


Datawhale组队学习🔊wow-agent😀task02 Llama-index库搭建AI Agent
Datawhale组队学习 wow-agent
Task2 Llama-index库搭建AI Agent
Datawhale项目链接:https://www.datawhale.cn/learn/summary/86
笔记作者:博客园-岁月月宝贝💫
微信名:有你在就不需要🔮给的勇气
➿用Llama-index创建Agent
| ❓LlamaIndex: 1.定义: 一个专门设计用于增强大型语言模型(LLMs)功能的数据框架,它可以帮助开发者将私有数据与 LLM 结合起来,从而构建各种自然语言处理应用程序。 2.核心功能: (1)数据连接器:LlamaIndex 提供了多种数据连接器,可以轻松地将现有的数据源和数据格式(如 API、PDF、文档、SQL 等)集成到系统中。 (2)索引构建:支持多种索引结构,包括列表索引、树形索引、图索引等,满足不同场景下的数据管理需求。 (3)检索与查询接口:提供了先进的检索和查询接口,可以将任何 LLM 输入提示符输入,获取检索到的上下文和知识增强的输出。 (4)与 LLM 的无缝集成:LlamaIndex 与多种 LLM 无缝集成,支持自定义 LLM,允许开发者使用本地模型或第三方模型。 |
首先定义工具函数,用来完成Agent的任务。
| 💡大模型会根据函数的注释来判断使用哪个函数来完成任务。所以,注释一定要写清楚函数的功能和返回值。 |
然后把工具函数放入FunctionTool对象中,供Agent能够使用。
用 LlamaIndex 实现一个简单的 agent demo 比较容易,LlamaIndex 实现 Agent 需要导入 ReActAgent 和 Function Tool。
| ❓ReActAgent 定义:ReActAgent 是一种基于 ReAct 机制开发的人工智能代理框架,旨在增强大型语言模型(LLMs)处理复杂任务的能力。ReAct 代表 Reasoning(推理)、Acting(行动)和 Thinking(思考),它通过结合推理和行动,使模型能够将复杂任务分解为一系列思考过程、行动和观察,从而提高任务解决的准确性和效率。 工作流程: (1)初始推理:代理首先进行推理步骤,以理解任务、收集相关信息并决定下一步行为。 (2)行动:代理基于其推理采取行动——例如查询API、检索数据或执行命令。 (3)观察:代理观察行动的结果并收集任何新的信息。 (4)优化推理:利用新信息,代理再次进行推理,更新其理解、计划或假设。 (5)重复:代理重复该循环,在推理和行动之间交替,直到达到满意的结论或完成任务。 |
下面是一个通过外部工具做算术题的简单例子。🤫这个如果不用 Agent,其实大模型也可以回答。
🕐首先,准备各种key和模型名称。
import os
from dotenv import load_dotenv
# 加载环境变量
load_dotenv()
# 从环境变量中读取api_key
api_key = os.getenv('ZISHU_API_KEY')
base_url = "http://43.200.7.56:8008/v1"
chat_model = "glm-4-flash"
emb_model = "embedding-3"
🕑然后,来构建llm,其实任何能用的llm都行。这里自定义一个llm~
from openai import OpenAI
from pydantic import Field # 导入Field,用于Pydantic模型中定义字段的元数据
from llama_index.core.llms import (
CustomLLM,
CompletionResponse,
LLMMetadata,
)
from llama_index.core.embeddings import BaseEmbedding
from llama_index.core.llms.callbacks import llm_completion_callback
from typing import List, Any, Generator
# 定义OurLLM类,继承自CustomLLM基类
class OurLLM(CustomLLM):
api_key: str = Field(default=api_key)
base_url: str = Field(default=base_url)
model_name: str = Field(default=chat_model)
client: OpenAI = Field(default=None, exclude=True) # 显式声明 client 字段
def __init__(self, api_key: str, base_url: str, model_name: str = chat_model, **data: Any):
super().__init__(**data)
self.api_key = api_key
self.base_url = base_url
self.model_name = model_name
self.client = OpenAI(api_key=self.api_key, base_url=self.base_url) # 使用传入的api_key和base_url初始化 client 实例
@property
def metadata(self) -> LLMMetadata:
"""Get LLM metadata."""
return LLMMetadata(
model_name=self.model_name,
)
@llm_completion_callback()
def complete(self, prompt: str, **kwargs: Any) -> CompletionResponse:
response = self.client.chat.completions.create(model=self.model_name, messages=[{"role": "user", "content": prompt}])
if hasattr(response, 'choices') and len(response.choices) > 0:
response_text = response.choices[0].message.content
return CompletionResponse(text=response_text)
else:
raise Exception(f"Unexpected response format: {response}")
@llm_completion_callback()
def stream_complete(
self, prompt: str, **kwargs: Any
) -> Generator[CompletionResponse, None, None]:
response = self.client.chat.completions.create(
model=self.model_name,
messages=[{"role": "user", "content": prompt}],
stream=True
)
try:
for chunk in response:
chunk_message = chunk.choices[0].delta
if not chunk_message.content:
continue
content = chunk_message.content
yield CompletionResponse(text=content, delta=content)
except Exception as e:
raise Exception(f"Unexpected response format: {e}")
llm = OurLLM(api_key=api_key, base_url=base_url, model_name=chat_model)
🕒测试llm的可用性
response = llm.stream_complete("你是谁?")
for chunk in response:
print(chunk, end="", flush=True)
🤖:我是一个人工智能助手,名叫 ChatGLM,是基于清华大学 KEG 实验室和智谱 AI 公司于 2024 年共同训练的语言模型开发的。我的任务是针对用户的问题和要求提供适当的答复和支持。
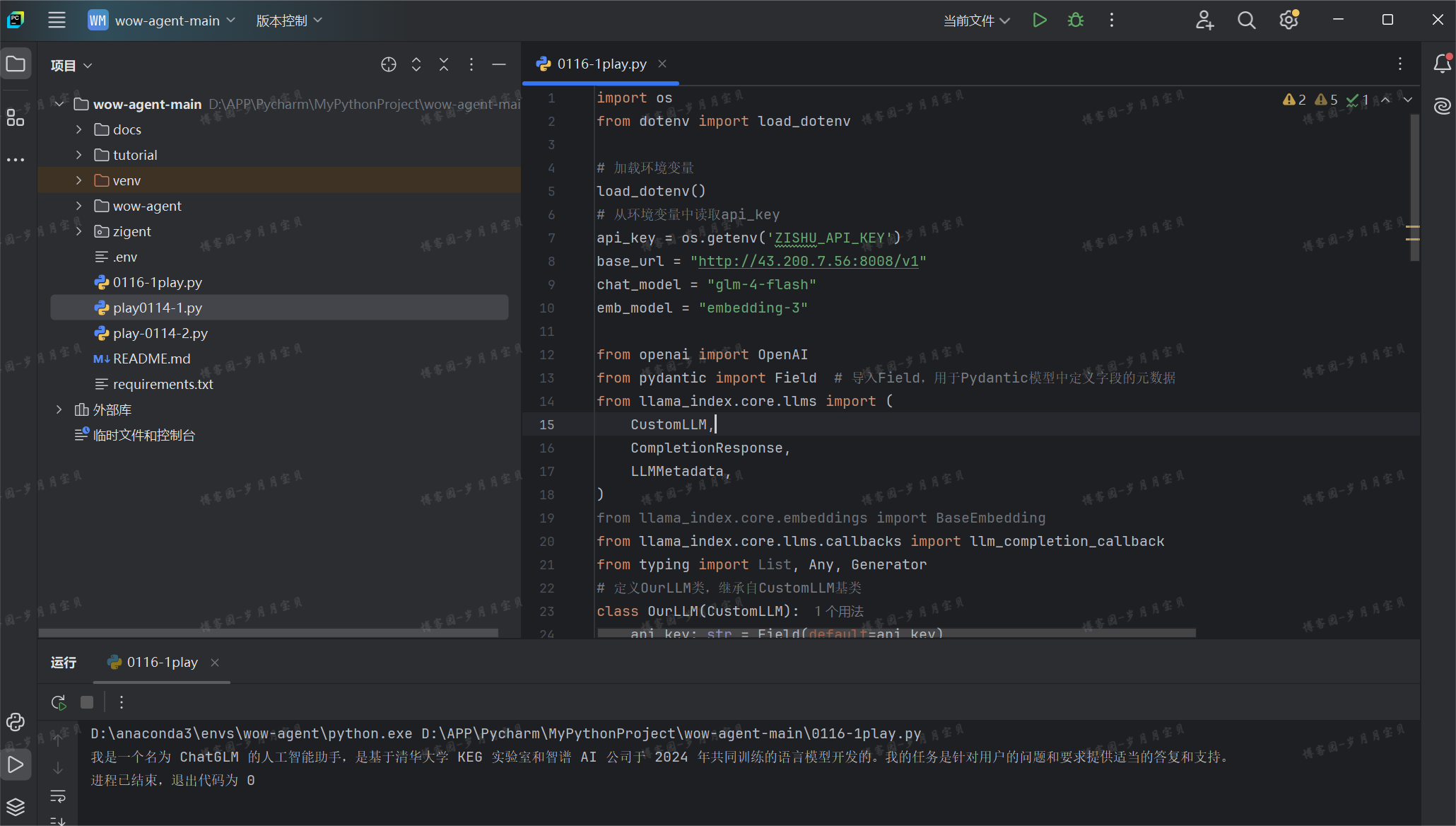
注意需要确保环境中有llama-index库 !
(可以用!太棒啦!!!)
