xpath模块之猪八戒网找服务信息爬取
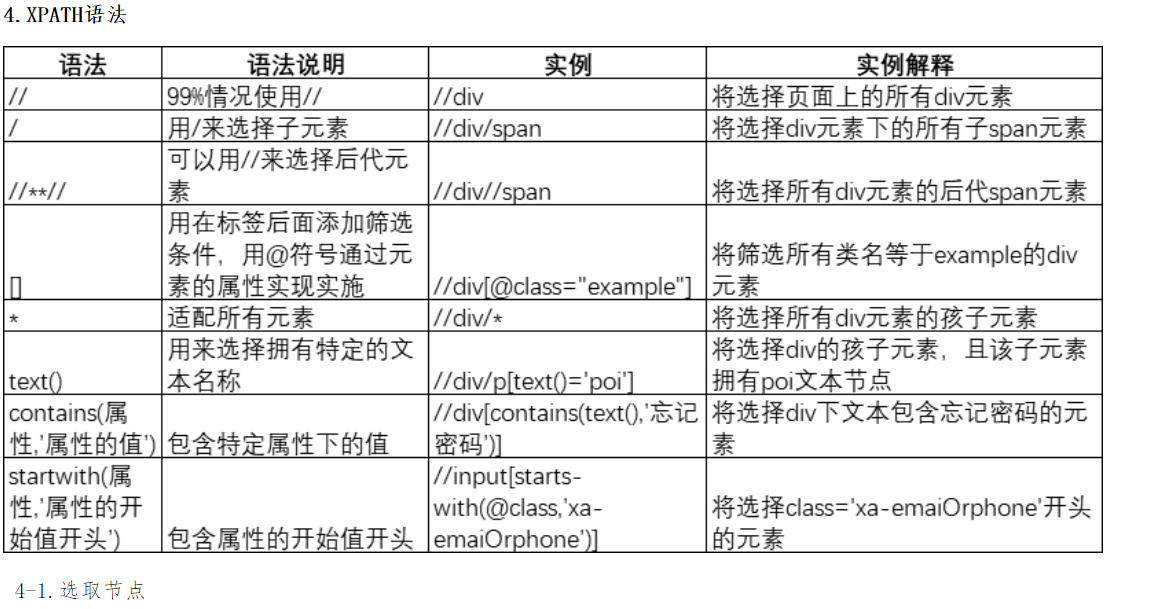
xpath基础语法
xpath获取的标签是下标从1开始

import requests
import csv
import time
from lxml import etree
# xpath写法: ,xpath('/标签/标签/@属性/text()内容')
#tree = etree.XML(string) .XML加载一个字符串
tree = etree.parse('百度.html') # parse 加载一个html文件
#res = tree.xpath('/html/body/*/p/text()') /*/是通配符,可以匹配任意的节点
#res = tree.xpath('/html/body/p/text()') 写出body下一级标签p
#res = tree.xpath('/html/body//p/text()') // 是写出body下所有标签中含有的p标签
#res = tree.xpath('/html/body/ul/li')
