SQL学习笔记系列(十)窗口函数
窗口函数介绍
窗口函数语法
<窗口函数> over (partition by <用于分组的列名>
order by <用于排序的列名>)
- 专用窗口函数,比如rank, dense_rank, row_number等
- 聚合函数,如sum. avg, count, max, min等
窗口函数功能
- 不减少原表的行数,所以经常用来在每组内排名
- 同时具有分组(partition by)和排序(order by)的功能
窗口函数使用场景
业务需求“在每组内排名”,比如:
- 排名问题:每个部门按业绩来排名
- topN问题:找出每个部门排名前N的员工进行奖励
注意事项
- 窗口函数原则上只能写在select子句中
- partition子句可以省略,省略就是不指定分组,但是,这就失去了窗口函数的功能,所以一般不要这么使用。
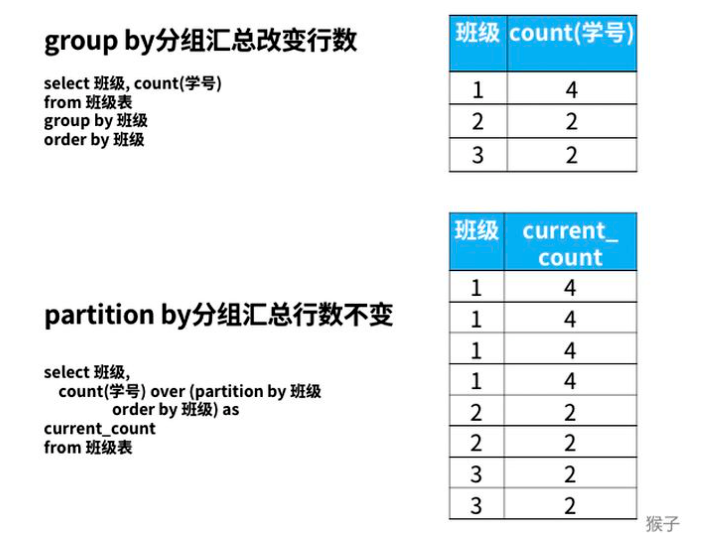
group by、order by子句与窗口函数的区别
group by分组汇总后改变了表的行数,一行只有一个类别。而partiition by和rank函数不会减少原表中的行数
标准聚合函数
标准的聚合函数有avg、count、sum、max和min,接下来分别介绍这些聚合函数的窗口函数形式。
移动平均窗口函数
移动平均值的定义:若依次得到测定值(x1,x2,x3,...xn)时,按顺序取一定个数所做的全部算数平均值。例如(x1+x2+x3)/3,(x2+x3+x4)/3,(x3+x4+x5)/3,....就是移动平均值。其中,x可以是日或者月,以上的可以成为3日移动平均,或3月移动平均,常用于股票分析中。
#语法结构
avg(字段名) over(
partition by 用于分组的列名
order by 用于排序的列名 asc/desc
rows between A and B )
#A和B是计算的行数范围,
rows between 2 preceding and current row # 取当前行和前面两行
rows between unbounded preceding and current row # 包括本行和之前所有的行
rows between current row and unbounded following # 包括本行和之后所有的行
rows between 3 preceding and current row # 包括本行和前面三行
rows between 3 preceding and 1 following # 从前面三行和下面一行,总共五行
当order by后面缺少窗口从句条件,窗口规范默认是rows between unbounded preceding and current row.