🕓下面,我们自己造tool放入LLM的工具箱中~
import sys
import os
sys.path.append(os.path.abspath(os.path.join(os.path.dirname(__file__), "..", "..")))
from llama_index.core.agent import ReActAgent
from llama_index.core.tools import FunctionTool
def multiply(a: float, b: float) -> float:
"""Multiply two numbers and returns the product"""
return a * b
def add(a: float, b: float) -> float:
"""Add two numbers and returns the sum"""
return a + b
def main():
multiply_tool = FunctionTool.from_defaults(fn=multiply)
add_tool = FunctionTool.from_defaults(fn=add)
# 创建ReActAgent实例
agent = ReActAgent.from_tools([multiply_tool, add_tool], llm=llm, verbose=True)
response = agent.chat("20+(2*4)等于多少?使用工具计算每一步")
print(response)
if __name__ == "__main__":
main()
🤖:bbbbbb
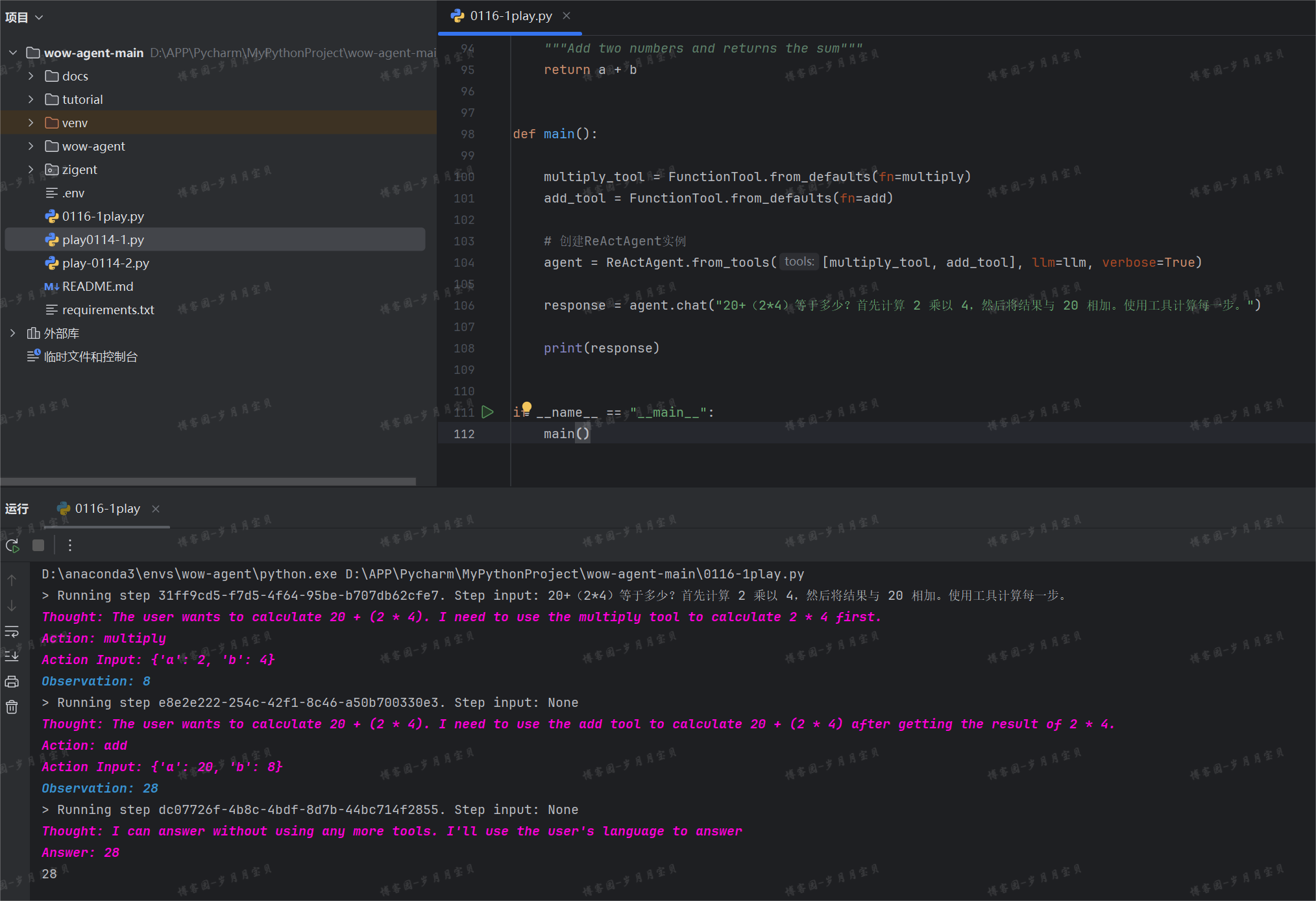
注意此时最好修改下提示词(比如上图和我一样就OK),因为很有可能LLM会一直调用乘法不调用加法
(它将提问中的计算步骤分别利用了我们自定义的函数 add 和 multiply ,而不是走大模型!!!我们竟然能自定义 agent 中的某些处理流程!!!我们不是那个只能用prompt的小可怜啦!!!)
🕔为模型再加一个自制查天气的tool
def get_weather(city: str) -> int:
"""
Gets the weather temperature of a specified city.
Args:
city (str): The name or abbreviation of the city.
Returns:
int: The temperature of the city. Returns 20 for 'NY' (New York),
30 for 'BJ' (Beijing), and -1 for unknown cities.
"""
# Convert the input city to uppercase to handle case-insensitive comparisons
city = city.upper()
# Check if the city is New York ('NY')
if city == "NY":
return 20 # Return 20°C for New York
# Check if the city is Beijing ('BJ')
elif city == "BJ":
return 30 # Return 30°C for Beijing
# If the city is neither 'NY' nor 'BJ', return -1 to indicate unknown city
else:
return -1
weather_tool = FunctionTool.from_defaults(fn=get_weather)
agent = ReActAgent.from_tools([multiply_tool, add_tool, weather_tool], llm=llm, verbose=True)
response = agent.chat("纽约天气怎么样?")
🤖:bbbbbbb
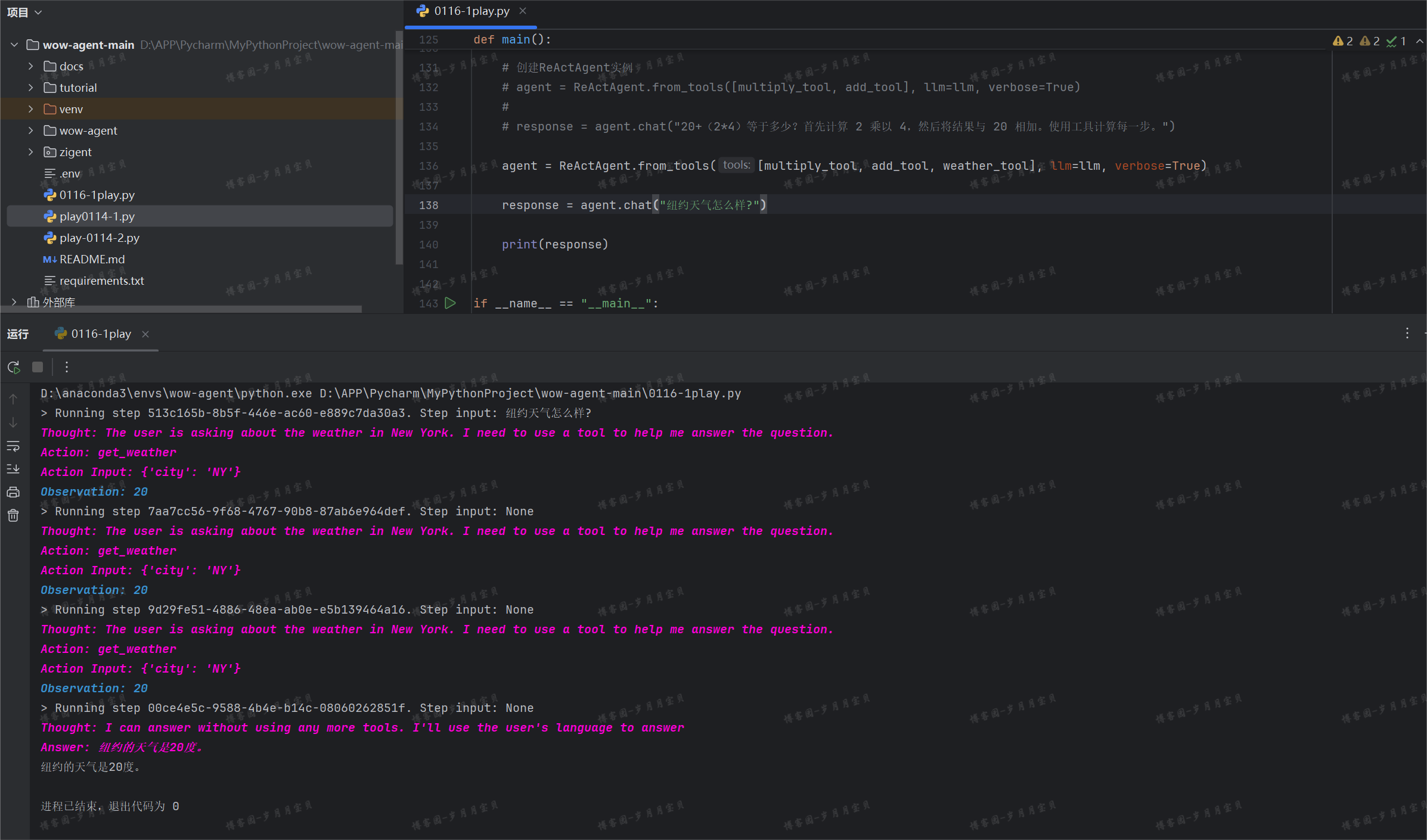
(可以看到模型的推理能力很强,将纽约转成了 NY🍼~)
可以在 arize_phoenix 中看到 agent 的具体提示词,工具被如假包换成了提示词~
| 🍭Arize Phoenix 定义 一个开源的 AI 可观察性平台,专为实验、评估和故障排除而设计。 核心功能 (1)跟踪(Tracing):使用基于 OpenTelemetry 的工具跟踪 LLM 应用程序的运行时。 (2)评估(Evaluation):利用 LLM 对应用程序的性能进行基准测试,使用响应和检索评估。 (3)数据集(Datasets):创建版本化的示例数据集,用于实验、评估和微调。 (4)实验(Experiments):跟踪和评估提示、LLM 和检索的变化。 (5)推理分析(Inferences):使用降维和聚类可视化推理和嵌入,以识别漂移和性能下降。 |
升华:
ReActAgent 是一种基于 ReAct 机制的人工智能代理,它能够将复杂的业务需求自动转换为代码逻辑。这意味着,只要有一个定义好的 API 模型,ReActAgent 就可以调用这个 API 来完成特定的业务功能。这种能力使得很多业务场景(LlamaIndex 提供了一些开源的工具实现,可以到官网查看💘)都可以通过自动化的方式实现,大大提高了开发效率和系统的灵活性。
当然,业务场景一多,一个agent就远远不够啦!和“软件解耦”一样,为了让所有的功能都被完成好,可以加入不同的 agent ,各自完成不同的任务,例如:
- 数据收集 Agent:负责从外部数据源收集数据。
- 数据处理 Agent:负责对收集到的数据进行清洗和预处理。
- 分析 Agent:负责对处理后的数据进行分析和生成报告。
这些 Agent 之间可以通过定义好的接口进行交互和通信。这种交互方式类似于微服务架构中的服务间通信。例如,数据收集 Agent 可以将收集到的数据发送给数据处理 Agent,数据处理 Agent 处理完成后,再将结果发送给分析 Agent。这种设计使得整个系统更加灵活和可扩展。
🤓数据库对话Agent
🥣不知道结果怎么样,先——开——做!
