(原创)tensorflow目标检测框架(object detection api)源码细粒度剖析
一.前言
Tensorflow 推出的 Object Detection API是一套抽象程度极高的目标检测框架,可以快速用于生产部署。但网络上大多数相关的中英文文章均只局限于应用层面的分析,对于该套框架的算法实现源码没有针对性的分析文章。对于选择tensorflow作为入门框架的深度学习新手,不仅应注重于算法本身的理解,更应注重算法的编码实现。本人也是刚入门深度学习的新手,深深困扰于tensorflow 目标检测框架的抽象代码,因此花费了大量时间分析源码,希望能对读者有益,同时受限于眼界,文章中必然存在有错误或不得其义的理解,欢迎各位指正。
二. 目标检测算法简介
Object Detection API实现了多种目标检测算法,包括faster-rcnn, rfcn, ssd, mask-rcnn等。本文针对于ssd算法的具体算法进行分析。其他算法可相应进行分析。
ssd算法的原文链接如下:
[https://arxiv.org/abs/1512.02325]
对ssd算法实现分析较好的文章有:
三. Object Detection API简介
1.模型总体架构简介
tensorflow object dectection API下的所有模型必须实现DetectionModel接口(请参阅完整定义object_detection/core/model.py),每一个模型需要实现如下五个功能:
- preprocess: 数据预处理。
- predict: 数据预测。
- postprocess:数据后处理。
- loss:损失函数计算
- restore:将checkpoint加载到Tensorflow图形中。
在模型预测阶段,数据流流程如下:
inputs (images tensor) -> preprocess -> predict -> loss -> outputs (loss tensor)
在模型验证阶段,数据流流程如下:
inputs (images tensor) -> preprocess -> predict -> postprocess ->outputs (boxes tensor, scores tensor, classes tensor, num_detections tensor)
更详细的架构说明见官方文档:[https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/defining_your_own_model.md]
对object dectection API有较好解读的文章有:
1.[https://becominghuman.ai/tensorflow-object-detection-api-basics-of-detection-7b134d689c75]
2.模型配置文件简介
tensorflow dectection API采用protobuf文件来管理模型参数的配置,通过这种方式实现了多种算法的参数灵活更换。但也是因为这种参数配置方式,加大了分析源码的难度。
详细的参数配置文档见[https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/configuring_jobs.md]
四. ssd算法源码解析
现在进入正题,分析ssd算法的源码实现。本文采用的ssd算法的特征提取层采用mobilenetv1,其他的特征提取层如mobilenetv2, resnet,inception等可以同样分析。关于特征提取层的网络代码实现本文不详细描述,有时间再开一篇博文解读。
首先附上ssd+mobilenetv1在验证阶段的tensorboard模块图:
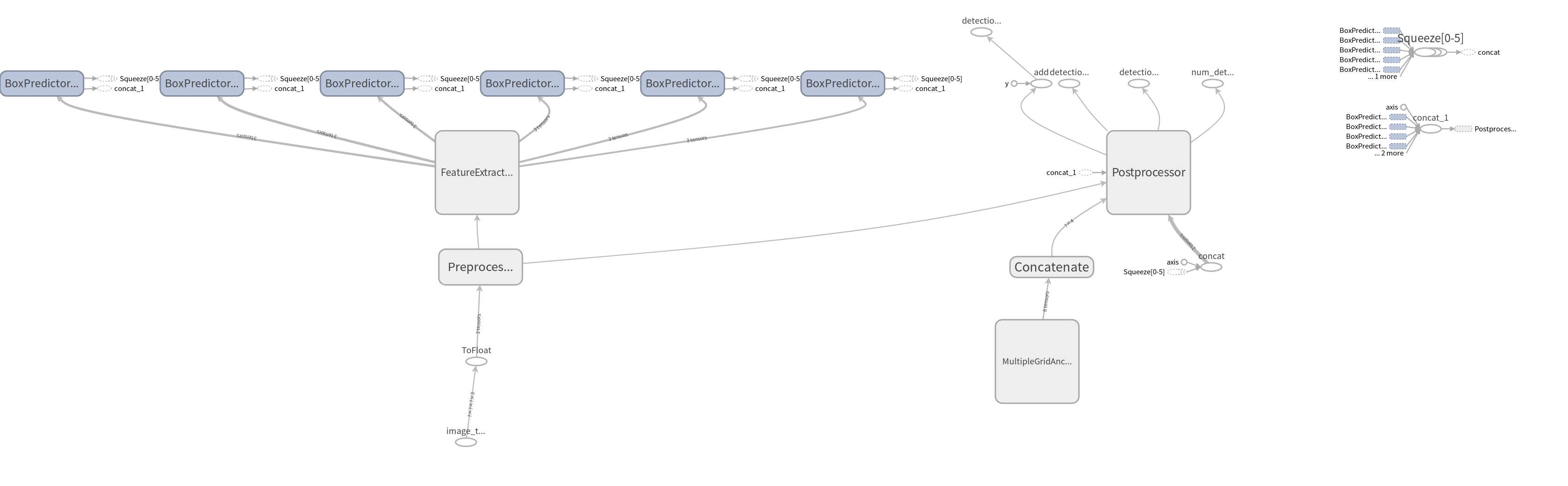 Figure 1. ssd+mobilenetv1 tensorflow模块图
