第三次作业
------------恢复内容开始------------
(一)熟悉常用的Linux操作
请按要求上机实践如下linux基本命令。
cd命令:切换目录
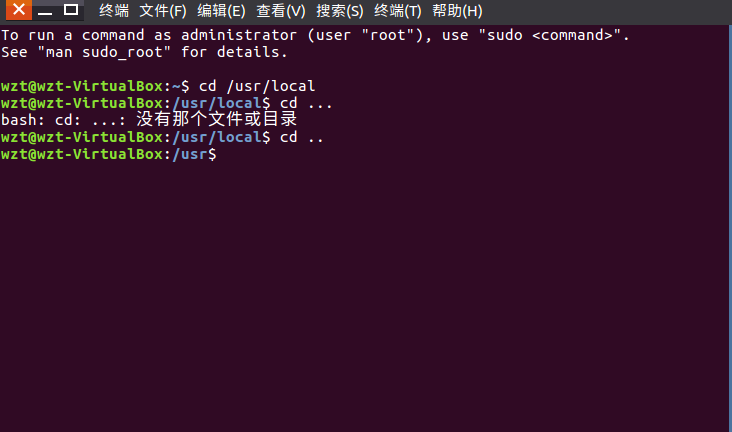
(1)切换到目录 /usr/local
(2)去到目前的上层目录
(3)回到自己的主文件夹
ls命令:查看文件与目录
(4)查看目录/usr下所有的文件

mkdir命令:新建新目录
(5)进入/tmp目录,创建一个名为a的目录,并查看有多少目录存在
(6)创建目录a1/a2/a3/a4
rmdir命令:删除空的目录
(7)将上例创建的目录a(/tmp下面)删除
(8)删除目录a1/a2/a3/a4,查看有多少目录存在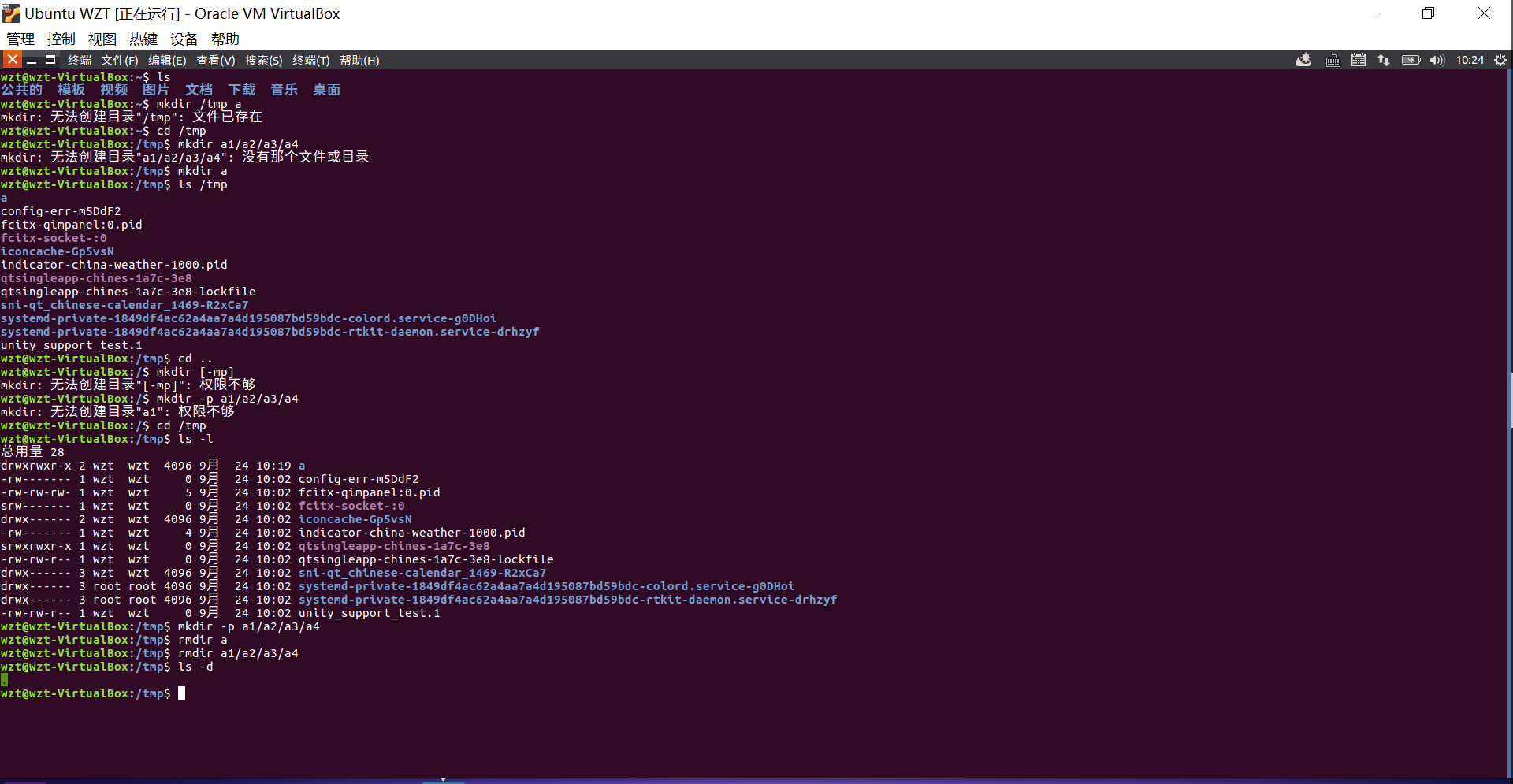
cp命令:复制文件或目录
(9)将主文件夹下的.bashrc复制到/usr下,命名为bashrc1