当order by和窗口从句都缺失, 窗口规范默认是 rows between unbounded preceding and unbounded following
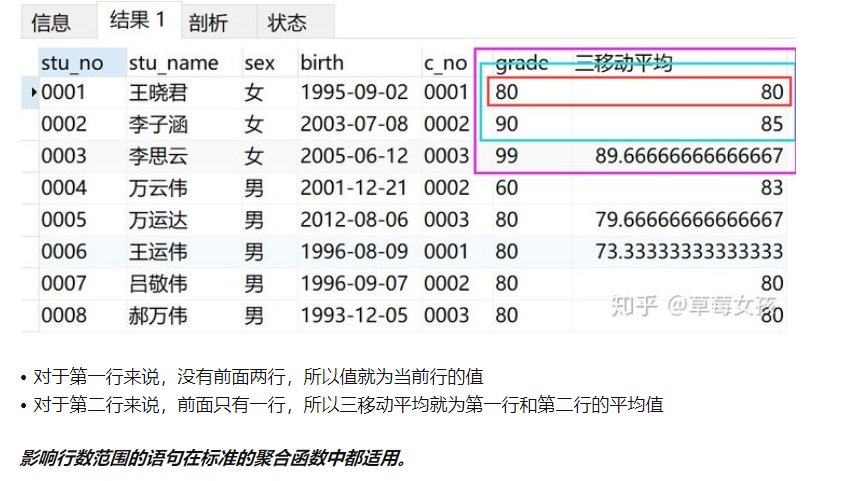
例子
SELECT *,AVG(grade) OVER(
ORDER BY stu_no
ROWS BETWEEN 2 preceding AND CURRENT ROW
) AS '三移动平均'
FROM v_info
计数(count)窗口函数
窗口函数 count(*) over() 对于查询返回的每一行,它返回了表中所有行的计数。
语法结构:
count(字段名1) over(
partition by 字段名2
order by 字段名3 asc/desc)
例子1
查询出成绩在90分以上的人数
SELECT *,
COUNT(*) OVER() AS 'ct'
FROM v_info
WHERE grade>=90
例子2
按照课程号进行分组,找出成绩大于等于80分的学生人数
SELECT *,
COUNT(*) OVER(PARTITION BY c_no) AS 'ct'
FROM v_info
WHERE grade>=80
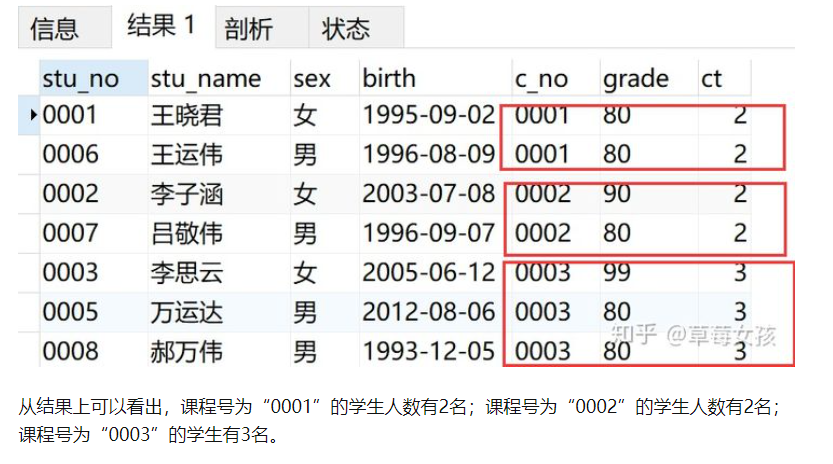
小声bb:这两个例子举得不是很好,如果只是为了看学生人数,用group by能更明了地看。应该说找出大于等于80分的学生人数及其相关信息。
累计求和(sum)窗口函数
语法结构
sum(字段名1) over(
partition by 字段名2
order by 字段名3 asc/desc)
--按照字段1进行累积求和
-- 按照字段2 进行分组
