


Datawhale组队学习 深入浅出Pytorch Task 4🌷
Datawhale组队学习
PyTorch进阶训练技巧
作者:博客园-岁月月宝贝
参考视频:Pytorch模型定义与训练技巧_哔哩哔哩_bilibili
代码来源:[thorough-pytorch/notebook/第六章 PyTorch进阶训练技巧/PyTorch模型定义与进阶训练技巧.ipynb at main · datawhalechina/thorough-pytorch](https://github.com/datawhalechina/thorough-pytorch/blob/main/notebook/第六章 PyTorch进阶训练技巧/PyTorch模型定义与进阶训练技巧.ipynb)
讲解内容:thorough-pytorch/source/第五章 at main · datawhalechina/thorough-pytorch
本节重点如下:
- 自定义损失函数
- 动态调整学习率
- 模型微调
- 半精度训练😘
我们Task3为大家介绍了模型定义方式,利用模型快速搭建复杂网络,以及模型修改和模型如何保存和读取。
下面我们以前面已经搭建好的U-Net模型为例,探索如何更优雅地训练Pytorch模型→
首先我们使用Carvana数据集(汽车的自然图像数据集,有车的位置的分割),实现一个基本的U-Net训练过程:
文件布置:
导入必要包:
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
import torch.optim as optim
import matplotlib.pyplot as plt
import PIL
from sklearn.model_selection import train_test_split
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
#os.environ['CUDA_VISIBLE_DEVICES'] = '2,3'
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
下面我们主要用Carvana有标签的训练集作了训练集和验证集的划分:
class CarvanaDataset(Dataset): # Dataset的定义参见上一个视频
def __init__(self, base_dir, idx_list, mode="train", transform=None):
self.base_dir = base_dir
self.idx_list = idx_list
self.images = os.listdir(base_dir + "train")
self.masks = os.listdir(base_dir + "train_masks")
self.mode = mode
self.transform = transform
def __len__(self):
return len(self.idx_list)
def __getitem__(self, index):
image_file = self.images[self.idx_list[index]]
mask_file = image_file[:-4] + "_mask.gif"
image = PIL.Image.open(os.path.join(base_dir, "train", image_file))
if self.mode == "train":
mask = PIL.Image.open(os.path.join(base_dir, "train_masks", mask_file))
if self.transform is not None:
image = self.transform(image)
mask = self.transform(mask)
mask[mask != 0] = 1.0
return image, mask.float()
else:
if self.transform is not None:
image = self.transform(image)
return image
base_dir = "./" # 原图图片大小是 1000+ × 1000+
transform = transforms.Compose([transforms.Resize((256, 256)), transforms.ToTensor()])
train_idxs, val_idxs = train_test_split(range(len(os.listdir(base_dir + "train_masks"))), test_size=0.3) # 训练集和测试集的划分
train_data = CarvanaDataset(base_dir, train_idxs, transform=transform)
val_data = CarvanaDataset(base_dir, val_idxs, transform=transform)
train_loader = DataLoader(train_data, batch_size=32, num_workers=0, shuffle=True)#Bug num_workers=0
val_loader = DataLoader(val_data, batch_size=32, num_workers=0, shuffle=False)#Bug val_data
我们来运行代码查看下这两个数据集里面的内容:
image, mask = next(iter(train_loader))
plt.subplot(121)
plt.imshow(image[0,0])
plt.subplot(122)
plt.imshow(mask[0,0], cmap="gray")
plt.show() # 添加这一行
输出如下:
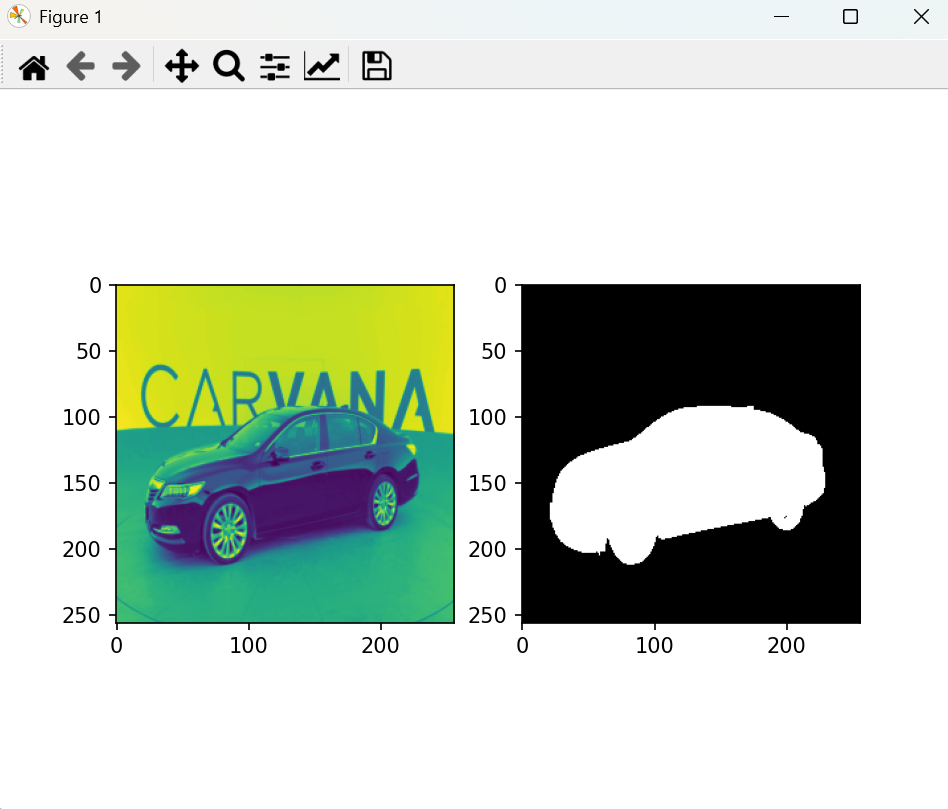
左边彩色图:RGB三通道中的一个;右边黑白图:白色的是前景,黑白色是背景
我们的任务是给我们的UNet输入RGB三通道图像,右边输出黑白分割的这样一个mask
接下来我们开启第六章四个内容的讲解!