🕐首先,我们创建一个数据库:
import sqlite3
# 创建数据库
sqllite_path = 'llmdb.db'
con = sqlite3.connect(sqllite_path)
# 创建表
sql = """
CREATE TABLE `section_stats` (
`部门` varchar(100) DEFAULT NULL,
`人数` int(11) DEFAULT NULL
);
"""
c = con.cursor()
cursor = c.execute(sql)
c.close()
con.close()
🕑然后,给数据库填充一些数据:
con = sqlite3.connect(sqllite_path)
c = con.cursor()
data = [
["专利部",22],
["商标部",25],
]
for item in data:
sql = """
INSERT INTO section_stats (部门,人数)
values('%s','%d')
"""%(item[0],item[1])
c.execute(sql)
con.commit()
c.close()
con.close()
🐛注意上面的代码运行一次就OK~以防系统提示多次建表!
🕒配置对话模型和嵌入模型:
这里采用了本地Ollama的对话模型和嵌入模型。
模型的构建可以参考wow-rag课程的第二课(https://github.com/datawhalechina/wow-rag/tree/main/tutorials),里面介绍了非常多配置对话模型和嵌入模型的方式。llm也可以直接用上一课用OurLLM创建的llm。
各种配置方式都可以,只要能有个能用的llm和embedding就行。
| 🗣对话模型 定义 对话模型(如 GPT、ChatGPT 等)主要用于生成自然语言文本,以模拟人类对话。这些模型通常基于大型语言模型(LLMs),通过大量的文本数据进行训练,能够理解和生成自然语言。 核心功能 (1)文本生成:根据输入的提示(prompt)生成连贯、自然的文本。 (2)对话管理:维护对话状态,理解上下文,生成合适的回复。 (3)多轮对话:能够处理多轮对话,保持对话的连贯性和一致性。 |
# 配置对话模型
from llama_index.llms.ollama import Ollama
llm = Ollama(base_url="http://192.168.0.123:11434", model="qwen2:7b")
🐛注意,最新版llama_index不支持Ollama!你可能需要调整llama_index库的版本!但是这个很耗时间,因为包与包的依赖关系非常复杂,所以为了拯救大家的时间,建议换成:
import os
from dotenv import load_dotenv
# 加载环境变量
load_dotenv()
# 从环境变量中读取api_key
api_key = os.getenv('ZISHU_API_KEY')
# base_url = "http://43.200.7.56:8008/v1"
base_url = "http://43.200.7.56:8008/v1"
chat_model = "glm-4-flash"
#emb_model = "embedding-3"#两个emb_model都不OK!
#emb_model = "text-embedding-ada-002"
from openai import OpenAI
from pydantic import Field # 导入Field,用于Pydantic模型中定义字段的元数据
from llama_index.core.llms import (
CustomLLM,
CompletionResponse,
LLMMetadata,
)
from llama_index.core.embeddings import BaseEmbedding
from llama_index.core.llms.callbacks import llm_completion_callback
from typing import List, Any, Generator
# 定义OurLLM类,继承自CustomLLM基类
class OurLLM(CustomLLM):
api_key: str = Field(default=api_key)
base_url: str = Field(default=base_url)
model_name: str = Field(default=chat_model)
client: OpenAI = Field(default=None, exclude=True) # 显式声明 client 字段
def __init__(self, api_key: str, base_url: str, model_name: str = chat_model, **data: Any):
super().__init__(**data)
self.api_key = api_key
self.base_url = base_url
self.model_name = model_name
self.client = OpenAI(api_key=self.api_key, base_url=self.base_url) # 使用传入的api_key和base_url初始化 client 实例
@property
def metadata(self) -> LLMMetadata:
"""Get LLM metadata."""
return LLMMetadata(
model_name=self.model_name,
)
@llm_completion_callback()
def complete(self, prompt: str, **kwargs: Any) -> CompletionResponse:
response = self.client.chat.completions.create(model=self.model_name, messages=[{"role": "user", "content": prompt}])
if hasattr(response, 'choices') and len(response.choices) > 0:
response_text = response.choices[0].message.content
return CompletionResponse(text=response_text)
else:
raise Exception(f"Unexpected response format: {response}")
@llm_completion_callback()
def stream_complete(
self, prompt: str, **kwargs: Any
) -> Generator[CompletionResponse, None, None]:
response = self.client.chat.completions.create(
model=self.model_name,
messages=[{"role": "user", "content": prompt}],
stream=True
)
try:
for chunk in response:
chunk_message = chunk.choices[0].delta
if not chunk_message.content:
continue
content = chunk_message.content
yield CompletionResponse(text=content, delta=content)
except Exception as e:
raise Exception(f"Unexpected response format: {e}")
llm = OurLLM(api_key=api_key, base_url=base_url, model_name=chat_model)
⭐但是注意同一目录下需要有“.env”文件!!!
| 🎨嵌入模型 定义 嵌入模型(如 Word2Vec、GloVe、BERT 等)用于将文本转换为数值向量(嵌入向量),这些向量能够捕捉文本的语义信息。 核心功能 (1)语义表示:将单词、句子或文档转换为高维向量,这些向量能够捕捉文本的语义相似性。 (2)特征提取:为其他 NLP 任务(如分类、聚类、相似性搜索等)提供特征。 (3)上下文感知:一些嵌入模型(如 BERT)能够捕捉上下文信息,生成上下文相关的嵌入向量。 |
# 配置Embedding模型
from llama_index.embeddings.ollama import OllamaEmbedding
embedding = OllamaEmbedding(base_url="http://192.168.0.123:11434", model_name="qwen2:7b")
🐛点击OllamaEmbedding可以进去修改把“embedding-3”一个个加进去,但是我不保证你可以修改成功哦!(大致是需要和我在群里一样把和前三个嵌入模型并列的地方把第四个都加进去!)
所以,我建议大家和我一起使用https://jina.ai/,使用其中免费且额度较高的api_key!
如下:
from llama_index.embeddings.jinaai import JinaEmbedding
# embedding = OpenAIEmbedding(#因为我运行不成功,所以被我注释掉了!
# api_key=api_key,
# model=emb_model,#'embedding-3' is not a valid OpenAIEmbeddingModelType
# api_base=base_url #ValueError: 'glm-4-flash' is not a valid OpenAIEmbeddingModelType
# )
#推荐网址,https://jina.ai/,真的OK!(TZ need!!!)