-- 在组内按照字段3进行排序
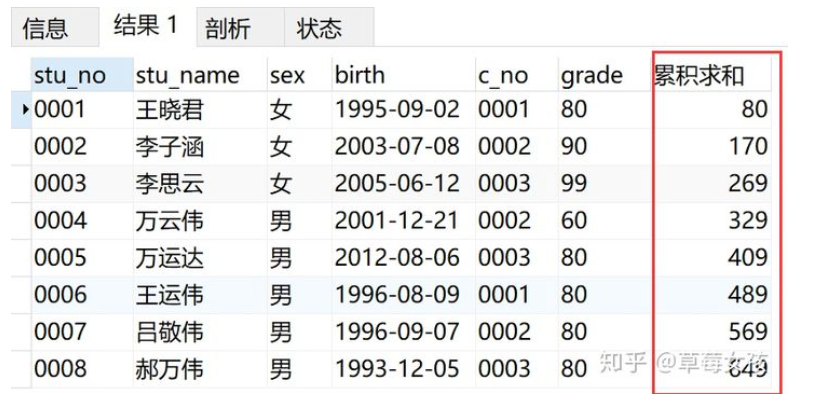
例子1
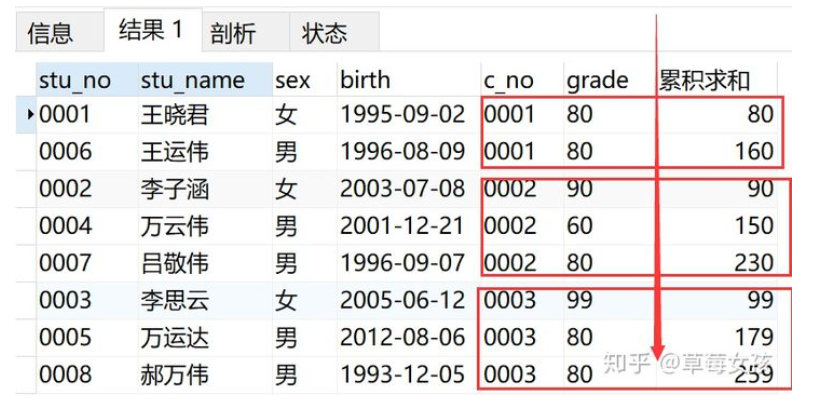
根据学号排序,对学生的成绩进行累积求和
SELECT *,
SUM(grade) OVER(ORDER BY stu_no) AS '累积求和'
FROM v_info
例子2
按照课程号分组,然后根据学号对成绩进行累积求和
SELECT *,SUM(grade) OVER(
PARTITION BY c_no
ORDER BY stu_no
) AS '累积求和'
FROM v_info
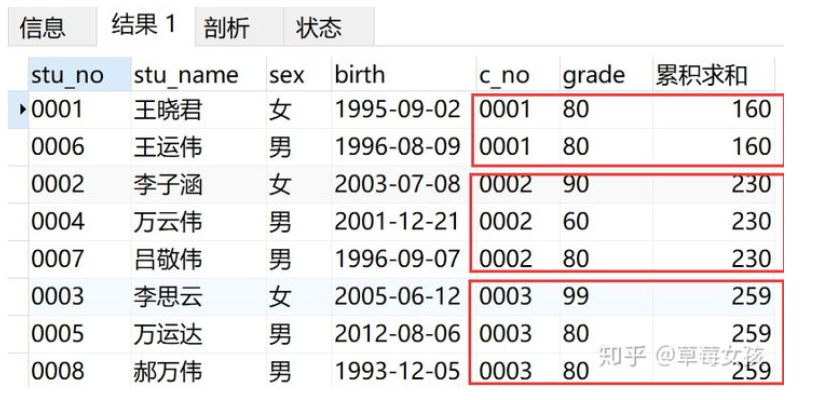
tips:一定要选择根据学号排序,要不然得出来的是最终的累积求和结果,如下图:
SELECT *,
SUM(grade) OVER(PARTITION BY c_no) AS '累积求和'
FROM v_info
最大(max)、最小值(min)窗口函数
语法结构
max(字段名1) over(partition by 字段名2 order by 字段名3 asc/desc)
min(字段名1) over(partition by 字段名2 order by 字段名3 asc/desc)
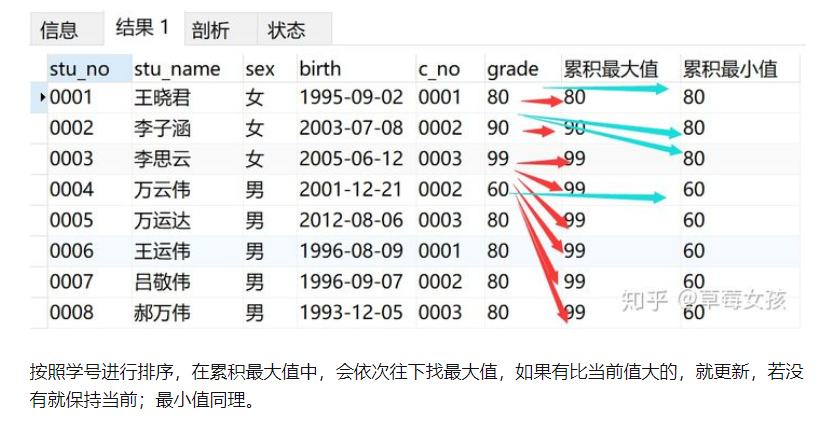
例子1
求成绩的累积最大值和累积最小值
例子2
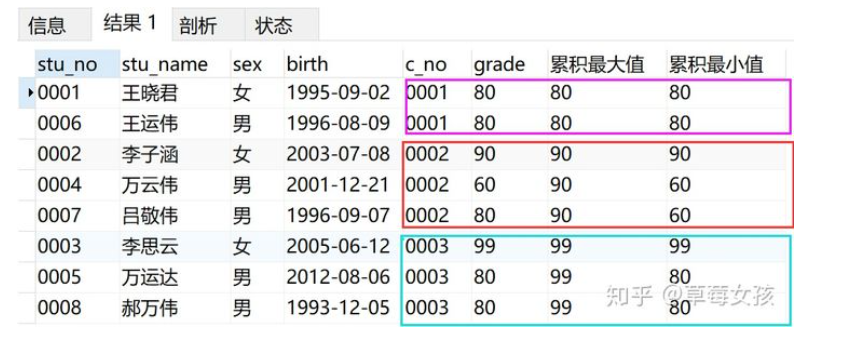
按照课程号进行分组,再求最大、最小值
SELECT *,
MAX(grade) OVER(PARTITION BY c_no ORDER BY stu_no) AS '累积最大值',