Figure 1. ssd+mobilenetv1 tensorflow模块图
A) ssd算法概述
ssd算法是一种直接预测目标类别和bounding box的多目标检测算法。与传统的faster rcnn相比,该算法没有生成 region proposal 的过程,因此极大提高了检测速度。
ssd算法的结构如下:
- SSD模型的第一环节是特征提取。特征提取可以采用主流的一些卷积模型(如VGG,Inception等),特征提取时的不同卷积层feature map的输出将同时送到到下一环节”检测“。
- SSD模型的第二环节是检测。检测环节采用一系列的小卷积模块(
3*3,1*1)来预测物体的类别与坐标。由于上一层输入的不同层数的feature map有不同的感受野,因此检测环节可以认为是对不同尺寸的图像进行回归和分类。检测环节可以细分成如下几个子模块。
- box generator: 针对不同卷积层(如
19*19,10*10)的feature map cell(feature map中的每个小格子),产生不同尺寸(scale)、不同纵横比(aspect ratios)的default boxes。- classification: 上述的default boxes通过classification预测对应feature map cell的类别(C+1类别, C为所有分类,1为背景)
- localization:上述的default boxes通过localization预测对应feature map cell的坐标
- SSD模型的第三环节是损失计算。该环节主要用于训练过程,损失函数包括Classification loss 和Localization losses。通过损失的最小化,缩短Classification 和Localization的预测误差。
- SSD模型的第四环节是后处理。 该环节主要用于验证过程,通过NMS(非极大值抑制)筛选出置信度最高、存在目标的区域。
注:后文出现的default box和anchor, anchor box的意思均指同一个box。
此处附上论文中的SSD模块框架图,帮助理解。
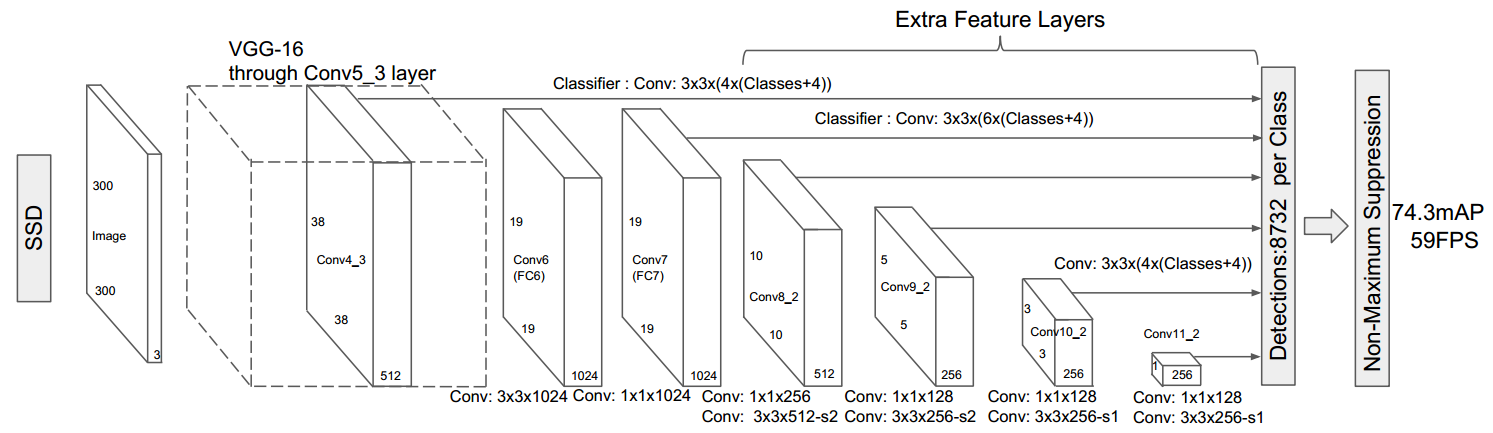 Figure 2. ssd论文模块框架
Figure 2. ssd论文模块框架
B) ssd训练过程源码分析
Train总体流程分析
ssd训练流程从Train.py中main()开始,
- 首先通过get_configs_from_pipeline_file()获得"model", "train", ”input“的相关protobuf配置参数。 本文采用"ssd_mobilenet_v1_pets.config"加以分析。该config文件的详情见附录。
- 固定相关参数,生成"model", ”input“的偏函数,便于调用。其中input的数据处理框架采用dataset机制,可以高效地向模型输入数据。这种机制比Reader的方式要高效很多,具体输入线程机制对比可参考美团技术团队的博文[https://www.toutiao.com/i6540566996331790852/?iid=29552265324&app=news_article×tamp=1522848438].
- 调用Trainer.train(create_input_dict_fn, model_fn, train_config...)。进行创建ssd模型,创建input输入流,创建算法主流程, 选择训练优化器, 计算total loss和梯度, 更新梯度,静态图所有操作节点添加好后,调用slim.learning.train()输入数据流进行反复训练迭代。
相应的流程图例如下:
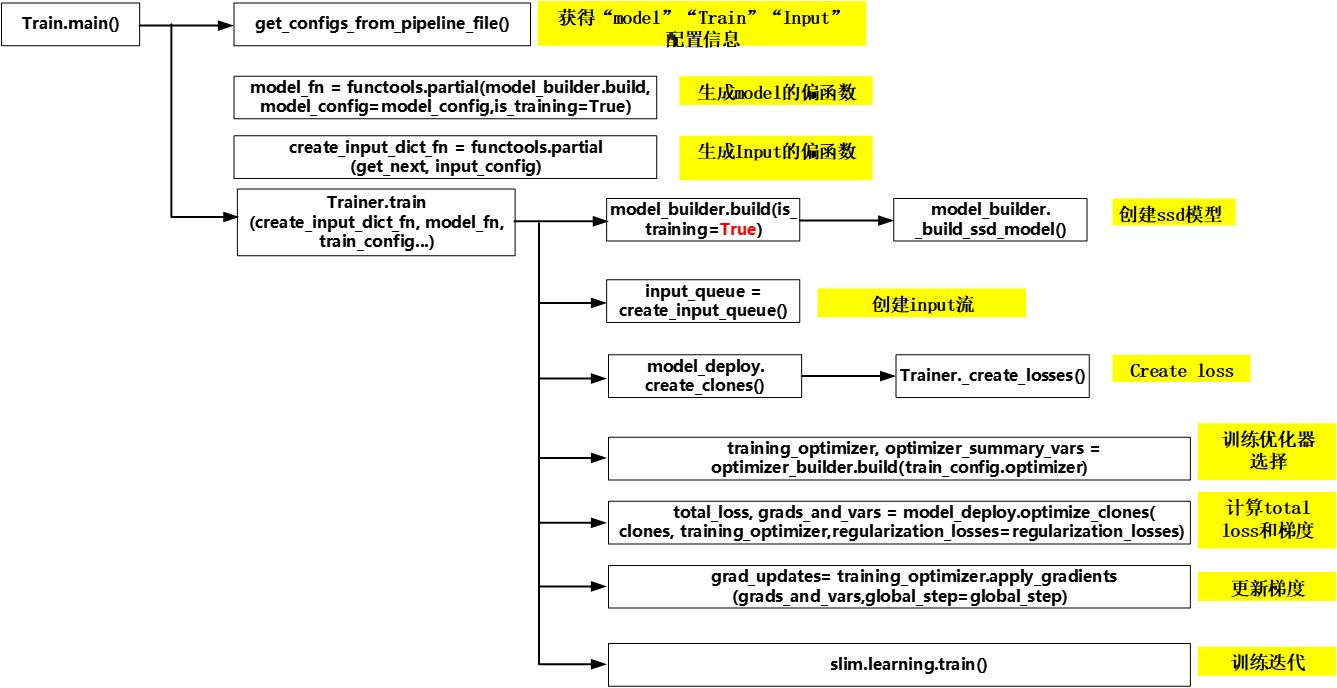 Figure 3. Train总体流程
Figure 3. Train总体流程