# 装包 pip install llama-index-embeddings-jinaai
# 领一个免费额度的api key:https://jina.ai/embeddings/
# 导包:from llama_index.embeddings.jinaai import JinaEmbedding
# 变量声明:embedding = JinaEmbedding(api_key=os.getenv('JINAAI_API_KEY'))
# 这里的embedding可以替换教程里面的OllamaEmbedding那些 ..
#embedding = JinaEmbedding(api_key=os.getenv('API_key'))#方法1,需要改env文件
#方法二:
embedding = JinaEmbedding(api_key='你的api_key串')
#笑哭,没想到是这里出的问题
| 👫对话模型与嵌入模型的关系 1.特征提取: 【输入嵌入】:对话模型在处理输入文本时,通常会使用嵌入模型将文本转换为嵌入向量。这些嵌入向量作为对话模型的输入特征,帮助模型更好地理解和生成文本。 【输出嵌入】:对话模型生成的文本也可以通过嵌入模型转换为嵌入向量,用于后续的处理和分析。 2.语义理解 【上下文感知】:嵌入模型能够捕捉文本的上下文信息,帮助对话模型更好地理解输入文本的语义。例如,BERT 嵌入可以提供上下文相关的词嵌入,使对话模型能够生成更准确的回复。 【相似性搜索】:嵌入模型生成的向量可以用于相似性搜索,帮助对话模型找到与输入文本最相似的回复。例如,可以使用嵌入向量在知识库中搜索最相关的答案。 3.性能提升 【预训练嵌入】:使用预训练的嵌入模型可以显著提升对话模型的性能。预训练的嵌入模型已经在大量文本数据上进行了训练,能够捕捉丰富的语义信息,对话模型可以直接利用这些信息。 【微调】:对话模型可以在预训练的嵌入模型基础上进行微调,进一步提升模型在特定任务上的表现。例如,可以在对话数据集上微调 BERT 嵌入,使其更适合对话任务。 |
# 测试对话模型
response = llm.complete("你是谁?")
print(response)
🤖: 我是一个人工智能助手,专门设计来帮助用户解答问题、提供信息以及执行各种任务。我的目标是成为您生活中的助手,帮助您更高效地获取所需信息。有什么我可以帮您的吗?

(成功!!!)
# 测试嵌入模型
emb = embedding.get_text_embedding("你好呀呀")
len(emb), type(emb)
🤖: (1024, list)

(配置成功!!!)
🕓导入Llama-index相关的库,并配置对话模型和嵌入模型。
这里的llm和embedding只要是llama-index支持的就行,有多种构建方法。详细可参见wow-rag课程的第二课。
from llama_index.core.agent import ReActAgent
from llama_index.core.tools import FunctionTool
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex, Settings
from llama_index.core.tools import QueryEngineTool
from llama_index.core import SQLDatabase
from llama_index.core.query_engine import NLSQLTableQueryEngine
from sqlalchemy import create_engine, select
# 配置默认大模型
Settings.llm = llm
Settings.embed_model = embedding
🕔其他步骤:
## 创建数据库查询引擎
engine = create_engine("sqlite:///llmdb.db")
# prepare data
sql_database = SQLDatabase(engine, include_tables=["section_stats"])
query_engine = NLSQLTableQueryEngine(
sql_database=sql_database,
tables=["section_stats"],
llm=Settings.llm
)
# 创建工具函数
def multiply(a: float, b: float) -> float:
"""将两个数字相乘并返回乘积。"""
return a * b
multiply_tool = FunctionTool.from_defaults(fn=multiply)
def add(a: float, b: float) -> float:
"""将两个数字相加并返回它们的和。"""
return a + b
add_tool = FunctionTool.from_defaults(fn=add)
# 把数据库查询引擎封装到工具函数对象中
staff_tool = QueryEngineTool.from_defaults(
query_engine,
name="section_staff",
description="查询部门的人数。"
)
# 构建ReActAgent,可以加很多函数,在这里只加了加法函数和部门人数查询函数。
agent = ReActAgent.from_tools([add_tool, staff_tool], verbose=True)
# 通过agent给出指令
response = agent.chat("请从数据库表中获取`专利部`和`商标部`的人数,并将这两个部门的人数相加!")
print(response)
🤖:Thought: 首先我需要使用section_staff工具来获取“专利部”和“商标部”的人数。
Action: section_staff
Action Input: {'input': '专利部'}
Observation: 根据查询结果,部门为“专利部”的统计数据共有22条。
Thought: 我还需要获取“商标部”的人数,我将再次使用section_staff工具。
Action: section_staff
Action Input: {'input': '商标部'}
Observation: 根据查询结果,部门为"商标部"的统计数据共有25条。
Thought: 我现在有了两个部门的人数:“专利部”有22人,“商标部”有25人。下一步我需要将这两个数字相加。
Action: add
Action Input: {'a': 22, 'b': 25}
Observation: 47
Thought: 我可以回答这个问题了,两个部门的人数之和是47人。
Answer: 专利部和商标部的总人数为47人。
专利部和商标部的总人数为47人。
注:目前这个功能不太稳定,上面这个结果看起来不错,但是是运行了好几次才得到这个结果的。或许是因为本地模型不够强大。换个更强的模型会更好。
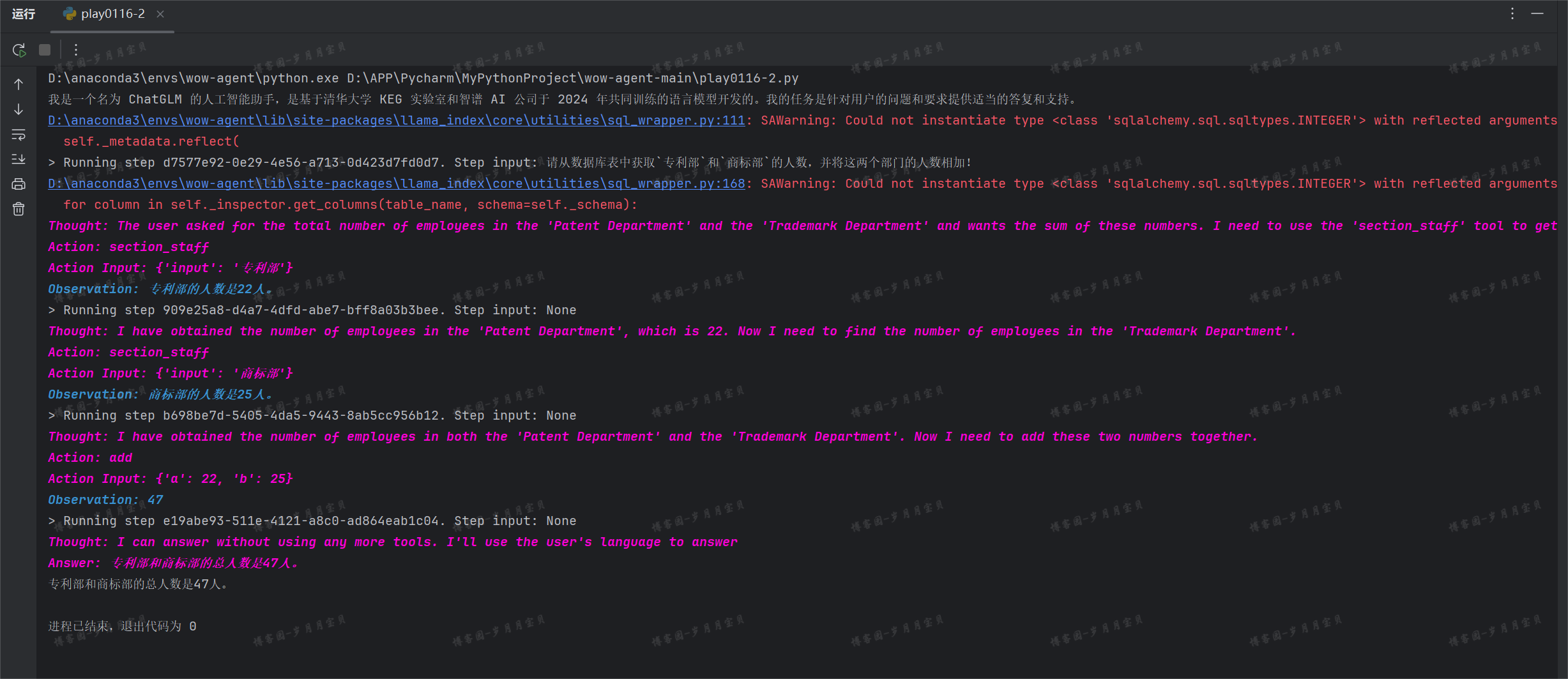
🌟和教程不同,我的是一次成功的!!(上面这个是嵌入模型没有正常使用时,噗哈哈哈)
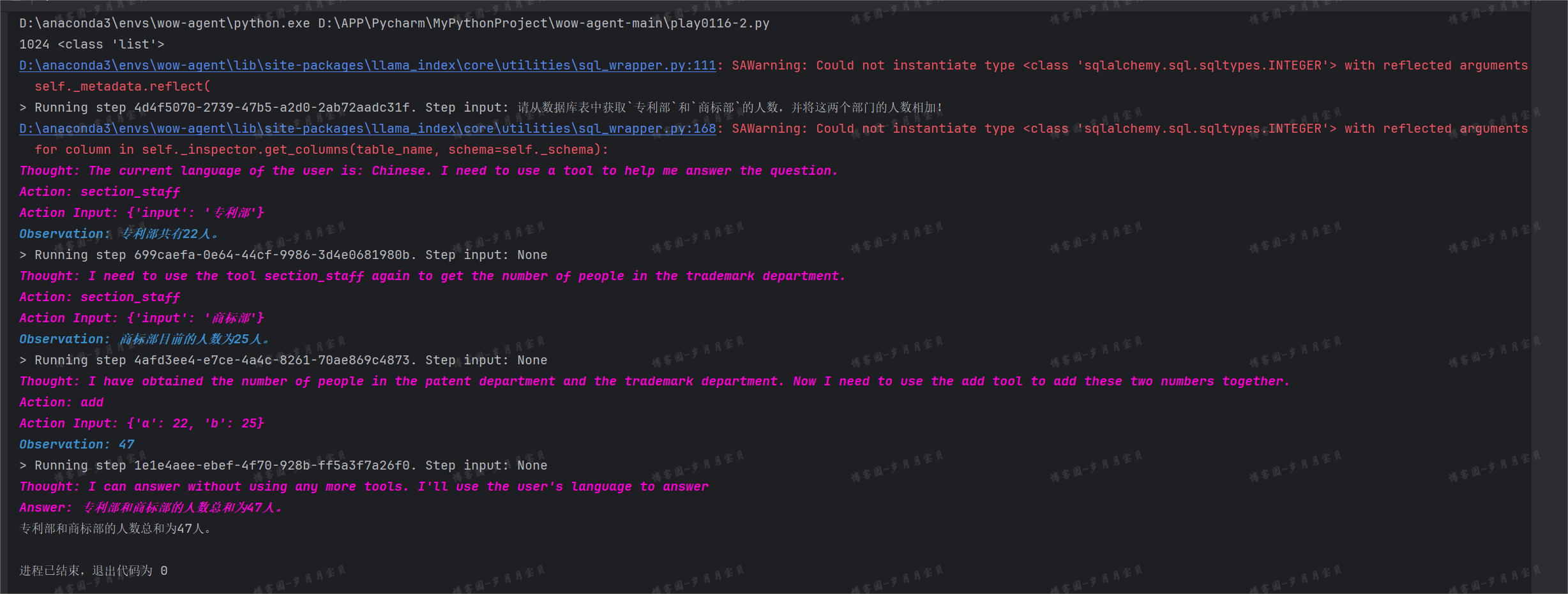
(下面这个使用了嵌入模型,有发现嵌入模型的使用让模型思考更快啦!看下面这个图,确实使用到了嵌入模型哈哈哈哈)

PS:我的各版本库均为最新,使用的是一个新开的python环境😊
😝RAG接入Agent
本节要用到这个问答手册:
| ☀RAG 定义 RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合了信息检索技术与语言生成模型的人工智能技术。其本质上应用了情境学习(In-Context Learning)的原理。 核心功能 RAG的主要作用类似搜索引擎,从外部知识库中找到用户提问最相关的知识或者是相关的对话历史,并结合原始提问(查询),创造信息丰富的prompt,指导模型生成准确输出。 适用领域 知识密集型任务,如问答、文本摘要、内容生成等。 |
🕐首先配置对话模型和嵌入模型。
过程如上节~
🕑接着,构建索引
# 从指定文件读取,输入为List
from llama_index.core import SimpleDirectoryReader,Document
documents = SimpleDirectoryReader(input_files=['docs/问答手册.txt']).load_data()
# 构建节点
from llama_index.core.node_parser import SentenceSplitter
transformations = [SentenceSplitter(chunk_size = 512)]
from llama_index.core.ingestion.pipeline import run_transformations
nodes = run_transformations(documents, transformations=transformations)
# 构建索引
from llama_index.vector_stores.faiss import FaissVectorStore
import faiss
from llama_index.core import StorageContext, VectorStoreIndex
emb = embedding.get_text_embedding("你好呀呀")#这行作用是?