MIN(grade) OVER(PARTITION BY c_no ORDER BY stu_no) AS '累积最小值'
FROM v_info
例子3
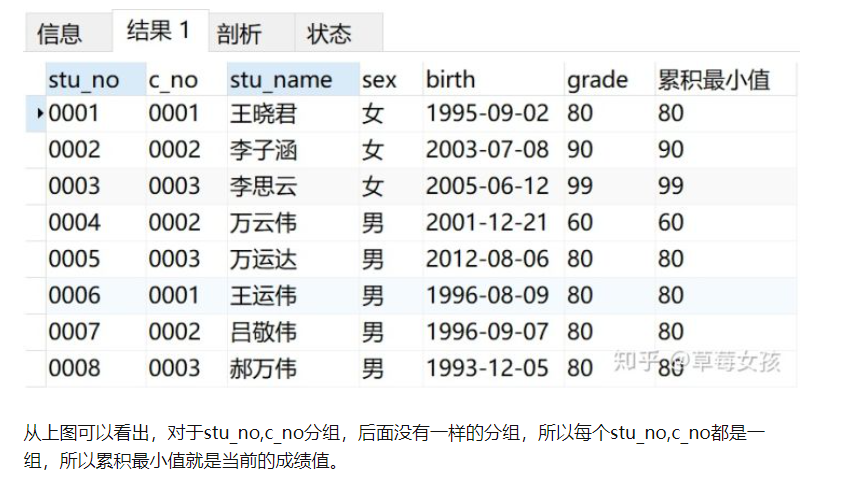
根据学生号和课程号求成绩的累积最小值
SELECT stu_no,c_no,stu_name,sex,birth,grade,
MIN(grade) OVER(PARTITION BY stu_no,c_no) AS '累积最小值'
FROM v_info
例子4
统计2019年10月1日-10月10日每天做新题的人的数量,重点在每天。
- 这个题的重点是在每天,所以需要求出count(时间)=10的用户ID;
- 这个题可以使用min() over()窗口函数,先根据每个做题者和试卷号,找出每个做题者的最小日期,这里和前面(3)的解题思路是一样的;
- 如果每天都做题,那么得到的日期是不一样的,所以count(时间)会等于10;
- 再对这部分的用户ID进行求和,就可以找出每天都做新题的人了。
SELECT COUNT(a.sno) AS '每天做题的人数'
FROM
(SELECT sno,
s_id,
time,
MIN(time) OVER(PARTITION BY sno,s_id) AS 'first_time'
FROM paper
WHERE DATE_FORMAT(time,'%Y-%m-%d') BETWEEN '2019-10-01' AND '2019-10-10') AS a
WHERE a.time=a.first_time
GROUP BY a.sno
HAVING COUNT(DISTINCT a.first_time)=10