- 自定义损失函数
- 动态调整学习率
- 模型微调
- 半精度训练😘
但是在我们进行改造之前,我们先用这些模块的基础版来完成下模型的训练:
criterion = nn.BCEWithLogitsLoss()#损失函数:Binary Cross Entropy Loss
optimizer = optim.Adam(unet.parameters(), lr=1e-3, weight_decay=1e-8)#优化器:Adam,学习率:0.001
#unet = nn.DataParallel(unet).cuda()#因为我使用的是单GPU,所以注释掉这行
unet = unet.cuda()
注意:前面必须加上我们前面定义好的unet网络,Task3里面的Point2这些都需要放在上面这个代码块前面
接下来我们添加获得结果的评价指标模块:
def dice_coeff(pred, target):
eps = 0.0001
num = pred.size(0)
m1 = pred.view(num, -1) # Flatten
m2 = target.view(num, -1) # Flatten
intersection = (m1 * m2).sum()
return (2. * intersection + eps) / (m1.sum() + m2.sum() + eps)
dice_coeff是分割模型用来评价分割好坏的一个指标(因为背景分对很容易,所以不使用accuracy),这个指标更能体现对前景也就是object分割的一个能力~
下面是模型的训练和验证模块:
def train(epoch):
unet.train()
train_loss = 0
for data, mask in train_loader:
data, mask = data.cuda(), mask.cuda()
optimizer.zero_grad()
output = unet(data)
loss = criterion(output,mask)
loss.backward()
optimizer.step()
train_loss += loss.item()*data.size(0)
train_loss = train_loss/len(train_loader.dataset)
print('Epoch: {} \tTraining Loss: {:.6f}'.format(epoch, train_loss))
def val(epoch):
print("current learning rate: ", optimizer.state_dict()["param_groups"][0]["lr"])
unet.eval()
val_loss = 0
dice_score = 0
with torch.no_grad():