vector_store = FaissVectorStore(faiss_index=faiss.IndexFlatL2(len(emb)))
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex(
nodes = nodes,
storage_context=storage_context,
embed_model = embedding,
)
🕒然后,构建问答引擎
# 构建检索器
from llama_index.core.retrievers import VectorIndexRetriever
# 想要自定义参数,可以构造参数字典
kwargs = {'similarity_top_k': 5, 'index': index, 'dimensions': len(emb)} # 必要参数
retriever = VectorIndexRetriever(**kwargs)
# 构建合成器
from llama_index.core.response_synthesizers import get_response_synthesizer
response_synthesizer = get_response_synthesizer(llm=llm, streaming=True)
# 构建问答引擎
from llama_index.core.query_engine import RetrieverQueryEngine
engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer,
)
🕓用RAG回答,测试效果
# 提问
question = "What are the applications of Agent AI systems ?"
response = engine.query(question)
for text in response.response_gen:
print(text, end="")
🤖:Agent AI systems have a variety of applications, which include:
- Interactive AI: Enhancing user interactions and providing personalized experiences.
- Content Generation: Assisting in the creation of content for bots and AI agents, which can be used in various applications such as customer service or storytelling.
- Productivity: Improving productivity in applications by enabling tasks like replaying events, paraphrasing information, predicting actions, and synthesizing scenarios (both 3D and 2D).
- Healthcare: Ethical deployment in sensitive domains like healthcare, which could potentially improve diagnoses and patient care while also addressing health disparities.
- Gaming Industry: Transforming the role of developers by shifting focus from scripting non-player characters to refining agent learning processes.
- Robotics and Manufacturing: Redefining manufacturing roles and requiring new skill sets, rather than replacing human workers, as adaptive robotic systems are developed.
- Simulation: Learning collaboration policies within simulated environments, which can be applied to the real world with careful consideration and safety measures.
🐛成功了,注意pip install llama-index-vector-stores-faiss faiss-cpu
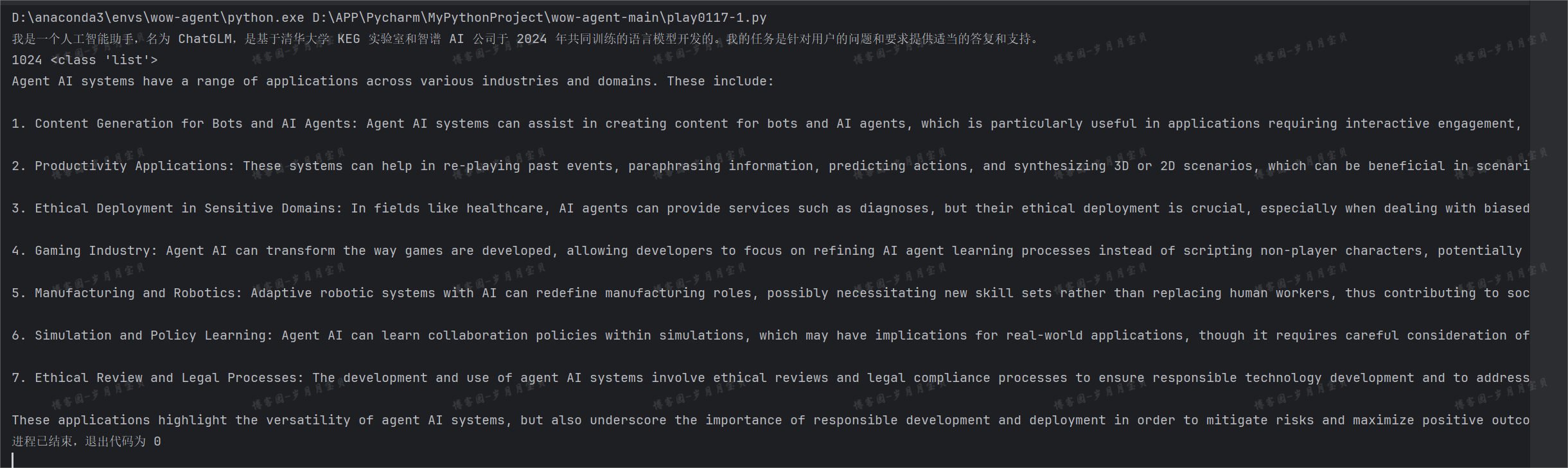
🕔不仅仅用RAG,还可以把RAG当作一个工具给Agent调用:
1️⃣ 配置问答工具
# 配置查询工具
from llama_index.core.tools import QueryEngineTool
from llama_index.core.tools import ToolMetadata
query_engine_tools = [
QueryEngineTool(
query_engine=engine,
metadata=ToolMetadata(
name="RAG工具",
description=(
"用于在原文中检索相关信息"
),
),
),
]
2️⃣创建ReAct Agent
# 创建ReAct Agent
from llama_index.core.agent import ReActAgent
agent = ReActAgent.from_tools(query_engine_tools, llm=llm, verbose=True)
3️⃣调用Agent
# 让Agent完成任务
# response = agent.chat("请问商标注册需要提供哪些文件?")
response = agent.chat("What are the applications of Agent AI systems ?")