排序窗口函数
row_number()、rank()、dense_rank(),这三个函数的作用都是返回相应规则的排序序号。
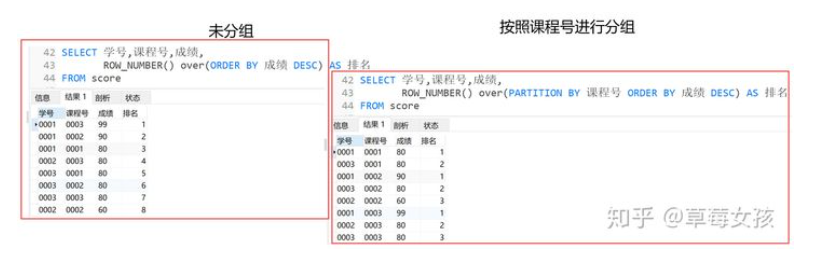
row_number()
为查询出来的每一行记录都会生成一个序号,依次排序且不会重复。
语法
row_number() over(partition by 字段1 order by 字段2) # 字段1是分组的字段名称
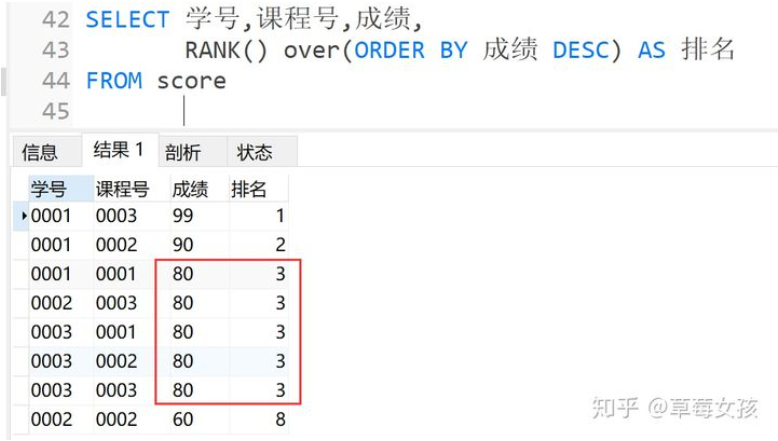
rank()
使用rank函数来生成序号,over子句中排序字段值相同的序号是一样的,后面字段值不相同的序号将跳过相同的排名排下一个,rank函数生成的序号有可能是不连续的,即排名可能为1,1,3,是跳跃式排名,有两个第一名时接下来就是第三名。
语法
rank() over(partition by 字段1 order by 字段2)
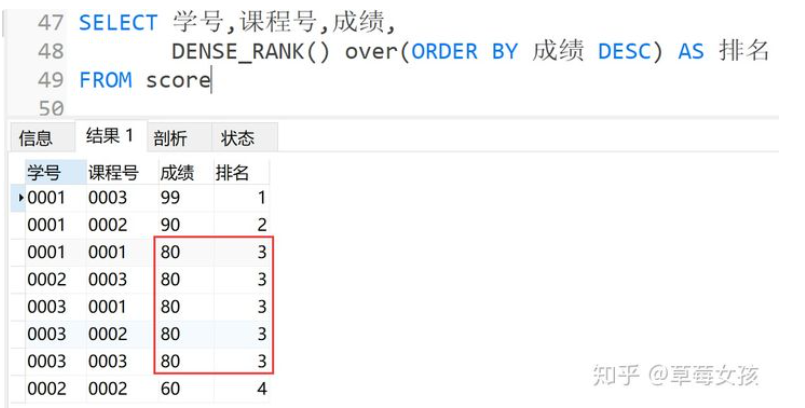
dense_rank()
dense_rank函数在生成序号时是连续的,当出现相同排名时,将不跳过相同排名号,有两个第一名时仍跟着第二名,即排名为1,1,2这种。
语法
dense_rank() over(partition by 字段1 order by 字段2)
分组排序窗口函数
可以按照销售额的高低、点击次数的高低,以及成绩的高低为对用户和学生进行分组,这里的考点是:取销售额最高的25%的用户(将用户分成4组,取出第一组)、取成绩高的前10%的学生(将学生分成10组,取出第一组)等等。
语法结构
ntile(n) over(partition by 字段名2 order by 字段名3 asc/desc)