(10)在/tmp下新建目录test,再复制这个目录内容到/usr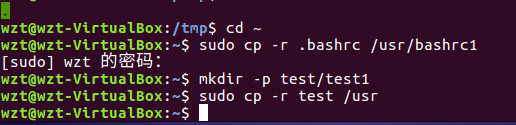
mv命令:移动文件与目录,或更名
(11)将上例文件bashrc1移动到目录/usr/test
(12)将上例test目录重命名为test2
rm命令:移除文件或目录
(13)将上例复制的bashrc1文件删除
(14)将上例的test2目录删除
cat命令:查看文件内容
(15)查看主文件夹下的.bashrc文件内容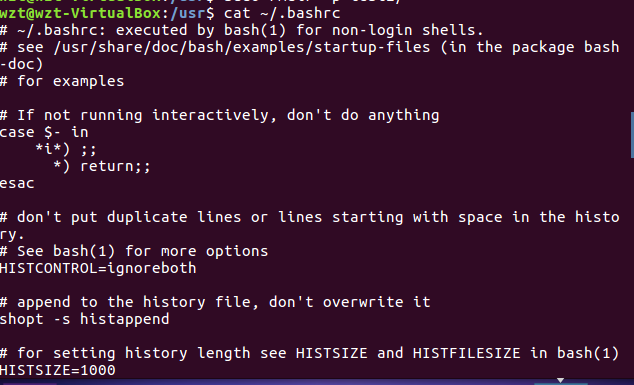
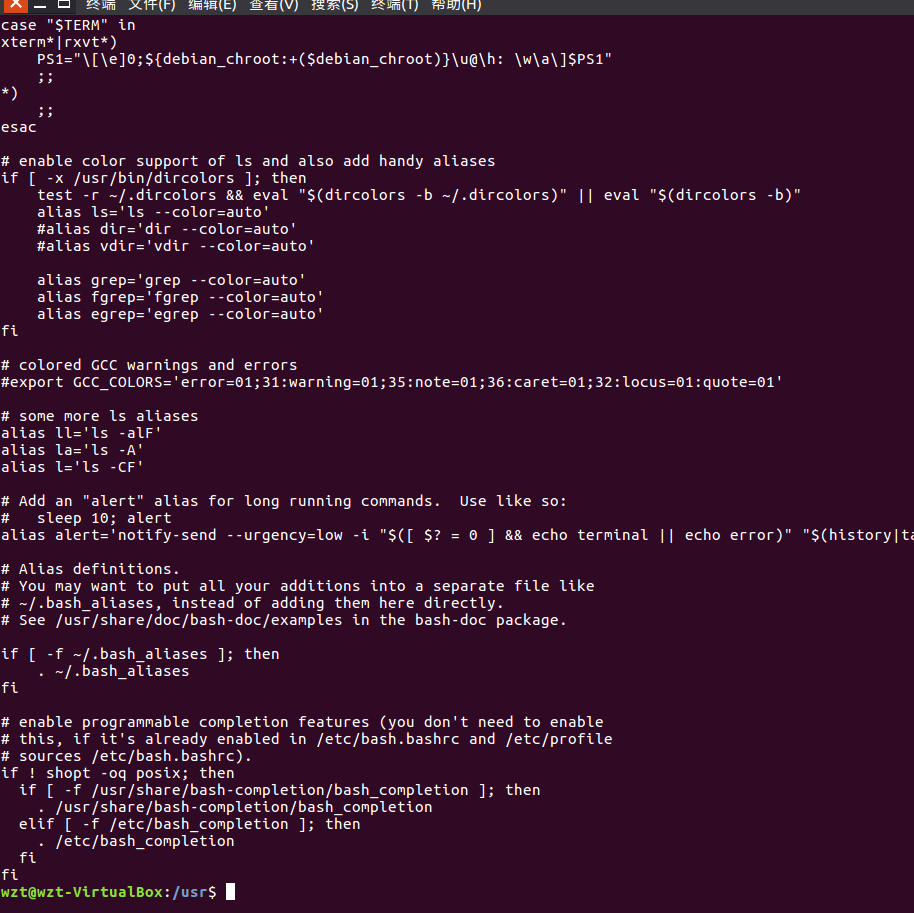
tac命令:反向列示
(16)反向查看主文件夹下.bashrc文件内容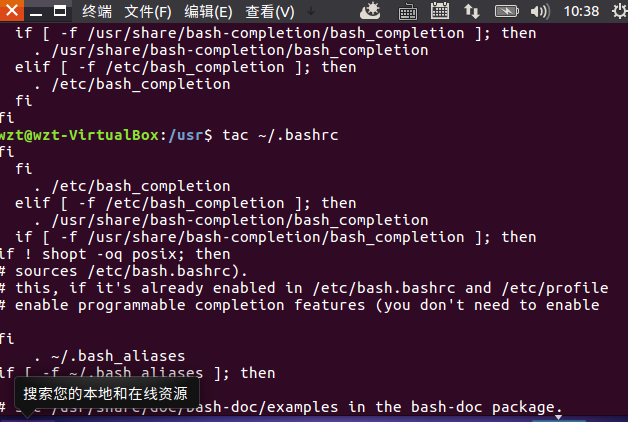
more命令:一页一页翻动查看