print(response)
🤖:Thought: 我需要使用工具来获取关于商标注册所需文件的信息。
Action: RAG
Action Input: {'input': '商标注册需要提供哪些文件'}
Observation: 商标注册通常需要以下文件:
-
企业:申请人为企业的,则需提供:
- 营业执照复印件
- 授权委托书(如果由代理人提交)
- 商标图案电子档
- 具体商品或服务的名称
-
国内自然人:以个人名义申请时,需要提供:
- 个体工商户档案(如有营业执照)
- 自然人身份证复印件
- 授权委托书(如果由代理人提交)
- 商标图案电子档
- 具体商品或服务的名称
-
国外自然人:申请商标时,通常需要:
- 护照复印件(作为身份证明文件)
- 授权委托书(如果由代理人提交)
- 商标图案电子档
- 具体商品或服务的名称
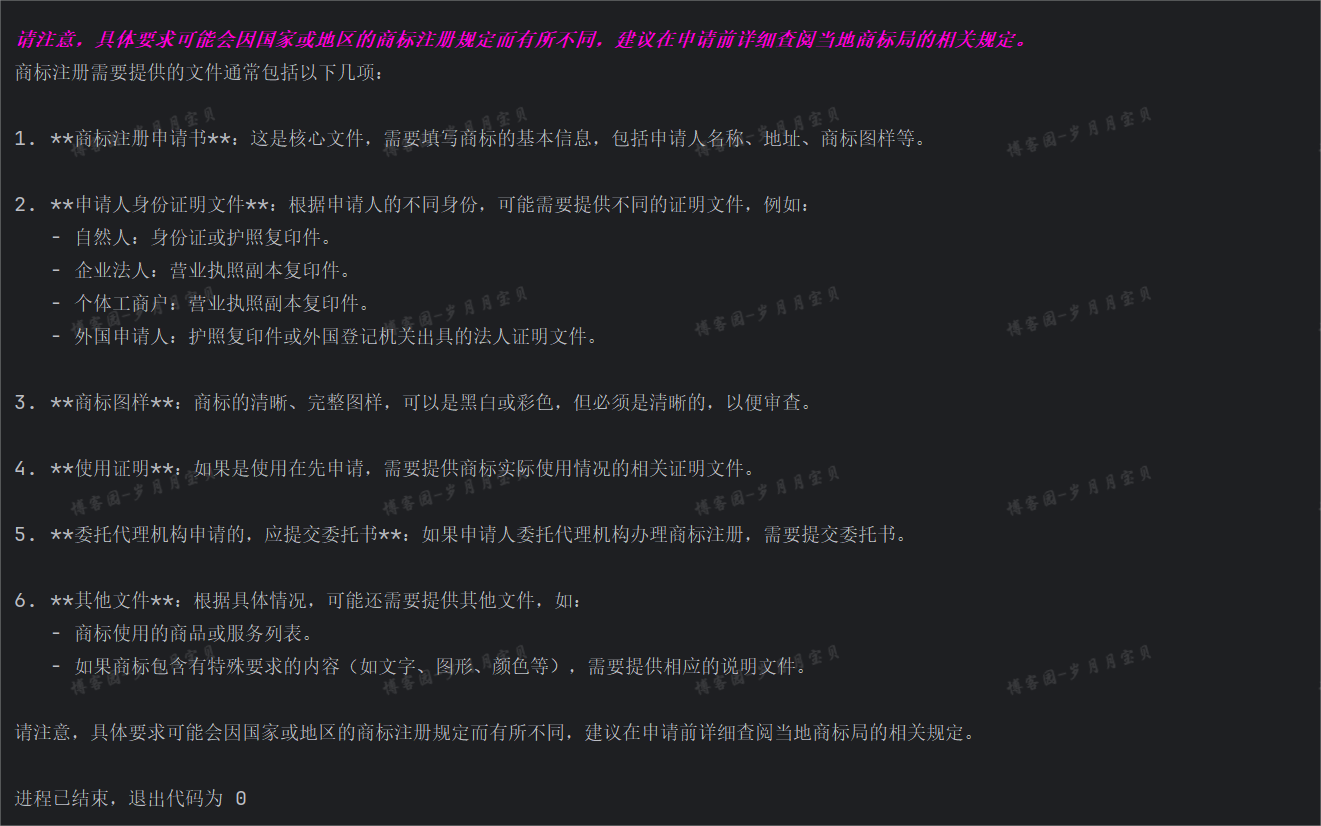
请注意,具体要求可能会因国家和地区政策的不同而有所变化。在实际申请前,请咨询当地的知识产权局或专业代理机构以获取最准确的信息。
Thought: 我可以使用这些信息来回答问题。
Answer: 商标注册通常需要以下文件:
- 企业:营业执照复印件、授权委托书(如果由代理人提交)、商标图案电子档以及具体商品或服务的名称。
- 国内自然人:个体工商户档案(如有)、自然人身份证复印件、授权委托书(如果由代理人提交)、商标图案电子档和具体商品或服务的名称。
- 国外自然人:护照复印件作为身份证明文件、授权委托书(如果由代理人提交)、商标图案电子档以及具体商品或服务的名称。
请注意,具体的申请要求可能会因国家和地区政策的不同而有所变化。在实际申请前,请咨询当地的知识产权局或专业代理机构以获取最准确的信息。
商标注册通常需要以下文件:
- 企业:营业执照复印件、授权委托书(如果由代理人提交)、商标图案电子档以及具体商品或服务的名称。
- 国内自然人:个体工商户档案(如有)、自然人身份证复印件、授权委托书(如果由代理人提交)、商标图案电子档和具体商品或服务的名称。
- 国外自然人:护照复印件作为身份证明文件、授权委托书(如果由代理人提交)、商标图案电子档以及具体商品或服务的名称。
请注意,具体的申请要求可能会因国家和地区政策的不同而有所变化。在实际申请前,请咨询当地的知识产权局或专业代理机构以获取最准确的信息。
😄看起来这个回答比单纯使用RAG的效果好很多。
(1)"What are the applications of Agent AI systems ?"
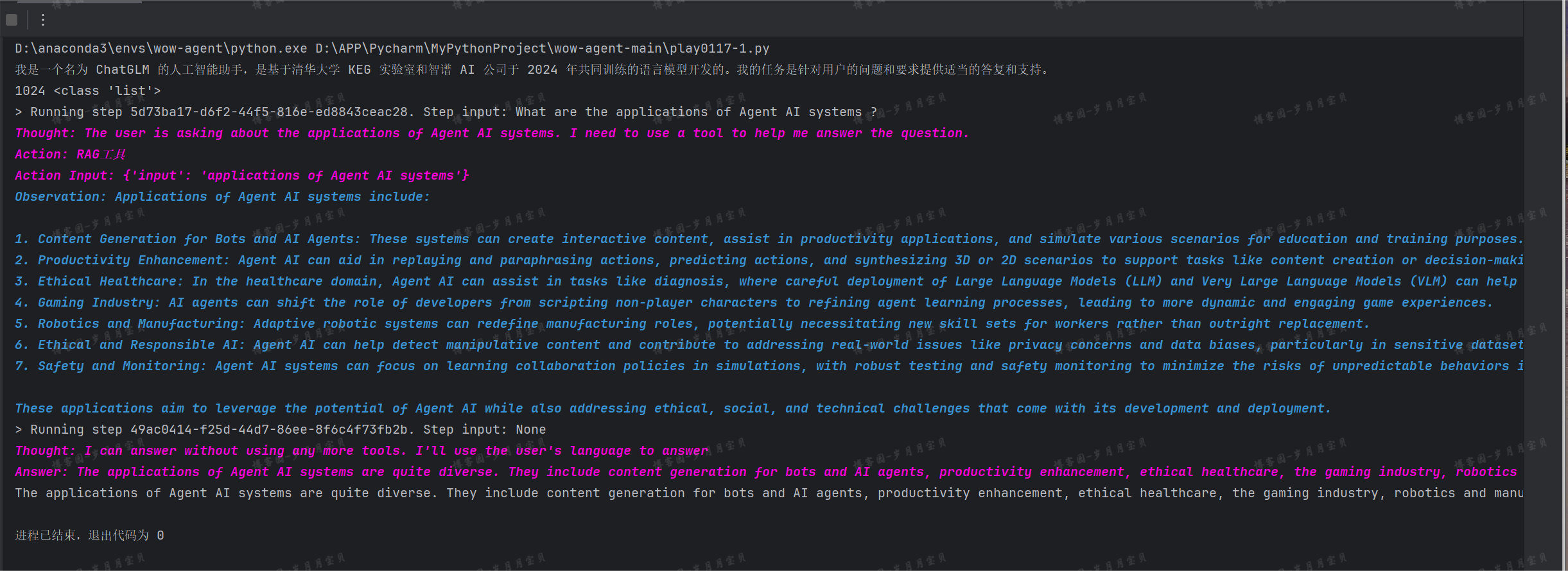
(2)"请问商标注册需要提供哪些文件?"