#n表示要切分的片数,如需要取前25%的用户,则需要分为4组,取前10%的用户,则需要分10组
- ntile(n),用于将分组数据按照顺序切分成n片,返回当前切片值
- ntile不支持rows between的用法
- 切片如果不均匀,默认增加第一个切片的分布
例子1
取出成绩前25%的学生信息
- 第一步:按照成绩的高低,将学生按照成绩进行切片
SELECT *,
ntile(4) OVER(ORDER BY grade DESC) AS 'rank'
FROM v_info
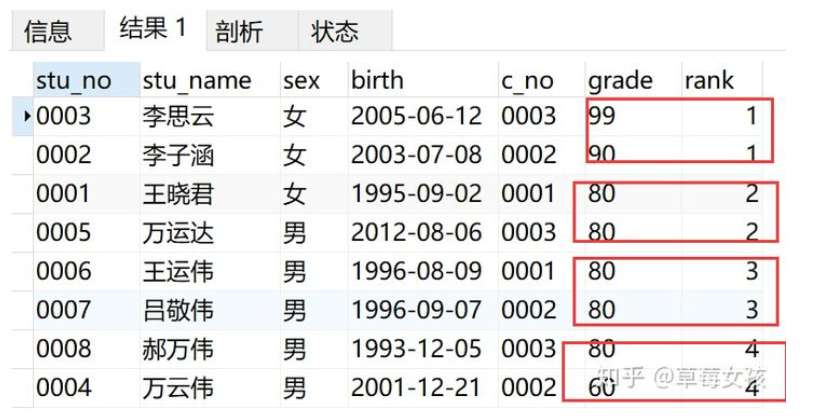
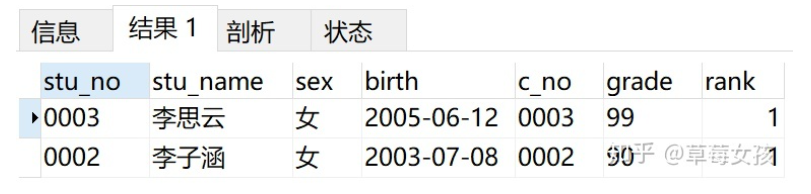
- 第二步:按照rank筛选出第一组,则得到最终的结果如下:
SELECT a.*
FROM
(SELECT *,
ntile(4) OVER(ORDER BY grade DESC) AS 'rank'
FROM v_info) AS a
WHERE a.rank=1
偏移分析窗口函数
- lag() over()和lead() over()窗口函数,lag和lead分析函数可以在同一次查询中取出同一个字段的前N行数据(lag)和后N行(lead)作为独立的列。
- 在实际应用当中,若要用到取今天和昨天的某字段的差值时,lag和lead函数的应用就显得尤为重要了。
- 适用场景:获取用户在某个页面停留的起始与结束时间
语法结构
lag(exp_str,offset,defval) over(partition by ... order by...)
lead(exp_str,offset,defval) over(partition by ... order by...)