(17)翻页查看主文件夹下.bashrc文件内容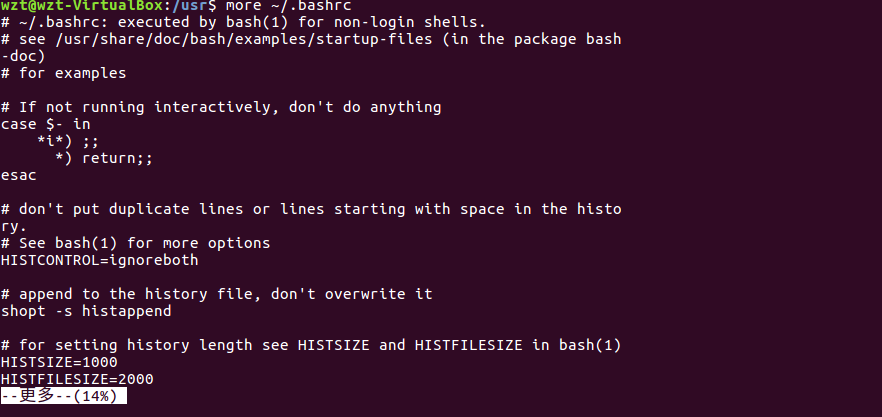
head命令:取出前面几行
(18)查看主文件夹下.bashrc文件内容前20行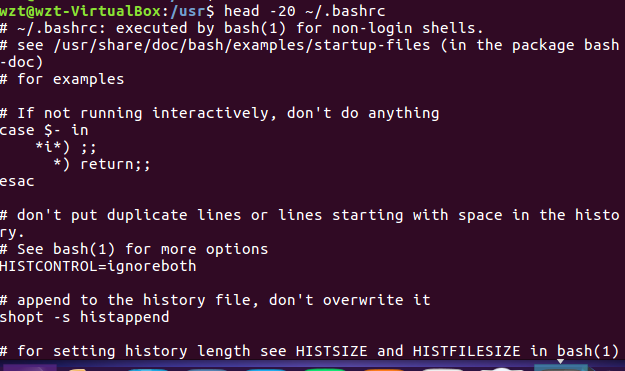
(19)查看主文件夹下.bashrc文件内容,后面50行不显示,只显示前面几行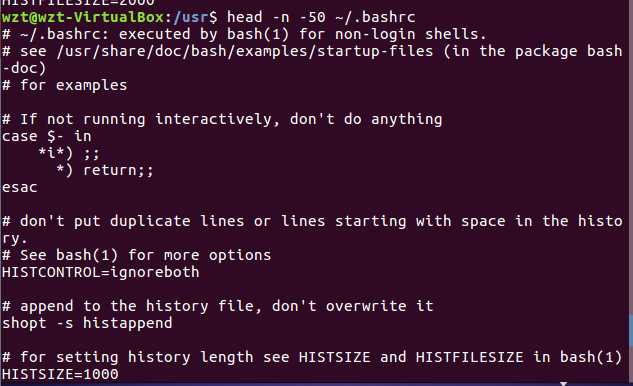
tail命令:取出后面几行
(20)查看主文件夹下.bashrc文件内容最后20行
(21)查看主文件夹下.bashrc文件内容,只列出50行以后的数据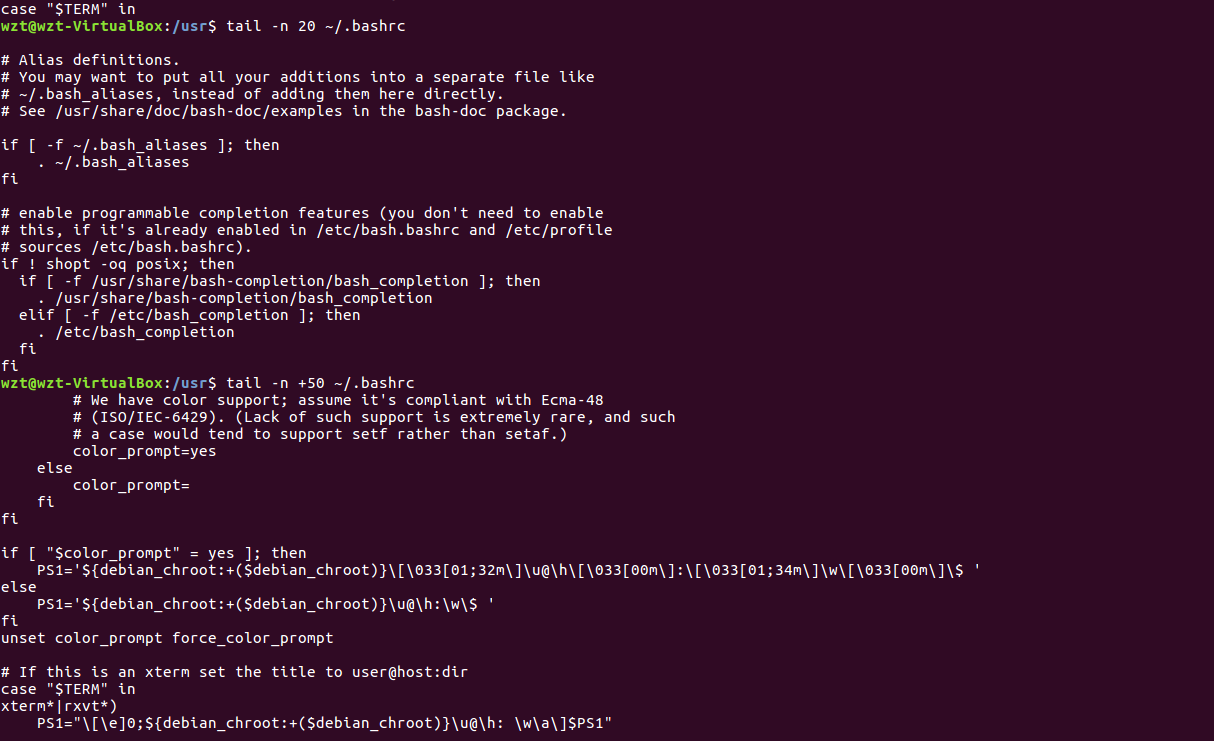
chown命令:修改文件所有者权限
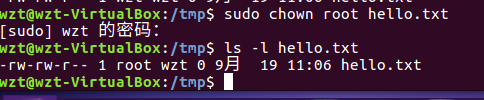
(22)将hello文件所有者改为root帐号,并查看属性
