

spark源码之Shuffle Write
一、shuffle定义
shuffle,即为洗牌的意思,在大数据计算中,无论是mapreduce框架还是spark框架,都需要shuffle,那是因为在计算的过程中,具有某种特征的数据最终需要汇聚在一个节点上进行计算,这些数据是分部在集群中不同的节点上由各自节点进行计算。就比如以workcount为例:
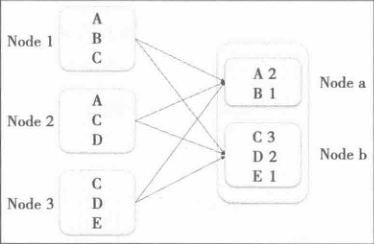
其中数据是分别保存在节点Node1,Node2,Node3上,经过处理之后,数据最终会汇聚到结点Node a和Node b上进行处理。
而这个数据重新打乱然后重新汇聚到不同节点的过程就是shuffle,但是实际情况下,shuffle的要比这个复杂的多。
- 数据量会很大,比如单位为TB或PB的数据分散在几百甚至数千、数万台机器上。
- 为了将这些数据汇聚到正确的节点,需要将这些数据放到正确的partition,因为数据大小已经大于节点的内存,因此这个过程可能会发生多次的硬盘的续写。
- 为了节省带宽,这个数据可能需要压缩,如何在压缩率与压缩解压时间中间做一个较好的平衡,是需要我们考虑的。
- 数据需要通过网络传输,所以数据的序列化与反序列化也变得相对复杂。
一般情况下,每个task处理的数据是可以完全载入内存当中的(如果说不能的话,可以减小partition的大小),所以task可以做到内存中计算,除非非常复杂的计算逻辑,否则,如果为了容错而持久化中间数据,是没有太大的收益的。毕竟中间的某个过程失败了的话,是可以重头进行计算的。但是,对于shuffle来说的话,持久化中间结果是有必要的,因为一旦数据丢失,就需要重新计算依赖的所有的RDD,这个代价是很大的。
所以,对于shuffle理解以及优化,就显得非常的重要,下面会从源码进行解读shuffle的过程。
二、Sort Based Shuffle Write
在spark1.0之前,spark只支持Hash Based Shuffle Write,因为在很多运算场景下,是不需要排序的,多余的排序只能使得性能变差。比如mapReduce就是这么实现的,也就是说reduce拿到的数据是经过排序的,对于spark的实现很简单:每个shuffle map task 根据key进行hash,计算出每个key需要写入的partition,然后将数据写入到一个单独的文件中,而这个partition就是对应的下游的一个shuffle map task 或者是shuffle result task,因此,下游task在计算的时候会通过网络来获取这个文件的数据(如果该task与上游的shuffle map task在同一个节点上的话,那么此时就是一个本地磁盘的读取操作)。
在spark1.2中,spark core 的一个重要升级就是Hash Based shuffle 换成了Sorted Based shuffle,即从spark.shuffle.Manager从Hash换成Sort,对应实现类分别是:org.apache.spark.shuffle.hash.HashShuffleManager和org.apache.spark.shuffle.sort.SortShuffleManager.而具体选择哪种方式,是在org.apache.spark.Env中进行选择的。
// Let the user specify short names for shuffle managers
val shortShuffleMgrNames = Map(
"hash" -> "org.apache.spark.shuffle.sort.SortShuffleManager",
"sort" -> "org.apache.spark.shuffle.sort.SortShuffleManager")
val shuffleMgrName = conf.get("spark.shuffle.manager", "sort")
val shuffleMgrClass =
shortShuffleMgrNames.getOrElse(shuffleMgrName.toLowerCase(Locale.ROOT), shuffleMgrName)
val shuffleManager = instantiateClass[ShuffleManager](shuffleMgrClass)
在spark1.6之后,已经将org.apache.spark.shuffle.sort.SortShuffleManager改为默认的实现,已经取消了HashShuffleManager:
// Let the user specify short names for shuffle managers
val shortShuffleMgrNames = Map(
"sort" -> classOf[org.apache.spark.shuffle.sort.SortShuffleManager].getName,
"tungsten-sort" -> classOf[org.apache.spark.shuffle.sort.SortShuffleManager].getName)
val shuffleMgrName = conf.get("spark.shuffle.manager", "sort")
val shuffleMgrClass =
shortShuffleMgrNames.getOrElse(shuffleMgrName.toLowerCase(Locale.ROOT), shuffleMgrName)
val shuffleManager = instantiateClass[ShuffleManager](shuffleMgrClass)
2.1 Sort Based Shuffle & Hash Based Shuffle
Hash Based Shuffle 的每个mapper都需要为每一个Reduce写一个文件,以供reduce读取,也就是说要差生M*R个文件,如果说map和reduce数量比较多的话,则产生的文件数会非常的多。Hash Based Shuffle设计目标之一就是避免不必要的排序(MapReduce被人诟病的一点就是,很多不需要排序的地方进行了排序导致损失了大量的性能),但是在处理大规模的数据集的时候,产生了大量的磁盘IO和内存消耗,这也无疑非常的影响性能,在spark0.8的时候引入了File Consolidation在一定程度上解决了文件map产生文件数目过多的问题。为了更好的解决这个问题,在spark1.1引入了Sort Based Shuffle。这种情况下,每个shuffle map task不会为每个reduce生成一个单独的文件,相反,它会将所有的结果写入到一个文件中,同时会生成一个Index文件,Reducer可以通过这个Index文件来获取它所需要的数据。避免产生大量文件的直接受益就是节省了内存的使用和顺序磁盘IO带来的低延时的性能问题,节省内存的使用可以减少GC的风险和频率,而减少文件数量可以避免同时给多个文件写数据大给系统带来的压力。
2.2 Basic shuffle write
在executor上执行shuffle map task 的时候,最终它调用的org.apache.spark.scheduler.ShuffleMapTask#runTask方法:
override def runTask(context: TaskContext): MapStatus = {
// Deserialize the RDD using the broadcast variable.