for data, mask in val_loader:
data, mask = data.cuda(), mask.cuda()
output = unet(data)
loss = criterion(output, mask)
val_loss += loss.item()*data.size(0)
dice_score += dice_coeff(torch.sigmoid(output).cpu(), mask.cpu())*data.size(0)
val_loss = val_loss/len(val_loader.dataset)
dice_score = dice_score/len(val_loader.dataset)
print('Epoch: {} \tValidation Loss: {:.6f}, Dice score: {:.6f}'.format(epoch, val_loss, dice_score))
上面我们把学习率也打了出来,但是因为我们没有强行地让学习率发生变化,所以这边打出的学习率应该是不变的
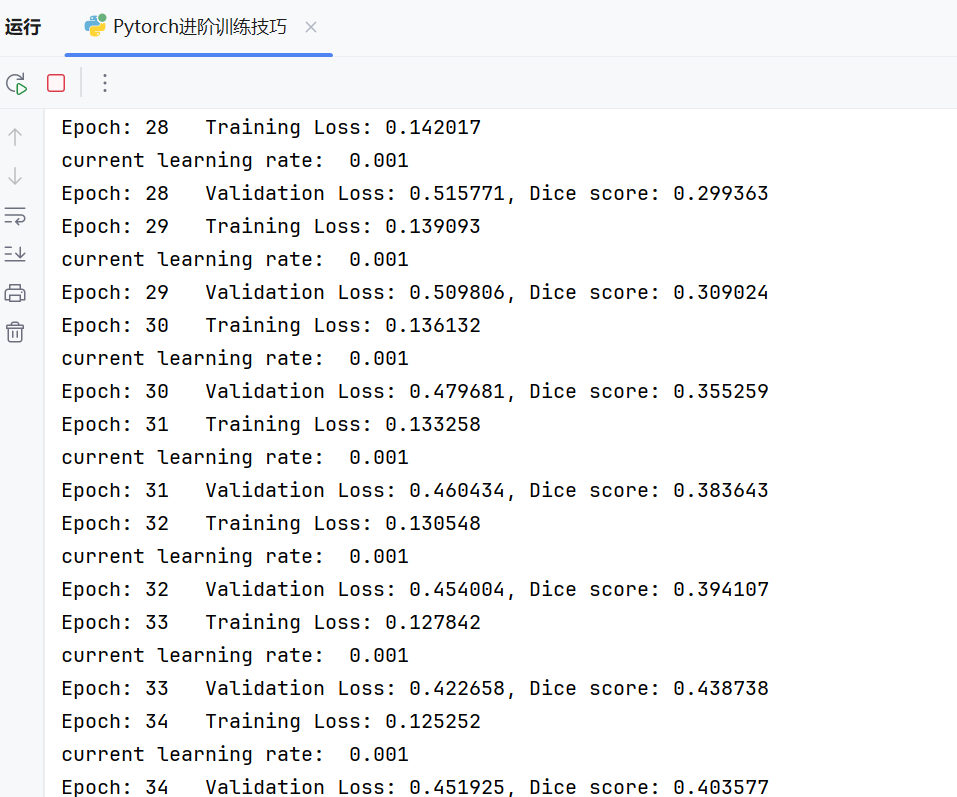
下面是模型的100轮迭代:
epochs = 100
for epoch in range(1, epochs+1):
train(epoch)
val(epoch)
下图表示模型在训练中:
在训练中(完成以上这些轮后),我们来观察下显卡的占用情况:
(步骤:1.打开 PyCharm。2.在右下角找到并点击 Terminal 标签,打开终端窗口。3.在终端中输入 nvidia-smi 并按下回车。)
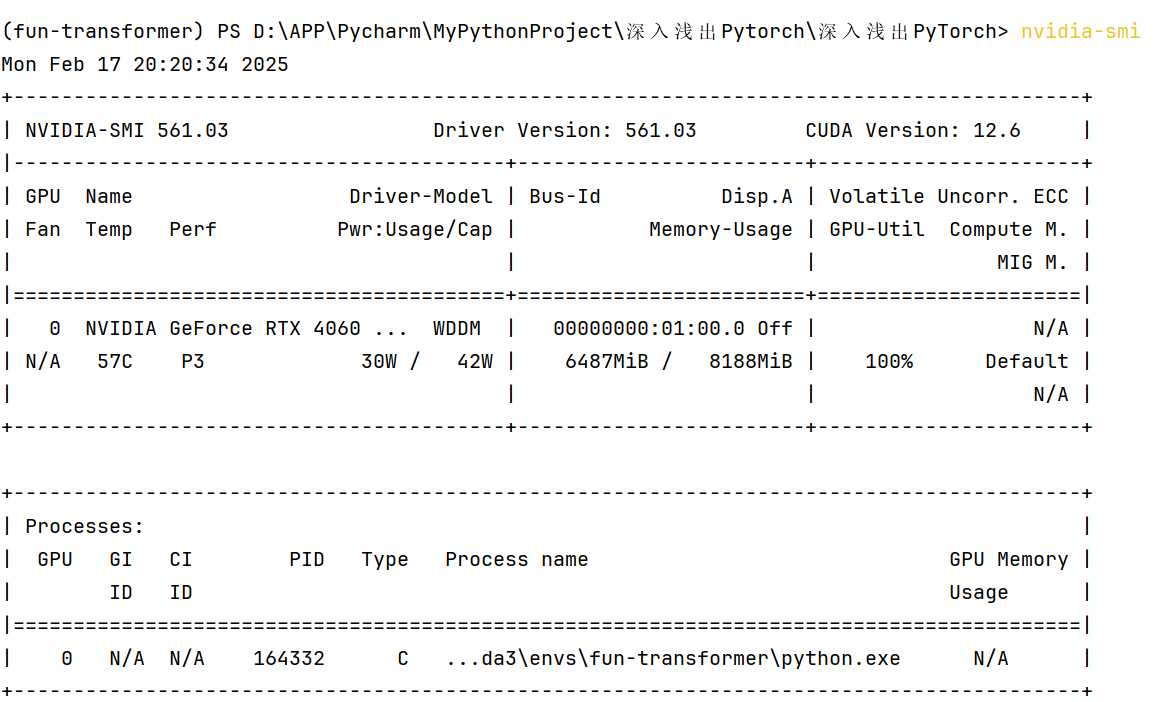
当训练完毕后:
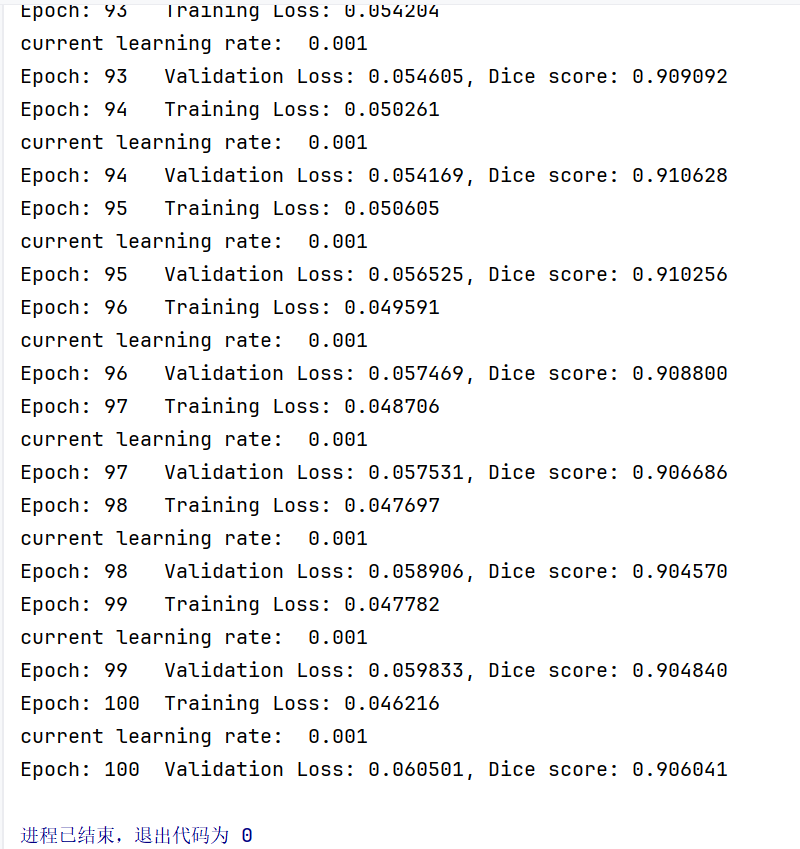
我们再看显卡占用情况:
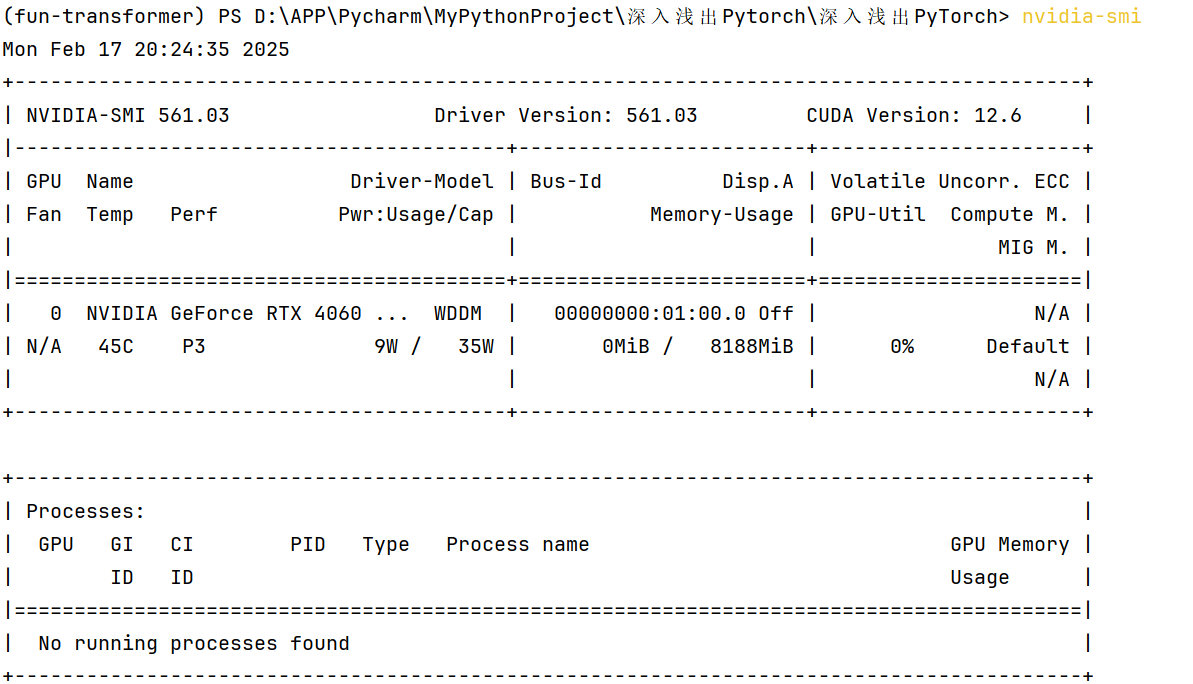
我们把两张图片中 GPU 状态列一个对比表:
| 属性 | 图一(训练中) | 图二(训练结束后) |
|---|---|---|
| GPU 名称 | NVIDIA GeForce RTX 4060 | NVIDIA GeForce RTX 4060 |
| 驱动版本 | 561.03 | 561.03 |
| CUDA 版本 | 12.6 | 12.6 |
| 温度 (°C) | 57°C | 45°C |
| 性能状态 (P) | P3 | P3 |
| 功耗 (W) | 30W / 42W | 9W / 35W |
| 显存使用 (MiB) | 6487MiB / 8188MiB | 0MiB / 8188MiB |
| GPU 利用率 (%) | 100% | 0% |
| 运行的进程 | 有进程运行(Python 脚本) | 无进程运行 |
| 显存占用 | N/A | N/A |