Vim/gedit/文本编辑器:新建文件
(23)在主文件夹下创建文本文件my.txt,输入文本保存退出。
tar命令:压缩命令
(24)将my.txt打包成test.tar.gz

(25)解压缩到~/tmp目录

(二)熟悉使用MySQL shell操作
(26)显示库:show databases;
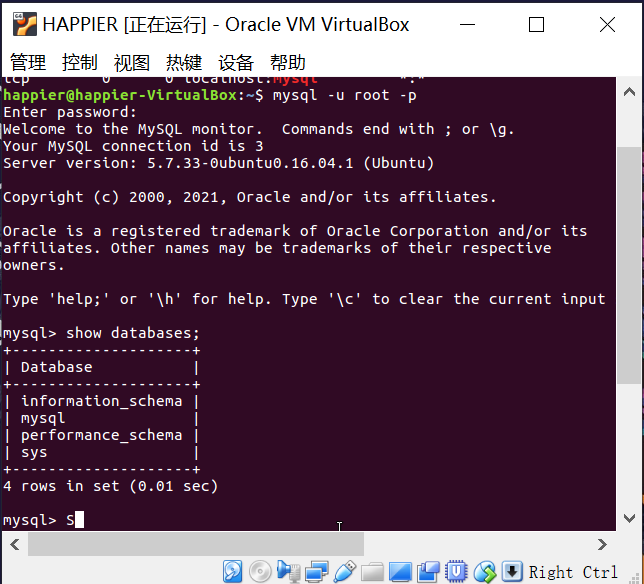
(27)进入到库:use 库名;
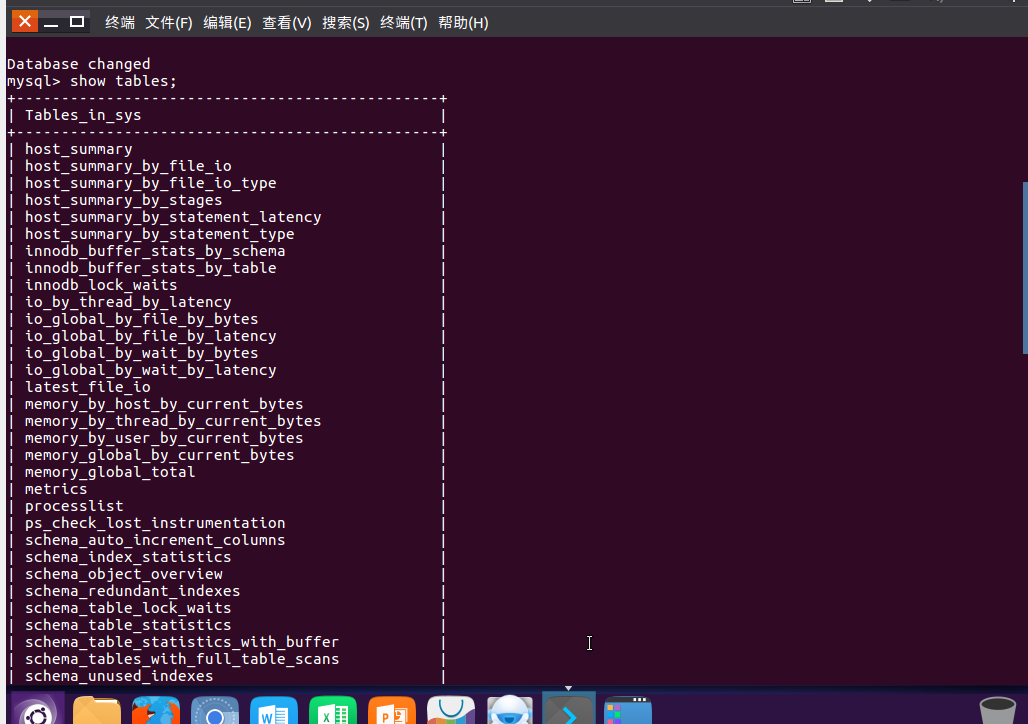
(28)展示库里表格:show tables;
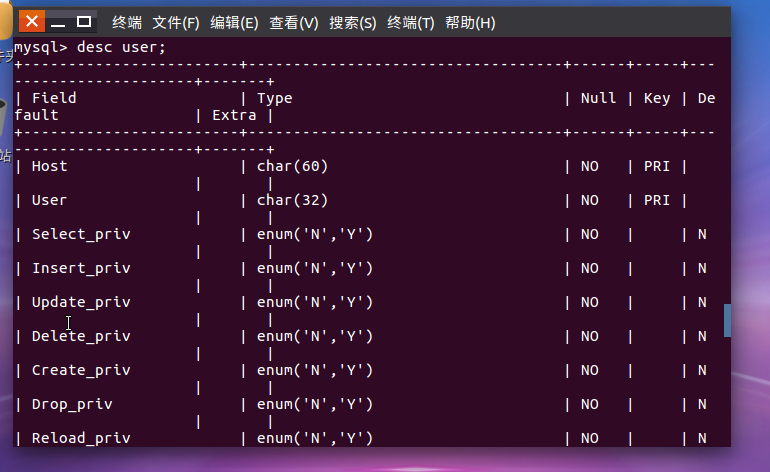
(29)显示某一个表格属性:desc 表格名;
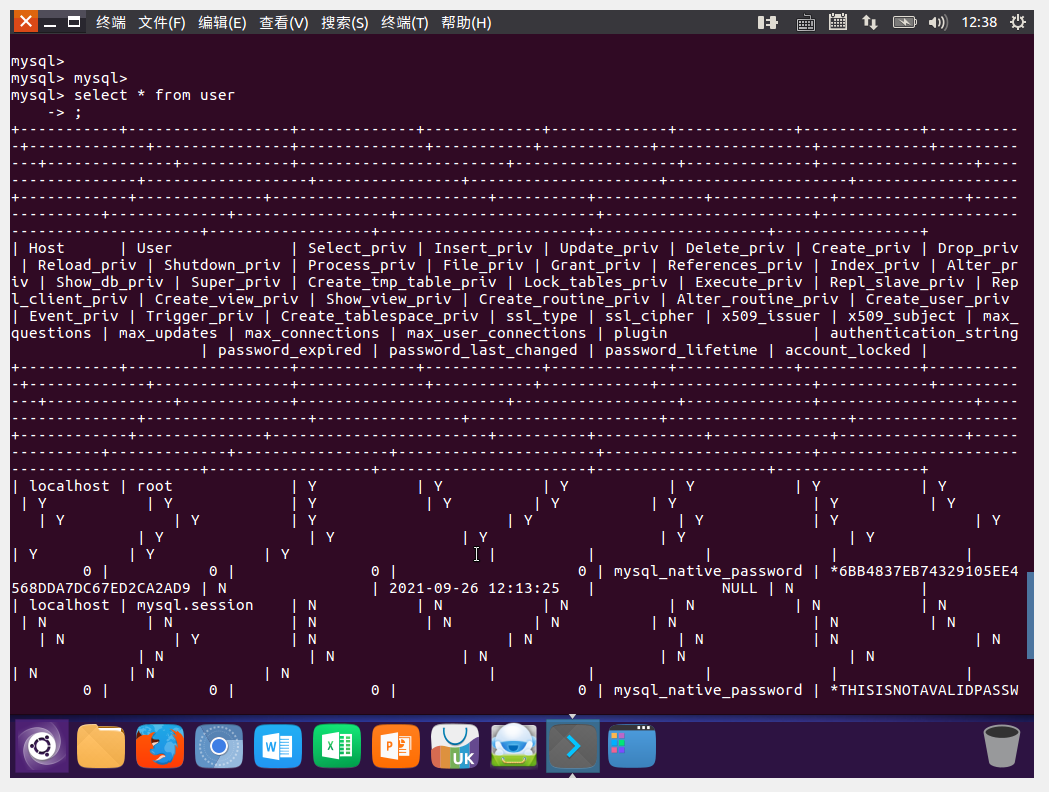
(30)显示某一个表格内的具体内容:select *form 表格名;