val threadMXBean = ManagementFactory.getThreadMXBean
val deserializeStartTime = System.currentTimeMillis()
val deserializeStartCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime
} else 0L
val ser = SparkEnv.get.closureSerializer.newInstance()
val (rdd, dep) = ser.deserialize[(RDD[_], ShuffleDependency[_, _, _])](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
_executorDeserializeTime = System.currentTimeMillis() - deserializeStartTime
_executorDeserializeCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime - deserializeStartCpuTime
} else 0L
var writer: ShuffleWriter[Any, Any] = null
try {
val manager = SparkEnv.get.shuffleManager
writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
writer.stop(success = true).get
} catch {
case e: Exception =>
try {
if (writer != null) {
writer.stop(success = false)
}
} catch {
case e: Exception =>
log.debug("Could not stop writer", e)
}
throw e
}
}
核心逻辑是:
val manager = SparkEnv.get.shuffleManager writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context) writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]]) writer.stop(success = true).get
简单总结如下:
- 先从sparkEnv中获取shuffleManager,spark除了支持Hash和Sort Based Shuffle之外,还支持external Shuffle Service。可以通过实现几个类进行自定义shuffle。
- 从shuffleManager 当中获取Writer。这里获取到的是org.apache.spark.shuffle.sort.SortShuffleWriter
/** Get a writer for a given partition. Called on executors by map tasks. */
override def getWriter[K, V](
handle: ShuffleHandle,
mapId: Int,
context: TaskContext): ShuffleWriter[K, V] = {
numMapsForShuffle.putIfAbsent(
handle.shuffleId, handle.asInstanceOf[BaseShuffleHandle[_, _, _]].numMaps)
val env = SparkEnv.get
handle match {
case unsafeShuffleHandle: SerializedShuffleHandle[K @unchecked, V @unchecked] =>
new UnsafeShuffleWriter(
env.blockManager,
shuffleBlockResolver.asInstanceOf[IndexShuffleBlockResolver],
context.taskMemoryManager(),
unsafeShuffleHandle,
mapId,
context,
env.conf)
case bypassMergeSortHandle: BypassMergeSortShuffleHandle[K @unchecked, V @unchecked] =>
new BypassMergeSortShuffleWriter(
env.blockManager,
shuffleBlockResolver.asInstanceOf[IndexShuffleBlockResolver],
bypassMergeSortHandle,
mapId,
context,
env.conf)
case other: BaseShuffleHandle[K @unchecked, V @unchecked, _] =>
new SortShuffleWriter(shuffleBlockResolver, other, mapId, context)
}
package org.apache.spark.shuffle.sort
private[spark] class SortShuffleWriter[K, V, C](
shuffleBlockResolver: IndexShuffleBlockResolver,
handle: BaseShuffleHandle[K, V, C],
mapId: Int,
context: TaskContext)
extends ShuffleWriter[K, V] with Logging {
... //省略部分代码
/** Write a bunch of records to this task's output */
override def write(records: Iterator[Product2[K, V]]): Unit = {
sorter = if (dep.mapSideCombine) {
require(dep.aggregator.isDefined, "Map-side combine without Aggregator specified!")
new ExternalSorter[K, V, C](
context, dep.aggregator, Some(dep.partitioner), dep.keyOrdering, dep.serializer)
} else {
// In this case we pass neither an aggregator nor an ordering to the sorter, because we don't
// care whether the keys get sorted in each partition; that will be done on the reduce side
// if the operation being run is sortByKey.
new ExternalSorter[K, V, V](
context, aggregator = None, Some(dep.partitioner), ordering = None, dep.serializer)
}
sorter.insertAll(records)
// Don't bother including the time to open the merged output file in the shuffle write time,
// because it just opens a single file, so is typically too fast to measure accurately
// (see SPARK-3570).
