 |
O(n2) | O(n2) | 稳定 | O(1) |
| 堆排序 | O(n*log2n) | O(n*log2n) | 不稳定 | O(1) |
| 希尔排序 | O | O | 不稳定 | O(1) |
定义:给定一个判定问题,如果存在一个算法,对任何一个答案为“是”的实例I。该算法首先给出一个猜想,该猜想规模不超过I的输入长度的某个多项式函数,且验证猜想的正确性仅需多项式时间,则称该问题属于NP类。
定义:如果NP类中所有问题都可以多项式时间归约到NP类中某个问题x,则称x是NP-完全问题。
定义:如果某优化问题x的判定问题是NP-完全的,则称问题x是NP-难的;如果x的判定问题是强NP-完全的,则称x是强NP-难的。
伪多项式时间概念(Pseudo-polynomial time)
algorithm - What is pseudopolynomial time? How does it differ from polynomial time?
To understand the difference between polynomial time and pseudopolynomial time, we need to start off by formalizing what "polynomial time" means.
The common intuition for polynomial time is "time O(nk) for some k." For example, selection sort runs in time O(n2), which is polynomial time, while brute-force solving TSP takes time O(n · n!), which isn't polynomial time.
These runtimes all refer to some variable n that tracks the size of the input. For example, in selection sort, n refers to the number of elements in the array, while in TSP n refers to the number of nodes in the graph. In order to standardize the definition of what "n" actually means in this context, the formal definition of time complexity defines the "size" of a problem as follows:
The size of the input to a problem is the number of bits required to write out that input.
For example, if the input to a sorting algorithm is an array of 32-bit integers, then the size of the input would be 32n, where n is the number of entries in the array. In a graph with n nodes and m edges, the input might be specified as a list of all the nodes followed by a list of all the edges, which would require Ω(n + m) bits.
Given this definition, the formal definition of polynomial time is the following:
An algorithm runs in polynomial time if its runtime is O(xk) for some constant k, where x denotes the number of bits of input given to the algorithm.
When working with algorithms that process graphs, lists, trees, etc., this definition more or less agrees with the conventional definition. For example, suppose you have a sorting algorithm that sorts arrays of 32-bit integers. If you use something like selection sort to do this, the runtime, as a function of the number of input elements in the array, will be O(n2). But how does n, the number of elements in the input array, correspond to the the number of bits of input? As mentioned earlier, the number of bits of input will be x = 32n. Therefore, if we express the runtime of the algorithm in terms of x rather than n, we get that the runtime is O(x2), and so the algorithm runs in polynomial time.
Similarly, suppose that you do depth-first search on a graph, which takes time O(m + n), where m is the number of edges in the graph and n is the number of nodes. How does this relate to the number of bits of input given? Well, if we assume that the input is specified as an adjacency list (a list of all the nodes and edges), then as mentioned earlier the number of input bits will be x = Ω(m + n). Therefore, the runtime will be O(x), so the algorithm runs in polynomial time.
Things break down, however, when we start talking about algorithms that operate on numbers. Let's consider the problem of testing whether a number is prime or not. Given a number n, you can test if n is prime using the following algorithm:
function isPrime(n):
for i from 2 to n - 1:
if (n mod i) = 0, return false
return true
So what's the time complexity of this code? Well, that inner loop runs O(n) times and each time does some amount of work to compute n mod i (as a really conservative upper bound, this can certainly be done in time O(n3)). Therefore, this overall algorithm runs in time O(n4) and possibly a lot faster.
In 2004, three computer scientists published a paper called PRIMES is in P giving a polynomial-time algorithm for testing whether a number is prime. It was considered a landmark result. So what's the big deal? Don't we already have a polynomial-time algorithm for this, namely the one above?
Unfortunately, we don't. Remember, the formal definition of time complexity talks about the complexity of the algorithm as a function of the number of bits of input. Our algorithm runs in time O(n4), but what is that as a function of the number of input bits? Well, writing out the number n takes O(log n) bits. Therefore, if we let x be the number of bits required to write out the input n, the runtime of this algorithm is actually O(24x), which is not a polynomial in x.
This is the heart of the distinction between polynomial time and pseudopolynomial time. On the one hand, our algorithm is O(n4), which looks like a polynomial, but on the other hand, under the formal definition of polynomial time, it's not polynomial-time.
To get an intuition for why the algorithm isn't a polynomial-time algorithm, think about the following. Suppose I want the algorithm to have to do a lot of work. If I write out an input like this:
10001010101011
then it will take some worst-case amount of time, say T, to complete. If I now add a single bit to the end of the number, like this:
100010101010111
The runtime will now (in the worst case) be 2T. I can double the amount of work the algorithm does just by adding one more bit!
An algorithm runs in pseudopolynomial time if the runtime is some polynomial in the numeric value of the input, rather than in the number of bits required to represent it. Our prime testing algorithm is a pseudopolynomial time algorithm, since it runs in time O(n4), but it's not a polynomial-time algorithm because as a function of the number of bits x required to write out the input, the runtime is O(24x). The reason that the "PRIMES is in P" paper was so significant was that its runtime was (roughly) O(log12n), which as a function of the number of bits is O(x12).