(31)创建一个数据库:create databases sc;
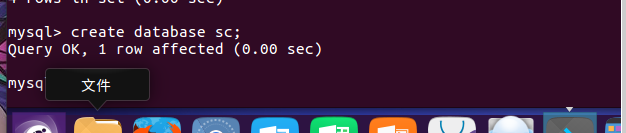
(32)在sc中创建一个表格:create table if not exists student( );
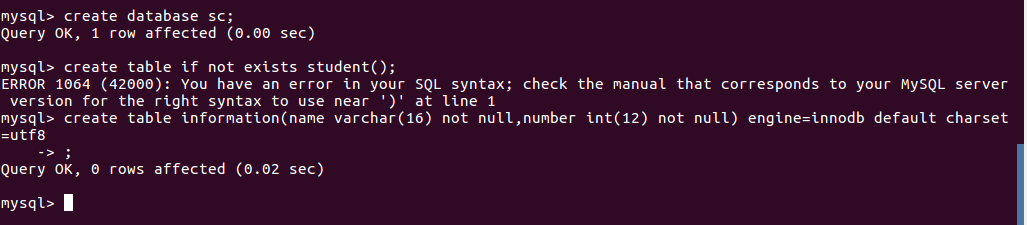
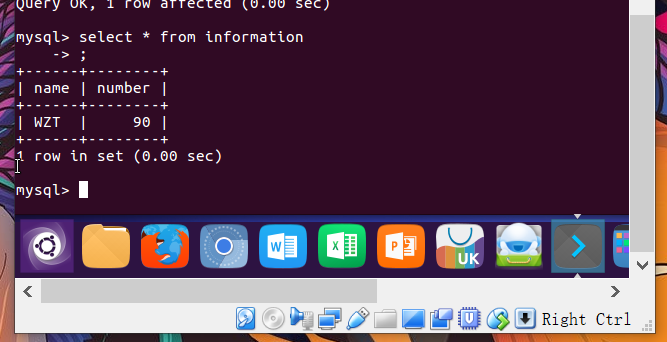
(33)向表格student中插入具体内容:insert into 表格名(名)values(value);
插入记录包含自己的学号姓名。

(33)显示表的内容。
(三)熟悉Hadoop及其操作
1.用图文与自己的话,简要描述Hadoop起源与发展阶段。
2.对比操作三个文件系统:分别用命令行与窗口方式查看windows,Linux和Hadoop的文件系统的用户主目录。
1、什么是Hadoop?