val output = shuffleBlockResolver.getDataFile(dep.shuffleId, mapId)
val tmp = Utils.tempFileWith(output)
try {
val blockId = ShuffleBlockId(dep.shuffleId, mapId, IndexShuffleBlockResolver.NOOP_REDUCE_ID)
val partitionLengths = sorter.writePartitionedFile(blockId, tmp)
shuffleBlockResolver.writeIndexFileAndCommit(dep.shuffleId, mapId, partitionLengths, tmp)
mapStatus = MapStatus(blockManager.shuffleServerId, partitionLengths)
} finally {
if (tmp.exists() && !tmp.delete()) {
logError(s"Error while deleting temp file ${tmp.getAbsolutePath}")
}
}
}
}
- 调用RDD进行计算,运算结果通过Writer进行持久化。具体的持久化逻辑如上代码write方法,org.apache.spark.shuffle.sort.SortShuffleWriter#write中
- 先通过org.apche.spark.shuffleDependency进行判断是否需要map端的聚合操作(dep.mapSideCombine)
- 如果需要聚合,则再次判断是否定义了org.apache.spark.Aggregator,如果为定义,则直接抛出异常 "Map-side combine without Aggregator specified!",(require(dep.aggregator.isDefined, "Map-side combine without Aggregator specified!"))
- 将原始数据进行聚合之后,通过sorter.insertAll(records)写入
def insertAll(records: Iterator[Product2[K, V]]): Unit = {
// TODO: stop combining if we find that the reduction factor isn't high
val shouldCombine = aggregator.isDefined
if (shouldCombine) {
// Combine values in-memory first using our AppendOnlyMap
val mergeValue = aggregator.get.mergeValue
val createCombiner = aggregator.get.createCombiner
var kv: Product2[K, V] = null
val update = (hadValue: Boolean, oldValue: C) => {
if (hadValue) mergeValue(oldValue, kv._2) else createCombiner(kv._2)
}
while (records.hasNext) {
addElementsRead()
kv = records.next()
map.changeValue((getPartition(kv._1), kv._1), update)
maybeSpillCollection(usingMap = true)
}
} else {
// Stick values into our buffer
while (records.hasNext) {
addElementsRead()
val kv = records.next()
buffer.insert(getPartition(kv._1), kv._1, kv._2.asInstanceOf[C])
maybeSpillCollection(usingMap = false)
}
}
}
-
- 写入完成之后,将元数据信息写入到MapStatus中(mapStatus = MapStatus(blockManager.shuffleServerId, partitionLengths))
2.3 Shuffle Map Task 运算结果的处理
Shuffle Map Task运算结果分为两部分。一部分是在executor端处理Task的结果的,另一部分是在Driver端接收到Task运行结束的消息之后,对Shuffle Write的结果进行处理,从而在调度下游的Task时,使其可以得到所需要的数据。
2.3.1 Executor端的处理
上面介绍Basic Shuffle Writer的时候,介绍到,Shuffle Map Task在Executor上运行时,最终会调用org.apache.spark.scheduler.ShuffleMapTask#runTask。
那么这个这个结果最终是如何处理的呢?下游的Task是如何获取这些数据的呢?这个还是要从Task如何开始执行谈起:
Worker上接收到Task执行命令的是:org.apache.spark.executor.CoarseGrainedExecutorBackend,它在接受到LaunchTask的命令之后,通过在Driver端创建SparkContext的时候创建的org.apache.spark.executor.Executor实例的lanuchTask来启动Task:
package org.apache.spark.executor
override def receive: PartialFunction[Any, Unit] = {
case RegisteredExecutor =>
logInfo("Successfully registered with driver")
try {
executor = new Executor(executorId, hostname, env, userClassPath, isLocal = false)
} catch {
case NonFatal(e) =>
exitExecutor(1, "Unable to create executor due to " + e.getMessage, e)
}
case RegisterExecutorFailed(message) =>
exitExecutor(1, "Slave registration failed: " + message)
case LaunchTask(data) => // 接收到LaunchTask命令
if (executor == null) {
exitExecutor(1, "Received LaunchTask command but executor was null")
} else {
val taskDesc = TaskDescription.decode(data.value)
logInfo("Got assigned task " + taskDesc.taskId)
executor.launchTask(this, taskDesc)
}
case KillTask(taskId, _, interruptThread, reason) =>
if (executor == null) {
exitExecutor(1, "Received KillTask command but executor was null")
} else {
executor.killTask(taskId, interruptThread, reason)
}
case StopExecutor =>
stopping.set(true)
logInfo("Driver commanded a shutdown")
// Cannot shutdown here because an ack may need to be sent back to the caller. So send
// a message to self to actually do the shutdown.
self.send(Shutdown)
case Shutdown =>
stopping.set(true)
new Thread("CoarseGrainedExecutorBackend-stop-executor") {
override def run(): Unit = {
// executor.stop() will call `SparkEnv.stop()` which waits until RpcEnv stops totally.
// However, if `executor.stop()` runs in some thread of RpcEnv, RpcEnv won't be able to
// stop until `executor.stop()` returns, which becomes a dead-lock (See SPARK-14180).