创建ssd模型分析
主体模型的选择在model_builder.build()中,由于选择的是ssd模型,因此在model_builder._build_ssd_model(ssd_config, is_training, add_summaries)中构建ssd模型。其中输入的ssd_config参数即为从"ssd_mobilenet_v1_pets.config"中提取出来的参数。
模型配置主要涉及到如下几个方面:
- 特征提取层(feature_extractor)
- box_coder(不知道何用,注释说 Scales location targets as used in paper for joint training,应该和faster-rcnn有关)
- 匹配规则(matcher)
- 区域相似度度量规则(region_similarity_calculator)
- 卷积预测层模块参数(ssd_box_predictor)
- 预测用的系列defaut_boxes(anchor_generator)
- 图像后处理(non_max_suppression_fn, score_conversion_fn,只用于验证流程,在训练流程中不使用)
- 损失函数及难样本挖掘规则(classification_loss、localization_loss、hard_example_miner)。
相应的流程图例如下:
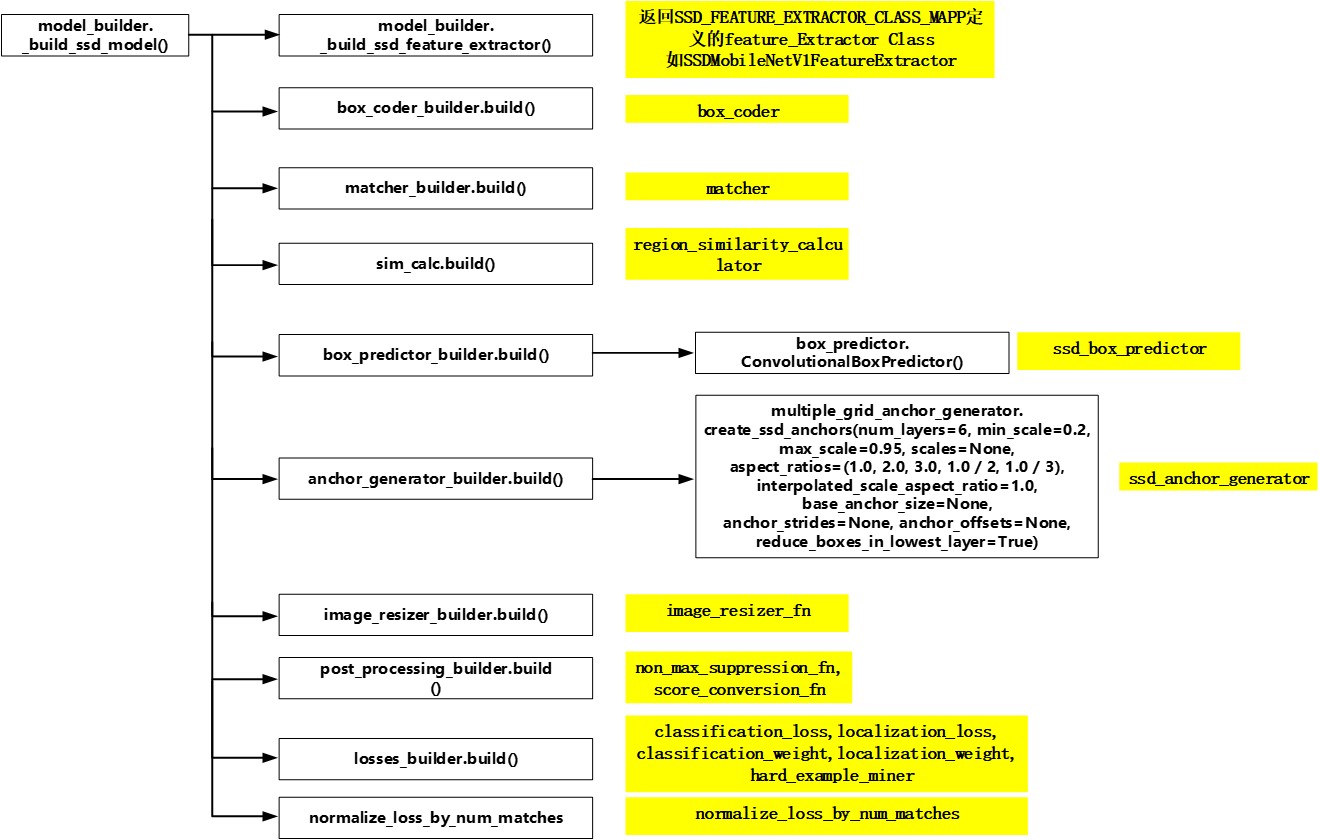 Figure 4. 创建ssd模型
Figure 4. 创建ssd模型
模型参数配置完后实例化ssd_meta_arch.SSDMetaArch(), SSDMetaArch()即为继承自DetectionModel()的类,其本身还有preprocess, _compute_clip_window(), predict()、postprocess()等方法。
所以说ssd_meta_arch.SSDMetaArch()是整个框架中最重要的数据结构。
因此简单将SSDMetaArch()的方法整理一下,如下图:
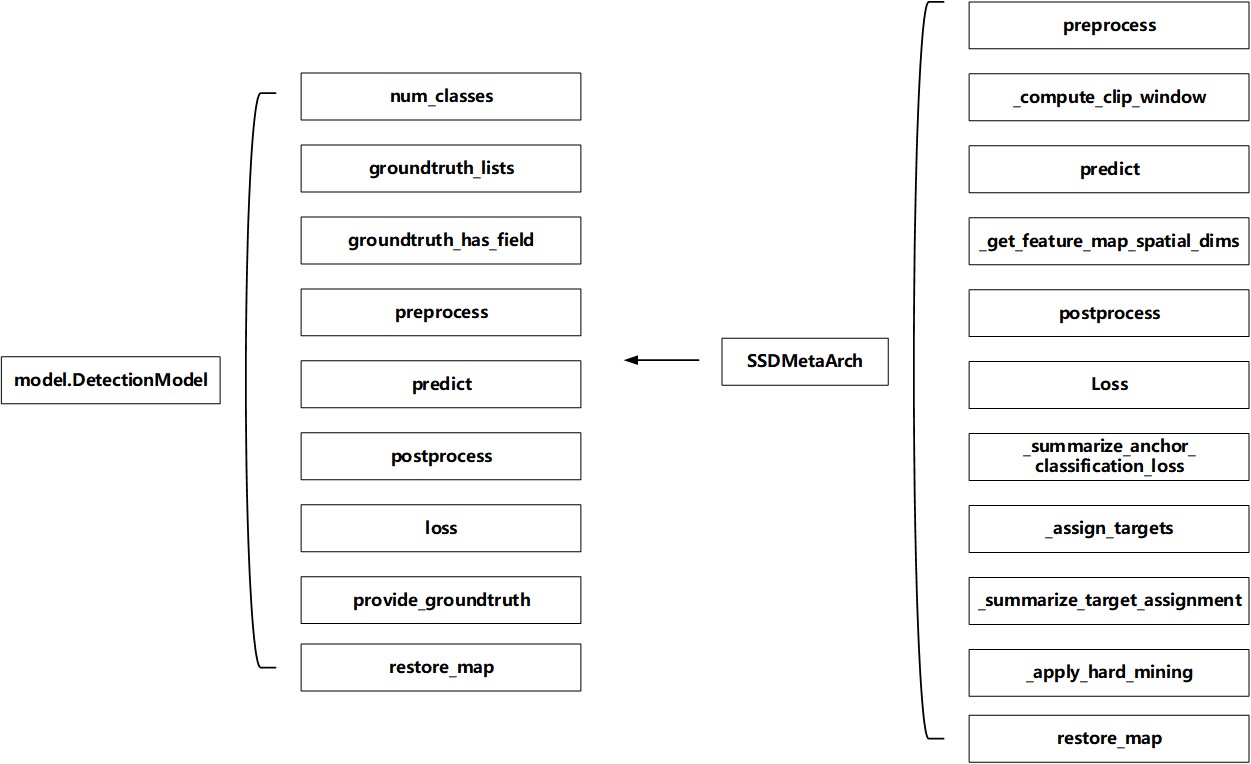 Figure 5. SSDMetaArch()数据结构
Figure 5. SSDMetaArch()数据结构
对anchor核心参数计算的分析
上一节创建ssd模型分析说到模型配置涉及的几个主要方面,其中的anchor_generator需要着重分析,因为default_boxes的生成方法是论文的核心。因此对照源码,分析anchor生成的编码实现流程。这段代码基本与原文的公式对应,通过create_ssd_anchors()生成了特征提取层每层feature map需要使用到的anchor的aspect_ratio和scale参数。具体的anchor生成过程会在后续分析。
def create_ssd_anchors(num_layers=6, min_scale=0.2,
max_scale=0.95,
scales=None,
aspect_ratios=(1.0, 2.0, 3.0, 1.0 / 2, 1.0 / 3),
interpolated_scale_aspect_ratio=1.0,
base_anchor_size=None,
anchor_strides=None,
anchor_offsets=None,
reduce_boxes_in_lowest_layer=True):
#base_anchor_size = [1.0,1,0]
base_anchor_size = tf.constant(base_anchor_size, dtype=tf.float32)
box_specs_list = []
#min_scale = 0.2, max_scale = 0.95, num_layers = 6, 这三个参数在"ssd_mobilenet_v1_pets.config"中定义
