数据库
数据库
索引

哪些情况需要创建索引
1.主键自动建立唯一索引
2.频繁作为查询的条件的字段应该创建索引
3.查询中与其他表关联的字段,外键关系建立索引
6.单间/组合索引的选择问题,who?(在高并发下倾向创建组合索引)
7.查询中排序的字段,排序字段若通过索引去访问将大大提高排序的速度
8.查询中统计或者分组字段
哪些情况不要创建索引
1.表记录太少
2.经常增删改的表
3.数据重复且分布平均的表字段,因此应该只为经常查询和经常排序的数据列建立索引。
注意,如果某个数据列包含许多重复的内容,为它建立索引就没有太大的实际效果。
4.频繁更新的字段不适合创建索引
5.Where条件里用不到的字段不创建索引
SQL优化
1,对查询进行优化避免全表扫描,首先考虑where和group by上涉及的列进行建立索引
2,应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描
3,应尽量避免在 where 子句中使用!=或<>操作符,or,否则将引擎放弃使用索引而进行全表扫描
4, in 和 not in 也要慎用,否则会导致全表扫描,连续值可以使用between and
5,查询使用模糊查询,两端使用%%,导致全表扫描
6,应尽量避免在 where 子句中对字段进行表达式及函数操作,这将导致引擎放弃使用索引而进行全表扫描。如:
7,很多时候用 exists 代替 in 是一个好的选择
8,尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。
这是因为引擎在处理查询和连接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
9,尽可能的使用 varchar 代替 char ,因为首先变长字段存储空间小,可以节省存储空间,
其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
10,任何地方都不要使用 select * from t ,用具体的字段列表代替“*”,不要返回用不到的任何字段
SQL执行流程
数据库范式
数据库自增id,当id值大于MAXINT时,数据库如何做
bigint unsigned
前戳索引
当要索引的列字符很多时 索引则会很大且变慢( 可以只索引列开始的部分字符串 节约索引空间 从而提高索引效率 )
Mysql索引类型
Mysql目前主要有以下几种索引类型:FULLTEXT,HASH,BTREE,RTREE。
https://blog.csdn.net/liutong123987/article/details/79384395
索引种类
普通索引:仅加速查询
唯一索引:加速查询 + 列值唯一(可以有null)
主键索引:加速查询 + 列值唯一(不可以有null)+ 表中只有一个
组合索引:多列值组成一个索引,专门用于组合搜索,其效率大于索引合并
全文索引:对文本的内容进行分词,进行搜索
主键索引与唯一索引区别

事务隔离级别实现原理
https://www.cnblogs.com/wade-luffy/p/8686883.html
Mysql加锁分析
https://www.cnblogs.com/wintersoft/p/10787474.html
https://www.cnblogs.com/zhaoyl/p/4121010.html
数据库如何保证事务的可串行化
事物a 执行读写操作时,会锁定检索的数据行范围(范围锁),这种锁会阻止其他事物在
本范围内的一切操作,只有事物a执行完毕,提交事物后,才会释放范围锁,这样就避免了幻读。
事务隔离级别有什么?通过什么来实现的?分别解决了什么问题
https://www.cnblogs.com/wade-luffy/p/8686883.html
Count区别


Explain


存储引擎的区别




InnoDB为什么推荐使用自增ID作为主键?
自增ID可以保证每次插入时B+索引是从右边扩展的,可以避免B+树和频繁合并和分裂
(对比使用UUID)。如果使用字符串主键和随机主键,会使得数据随机插入,效率比较差。
SQL
删除重复行
DELETE FROM table WHERE
id IN (
SELECT id FROM (
SELECT id,COUNT(*) FROM table
GROUP BY id
HAVING COUNT(*) > 1
) AS a
) LIMIT 1;
REDIS
Redis与zookeeper分布式锁区别
(1)redis分布式锁,其实需要自己不断去尝试获取锁,比较消耗性能
zk分布式锁,获取不到锁,注册个监听器即可,不需要不断主动尝试获取锁,性能开销较小
(2)另外一点就是,如果是redis获取锁的那个客户端bug了或者挂了,那么只能等待超时时间之后才能释放锁;
而zk的话,因为创建的是临时znode,只要客户端挂了,znode就没了,此时就自动释放锁
Redis分布式锁