// Therefore, we put this line in a new thread.
executor.stop()
}
}.start()
}
// 启动 Task
package org.apache.spark.executor
def launchTask(context: ExecutorBackend, taskDescription: TaskDescription): Unit = {
val tr = new TaskRunner(context, taskDescription)
runningTasks.put(taskDescription.taskId, tr)
threadPool.execute(tr)
}
最终Task的执行是在org.apache.spark.executor#TaskRunner
package org.apache.spark.executor
class TaskRunner(
execBackend: ExecutorBackend,
private val taskDescription: TaskDescription)
extends Runnable {
val taskId = taskDescription.taskId
val threadName = s"Executor task launch worker for task $taskId"
private val taskName = taskDescription.name
/** If specified, this task has been killed and this option contains the reason. */
@volatile private var reasonIfKilled: Option[String] = None
@volatile private var threadId: Long = -1
def getThreadId: Long = threadId
/** Whether this task has been finished. */
@GuardedBy("TaskRunner.this")
private var finished = false
def isFinished: Boolean = synchronized { finished }
/** How much the JVM process has spent in GC when the task starts to run. */
@volatile var startGCTime: Long = _
/**
* The task to run. This will be set in run() by deserializing the task binary coming
* from the driver. Once it is set, it will never be changed.
*/
@volatile var task: Task[Any] = _
def kill(interruptThread: Boolean, reason: String): Unit = {
logInfo(s"Executor is trying to kill $taskName (TID $taskId), reason: $reason")
reasonIfKilled = Some(reason)
if (task != null) {
synchronized {
if (!finished) {
task.kill(interruptThread, reason)
}
}
}
}
/**
* Set the finished flag to true and clear the current thread's interrupt status
*/
private def setTaskFinishedAndClearInterruptStatus(): Unit = synchronized {
this.finished = true
// SPARK-14234 - Reset the interrupted status of the thread to avoid the
// ClosedByInterruptException during execBackend.statusUpdate which causes
// Executor to crash
Thread.interrupted()
// Notify any waiting TaskReapers. Generally there will only be one reaper per task but there
// is a rare corner-case where one task can have two reapers in case cancel(interrupt=False)
// is followed by cancel(interrupt=True). Thus we use notifyAll() to avoid a lost wakeup:
notifyAll()
}
override def run(): Unit = {
threadId = Thread.currentThread.getId
Thread.currentThread.setName(threadName)
val threadMXBean = ManagementFactory.getThreadMXBean
val taskMemoryManager = new TaskMemoryManager(env.memoryManager, taskId)
val deserializeStartTime = System.currentTimeMillis()
val deserializeStartCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime
} else 0L
Thread.currentThread.setContextClassLoader(replClassLoader)
val ser = env.closureSerializer.newInstance()
logInfo(s"Running $taskName (TID $taskId)")
execBackend.statusUpdate(taskId, TaskState.RUNNING, EMPTY_BYTE_BUFFER)
var taskStart: Long = 0
var taskStartCpu: Long = 0
startGCTime = computeTotalGcTime()
try {
// Must be set before updateDependencies() is called, in case fetching dependencies
// requires access to properties contained within (e.g. for access control).
Executor.taskDeserializationProps.set(taskDescription.properties)
updateDependencies(taskDescription.addedFiles, taskDescription.addedJars)
task = ser.deserialize[Task[Any]](
taskDescription.serializedTask, Thread.currentThread.getContextClassLoader)
task.localProperties = taskDescription.properties
task.setTaskMemoryManager(taskMemoryManager)
// If this task has been killed before we deserialized it, let's quit now. Otherwise,
// continue executing the task.
val killReason = reasonIfKilled
if (killReason.isDefined) {
// Throw an exception rather than returning, because returning within a try{} block
// causes a NonLocalReturnControl exception to be thrown. The NonLocalReturnControl
// exception will be caught by the catch block, leading to an incorrect ExceptionFailure
// for the task.
throw new TaskKilledException(killReason.get)
}
logDebug("Task " + taskId + "'s epoch is " + task.epoch)
env.mapOutputTracker.updateEpoch(task.epoch)
// Run the actual task and measure its runtime.
taskStart = System.currentTimeMillis()
taskStartCpu = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime
} else 0L
var threwException = true
val value = try {
val res = task.run(
taskAttemptId = taskId,
attemptNumber = taskDescription.attemptNumber,
metricsSystem = env.metricsSystem)
threwException = false
res
} finally {
val releasedLocks = env.blockManager.releaseAllLocksForTask(taskId)
val freedMemory = taskMemoryManager.cleanUpAllAllocatedMemory()
if (freedMemory > 0 && !threwException) {
val errMsg = s"Managed memory leak detected; size = $freedMemory bytes, TID = $taskId"
if (conf.getBoolean("spark.unsafe.exceptionOnMemoryLeak", false)) {
throw new SparkException(errMsg)
} else {
logWarning(errMsg)
}
}
if (releasedLocks.nonEmpty && !threwException) {
val errMsg =
s"${releasedLocks.size} block locks were not released by TID = $taskId:\n" +
releasedLocks.mkString("[", ", ", "]")
if (conf.getBoolean("spark.storage.exceptionOnPinLeak", false)) {
throw new SparkException(errMsg)
} else {
logInfo(errMsg)
}
}
}
task.context.fetchFailed.foreach { fetchFailure =>
// uh-oh. it appears the user code has caught the fetch-failure without throwing any
// other exceptions. Its *possible* this is what the user meant to do (though highly
// unlikely). So we will log an error and keep going.