# for i in res:
# ans = i.xpath('./a/text()') # ./ 是用来继承上级目录
# print(ans)
# ans2 = i.xpath('./a/@href') # 获取某个标签的属性值 : @属性值
# print(ans2)
print(tree.xpath('/html/body/ul/li/a/text()'))
print(tree.xpath('/html/body/ul/li/a/@href'))
print(tree.xpath('/html/body/ul/li[3]/a/text()'))
实战
目标:我们的目标是获取提供服务的服务名称,企业名称,服务价格
我们这次搜索的服务是web前端开发
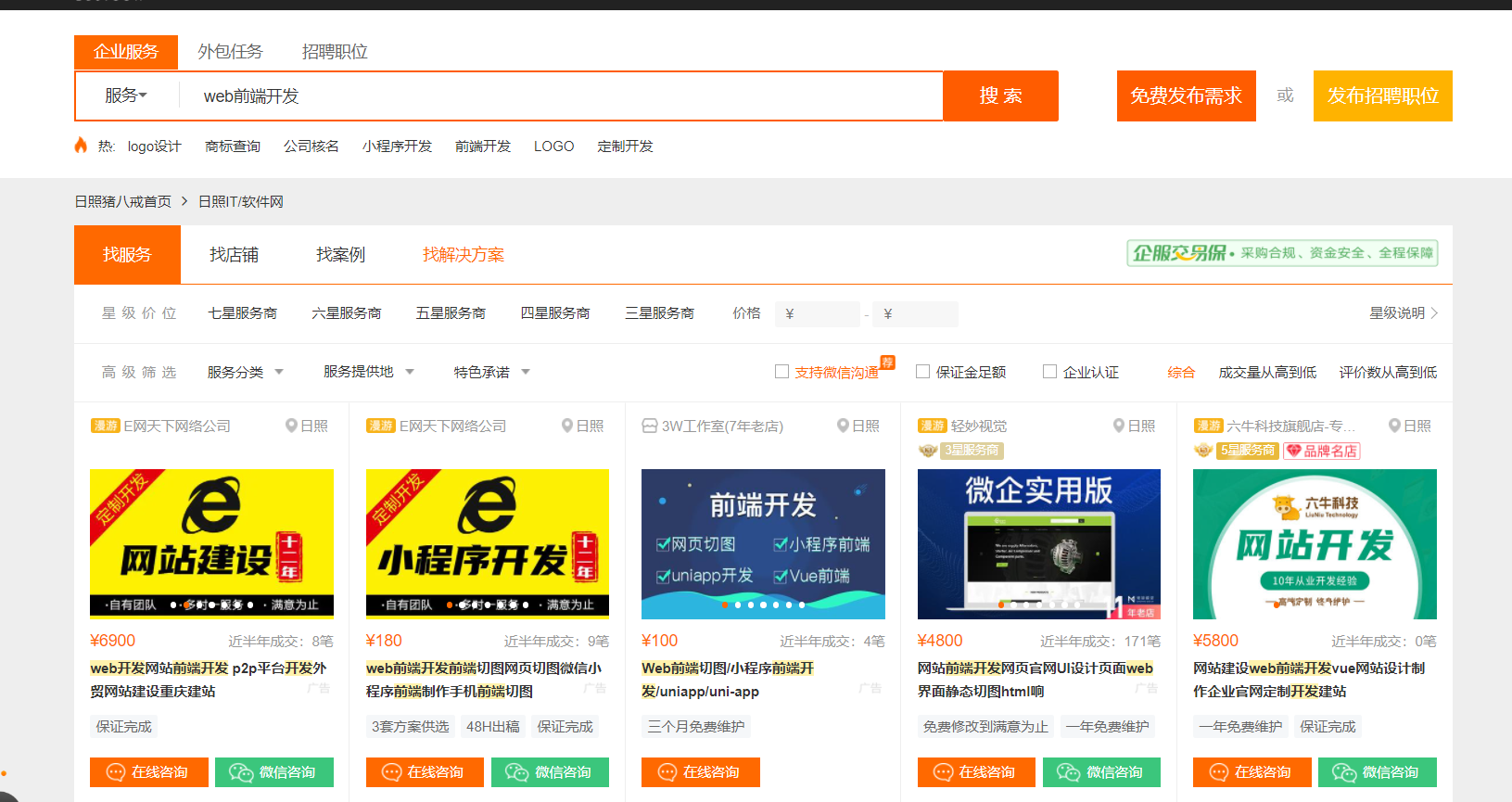
F12 进入检查获取源码
url = "https://rizhao.zbj.com/search/f/?kw=web%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36 Edg/95.0.1020.40'
}