可以发现图一GPU 利用率 100%,显存占用较高(6487MiB),说明模型训练正在积极使用 GPU。图二GPU 利用率 0%,显存占用为 0MiB,说明 GPU 资源已被释放。(另外,这边是满显的,下面我们还会介绍一种省显存的方案,具体是“半精度训练”)
下面我们正式进入point的比较😊:
Point 5:自定义损失函数
如果我们不想使用交叉熵函数,而是想针对分割模型常用的Dice系数设计专门的loss,即DiceLoss($$ DSC = \frac{2|X∩Y|}{|X|+|Y|} $$),这时就需要我们自定义PyTorch的损失函数
class DiceLoss(nn.Module):#继承的是一个类似神经网络的结构
def __init__(self, weight=None, size_average=True):
super(DiceLoss, self).__init__()
def forward(self,inputs,targets,smooth=1):
inputs = torch.sigmoid(inputs) #这边是先把输入的logits激活一下
inputs = inputs.view(-1)#然后用view进行向量拉平
targets = targets.view(-1)
intersection = (inputs * targets).sum() #这边的意思是,如果inputs和targets都为1的话,intersection算有效
dice = (2.*intersection + smooth)/(inputs.sum() + targets.sum() + smooth) #这边取决于dice的公式
return 1 - dice
读者可能想问,我们的Loss函数定义得这么像一个模型,那么我们有没有办法把它定义为function?答:可以用def,但是这样不如继承nn.Module使用里面的forward函数好,没有保证结构的统一。另外在自定义损失函数时,涉及到数学运算时,全程使用PyTorch提供的张量计算接口不需要我们实现自动求导功能并且我们可以直接调用cuda😊
下面我们来测试下我们的损失函数:
newcriterion = DiceLoss()
unet.eval()
image, mask = next(iter(val_loader))#迭代Dataloader
out_unet = unet(image.cuda())#网络输出计算
loss = newcriterion(out_unet, mask.cuda())#实际输出和Groundtruth
print(loss)
输出如下:

好嘞!那么我们现在写好了这个模块,为什么不把这个Loss函数的修改直接放到整个网络中呢?因为没有那么简单,我们evaluation部分也要改(怎么计算 dice_coeff 的部分)😊。好嘞,那这个就定为未来的任务!