-- exp_str表示字段名称
-- offset偏移量,假设当前行在表中排在第5行,offset为3,则表示我们所要找的数据行就是表中的第2行(即5-3=2)
-- offset默认为1
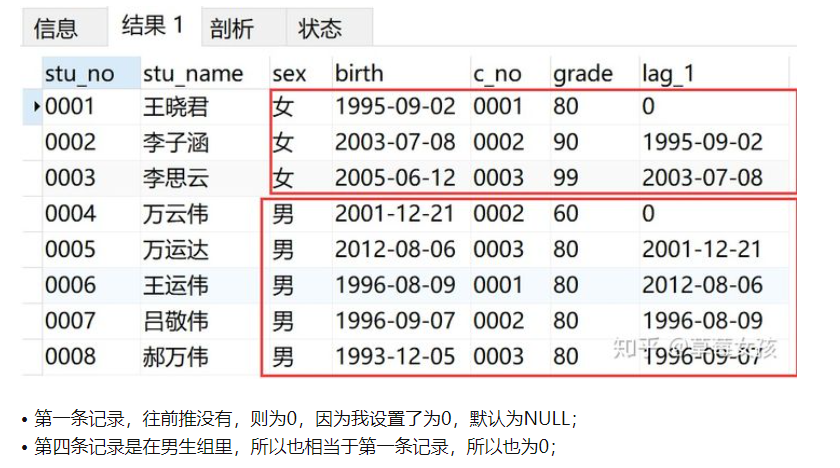
例子1
向前推1个日期
SELECT *,
LAG(birth,1,0) OVER(PARTITION BY sex) AS 'lag_1'
FROM v_info
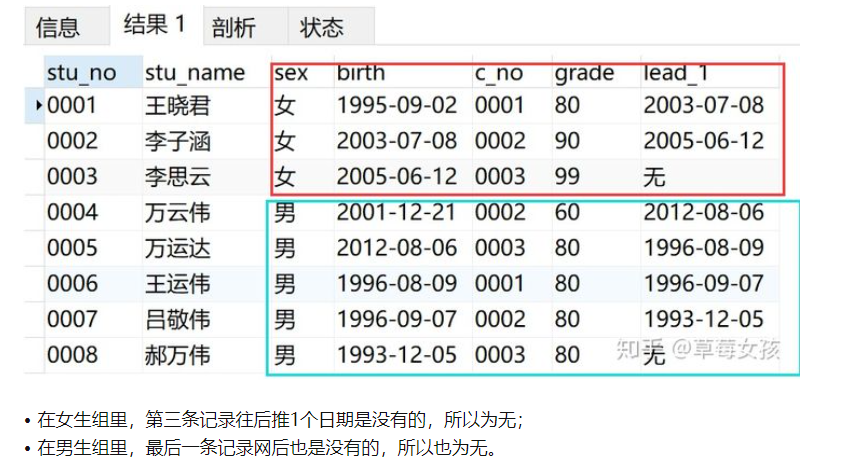
例子2
向后推1个日期
SELECT *,
LEAD(birth,1,'无') OVER(PARTITION BY sex) AS 'lead_1'
FROM v_info
例子3
统计每天符合以下条件的用户数:A操作之后是B操作,AB操作必须相邻。
用户行为表racking_log(user_id,operate_id,log_time)
- 先根据用户ID和日期,用LEAD()窗口函数向后获取下一步的步骤;
- AB必须相邻,则表明当前的步骤为A,而下一个步骤为B,即A向下移的步骤是B;
- “每天”,即根据日期进行分组。
SELECT a.log_date,
COUNT(DISTINCT a.user_id)
FROM
(SELECT user_id,
operate_id,
DATE_FORMAT(log_time,'%Y-%m-%d') AS log_date,
LEAD(operate_id,1,NULL) OVER(PARTITION BY user_id,DATE_FORMAT(log_time,'%Y-%m-%d') ORDER BY log_time) AS 'next_operate'
FROM tracking_log) AS a
WHERE a.operate_id=A AND b.next_operate=B
GROUP BY a.log_date

 浙公网安备 33010602011771号
浙公网安备 33010602011771号