EDAC工具助力检测服务器内存故障
什么是EDAC
EDAC(Error Detection And Correction 错误检测与纠正),是Linux系统的错误检测和纠正的框架,它的目的是在linux系统运行过程中,当错误发生时能够发现并且报告出硬件错误。
内存有两种错误类型分别是CE和UE,CE 是 Correctable Error 的简称, UE是Uncorrectable Error的简称,CE即可恢复的错误,暂不影响系统的正常运行。可以在找时机停机换掉。UE为不可恢复的内存错误,通常会导致宕机。
那么EDAC是如何控制和报告设备故障的呢?它又是如何将故障定位以及记录到对应的内存条上的呢?
- 硬件检测:内存控制器(如 Intel UMC)发现 ECC 错误。
- 中断触发:MCE(Machine Check Exception)或 CMCI(Corrected Machine Check Interrupt)。
- EDAC 驱动处理:如 sb_edac 解析错误信息。
- 更新 sysfs 和日志:
- ce_count/ue_count 递增。
- dmesg 输出错误详情(如 CPU_SrcID#0_Channel#1_DIMM#0)。
故障确认及定位故障内存槽位
grep "[0-9]" /sys/devices/system/edac/mc/mc*/csrow*/ch*_ce_count
传统系统(如Intel Nehalem/Sandy Bridge等)每个物理内存插槽(DIMM)对应一个 csrow。例如:csrow0 对应第一个内存插槽,csrow1 对应第二个内存插槽,依此类推。
- count:不为0的行即代表存在内存错误。
- mc: 内存控制器
- csrow:内存控制器的物理内存插槽(CSROW,Channel Select ROW)
- ch*:通道内的第几根内存。
现代Intel系统(Skylake及以后)的csrow是逻辑概念,需通过dimm*目录或dmidecode确认实际插槽:
cat /sys/devices/system/edac/mc/mc0/dimm*/dimm_label
或
dmidecode -t memory
案例:某客户上报内存发生CE错误,丢给我们如下的截图,那我们要怎么定位到内存槽位呢?
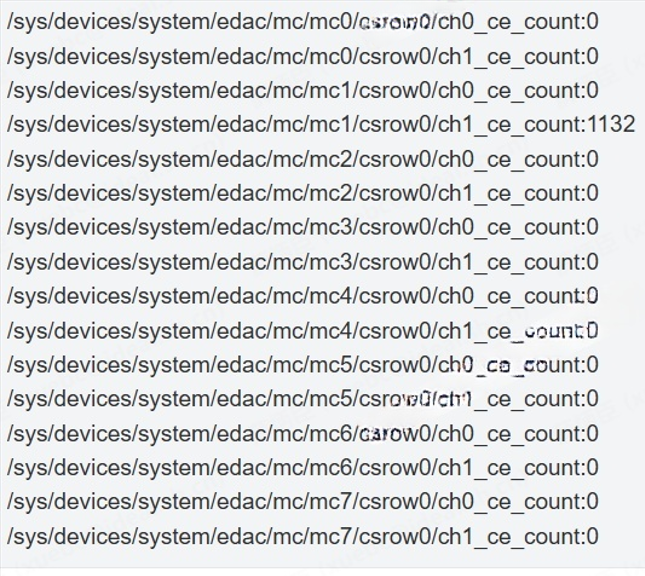
可以看出在第四根内存上发生了CE错误,检查服务器2C&16的插法如下

结合上面的结果 ,第四根内存槽位是P1-DIMMB2(注:不同的机型,会有不同的结果,需要结合产品手册来看)。
验证上面的结果,我们更换前检查一下内存槽位及内存SN,命令如下
dmidecode -t memory | grep -P 'Serial Number:\s*(?!NO DIMM$)[A-Z0-9]+' -B 10 -A 10
另外在/sys/devices/system/edac/mc/mc0/csrow*/下面还要如下几个文件,也可以助力你查询内存问题

检查UE计数:
cat /sys/devices/system/edac/mc/mc*/csrow*/ue_count
总结
csrow 不直接对应物理插槽:现代Intel系统中需结合 dimm_label 或 dmidecode。
通道编号规则:
MC0#Channel#0 → A1
MC0#Channel#1 → A2
MC1#Channel#0 → B1
MC1#Channel#1 → B2
EDAC日志格式:CPU_SrcID#X_Channel#Y_DIMM#Z 明确指向具体插槽。
使用edac工具来检测服务器内存故障
在linux中提供了一个edac-utils 内存纠错诊断工具,也可以用来检查服务器内存潜在的故障。
1.安装 edac-utils 工具
yum install -y libsysfs edac-utils
2.执行检测命令,可查看纠错提示如下

其中
- mc X表示 表示内存控制器0;
- CPU_Src_ID#0 表示CPU;
- Channel#0 表示通道0;
- DIMM#0 标示内存槽0;
- Corrected Errors 代表已经纠错的次数
注:判断方法和上面一样

 浙公网安备 33010602011771号
浙公网安备 33010602011771号