unet.eval()
unet.eval()是 PyTorch 中用于将模型切换到评估模式的方法。具体来说,当模型处于评估模式时,某些特定的层(如 Dropout 和 Batch Normalization)会改变其行为,以确保在评估或测试阶段得到一致的结果。详细解释
- Dropout 层:
- 在训练模式(
unet.train())下,Dropout 层会随机将一部分神经元的输出设置为 0,以防止过拟合。- 在评估模式(
unet.eval())下,Dropout 层不会随机关闭神经元,而是使用所有神经元进行前向传播,以确保评估结果的准确性。- Batch Normalization 层:
- 在训练模式下,Batch Normalization 层会对每个小批量数据计算均值和方差,并用这些值对数据进行归一化。
- 在评估模式下,Batch Normalization 层会使用训练阶段计算的全局均值和方差,而不是对每个小批量数据重新计算,以确保评估结果的一致性。
其他损失函数,如BCE-Dice Loss,Jaccard/Intersection over Union (IoU) Loss,Focal Loss......见Github
Point 6:动态调整学习率
随着优化的进行,固定的学习率可能无法满足优化的需求(比如下山不能只是一个速度),这时需要调整学习率,降低优化的速度~
这里,我们演示使用PyTorch自带的StepLR scheduler(step learning rate)动态调整学习率的效果,文字版教程中给出了自定义scheduler的方式(还有许多调整学习率的方式,除了lr_scheduler,但是更多需要去官网查看)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.8)
StepLR:每隔多少步,降低多少倍的学习率(每隔一步,学习率降为原来的0.8),一般为了方便设为5/10,1的话较小;step_size与gama需要配合使用,如果每隔很久一步需要大量降低学习率,就把step_size调高,把gama数值调小;如果希望下降更加平滑,需要把step_size调小一点,然后把gama数值调大。
其他可以调用的损失函数API和调用方式见Github 😊
epochs = 100
for epoch in range(1, epochs+1):
train(epoch)
val(epoch)
scheduler.step()
输出如下:
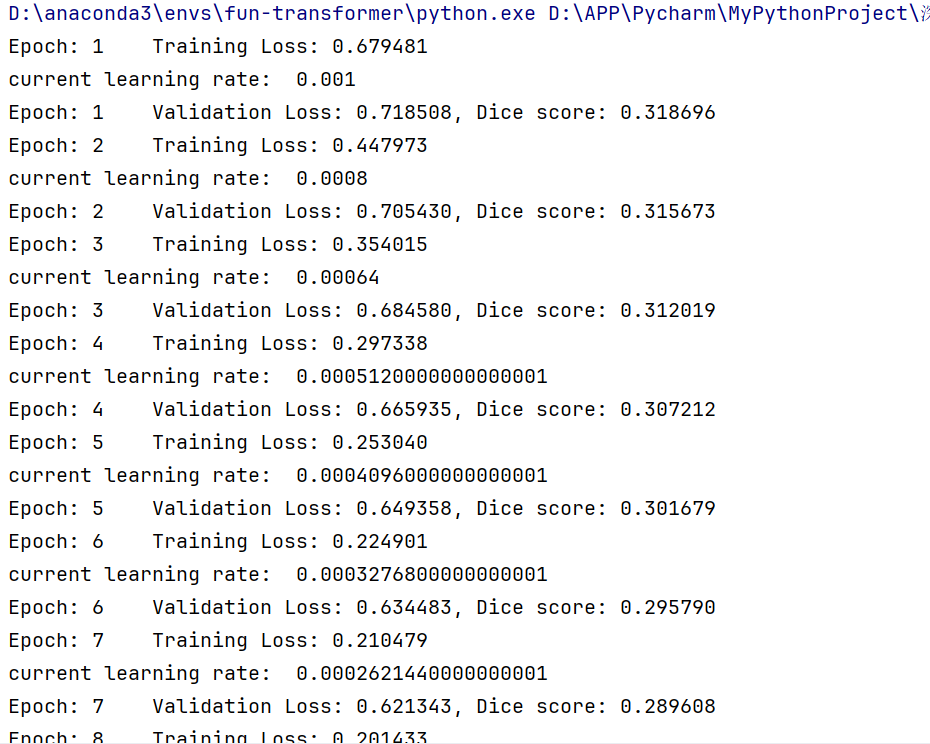
(可以看到epoch2的学习率是epoch1的0.8倍)
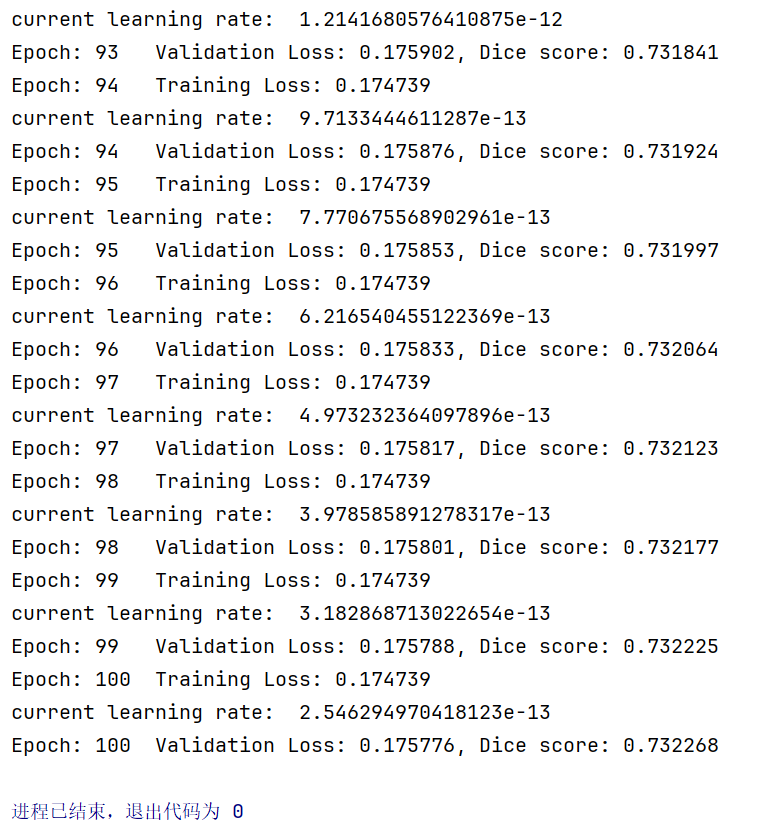
(这边会发现调整学习率带来的Loss降低结果没有原来好)
#?optim.lr_scheduler.StepLR