#scales = [0.2, 0.35 , 0.5, 0.65 0.80, 0.95, 1]
scales = [min_scale + (max_scale - min_scale) * i / (num_layers - 1)
for i in range(num_layers)] + [1.0]
for layer, scale, scale_next in zip(
range(num_layers), scales[:-1], scales[1:]):
layer_box_specs = []
if layer == 0 and reduce_boxes_in_lowest_layer:
#layer =0时,只有三组box, 如何选取??
layer_box_specs = [(0.1, 1.0), (scale, 2.0), (scale, 0.5)]
else:
#aspect_ratios= [1.0, 2.0 , 0.5, 3.0, 0.3333]
#aspect_ratios可在"ssd_mobilenet_v1_pets.config"中自行定义
for aspect_ratio in aspect_ratios:
layer_box_specs.append((scale, aspect_ratio))
#多增加一个anchor, aspect ratio=1, scale是现在的scale与下一层scale的乘积开平方。
if interpolated_scale_aspect_ratio > 0.0:
layer_box_specs.append((np.sqrt(scale*scale_next),
interpolated_scale_aspect_ratio))
box_specs_list.append(layer_box_specs)
return MultipleGridAnchorGenerator(box_specs_list, base_anchor_size,
anchor_strides, anchor_offsets)
算法主流程分析
Trainer.train()中的model_deploy.create_clones(deploy_config, model_fn, [input_queue])可将将输入数据流及模型算法布署到多台主机进行分布式训练,本文只关心其模型算法的布署细节,因此只关心其调用的Trainer._create_losses()方法细节。
Trainer._create_losses()分成如下四个流程:
- 获得一定batch的图片及对应的真实box的坐标、分类标签。
- 图片预处理,将图片缩放成300*300
- 对图片进行预测
- 计算损失
相应的流程图例如下:
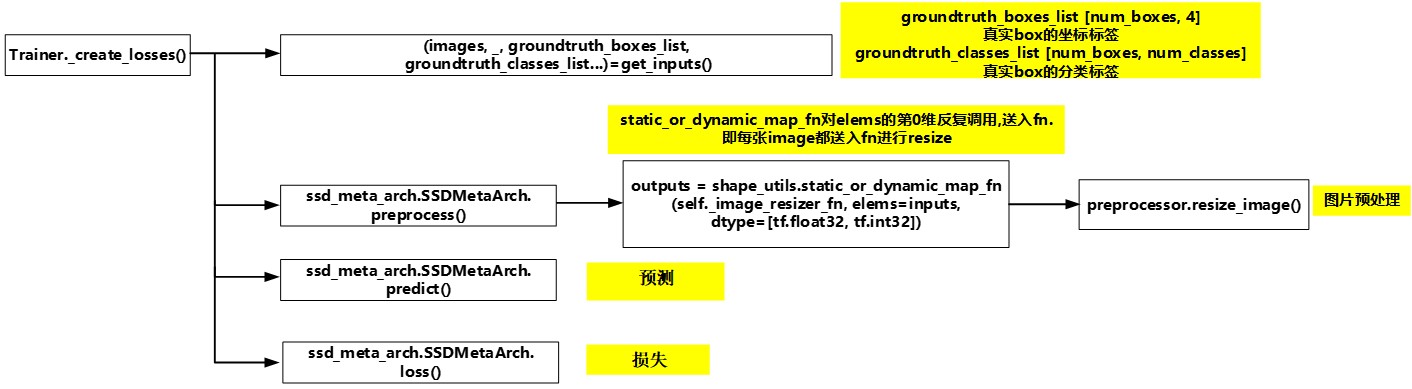 Figure 6. create_loss主流程
Figure 6. create_loss主流程
流程三预测及流程四计算损失是整个算法的核心,因此接下来着重这两部分的分析。
predict流程分析
预测流程从SSDMetaArch.predict()开始调用, 可以分成如下四个流程:
- 特征提取: mobilenetv1的特征提取层提取出不同层的feature map, 一共获得6层。(6层featuremap的尺寸是[(19,19) (10,10) (5,5) (3,3) (2,2) (1,1)])
- anchor生成:根据各个特征提取层的尺寸及之前确定的scales, aspect ratios参数生成1917个anchor。(6层featuremap的单个cell对应anchor个数为[3,6,6,6,6,6])
$$1917=19193+10106 + 556 + 336+226+116$$ - 对每一层feature map分别预测其anchor的分类及坐标.