logError(s"TID ${taskId} completed successfully though internally it encountered " +
s"unrecoverable fetch failures! Most likely this means user code is incorrectly " +
s"swallowing Spark's internal ${classOf[FetchFailedException]}", fetchFailure)
}
val taskFinish = System.currentTimeMillis()
val taskFinishCpu = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime
} else 0L
// If the task has been killed, let's fail it.
task.context.killTaskIfInterrupted()
val resultSer = env.serializer.newInstance()
val beforeSerialization = System.currentTimeMillis()
val valueBytes = resultSer.serialize(value)
val afterSerialization = System.currentTimeMillis()
// Deserialization happens in two parts: first, we deserialize a Task object, which
// includes the Partition. Second, Task.run() deserializes the RDD and function to be run.
task.metrics.setExecutorDeserializeTime(
(taskStart - deserializeStartTime) + task.executorDeserializeTime)
task.metrics.setExecutorDeserializeCpuTime(
(taskStartCpu - deserializeStartCpuTime) + task.executorDeserializeCpuTime)
// We need to subtract Task.run()'s deserialization time to avoid double-counting
task.metrics.setExecutorRunTime((taskFinish - taskStart) - task.executorDeserializeTime)
task.metrics.setExecutorCpuTime(
(taskFinishCpu - taskStartCpu) - task.executorDeserializeCpuTime)
task.metrics.setJvmGCTime(computeTotalGcTime() - startGCTime)
task.metrics.setResultSerializationTime(afterSerialization - beforeSerialization)
// Note: accumulator updates must be collected after TaskMetrics is updated
val accumUpdates = task.collectAccumulatorUpdates()
// TODO: do not serialize value twice
val directResult = new DirectTaskResult(valueBytes, accumUpdates)
val serializedDirectResult = ser.serialize(directResult)
val resultSize = serializedDirectResult.limit
// directSend = sending directly back to the driver
val serializedResult: ByteBuffer = {
if (maxResultSize > 0 && resultSize > maxResultSize) {
logWarning(s"Finished $taskName (TID $taskId). Result is larger than maxResultSize " +
s"(${Utils.bytesToString(resultSize)} > ${Utils.bytesToString(maxResultSize)}), " +
s"dropping it.")
ser.serialize(new IndirectTaskResult[Any](TaskResultBlockId(taskId), resultSize))
} else if (resultSize > maxDirectResultSize) {
val blockId = TaskResultBlockId(taskId)
env.blockManager.putBytes(
blockId,
new ChunkedByteBuffer(serializedDirectResult.duplicate()),
StorageLevel.MEMORY_AND_DISK_SER)
logInfo(
s"Finished $taskName (TID $taskId). $resultSize bytes result sent via BlockManager)")
ser.serialize(new IndirectTaskResult[Any](blockId, resultSize))
} else {
logInfo(s"Finished $taskName (TID $taskId). $resultSize bytes result sent to driver")
serializedDirectResult
}
}
setTaskFinishedAndClearInterruptStatus()
execBackend.statusUpdate(taskId, TaskState.FINISHED, serializedResult)
} catch {
case t: Throwable if hasFetchFailure && !Utils.isFatalError(t) =>
val reason = task.context.fetchFailed.get.toTaskFailedReason
if (!t.isInstanceOf[FetchFailedException]) {
// there was a fetch failure in the task, but some user code wrapped that exception
// and threw something else. Regardless, we treat it as a fetch failure.
val fetchFailedCls = classOf[FetchFailedException].getName
logWarning(s"TID ${taskId} encountered a ${fetchFailedCls} and " +
s"failed, but the ${fetchFailedCls} was hidden by another " +
s"exception. Spark is handling this like a fetch failure and ignoring the " +
s"other exception: $t")
}
setTaskFinishedAndClearInterruptStatus()
execBackend.statusUpdate(taskId, TaskState.FAILED, ser.serialize(reason))
case t: TaskKilledException =>
logInfo(s"Executor killed $taskName (TID $taskId), reason: ${t.reason}")
setTaskFinishedAndClearInterruptStatus()
execBackend.statusUpdate(taskId, TaskState.KILLED, ser.serialize(TaskKilled(t.reason)))
case _: InterruptedException | NonFatal(_) if
task != null && task.reasonIfKilled.isDefined =>
val killReason = task.reasonIfKilled.getOrElse("unknown reason")
logInfo(s"Executor interrupted and killed $taskName (TID $taskId), reason: $killReason")
setTaskFinishedAndClearInterruptStatus()
execBackend.statusUpdate(
taskId, TaskState.KILLED, ser.serialize(TaskKilled(killReason)))
case CausedBy(cDE: CommitDeniedException) =>
val reason = cDE.toTaskFailedReason
setTaskFinishedAndClearInterruptStatus()
execBackend.statusUpdate(taskId, TaskState.FAILED, ser.serialize(reason))
case t: Throwable =>
// Attempt to exit cleanly by informing the driver of our failure.