help(optim.lr_scheduler.StepLR)#查看这个函数的使用方式
输出:
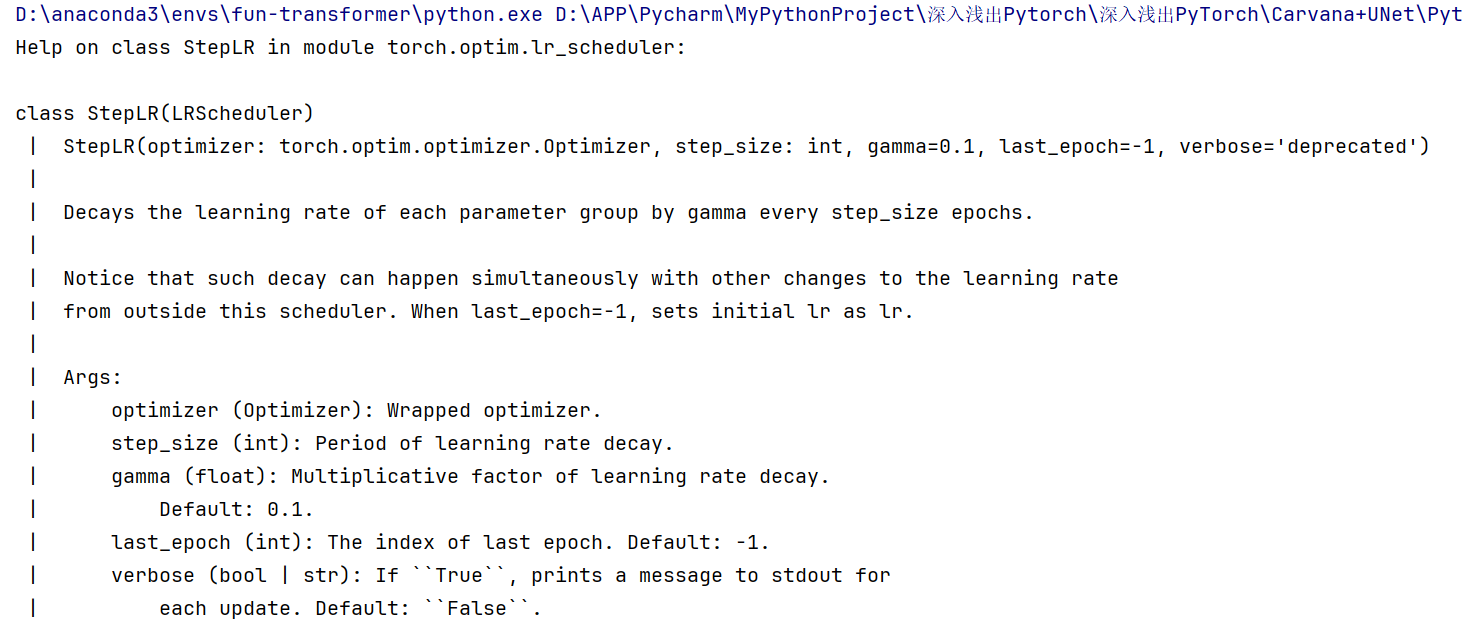
这边last_epoch的意思是到哪个epoch学习率就不动了
当然,我们还能自定义损失函数嘿嘿-👉Github
Point 7:模型微调
在前面,我想简要介绍一些关于模型微调的知识:
模型微调的本质是固定一些层,让它不要进行梯度/参数的更新,常用于卷积层与全连接层多的网络(虽说unet并非如此)⭐。
微调的意义是防止复杂的预训练模型在我们较小的数据集上过拟合,同时利用预训练模型迁移学习的本领,辅助属于相近邻域的我们的数据集所需模型的构建😊。
下面,我们先回忆下unet网络结构:
print(unet)
输出如下:
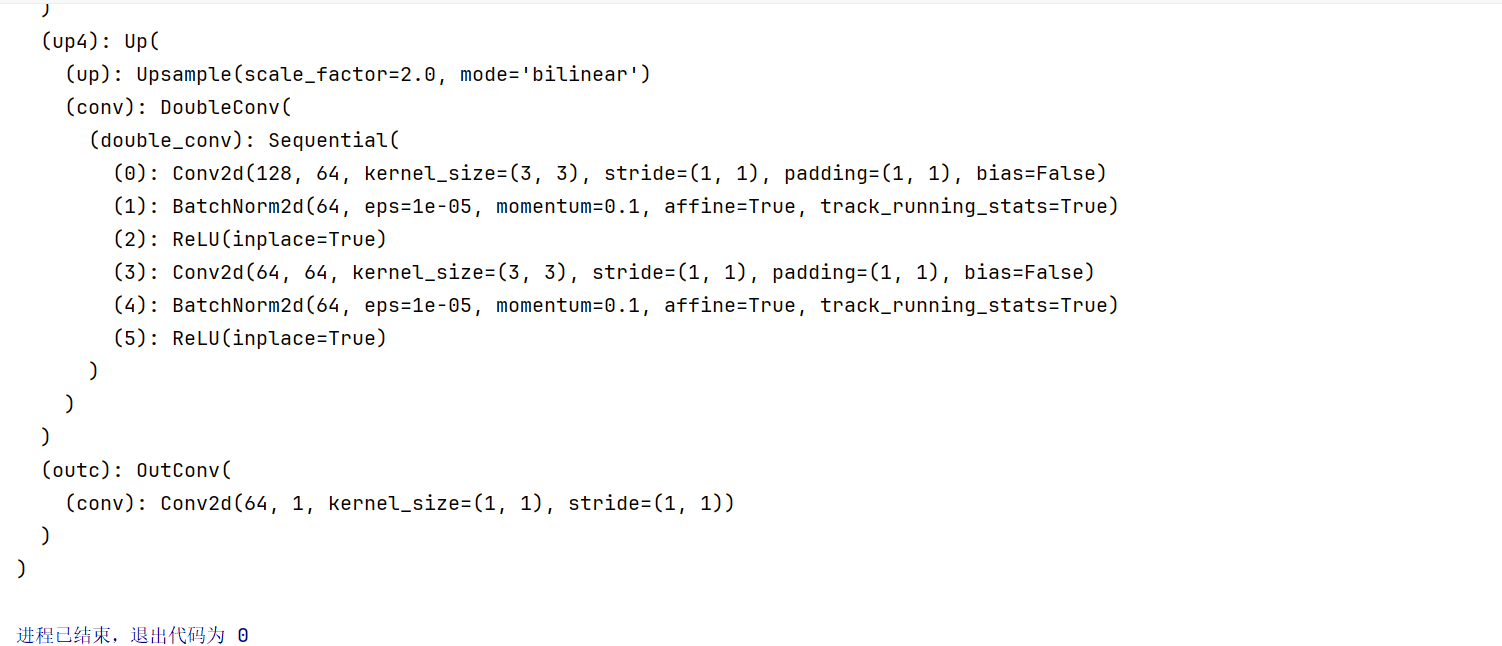
假如说我们现在输出卷积模块已经训练得足够好,我们想固定住(训练时不想调整里面的参数),怎么办?
我们先把输出卷积层单拎出来:
print(unet.outc)#多卡则为unet.module.outc
输出:

那么我们能否把里面的卷积单挑出来?
print(unet.outc.conv)#多卡则为unet.module.outc.conv
输出:

现在我们具体到了里面的特定层,就可以看它的权重:
print(unet.outc.conv.weight)
输出:

输出中可以看到我们的权重张量与使用GPU和是否进行权重更新。由图片中的requires_grad=True,可以看到是默认进行权重更新的,那么,如果我们不更新,就需要把requires_grad设为Fause。
unet.outc.conv.weight.requires_grad = False
#unet.outc.conv.bias.requires_grad = False#后面加上
#我们设置好后,用下面的命令查看哪些层需要梯度更新:
for layer, param in unet.named_parameters():
print(layer, '\t', param.requires_grad)
截取部分输出如下:
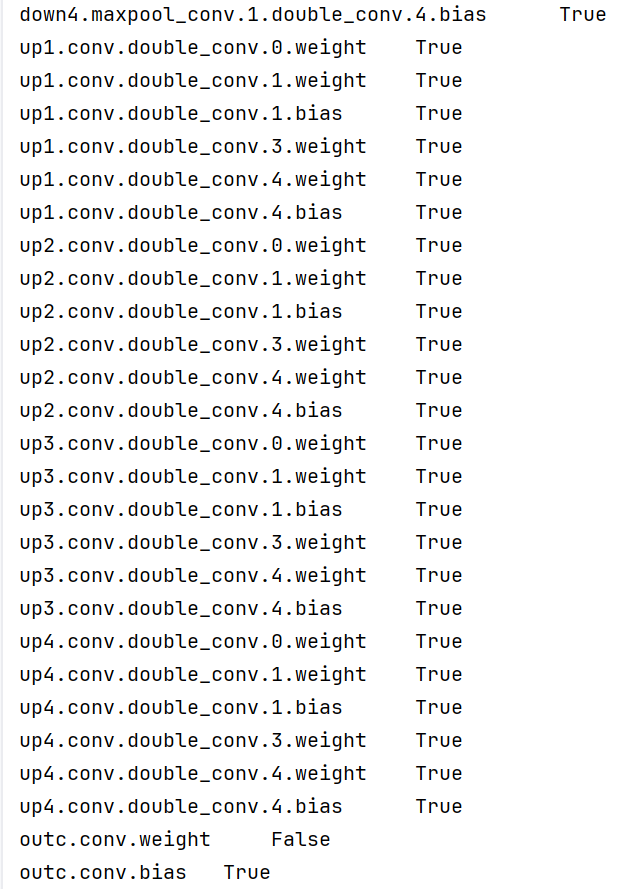
这里发现我们漏掉了最后一行的偏置量!这样我们要补加一行见被注释的那行,终于实现了输出卷积层完全不更新!
所以,不想让哪部分进行梯度更新,就把这部分的梯度更新选项设为fause就OK啦!
PS:我们这种状况常见于从官网下载了模型权重,想要进行微调,那你就设置一些层requires_grad = False,再检验下,就OK啦!
除了torchvision.models其他的预训练模型库:timm,其中的模型在准确度上也较高😊,具体见Github
但是,前面我们只讲了参数的冻结,那么我们怎么在冻结参数的情况下训练呢?