(1)Hadoop是一个开源的框架,可编写和运行分布式应用处理大规模数据,是专为离线和大规模数据分析而设计的,并不适合那种对几个记录随机读写的在线事务处理模式。Hadoop=HDFS(文件系统,数据存储技术相关)+ Mapreduce(数据处理),Hadoop的数据来源可以是任何形式,在处理半结构化和非结构化数据上与关系型数据库相比有更好的性能,具有更灵活的处理能力。
2.对比操作三个文件系统:分别用命令行与窗口方式查看windows,Linux和Hadoop的文件系统的用户主目录。
window系统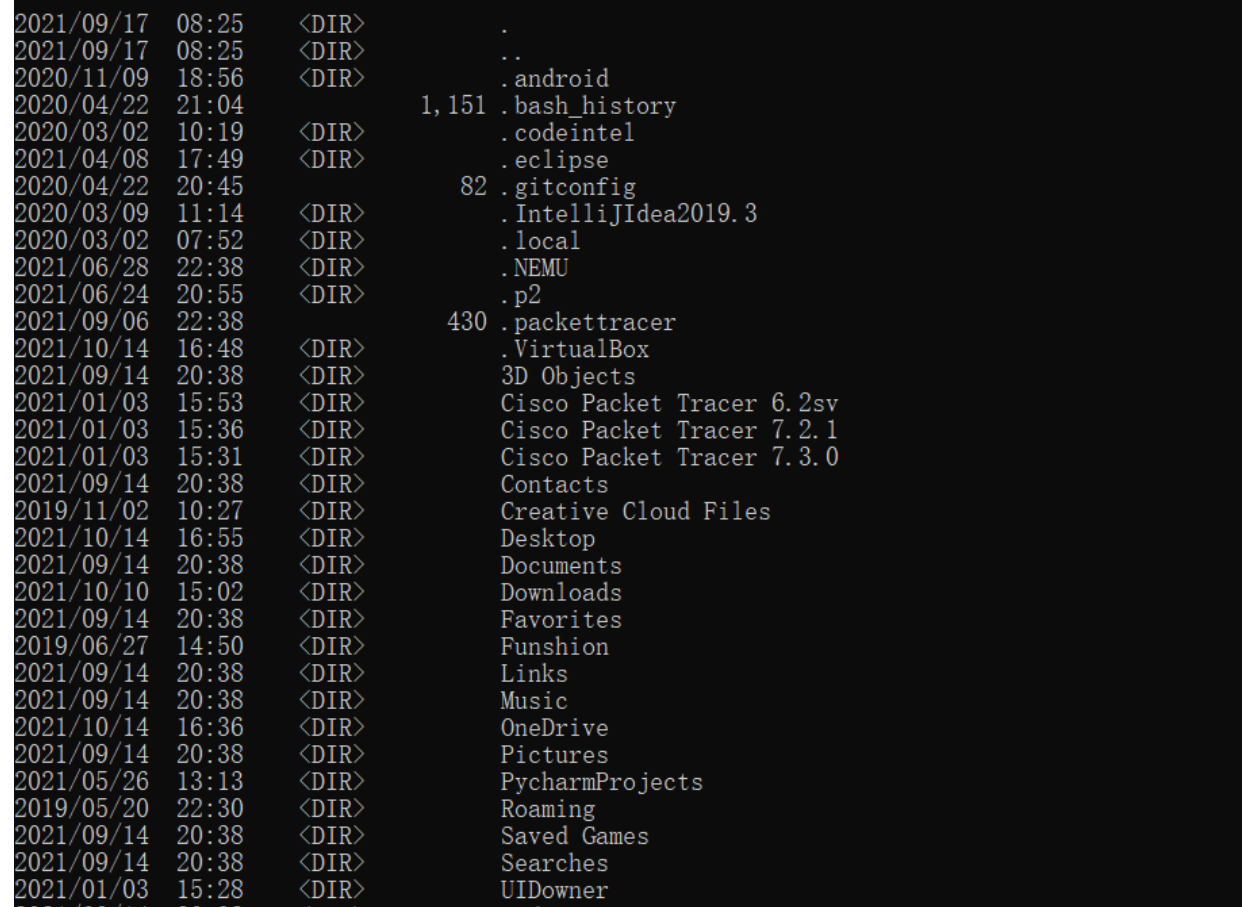
Linux系统