- 将所有feature map的anchor的分类及坐标整合在一起。
相应的流程图例如下:
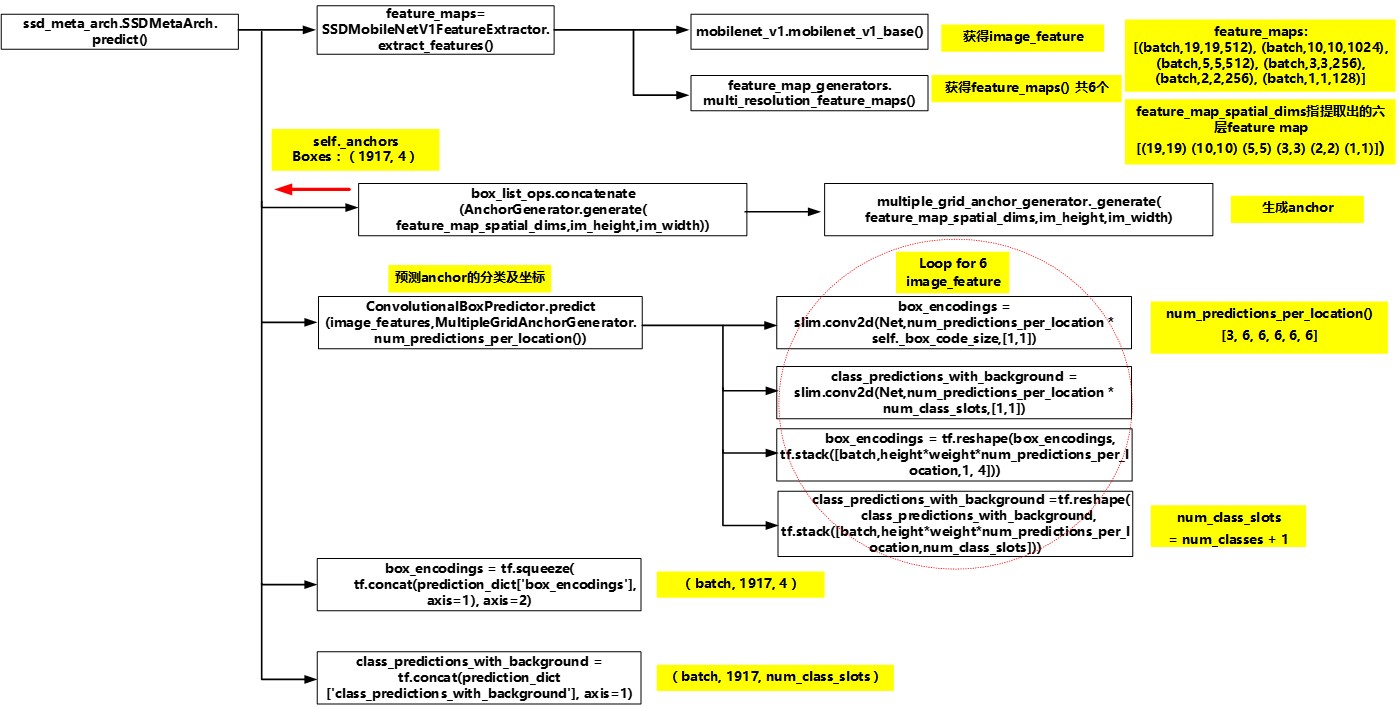 Figure 7. predict总体流程
Figure 7. predict总体流程
对特征提取层的分析实际就是分析对应的mobilenetv1的结构,本文不作深入分析。预测anchor的分类及坐标的代码比较清晰,就是简单的多次卷积操作,因此本文不做详细说明。
因此重点分析如何生成1917个anchor。随后在计算损失的环节anchor的真实分类及坐标标签将会与预测分类及坐标值对比,从而计算出总的损失值。
1). anchor_generator分析
anchor generator的流程会生成每个feature map对应的所有anchor,然后将所有anchor串联起来。因此我们以其中一个feature map(19,19)为例,分析该feature map上使用的anchor的生成细节。生成anchor的细节在GridAnchorGenerator.tile_anchors()中。
生成anchor的步骤如下:
- 通过调用MultipleGridAnchorGenerator.create_ssd_anchors()计算出了每一层使用的anchor的scale和aspect ratio,因此可以计算出第k个feature map下所使用的anchor的长和宽,公式分别为\(h_k^a = {s_k}/\sqrt {{a_r}}\)和\(w_k^a = {s_k}\sqrt {{a_r}}\)。k=0,1...5
- 确定所有anchor的中心位置的纵坐标和横坐标。中心位置的公式为\((\frac{{i + 0.5}}{{\left| {{f_k}} \right|}},\frac{{j + 0.5}}{{\left| {{f_k}} \right|}})\),其中\(i,j \in [0,\left| {{f_k}} \right|)\)。
- 生成anchor的三维网格坐标。
- 计算获得所有anchor的bbox_centetrs与bbox_sizes坐标,shape均为(1083,2),其中每个bbox_center坐标均为(y_center,x_center)形式,每个bbox_sizes坐标均为(height,width)形式。
- 计算获得所有anchor的坐标,shape为(1083,4)。其中每个anchor的坐标形式均为(ymin,xmin,ymax,xmax)。
相应的流程图例如下:
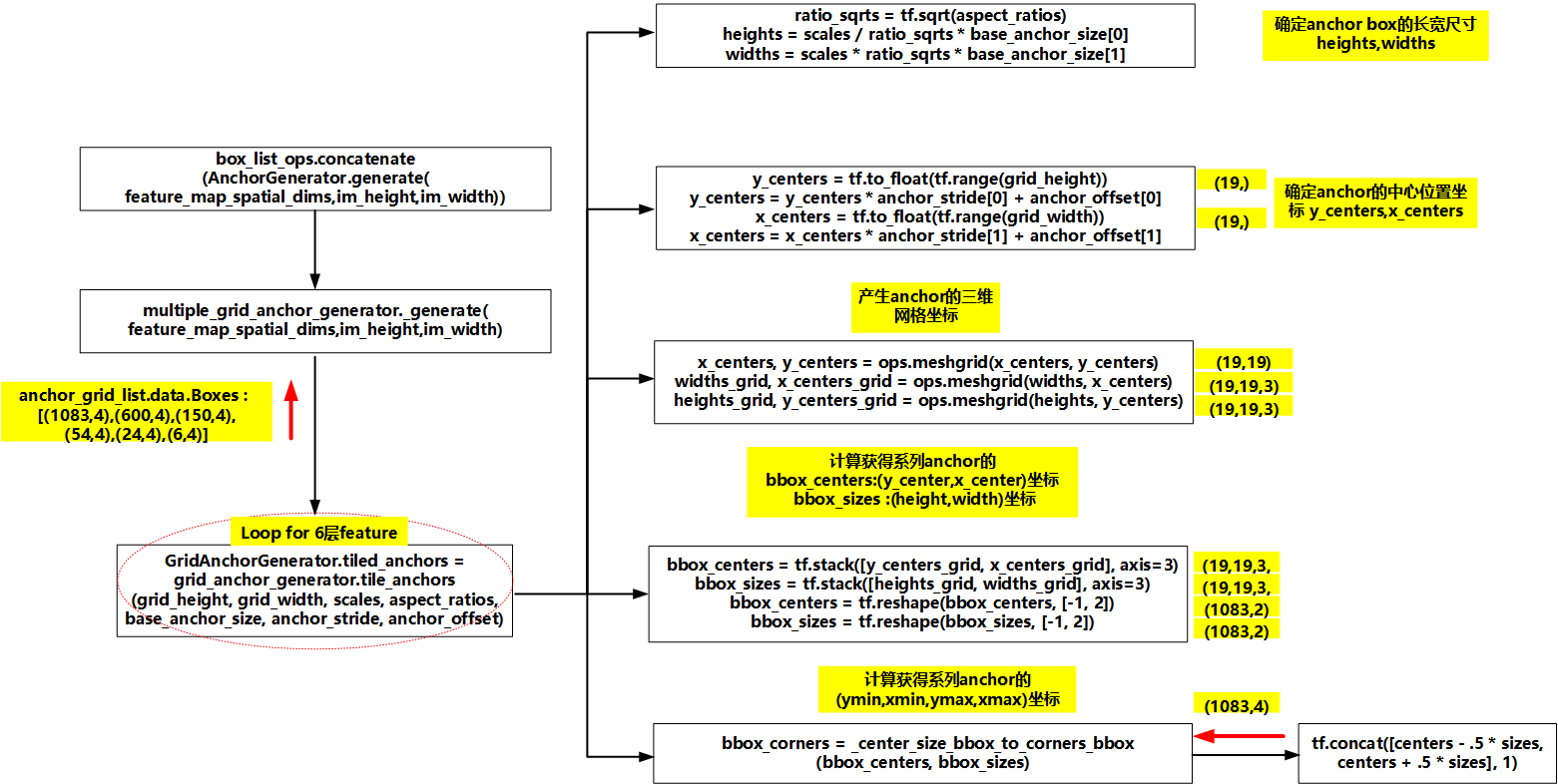 Figure 8. anchor核心参数确定
Figure 8. anchor核心参数确定
loss流程分析
预测流程从ssd_meta_arch.SSDMetaArch.loss()开始调用, 可以分成如下五个流程:
- 所有anchor与真实box按照IOU进行配对,返回anchor对应的groundth box的坐标及分类标签。
- 计算每一个anchor的location loss,注意anchor只有对应groundth box才会有有效的location loss。
- 计算每一个anchor的classification loss,每个anchor都会有有效的classification loss,包括对应背景标签的anchor。
- 由于正负样本的不均衡,因此对loss进行难样本挖掘(apply_hard_mining),保证正负样本比例在1:3。
- 根据公式对location loss和classification loss进行标幺化。
相应的流程图例如下:
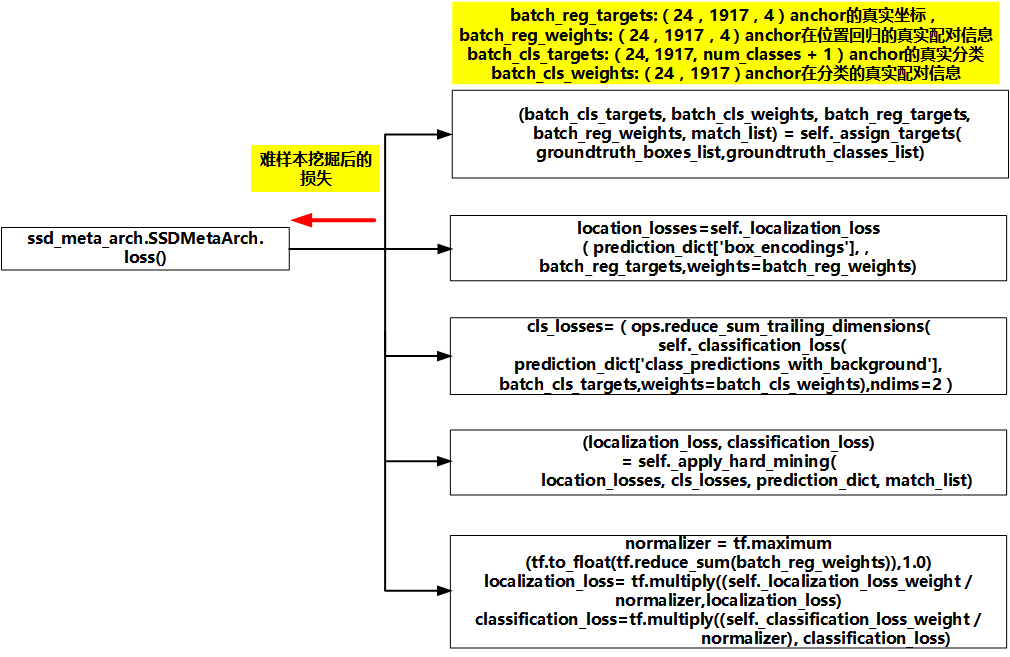 Figure 9. loss总体流程
Figure 9. loss总体流程
loss计算在算法里是最核心的部分,同时也是分析难度最大的部分,为了尽可能描述清楚loss的编码流程,这一部分的每个流程都会详细分析,并辅以必要的代码分析。
1)matching strategy
第一部分的matching strategy指的是每个anchor与groundth box的配对。也就是对所有anchor区分出正样本和负样本。这部分的原理如论文所述,截图如下:

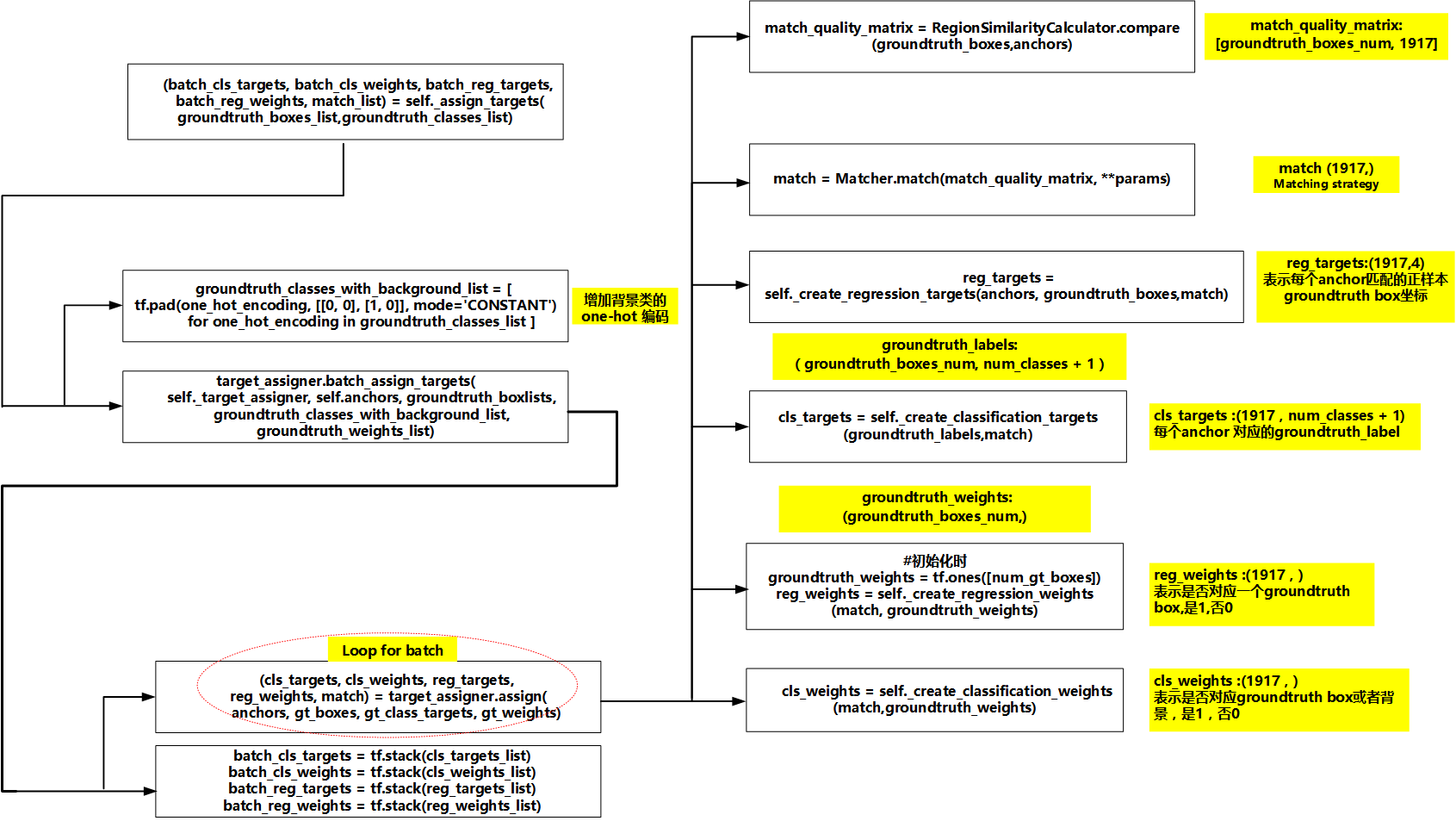 Figure 10. matching_strategy总体流程