// If anything goes wrong (or this was a fatal exception), we will delegate to
// the default uncaught exception handler, which will terminate the Executor.
logError(s"Exception in $taskName (TID $taskId)", t)
// Collect latest accumulator values to report back to the driver
val accums: Seq[AccumulatorV2[_, _]] =
if (task != null) {
task.metrics.setExecutorRunTime(System.currentTimeMillis() - taskStart)
task.metrics.setJvmGCTime(computeTotalGcTime() - startGCTime)
task.collectAccumulatorUpdates(taskFailed = true)
} else {
Seq.empty
}
val accUpdates = accums.map(acc => acc.toInfo(Some(acc.value), None))
val serializedTaskEndReason = {
try {
ser.serialize(new ExceptionFailure(t, accUpdates).withAccums(accums))
} catch {
case _: NotSerializableException =>
// t is not serializable so just send the stacktrace
ser.serialize(new ExceptionFailure(t, accUpdates, false).withAccums(accums))
}
}
setTaskFinishedAndClearInterruptStatus()
execBackend.statusUpdate(taskId, TaskState.FAILED, serializedTaskEndReason)
// Don't forcibly exit unless the exception was inherently fatal, to avoid
// stopping other tasks unnecessarily.
if (Utils.isFatalError(t)) {
uncaughtExceptionHandler.uncaughtException(Thread.currentThread(), t)
}
} finally {
runningTasks.remove(taskId)
}
}
private def hasFetchFailure: Boolean = {
task != null && task.context != null && task.context.fetchFailed.isDefined
}
}
在Executor上运行task的时候,计算结果会保存在 org.apache.spark.scheduler.DirectTaskResult 中
package org.apache.spark.scheduler
/** A TaskResult that contains the task's return value and accumulator updates. */
private[spark] class DirectTaskResult[T](
var valueBytes: ByteBuffer,
var accumUpdates: Seq[AccumulatorV2[_, _]])
extends TaskResult[T] with Externalizable {
private var valueObjectDeserialized = false
private var valueObject: T = _
def this() = this(null.asInstanceOf[ByteBuffer], null)
override def writeExternal(out: ObjectOutput): Unit = Utils.tryOrIOException {
out.writeInt(valueBytes.remaining)
Utils.writeByteBuffer(valueBytes, out)
out.writeInt(accumUpdates.size)
accumUpdates.foreach(out.writeObject)
}
override def readExternal(in: ObjectInput): Unit = Utils.tryOrIOException {
val blen = in.readInt()
val byteVal = new Array[Byte](blen)
in.readFully(byteVal)
valueBytes = ByteBuffer.wrap(byteVal)
val numUpdates = in.readInt
if (numUpdates == 0) {
accumUpdates = Seq()
} else {
val _accumUpdates = new ArrayBuffer[AccumulatorV2[_, _]]
for (i <- 0 until numUpdates) {
_accumUpdates += in.readObject.asInstanceOf[AccumulatorV2[_, _]]
}
accumUpdates = _accumUpdates
}
valueObjectDeserialized = false
}
/**
* When `value()` is called at the first time, it needs to deserialize `valueObject` from
* `valueBytes`. It may cost dozens of seconds for a large instance. So when calling `value` at
* the first time, the caller should avoid to block other threads.
*
* After the first time, `value()` is trivial and just returns the deserialized `valueObject`.
*/
def value(resultSer: SerializerInstance = null): T = {
if (valueObjectDeserialized) {
valueObject
} else {
// This should not run when holding a lock because it may cost dozens of seconds for a large
// value
val ser = if (resultSer == null) SparkEnv.get.serializer.newInstance() else resultSer
valueObject = ser.deserialize(valueBytes)
valueObjectDeserialized = true
valueObject
}
}
}
在将结果传回到Driver 端的时候,会根据结果的大小使用不同的策略:
- 如果大于1G,则直接丢弃这个结果,不过在spark1.2之后,可以通过spark.driver.maxResultSize来进行设置
- 对于“较大”的结果,将其以taskId为key存入到org.apache.spark.storage.BlockManager;如果结果不大的话,则结果直接回传给Driver.那么如何确定这个阈值呢?这里的回传机制是直接通过AKKA的消息传递机制。因此结果首先不能超过该机制设置的消息的最大值。而这个最大值通过spark.akka.frameSize设置的。单位是MByte.默认值是10M,除此之外,还有200K的预留空间。因此这个阈值就是:cong.getInt("spark.akka.frameSize",10)*1024*1024-200*1024
- 其他情况则直接通过akka传递给Driver。具体实现如下
import org.apache.spark.Executor
// directSend = sending directly back to the driver
val serializedResult: ByteBuffer = {
if (maxResultSize > 0 && resultSize > maxResultSize) {
logWarning(s"Finished $taskName (TID $taskId). Result is larger than maxResultSize " +
s"(${Utils.bytesToString(resultSize)} > ${Utils.bytesToString(maxResultSize)}), " +
s"dropping it.")