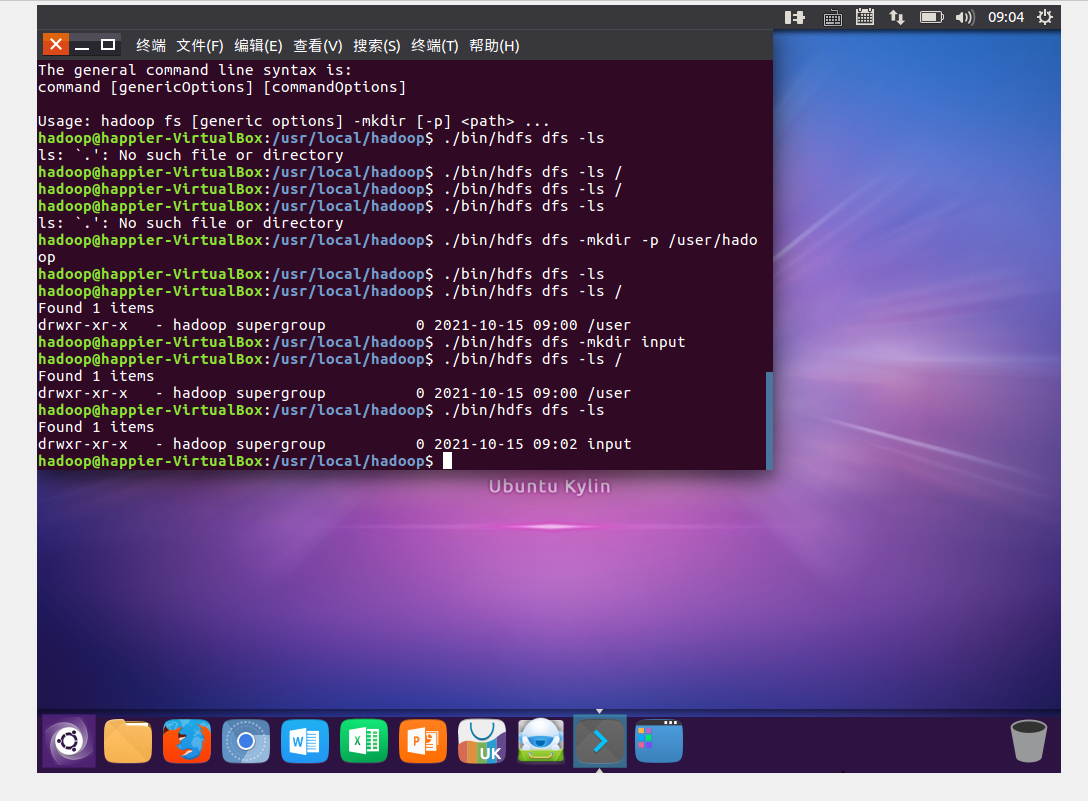
36.一个操作案例:
- 启动hdfs
- 查看与创建hadoop用户目录。
- 在用户目录下创建与查看input目录。
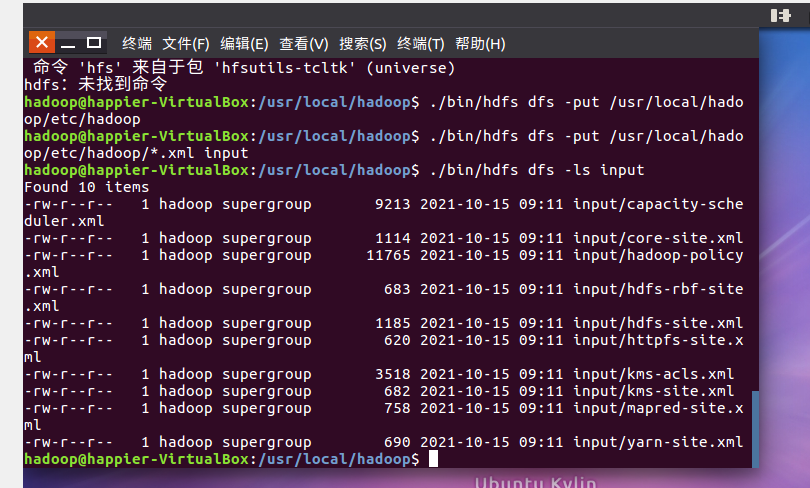
- 将hadoop的配置文件上传到hdfs上的input目录下。
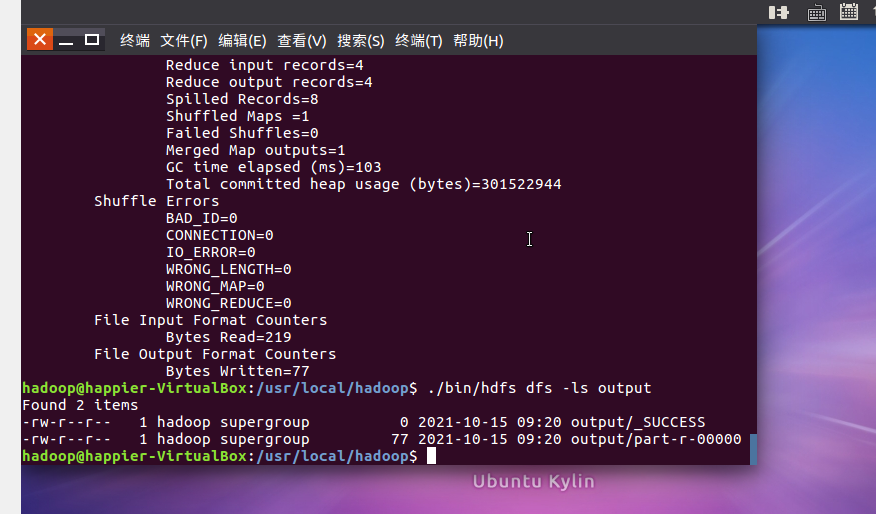
- 运行MapReduce示例作业,输出结果放在output目录下。
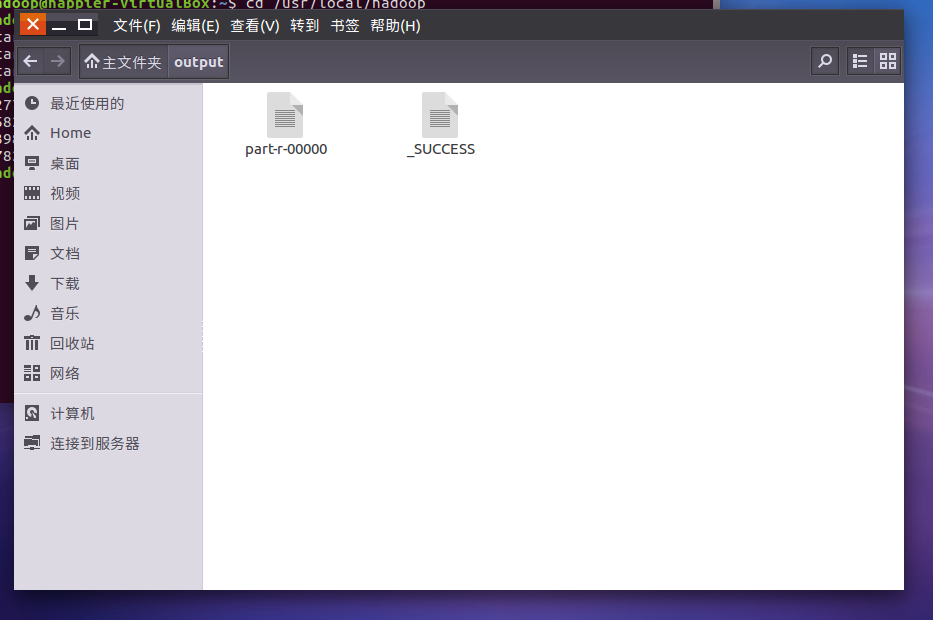
- 查看output目录下的文件。
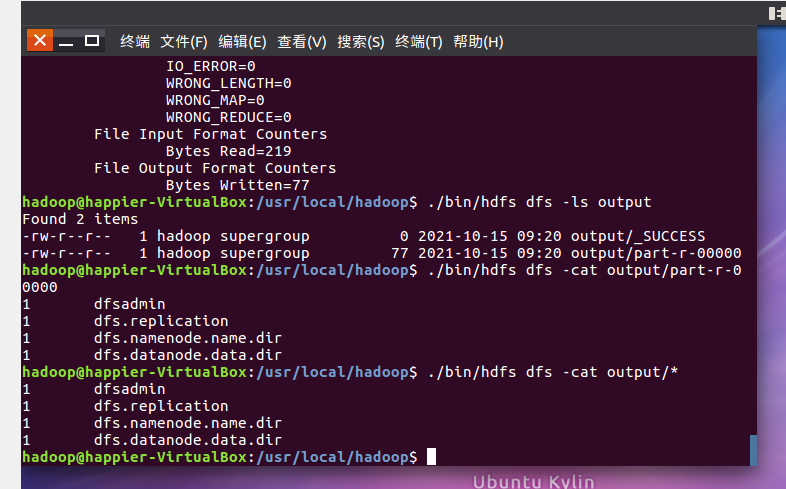