Figure 10. matching_strategy总体流程
# 运行matching strategy, 获得每个anchorc对应的groundth box编号 match(1917, )
match = self._matcher.match(match_quality_matrix, **params)
# 获得每个anchor匹配的正样本groundtruth box与anchor的坐标差距,即论文中的$\widehat g_j^m$,无效或负样本(背景)用[0 0 0 0], reg_targets(1917,4)
reg_targets = self._create_regression_targets(anchors, groundtruth_boxes, match)
# 获得每个anchor匹配的正样本groundtruth box的分类 cls_targets (1917, num_classes + 1)
cls_targets = self._create_classification_targets(groundtruth_labels, match)
#表示anchor是否对应一个groundtruth box,是1,否0,用于计算location loss。 reg_weights (1917,)
reg_weights = self._create_regression_weights(match, groundtruth_weights)
#表示anchor是否对应一个groundtruth box或者背景,是1,否0,用于计算classification loss。 cls_weights (1917,)
cls_weights = self._create_classification_weights(match, groundtruth_weights)
限于篇幅,我们着重关注match和reg_targets的源码实现。
##### A) match细节(ArgMaxMatcher._match(self, similarity_matrix))
先贴相应的流程图例:
<center>
<img src="https://images2018.cnblogs.com/blog/1410422/201805/1410422-20180530183614537-1391787123.png" width="100%" alt="match细节" align=center/>
Figure 11. match细节
</center>
从match细节实现上,可以看出匹配思路与论文中的稍微不一样。编码思路如下:
1. 首先获得每个default box对应的最匹配groundtruth box。
2. 然后再将其中IOU<unmatched_threshold(0.5)的default box重对应成unmatched(即标记为-1)。 由于"ssd_mobilenet_v1_pets.config" 中定义unmatched_threshold = matched_threshold = 0.5, 因此不会有default box 对应ignored(-2)。 如果unmatched_threshold != matched_threshold,由可能会有default box 对应ignored标记, 这种情况本文不加以分析,有兴趣自行分析。<font color=#ff0000 size=5 face="黑体">(注:Yolo v3论文中提及了这种Dual IOU threshold方式,谈及是faster rcnn里使用,但似乎我在faster rcnn论文中没有找到这一点,不清楚双阈值的设定好处如何??不知道是否有网友帮忙解惑。)</font>
3. 由于流程2的阈值的引入,可能会出现某个groundtruth box无对应的default box的特殊情况出现,因此强行保证每个groundtruth box能至少对应上一个default box。
##### B) reg_targets细节(TargetAssigner._create_regression_targets(anchors, groundtruth_boxes,match))
先贴相应的流程图例:
<center>
<img src="https://images2018.cnblogs.com/blog/1410422/201805/1410422-20180530190408321-1952954892.png" width="100%" alt="reg_targets" align=center/>