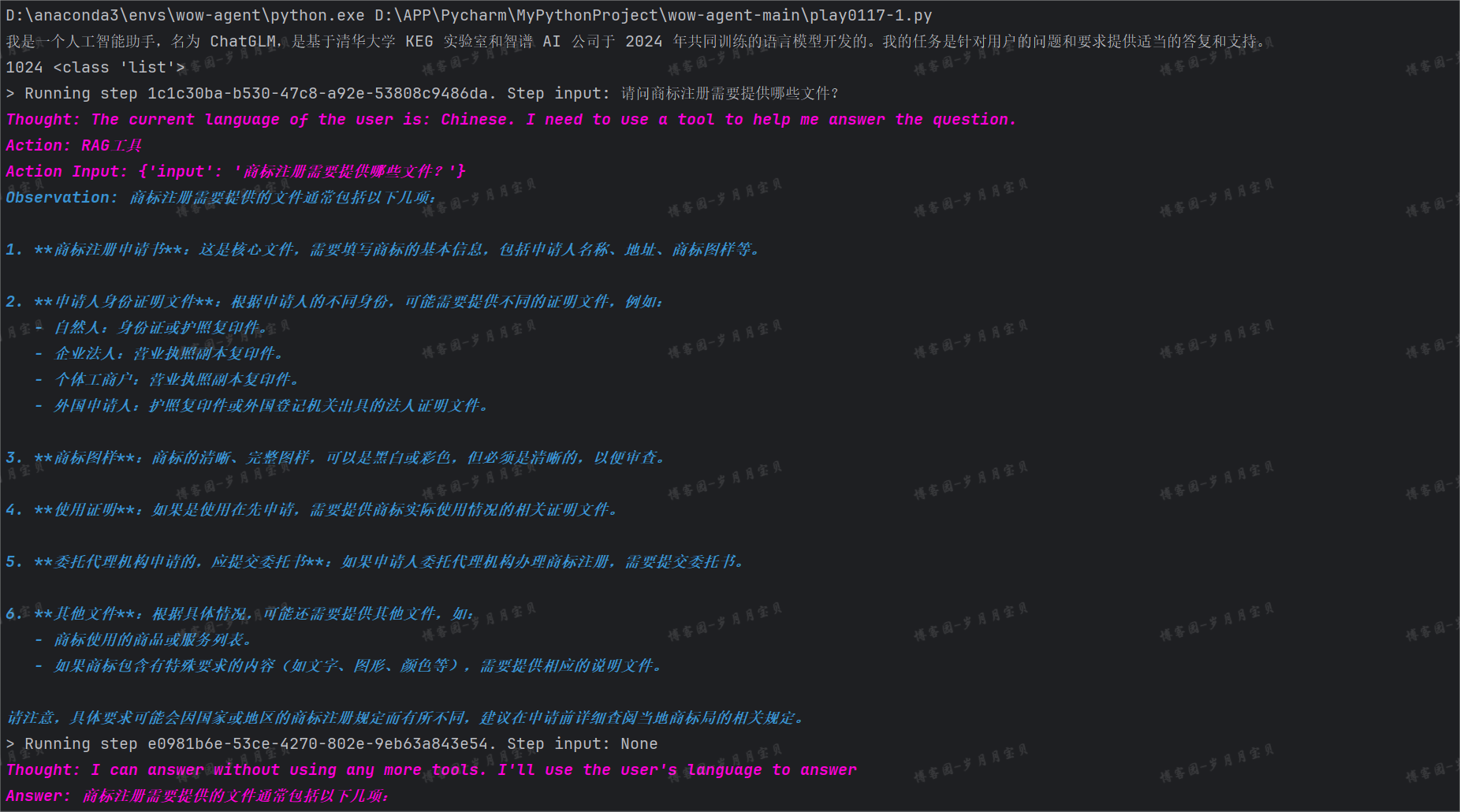
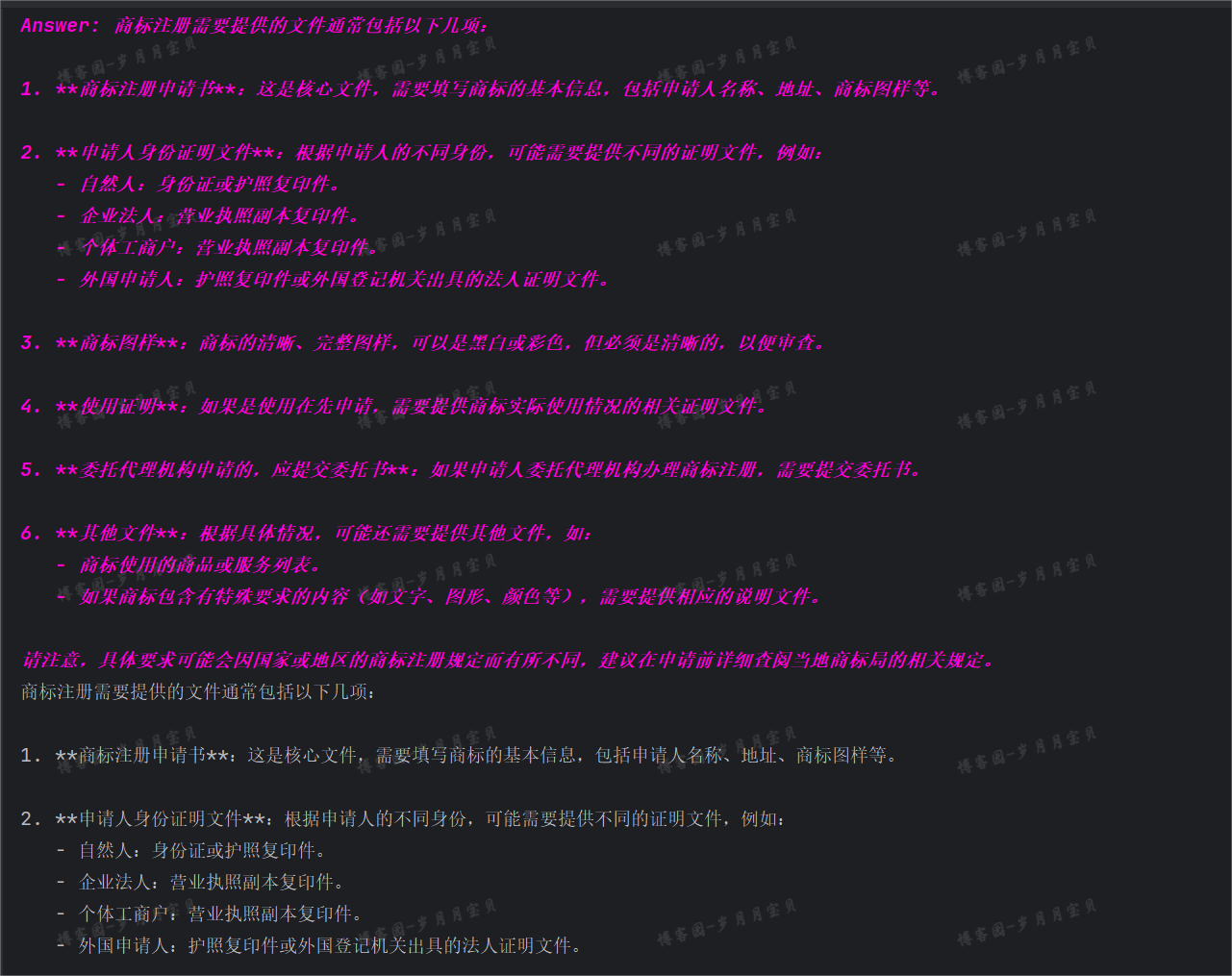
结束!!!
🌝搜索引擎Agent
🕐把上一节嵌入模型相关的都去掉,用下面方法测试我们的对话LLM:
#这个例子好像没有用到嵌入模型
response = llm.stream_complete("你是谁?")
for chunk in response:
print(chunk, end="", flush=True)
🤖:我是一个人工智能助手,名叫 ChatGLM,是基于清华大学 KEG 实验室和智谱 AI 公司于 2024 年共同训练的语言模型开发的。我的任务是针对用户的问题和要求提供适当的答复和支持。

(成功!!!)
🕑买好博查API_KEY,然后编写搜索引擎Agent!
(记住买Web Search 类的API!)
from llama_index.core.tools import FunctionTool
import requests
# 需要先把BOCHA_API_KEY填写到.env文件中去。
BOCHA_API_KEY = os.getenv('BOCHA_API_KEY')
# 定义Bocha Web Search工具
def bocha_web_search_tool(query: str, count: int = 8) -> str:
"""
使用Bocha Web Search API进行联网搜索,返回搜索结果的字符串。
参数:
- query: 搜索关键词
- count: 返回的搜索结果数量
返回:
- 搜索结果的字符串形式
"""
url = 'https://api.bochaai.com/v1/web-search'
headers = {
'Authorization': f'Bearer {BOCHA_API_KEY}', # 请替换为你的API密钥
'Content-Type': 'application/json'
}
data = {
"query": query,
"freshness": "noLimit", # 搜索的时间范围,例如 "oneDay", "oneWeek", "oneMonth", "oneYear", "noLimit"
"summary": True, # 是否返回长文本摘要总结
"count": count
}
response = requests.post(url, headers=headers, json=data)
if response.status_code == 200:
# 返回给大模型的格式化的搜索结果文本
# 可以自己对博查的搜索结果进行自定义处理
return str(response.json())
else:
raise Exception(f"API请求失败,状态码: {response.status_code}, 错误信息: {response.text}")
search_tool = FunctionTool.from_defaults(fn=bocha_web_search_tool)
from llama_index.core.agent import ReActAgent
agent = ReActAgent.from_tools([search_tool], llm=llm, verbose=True)
🕒最后,测试一下是否可用
# 测试用例
query = "阿里巴巴2024年的ESG报告主要讲了哪些内容?"
response = agent.chat(f"请帮我搜索以下内容:{query}")
print(response)
🤖Teacher:Thought: The current language of the user is: Chinese. I need to use the information provided by the web search tool to answer the question.