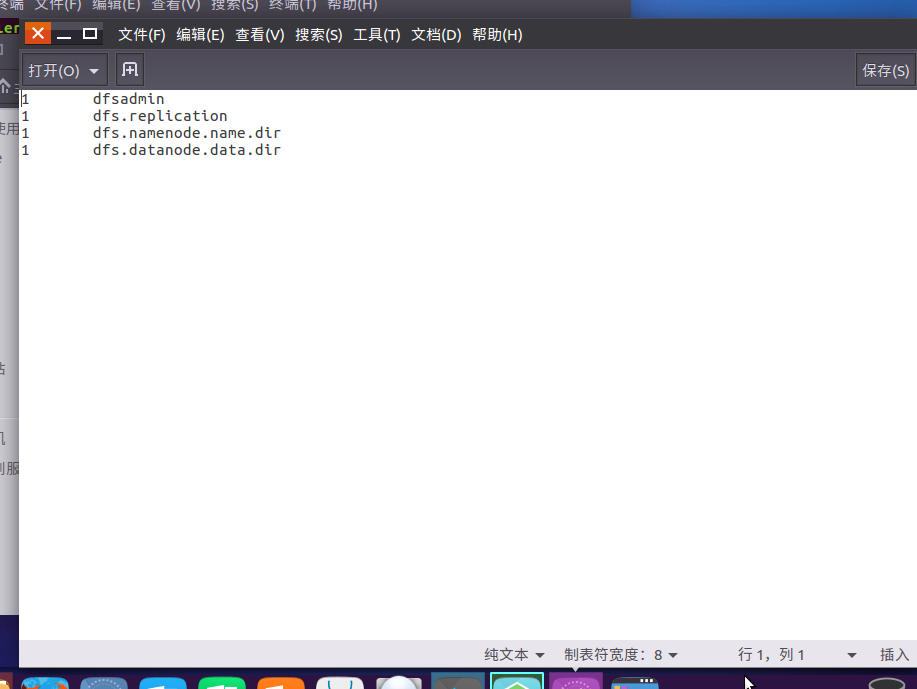
- 查看输出结果
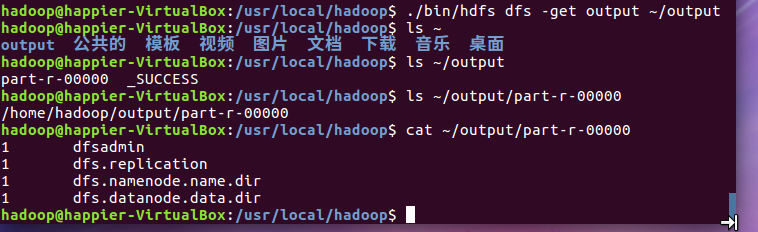
- 将输出结果文件下载到本地。
- 查看下载的本地文件。
- 停止hdfs
![]()
![]()
![]()
![]()
![]()
将输出结果文件下载到本地。
![]()
查看下载的本地文件。
![]()
37.设置Hadoop环境变量,在本地用户主目录下启动hdfs,查看hdfs用户主目录,停止hdfs。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号