Figure 12. reg_targets
</center>
reg_targets的主要目的是获得每个anchor匹配的正样本groundtruth box与anchor的坐标差距,即论文中的$\widehat g_j^m$。此处将论文中的相关公式贴出
$$\begin{array}{l}
\widehat g_j^{cx} = (g_j^{cx} - d_i^{cx})/d_i^w\\
\widehat g_j^{cy} = (g_j^{cy} - d_i^{cy})/d_i^h\\
\widehat g_j^w = \log (\frac{{g_j^w}}{{d_i^w}})\\
\widehat g_j^h = \log (\frac{{g_j^h}}{{d_i^h}})
\end{array}$$
**2)localization_loss**
第二部分的localization_loss 计算每个anchor的location_loss,贴出论文中的相关公式:
$$\sum\limits_{m \in \{ cx,cy,w,h\} } {x_{ij}^ksmoot{h_{L1}}(l_i^m - \widehat g_j^m)} $$
贴上相应的流程图例:
<center>
<img src="https://images2018.cnblogs.com/blog/1410422/201805/1410422-20180530193320854-645632651.png" width="50%" alt="localization_loss" align=center/>
Figure 13. localization_loss
</center>
需要注意的是这里的localizatio_loss计算了每个anchor的loss,由于负样本远远高于正样本,因此后续还有难样本挖掘算法挑选出1:3的正负样本以计算总的localizatio_loss。
**3)classification_loss**
第三部分的classification_loss 计算每个anchor的classification_loss,贴出论文中的相关公式:
$$\left\{ \begin{array}{l}
x_{ij}^p\log (\widehat c_i^p){\rm{ }}(i \in Pos)\\
\log (\widehat c_i^0){\rm{ }}(i \in Neg)
\end{array} \right.where{\rm{ }}\widehat c_i^p = \frac{{\exp (c_i^p)}}{{\sum\limits_p {\exp (c_i^p)} }}$$
贴上相应的流程图例:
<center>
<img src="https://images2018.cnblogs.com/blog/1410422/201805/1410422-20180530194350671-392266190.png" width="50%" alt="classification_loss" align=center/>
Figure 14. classification_loss
</center>
需要注意的是tensorflow官方给的实现classification_loss使用的是**WeightedSigmoidClassificationLoss**,而不是论文里的softmax_loss。 当然源码里是提供了WeightedSoftmaxClassificationLoss供训练。但官方放出的源码采用WeightedSigmoidClassificationLoss,是否意味着此处用sigmoid loss比softmax loss的训练效果更好??? <font color=#ff0000 size=3 face="黑体">(注:yolo v3论文中谈及 softmax的使用对性能没有好处,说softmax基于一个box只有一个类别的假设。官方不使用softmax而使用sigmoidloss,也是为了适用于每个类别相互独立但互不排斥的情况)</font>
**4)apply hard mining**
第四部分的apply hard mining对正负样本进行难样本挖掘,从而挑选出1:3的正负样本。首先看一下论文对难样本挖掘的方法介绍。
<center>