ser.serialize(new IndirectTaskResult[Any](TaskResultBlockId(taskId), resultSize))
} else if (resultSize > maxDirectResultSize) {
val blockId = TaskResultBlockId(taskId)
env.blockManager.putBytes(
blockId,
new ChunkedByteBuffer(serializedDirectResult.duplicate()),
StorageLevel.MEMORY_AND_DISK_SER)
logInfo(
s"Finished $taskName (TID $taskId). $resultSize bytes result sent via BlockManager)")
ser.serialize(new IndirectTaskResult[Any](blockId, resultSize))
} else {
logInfo(s"Finished $taskName (TID $taskId). $resultSize bytes result sent to driver")
serializedDirectResult
}
}
setTaskFinishedAndClearInterruptStatus()
// 通过AKKA向Driver汇报本次Task已经完成
execBackend.statusUpdate(taskId, TaskState.FINISHED, serializedResult)
而execBackend是 org.apache.spark.executor.ExecutorBackend 的一个实例,它实际上是Executor与Driver通信的接口。
package org.apache.spark.executor
import java.nio.ByteBuffer
import org.apache.spark.TaskState.TaskState
/**
* A pluggable interface used by the Executor to send updates to the cluster scheduler.
*/
private[spark] trait ExecutorBackend {
def statusUpdate(taskId: Long, state: TaskState, data: ByteBuffer): Unit
}
TaskRunner会将Task的执行状态汇报给Driver(org.apache.spark.scheduler.cluster.CoarseGrainedSchedulerBackend.DriverActor).而Driver会转给 org.apache.spark.scheduler.TaskSchedulerImpl#statusUpdate.
2.3.2 Driver端的处理
TaskRunner将task的执行状态汇报给Driver之后,Driver会转给org.apache.spark.scheduler.TaskSchedulerImpl#statusUpdate.在这里,不同的状态有不同的处理:
org.apache.spark.scheduler
def statusUpdate(tid: Long, state: TaskState, serializedData: ByteBuffer) {
var failedExecutor: Option[String] = None
var reason: Option[ExecutorLossReason] = None
synchronized {
try {
taskIdToTaskSetManager.get(tid) match {
case Some(taskSet) =>
if (state == TaskState.LOST) {
// TaskState.LOST is only used by the deprecated Mesos fine-grained scheduling mode,
// where each executor corresponds to a single task, so mark the executor as failed.
val execId = taskIdToExecutorId.getOrElse(tid, throw new IllegalStateException(
"taskIdToTaskSetManager.contains(tid) <=> taskIdToExecutorId.contains(tid)"))
if (executorIdToRunningTaskIds.contains(execId)) {
reason = Some(
SlaveLost(s"Task $tid was lost, so marking the executor as lost as well."))
removeExecutor(execId, reason.get)
failedExecutor = Some(execId)
}
}
if (TaskState.isFinished(state)) {
cleanupTaskState(tid)
taskSet.removeRunningTask(tid)
if (state == TaskState.FINISHED) {
taskResultGetter.enqueueSuccessfulTask(taskSet, tid, serializedData)
} else if (Set(TaskState.FAILED, TaskState.KILLED, TaskState.LOST).contains(state)) {
taskResultGetter.enqueueFailedTask(taskSet, tid, state, serializedData)
}
}
case None =>
logError(
("Ignoring update with state %s for TID %s because its task set is gone (this is " +
"likely the result of receiving duplicate task finished status updates) or its " +
"executor has been marked as failed.")