reqs = requests.get(url,headers=headers)
reqs.encoding = 'utf-8'
数据分析
我们点击左上角图标
我们可以发现这个页面的信息是一格格镶嵌进去的,因此我们决定用xpath来解析
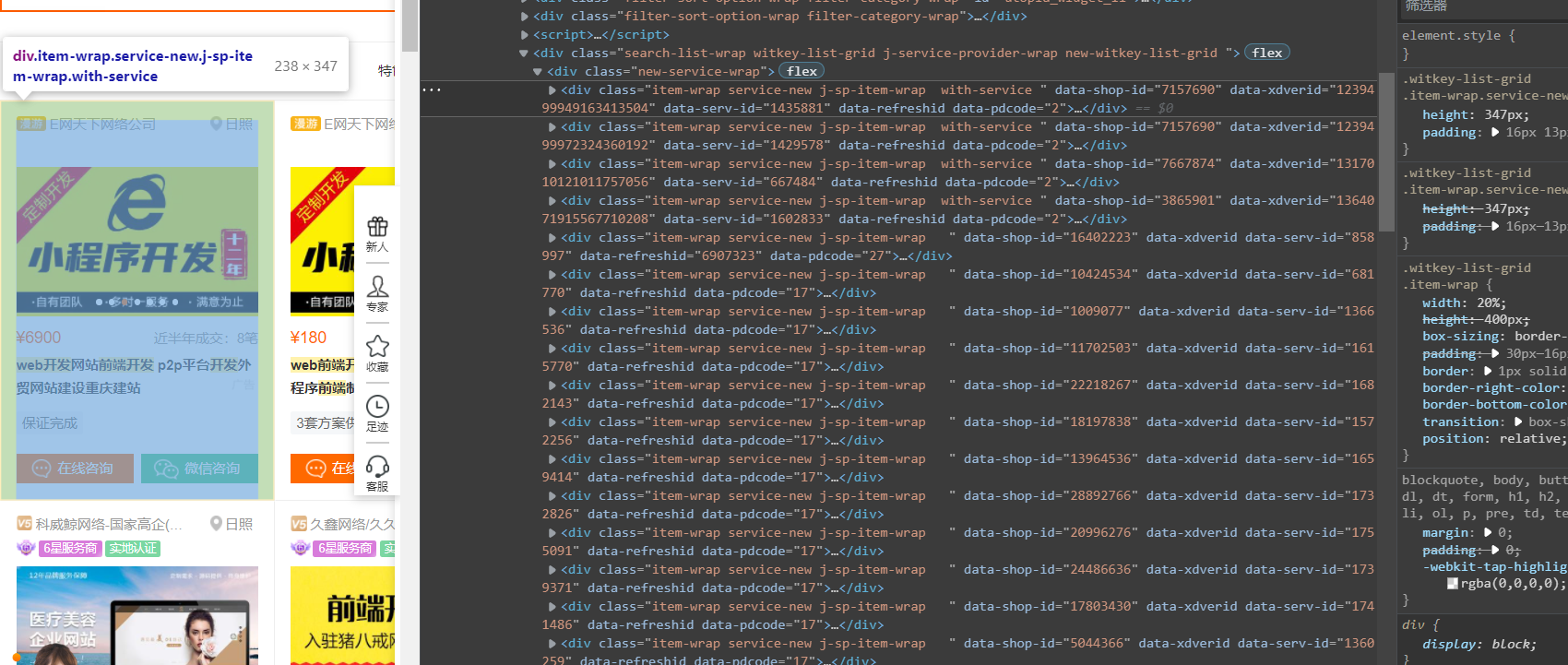
右键复制这个div标签的xpath路径
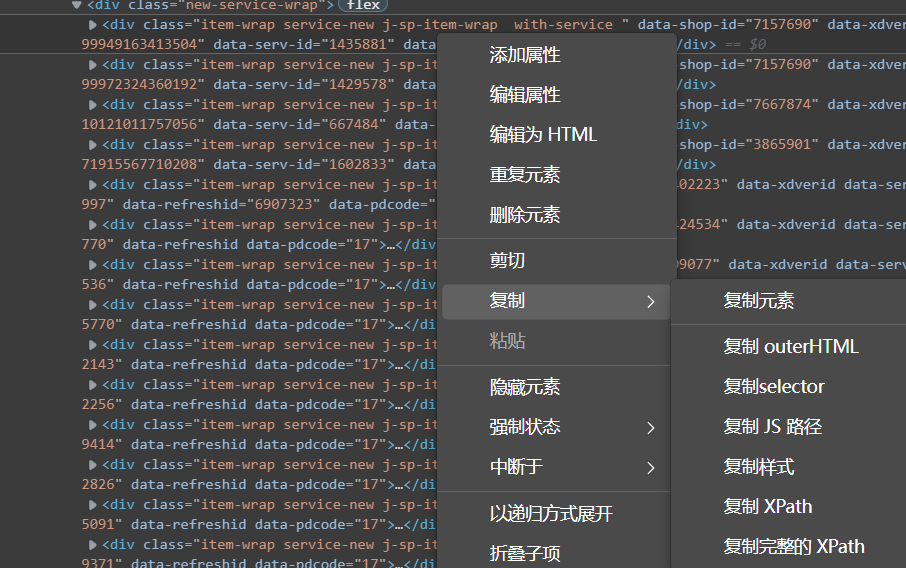
可以看到第一个服务信息对应的是./div[1]
所以我们去掉'[1]' 这样获取的就是所有服务的数据
/html/body/div[6]/div/div/div[2]/div[5]/div[1]/div[1]
提取数据
# 提取数据
html = etree.HTML(reqs.text) # HTML对html源码进行加载
divs = html.xpath("/html/body/div[6]/div/div/div[2]/div[5]/div[1]/div")
之后我们可以开一个循环,遍历所有的服务数据,爬取我们需要的信息
以公司名称位例:
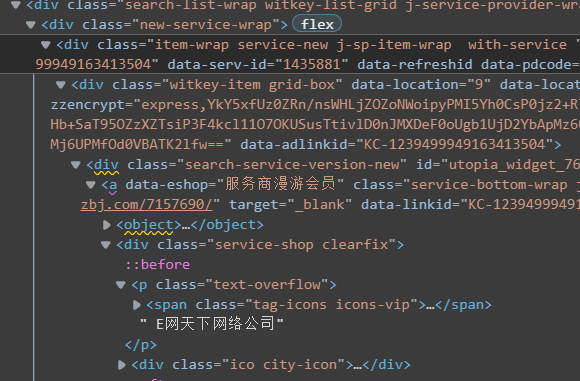
名称是在子标签下的两层div下的a[1]下的div[1]下的p标签内容(右键复制
xpath路径然后删改一下就可)
company = i.xpath("./div/div/a[1]/div[1]/p/text()")[1].strip('\n')
code:
import csv
import requests
from lxml import etree
# 获取源码
# 提取数据
url = "https://rizhao.zbj.com/search/f/?kw=web%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36 Edg/95.0.1020.40'
}
reqs = requests.get(url,headers=headers)
reqs.encoding = 'utf-8'
# 提取数据
html = etree.HTML(reqs.text) # HTML对html源码进行加载
divs = html.xpath("/html/body/div[6]/div/div/div[2]/div[5]/div[1]/div")