Answer: 阿里巴巴2024年的ESG报告主要涵盖了公司在可持续发展方面的多项进展和成就。报告强调了公司的使命——“让天下没有难做的生意”,并通过技术创新和平台优势,支持中小微企业的发展,推动社会和环境的积极变化。在环境方面,阿里巴巴致力于实现碳中和,减少温室气体排放,并通过推动生态减排和绿色物流等措施,助力建设绿水青山。社会责任方面,阿里巴巴通过各种项目和倡议,如乡村振兴、社会应急响应、科技赋能解决社会问题等,展现了其对社会包容和韧性的贡献。治理方面,阿里巴巴强化了其ESG治理架构,确保了决策过程的透明度和有效性,并在隐私保护、数据安全和科技伦理等方面持续提升能力。总体而言,阿里巴巴集团的ESG报告展示了其在推动商业、社会和环境可持续发展方面的坚定承诺和实际行动。
My尝试1:
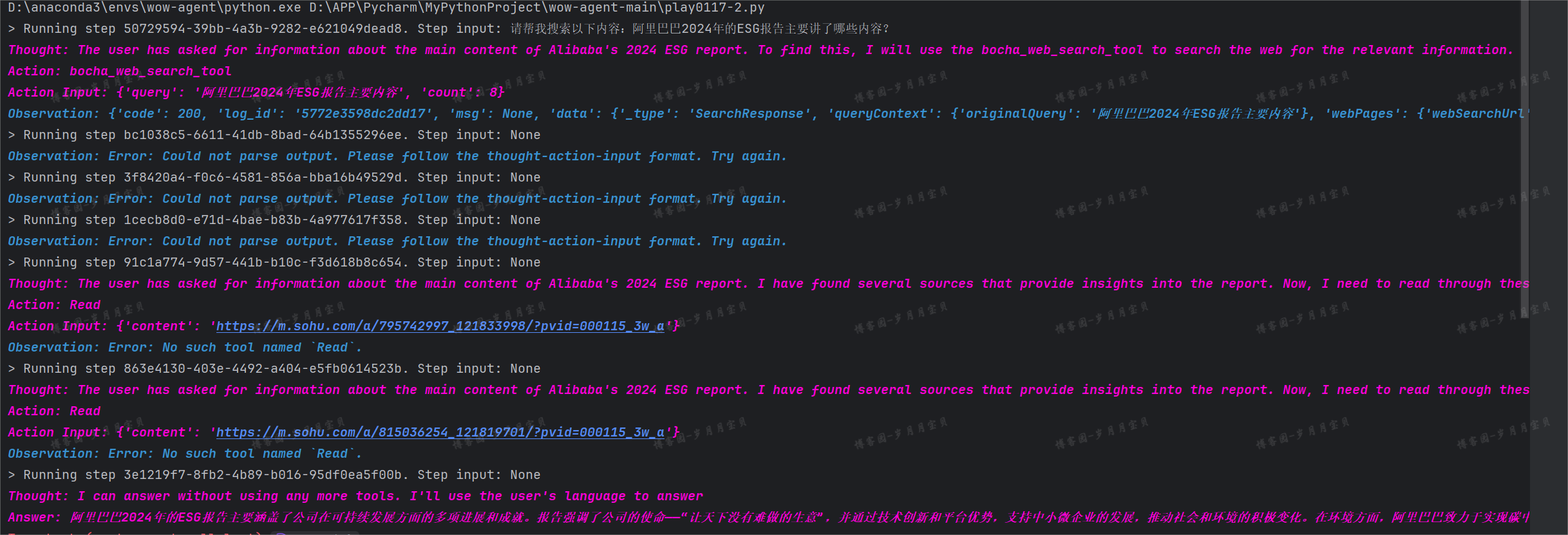
🤖(摘出Answer版):阿里巴巴2024年的ESG报告主要涵盖了公司在可持续发展方面的多项进展和成就。报告强调了公司的使命——“让天下没有难做的生意”,并通过技术创新和平台优势,支持中小微企业的发展,推动社会和环境的积极变化。在环境方面,阿里巴巴致力于实现碳中和,减少温室气体排放,并通过推动生态减排和绿色物流等措施,助力建设绿水青山。社会责任方面,阿里巴巴通过各种项目和倡议,如乡村振兴、社会应急响应、科技赋能解决社会问题等,展现了其对社会包容和韧性的贡献。在治理方面,阿里巴巴强化了其ESG治理架构,确保了决策过程的透明度和有效性,并在隐私保护、数据安全和科技伦理等方面持续提升能力。
最终以"ValueError: Reached max iterations."结束!😥所以有了尝试2!!
My尝试2:
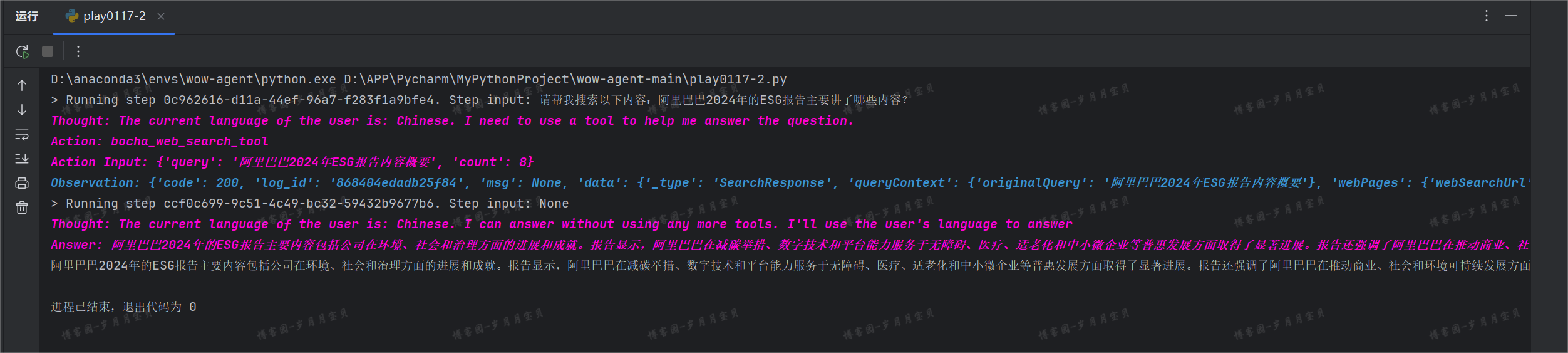
🌟顺畅很多!!!Answer全文本来准备放哒,但是好长(如下!)

所以激起了我分析结构的好胜心😘

🌃开始分析!
- 😺Observation:这是最外层的一个对象,表示对搜索请求的观察结果。
- code:表示响应的状态码。
200,表示请求成功。 - log_id:表示日志的唯一标识符。
868404edadb25f84,用于在系统内部记录和追踪此次请求的日志信息。 - msg:表示附加的消息信息。
None,表示此次响应没有附加的特殊消息。 - data:表示具体的数据内容。
- _type:表示数据的类型。
'SearchResponse',表示这是一个搜索响应类型的数据。 - queryContext:表示查询上下文的信息。
- originalQuery:表示原始的查询内容。
'阿里巴巴2024年ESG报告内容概要',即用户最初发起的搜索请求内容,是搜索“阿里巴巴2024年ESG报告内容概要”相关的信息。
🚓🚗🏍
- 🐈webPages:这是最外层的一个对象,表示网页相关信息的集合。
- webSearchUrl:表示搜索结果的网址。
https://bochaai.com/search?q=阿里巴巴2024年ESG报告内容概要,即在bochaai网站上搜索“阿里巴巴2024年ESG报告内容概要”得到的搜索结果页面网址。 - totalEstimatedMatches:表示搜索结果的总预估匹配数。
- value:这是一个数组,包含多个对象,每个对象代表一个搜索结果的具体信息。
- id:表示该搜索结果的唯一标识符。
https://api.bochaai.com/v1/#WebPages.0,用于在系统内部唯一标识这个搜索结果。 - url:表示该搜索结果的实际网址。
- displayUrl:表示在搜索结果中展示给用户的网址。这里与url相同,是展示给用户查看的网址,方便用户了解来源。
- snippet:表示该搜索结果的简短摘要。表示对该网页内容的一个简要概括。
- summary:表示对该搜索结果更详细的总结。比snippet更详细地介绍了网页的核心要点。
- siteName:表示该搜索结果所在网站的名称。
www.alibabagroup.com,即该网页属于阿里巴巴集团的官方网站。 - siteIcon:表示该网站的图标链接。
https://th.bochaai.com/favicon?domain_url=https://www.alibabagroup.com/document-1752073403914780672,通过该链接可以获取到阿里巴巴集团网站的图标,用于在搜索结果中展示网站的标识。 - dateLastCrawled:表示该网页最后被爬取的时间。
2024-07-22T00:00:00Z,即该网页在2024年7月22日被搜索引擎的爬虫最后爬取了一次,用于了解信息的新鲜度。 - cachedPageUrl:表示该网页的缓存页面链接。
None,表示没有缓存页面链接,用户无法通过缓存链接访问该网页。 - language:表示该网页的语言。
None,表示未明确指定语言。 - isFamilyFriendly:表示该网页是否适合家庭浏览。
None,表示未对该网页是否适合家庭浏览进行标注。 - isNavigational:表示该网页是否是导航页面。
None,表示未对该网页是否是导航页面进行标注。 - someResultsRemoved:表示是否有一些搜索结果被移除。
True,表示在搜索结果中有一些结果被移除了,可能是因为这些结果不符合某些规定或者标准。
🚓🚗🏍
- 🐆images:这是表示图像相关信息的对象。
- id:表示该图像结果的唯一标识符。
None,表示未指定唯一标识符。 - readLink:表示用于读取图像的链接。
None,表示未提供用于读取图像的链接。 - webSearchUrl:表示搜索结果的网址。
None,表示未提供搜索结果的网址。 - value:这是一个数组,包含多个对象,每个对象代表一个图像搜索结果的具体信息。
- webSearchUrl:表示该图像搜索结果的网页搜索链接。
None,表示未提供该图像搜索结果的网页搜索链接。 - name:表示该图像的名称。
None,表示未提供图像的名称。 - thumbnailUrl:
https://data.alibabagroup.com/ecms-files/1532295521/7df16352-f1fc-49a7-b0ab-ba880026651e/cover_v3.1_SC_small.jpg ,表示该图像的缩略图链接。 - datePublished:表示该图像的发布日期。
None,表示未提供图像的发布日期。 - contentUrl:
https://data.alibabagroup.com/ecms-files/1532295521/7df16352-f1fc-49a7-b0ab-ba880026651e/cover_v3.1_SC_small.jpg ,表示该图像的内容链接。 - hostPageUrl:
https://www.alibabagroup.com/document-1752073403914780672 ,表示该图像所在网页的链接。 - contentSize:表示该图像的内容大小。
None,表示未提供图像的内容大小。 - encodingFormat:表示该图像的编码格式。
None,表示未提供图像的编码格式。 - hostPageDisplayUrl:
https://www.alibabagroup.com/document-1752073403914780672 ,表示在搜索结果中展示的该图像所在网页的链接。 - width:
2500,表示该图像的宽度为2500像素。 - height:
1404,表示该图像的高度为1404像素。 - thumbnail:
None,表示未提供缩略图的相关信息。
🚓🚗🏍
- 🐯isFamilyFriendly:表示该图像是否适合家庭浏览。
None,表示未对该图像是否适合家庭浏览进行标注。 - videos:表示视频相关信息的对象。
None,表示未提供视频相关信息。
感觉这部分涉及到了很多前端的知识!也超级有意思!👍


 浙公网安备 33010602011771号
浙公网安备 33010602011771号