.format(state, tid))
}
} catch {
case e: Exception => logError("Exception in statusUpdate", e)
}
}
// Update the DAGScheduler without holding a lock on this, since that can deadlock
if (failedExecutor.isDefined) {
assert(reason.isDefined)
dagScheduler.executorLost(failedExecutor.get, reason.get)
backend.reviveOffers()
}
}
- 如果类型是TaskState.FINISHED,那么调用org.apache.spark.scheduler.TaskResultGetter#enqueueSuccessfulTask 进行处理
- 对于enqueueSuccessfulTask逻辑,即如果是IndirectTaskResult,那么需要通过blockId来获取结果:sparkEnv.blockManager.getRemoteBytes(blockId);如果是 directTaskResult ,那么结果就无需远程获取了。具体实现为:
package org.apache.spark.scheduler def enqueueSuccessfulTask( taskSetManager: TaskSetManager, tid: Long, serializedData: ByteBuffer): Unit = { getTaskResultExecutor.execute(new Runnable { override def run(): Unit = Utils.logUncaughtExceptions { try { val (result, size) = serializer.get().deserialize[TaskResult[_]](serializedData) match { case directResult: DirectTaskResult[_] => if (!taskSetManager.canFetchMoreResults(serializedData.limit())) { return } // deserialize "value" without holding any lock so that it won't block other threads. // We should call it here, so that when it's called again in // "TaskSetManager.handleSuccessfulTask", it does not need to deserialize the value. directResult.value(taskResultSerializer.get()) (directResult, serializedData.limit()) case IndirectTaskResult(blockId, size) => if (!taskSetManager.canFetchMoreResults(size)) { // dropped by executor if size is larger than maxResultSize sparkEnv.blockManager.master.removeBlock(blockId) return } logDebug("Fetching indirect task result for TID %s".format(tid)) scheduler.handleTaskGettingResult(taskSetManager, tid) val serializedTaskResult = sparkEnv.blockManager.getRemoteBytes(blockId) if (!serializedTaskResult.isDefined) { /* We won't be able to get the task result if the machine that ran the task failed * between when the task ended and when we tried to fetch the result, or if the * block manager had to flush the result. */ scheduler.handleFailedTask( taskSetManager, tid, TaskState.FINISHED, TaskResultLost) return } val deserializedResult = serializer.get().deserialize[DirectTaskResult[_]]( serializedTaskResult.get.toByteBuffer) // force deserialization of referenced value deserializedResult.value(taskResultSerializer.get()) sparkEnv.blockManager.master.removeBlock(blockId) (deserializedResult, size) } // Set the task result size in the accumulator updates received from the executors. // We need to do this here on the driver because if we did this on the executors then // we would have to serialize the result again after updating the size. result.accumUpdates = result.accumUpdates.map { a => if (a.name == Some(InternalAccumulator.RESULT_SIZE)) { val acc = a.asInstanceOf[LongAccumulator] assert(acc.sum == 0L, "task result size should not have been set on the executors") acc.setValue(size.toLong) acc } else { a } } scheduler.handleSuccessfulTask(taskSetManager, tid, result) } catch { case cnf: ClassNotFoundException => val loader = Thread.currentThread.getContextClassLoader taskSetManager.abort("ClassNotFound with classloader: " + loader) // Matching NonFatal so we don't catch the ControlThrowable from the "return" above. case NonFatal(ex) => logError("Exception while getting task result", ex) taskSetManager.abort("Exception while getting task result: %s".format(ex)) } } }) }
- 对于enqueueSuccessfulTask逻辑,即如果是IndirectTaskResult,那么需要通过blockId来获取结果:sparkEnv.blockManager.getRemoteBytes(blockId);如果是 directTaskResult ,那么结果就无需远程获取了。具体实现为:
- 如果类型是TaskState.FAILED或者TaskState.KILLED或者TaskState.LOST.调用org.apache.spark.scheduler.TaskResultGetter#enqueueFailedTask 进行处理。对于TaskState.LOST还需要将其所在Executor标记为failed,并且根据更新后的Executor重新调度
- 如果task是ShuffleMapTask,那么,它需要通过某种机制将结果通知给下游的stage,以便于可以作为下游stage的输入。这个机制的实现如下:
对于ShuffleMapTask来说,其结果实际上是org.apache.spark.scheduler.MapStatus;其序列化后存入DirectTaskResult或InDirectTask.DAGScheduler#handleTaskComletion通过下面方式来获取数据:
/**
* Responds to a task finishing. This is called inside the event loop so it assumes that it can
* modify the scheduler's internal state. Use taskEnded() to post a task end event from outside.
*/
private[scheduler] def handleTaskCompletion(event: CompletionEvent) {
val task = event.task
val taskId = event.taskInfo.id
val stageId = task.stageId
val taskType = Utils.getFormattedClassName(task)
...
case smt: ShuffleMapTask =>
val shuffleStage = stage.asInstanceOf[ShuffleMapStage]
updateAccumulators(event)
val status = event.result.asInstanceOf[MapStatus]
val execId = status.location.executorId
logDebug("ShuffleMapTask finished on " + execId)
...
}
}
通过这个将status注册到 org.apache.spark.MapOutputTrackerMaster,就完成了结果的处理过程:
package org.apache.spark.scheduler
// TODO: This will be really slow if we keep accumulating shuffle map stages
for ((shuffleId, stage) <- shuffleIdToMapStage) {
stage.removeOutputsOnExecutor(execId)
mapOutputTracker.registerMapOutputs(
shuffleId,
stage.outputLocInMapOutputTrackerFormat(),
changeEpoch = true)
}
registerMapOutputs的实现逻辑如下:
package org.apache.spark
/** Register multiple map output information for the given shuffle */
def registerMapOutputs(shuffleId: Int, statuses: Array[MapStatus], changeEpoch: Boolean = false) {
mapStatuses.put(shuffleId, statuses.clone())
if (changeEpoch) {
incrementEpoch()
}
}
以shuffleId为key将MapStatues的列表存入ConcurrentHashMap中
以上是关于shuffle Write的一些源码阅读笔记,下一节继续解读Shuffle Read源码

 浙公网安备 33010602011771号
浙公网安备 33010602011771号