# 写入文件
for i in divs:
price = i.xpath("./div/div/a[2]/div[2]/div[1]/span[1]/text()")[0]
title = "web前端开发".join(i.xpath("./div/div/a[2]/div[2]/div[2]/p/text()"))
company = i.xpath("./div/div/a[1]/div[1]/p/text()")[1].strip('\n')
s = '项目:' + title + ' 价格:' + price + ' 公司:' + company + '\n'
# print(s)
with open('八戒网爬取.csv', 'a', encoding='utf-8') as f:
f.write(s)
reqs.close()
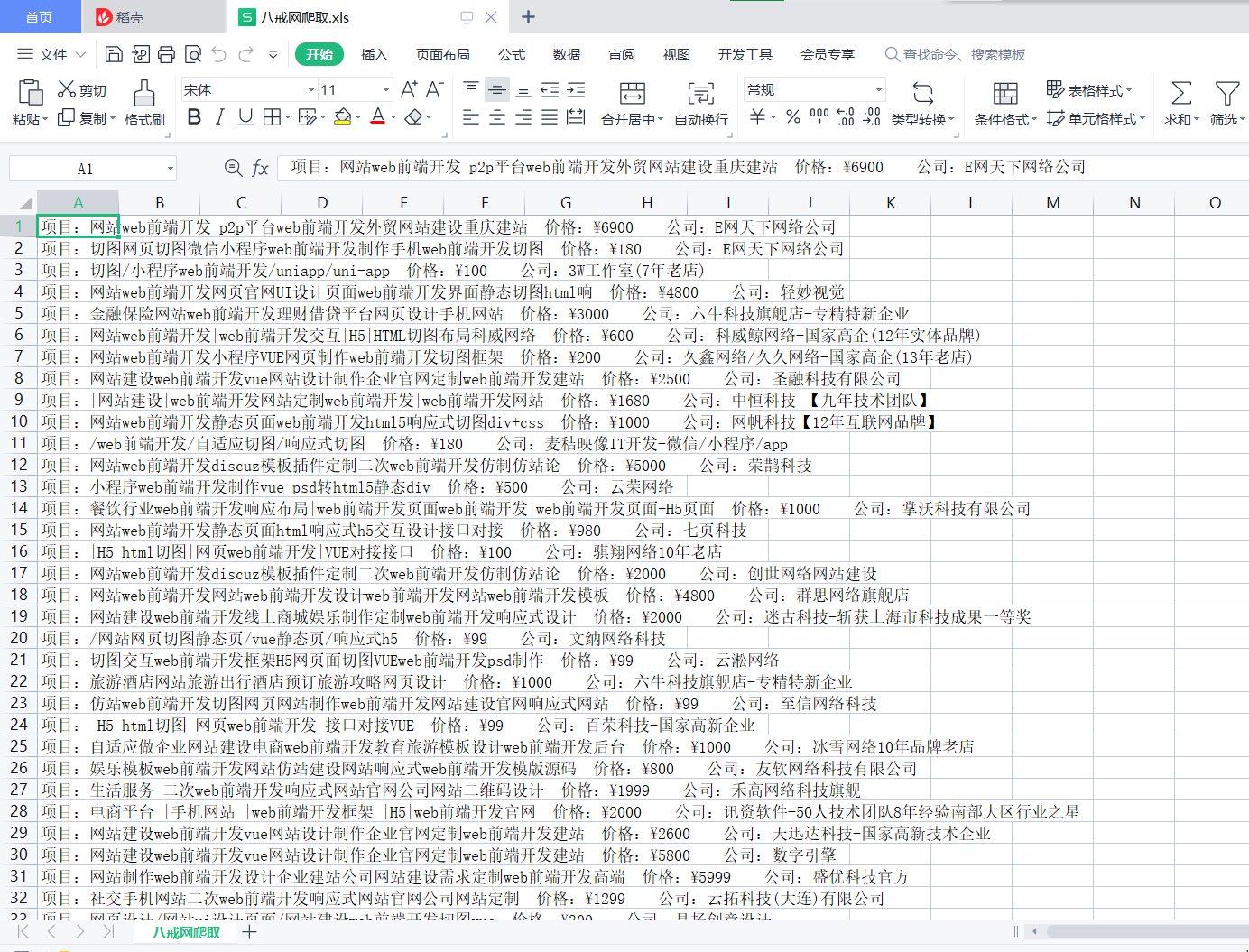
效果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号