zookeeper分布式锁
https://blog.csdn.net/crazymakercircle/article/details/85956246
Redis 与 memcached 相比有哪些优势?
1.memcached 所有的值均是简单的字符串, redis 作为其替代者,支持更为丰富的数据类型
2.redis 的速度比 memcached 快很多
3.redis 可以持久化其数据
Redis 消息队列

Redis 有哪几种数据淘汰策略?
1.noeviction:返回错误当内存限制达到,并且客户端尝试执行会让更多内存被使用的命令。
2.allkeys-lru: 尝试回收最少使用的键( LRU),
3.volatile-lru: 尝试回收最少使用的键( LRU),但仅限于在过期集合的键,
4.allkeys-random: 回收随机
5.volatile-random: 回收随机的但仅限于在过期集合的键。
6.volatile-ttl: 回收在过期集合的键,并且优先回收存活时间( TTL)较短的键,
Redis 集群的主从复制模型是怎样的
为了使在部分节点失败或者大部分节点无法通信的情况下集群仍然可用,所以
集群使用了主从复制模型,每个节点都会有 N-1 个复制品.
Redis 集群会有写操作丢失吗?为什么?
Redis 并不能保证数据的强一致性,实际中集群在特定的条件下可能会丢失写操作。
Redis 集群之间是如何复制的?
异步复制
Redis如何实现集群和高可用?
https://www.cnblogs.com/zhuyeshen/p/11737273.html
Redis高可用
cnblogs.com/huangjuncong/p/8494295.html
主从,一致性哈希,
集群模式(哈希槽,客户端重定向,心跳机制)

Redis哨兵模式
https://www.jianshu.com/p/06ab9daf921d
有哪些持久化方式?区别呢?
RDB

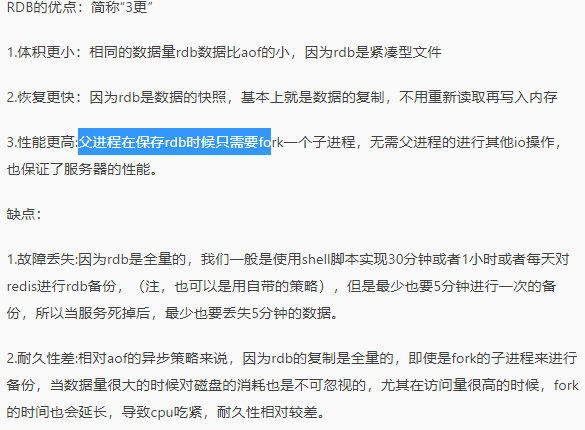
AOF


Redis集群和哨兵模式区别
https://www.php.cn/redis/423113.html
使用过 Redis 分布式锁么,它是怎么实现的?

使用过 Redis 做异步队列么,你是怎么用的?有什么缺点?

什么是缓存穿透?如何避免?什么是缓存雪崩?何如避免?

缓存一致性问题解决方案
https://www.jianshu.com/p/2edbb48604bd
InnoDB存储引擎(从InnoDB的特性出发,行锁,全文索引,聚蔟索引,必须含有主键(没有主键怎么办,如何选择),
为什么是B+树,而不是B树,而不是红黑树,磁盘IO,以及B+树和B树的区别),然后就是InnoDB的MVVC实现
(版本号如何进行各种数据库操作)。
mysql调优过程,即如何发现问题,问题出现的场景,问题出现的原因,解决问题的方法
问了一个这样的表(三个字段:姓名,id,分数)要求查出平均分大于80的id然后分数降序排序。
select id from table group by id having avg(score) > 80 order by avg(score) desc。
posted on 2020-04-01 00:24 huangzhihao 阅读(336) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号