这里我们以torchvision中的常见模型为例,进行完整步骤的讲解(详细版见Github):
使用已有模型结构
首先,我们需要导入相关包import torchvision.models as models,然后实例化网络,
resnet18 = models.resnet18()
# resnet18 = models.resnet18(pretrained=False) 等价于与上面的表达式
然后传递pretrained参数:
resnet18 = models.resnet18(pretrained=True)
PS:通常PyTorch模型的扩展为.pt或.pth,程序运行时会首先检查默认路径中是否有已经下载的模型权重,一旦权重被下载,下次加载就不需要下载了。另外,因为一般情况下预训练模型的下载会比较慢,所以可以查看自己模型的model_urls,然后手动下载,预训练模型的权重在Linux和Mac的默认下载路径是用户根目录下的.cache文件夹。
如果觉得麻烦,还可以将自己的权重下载下来放到同文件夹下,然后再将参数加载网络。
self.model = models.resnet50(pretrained=False)
self.model.load_state_dict(torch.load('./model/resnet50-19c8e357.pth'))
如果中途强行停止下载的话,一定要去对应路径下将权重文件删除干净,要不然可能会报错。
训练特定层
前面我们设置了requires_grad = False现在教大家另一种方法:
Pytorch官方文档中有这样一个函数:
def set_parameter_requires_grad(model, feature_extracting):
if feature_extracting:
for param in model.parameters():
param.requires_grad = False
所以我们如果设feature_extracting=True不就冻住了嘛😊,那我们就可以试试仍旧使用resnet18为例的将1000类改为4类,但是仅改变最后一层的模型参数,不改变特征提取的模型参数👉
注意我们先冻结模型参数的梯度,再对模型输出部分的全连接层进行修改,这样修改后的全连接层的参数就是可计算梯度的
import torchvision.models as models
# 冻结参数的梯度
feature_extract = True
model = models.resnet18(pretrained=True)
set_parameter_requires_grad(model, feature_extract)
# 修改模型
num_ftrs = model.fc.in_features
model.fc = nn.Linear(in_features=num_ftrs, out_features=4, bias=True)
之后在训练过程中,model仍会进行梯度回传,但是参数更新则只会发生在fc层。
Point 8:半精度训练
这里就是来缩小显存占用哒!
而GPU的性能主要分为两部分:算力和显存,前者决定了显卡计算的速度,后者则决定了显卡可以同时放入多少数据用于计算。在可以使用的显存数量一定的情况下,每次训练能够加载的数据更多(也就是batch size更大),则也可以提高训练效率。
半精度训练对应全精度训练,当我们不去实际干预参数的变量类型时,它默认的类型是32位浮点数.比如说我们看下刚刚实例化后的图像:
print(image.dtype)
输出:
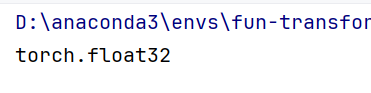
那么我们默认的半精度训练,就是用16位浮点数进行数据的表示(torch.float16)
为了进行半精度训练,只需要进行3个部分的更改(注意:用jupyter notebook演示时需要restart kernel,并且前面必须有Unet模块):
1.导入相关包
from torch.cuda.amp import autocast#⭐
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
2.模型定义时在forward前,需要加入autocast
class CarvanaDataset(Dataset):
def __init__(self, base_dir, idx_list, mode="train", transform=None):
self.base_dir = base_dir
self.idx_list = idx_list
self.images = os.listdir(base_dir+"train")
self.masks = os.listdir(base_dir+"train_masks")
self.mode = mode
self.transform = transform
def __len__(self):
return len(self.idx_list)
def __getitem__(self, index):
image_file = self.images[self.idx_list[index]]
mask_file = image_file[:-4]+"_mask.gif"
image = PIL.Image.open(os.path.join(base_dir, "train", image_file))
if self.mode=="train":
mask = PIL.Image.open(os.path.join(base_dir, "train_masks", mask_file))
if self.transform is not None:
image = self.transform(image)
mask = self.transform(mask)
mask[mask!=0] = 1.0
return image, mask.float()
else:
if self.transform is not None:
image = self.transform(image)
return image
base_dir = "./"
transform = transforms.Compose([transforms.Resize((256,256)), transforms.ToTensor()])
train_idxs, val_idxs = train_test_split(range(len(os.listdir(base_dir+"train_masks"))), test_size=0.3)
train_data = CarvanaDataset(base_dir, train_idxs, transform=transform)
val_data = CarvanaDataset(base_dir, val_idxs, transform=transform)
train_loader = DataLoader(train_data, batch_size=32, num_workers=0, shuffle=True)
val_loader = DataLoader(val_data, batch_size=32, num_workers=0, shuffle=False)#Bug val_data
重新定义模型:
class UNet_half(nn.Module):
def __init__(self, n_channels, n_classes, bilinear=True):
super(UNet_half, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
factor = 2 if bilinear else 1
self.down4 = Down(512, 1024 // factor)
self.up1 = Up(1024, 512 // factor, bilinear)
self.up2 = Up(512, 256 // factor, bilinear)
self.up3 = Up(256, 128 // factor, bilinear)
self.up4 = Up(128, 64, bilinear)
self.outc = OutConv(64, n_classes)
#@autocast() # ⭐
@torch.amp.autocast('cuda') # ⭐
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc(x)
return logits
unet_half = UNet_half(3,1)
#unet_half = nn.DataParallel(unet_half).cuda()
unet_half = unet_half.cuda()
优化器和损失函数:
criterion = nn.BCEWithLogitsLoss()
optimizer = optim.Adam(unet_half.parameters(), lr=1e-3, weight_decay=1e-8)
3.训练和验证都需要加入with autocast():
def dice_coeff(pred, target):
eps = 0.0001
num = pred.size(0)
m1 = pred.view(num, -1) # Flatten
m2 = target.view(num, -1) # Flatten
intersection = (m1 * m2).sum()
return (2. * intersection + eps) / (m1.sum() + m2.sum() + eps)
def train_half(epoch):
unet_half.train()
train_loss = 0
for data, mask in train_loader:
data, mask = data.cuda(), mask.cuda()
#with autocast():#⭐
with torch.amp.autocast('cuda'): # ⭐
optimizer.zero_grad()
output = unet_half(data)
loss = criterion(output,mask)
loss.backward()
optimizer.step()
train_loss += loss.item()*data.size(0)
train_loss = train_loss/len(train_loader.dataset)
print('Epoch: {} \tTraining Loss: {:.6f}'.format(epoch, train_loss))
def val_half(epoch):
print("current learning rate: ", optimizer.state_dict()["param_groups"][0]["lr"])
unet_half.eval()
val_loss = 0
dice_score = 0
with torch.no_grad():
for data, mask in val_loader:
data, mask = data.cuda(), mask.cuda()
#with autocast():#⭐
with torch.amp.autocast('cuda'): # ⭐
output = unet_half(data)
loss = criterion(output, mask)
val_loss += loss.item()*data.size(0)
dice_score += dice_coeff(torch.sigmoid(output).cpu(), mask.cpu())*data.size(0)
val_loss = val_loss/len(val_loader.dataset)
dice_score = dice_score/len(val_loader.dataset)
print('Epoch: {} \tValidation Loss: {:.6f}, Dice score: {:.6f}'.format(epoch, val_loss, dice_score))
改完啦!我们开始训练!