So why does this matter? Well, we have many pseudopolynomial time algorithms for factoring integers. However, these algorithms are, technically speaking, exponential-time algorithms. This is very useful for cryptography: if you want to use RSA encryption, you need to be able to trust that we can't factor numbers easily. By increasing the number of bits in the numbers to a huge value (say, 1024 bits), you can make the amount of time that the pseudopolynomial-time factoring algorithm must take get so large that it would be completely and utterly infeasible to factor the numbers. If, on the other hand, we can find a polynomial-time factoring algorithm, this isn't necessarily the case. Adding in more bits may cause the work to grow by a lot, but the growth will only be polynomial growth, not exponential growth.
That said, in many cases pseudopolynomial time algorithms are perfectly fine because the size of the numbers won't be too large. For example, counting sort has runtime O(n + U), where U is the largest number in the array. This is pseudopolynomial time (because the numeric value of U requires O(log U) bits to write out, so the runtime is exponential in the input size). If we artificially constrain U so that U isn't too large (say, if we let U be 2), then the runtime is O(n), which actually is polynomial time. This is how radix sort works: by processing the numbers one bit at a time, the runtime of each round is O(n), so the overall runtime is O(n log U). This actually is polynomial time, because writing out n numbers to sort uses Ω(n) bits and the value of log U is directly proportional to the number of bits required to write out the maximum value in the array.
另外:Pseudo-polynomial time complexity means polynomial in the value/magnitude of input but exponential in the size of input.
By size we mean the number of bits required to write the input.
From the pseudo-code of knapsack, we can find the time complexity to be O(nW).
// Input:
// Values (stored in array v)
// Weights (stored in array w)
// Number of distinct items (n) //
Knapsack capacity (W)
for w from 0 to W
do m[0, w] := 0
end for
for i from 1 to n do
for j from 0 to W do
if j >= w[i] then
m[i, j] := max(m[i-1, j], m[i-1, j-w[i]] + v[i])
else
m[i, j] := m[i-1, j]
end if
end for
end for
Here, W is not polynomial in the length of the input though, which is what makes it pseudo-polynomial.
Let s be number of bits required to represent W
i.e. size of input= s =log(W) (log= log base 2)
-> 2^(s)=2^(log(W))
-> 2^(s)=W (because 2^(log(x)) = x)
Now, running time of knapsack= O(nW) = O(n * 2^s) which is not polynomial.
想要理解“伪多项式时间”,我们需要先给出“多项式时间”的一个清楚的定义。
对于“多项式时间”,我们的直观概念是时间复杂度,其中
是一常数。比如,选择排序的时间复杂度是
,是多项式时间;暴力解决TSP问题的时间复杂度是
,不是多项式时间。我们称这种时间复杂度为“传统时间复杂度”。
我们通常认为传统时间复杂度中的变量表示数据的输入规模。比如,选择排序中,
指待排序数组中元素的个数;TSP问题中
表示图中节点的数量。但是,这些所谓的输入规模,仅仅是直观的定义,并不足够严谨。为了标准化这些
,在计算标准时间复杂度时,我们给出了输入规模的标准定义:
一个问题的输入规模是保存输入数据所需要的bit位数。
比如,如果排序算法的输入是一个32-bit整数 数组,那么输入规模就是,
是指数组中元素的个数。对于一个带有
个节点、
条边的图,需要的bit位数就是
。
了解了输入规模的定义,我们来看“多项式时间”的标准定义:
对于一个问题,在输入规模为x的情况下,如果一个算法能够在O()时间内解决此问题,则我们称此算法是多项式时间的,其中
为一常数。
当我们处理一些图论、链表、数组、树等问题时,这个标准定义下的多项式时间和我们传统的多项式时间相差无几。比如,用选择排序对元素个数为的数组进行排序时,传统时间复杂度为
。输入规模
,因此,得到的标准时间复杂度是
,仍然是多项式时间。
类似的,假设在带有个节点、
条边的图中做DFS(深度优先搜索),传统时间复杂度为
。数据规模
,因此,标准时间复杂度是
,仍是多项式时间的。
然而,当我们处理一些与数论有关的问题时,事情就不太乐观了。现在我们来讨论判断一个整数是否为素数的算法,下面是一个简单的算法:
显然,这个算法在传统时间复杂度计算方法中是多项式时间的。我们不妨认为它的传统时间复杂度是function isPrime(n): for i from 2 to n - 1: if (n mod i) = 0, return false return true。然后我们再来分析这个问题的输入规模,可能有的同学会说,对于32-bit整数,这个输入规模不就是32吗?这话虽然没错,但是因为在这个问题中,输入规模完全依赖于
的大小,所以
的范围不再限制在32-bit整数的范围内,而是要探讨当
更大时对数据规模的影响。我们知道,保存一个整数所需要的bit位数
,因此,在标准的时间复杂度中,此算法的复杂度变为了
!这已经不再是多项式时间,而是一个指数时间。
我们可以从下面这个例子中直观感受一下这种指数时间的增长速度:
对于一个二进制串:
10001010101011
我们记指数时间复杂度算法运行时间为T。
然后,我们在二进制串后面仅仅增加一位:
100010101010111
这时,算法运行时间会变为2T(至少)!因此,我们仅仅增加几个bit 就会使得算法运行时间成倍成倍的增长。
... ...
最后我们来说伪多项式时间的定义:
如果一个算法的传统时间复杂度是多项式时间的,而标准时间复杂度不是多项式时间的,则我们称这个算法是伪多项式时间的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号