<img src="https://images2018.cnblogs.com/blog/1410422/201805/1410422-20180530195031062-1961879128.png" width="60%" alt="paper_hard_mining" align=center/>
</center>
论文里介绍的难样本挖掘技术比较简单,缺乏细节。
因此结合源码对难样本挖掘的细节进行分析。
首先贴上相应的流程图例:
<center>
<img src="https://images2018.cnblogs.com/blog/1410422/201805/1410422-20180530210125889-1982435200.png" width="90%" alt="hard_mining" align=center/>
Figure 15. hard_mining
</center>
源码采用的难样本挖掘技术分成以下几步:
>1. 采用非大值抑制贪婪算法,在最多取3000张样本的情况取出分类置信度最高的anchor。每选出一个高置信度的anchor,都会将与其iou大于一定阈值的anchor剔除。 具体的非大值抑制贪婪算法实现源码可参考
[https://www.pyimagesearch.com/2014/11/17/non-maximum-suppression-object-detection-python/] 及[https://www.pyimagesearch.com/2015/02/16/faster-non-maximum-suppression-python/]。
>2. 对挑选出来的anchor按差不多1:3的比例挑选正负样本。其中正样本的数量是确定的,负样本的数量可能是正样本的3倍,也可能限制于总样本的数量。
**4)标幺化**
第五部分标幺化比较简单,就是计算出难样本挖掘后正样本的个数,loss除以这个系数即可,附上论文公式。
$$L(x,c,{\mathop{\rm l}\nolimits} ,g) = \frac{1}{N}({L_{conf}}(x,c) + \alpha {L_{loc}}(x,l,g))$$
注意公式中的$\alpha $似乎在源码中直接取了1。
## C) ssd验证过程源码分析
验证过程相对于训练过程而言多了一个postprocess的模块处理,这部分源码之后再进行分析。
未完待续
## D) ssd算法总结:
看完上文对ssd算法源码分析,读者是否对ssd算法有了细致入微的理解? 我归纳了ssd算法需要理解的几个核心论点(启发于[https://becominghuman.ai/tensorflow-object-detection-api-basics-of-detection-7b134d689c75]),能够解读这几个问题,就差不多能掌握ssd算法的算法实现。读者可以对照前面的分析,对不理解的地方再进行研究。
1. anchor box的生成算法。
2. matching strategy的算法。
3. training loss的算法。
4. 非极大值抑制的算法
5. 难样本挖掘的算法。
<div style="background:#FFF68F; color:#0; font-size:small;">
<p >
作者:
<a href="http://www.cnblogs.com/HaijunLv/">HaijunLv</a>
</p>
<p >
出处:
<a href="https://www.cnblogs.com/HaijunLv/p/9101957.html">https://www.cnblogs.com/HaijunLv/p/9101957.html></a>
</p>
<p >
关于作者:专注深度学习领域,请多多赐教!
</p>
<p >
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出,
<a href="#" onclick="Curgo()" style="background:#b6ff00; color:#0; font-size:medium;">原文链接</a>
如有问题, 可邮件(248354172@qq.com)咨询.
</p>
<script type="text/javascript">
function Curgo()
{
window.open(window.location.href);
}
</script>
</div>
转载请注明出处
 浙公网安备 33010602011771号
浙公网安备 33010602011771号