epochs = 100
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.8)
for epoch in range(1, epochs+1):
train_half(epoch)
val_half(epoch)
scheduler.step()
加入代码,输出如下:
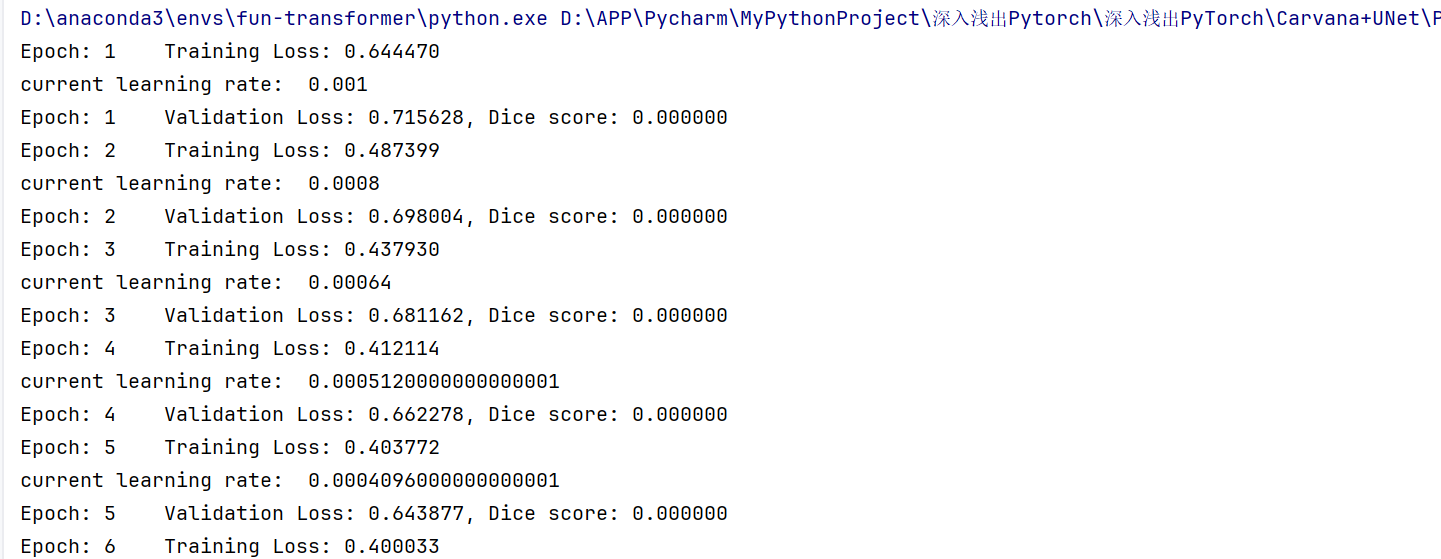
(但是Dice score一直为0,我认为可能是精度低了一半导致的,因为我对比了其他各处,排除了其他问题,所以我不完全支持这种做法)
在训练中,我们也有查看显存占用情况:
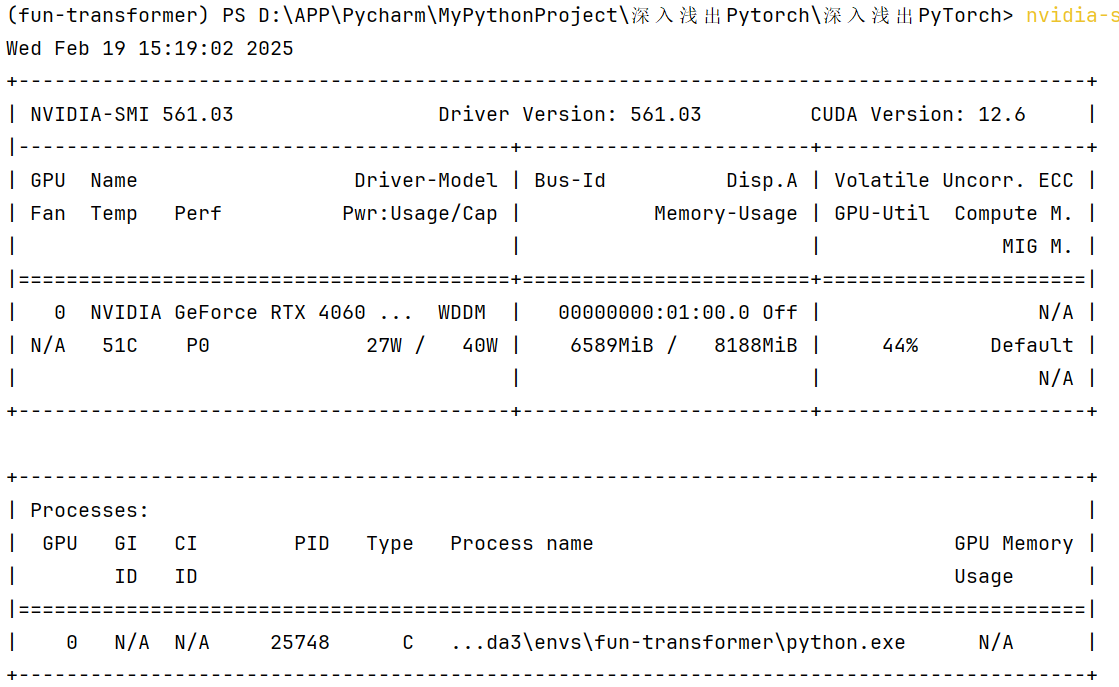
可见只有44%!效果很理想(尤其对大尺寸的图像数据集来说)!
好啦!正课就先上到这里😭超级依依不舍~
如果大家想用命令行简单调参/实现参数极简配置,可以参照[thorough-pytorch/source/第六章/6.6 使用argparse进行调参.md at main · datawhalechina/thorough-pytorch](https://github.com/datawhalechina/thorough-pytorch/blob/main/source/第六章/6.6 使用argparse进行调参.md) ,完整代码在[thorough-pytorch/notebook/第六章 PyTorch进阶训练技巧/使用argparse调参 at main · datawhalechina/thorough-pytorch](https://github.com/datawhalechina/thorough-pytorch/tree/main/notebook/第六章 PyTorch进阶训练技巧/使用argparse调参) ;
然后,关于会动的表,可以看[thorough-pytorch/notebook/第六章 PyTorch进阶训练技巧/利用Visdom可视化训练过程.ipynb at main · datawhalechina/thorough-pytorch](https://github.com/datawhalechina/thorough-pytorch/blob/main/notebook/第六章 PyTorch进阶训练技巧/利用Visdom可视化训练过程.ipynb) 超级轻量级!
最后,CV方向的UU可以学这里[thorough-pytorch/source/第六章/6.5 数据增强-imgaug.md at main · datawhalechina/thorough-pytorch](https://github.com/datawhalechina/thorough-pytorch/blob/main/source/第六章/6.5 数据增强-imgaug.md) ,可以对不同批次/大小的图像数据集进行增强!😊
超级舍不得Datawhale ,最后,再见啦!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号