

正则表达式
首先正则ORACLE使用正则表达式的函数为REGEXP_LIKE():
下面这段可以匹配并只匹配出数字。
含义为: ^ 表示字符串的开始符 , [0-9] 表示任意一个数字, + 表示匹配一个或多个前个字符, $ 表示字符串的结束符。
SELECT * FROM REG_TEST WHERE REGEXP_LIKE(TEXT , '^[0-9]+$') ;
可以匹配的字符串:1234567890
下面这段SQL可以匹配出标准格式的千分符金额:
含义为单个字符含义:
| 符号 | 名称 | 含义 |
| ^ | 起始锚点 | 匹配字符串的开始位置 |
| $ | 结束锚点 | 匹配字符串的结束位置 |
| ? | 问号量词 | 匹配前面的元素零次或一次(即可选) |
| * | 星号量词 | 匹配前面的元素零次或多次(任意次) |
| + | 加号量词 | 匹配前面的元素一次或多次(至少一次) |
组合控制字符的含义为:
| 符号 | 名称 | 含义 |
| [] | 字符类 | 匹配方括号内的任意一个字符 |
| {} | 量词范围 | 匹配前面元素的指定次数 |
| () | 分组(子表达式) | 将多个元素组合成一个单元,并可捕获 |
SELECT * FROM REG_TEST WHERE REGEXP_LIKE(TEXT, '^[0-9]{1,3}(,[0-9]{3})*(\.[0-9]+)?$');
最后的执行的SQL为: 可匹配的字符类型为:12,123,234,555.031111111
匹配汉字字符 在ORACLE 用下面的代码可以查询到ORACLE基础的字符信息 , 查询结果如下图所示 , 其中 NLS_CHARACTERSET ZHS16GBK 为GBK格式
SELECT * FROM nls_database_parameters;
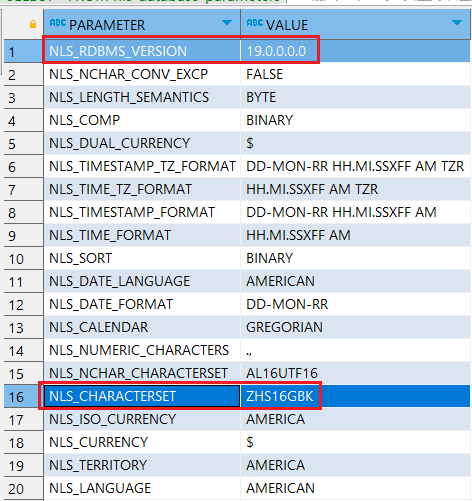
在GBK格式中 , \x00-\xFF 代表单个ASCII字符 , 而两个相连的ASCII字符代表中日韩字符 , 而 A-Za-z代表所有的英文。
SELECT * FROM REG_TEST WHERE REGEXP_LIKE(TEXT, '[^\x00-\xFF]{2}') -- 匹配至少2个非ASCII字符 AND NOT REGEXP_LIKE(TEXT, '[A-Za-z]') -- 排除任何英文字母

 浙公网安备 33010602011771号
浙公网安备 33010602011771号